
Écriture: Preda Source: Chainfeeds
résumé
En regardant l’histoire parallèle de l’ordinateur: le parallélisme du premier niveau estNiveau d’instructions parallèleEssenceLe parallèle au niveau de l’instruction est le principal moyen d’améliorer les performances au cours des 20 dernières années du 20e siècle.Le parallélisme au niveau de l’instruction peut améliorer les performances sur la prémisse que le programme est compatible binaire, ce qui est particulièrement apprécié par les programmeurs.Il existe deux types d’instructions en parallèle.L’un est le temps parallèle, c’est-à-dire la chaîne de montage d’instructions.L’ordre de la chaîne de montage est comme la chaîne de montage de la production d’usine d’une voiture. , il produira plusieurs voitures en même temps dans plusieurs processus.L’autre est l’espace parallèle, c’est-à-dire plus de lancement ou de dépasser la norme.Le multi-lancement est comme une route multi-voies, et l’exécution hors service est autorisée à dépasser les multiples-voies.Après l’émergence de RISC dans les années 80, le niveau de développement parallèle de l’instruction de 20 ans a atteint un pic.
Le parallélisme du deuxième niveau estParallèle de niveau de données, Il fait principalement référence à la structure vectorielle du flux unique (SIMD).La première ligne parallèle au niveau des données est apparue sur ENIAC.La machine vectorielle représentée par Cray dans les années 1960 et 1970 était très populaire.Jusqu’à Cray-4, Simd est resté silencieux pendant un certain temps, et maintenant il a commencé à récupérer la vitalité, et il est de plus en plus utilisé.Par exemple, les instructions multimédias AVX dans X86 peuvent utiliser des canaux 256-bits pour effectuer quatre opérations 64-bits ou huit opérations à 32 bits.SIMD, en tant que supplément efficace d’instructions parallèles, a joué un rôle important dans le domaine de la diffusion en streaming.
Le troisième niveau de parallélisme estParallèle au niveau de la missionEssenceUn grand nombre de parallèles au niveau de la tâche se trouve dans l’application Internet.Le représentant du parallèle au niveau de la tâche est un processeur multi-ore et un processeur multi-thread, qui est la principale méthode pour l’architecture informatique actuelle afin d’améliorer les performances.La granularité parallèle du parallèle au niveau de la tâche est grande et un fil contient des centaines ou plus d’instructions.
Du point de vue du développement de l’informatique parallèle, ce qui est maintenant au premier niveau de la blockchain est le processus de transition du premier niveau au deuxième niveau.Le système de blockchain traditionnel adopte généralement deux architecture: l’architecture unique ou multi-chaînes.Chaîne unique, comme le bitcoin commun et Ethereum, l’ensemble du système n’a qu’une seule chaîne.Dans chaque nœud blockchain, les transactions de contrat intelligentes sont généralement exécutées en série, ce qui entraîne un faible débit de l’ensemble du système.
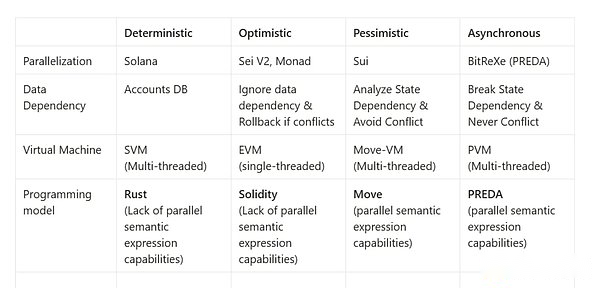
Certains des systèmes de blockchain hauts récent récent, bien que l’architecture à une seule chaîne soit adoptée, prend également en charge l’exécution parallèle des transactions de contrat intelligentes.Thomas Dickerson et Maurice Herlihy de Brown University et Yale University ont d’abord proposé un modèle d’exécution parallèle basé sur STM (Mémoire transactionnelle du logiciel) dans son article PODC’17. , il terminera le recul du statut via STM, puis effectuera ces transactions de conflit d’État sérialisées en série.De telles méthodes ont été appliquées à plusieurs projets de blockchain à haute performance, notamment les aptos, SEI et Monad.En conséquence, un autre modèle d’exécution parallèle est basé sur la concurrence pessimiste (parallèle pessimiste), c’est-à-dire avant que la transaction ne soit exécutée parallèle, il existe un conflit entre l’état d’accès des transactions. .Ce type de méthode utilise généralement une méthode de pré-comptation pour utiliser des outils d’analyse de programme pour effectuer une analyse statique et construire des dépendances d’état sur le code de contrat intelligent, tel que la direction du graphique non boucle (DAG).Lorsque la transaction simultanée est soumise au système, le système détermine si la transaction peut être exécutée parallèle en fonction de l’état des besoins de transaction et de la relation de dépendance entre les besoins de transaction.Seules les transactions qui n’ont aucune relation dépendante de l’état entre elles seront exécutées parallèles.Ce type de méthode est appliqué à Zilliqa (version Cosplit) et à des projets de blockchain haute performance tels que SUI.Les modèles d’exécution parallèle ci-dessus peuvent améliorer considérablement le débit du système.Ces deux schémas correspondent au niveau d’instruction mentionné ci-dessus parallèle.Cependant, il y a deux problèmes dans ces tâches: 1) des problèmes d’évolutivité et 2) des problèmes d’expression sémantique parallèle, nous expliquerons en détail ci-dessous.
