
Escritura: Preda Fuente: Cadena Capases
resumen
Mirando la historia paralela de la computadora: el paralelismo del primer nivel esNivel de instrucción paraleloEsenciaInstrucción El paralelo al nivel es la forma principal de mejorar el rendimiento en los últimos 20 años del siglo XX.El paralelismo de nivel de instrucción puede mejorar el rendimiento con la premisa de que el programa es compatible binario, que los programadores les gusta particularmente.Hay dos tipos de instrucciones en paralelo.Uno es el tiempo paralelo, es decir, la línea de ensamblaje de instrucciones.El orden de la línea de ensamblaje es como la línea de ensamblaje de la producción de fábrica de un automóvil. , producirá varios autos al mismo tiempo en múltiples procesos.El otro es el espacio paralelo, es decir, más lanzamiento o exceder el estándar.El lanzamiento múltiple es como una carretera de carril múltiple, y la ejecución fuera de orden puede superar las cantidades múltiples.Después de la aparición de RISC en la década de 1980, el desarrollo paralelo del nivel de instrucción de 20 años posterior alcanzó un pico.
El paralelismo del segundo nivel esData -Level Paralel, Se refiere principalmente a la estructura vectorial de la transmisión única (SIMD).La primera línea paralela a nivel de datos apareció en ENIAC.La máquina vectorial representada por Cray en los años sesenta y setenta fue muy popular.Hasta Cray-4, Simd guardó silencio por un tiempo, y ahora ha comenzado a recuperar la vitalidad, y se usa cada vez más.Por ejemplo, las instrucciones multimedia AVX en X86 pueden usar canales de 256 bits para realizar cuatro operaciones de 64 bits u ocho operaciones de 32 bits.SIMD, como un suplemento efectivo de instrucciones paralelas, ha jugado un papel importante en el campo de la transmisión de medios.
El tercer nivel de paralelismo esMisión -nivel paraleloEsenciaUna gran cantidad de tareas paralelas en el nivel de tareas está en la aplicación de Internet.El representante del paralelo a nivel de tarea es un procesador de múltiples costos y un procesador multifreshalado, que es el método principal para que la arquitectura de computadora actual mejore el rendimiento.La granularidad paralela de la tarea en paralelo es grande, y un hilo contiene cientos de o más instrucciones.
Desde la perspectiva del desarrollo de la computación paralela, lo que ahora está en el primer nivel de la cadena de bloques es el proceso de transición del primer nivel al segundo nivel.El sistema de cadena de bloques convencional generalmente adopta dos arquitectura: arquitectura única o múltiple.La cadena única, como Bitcoin y Ethereum común, todo el sistema tiene solo una cadena.En cada nodo blockchain, las transacciones de contrato inteligente generalmente se ejecutan en la ejecución en serie, lo que resulta en un bajo rendimiento de todo el sistema.
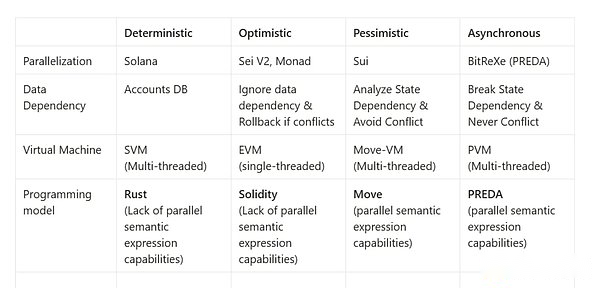
Algunos de los sistemas blockchain de alto rendimiento recientes, aunque se adopta la arquitectura de una sola cadena, también admite la ejecución paralela de transacciones de contratos inteligentes.Thomas Dickerson y Maurice Herlihy de la Universidad de Brown y la Universidad de Yale propusieron por primera vez un modelo de ejecución paralelo basado en STM (Memoria de transaccionamiento de software) en su documento PODC’17. , completará la reversión de estado a través de STM, y luego realizará estas transacciones de conflicto estatales en serie en serie.Dichos métodos se han aplicado a múltiples proyectos de blockchain de alto rendimiento, incluidos APtos, SEI y Mónada.En consecuencia, otro modelo de ejecución paralelo se basa en la concurrencia pesimista (paralelo pesimista), es decir, antes de que la transacción se ejecute la ejecución paralela, existe un conflicto entre el estado de acceso a la transacción. .Este tipo de método generalmente utiliza un método previo a la competencia para utilizar herramientas de análisis de programa para realizar un análisis estático y construir dependencias de estado en el código de contrato inteligente, como la dirección del gráfico sin bucle (DAG).Cuando la transacción concurrente se envía al sistema, el sistema determina si la transacción se puede ejecutar paralela de acuerdo con el estado de las necesidades de transacción y la relación de dependencia entre las necesidades de transacción.Solo las transacciones que no tienen una relación dependiente del estado entre sí se ejecutarán paralelas.Este tipo de método se aplica a Zilliqa (versión de cospla) y proyectos blockchain de alto rendimiento como SUI.Los modelos de ejecución paralelos anteriores pueden mejorar significativamente el rendimiento del sistema.Estos dos esquemas corresponden al nivel de instrucción mencionado anteriormente paralelo.Sin embargo, hay dos problemas en estas tareas: 1) problemas de escalabilidad y 2) problemas de expresión semántica paralela, explicaremos en detalle a continuación.
