著者:Zeke、YBB Capital;
序文
2月16日、Openaiは、「SORA」と呼ばれる最新のWenshengビデオ生成拡散モデルの発売を発表しました。複数の画像から数秒のビデオを生成するPikaやその他のAIビデオ生成ツールとは異なり、SORAは、ビデオと画像の圧縮された潜在的な空間で列車を訓練して、それらを時空パッチに分解してスケーラブルなビデオを生成します。さらに、このモデルは、シミュレートされた物理的およびデジタル世界の能力を示しており、その60秒のデモンストレーションは「物理世界の一般的なシミュレーター」と呼ばれています。
SORAは、以前のGPTモデル「ソースデータトランスフォーマー拡散 – 発光」の技術的パスを継続しており、その開発の成熟度もコンピューティングパワーに依存していることを示しています。ビデオトレーニングに必要なデータの量がテキストよりも大きいことを考えると、コンピューティングパワーの需要はさらに増加すると予想されます。ただし、以前の記事「潜在的な産業の普及:地方分権のベーコン市場」で説明したように、AI時代のコンピューティングパワーの重要性については、AIの人気が高まっています。試みの試みの時点で、depinプロジェクト(ストレージ、コンピューティングパワーなど)に利益をもたらします。Depinに加えて、この記事は過去の議論を更新および改善し、Web3とAIが生み出す可能性のある火花とAI時代のトラックの機会について考えることを目的としています。
AI開発の3つの方向
AIは、人間の知性をシミュレート、拡張、強化することを目的とした新興科学技術です。1950年代と1960年代の誕生以来、AIは半世紀以上にわたって発展しており、現在は社会生活やさまざまな産業を促進するための重要な技術になっています。その過程で、象徴性、つながり、行動主義の3つの主要な研究方向の発展が、今日、人工知能の急速な発展の基盤を築いてきました。
象徴性
シンボリズムは、論理主義またはルールに基づいた推論としても知られています。この方法は、シンボルを使用して、問題ドメインのオブジェクト、概念、関係を表し、論理的推論を使用して問題を解決します。特に専門家のシステムと知識の点で、象徴性は大きな成功を収めています。象徴性の中心的な考え方は、象徴的な操作と論理的推論を通じてインテリジェントな行動を達成できることです。
関連性
または、人間の脳の構造と機能を模倣することにより知性を実現するために、ニューラルネットワーク法と呼ばれます。この方法は、多くの単純な処理ユニット(ニューロンに類似)で構成されるネットワークを構築し、これらのユニット間の接続強度(シナプスと同様)を調整して、学習を促進します。コネクティズムは、データから学習し、一般化する能力を強調しているため、モード認識、分類、および継続的な入力および出力マッピングの問題に特に適しています。コネクショニズムの進化として、深い学習は、画像認識、音声認識、および自然言語処理の分野で突破口になりました。
行動主義
行動主義は、バイオニックロボットと自律的なインテリジェントシステムの研究と密接に関連しており、環境との相互作用を通じて知性が学ぶことができることを強調しています。前の2つとは異なり、行動主義は内部特性や思考プロセスのシミュレーションに焦点を当てていませんが、知覚と行動のサイクルを通じて適応行動を達成することに焦点を当てています。行動主義は、環境との動的な相互作用と学習を通じて知性が反映されると考えているため、複雑で予測不可能な環境で実行されるモバイルロボットと適応制御システムに特に効果的です。
これらの3つの研究方向には根本的な違いがありますが、AIの実際の研究と応用において、人工知能の開発を共同で促進するために、それらは相互作用し、統合することができます。
AIGC原則
AIGCの爆発的な開発分野は、コネクショニズムの進化と応用を表しており、人間の創造性を模倣することで新しい内容を生み出すことができます。これらのモデルは、トレーニングに大きなデータセットとディープラーニングアルゴリズム、および学習データの基礎となる構造、関係、パターンを使用します。ユーザーのプロンプトによると、画像、ビデオ、コード、音楽、デザイン、翻訳、質問の回答、テキストなど、一意の出力が生成されます。現在、AIGCは基本的に、ディープラーニング、ビッグデータ、大規模なコンピューティング機能の3つの要素で構成されています。
深い学習
