Im Jahr 2022 schrieb ich (Anna) einen Vorschlag, ein benutzerbezogenes Basismodell vorzuschlagen, das mit privaten Daten geschult wurde, anstatt öffentlich aus dem Internet zu kroch.Ich denke, obwohl es möglich ist, grundlegende Modelle mithilfe öffentlicher Daten (z. B. Wikipedia, 4chan) zu schulen, um sie auf die nächste Stufe zu bringen, benötigen Sie hochwertige private Daten, die nur in den Berechtigungen oder Anmeldungen in isoliertem Zugriff vorhanden sind Plattformen (wie Twitter, persönliche Nachrichten, Unternehmensinformationen).
Diese Vorhersage beginnt in Kraft zu treten.Unternehmen wie Reddit und Twitter haben den Wert ihrer Plattformdaten erkannt und haben also die Entwickler -API (1, 2) gesperrt, um zu verhindern, dass andere Unternehmen ihre Textdaten frei verwenden, um das zugrunde liegende Modell zu schulen.
Dies hat sich im Vergleich zu zwei Jahren dramatisch verändert.Venture -Capitalist Sam Lessin fasste die Änderung zusammen: „[Die Plattform] wirft diesen Müll nur hinter sich, niemand kümmert sich darum, und plötzlich sind Sie wie, oh, verdammt, dieser Müll ist Gold, oder? Wir haben es viel.Dies ist nach der Verwendung der neuen API von Reddit nicht mehr möglich.
Das Internet wird immer ungeöffnet, und isolierte Plattformen bauen größere Wände auf, um ihre wertvollen Schulungsdaten zu schützen.
Obwohl Entwickler in großem Maßstab nicht mehr auf diese Daten zugreifen können, können Einzelpersonen aufgrund von Datenschutzbestimmungen auf ihre eigenen Daten über Plattformen hinweg zugreifen (5, 6).Die Tatsache, dass die Plattform in der Entwickler -API sperrt, während einzelne Benutzer weiterhin Zugriff auf ihre eigenen Daten haben, bietet eine Chance: Können 100 Millionen Benutzer ihre Plattformdaten exportieren, um das weltweit größte Schatzhaus der Daten zu erstellen?Dieses Schatzhaus der Daten wird alle von großen Technologieunternehmen und anderen Unternehmen gesammelten Benutzerdaten zusammengefasst, die häufig nicht tendieren.Dies wird der bislang größte und umfassendste Schulungsdatensatz sein, das 100 -mal größer ist als der Datensatz, mit dem die führenden grundlegenden Modelle von heute geschult werden.1
Tabelle 1. Daten
Eine grobe Schätzung zum Vergleich des Basismodell -Schulungsdatensatzes mit dem Beispielbenutzer -Datensatz.Quelle und Berechnung.

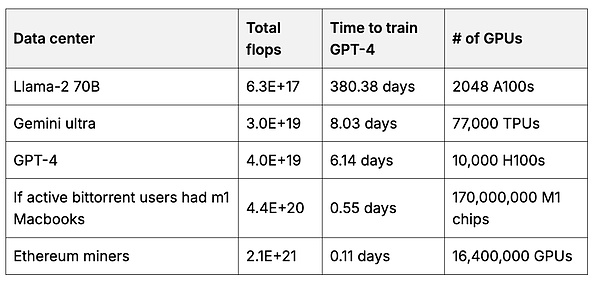
Der Benutzer kann dann ein grundlegendes Modell erstellen, das der Benutzer hat und das mehr Daten verwendet, als jedes Unternehmen aggregieren kann.Training Das Grundmodell erfordert viele GPU -Berechnungen.Jeder Benutzer kann seine eigene Hardware verwenden, um einen kleinen Teil des Modells zu trainieren und diese Teile dann zusammenzuführen, um ein größeres und leistungsfähigeres Modell zu erstellen (7, 8, 9).2 Wenn Anreize angemessen sind, können Benutzer eine große Anzahl von Berechnungen sammeln.Beispielsweise beträgt die Gesamtberechnung für Ethereum -Miner 50 -mal mehr als sie zum Training führender Grundmodelle verwendet werden.
Tabelle 2. Berechnung
Die Gesamtzahl der Gleitkommaoperationen (Float pro Sekunde = Summe der „Denkgeschwindigkeiten“ des Rechenzentrums, mit dem das zugrunde liegende Modell im Vergleich zur GPU von Ethereum Miner geschult wurde.3 mit der Berechnung der Quelle.
Benutzer, die zum Modell beitragen, werden das Modell gemeinsam besitzen und verwalten.Sie können bei der Verwendung des Modells bezahlt werden und sogar proportional basierend darauf, wie viel ihre Daten das Modell verbessern.Kollektive können Nutzungsregeln festlegen, einschließlich der, wer auf das Modell zugreifen kann und welche Kontrollen implementiert werden sollten.Vielleicht erstellen Benutzer in jedem Land ihre eigenen Modelle, die ihre Ideologie und Kultur repräsentieren.Oder vielleicht ist ein Land nicht die richtige Trennlinie, wir werden eine Welt sehen, in der jedes Netzwerkland ein eigenes Modell auf der Grundlage seiner Mitgliedsdaten hat.