Diseño paralelo
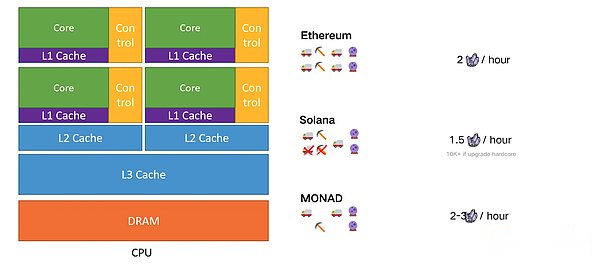
Utilizaremos el proyecto típico de Solana y Mónada como un ejemplo para desmontar su diseño de arquitectura paralela que incluye la clasificación de paralelización, la dependencia de los datos, etc. Afectará los indicadores clave de Paralelismo y TPS.
Solana
Desde un nivel superior, el concepto de diseño de Solana es que la innovación de blockchain debería desarrollarse con el avance del hardware.Con la mejora continua del hardware según la ley de Moore, Solana tiene como objetivo beneficiarse de un mayor rendimiento y escalabilidad.El coeficiente de Solana, Anatoly Yakovenko, diseñó inicialmente la arquitectura de paralelización de Solana hace más de cinco años.
Uso de solanaParalelismo de defirmación(Paralelización determinista), que proviene de la experiencia de Anatoly en el uso de sistemas integrados en el pasado, los desarrolladores generalmente declaran todos los estados por adelantado.Esto permite que la CPU comprenda todas las dependencias, a fin de prefiere la parte necesaria de la memoria.El resultado es optimizar la implementación del sistema, pero lo mismo requiere que los desarrolladores realicen un trabajo adicional por adelantado.En Solana, todas las dependencias de memoria del programa son necesarias y explican en el constructor (es decir, la lista de acceso), de modo que el tiempo de ejecución puede sintonizar de manera eficiente y realizar múltiples transacciones.
El siguiente componente principal de la arquitectura Solana esVM de alce de mar,Admite múltiples contratos y transacciones en paralelo de acuerdo con la cantidad central del dispositivo de verificación.Las verificaciones en la cadena de bloques son los participantes de la red, responsables de verificar y confirmar transacciones, proponer nuevos bloques y mantener la integridad y la seguridad de la cadena de bloques.Dado que los estados previos de la transacción que las cuentas deben leerse, escribir y bloquear, el programa de programación de Solana puede determinar qué transacciones se pueden ejecutar simultáneamente.Debido a esto, durante la verificación, los «productores de bloque» o los líderes pueden clasificar miles de transacciones procesadas y ajuste paralelo de transacciones no superpuestas.
Monada
Mónada está construyendo la primera capa de EVM paralela con un EVM paralelo completo.La singularidad de la monad se encuentra no solo su motor paralelo, sino también el motor de optimización que construyeron en el fondo.Monad utiliza un método único para su diseño general, combinando varias funciones clave, incluidas las tuberías, la E/S asíncrona, el consenso y la ejecución de separación, y MonaddB.