ディープラーニングは、人間のニューラルネットワークを模倣するアルゴリズムを使用する機械学習のサブフィールドです。たとえば、人間の脳は何百万もの相互に関連したニューロンで構成されており、情報を学習および処理するために協力しています。同様に、深い学習ニューラルネットワーク(または人工ニューラルネットワーク)は、コンピューターで一緒に機能する多層人工ニューロンで構成されています。これらの人工ニューロン(ノードと呼ばれる)は、数学的計算を使用してデータを処理します。人工ニューラルネットワークは、これらのノードを使用して、深い学習アルゴリズムを通じて複雑な問題を解決します。
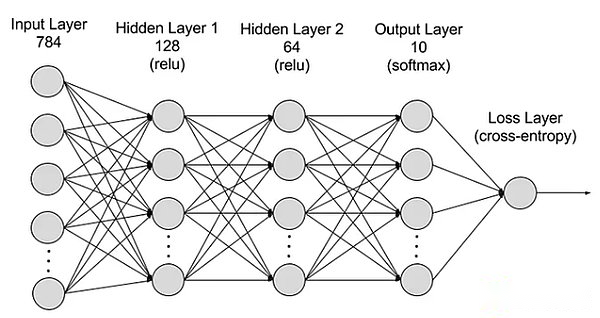 ニューラルネットワークは、入力層、隠されたレイヤー、出力層、およびパラメーターが異なるレイヤーに接続されているレイヤーに分割されます。
ニューラルネットワークは、入力層、隠されたレイヤー、出力層、およびパラメーターが異なるレイヤーに接続されているレイヤーに分割されます。
レイヤーを入力:ニューラルネットワークの最初の層は、外部入力データの受信を担当します。入力層の各ニューロンは、入力データの特徴に対応します。たとえば、画像データを処理する場合、各ニューロンは画像のピクセル値に対応する場合があります。
隠れレイヤー:入力層はデータを処理し、さらにネットワークに渡されます。これらの隠されたレイヤーは、さまざまなレベルで情報を処理し、新しい情報を受信するときに動作を調整します。深い学習ネットワークには何百もの隠れ層があり、複数の角度から問題を分析できます。たとえば、分類する必要がある未知の動物のイメージがある場合、耳の形、脚の数、生徒のサイズをチェックすることで、すでに知っている動物と比較できます。ディープニューラルネットワークの隠れた層も同様の方法で機能します。ディープラーニングアルゴリズムが動物の画像を分類しようとする場合、各隠された層は動物の異なる特性を処理し、それを正確に分類しようとします。
出力層:ニューラルネットワークの最後のレイヤーは、ネットワークの出力を生成する責任があります。出力層の各ニューロンは、可能な出力カテゴリまたは値を表します。たとえば、分類問題では、各出力層ニューロンは1つのカテゴリに対応する場合があり、回帰問題では、出力層には1つのニューロンのみがあり、その値は予測結果を表します。
パラメーター:ニューラルネットワークでは、異なるレイヤー間の接続は、トレーニングプロセス中に最適化される重みと逸脱によって表され、ネットワークがデータのパターンを正確に識別して予測を行うことができます。パラメーターを増やすと、ニューラルネットワークの能力、つまりデータの複雑なモードを学習して表現する能力が向上します。ただし、これにより、コンピューティングパワーの需要も高まります。
ビッグデータ
効果的なトレーニングを実施するために、ニューラルネットワークには通常、大規模で多様で高品質でマルチソースデータが必要です。トレーニングと検証機械学習モデルの基礎を構成します。ビッグデータを分析することにより、機械学習モデルは、予測または分類を実現するために、データのパターンと関係を学習できます。
大規模なコンピューティングパワー
ニューラルネットワークの多層構造は複雑で、多くのパラメーター、ビッグデータ処理要件、反復トレーニング方法があります(モデルは、活性化関数計算を含む各層の順方向および後方伝送計算を含むトレーニング中に繰り返し反復する必要があります。 、損失関数の計算、勾配レベルの計算、および体重更新)、高精度のコンピューティング要件、並列コンピューティング機能、最適化と正規化技術、モデル評価と検証プロセスは、高いコンピューティング電力要件につながります。

ソラ
OpenAIのAIモデルを生成する最新のビデオとして、SORAは、人工知能の処理と多様な視覚データの理解の大きな進歩を表しています。ビデオ圧縮ネットワークと時空パッチテクノロジーを使用することにより、SORAは世界中のさまざまなデバイスによってキャプチャされた大規模な視覚データを統一された表現形式に変換し、それにより複雑な視覚コンテンツの効率的な処理と理解を実現できます。テキスト条件を使用してモデルを拡散させると、SORAはテキストプロンプトと高度に一致するビデオまたは画像を生成し、高い創造性と適応性を示しています。
ただし、SORAは現実世界でのビデオ生成とシミュレーションの相互作用でブレークスルーを行っていますが、物理世界のシミュレーションの精度、成長ビデオの一貫性、複雑なテキストの指示、トレーニングとトレーニングとトレーニングと生成効率の生成。本質的に、SORAは、Openaiの独占コンピューティングパワーとファーストモーバーの利点を通じて、「ビッグデータトランスフォーマー拡散 – エマージェンス」の古い技術的パスを継続し、ブルートの美学を実現します。他の人工知能企業は、技術革新を通じて依然として上回る可能性があります。
