Auteur: Zeke, YBB Capital;
Avant-propos
Le 16 février, Openai a annoncé le lancement du dernier modèle de diffusion générant de la vidéo Wensheng appelée « Sora ».Contrairement à PIKA et à d’autres outils de génération de vidéos AI qui génèrent plusieurs secondes de vidéo à partir de plusieurs images, Sora s’entraîne dans l’espace potentiel compressé de vidéo et d’images pour les décomposer en patch à temps d’espace pour générer des vidéos évolutives.De plus, le modèle montre la capacité des mondes physiques et numériques simulés, et sa démonstration de 60 secondes est décrite comme « simulateur général du monde physique ».
SORA poursuit le chemin technique du modèle GPT précédent « Source Data-Transformateur-Diffusion-Emergence », indiquant que sa maturité de développement dépend également de la puissance de calcul.Étant donné que la quantité de données requises pour la formation vidéo est plus grande que le texte, sa demande de puissance de calcul devrait augmenter davantage.Cependant, comme nous l’avons discuté dans notre article précédent « Pulpulsion of Potential Industry: Decentralization Bectic Market », l’importance de la puissance de calcul dans l’ère de l’IA a été discutée. Le temps de tentative d’être au moment des tentatives.En plus de DePin, cet article vise à mettre à jour et à améliorer les discussions passées et à réfléchir aux étincelles qui peuvent être produites par Web3 et AI et les opportunités dans la piste de l’ère IA.
Les trois directions du développement de l’IA
L’IA est une science et une technologie émergentes qui visent à simuler, étendre et améliorer l’intelligence humaine.Depuis la naissance des années 1950 et des années 1960, l’IA s’est développée depuis plus d’un demi-siècle et est maintenant devenue une technologie clé pour promouvoir la vie sociale et diverses industries.Dans le processus, le développement entrelacé des trois principales orientations de recherche du symbolisme, du connexion et du comportementalisme a jeté les bases du développement rapide de l’intelligence artificielle aujourd’hui.
Symbolisme
Le symbolisme est également connu sous le nom de logicalisme ou de raisonnement basé sur les règles.Cette méthode utilise des symboles pour représenter les objets, les concepts et les relations dans le domaine du problème, et utiliser le raisonnement logique pour résoudre le problème.Le symbolisme a connu un grand succès, en particulier en termes de systèmes et de connaissances experts.L’idée principale du symbolisme est que le comportement intelligent peut être réalisé grâce à une manipulation symbolique et à un raisonnement logique.
Association
Ou il est appelé méthode du réseau neuronal, pour réaliser l’intelligence en imitant la structure et les fonctions du cerveau humain.Cette méthode construit un réseau composé de nombreuses unités de traitement simples (similaires aux neurones) et ajuste l’intensité de connexion entre ces unités (similaires aux synapses) pour promouvoir l’apprentissage.Le Connetisme met l’accent sur la capacité d’apprendre et de généraliser à partir des données, de sorte qu’elle convient particulièrement à la reconnaissance de mode, à la classification et aux problèmes de cartographie des entrées et de la sortie continues.En tant qu’évolution du connexionnisme, l’apprentissage en profondeur a fait des percées dans les domaines de la reconnaissance d’image, de la reconnaissance vocale et du traitement du langage naturel.
Comportementalisme
Le comportementalisme est étroitement lié à la recherche de robots bioniques et de systèmes intelligents autonomes, soulignant que l’intelligence peut apprendre par l’interaction avec l’environnement.Contrairement aux deux précédents, le comportementalisme ne se concentre pas sur la simulation des caractéristiques internes ou des processus de réflexion, mais pour atteindre un comportement adaptatif à travers le cycle de perception et d’action.Le comportementalisme estime que l’intelligence se reflète par l’interaction dynamique et l’apprentissage avec l’environnement, ce qui le rend particulièrement efficace pour les robots mobiles et les systèmes de contrôle adaptatif fonctionnant dans un environnement complexe et imprévisible.
Bien qu’il existe des différences fondamentales dans ces trois directions de recherche, elles peuvent interagir et s’intégrer entre elles dans la recherche réelle et l’application de l’IA pour promouvoir conjointement le développement de l’intelligence artificielle.
