En 2022, I (Anna) a écrit une proposition pour proposer un modèle de base appartenant à l’utilisateur formé à l’aide de données privées plutôt que de ramper publiquement sur Internet.Je pense que s’il est possible de former des modèles de base en utilisant des données publiques (par exemple Wikipedia, 4Chan), pour les faire passer au niveau supérieur, vous avez besoin de données privées de haute qualité qui n’existent que dans ce dont vous avez besoin d’autorisations ou de connexion pour accéder à l’isolement isolé plates-formes (telles que Twitter, messages personnels, informations de l’entreprise).
Cette prédiction commence à entrer en vigueur.Des entreprises comme Reddit et Twitter ont réalisé la valeur des données de leur plate-forme, elles ont donc verrouillé l’API du développeur (1, 2) pour empêcher d’autres sociétés d’utiliser librement leurs données de texte pour former le modèle sous-jacent.
Cela a changé considérablement par rapport à il y a deux ans.Le capital-risqueur Sam Lessin a résumé le changement: «[La plate-forme] jette juste cette poubelle derrière, personne ne s’en occupe, et puis tout d’un coup, tu es comme, oh, putain, cette poubelle est l’or, non? Nous l’avons beaucoup.Ce n’est plus possible après avoir utilisé la nouvelle API de Reddit.
Internet devient de plus en plus non ouvert et les plates-formes isolées construisent des murs plus grands pour protéger leurs précieuses données de formation.
Bien que les développeurs ne puissent plus accéder à ces données à grande échelle, les individus peuvent toujours accéder et exporter leurs propres données sur toutes les plateformes en raison des réglementations de confidentialité des données (5, 6).Le fait que la plate-forme verrouille l’API du développeur, tandis que les utilisateurs individuels ont encore accès à leurs propres données offrent une opportunité: 100 millions d’utilisateurs peuvent-ils exporter leurs données de plate-forme pour créer le plus grand trésor des données au monde?Ce trésor des données agrégera toutes les données des utilisateurs collectées par les grandes entreprises technologiques et d’autres sociétés qui sont souvent réticentes à partager.Ce sera le jeu de données de formation le plus grand et le plus complet à ce jour, 100 fois plus grand que l’ensemble de données utilisé pour former les principaux modèles fondamentaux d’aujourd’hui.1
Tableau 1. Données
Une estimation approximative de la comparaison de l’ensemble de données de formation de modèle de base avec l’ensemble de données de l’utilisateur de l’échantillon.Source et calcul.

L’utilisateur peut ensuite créer un modèle de base que l’utilisateur possède, qui utilise plus de données que n’importe quelle entreprise peut agréger.La formation du modèle de base nécessite beaucoup de calculs GPU.Mais chaque utilisateur peut utiliser son propre matériel pour aider à former une petite partie du modèle, puis fusionner ces pièces ensemble pour créer un modèle plus grand et plus puissant (7, 8, 9).2 Lorsque les incitations sont appropriées, les utilisateurs peuvent rassembler un grand nombre de calculs.Par exemple, la quantité totale de calcul pour les mineurs Ethereum est 50 fois plus que celles utilisées pour former des modèles de base de base.
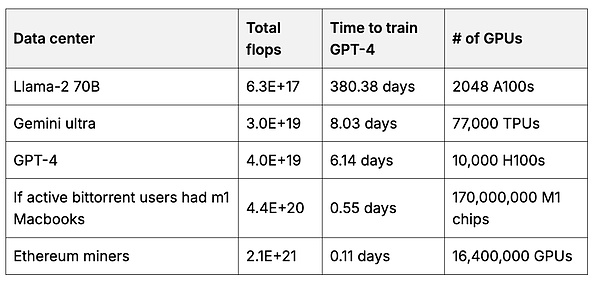
Tableau 2. Calcul
Le nombre total d’opérations à virgule flottante (flotteur par seconde = somme des vitesses de « pensée ») du centre de données utilisé pour former le modèle sous-jacent par rapport au GPU de mineur Ethereum.3 avec la source de calcul.
Les utilisateurs qui contribuent au modèle posséderont et géreront collectivement le modèle.Ils peuvent être payés lors de l’utilisation du modèle, et même proportionnellement en fonction de la quantité de données améliorent le modèle.Les collectifs peuvent définir des règles d’utilisation, y compris qui peut accéder au modèle et quels contrôles doivent être mis en œuvre.Peut-être que les utilisateurs de chaque pays créeront leurs propres modèles qui représenteront leur idéologie et leur culture.Ou peut-être qu’un pays n’est pas la bonne ligne de démarcation, nous verrons un monde où chaque pays de réseau a son propre modèle sous-jacent basé sur ses données membres.
