Autor: Zeke, YBB Capital;
Vorwort
Am 16. Februar kündigte OpenAI den Start des neuesten WENSheng -Video -generierenden Diffusionsmodells mit dem Namen „Sora“ an.Im Gegensatz zu Pika und anderen KI -Videogenerier -Tools, die mehrere Sekunden von Videos aus mehreren Bildern generieren, trainiert Sora im komprimierten potenziellen Bereich von Video und Bildern, um sie in den Space -Time -Patch zu zerlegen, um skalierbare Videos zu generieren.Darüber hinaus zeigt das Modell die Fähigkeit simulierter physischer und digitaler Welten, und seine 60 -zweite Demonstration wird als „allgemeiner Simulator der physischen Welt“ beschrieben.
Sora setzt den technischen Pfad des vorherigen GPT-Modells „Quelldaten-Transformator-Diffusion-Anstrengung“ fort, was darauf hinweist, dass seine Entwicklungsreife auch von der Rechenleistung abhängt.Angesichts der Tatsache, dass die für das Video -Training erforderliche Datenmenge größer als Text ist, wird die Nachfrage nach Rechenleistung voraussichtlich weiter zunehmen.Wie wir jedoch in unserem vorherigen Artikel „Popularisierung der potenziellen Branche: Dezentralisierung des Marktes“ erörtert haben, wurde die Bedeutung der Rechenleistung in der KI -Ära mit zunehmender Popularität der KI erörtert, aber viele Rechenleistungsprojekte sollten in der Rechenleistung erfolgen. Zeit des Versuchs, zum Zeitpunkt der Versuche zu sein.Zusätzlich zu Depin zielt dieser Artikel darauf ab, frühere Diskussionen zu aktualisieren und zu verbessern und über die Funken nachzudenken, die von Web3 und AI produziert werden können, sowie über die Möglichkeiten in der Strecke in der KI -Ära.
Die drei Richtungen der KI -Entwicklung
AI ist eine aufstrebende Wissenschaft und Technologie, die darauf abzielt, die menschliche Intelligenz zu simulieren, zu erweitern und zu verbessern.Seit der Geburt der 1950er und 1960er Jahre entwickelt sich AI seit mehr als einem halben Jahrhundert und ist nun zu einer Schlüsseltechnologie, um das soziale Leben und verschiedene Branchen zu fördern.Dabei hat die miteinander verflochtene Entwicklung der drei wichtigsten Forschungsrichtungen von Symbolik, Connectionism und Verhaltensumalismus die Grundlage für die rasche Entwicklung künstlicher Intelligenz heute gelegt.
Symbolismus
Die Symbolik ist auch als logisch oder regeln bekannt.Diese Methode verwendet Symbole, um die Objekte, Konzepte und Beziehungen in der Problemdomäne darzustellen, und verwendet logisches Denken, um das Problem zu lösen.Die Symbolik hat großen Erfolg erzielt, insbesondere in Bezug auf Expertensysteme und Kenntnisse.Die Kernidee der Symbolik ist, dass intelligentes Verhalten durch symbolische Manipulation und logisches Denken erreicht werden kann.
Assoziiertes
Oder es wird als neuronale Netzwerkmethode bezeichnet, um Intelligenz durch Nachahmung der Struktur und Funktionen des menschlichen Gehirns zu realisieren.Diese Methode erstellt ein Netzwerk, das aus vielen einfachen Verarbeitungseinheiten (ähnlich wie Neuronen) besteht, und passt die Verbindungsintensität zwischen diesen Einheiten (ähnlich wie die Synapsen) an, um das Lernen zu fördern.Connectism betont die Fähigkeit, Daten zu lernen und zu verallgemeinern, so dass er besonders für die Moduserkennung, Klassifizierung und kontinuierliche Eingabe- und Ausgangszuordnungsprobleme geeignet ist.Als Evolution des Connectionism hat Deep Learning durch Durchbrüche in den Bereichen Bilderkennung, Spracherkennung und Verarbeitung natürlicher Sprache erzielt.