Principe AIGC
Le champ de développement explosif d’AIGC représente l’évolution et l’application du connexionnisme, et peut générer un nouveau contenu en imitant la créativité humaine.Ces modèles utilisent de grands ensembles de données et des algorithmes d’apprentissage en profondeur pour la formation, ainsi que la structure sous-jacente, les relations et les modèles dans les données d’apprentissage.Selon les invites de l’utilisateur, ils génèrent des sorties uniques, y compris des images, des vidéos, du code, de la musique, du design, de la traduction, des réponses de questions et des textes.À l’heure actuelle, l’AIGC est essentiellement composé de trois éléments: apprentissage en profondeur, big data et capacités informatiques massives.
Apprentissage en profondeur
Deep Learning est un sous-champ de l’apprentissage automatique, qui utilise des algorithmes qui imitent les réseaux de neurones humains.Par exemple, le cerveau humain se compose de millions de neurones interdépendants, et ils travaillent ensemble pour apprendre et traiter les informations.De même, les réseaux de neurones en profondeur (ou les réseaux de neurones artificiels) sont constitués de neurones artificiels multi-couches qui travaillent ensemble dans des ordinateurs.Ces neurones artificiels (appelés nœuds) utilisent des calculs mathématiques pour traiter les données.Les réseaux de neurones artificiels utilisent ces nœuds pour résoudre des problèmes complexes à travers des algorithmes d’apprentissage en profondeur.
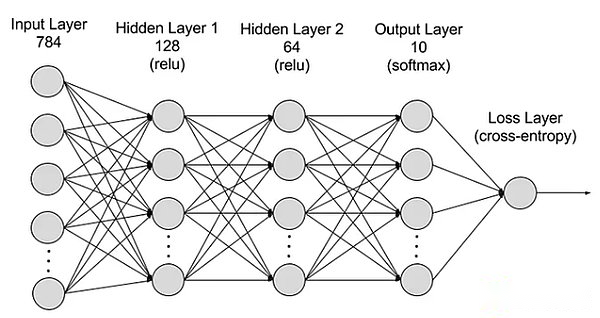 Le réseau neuronal est divisé en couches: couches d’entrée, couches cachées et couches de sortie, et les paramètres sont connectés à différentes couches.
Le réseau neuronal est divisé en couches: couches d’entrée, couches cachées et couches de sortie, et les paramètres sont connectés à différentes couches.
Entrez la couche:La première couche de réseau neuronal est responsable de la réception des données d’entrée externes.Chaque neurone de la couche d’entrée correspond à une caractéristique des données d’entrée.Par exemple, lors du traitement des données d’image, chaque neurone peut correspondre à une valeur de pixel de l’image.
Couche cachée:La couche d’entrée traite les données et est en outre transmise au réseau.Ces couches cachées traitent les informations à différents niveaux et ajustent leur comportement lors de la réception de nouvelles informations.Il existe des centaines de couches cachées dans les réseaux d’apprentissage en profondeur, qui peuvent analyser les problèmes sous plusieurs angles.Par exemple, lorsqu’une image d’un animal inconnu qui doit être classé, vous pouvez le comparer avec les animaux que vous connaissez déjà en vérifiant la forme des oreilles, le nombre de jambes et la taille de l’élève.La couche cachée du réseau neuronal profond fonctionne de manière similaire.Si les algorithmes d’apprentissage en profondeur essaient de classer les images animales, chaque couche cachée gérera différentes caractéristiques des animaux et essaiera de la classer avec précision.
Couche de sortie:La dernière couche du réseau neuronal est responsable de la génération de la sortie du réseau.Chaque neurone de la couche de sortie représente une catégorie ou une valeur de sortie possible.Par exemple, dans le problème de classification, chaque neurone de la couche de sortie peut correspondre à une catégorie, et dans le problème de régression, la couche de sortie peut n’avoir qu’un seul neurone, et sa valeur représente le résultat prédictif.
paramètre:Dans les réseaux de neurones, les connexions entre différentes couches sont représentées par des poids et des écarts qu’ils sont optimisés pendant le processus de formation afin que le réseau puisse identifier avec précision les modèles des données et faire des prédictions.L’augmentation des paramètres peut améliorer la capacité du réseau neuronal, c’est-à-dire la capacité d’apprendre et de représenter le mode complexe dans les données.Cependant, cela augmente également la demande de puissance de calcul.