Ich ermutige Sie, sich die Zeit zu nehmen, um darüber nachzudenken, welchen Teil des zugrunde liegenden Modells Sie haben möchten und welche Trainingsdaten Sie von der von Ihnen verwendeten Plattform beitragen können.Möglicherweise haben Sie mehr Daten als Sie erkennen – Ihre Forschungsarbeiten, unveröffentlichte Grafiken, Ihre Google -Dokumentation, Ihr Dating -Profil, Ihre medizinischen Unterlagen, Ihre Slack -Nachrichten.Eine Möglichkeit, diese Daten zusammenzubringen, ist über einen persönlichen Server, mit dem Sie Ihre privaten Daten einfach mit Ihrem lokalen LLM verwenden können.In Zukunft kann Ihr persönlicher Server auch einen Teil des Benutzerbasismodells trainieren, das Sie haben.
Die zugrunde liegenden Modelle sind in der Regel monopolistisch, da sie erhebliche Vorabinvestitionen in Daten und Computer erfordern.Es ist einfach, die einfache Option auszuwählen: Verwenden Sie das Open -Source -Modell, das hinter Generationen zurückbleibt, die Überreste großer KI -Unternehmen, so wie wir können.Aber wir sollten nicht zufrieden sein, wenn wir hinter Generationen fallen und nur Reste essen!Als Benutzer sollten wir unser eigenes bestes Modell erstellen – wir haben die Daten und die Rechenleistung, um dies zu erreichen.
Da KI zunehmend in der Lage ist, wertvolle wirtschaftliche Arbeit zu erledigen, tritt eine enorme wirtschaftliche Transformation auf.Große Technologieunternehmen haben KI -Modelle basierend auf Ihrer öffentlichen Arbeit, Schreiben, Kunstwerken, Fotos und anderen Daten und anderen geschult und verdienen Milliarden von Dollar pro Jahr (1).Sie verfolgen jetzt Daten, die Sie nicht im öffentlichen Internet erhalten können, und kaufen Ihre privaten Daten von Unternehmen wie Reddit, damit sie ihre KI -Einnahmen auf Billionen Dollar pro Jahr erhöhen können (2, 3).
Sollten Sie nicht einen Teil eines KI -Modells haben, das von Ihren Datenhilfe erstellt wurde?
Hier funktioniert die Daten Dao.Data DAO ist eine dezentrale Einheit, mit der Benutzer ihre Daten zusammenfassen und verwalten können und die Mitwirkenden mit spezifischen Token, die das Eigentum eines bestimmten Datensatzes darstellen, zu aggregieren und zu belohnen.Es ist wie eine Data Union.Diese Datensätze können Datensätze replizieren oder sogar übertreffen, die von großen Technologieunternehmen für Hunderte von Millionen Dollar verkauft werden (4).DAO hat die volle Kontrolle über den Datensatz und hat die Möglichkeit, anonyme Kopien zu mieten oder zu verkaufen.Beispielsweise können Reddit-Daten sogar verwendet werden, um neue, benutzerbezogene Plattformen, einschließlich Freunde, Ihre früheren Beiträge und andere Daten, die jederzeit auf der neuen Plattform verwendet werden können, säen.
Wenn Sie an technischen Details interessiert sind: Data DAO verfügt über zwei Hauptkomponenten: 1) Governance für die Kette, die Token durch Datenbeiträge erhalten; .Um einen Beitrag zu leisten, müssen Sie zunächst die Daten überprüfen, um das Eigentum nachzuweisen und ihren Wert zu schätzen.Verwenden Sie dann den öffentlichen Schlüssel des Servers, um die Daten im Browser zu verschlüsseln und die verschlüsselten Daten in der Cloud zu speichern.Die Daten werden nur entschlüsselt, wenn der DAO den Vorschlag zur Gewährung von Zugriffs zu genehmigt.Zum Beispiel könnte es KI -Unternehmen ermöglichen, Daten zu mieten, um Modelle zu schulen.Hier finden Sie mehr über die Vana -Netzwerkarchitektur, die darauf abzielt, das kollektive Eigentum an Datensätzen und Modellen zu implementieren.
Data DAO kommt nicht nur den Benutzern zugute, sondern steuert auch die Entwicklung von KI, wodurch es möglich ist, KI wie Open -Source -Software aufzubauen, was allen zugute kommt, die dazu beitragen.Open Source AI kämpft darum, tragfähige Geschäftsmodelle zu finden: Es ist sehr teuer, GPUs, Daten und Forscher zu bezahlen.Und sobald das Modell trainiert ist, können diese Kosten, wenn es Open Source ist, nicht wiederhergestellt werden.Die technische Architektur von Daten DAO kann auf das Modell DAO angewendet werden, bei dem Benutzer und Entwickler Daten, Berechnungen und Forschungsarbeiten im Austausch für das Eigentum des Modells leisten können.
Die Standardoption in der heutigen Gesellschaft besteht darin, großen Technologieunternehmen zu ermöglichen, unsere Daten zu erhalten und sie mithilfe der für uns funktionierenden KI -Modelle auszubilden.Sie profitieren von diesen KI -Modellen, weil wir durch Modelle ersetzt werden, die mit unseren Daten geschult sind.Dies ist ein sehr schlechtes Geschäft für die Gesellschaft, aber eine gute Sache für große Technologieunternehmen.Der einzige Weg, dies zu verhindern, besteht darin, kollektive Maßnahmen zu ergreifen.Daten sind Währung und kollektive Daten sind Leistung.Ich ermutige Sie zur Teilnahme: Die weltweit ersten Daten, die sich auf Reddit Data DAO konzentrieren, ist heute im Vana -Netzwerk online.Durch das Brechen des von der privilegierten Minderheit kontrollierten Datengrabens hat Daten Dao einen Weg zum Internet eröffnet, das echten Benutzern gehört.