Verhalten
Behaviorismus ist eng mit der Forschung von bionischen Robotern und autonomen intelligenten Systemen verbunden und betont, dass Intelligenz durch Interaktion mit der Umwelt lernen kann.Im Gegensatz zu den beiden vorherigen Konzentrationen konzentriert sich der Verhalten nicht auf die Simulation interner Merkmale oder Denkprozesse, sondern um ein adaptives Verhalten durch den Zyklus von Wahrnehmung und Handlung zu erreichen.Behaviorismus ist der Ansicht, dass Intelligenz durch dynamische Interaktion und Lernen mit der Umgebung widerspiegelt wird, was es für mobile Roboter und adaptive Steuerungssysteme, die in einer komplexen und unvorhersehbaren Umgebung laufen, besonders effektiv sind.
Obwohl es in diesen drei Forschungsrichtungen grundlegende Unterschiede gibt, können sie in der tatsächlichen Forschung und Anwendung von KI interagieren und ineinander integrieren, um die Entwicklung künstlicher Intelligenz gemeinsam zu fördern.
AIGC -Prinzip
Das explosive Entwicklungsfeld von AIGC repräsentiert die Entwicklung und Anwendung des Connectionism und kann durch Nachahmung der menschlichen Kreativität neuartige Inhalte erzeugen.Diese Modelle verwenden große Datensätze und Deep -Lern -Algorithmen für das Training sowie die zugrunde liegenden Struktur, Beziehungen und Muster in Lerndaten.Gemäß den Eingabeaufforderungen des Benutzers generieren sie eindeutige Ausgänge, einschließlich Bilder, Videos, Code, Musik, Design, Übersetzung, Frage -Antworten und Texte.Derzeit besteht AIGC im Grunde genommen aus drei Elementen: Deep Learning, Big Data und massive Computerfunktionen.
Tiefes Lernen
Deep Learning ist ein Unterfeld des maschinellen Lernens, das Algorithmen verwendet, die menschliche neuronale Netzwerke imitieren.Zum Beispiel besteht das menschliche Gehirn aus Millionen von miteinander verbundenen Neuronen und arbeiten zusammen, um Informationen zu lernen und zu verarbeiten.In ähnlicher Weise bestehen Deep Learning Neural Networks (oder künstliche neuronale Netzwerke) aus multi -layer -künstlichen Neuronen, die in Computern zusammenarbeiten.Diese künstlichen Neuronen (als Knoten bezeichnet) verwenden mathematische Berechnungen, um Daten zu verarbeiten.Künstliche neuronale Netze verwenden diese Knoten, um komplexe Probleme durch Deep -Lern -Algorithmen zu lösen.
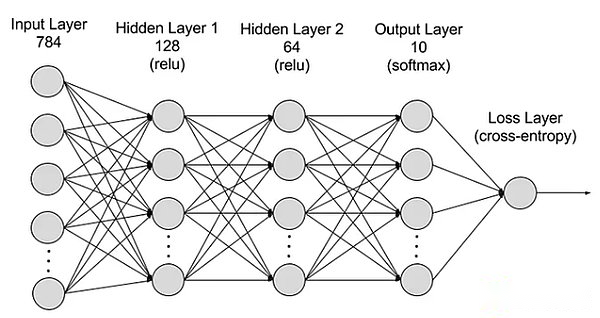 Das neuronale Netzwerk ist in Schichten unterteilt: Eingabeben, versteckte Schichten und Ausgabeschichten, und Parameter werden mit verschiedenen Schichten verbunden.
Das neuronale Netzwerk ist in Schichten unterteilt: Eingabeben, versteckte Schichten und Ausgabeschichten, und Parameter werden mit verschiedenen Schichten verbunden.
Schicht eingeben:Die erste Ebene des neuronalen Netzwerks ist für den Empfang externer Eingabedaten verantwortlich.Jedes Neuron in der Eingangsschicht entspricht einer Funktion der Eingabedaten.Bei der Verarbeitung von Bilddaten kann jedes Neuron einem Pixelwert des Bildes entsprechen.