Conception parallèle
Nous utiliserons le projet de Solana et Monad typique comme exemple pour démonter leur conception d’architecture parallèle.
Solana
À partir d’un niveau supérieur, le concept de conception de Solana est que l’innovation blockchain devrait se développer avec l’avancement du matériel.Avec l’amélioration continue du matériel selon la loi de Moore, Solana vise à bénéficier de performances et d’évolutivité plus élevées.Le co-fondateur de Solana, Anatoly Yakovenko, a initialement conçu l’architecture de parallélisation de Solana il y a plus de cinq ans.
Utilisation de SolanaParallélisme de la défense(Parallélisation déterministe), qui provient de l’expérience d’Anatoly dans l’utilisation des systèmes intégrés dans le passé, les développeurs déclarent généralement tous les états à l’avance.Cela permet au CPU de comprendre toutes les dépendances, afin de préfère la partie nécessaire de la mémoire.Le résultat est d’optimiser la mise en œuvre du système, mais la même chose oblige les développeurs à effectuer un travail supplémentaire à l’avance.Sur Solana, toutes les dépendances de mémoire du programme sont nécessaires et expliquent dans le constructeur (c’est-à-dire la liste d’accès), afin que l’exécution puisse régler et effectuer efficacement plusieurs transactions.
Le composant principal suivant de l’architecture Solana estVM de la mer,,Il prend en charge plusieurs contrats et transactions en parallèle en fonction de la quantité de base du dispositif de vérification.Les vérifications de la blockchain sont des participants au réseau, responsables de la vérification et de la confirmation des transactions, de la proposition de nouveaux blocs et de la maintenance de l’intégrité et de la sécurité de la blockchain.Étant donné que la transaction pré-states quels comptes doivent être lus, écrits et verrouillés, le programme de planification Solana peut déterminer quelles transactions peuvent être exécutées simultanément.Pour cette raison, pendant la vérification, les «producteurs de blocs» ou les dirigeants peuvent trier des milliers de transactions traitées et l’ajustement parallèle des transactions non chevauchantes.
Monade
Monad construit la première couche d’EVM parallèle avec un EVM parallèle complet.Le caractère unique de Monad réside non seulement son moteur parallèle, mais aussi le moteur d’optimisation qu’ils ont construit en arrière-plan.Monad utilise une méthode unique pour sa conception globale, combinant plusieurs fonctions clés, notamment des pipelines, des E / S asynchrones, du consensus de séparation et de l’exécution, et MonADDB.
Semblable à SEI, monad blockchain utilise« Optimisme et contrôle de passe (OCC) »Venez exécuter la transaction.Lorsque plusieurs transactions existent dans le système en même temps, des transactions simultanées se produisent.Il existe deux étapes de cette méthode de transaction: l’exécution et la vérification.
Pendant la phase d’exécution, les transactions sont optimistes et toute lecture / écriture est temporairement stockée dans un stockage spécifique de transactions.Depuis lors, chaque transaction entrera dans l’étape de vérification, qui sera modifiée pour vérifier les informations de l’opération de stockage temporaire en fonction de tout statut établi par le bureau précédent.Si la transaction est indépendante, la transaction s’exécute parallèle.Si une transaction lit les données d’une autre modification des transactions, un conflit sera généré.