Similar a SEI, Uso de Mónadas Blockchain«Optimismo y control de pase (OCC)»Ven a ejecutar la transacción.Cuando existen múltiples transacciones en el sistema al mismo tiempo, se producen transacciones concurrentes.Hay dos etapas de este método de transacción: ejecución y verificación.
Durante la etapa de ejecución, las transacciones son optimistas y toda lectura/escritura se almacena temporalmente en un almacenamiento específico de transacciones.Desde entonces, cada transacción ingresará a la etapa de verificación, que se cambiará para verificar la información en la operación de almacenamiento temporal de acuerdo con cualquier estado realizado por la oficina anterior.Si la transacción es independiente, la transacción se ejecuta paralela.Si una transacción lee los datos de otra modificación de la transacción, se generará conflictos.
Una innovación clave diseñada por Monad es un ferrocarril con un ligero desplazamiento.Este desplazamiento permite más procesos en paralelización al ejecutar múltiples instancias al mismo tiempo.Por lo tanto, la línea de ensamblaje se utiliza para optimizar muchas funciones, como el acceso de estado a la tubería, la tubería de ejecución de la transacción, el consenso y la tubería, y la tubería en el mecanismo de consenso en sí. el armario.
>
En Mónada, las transacciones se clasifican en lineal en el bloque, pero el objetivo es lograr el estado final mediante la ejecución paralela.MonadaOptimista y paralelismoUn algoritmo para diseñar el motor de ejecución.El motor de Monad maneja la transacción al mismo tiempo, y luego se analiza para garantizar que si la transacción se ejecuta una tras otra, los resultados serán los mismos.Si hay conflictos, debe volver a ejecutar.La ejecución paralela aquí es un algoritmo relativamente simple, pero lo combina con otras innovaciones clave de Monad para hacer que este método sea novedoso.Una cosa que debe tenerse en cuenta aquí es que incluso si se produce una ejecución por referencia, generalmente es muy barata, porque la entrada requerida por las agencias inválidas siempre siempre mantiene el caché, por lo que esta será una simple búsqueda de caché.La ejecución de la referencia tendrá éxito porque ya ha ejecutado las transacciones anteriores.
Además de retrasar la ejecución,Mónada también mejora el rendimiento al separar la ejecución y el consensoSimilar a Solana y SEI.La idea aquí es que si relaja las condiciones para completar la ejecución cuando se completa el consenso, los dos se pueden ejecutar paralelos para aportar tiempo extra a los dos.Por supuesto, Monad usa un algoritmo de certeza para lidiar con esta situación para garantizar que uno de ellos no corra demasiado lejos y no pueda ponerse al día.
Independientemente de si los métodos optimistas de ejecución paralelos o pesimistas, los sistemas anteriores usan la memoria compartida como la abstracción del modelo de datos de la capa inferior, es decir, no importa cuántas unidades paralelas sean, las unidades paralelas pueden obtener todos los datos (aquí se refiere a todos los datos En los datos de blockchain), los datos de estado pueden acceder directamente mediante diferentes ejecuciones paralelas (es decir, todos los datos en todas las cadenas se pueden leer y escribir directamente en paralelo).Use la memoria compartida como un sistema de blockchain como el modelo de datos subyacente.
Este tipo de método paralelo en este nodo solo necesita modificar la arquitectura de la capa ejecutiva del contrato inteligente, y no necesita modificar la lógica de la capa de consenso del sistema, que es muy adecuada para mejorar el rendimiento de la cadena única. sistema.Por lo tanto, porque no hay una porción de almacenamiento de datos,Cada nodo en la red blockchain aún necesita ejecutar todas las transacciones y almacenar todos los estadosEsenciaAl mismo tiempo, en comparación con la arquitectura de nada compartido que es más adecuado para las extensiones distribuidas, estos usan la memoria compartida como una abstracción del sistema abstracto del modelo de datos subyacente. Las capacidades de ejecución no pueden resolver fundamentalmente la escalabilidad de la cadena de bloques.
Entonces, ¿hay una solución preparada lista?