Versteckte Schicht:Die Eingabeschicht verarbeitet die Daten und wird weiter an das Netzwerk übergeben.Diese versteckten Ebenen verarbeiten Informationen auf unterschiedlichen Ebenen und passen ihr Verhalten an, wenn sie neue Informationen erhalten.Es gibt Hunderte von versteckten Schichten in tiefen Lernnetzwerken, die Probleme aus mehreren Blickwinkeln analysieren können.Wenn Sie beispielsweise ein Bild eines unbekannten Tieres, das klassifiziert werden muss, mit den Tieren, die Sie bereits kennen, durch Überprüfen der Ohrenform, der Anzahl der Beine und der Größe des Schülers vergleichen können.Die versteckte Schicht im tiefen neuronalen Netzwerk funktioniert auf ähnliche Weise.Wenn Deep -Learning -Algorithmen versuchen, Tierbilder zu klassifizieren, behandelt jede versteckte Schicht unterschiedliche Merkmale von Tieren und versuchen, sie genau zu klassifizieren.
Ausgangsschicht:Die letzte Ebene des neuronalen Netzwerks ist für die Generierung der Ausgabe des Netzwerks verantwortlich.Jedes Neuron in der Ausgangsschicht repräsentiert eine mögliche Ausgangskategorie oder einen möglichen Wert.Beispielsweise kann im Klassifizierungsproblem jeder Ausgangsschicht -Neuron einer Kategorie entsprechen, und im Regressionsproblem kann die Ausgangsschicht nur ein Neuron haben und ihr Wert das Vorhersageergebnis darstellt.
Parameter:In neuronalen Netzwerken werden die Verbindungen zwischen verschiedenen Schichten durch Gewichte und Abweichungen dargestellt, die sie während des Schulungsprozesses so optimiert werden, dass das Netzwerk die Muster in den Daten genau identifizieren und Vorhersagen treffen kann.Erhöhte Parameter können die Fähigkeit des neuronalen Netzwerks verbessern, dh die Fähigkeit, den komplexen Modus in den Daten zu lernen und darzustellen.Dies erhöht jedoch auch die Nachfrage nach Rechenleistung.
Big Data
Um eine wirksame Schulung durchzuführen, benötigen neuronale Netze in der Regel eine große, vielfältige, hochwertige und multi -saure Daten.Es bildet die Grundlage für Schulungs- und Überprüfungsmodelle für maschinelles Lernen.Durch die Analyse von Big Data können maschinelle Lernmodelle die Muster und Beziehungen in den Daten lernen, um Vorhersage oder Klassifizierung zu erreichen.
Massive Rechenleistung
Die mehrstufige Struktur neuronaler Netze ist kompliziert, es gibt viele Parameter, Big -Data -Verarbeitungsanforderungen und iterative Trainingsmethoden (das Modell muss während des Trainings wiederholt iteriert werden, die die Vorwärts- und Rückwärtsübertragungsberechnungen jeder Schicht einschließlich der Berechnung der Aktivierungsfunktion umfassen , Berechnung der Verlustfunktion, Berechnung des Gradientenebene und Gewichtsverlängerung), Anforderungen an die Berechnung des Hochverhältnisses, Berechnung des Hochverhältnisses, parallele Computerfunktionen, Optimierungstechnologien und Regularisierungstechnologien sowie Modellbewertungs- und Überprüfungsprozesse führen zusammen zu hohen Anforderungen an die Rechenleistung.

Sora
Als neueste Video -Generierung von KI -Modell von OpenAI stellt Sora einen großen Fortschritt der Verarbeitung künstlicher Intelligenz und des Verständnisses diversifizierter visueller Daten dar.Durch die Verwendung von Videokomprimierungsnetzwerk und Space -Time Patch -Technologie kann Sora massive visuelle Daten umwandeln, die von verschiedenen Geräten weltweit erfasst werden, in ein einheitliches Repräsentationsformular, wodurch eine effiziente Verarbeitung und das Verständnis komplexer visueller Inhalte erreicht wird.Mithilfe von Textbedingungen für diffuse Modelle kann Sora Videos oder Bilder generieren, die stark mit Texteingabeaufforderungen übereinstimmen und hohe Kreativität und Anpassungsfähigkeit zeigen.