Une innovation clé conçue par Monad est un rail avec un léger décalage.Ce décalage permet plus de processus en parallélisation en exécutant plusieurs instances en même temps.Par conséquent, la chaîne de montage est utilisée pour optimiser de nombreuses fonctions, telles que l’accès à l’état au pipeline, le pipeline d’exécution des transactions, le consensus et le pipeline et le pipelin dans le mécanisme de consensus lui-même. la garde-robe.
>
À Monad, les transactions sont triées en linéaire dans le bloc, mais l’objectif est d’atteindre l’état final en utilisant une exécution parallèle.MonadeOptimiste et parallélismeUn algorithme pour concevoir le moteur d’exécution.Le moteur de Monad gère la transaction en même temps, puis analyse pour s’assurer que si la transaction est exécutée les unes après les autres, les résultats seront les mêmes.S’il y a des conflits, vous devez vous réécrire.L’exécution parallèle ici est un algorithme relativement simple, mais il le combine avec d’autres innovations clés de Monad pour rendre cette méthode nouvelle.Une chose qui doit être notée ici est que même si la ré-exécution se produit, elle est généralement très bon marché, car l’entrée requise par les agences non valides conserve toujours le cache, donc ce sera une simple recherche de cache.Re -execution réussira car vous avez déjà exécuté les transactions précédentes.
En plus de retarder l’exécution,Monad améliore également les performances en séparant l’exécution et le consensusSimilaire à Solana et SEI.L’idée ici est que si vous détendez les conditions pour compléter l’exécution lorsque le consensus est terminé, les deux peuvent être exécutés parallèles pour apporter plus de temps aux deux.Bien sûr, Monad utilise un algorithme de certitude pour faire face à cette situation pour garantir que l’un d’eux ne fonctionnera pas trop loin et ne peut pas rattraper son retard.
Que ce soit des méthodes optimistes d’exécution parallèle ou pessimiste, les systèmes ci-dessus utilisent la mémoire partagée comme l’abstraction du modèle de données de couche inférieure, c’est-à-dire quelles que soient les unités parallèles, les unités parallèles peuvent obtenir toutes les données (se réfère ici à toutes les données Sur les données de blockchain), les données d’état peuvent être directement accessibles par différentes exécutions parallèles (c’est-à-dire que toutes les données sur toutes les chaînes peuvent être lues et écrire directement en parallèle).Utilisez la mémoire partagée comme système de blockchain comme modèle de données sous-jacent.
Ce type de méthode parallèle dans ce nœud n’a besoin que de modifier l’architecture de la couche exécutive du contrat intelligent, et n’a pas besoin de modifier la logique de la couche de consensus système, qui est très adaptée à l’amélioration du débit de la chaîne unique système.Par conséquent, car il n’y a pas de tranche de stockage de données,Chaque nœud du réseau blockchain doit encore exécuter toutes les transactions et stocker tous les étatsEssenceEn même temps, par rapport à l’architecture partagée qui est plus adaptée aux extensions distribuées, celles-ci utilisent la mémoire partagée comme abstraction du système abstrait du modèle de données sous-jacent. Les capacités d’exécution ne peuvent pas résoudre fondamentalement l’évolutivité de la blockchain.
Alors, y a-t-il une solution prête?
Modèle de programmation parallèle
Avant de présenter Preda, nous espérons poser une question naturelle ::Pourquoi utiliser la programmation parallèle?Dans une partie des années 1970, 1980, et même une partie des années 1990, nous étions très satisfaits de la programmation à thread unique (ou de la programmation en série).Vous pouvez rédiger un programme pour effectuer une tâche.Une fois l’exécution terminée, cela vous donnera un résultat.La tâche est terminée, tout le monde sera très heureux!Bien que la tâche ait été terminée, mais si vous faites des millions, voire des milliards de simulation de particules calculées par seconde, ou si vous êtes traité avec des milliers d’images de pixels, vous voudrez que le programme s’exécute plus rapidement, cela signifie que vous avez besoin d’un processeur plus rapide.