Modelo de programación paralelo
Antes de presentar Preda, esperamos hacer una pregunta natural ::¿Por qué usar la programación paralela?En parte de los años setenta, ochenta, e incluso parte de la década de 1990, estábamos muy satisfechos con la programación (o programación en serie).Puede escribir un programa para completar una tarea.Después de que termine la ejecución, le dará un resultado.La tarea se completa, ¡todos estarán muy felices!Aunque la tarea se ha completado, pero si está haciendo millones o incluso miles de millones de simulación de partículas calculada por segundo, o se procesa con miles de imágenes de píxeles, querrá que el programa se ejecute más rápido, esto significa que necesita una CPU más rápida.
Antes de 2004, el fabricante de la CPU IBM, Intel y AMD pueden proporcionarle un procesador más rápido y rápido. UPC.Pero para 2004, debido a restricciones técnicas, la tendencia de aumentar la velocidad de la CPU no puede continuar.Esto requiere que otras tecnologías continúen proporcionando un mayor rendimiento.La solución del fabricante de la CPU es colocar las dos CPU en una CPU, incluso si las dos CPU funcionan de velocidad inferior a una sola CPU.Por ejemplo, en comparación con la CPU de un solo puntaje a la velocidad de 300 MHz, dos CPU (los fabricantes los llaman el núcleo) a una velocidad de 200 MHz pueden realizar más cálculos por segundo (es decir, intuitiva intuitiva, un aspecto intuitivo de 2 × 200 & gt;
Suena como una historia de «CPU Single Multi -Core» de sueño se convierte en realidad, lo que significa que los programadores ahora deben aprender métodos de programación paralelos para usar estos dos núcleos.Si una CPU puede realizar dos programas al mismo tiempo, el programador debe escribir estos dos programas.Pero, ¿se puede transformar en dos veces la velocidad de ejecución del programa?Si no, entonces la idea de nuestro 2 × 200 y GT;¿Qué pasa si un núcleo no tiene suficiente trabajo?En otras palabras, solo un núcleo está realmente ocupado, pero el otro núcleo no hace nada?En este caso, es mejor usar un solo núcleo de 300 MHz.Después de la introducción de multicore, muchos problemas similares son muy prominentes.
>
En la figura a continuación, imaginamos a Bob y Alice como dos justas de oro, y la fiebre del oro requiere cuatro pasos:
-
Conduzca hasta la mina
-
minería
-
Mineral de carga
-
Almacenar y pulir
>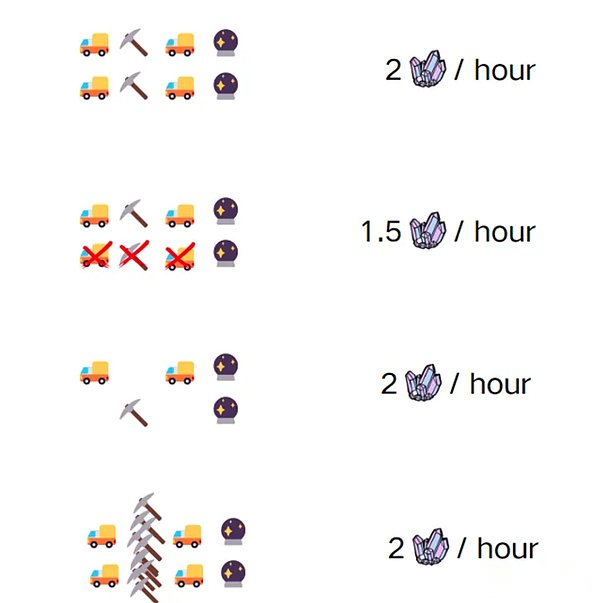
Todo el proceso minero consta de cuatro tareas independientes pero ordenadas, y cada tarea lleva 15 minutos.Cuando Bob y Alice están en curso al mismo tiempo, pueden completar el doble de la carga de trabajo minero en una hora, porque tienen sus propios autos, pueden compartir el camino y pueden compartir la herramienta de pulido.
Pero si un día, el vehículo minero Bob falla.Dejó el auto minero en el taller de reparación y olvidó la selección de hierro del auto minero.Era demasiado tarde para regresar a la planta de procesamiento, pero aún tenían un trabajo que hacer.¿Pueden usar el vehículo minero de Alice y un mango en el interior, pueden elegir dos minerales por minuto?