Obwohl Sora Durchbrüche in der Interaktion der Videogenerierung und -Simulation in der realen Welt erzielt hat, steht es immer noch mit einigen Einschränkungen, einschließlich der Genauigkeit der physischen Weltsimulation, der Konsistenz des Wachstumsvideos, der komplexen Textanweisungen sowie der Ausbildung und der Ausbildung und Erzeugung der Erzeugungseffizienz.Im Wesentlichen setzt Sora den alten technischen Weg des „Big Data-Transformler-Diffusion-Emergece“ durch OpenAs Monopoly Computing Power und First-Mover-Vorteile fort und erkennt eine brutale Ästhetik.Andere Unternehmen für künstliche Intelligenz haben nach wie vor das Potenzial, durch technologische Innovationen zu übertreffen.
Obwohl die Beziehung zwischen Sora und der Blockchain nicht großartig ist, glaube ich, dass in den nächsten ein oder zwei Jahren aufgrund des Einflusses von Sora andere Tools für hochwertige KI -Erzeugung erscheinen und sich schnell entwickeln werden, Impact, Depin usw.Daher ist es notwendig, ein allgemeines Verständnis von Sora zu haben.
Vier Möglichkeiten von AI X Web3 Fusion
Wie bereits erwähnt, können wir verstehen, dass die grundlegenden Elemente, die von der Generation AI erforderlich sind, im Wesentlichen drei betragen: Algorithmen, Daten und Rechenleistung.Andererseits ist AI unter Berücksichtigung ihrer Universalitäts- und Ausgangseffekt ein Werkzeug, das die Produktionsmethode vollständig verändert.Gleichzeitig ist der größte Einfluss der Blockchain zwei: Reorganisation von Produktionsbeziehungen und Dezentralisierung.
Daher denke ich, dass die Kollision dieser beiden Technologien die folgenden vier Pfade erzeugen kann:
Dezentralisierung
Wie bereits erwähnt, soll dieser Abschnitt den Status der Computerfunktionen aktualisieren.Wenn es um KI geht, ist die Rechenleistung ein unverzichtbarer Aspekt.Die Entstehung von Sora machte die unvorstellbare KI -Nachfrage nach Rechenleistung.In jüngster Zeit erklärte der CEO von OpenAI, CEO von OpenAI, Sam Altman, während des Davos World Economic Forum in der Schweiz im Jahr 2024 öffentlich, dass Rechenleistung und Energie die größten Einschränkungen sind, was bedeutet, dass ihre zukünftige Bedeutung möglicherweise sogar der Währung entspricht.Anschließend kündigte Sam Altman am 10. Februar einen schockierenden Plan auf Twitter an, der 7 Billionen US -Dollar (entspricht 40%des chinesischen BIP im Jahr 2023) aufbringen wird, um die derzeitige globale Halbleiterindustrie vollständig zu reformieren.Mein früheres Denken über die Computermacht beschränkt sich auf nationale Blockade und Unternehmensmonopol.
Daher ist die Bedeutung der dezentralen Rechenleistung selbstverständlich.Die Eigenschaften der Blockchain können tatsächlich das Problem des extremen Monopols bei der aktuellen Rechenleistung sowie die teuren Kosten im Zusammenhang mit der Erlangung einer dedizierten GPU lösen.Aus Sicht der KI -Anforderungen kann die Verwendung von Rechenleistung in zwei Richtungen unterteilt werden: Argumentation und Schulung.Es gibt nur sehr wenige Projekte, die sich auf Schulungen konzentrieren, da dezentrale Netzwerke das Design des neuronalen Netzwerks integrieren müssen und die Hardwareanforderungen extrem hoch sind.Im Gegensatz dazu ist die Argumentation relativ einfach, da das dezentrale Netzwerkdesign nicht so kompliziert ist und die Anforderungen an Hardware und Bandbreite ebenfalls niedrig sind, was eine wichtigere Richtung ist.