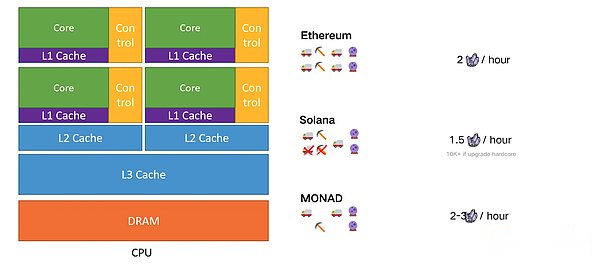
Avant 2004, le fabricant du CPU IBM, Intel et AMD peuvent vous fournir un processeur plus rapide et plus rapide. CPU.Mais en 2004, en raison de restrictions techniques, la tendance à l’augmentation de la vitesse du CPU ne peut pas se poursuivre.Cela nécessite d’autres technologies pour continuer à fournir des performances plus élevées.La solution du fabricant du processeur consiste à mettre les deux processeurs dans un processeur, même si les deux CPU de travail de la vitesse inférieure à un seul CPU.Par exemple, par rapport au processeur à ore à un seul niveau à la vitesse de 300 MHz, deux CPU (les fabricants les appellent le noyau) à 200 MHz peuvent effectuer plus de calculs par seconde (c’est-à-dire une intuition intuitive intuitive, un regard intuitif à 2 × 200 & gt; 300).
Cela ressemble à une histoire de rêve « CPU unique Multi -Core » devient réalité, ce qui signifie que les programmeurs doivent maintenant apprendre des méthodes de programmation parallèles pour utiliser ces deux cœurs.Si un CPU peut effectuer deux programmes en même temps, le programmeur doit écrire ces deux programmes.Mais cela peut-il être transformé en deux fois la vitesse d’exécution du programme?Sinon, l’idée de notre 2 × 200 & gt; 300 est problématique.Et si un noyau n’a pas assez de travail?En d’autres termes, un seul noyau est vraiment occupé, mais l’autre noyau ne fait rien?Dans ce cas, il est préférable d’utiliser un seul noyau de 300 MHz.Après l’introduction de multi-oreaux, de nombreux problèmes similaires sont très importants.
>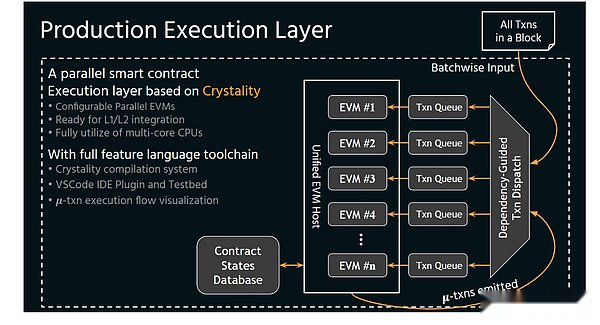
Dans la figure ci-dessous, nous imaginons Bob et Alice comme deux ruminnistes d’or, et la ruée vers l’or nécessite quatre étapes:
-
Conduire jusqu’à la mine
-
exploitation minière
-
Chargement du minerai
-
Magasin et poli
>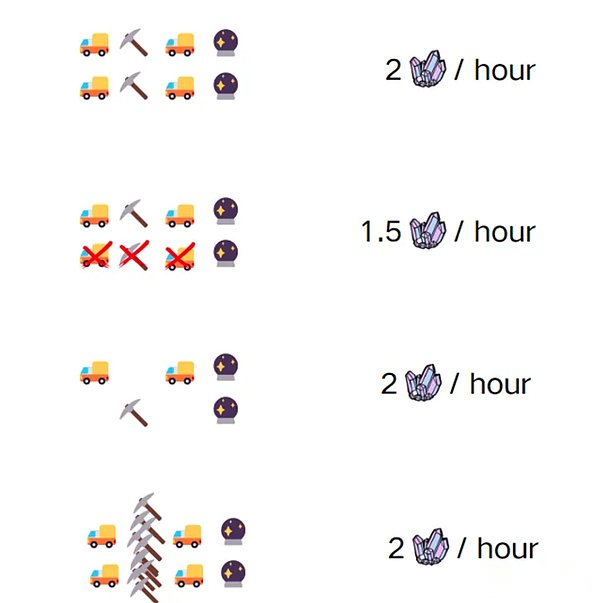
L’ensemble du processus d’extraction se compose de quatre tâches indépendantes mais ordonnées, et chaque tâche prend 15 minutes.Lorsque Bob et Alice se poursuivent en même temps, ils peuvent terminer deux fois la charge de travail minière en une heure – car ils ont leurs propres voitures, ils peuvent partager la route et ils peuvent partager l’outil de polissage.