En la analogía mencionada anteriormente, los cuatro pasos de la minería son los hilos, y los autos mineros son centrales (núcleo); : Antes de la ejecución del hilo 1, no puede ejecutar el hilo 2.El número de minerales cosechados significa rendimiento del programa.Cuanto mayor sea el rendimiento, mayores serán los beneficios de Bob y Alice.Puede considerar la mina como memoria, y puede obtener una unidad de datos (mina de oro), para que el proceso de elegir un mineral en el subproceso 1 sea similar a la lectura de unidades de datos de la memoria.
Ahora, veamos qué pasará si el vehículo minero de Bob falla.Bob y Alice necesitan compartir un automóvil, lo cual no es un problema al principio. El número de mineral que se puede enviar a pulido está restringido por el «automóvil minero máximo puede acomodar minerales».
Esta es también la naturaleza de VM paralela de Solana, Core Sharing.
Intercambio del núcleo
El elemento de diseño final de Solana es«Tubería»EsenciaCuando los datos deben procesarse a través de una serie de pasos y diferente hardware es responsable de cada paso, aparece la operación de la línea de ensamblaje.La idea clave aquí es obtener datos que requieran operación en serie y usar la tubería para que sea paralela.Estas tuberías pueden ejecutarse en paralelo, y cada tubería puede manejar diferentes lotes de transacción.Cuanto mayor sea la velocidad de procesamiento del hardware (capacidad de carga del vehículo minero), mayor será la paralelización en todo momento.Hoy, el nodo de hardware de Solana requiere que sus operadores de nodo tengan solo un centro de datos de opción, lo que brinda eficiencia pero se aparta de la intención original de la cadena de bloques.
La dependencia de los datos no se divide (compartir los recursos de memoria)
Después de actualizar el vehículo minero, debido a que la capacidad minera no puede mantenerse al día, muchas veces el vehículo minero no está satisfecho.Por lo tanto, Bob gastó un alto precio para comprar máquinas mineras, lo que mejoró la eficiencia de la minería (actualización de la unidad de ejecución).Se pueden producir 10 copias de minerales en los mismos 15 minutos, pero debido a que el trabajo de molienda todavía se realiza a mano, el mineral generado por más unidades de tiempo no se ha convertido en más oro, y más mineral se aprieta por la exprimencia. Almacén;Qué tan rápido son los datos de procesamiento (es decir, la velocidad de operación central) es irrelevante.Estaremos limitados por la velocidad de adquisición de datos.
La velocidad de E/S más lenta nos molestará seriamente, porque la E/S es la parte más lenta de la computadora, y la lectura asincrónica de los datos (E/S asincrónicas) se volverá crucial.
Incluso si Bob puede cavar 10 máquinas mineras en 15 minutos, si la competencia de acceso a la memoria existe, aún se limitará a 2 minería de 2 partes cada 15 minutos.Los esquemas de cadena de bloques paralelos existentes se dividen en dos facciones: ejecución poseal y ejecución optimista de la solución propuesta por este problema.
El primero requiere la dependencia del estado de los datos antes de la escritura y la lectura de los datos.Este último no hace suposiciones y restricciones al escribir datos.
Examinado por el plan de ejecución optimista de Monad: la realidad es que la mayor parte de la carga de trabajo es la ejecución de la transacción, y las escenas que ocurren en paralelo no son las esperadas.La imagen a continuación es el tipo de fuente de consumo de tarifa de gas de Ethereum; aunque la proporción de contratos inteligentes sin popularidad en esta distribución es tan alta, de hecho, los diferentes tipos de tipos de transacciones no tienen una distribución uniforme.La lógica paralela de la ejecución optimista es factible en la era de Web2, porque una gran parte de las solicitudes de aplicación Web2 son el acceso, no la modificación;Sin embargo, el campo Web3 es todo lo contrario.