Big data
Afin de mener une formation efficace, les réseaux de neurones ont généralement besoin de données importantes, diverses, de haute qualité et multi-sources.Il constitue la base de la formation et de la vérification des modèles d’apprentissage automatique.En analysant les mégadonnées, les modèles d’apprentissage automatique peuvent apprendre les modèles et les relations dans les données, afin d’atteindre la prédiction ou la classification.
Puissance de calcul massive
La structure multi-réparties des réseaux de neurones est compliquée, il existe de nombreux paramètres, les exigences de traitement des mégadonnées, les méthodes de formation itératives (le modèle doit être itéré à plusieurs reprises pendant la formation, impliquant les calculs de transmission avant et arrière de chaque couche, y compris le calcul de la fonction d’activation , calcul de la fonction de perte, calcul du niveau de gradient et renouvellement du poids), exigences de calcul à forte provision, capacités de calcul parallèle, technologies d’optimisation et de régularisation, ainsi que des processus d’évaluation et de vérification des modèles conduisent ensemble à des besoins élevés de puissance de calcul.

Sora
En tant que dernier modèle d’IA générant une vidéo d’OpenAI, Sora représente un progrès majeur du traitement de l’intelligence artificielle et de la compréhension des données visuelles diversifiées.En utilisant un réseau de compression vidéo et une technologie de correctifs à temps spatial, Sora peut convertir des données visuelles massives capturées par différents appareils dans le monde en une forme de représentation unifiée, réalisant ainsi un traitement et une compréhension efficaces du contenu visuel complexe.En utilisant des conditions de texte pour diffuser les modèles, Sora peut générer des vidéos ou des images fortement appariées avec des invites de texte, montrant une créativité et une adaptabilité élevées.
Cependant, bien que Sora ait fait des percées dans l’interaction de la génération de vidéos et de la simulation dans le monde réel, il fait toujours face à certaines limites, y compris la précision de la simulation du monde physique, la cohérence de la vidéo de croissance, des instructions de texte complexes et de la formation et Génération de l’efficacité de la génération.Essentiellement, Sora poursuit l’ancien chemin technique du « Big Data-Transformateur-Diffusion-Emergeance » par le biais de la puissance de calcul de monopole d’Openai et des avantages de premier mobilisation, et réalise une esthétique brute.D’autres sociétés d’intelligence artificielle ont encore le potentiel de dépasser l’innovation technologique.
Bien que la relation entre Sora et la blockchain ne soit pas grande, je crois que dans la prochaine année ou deux, en raison de l’influence de Sora, d’autres outils de génération d’IA de haute qualité apparaîtront et se développent rapidement, l’impact, le depin, etc.Par conséquent, il est nécessaire d’avoir une compréhension générale de Sora.
Quatre façons de fusion AI x web3
Comme discuté précédemment, nous pouvons comprendre que les éléments de base requis par l’IA de génération sont essentiellement trois: algorithmes, données et alimentation informatique.D’un autre côté, compte tenu de son effet d’universalité et de sortie, l’IA est un outil qui modifie complètement la méthode de production.Dans le même temps, le plus grand impact de la blockchain est double: réorganisation des relations de production et décentralisation.
