En 2022, I (Anna) escribí una propuesta para proponer un modelo base propiedad del usuario capacitado con datos privados en lugar de arrastrarse públicamente de Internet.Creo que si bien es posible capacitar a modelos básicos utilizando datos públicos (por ejemplo, Wikipedia, 4chan), para llevarlos al siguiente nivel, necesita datos privados de alta calidad que solo exista en lo que necesita permisos o inicio de sesión para acceder a aislados plataformas (como Twitter, mensajes personales, información de la empresa).
Esta predicción está comenzando a entrar en vigencia.Empresas como Reddit y Twitter se han dado cuenta del valor de los datos de su plataforma, por lo que encerraron la API del desarrollador (1, 2) para evitar que otras compañías usen libremente sus datos de texto para capacitar al modelo subyacente.
Esto ha cambiado drásticamente en comparación con hace dos años.El capitalista de riesgo Sam Lessin resumió el cambio: “[La plataforma] simplemente tira esta basura, nadie se ocupa de ella, y de repente, estás como, oh, maldita sea, esa basura es oro, ¿verdad? Lo conseguimos mucho.Esto ya no es posible después de usar la nueva API de Reddit.
Internet se está volviendo cada vez más sin abrir, y las plataformas aisladas construyen muros más grandes para proteger sus valiosos datos de capacitación.
Aunque los desarrolladores ya no pueden acceder a estos datos a gran escala, las personas aún pueden acceder y exportar sus propios datos a través de las plataformas debido a las regulaciones de privacidad de los datos (5, 6).El hecho de que la plataforma se bloquee en la API del desarrollador, mientras que los usuarios individuales aún tienen acceso a sus propios datos brindan una oportunidad: ¿pueden 100 millones de usuarios exportar sus datos de plataforma para crear la casa de datos del tesoro más grande del mundo?Esta casa de datos del tesoro agregará todos los datos de los usuarios recopilados por grandes empresas tecnológicas y otras compañías que a menudo son reacios a compartir.Este será el conjunto de datos de capacitación más grande y completo hasta la fecha, 100 veces más grande que el conjunto de datos utilizado para capacitar a los principales modelos fundamentales de hoy.1
Tabla 1. Datos
Una estimación aproximada de comparar el conjunto de datos de capacitación de modelo básico con el conjunto de datos de usuario de la muestra.Fuente y cálculo.

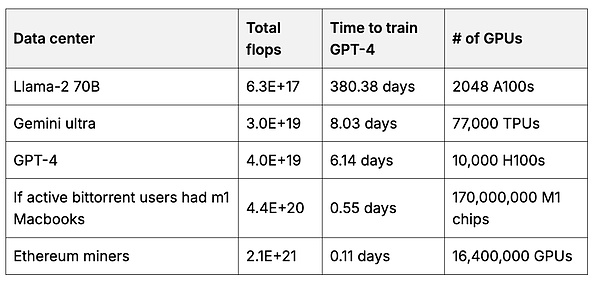
El usuario puede crear un modelo básico que el usuario tiene, que utiliza más datos de los que cualquier empresa puede agregar.Entrenar el modelo básico requiere muchos cálculos de GPU.Pero cada usuario puede usar su propio hardware para ayudar a entrenar una pequeña porción del modelo, y luego fusionar estas partes para crear un modelo más grande y más potente (7, 8, 9).2 Cuando los incentivos son apropiados, los usuarios pueden recopilar una gran cantidad de cálculos.Por ejemplo, la cantidad total de cálculo para los mineros de Ethereum es 50 veces más de lo que se utilizan para entrenar modelos básicos líderes.
Tabla 2. Cálculo
El número total de operaciones de punto flotante (flotante por segundo = suma de las velocidades de «pensamiento») del centro de datos utilizado para entrenar el modelo subyacente en comparación con la GPU de Miner Ethereum.3 con la fuente de cálculo.
Los usuarios que contribuyen al modelo poseerán y administrarán colectivamente el modelo.Se pueden pagar al usar el modelo, e incluso proporcionalmente en función de cuánto mejoran sus datos el modelo.Los colectivos pueden establecer reglas de uso, incluido quién puede acceder al modelo y qué controles deben implementarse.Quizás los usuarios en cada país crearán sus propios modelos que representen su ideología y cultura.O tal vez un país no es la línea divisoria correcta, veremos un mundo donde cada país de la red tiene su propio modelo subyacente basado en los datos de sus miembros.