>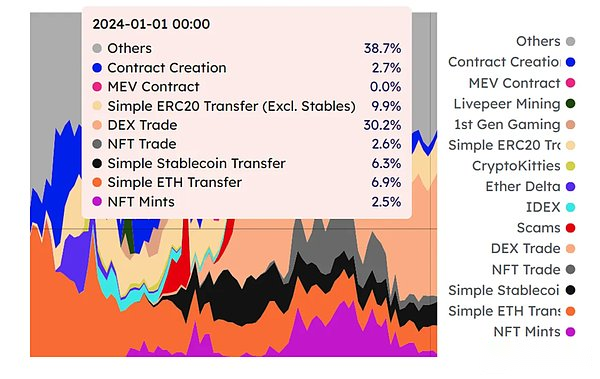
Entonces, la conclusión es que la monad puede alcanzar el paralelo, peroLa concurrencia existe en el límite teórico, es decir, cae en el intervalo de 2 a 3 veces, No los 100k de su propaganda.En segundo lugar, no hay forma de expandir este límite superior al aumentar la máquina virtual, es decir, no hay forma de lograr un equivalente de múltiples puntos para aumentar la capacidad de procesamiento.Finalmente, es un problema que siempre está hablando, porque no hay datos de corte, Monad en realidad no responde los requisitos del nodo después de la expansión de la expansión del estado. inevitablemente ver el camino de Mónada a Solana.Al final, el punto más importante es que la implementación optimista no es adecuada para paralelo en el campo blockchain.
>
采矿一段时间后,Bob 问了自己一个问题:「为什么我要等 Alice 回来以后再进行打磨?当他打磨时,我可以装车子,因为装车和打磨需要的时间完全相同,我们肯定不会遇到需要等待打磨空闲的状态。在 Alice 完成采矿之前,我会开车继续去挖矿,这样我们俩都可以是 100% 的忙碌。”」这个天才的想法让他们重新回到两倍的效率,甚至不需要额外的采矿车。重要的是,Bob 重新设计了程序,也就是线程执行的顺序,让所有的线程永远都不会陷入等待核心内部共享资源(比如采矿车及石镐)的状态。
This is the correct version of parallel. Through the division of the state of smart contracts, accessing shared resources will neither cause a thread to enter the queue, nor will it limit the speed of the final atomicity due to the pipeline of data I/O .
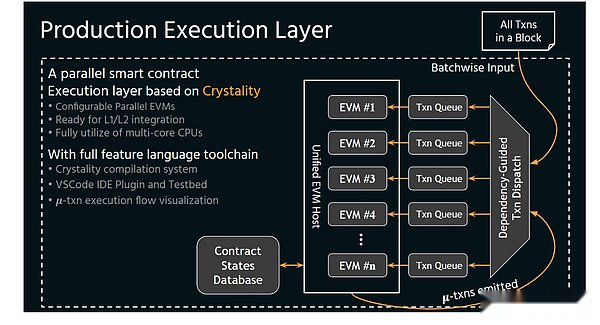
PREDA 模型通过将合约代码执行时刻对合约状态的访问结构暴露给执行层,使得执行层可以轻易合理调度,完全避免执行结果的回滚。Este modo paralelo también se llama asíncrono.
Asincrónico
>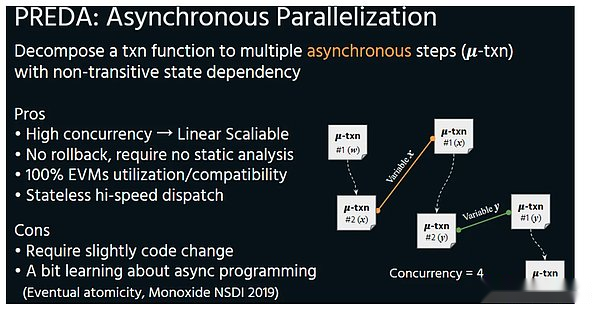
Debido a que solo en paralelo es asíncrono, los hilos crecientes llegarán a la mejora lineal.而不会像前面的例子一样,升级了采矿车的容量但是因为采矿设备落后导致采矿车空跑。The parallel execution environment of Preda is the most essential difference between Solana -just like the difference between multi -core CPU and GPU. Data dependence, and more importantly, the parallelism of Porta’s parallel model will increase due to the increase in threads, which is lo mismo que la GPU.在区块链的逻辑中,线程的增加(VM)会降低全节点的硬件需求,从而达到在保证去中心化的前提下提升性能。
>
>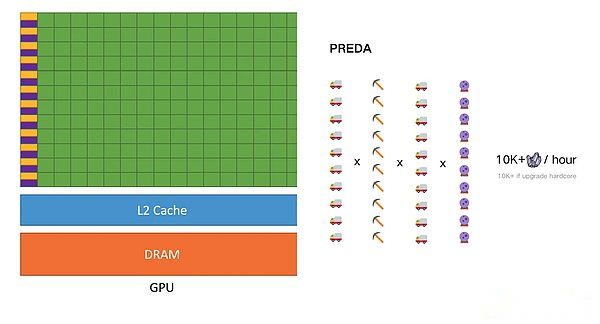
最后达到这一并行区块链的终局,行业内缺乏的除了是架构设计,还缺乏并行编程语言的语义表达。
Expresión semántica del lenguaje de programación paralelo