Par conséquent, je pense que la collision de ces deux technologies peut produire les quatre voies suivantes:
Décentralisation
Comme mentionné précédemment, cette section vise à mettre à jour l’état des capacités informatiques.En ce qui concerne l’IA, la puissance de calcul est un aspect indispensable.L’émergence de Sora a rendu la demande inimaginable de l’IA de pouvoir de calcul.Récemment, lors du Davos World Economic Forum en Suisse en 2024, le PDG d’OpenAI, Sam Altman, a déclaré publiquement que le pouvoir informatique et l’énergie sont les plus grandes contraintes à l’heure actuelle, ce qui implique que leur importance future pourrait même être équivalente à la monnaie.Par la suite, le 10 février, Sam Altman a annoncé un plan choquant sur Twitter qui collectera 7 billions de dollars américains (équivalent à 40% du PIB de la Chine en 2023) pour réformer complètement l’industrie mondiale actuelle des semi-conducteurs.Ma réflexion précédente sur le pouvoir de calcul est limitée au blocage national et au monopole des entreprises;
Par conséquent, l’importance de la puissance informatique décentralisée est auto-évidente.Les caractéristiques de la blockchain peuvent en effet résoudre le problème du monopole extrême à la puissance de calcul actuelle, ainsi que le coût coûteux lié à l’obtention d’un GPU dédié.Du point de vue des exigences de l’IA, l’utilisation de la puissance de calcul peut être divisée en deux directions: le raisonnement et la formation.Il y a très peu de projets axés sur la formation, car les réseaux décentralisés doivent intégrer la conception du réseau neuronal, et les exigences matérielles sont extrêmement élevées.En revanche, le raisonnement est relativement simple, car la conception du réseau décentralisé n’est pas si compliquée, et les exigences en matière de matériel et de bande passante sont également faibles, ce qui est une direction plus courante.
Le marché de la puissance de calcul centralisée a un large éventail d’imagination, souvent lié aux mots clés des « milliards de niveaux », qui est également le sujet le plus simple de l’ère de l’IA.Cependant, en examinant les nombreux projets qui sont apparus récemment, la plupart d’entre eux semblent utiliser la tendance pour envisager des tentatives inattendues.Ils soulèvent souvent le drapeau de la décentralisation, mais évitent de discuter de l’inefficacité des réseaux décentralisés.De plus, le degré d’homogénéité de la conception est très élevé.
Algorithme et système de collaboration modèle
Les algorithmes d’apprentissage automatique sont des algorithmes qui peuvent apprendre les modes et les règles des données et prendre des prédictions ou des décisions basées sur eux.L’algorithme est dense de la technologie, car sa conception et son optimisation nécessitent des connaissances professionnelles profondes et une innovation technologique.Les algorithmes sont au cœur de la formation de modèles d’intelligence artificielle, définissant comment transformer les données en idées ou décisions utiles.La génération commune d’algorithmes AI comprend la génération de réseaux de confrontation (GAN) (GAN), d’auto-encodeur transformateur (VAE) et de transformateurs. Puis utilisé pour former des modèles d’IA spécialisés.
Il y a donc tellement d’algorithmes et de modèles, chacun est possible de les intégrer dans un modèle commun?Bittersor est un projet récent qui a attiré beaucoup d’attention.Les autres projets axés sur cette direction comprennent la commune AI (collaboration du code), mais les algorithmes et les modèles sont strictement confidentiels pour les sociétés d’IA et ne sont pas faciles à partager.
Par conséquent, le récit de l’écosystème collaboratif de l’IA est nouveau et intéressant.L’écosystème collaboratif utilise les avantages de la blockchain pour intégrer l’inconvénient de l’algorithme d’IA isolé, mais il reste à observer s’il peut créer une valeur correspondante.Après tout, la principale entreprise d’IA avec des algorithmes et des modèles indépendants a de solides mises à jour, itérations et capacités d’intégration.Par exemple, OpenAI est passé des premiers modèles de génération de texte aux modèles de génération multi-champs en moins de deux ans.Des projets comme Bittersor peuvent avoir besoin d’explorer de nouveaux chemins dans leurs modèles et des champs cibles d’algorithme.
Décentralisation des mégadonnées
D’un point de vue simple, l’utilisation des données de confidentialité pour alimenter les données d’IA et d’annotation est très cohérente avec la technologie de la blockchain.De plus, le stockage de données peut bénéficier aux projets Depin tels que FIL et AR.Dans une perspective plus compliquée, l’utilisation de données de blockchain pour l’apprentissage automatique pour résoudre l’accessibilité des données de la blockchain est une autre direction intéressante (une exploration de Giza).