Mais si un jour, le véhicule minier Bob échoue.Il a quitté la voiture minière dans l’atelier de réparation et a oublié le choix de fer de la voiture minière.Il était trop tard pour retourner dans l’usine de transformation, mais ils avaient toujours un travail à faire.Peuvent-ils utiliser le véhicule minier d’Alice et une poignée à l’intérieur, peuvent-ils encore choisir deux minerai par minute?
Dans l’analogie mentionnée ci-dessus, les quatre étapes de l’exploitation sont des threads et les voitures miniers sont de base (noyau); : Avant l’exécution du thread 1, vous ne pouvez pas exécuter le thread 2.Le nombre de minéraux récoltés signifie la performance du programme.Plus les performances sont élevées, plus les avantages de Bob et Alice sont élevés.Vous pouvez considérer la mine comme de la mémoire, et vous pouvez en obtenir une unité de données (mine d’or), afin que le processus de sélection d’un minerai dans le thread 1 soit similaire à la lecture des unités de données de la mémoire.
Maintenant, voyons ce qui se passera si le véhicule minier du bob échoue.Bob et Alice doivent partager une voiture, ce qui n’est pas un problème au début. Le nombre de minerai qui peut être envoyé au poli est restreint par « la voiture minière maximale peut accueillir des minéraux ».
Il s’agit également de la nature VM parallèle de Solana, partage de base.
Partage de base
L’élément de conception final de Solana est« Pipeline »EssenceLorsque les données doivent être traitées via une série d’étapes et que différents matériels sont responsables de chaque étape, le fonctionnement de la ligne de montage apparaît.L’idée clé ici est d’obtenir des données qui nécessitent un fonctionnement en série et d’utiliser le pipeline pour le rendre parallèle.Ces tuyaux peuvent fonctionner parallèles et chaque pipeline peut gérer différents lots de transaction.Plus la vitesse de traitement du matériel (capacité de chargement du véhicule minier) est élevée, plus la parallélisation est élevée.Aujourd’hui, le nœud matériel de Solana exige que ses opérateurs de nœud ne disposent qu’un seul centre de choix, qui apporte l’efficacité mais s’écarte de l’intention d’origine de la blockchain.
La dépendance aux données n’est pas divisée (partage de ressources de mémoire)
Après la mise à niveau du véhicule minier, car la capacité d’exploitation ne peut pas se poursuivre, plusieurs fois le véhicule minier n’est pas satisfait.Bob a donc dépensé un prix élevé pour acheter des machines d’exploitation, ce qui a amélioré l’efficacité de l’exploitation minière (mise à niveau de l’unité d’exécution).10 copies des minéraux peuvent être produites dans les 15 minutes, mais parce que le travail de broyage est toujours effectué à la main, le minerai généré par plus d’unités de temps n’a pas été converti en plus d’or, et plus de minerai est pressé par la compression. entrepôt; Cet exemple montre ce qui se passe lorsque l’accès à la mémoire est un facteur limité pour la vitesse d’exécution de notre programme.À quelle vitesse les données de traitement sont (c’est-à-dire la vitesse de fonctionnement centrale) n’est pas pertinente.Nous serons limités par la vitesse d’acquisition de données.
La vitesse d’E / S plus lente nous dérangera sérieusement, car les E / S sont la partie la plus lente de l’ordinateur, et la lecture asynchrone des données (E / S asynchrone) deviendra cruciale.
Même si Bob peut creuser 10 machines minières en 15 minutes, si la compétition d’accès à la mémoire existe, elles seront toujours limitées à 2 mines de 2 parties toutes les 15 minutes.Les schémas de blockchain parallèles existants sont divisés en deux factions – exécution sensible et exécution optimiste de la solution proposée par ce problème.
Le premier nécessite la dépendance de l’état des données avant la rédaction et la lecture des données.Ce dernier ne fait aucune hypothèse et restrictions sur la rédaction de données.
Échantillonné par le plan d’exécution optimiste de Monad: la réalité est que la plupart de la charge de travail est l’exécution des transactions, et les scènes qui se produisent en parallèle ne sont pas comme prévu.L’image ci-dessous est le type de source de consommation de frais de gaz d’Ethereum;La logique parallèle de l’exécution optimiste est réalisable dans l’ère web2, car une grande partie des demandes d’application Web2 est un accès, pas une modification;Cependant, le champ Web3 est le contraire.