Al igual que Nvidia requiere CUDA, y la cadena de bloques paralela también necesita nuevos lenguajes de programación: Preda.如今的智能合约的开发者并行语义进行表达,无法有效利用底层多链架构提供的支持(数据分片或执行分片或者兼而有之),无法实现通用智能合约交易的有效并行。Todos los sistemas utilizan lenguajes tradicionales de programación de contratos inteligentes comunes, como solidez, movimiento, óxido.These programming languages lack the ability of parallel semantic expression, that is, do not have the ability to control and data flow between parallel programming models and programming language expression like CUDA or parallel programming models in the field of high -performance computing or big Campos de datos como CUDA.
The lack of parallel programming models and programming languages suitable for smart contracts will cause the application and algorithm from serial to parallel restructuring cannot be completed. As a result, the application and algorithm cannot be adapted with parallel execution capabilities with the bottom layer. Mejorar la eficiencia de implementación de las aplicaciones y el rendimiento general del sistema blockchain.
PREDA 提出的这一种分布式编程模型,通过程序化合约作用域对合约状态进行细粒度划分,并通过功能中继语义(Functional Relay) 将交易执行流分解后分布在多个并行执行引擎上执行。
该模型还通过程序化合约作用域(Programmable Scope)定义合约状态的划分方案,允许开发者根据应用的访问模式进行优化。通过异步功能中继,可以将交易执行流移动到需要访问状态的执行引擎上继续,实现了执行流程的移动而非数据的移动。
这种模型实现了合约状态的分布式划分和交易流量的分担,而不需要开发者关心底层多链系统的细节。实验结果表明,在 256 个执行引擎上 PREDA 模型可实现最高 18 倍的吞吐量提升,接近理论上的并行极限。Mediante el uso de instrucciones de contador e intercambio de partición, mejora aún más el paralelismo.
Conclusión
El sistema blockchain utiliza tradicionalmente un motor de ejecución de un solo pedido (como EVM) para manejar todas las transacciones, lo que limita la escalabilidad.多链系统运行并行执行引擎,但每个引擎都处理智能合约的所有交易,无法在合约级别实现可扩展性。本篇文章论述了以 Solana 为代表的确定性并行的本质核心共享,以及以 Monad 为代表的乐观并行为何无法在真实的区块链应用场景中稳定运行 & 面临的高频率回滚的可能。E introdujo el motor de ejecución paralelo de PredA.PREDA 团队提出了一种新颖的编程模型,通过划分智能合约的状态并跨执行引擎分配交易流量来扩展单个智能合约。Presenta el alcance de los contratos programables para definir la división del estado del contrato.Cada alcance se ejecuta en un motor de ejecución dedicado.El relé funcional asincrónico se usa para descomponer las corrientes de ejecución de transacciones y lo mueve por el motor cuando se queda en otro lugar.
>
Esto combina la lógica de transacciones con la partición de estado del contrato, que permite el paralelismo inherente sin la sobrecarga de datos en movimiento.其并行模型既在智能合约层面拆分了状态,解耦了数据发布层面的依赖性,也提供了类似 Move 的 Multi-Threaded 执行引擎集群架构。Más importante aún, lanzó innovativamente un nuevo modelo de programación PREDA, que puede ser el último rompecabezas alcanzado por la cadena de bloques paralela.
>







{kind=link}
{kind=link}