Je vous encourage à prendre le temps de réfléchir à la partie du modèle sous-jacent que vous souhaitez avoir et aux données de formation que vous pouvez contribuer à partir de la plate-forme que vous utilisez.Vous pouvez avoir plus de données que vous ne le pensez – vos articles de recherche, les illustrations non publiées, votre documentation Google, votre profil de rencontres, vos dossiers médicaux, vos messages Slack.Une façon de rassembler ces données est via un serveur personnel, qui vous permet d’utiliser facilement vos données privées avec votre LLM local.À l’avenir, votre serveur personnel peut également former une partie du modèle de base d’utilisateurs que vous avez.
Les modèles sous-jacents ont tendance à être monopolistiques car ils nécessitent des investissements initiaux substantiels dans les données et l’informatique.Il est facile de choisir l’option simple: utiliser le modèle open source qui est à la traîne par rapport aux générations, les restes de grandes sociétés d’IA, comme nous le pouvons.Mais nous ne devons pas être satisfaits de prendre du retard sur les générations et de ne manger que des restes!En tant qu’utilisateurs, nous devons créer notre meilleur modèle – nous avons les données et la puissance de calcul pour y parvenir.
Comme l’IA est de plus en plus capable de réaliser un travail économique précieux, une énorme transformation économique se produit.Les grandes entreprises technologiques ont formé des modèles d’IA en fonction de votre travail public, de l’écriture, de l’œuvre d’art, des photos et d’autres données, et d’autres, et commencez à gagner des milliards de dollars par an (1).Ils poursuivent désormais des données que vous ne pouvez pas obtenir sur Internet public, achetant vos données privées auprès d’entreprises comme Reddit afin qu’ils puissent augmenter leurs revenus d’IA à des milliards de dollars par an (2, 3).
Ne devriez-vous pas avoir une partie d’un modèle d’IA créé par votre aide de données?
C’est là que fonctionne les données DAO.Data DAO est une entité décentralisée qui permet aux utilisateurs d’agréger et de gérer leurs données et de récompenser les contributeurs avec des jetons spécifiques représentant la propriété d’un ensemble de données spécifique.C’est un peu comme un syndicat de données.Ces ensembles de données peuvent reproduire ou même dépasser les ensembles de données vendus par de grandes entreprises technologiques pour des centaines de millions de dollars (4).DAO a un contrôle total sur l’ensemble de données et a la possibilité de louer ou de vendre des copies anonymes.Par exemple, les données Reddit peuvent même être utilisées pour semer de nouvelles plates-formes appartenant à des utilisateurs, y compris des amis, vos publications passées et d’autres données qui peuvent être utilisées à tout moment sur la nouvelle plate-forme.
Si vous êtes intéressé par les détails techniques: les données DAO ont deux composantes principales: 1) la gouvernance sur la chaîne, l’obtention de jetons par le biais de contributions de données; .Pour contribuer, vous devez d’abord vérifier les données pour prouver la propriété et estimer sa valeur.Ensuite, utilisez la clé publique du serveur pour crypter les données du navigateur et stocker les données cryptées dans le cloud.Les données sont déchiffrées uniquement lorsque le DAO approuve la proposition d’accorder l’accès.Par exemple, cela pourrait permettre aux entreprises d’IA de louer des données pour former des modèles.Vous pouvez en savoir plus sur l’architecture du réseau VANA ici, qui vise à implémenter la propriété collective des ensembles de données et des modèles.
Data DAO profite non seulement aux utilisateurs, mais stimule également le développement de l’IA, ce qui permet de créer une IA comme des logiciels open source, bénéficiant à tous ceux qui contribuent.L’IA open source a du mal à trouver des modèles commerciaux viables: il est très coûteux de payer des GPU, des données et des chercheurs.Et, une fois le modèle formé, s’il est open source, ces coûts ne peuvent pas être récupérés.L’architecture technique des données DAO peut être appliquée au modèle DAO, où les utilisateurs et les développeurs peuvent apporter des données, des calculs et des recherches en échange de la propriété du modèle.
L’option par défaut dans la société d’aujourd’hui est de permettre aux grandes entreprises technologiques d’obtenir nos données et de les utiliser pour former les modèles d’IA qui fonctionnent pour nous.Ils profitent de ces modèles d’IA car nous sommes remplacés par des modèles formés par nos données.C’est une très mauvaise affaire pour la société, mais une bonne chose pour les grandes entreprises technologiques.La seule façon d’empêcher cela de se produire est de prendre des mesures collectives.Les données sont de la monnaie et les données collectives sont la puissance.Je vous encourage à participer: les premières données du monde axées sur les données de Reddit Dao sont en ligne aujourd’hui sur le réseau VANA.En cassant les douves de données contrôlées par la minorité privilégiée, Data DAO a ouvert un chemin vers Internet appartenant à de vrais utilisateurs.