Der zentralisierte Rechenleistungmarkt hat eine breite Palette an Vorstellungskraft, die häufig mit den Schlüsselwörtern der „Billionen Ebene“ verbunden ist, was auch das einfachste Thema der KI -Ära ist.Wenn man sich jedoch die vielen Projekte ansieht, die in letzter Zeit erschienen sind, scheinen die meisten von ihnen Trend zu verwenden, um unerwartete Versuche zu berücksichtigen.Sie erhöhen häufig die Flagge der Dezentralisierung, vermeiden es jedoch, die Ineffizienz dezentraler Netzwerke zu diskutieren.Darüber hinaus ist der Grad der Homogenität des Designs sehr hoch.
Algorithmus und Modellkooperationssystem
Algorithmen für maschinelles Lernen sind Algorithmen, mit denen Modi und Regeln aus den Daten gelernt und auf der Grundlage von ihnen Vorhersagen oder Entscheidungen treffen können.Der Algorithmus ist technologisch dicht, da sein Design und seine Optimierung tiefgreifende berufliche Kenntnisse und technologische Innovationen erfordert.Algorithmen sind der Kern der Schulung künstlicher Intelligenzmodelle und definieren, wie Daten in nützliche Erkenntnisse oder Entscheidungen umwandelt werden.Die gemeinsame Generation von AI -Algorithmen umfasst die Generierung von Konfrontationsnetzwerken (GaN) (GaN), Transformator Self -Coder (VAE) und Transformers. dann verwendet, um spezialisierte KI -Modelle zu trainieren.
Es gibt also so viele Algorithmen und Modelle, von denen jede möglich ist, um sie in ein gemeinsames Modell zu integrieren?Bittersor ist ein aktuelles Projekt, das viel Aufmerksamkeit erregt hat.Andere Projekte, die sich auf diese Richtung konzentrieren, sind Commune KI (Code Collaboration), Algorithmen und Modelle sind jedoch für KI -Unternehmen ausschließlich vertraulich und sind nicht einfach zu teilen.
Daher ist die Erzählung des KI -kollaborativen Ökosystems neu und interessant.Das kollaborative Ökosystem nutzt die Vorteile der Blockchain, um den Nachteil des isolierten AI -Algorithmus zu integrieren. Es bleibt jedoch zu beobachten, ob es einen entsprechenden Wert schaffen kann.Das führende KI -Unternehmen mit unabhängigen Algorithmen und Modellen hat schließlich starke Aktualisierungen, Iterationen und Integrationsfunktionen.Zum Beispiel hat sich OpenAI in weniger als zwei Jahren von frühen Modellen für die Erzeugung von Texten zu Multi -Feld -Generierungsmodellen entwickelt.Projekte wie Bittersor müssen möglicherweise neue Wege in ihren Modellen und Algorithmus -Zielfeldern untersuchen.
Dezentralisierung Big Data
Aus einfacher Sicht stimmt die Verwendung von Datenschutzdaten zur Fütterung von KI- und Annotationsdaten mit der Blockchain -Technologie sehr überein.Darüber hinaus kann die Datenspeicherung den Depinprojekten wie Fil und AR zugute kommen.Aus komplizierterer Perspektive ist die Verwendung von Blockchain -Daten für maschinelles Lernen zur Lösung der Zugriffbarkeit von Blockchain -Daten eine weitere interessante Richtung (eine der Giza -Erkundungen).
Theoretisch können jederzeit auf Blockchain -Daten zugegriffen werden, was den Zustand der gesamten Blockchain widerspiegelt.Für Personen außerhalb des Blockchain -Ökosystems ist es jedoch nicht einfach, auf diese großen Datenmengen zuzugreifen.Das Speichern der gesamten Blockchain erfordert ein reichhaltiges professionelles Wissen und eine große Anzahl professioneller Hardware -Ressourcen.Um die Herausforderungen des Zugriffs auf die Blockchain -Daten zu bewältigen, sind in der Branche verschiedene Lösungen aufgetreten.Beispielsweise bieten RPC -Anbieter einen Knotenzugriff über die API, und Indexdienste ermöglichen das Abrufen von Daten über SQL und GraphQL, was eine wichtige Rolle bei der Lösung dieses Problems spielt.Diese Methoden haben jedoch ihre Grenzen.RPC -Dienste eignen sich nicht für Fälle mit hoher Dichte, die eine große Menge an Datenabfragen benötigen, und können die Bedürfnisse häufig nicht erfüllen.Obwohl der Indexdienst eine strukturellere Methode zum Abrufen von Daten zur Verfügung stellt, macht es die Komplexität des Web3 -Protokolls für strukturelle effiziente Abfragen äußerst schwierig, und manchmal sind Hunderte oder sogar Tausende komplexer Code erforderlich.Diese Komplexität ist ein wesentliches Hindernis für allgemeine Datenpraktiker und diejenigen, die ein begrenztes Verständnis der Web3 -Details haben.Diese eingeschränkten kumulativen Effekte unterstreichen die Notwendigkeit, auf Blockchain -Daten zuzugreifen und zu verwenden, die mehr Zugriff und Verwendung erfordern, was eine breitere Anwendung und Innovation vor Ort fördern kann.
