
撰文:PREDA 來源:chainfeeds
摘要
縱觀計算機的並行史:第一個層次的並行性是 指令級並行 。指令級並行是 20 世紀最後 20 年體系結構提升性能的主要途徑。指令級並行性可以在保持程序二進位兼容的前提下提高性能,這一點是程式設計師特別喜歡的。指令級並行分成兩種。一種是時間並行,即指令流水線。指令流水線就像工廠生產汽車的流水線一樣,汽車生產工廠不會等一輛汽車都裝好以後再開始下一輛汽車的生產,而是在多道工序上同時生產多輛汽車。另一種是空間並行,即多發射,或者叫超標量。多發射就像多車道的馬路,而亂序執行(Out-of-Order Execution)就是允許在多車道上超車,超標量和亂序執行常常一起使用來提高效率。在 20 世紀 80 年代 RISC 出現後,隨後的 20 年指令級並行的開發達到了一個頂峰,2010 年後進一步挖掘指令級並行的空間已經不大。
第二個層次的並行性是 數據級並行 ,主要指單指令流多數據流(SIMD)的向量結構。最早的數據級並行出現在 ENIAC 上。20 世紀六七十年代以 Cray 為代表的向量機十分流行,從 Cray-1、Cray-2,到後來的 Cray X-MP、Cray Y-MP。直到 Cray-4 後, SIMD 沉寂了一段時間,現在又開始恢復活力,而且用得越來越多。例如 X86 中的 AVX 多媒體指令可以用 256 位通路做四個 64 位的運算或八個 32 位的運算。SIMD 作為指令級並行的有效補充,在流媒體領域發揮了重要的作用,早期主要用在專用處理器中,現在已經成為通用處理器的標配。
第三個層次的並行性是 任務級並行 。任務級並行大量存在於 Internet 應用中。任務級並行的代表是多核處理器以及多線程處理器,是目前計算機體系結構提高性能的主要方法。任務級並行的並行粒度較大,一個線程中包含幾百條或者更多的指令。
從並行計算發展的角度上來看,如今區塊鏈所處的正是第一層次向第二層次轉變的過程。主流區塊鏈系統通常採用單鏈或者多鏈兩種架構。單鏈,比如常見的 Bitcoin 和 Ethereum,整個系統只有一條鏈,鏈的每個節點執行完全相同的智能合約交易,維護完全一致的鏈上狀態。每一個區塊鏈節點內,智能合約交易通常採用串行執行,導致整個系統的吞吐率低。
最近出現的一些高性能區塊鏈系統,雖然採用了單鏈架構,但同時也支持智能合約交易的並行執行。布朗大學和耶魯大學的 Thomas Dickerson 和 Maurice Herlihy 等人在其 PODC』17 的論文中首先提出了基於 STM(Software Transactional Memory)方法的並行執行模型,該方法通過 optimistic parallelism(樂觀並行)的方式將多條交易並行執行,如果交易在並行執行過程中遇到了狀態訪問衝突的問題,則通過 STM 去完成狀態的回滾,然後再串行執行這些有狀態衝突的交易。這類方法被應用到了多個高性能區塊鏈項目當中,包括 Aptos、Sei 及 Monad 等等。與之對應,另一種並行執行模型基於 pessimistic concurrency(悲觀並行)的方式,即交易被並行執行之前,需要檢測交易訪問的狀態是否存在衝突,只有不存在衝突的交易才能夠被並行執行。這類方法通常採用預先計算(pre-compute)的方式,利用程序分析工具對智能合約代碼做靜態分析並構建狀態依賴關係,比如有向無環圖(DAG)。當並發交易提交到系統以後,系統根據交易需要訪問的狀態以及狀態之間的依賴關係來判斷交易是否可以並行執行。只有相互之間沒有狀態依賴關係的交易才會被並行執行。該類方法被應用到了 Zilliqa(CoSplit 版本),Sui 等高性能區塊鏈項目當中。上述的並行執行模型,都可以顯著提升系統的吞吐率。這兩種方案對應的是上文提到的指令級別並行。但是,這些工作存在兩個問題:1)可擴展性問題和 2)並行語義表達問題,我們將在下文詳細闡述。