>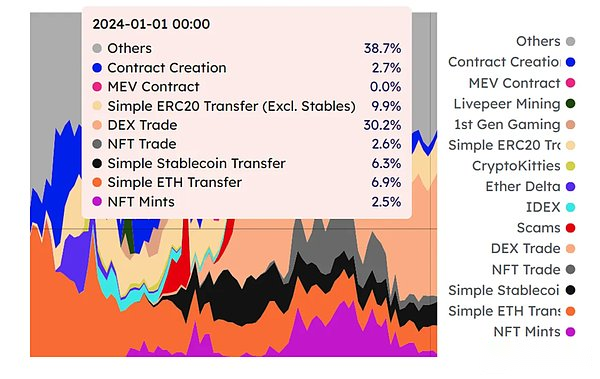
La conclusion est donc que Monad peut effectivement atteindre parallèle, maisLa concurrence existe dans la limite théorique, c’est-à-dire qu’elle tombe dans l’intervalle de 2 à 3 fois, Pas le 100k de sa propagande.Deuxièmement, il n’y a aucun moyen d’élargir cette limite supérieure en augmentant la machine virtuelle, c’est-à-dire qu’il n’y a aucun moyen d’atteindre l’équivalent multi-core pour augmenter la capacité de traitement.Enfin, c’est un problème qui parle toujours, car il n’y a pas de données de tranchage, Monad ne répond pas réellement aux exigences du nœud après l’expansion de l’expansion de l’État. Peut inévitablement voir le chemin de Monad à Solana.En fin de compte, le point le plus important est que la mise en œuvre optimiste ne convient pas au parallèle dans le champ Blockchain.
>
Après l’exploitation minière pendant un certain temps, Bob s’est posé une question: « Pourquoi devrais-je attendre que Alice revienne puis polir? Quand il est poli, je peux charger la voiture, car le temps de chargement et de polissage est exactement le même, Nous ne devons pas le rencontrer.L’important est que le bob a repensé le programme, c’est-à-dire l’ordre de l’exécution des fils, afin que tous les fils ne tombent jamais dans l’état d’attendre les ressources de partage de base (comme les voitures miniers et les choix de pierre).
Il s’agit de la bonne version de parallèle. .
Le modèle PredA est exposé à la couche d’exécution en exposant la structure d’accès du code du contrat au moment du code du contrat, afin que la couche d’exécution puisse facilement planifier et éviter complètement le recul des résultats.Ce mode parallèle est également appelé asynchrone.
Asynchrone
>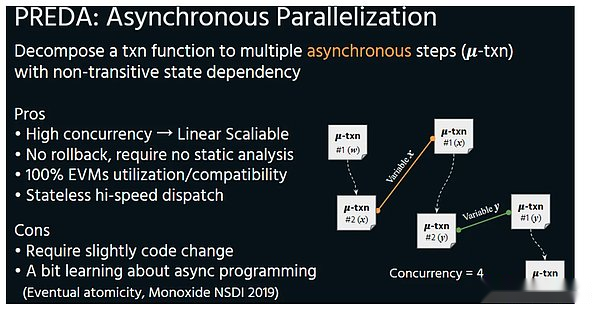
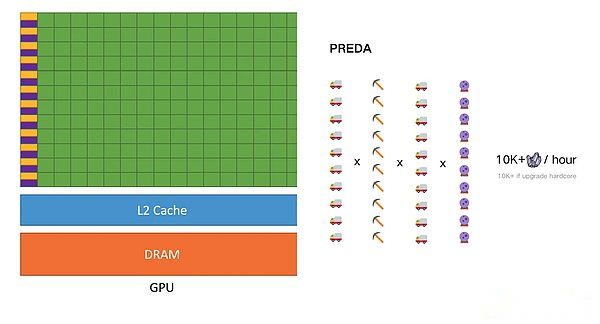
Parce que ce n’est qu’en parallèle est asynchrone, l’augmentation des threads arrivera à l’amélioration linéaire.Au lieu de mettre à niveau la capacité du véhicule minier comme l’exemple précédent, mais le véhicule minier est vide en raison de l’équipement minière vers l’arrière.L’environnement d’exécution parallèle de Preda a la différence la plus essentielle entre Solana – Tout comme la différence entre le processeur multi-ore et le GPU, l’efficacité de traitement de son noyau de partage ne sera pas un goulot d’étranglement de parallélisme, ni lorsqu’il n’existe pas lorsque les I / S se lit et écrire la dépendance aux données, et plus important encore, le parallélisme du modèle parallèle de Porta augmentera en raison de l’augmentation des threads, qui est le même que le GPU.Dans la logique de la blockchain, l’augmentation du thread (VM) réduira la demande matérielle de l’ensemble du nœud, réalisant ainsi l’amélioration des performances sous la prémisse d’assurer la décentralisation.