Daher können die Kombination von ZKML (Null -Wissen -Beweis für maschinelles Lernen, Reduzieren der Belastung des maschinellen Lernens in der Kette) und Blockchain -Daten von hohen Qualität möglicherweise Datensätze erstellen, die die Zugriffbarkeit von Blockchain -Daten lösen.KI kann die Zugangsbarriere von Blockchain -Daten erheblich reduzieren.Im Laufe der Zeit können Entwickler, Forscher und Enthusiasten für maschinelles Lernen auf mehr hochwertige und verwandte Datensätze zugreifen, um effektive und innovative Lösungen aufzubauen.
KI Empowerment Dapp
Seit dem Ausbruch von Chatgpt3 im Jahr 2023 ist die Ermächtigung von AI von DAPP zu einer sehr häufigen Richtung geworden.Eine umfangreiche künstliche Intelligenz auf Anwendungsbasis kann durch API integriert werden, wodurch und intelligente Datenplattformen, Handelsroboter, Blockchain -Enzyklopädie und andere Anwendungen vereinfacht werden.Andererseits kann es auch als Chat -Roboter (wie MyShell) oder KI -Partner (Sleepless AI) fungieren und sogar eine großzügige KI verwenden, um NPCs im Blockchain -Spiel zu erstellen.Da jedoch die technische Schwelle niedrig ist, sind die meisten von ihnen nur Anpassungen nach integrierter API, und die Integration des Projekts selbst ist nicht perfekt, so dass sie selten erwähnt wird.
Aber mit der Ankunft von Sora denke ich persönlich, dass die Stärkung von GameFi (einschließlich Yuan -Universum) und kreative Plattformen von AI im Mittelpunkt der Zukunft stehen wird.Angesichts der unteren Art des Web3 -Bereichs ist es unwahrscheinlich, dass Produkte produziert werden, die mit traditionellen Spielen oder kreativen Unternehmen konkurrieren können.Die Entstehung von Sora kann jedoch diesen Deadlock brechen (vielleicht nur zwei bis drei Jahre).Nach Soras Demonstration zu urteilen, hat es das Potenzial, mit kurzen Dramaunternehmen zu konkurrieren.Die aktive Gemeinschaftskultur des Web3 kann auch viele interessante Ideen hervorbringen.
abschließend
Mit der kontinuierlichen Entwicklung der Erzeugung von Tools für künstliche Intelligenz werden wir in Zukunft mehr durchbrachliche „iPhone -Momente“ erleben.Obwohl Menschen der Integration von KI und Web3 skeptisch gegenüberstehen, glaube ich, dass die aktuelle Richtung im Grunde korrekt ist und nur drei Hauptschmerzpunkte erforderlich sind: Notwendigkeit, Effizienz und Passform.Obwohl sich die Integration der beiden noch in der Erkundungsstufe befindet, verhindert es nicht, dass dieser Weg zum Mainstream des nächsten Bullenmarktes wird.
Die Aufrechterhaltung von genügend Neugier und Offenheit neuer Dinge ist unsere grundlegende Mentalität.Historisch gesehen wurde die Transformation von einem Wagen zu einem Auto sofort gelöst, da die Inschriften und die vergangene NFT gezeigt wurden.Zu viel Vorurteil zu halten, wird nur verpasste Möglichkeiten verursachen.