Théoriquement, les données de blockchain sont accessibles à tout moment, reflétant l’état de l’ensemble de la blockchain.Cependant, pour les personnes en dehors de l’écosystème de la blockchain, il n’est pas facile d’accéder à ces grandes quantités de données.Le stockage de l’ensemble de la blockchain nécessite des connaissances professionnelles riches et un grand nombre de ressources matérielles professionnelles.Afin de surmonter les défis de l’accès aux données de la blockchain, diverses solutions sont apparues dans l’industrie.Par exemple, les fournisseurs de RPC fournissent un accès aux nœuds via l’API, et les services d’index rendent la récupération des données possible via SQL et GraphQL, qui joue un rôle vital dans la résolution de ce problème.Cependant, ces méthodes ont leurs limites.Les services RPC ne conviennent pas aux cas de forte densité qui nécessitent une grande quantité de requête de données et ne peuvent souvent pas répondre aux besoins.Dans le même temps, bien que le service d’index fournit une méthode de récupération de données plus structurelle, la complexité du protocole Web3 rend extrêmement difficile les requêtes efficaces structurelles, et parfois des centaines, voire des milliers de code complexes sont nécessaires.Cette complexité est un obstacle majeur pour les praticiens généraux des données et ceux qui ont une compréhension limitée des détails Web3.Ces effets cumulatifs restreints mettent en évidence la nécessité d’accéder et d’utiliser des données de blockchain qui nécessitent plus d’accès et d’utilisation, ce qui peut favoriser une application et une innovation plus larges dans le domaine.
Par conséquent, la combinaison de la preuve ZKML (Zero-Knowledge de l’apprentissage automatique, de la réduction du fardeau de l’apprentissage automatique sur la chaîne) et des données de blockchain à haute qualité peuvent créer des ensembles de données qui résolvent l’accessibilité des données de blockchain.L’IA peut réduire considérablement la barrière d’accès des données de blockchain.Au fil du temps, les développeurs, les chercheurs et les amateurs d’apprentissage automatique peuvent accéder à des ensembles de données plus élevés et connexes pour construire des solutions efficaces et innovantes.
AI Empowerment Dapp
Depuis le déclenchement de Chatgpt3 en 2023, l’autonomisation de l’IA de DAPP est devenue une direction très courante.Une intelligence artificielle basée sur l’application étendue peut être intégrée via l’API, simplifiant ainsi les plateformes de données intelligentes, les robots de trading, l’encyclopédie blockchain et d’autres applications.D’un autre côté, il peut également agir comme un robot de chat (comme MyShell) ou un partenaire AI (IA sans sommeil), et peut même utiliser l’IA générateur pour créer des PNJ dans le jeu de la blockchain.Cependant, parce que le seuil technique est faible, la plupart d’entre eux ne sont que des ajustements après API intégrée, et l’intégration du projet lui-même n’est pas parfaite, il est donc rarement mentionné.
Mais avec l’arrivée de Sora, je pense personnellement que l’autonomisation de l’AI de GameFi (y compris l’univers Yuan) et des plateformes créatives seront au centre de l’avenir.Compte tenu de la nature inférieure du champ Web3, il est peu probable qu’il produise des produits qui peuvent rivaliser avec les jeux traditionnels ou les entreprises créatives.Cependant, l’émergence de Sora pourrait briser cette impasse (peut-être seulement deux à trois ans).À en juger par la démonstration de Sora, il a le potentiel de rivaliser avec de courtes entreprises dramatiques.La culture communautaire active du Web3 peut également donner naissance à de nombreuses idées intéressantes.
en conclusion
Avec le développement continu de la génération d’outils d’intelligence artificielle, nous allons assister à plus de « moments iPhone » révolutionnaires à l’avenir.Bien que les gens soient sceptiques quant à l’intégration de l’IA et du Web3, je crois que la direction actuelle est fondamentalement correcte, et seulement trois points de douleur principaux sont nécessaires: nécessité, efficacité et ajustement.Bien que l’intégration des deux soit toujours au stade d’exploration, elle n’empêche pas cette voie de devenir le courant dominant du prochain marché haussier.
Le maintien d’une curiosité et une ouverture de nouvelles choses est notre mentalité de base.Historiquement, la transformation d’une voiture en voiture a été instantanément résolue, car les inscriptions et le NFT passé ont été montrés.Tenir trop de préjugés ne provoquera que des opportunités manquées.