Le animo a que se tome el tiempo para pensar en qué parte del modelo subyacente desea tener y qué datos de capacitación puede contribuir desde la plataforma que usa.Es posible que tenga más datos de los que se da cuenta: sus trabajos de investigación, obras de arte no publicadas, su documentación de Google, su perfil de citas, sus registros médicos, sus mensajes de Slack.Una forma de reunir estos datos es a través de un servidor personal, que le permite usar fácilmente sus datos privados con su LLM local.En el futuro, su servidor personal también puede entrenar parte del modelo de base de usuarios que tiene.
Los modelos subyacentes tienden a ser monopolísticos porque requieren una inversión sustancial en los datos y la computación.Es fácil elegir la opción simple: use el modelo de código abierto que se queda atrás de las generaciones, los restos de las grandes compañías de IA, como podemos.¡Pero no debemos estar satisfechos con quedarnos atrás de las generaciones y comer solo las sobras!Como usuarios, debemos crear nuestro propio mejor modelo: tenemos los datos y el poder informático para lograr esto.
Como AI es cada vez más capaz de completar un valioso trabajo económico, está ocurriendo una gran transformación económica.Las grandes empresas tecnológicas han capacitado a modelos de IA basados en su trabajo público, escritura, obras de arte, fotos y otros datos, y otros, y comienzan a ganar miles de millones de dólares al año (1).Ahora están persiguiendo datos que no puede obtener en Internet público, comprando sus datos privados de compañías como Reddit para que puedan aumentar sus ingresos de IA a billones de dólares por año (2, 3).
¿No debería tener una parte de un modelo de IA creado por su ayuda de datos?
Aquí es donde funciona los datos DAO.Data DAO es una entidad descentralizada que permite a los usuarios agregar y administrar sus datos y recompensar a los contribuyentes con tokens específicos que representan la propiedad de un conjunto de datos específico.Es como una unión de datos.Estos conjuntos de datos pueden replicar o incluso superar los conjuntos de datos vendidos por grandes compañías tecnológicas por cientos de millones de dólares (4).DAO tiene control total sobre el conjunto de datos y tiene la opción de alquilar o vender copias anónimas.Por ejemplo, los datos de Reddit incluso se pueden usar para sembrar nuevas plataformas de propiedad de usuarios, incluidos amigos, sus publicaciones anteriores y otros datos que se pueden usar en cualquier momento en la nueva plataforma.
Si está interesado en los detalles técnicos: Data DAO tiene dos componentes principales: 1) Gobernanza en la cadena, obtener tokens a través de las contribuciones de datos; .Para contribuir, primero debe verificar los datos para probar la propiedad y estimar su valor.Luego, use la clave pública del servidor para cifrar los datos en el navegador y almacenar los datos encriptados en la nube.Los datos se descifran solo cuando el DAO aprueba la propuesta de otorgar acceso.Por ejemplo, podría permitir a las compañías de IA alquilar datos para capacitar modelos.Puede leer más sobre la arquitectura de la red VANA aquí, cuyo objetivo es implementar la propiedad colectiva de conjuntos de datos y modelos.
Data DAO no solo beneficia a los usuarios, sino que también impulsa el desarrollo de la IA, lo que hace posible construir IA como software de código abierto, beneficiando a todos los que contribuyen.La IA de código abierto está luchando por encontrar modelos comerciales viables: es muy costoso pagar GPU, datos e investigadores.Y, una vez que el modelo está capacitado, si es de código abierto, estos costos no se pueden recuperar.La arquitectura técnica de los datos DAO se puede aplicar al modelo DAO, donde los usuarios y desarrolladores pueden contribuir con datos, cálculos e investigación a cambio de la propiedad del modelo.
La opción predeterminada en la sociedad actual es permitir que grandes empresas tecnológicas obtengan nuestros datos y los usen para capacitar a los modelos de IA que funcionan para nosotros.Se benefician de estos modelos de IA porque somos reemplazados por modelos capacitados con nuestros datos.Este es un trato muy malo para la sociedad, pero algo bueno para las grandes empresas tecnológicas.La única forma de evitar que esto suceda es tomar medidas colectivas.Los datos son moneda, y los datos colectivos son potencia.Le animo a participar: los primeros datos del mundo centrados en los datos de Reddit DAO están en línea hoy en la red VANA.Al romper el foso de datos controlado por la minoría privilegiada, Data DAO ha abierto una ruta a Internet propiedad de usuarios reales.