SORAとブロックチェーンの関係は大きくありませんが、SORAの影響により、来年か2年では、他の高品質のAI世代ツールが迅速に現れ、発達し、衝撃、Depinなどが発達します。したがって、SORAを一般的に理解する必要があります。
ai x web3融合の4つの方法
前述のように、AIの生成に必要な基本的な要素は、基本的に3つのものであることを理解できます:アルゴリズム、データ、コンピューティングパワー。一方、その普遍性と出力効果を考慮すると、AIは生産方法を完全に変更するツールです。同時に、ブロックチェーンの最大の影響は二重です。生産関係と分散化の再編成です。
したがって、これら2つのテクノロジーの衝突により、次の4つのパスが生成される可能性があると思います。
地方分権
前述のように、このセクションは、コンピューティング機能のステータスを更新することを目的としています。AIに関しては、コンピューティングパワーは不可欠な側面です。ソラの出現により、コンピューティングパワーに対する想像を絶するAI需要が生まれました。最近、2024年のスイスで開催されたダボス世界経済フォーラムで、Openai CEOのSam Altmanは、現在の最大の制約であるとCEOのSam Altmanは、彼らの将来の重要性が通貨と同等である可能性があることを暗示していると公に述べています。その後、2月10日、サム・アルトマンは、現在のグローバルな半導体帝国を作成するために、7兆米ドル(2023年の中国のGDPの40%に相当)を調達する衝撃的な計画を発表しました。コンピューティングパワーについての私の考え方は、全国的な封鎖と企業の独占に限定されています。
したがって、分散化されたコンピューティングパワーの重要性は自明です。ブロックチェーンの特性は、実際に現在のコンピューティング能力での極端な独占の問題と、専用のGPUの取得に関連する高価なコストを解決できます。AI要件の観点から見ると、コンピューティングパワーの使用は、推論とトレーニングの2つの方向に分けることができます。分散型ネットワークがニューラルネットワーク設計を統合する必要があるため、トレーニングに焦点を当てたプロジェクトはほとんどありません。これは、より高いしきい値と困難な実装を備えた方向です。対照的に、分散型ネットワーク設計はそれほど複雑ではなく、ハードウェアと帯域幅の要件も低く、これはより主流の方向であるため、推論は比較的単純です。
集中化されたコンピューティングパワー市場には、幅広い想像力があり、多くの場合、「兆レベル」のキーワードとリンクしています。これは、AI時代の最も簡単なトピックでもあります。しかし、最近登場した多くのプロジェクトを見ると、それらのほとんどは、予期しない試みを検討するためにトレンドを使用しているようです。彼らはしばしば分散化の旗を上げますが、分散型ネットワークの非効率性について議論することは避けてください。さらに、デザインの均一性の程度は非常に高いです(1つのL2プラスマイニングデザイン)。
アルゴリズムとモデルの共同システム
機械学習アルゴリズムは、データからモードとルールを学習し、それらに基づいて予測または決定を下すことができるアルゴリズムです。アルゴリズムは、その設計と最適化には深い専門知識と技術革新が必要であるため、テクノロジーは密集しています。アルゴリズムは、人工知能モデルをトレーニングするコアであり、データを有用な洞察または決定に変換する方法を定義します。AIアルゴリズムの共通生成には、対立ネットワーク(GAN)(GAN)、トランスセルフエンコーダー(VAE)、および変圧器の生成が含まれます。次に、特殊なAIモデルをトレーニングするために使用しました。
それで、非常に多くのアルゴリズムとモデルがあり、それぞれがそれらを共通モデルに統合することが可能ですか?Bittersorは、さまざまなAIモデルとアルゴリズムから協力して学習し、より効率的で有能なAIモデルを作成している最近のプロジェクトです。この方向に焦点を当てた他のプロジェクトには、Commune AI(コードコラボレーション)が含まれますが、アルゴリズムとモデルはAI企業にとって厳密に機密性が高く、共有するのは簡単ではありません。
したがって、AI共同生態系の物語は斬新で興味深いものです。共同エコシステムは、ブロックチェーンの利点を使用して、分離されたAIアルゴリズムの欠点を統合しますが、対応する値を作成できるかどうかはまだわかりません。結局のところ、独立したアルゴリズムとモデルを備えた大手AI企業には、強力な更新、反復、統合機能があります。たとえば、Openaiは、初期のテキスト生成モデルから2年未満でマルチフィールド生成モデルに開発されています。BitterSorのようなプロジェクトは、モデルとアルゴリズムターゲットフィールドの新しいパスを探索する必要がある場合があります。