>
>
En fin de compte, la fin de cette blockchain parallèle.
Expression sémantique du langage de programmation parallèle
Tout comme Nvidia nécessite CUDA, et la blockchain parallèle a également besoin de nouveaux langages de programmation: Preda.Les développeurs des contrats intelligents d’aujourd’hui sont exprimés en sémantique parallèle, qui ne peut pas utiliser efficacement le support fourni par l’architecture multi-chaîne sous-jacente (rayonnement de données ou exécution des éclats ou les deux), et ne peut pas atteindre le parallèle efficace parallèle des transactions de contrat intelligentes générales.Tous les systèmes utilisent des langages de programmation de contrats intelligents communs traditionnels tels que Solidity, Move, Rust.Ces langages de programmation n’ont pas la capacité de l’expression sémantique parallèle, c’est-à-dire n’ont pas la capacité de contrôler et le flux de données entre les modèles de programmation parallèle et l’expression du langage de programmation comme CUDA ou des modèles de programmation parallèle dans le domaine de l’informatique haute performance ou de Big champs de données comme CUDA.
L’absence de modèles de programmation parallèle et de langages de programmation adaptés aux contrats intelligents entraînera l’application et l’algorithme de série à la restructuration parallèle ne peut pas être terminée. Améliorer l’efficacité de mise en œuvre des applications et le débit global du système de blockchain.
Ce modèle de programmation distribué proposé par Preda, grâce à la portée d’un contrat programmatique, effectue une division de la granularité fine du statut du contrat et distribue la décomposition du flux d’exécution des transactions par le délai de relais fonctionnel via le relais fonctionnel du relais.
Ce modèle définit également le schéma de division de l’état du contrat via la portée du contrat programmatique, permet aux développeurs d’optimiser en fonction du mode d’accès à l’application de l’application.Grâce à un relais fonctionnel asynchrone, le flux d’exécution des transactions peut être déplacé vers le moteur d’exécution qui doit être accessible et le mouvement du processus d’exécution est déplacé au lieu du mouvement des données.
Ce modèle réalise la division distribuée du statut du contrat et le partage du flux de transactions sans avoir besoin que les développeurs se soucient des détails du système multi-chaîne sous-jacent.Les résultats expérimentaux montrent que le modèle PredA sur le moteur d’exécution 256 peut atteindre un maximum de 18 fois le débit, qui est proche de la limite parallèle théorique.Grâce à l’utilisation du compteur de partition et des instructions d’échange, améliore encore le parallélisme.
Conclusion
Le système de blockchain utilise traditionnellement un moteur d’exécution d’ordre unique (tel que EVM) pour gérer toutes les transactions, limitant ainsi l’évolutivité.Le système multi-chaîne exécute un moteur d’exécution parallèle, mais chaque moteur gère toutes les transactions de contrats intelligents et ne peut pas atteindre l’évolutivité au niveau du contrat.Cet article traite du partage de base essentiel du parallélisme permanent représenté par Solana, et pourquoi est-il possible pour l’optimisme et le comportement représentés par Monad de s’exécuter et d’ampli dans le scénario d’application de la blockchain réel.Et a introduit le moteur d’exécution parallèle de Preda.L’équipe Preda a proposé un nouveau modèle de programmation qui étend un seul contrat intelligent en divisant l’état des contrats intelligents et en allouant les flux de transactions à travers le moteur.Il introduit la portée des contrats programmables pour définir la division du statut de contrat.Chaque portée fonctionne sur un moteur d’exécution dédié.Le relais fonctionnel asynchrone est utilisé pour décomposer les flux d’exécution des transactions et le déplace à travers le moteur lorsque vous séjournez ailleurs.
>
Cela combine la logique des transactions avec la partition d’état du contrat, qui permet un parallélisme inhérent sans frais de surcharge de données.Son modèle parallèle a divisé le statut non seulement au contrat intelligent, a découplé la dépendance du niveau de libération de données, mais fournit également une architecture de cluster d’exécution multi-threads multiples.Plus important encore, il a lancé de manière innovante un nouveau modèle de programmation Preda, qui peut être le dernier puzzle atteint par le parallèle de la blockchain.
>







{kind=link}
{kind=link}