Parallel Design
我們將使用典型的 Solana,Monad 項目的技術方案舉例,拆解他們的並行架構設計,這包括並行化分類,數據依賴性等等會影響並行度和 TPS 的關鍵指標。
Solana
從較高的層面來看,Solana 的設計理念是區塊鏈創新應該隨著硬體的進步而發展。隨著硬體根據摩爾定律不斷改進,Solana 旨在從更高的性能和可擴展性中受益。 Solana 聯合創始人 Anatoly Yakovenko 在五年多前最初設計了 Solana 的並行化架構,如今,並行性作為區塊鏈設計原則正在迅速傳播。
Solana 使用 確定性並行化 (Deterministic Parallelization), 這來自 Anatoly 過去使用嵌入式系統的經驗,開發者通常會預先聲明所有狀態。這使得 CPU 能夠了解所有依賴關係,從而能夠預取內存的必要部分。結果是優化了系統執行,但同樣,它需要開發人員預先做額外的工作。在 Solana 上,程序的所有內存依賴項都是必需的,並在構造的事務(即訪問列表)中進行說明,從而使運行時能夠高效地並行調度和執行多個事務。
Solana 架構的下一個主要組件是 Sealevel VM , 其支持根據驗證器擁有的核心數量並行處理多個合約和交易。 區塊鏈中的驗證者是網絡參與者,負責驗證和確認交易、提出新區塊以及維護區塊鏈的完整性和安全性。由於事務預先聲明哪些帳戶需要讀寫鎖定,因此 Solana 調度程序能夠確定哪些事務可以並發執行。正因為如此,在驗證時,「區塊生產者」或領導者能夠對數千個待處理交易進行排序,並並行調度非重疊交易。
Monad
Monad 正在構建具有圖靈完備的並行 EVM 第 1 層。 Monad 的獨特之處不僅在於它的並行化引擎,還在於他們在後臺構建的優化引擎。 Monad 對其整體設計採用了獨特的方法,融合了幾個關鍵功能,包括管道、異步 I/O、分離共識和執行以及 MonadDB。
與 Sei 類似,Monad 區塊鏈使用 「樂觀並發控制(OCC)」 來執行交易。當多個事務同時存在於系統中時,就會發生並發事務處理。該交易方法有兩個階段:執行和驗證。
在執行階段,事務被樂觀地處理,所有讀/寫都臨時存儲在事務特定的存儲中。此後,每個事務都將進入驗證階段,其中將根據先前事務所做的任何狀態更改檢查臨時存儲操作中的信息。如果事務是獨立的,則事務並行運行。如果一個事務讀取另一個事務修改的數據,就會產生衝突。
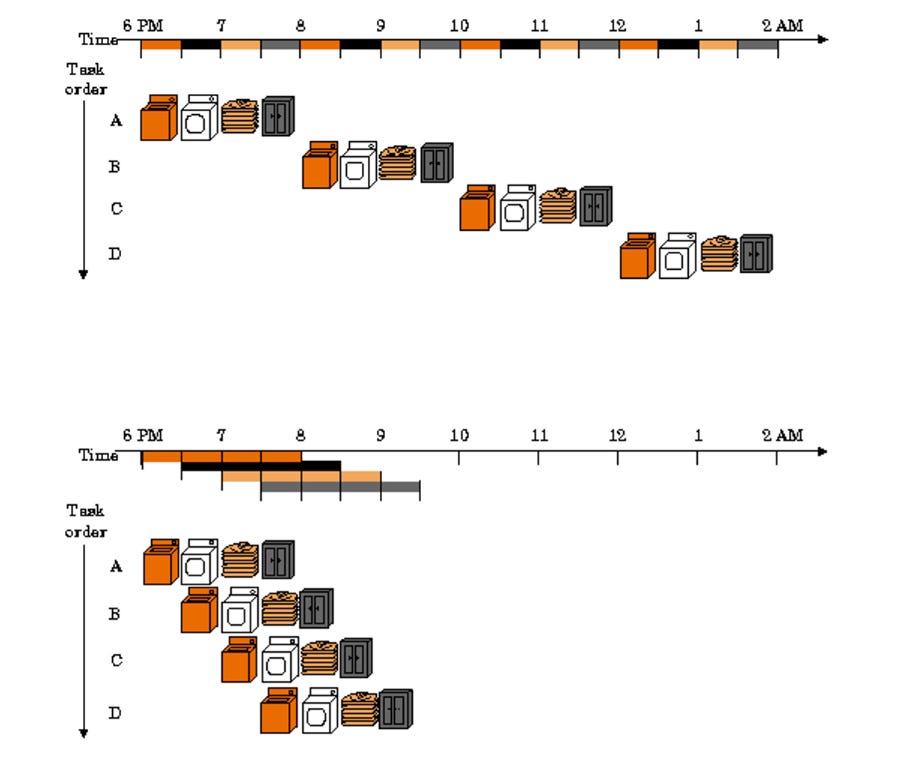
Monad 設計的一個關鍵創新是帶有輕微偏移的流水線。該偏移量允許通過同時運行多個實例來並行化更多進程。因此,流水線用於優化許多功能,例如狀態訪問 Pipeline、交易執行 Pipeline、共識和執行內的 Pipeline 以及共識機制本身的 Pipelin,在下圖對應的則是洗衣,烘乾,疊衣服和放進衣櫃。