分散化ビッグデータ
単純な観点から、AIおよび注釈データをフィードするためのプライバシーデータを使用することは、ブロックチェーンテクノロジーと非常に一致しています。さらに、データストレージは、FILやARなどのDePINプロジェクトに利益をもたらす可能性があります。より複雑な観点から、ブロックチェーンデータのブロックチェーンデータを使用してブロックチェーンデータのアクセシビリティを解決することも、もう1つの興味深い方向です(Giza Explorationの1つ)。
理論的には、ブロックチェーン全体の状態を反映して、ブロックチェーンデータにいつでもアクセスできます。ただし、ブロックチェーンエコシステム以外の人々の場合、これらの大量のデータにアクセスするのは簡単ではありません。ブロックチェーン全体を保存するには、豊富な専門知識と多数の専門的なハードウェアリソースが必要です。ブロックチェーンデータへのアクセスの課題を克服するために、業界にさまざまなソリューションが登場しています。たとえば、RPCプロバイダーはAPIを介してノードアクセスを提供し、インデックスサービスによりSQLとGraphQLを介してデータ取得を可能にします。これは、この問題を解決する上で重要な役割を果たします。ただし、これらの方法には制限があります。RPCサービスは、大量のデータクエリが必要な高密度のケースには適しておらず、多くの場合、ニーズを満たすことができません。同時に、インデックスサービスはより構造データ検索方法を提供しますが、Web3プロトコルの複雑さにより、構造効率の高いクエリが非常に困難になり、場合によっては数百または数千の複雑なコードが必要です。この複雑さは、一般的なデータ実践者とWeb3の詳細の理解が限られている人にとって大きな障害です。これらの制限された累積効果は、より多くのアクセスと使用を必要とするブロックチェーンデータにアクセスして使用する必要性を強調しています。
したがって、ZKML(機械学習のゼロの証明、チェーン上の機械学習の負担を軽減する)と高品質のブロックチェーンデータを組み合わせることで、ブロックチェーンデータのアクセシビリティを解決するデータセットが作成される場合があります。AIは、ブロックチェーンデータのアクセス障壁を大幅に削減できます。時間が経つにつれて、開発者、研究者、機械学習愛好家は、より高品質で関連するデータセットにアクセスして、効果的で革新的なソリューションを構築できます。
AIエンパワーメントdapp
2023年のChatGPT3の発生以来、AIのDAPPのエンパワーメントは非常に一般的な方向になりました。広範なアプリケーションベースの人工知能は、APIを介して統合でき、それにより、単純化されたインテリジェントなデータプラットフォーム、取引ロボット、ブロックチェーン百科事典、およびその他のアプリケーションを統合できます。一方、チャットロボット(MyShellなど)やAIパートナー(Sleepless AI)として機能し、Generatory AIを使用してブロックチェーンゲームでNPCを作成することもできます。ただし、技術的なしきい値は低いため、それらのほとんどは統合されたAPI後の調整にすぎず、プロジェクト自体の統合は完全ではないため、めったに言及されません。
しかし、ソラの到着に伴い、私は個人的には、AIのGameFi(Yuan Universeを含む)と創造的なプラットフォームのエンパワーメントが未来の焦点になると考えています。Web3フィールドの下位の性質を考えると、従来のゲームやクリエイティブ企業と競合できる製品を生産する可能性は低いです。しかし、ソラの出現はこのデッドロックを破るかもしれません(たぶん2〜3年しか)。ソラのデモから判断すると、短いドラマ企業と競争する可能性があります。Web3のアクティブなコミュニティ文化は、多くの興味深いアイデアを産むことができます。
結論は
人工知能ツールの生成の継続的な開発により、将来的には「iPhoneの瞬間」がよりブレークスルーするのを目撃します。人々はAIとWeb3の統合に懐疑的ですが、現在の方向は基本的に正しいと信じており、必要性、効率、適合という3つの主な問題点のみが必要です。2つの統合はまだ探査段階にありますが、この道が次の強気市場の主流になることを妨げません。
十分な好奇心と新しいものの開放性を維持することが私たちの基本的なメンタリティです。歴史的に、碑文と過去のNFTが示されたように、馬車から車への変換が即座に解決されました。あまりにも多くの偏見を保持することは、逃した機会を引き起こすだけです。