Monad 中,事務在塊內線性排序,但目標是通過利用並行執行更快地達到最終狀態。 Monad 使用 樂觀並行化 算法來設計執行引擎。 Monad 的引擎同時處理交易,然後進行分析,以確保如果交易相繼執行,結果將是相同的。如果有衝突,需要重新執行。這裡的並行執行是一個相對簡單的算法,但將其與 Monad 的其他關鍵創新相結合,使得這種方法變得新穎。這裡需要注意的一件事是,即使發生重新執行,它通常也很便宜,因為無效事務所需的輸入幾乎總是保留在緩存中,因此這將是一個簡單的緩存查找。重新執行一定會成功,因為您已經執行了塊中之前的交易。
除了延遲執行之外, Monad 還通過分離執行和共識來提高性能 ,類似於 Solana 和 Sei。這裡的想法是,如果您放寬在共識完成時完成執行的條件,則可以並行運行兩者,從而為兩者帶來額外的時間。當然,Monad 使用確定性算法來處理這種情況,以確保其中一個不會跑得太遠而無法趕上。
不論採用樂觀並行還是悲觀並行的執行方式,上述系統都採用 shared-memory 作為底層數據模型抽象,即不管有多少並行單元,並行單元都可以獲取所有的數據(這裡指區塊鏈的所有鏈上數據),狀態數據可以被不同的並行執行單元直接訪問(即所有鏈上數據都可以被並行單元直接讀寫)。採用 shared-memory 作為底層數據模型的區塊鏈系統,它的並發通常局限於單個物理節點(Solana),每一個物理節點的並發能力又受限於節點的計算能力,即物理線程的數量(假定每個線程支持一個虛擬機)。
這種節點內並行的方式只需要修改智能合約執行層的架構,不需要修改系統共識層的邏輯,從而非常適用於提升單鏈系統的吞吐率。因此,由於沒有對數據存儲進行分片, 區塊鏈網絡中的每一個節點仍舊需要執行所有的交易並存儲所有的狀態 。同時,相比於更適用於分布式擴展的 shared-nothing 架構,這些採用 shared-memory 作為底層數據模型抽象的系統,它們的處理能力無法做到水平擴展,即可通過增加物理機器的數量來實現系統狀態存儲以及執行能力的擴容,從而無法從根本上解決區塊鏈的可擴展性問題。
那麼是否有現成的解決方案呢?
Parallel Programming Model
在介紹 PREDA 之前,我們希望提出一個自然而然的問題是: 為什麼要用並行編程? 在 20 世紀 70 年代、80 年代甚至 90 年代的一部分時間裡,我們對單線程編程(或者稱為串行編程)非常滿意。你可以編寫一個程序來完成一項任務。執行結束後,它會給你一個結果。任務完成,每個人都會很開心!雖然任務已經完成,但是如果你正在做一個每秒需要數百萬甚至數十億次計算的粒子模擬,或者正在對具有成千上萬像素的圖像進行處理,你會希望程序運行得更快一些,這意味著你需要更快的 CPU。
在 2004 年以前,CPU 製造商 IBM、英特爾和 AMD 都可以為你提供越來越快的處理器,處理器時鐘頻率從 16 MHz、20 MHz、66 MHz、100 MHz,逐漸提高到 200 MHz、333 MHz、466 MHz⋯⋯看起來它們可以不斷地提高 CPU 的速度,也就是可以不斷地提高 CPU 的性能。但到 2004 年時,由於技術限制,CPU 速度的提高不能持續下去的趨勢已經很明顯了。這就需要其他技術來繼續提供更高的性能。CPU 製造商的解決方案是將兩個 CPU 放在一個 CPU 內,即使這兩個 CPU 的工作速度都低於單個 CPU。例如,與工作在 300 MHz 速度上的單核 CPU 相比,以 200 MHz 速度工作的兩個 CPU(製造商稱它們為核心)加在一起每秒可以執行更多的計算(也就是說,直觀上看 2×200 > 300)。
聽上去像夢一樣的「單 CPU 多核心」的故事變成了現實,這意味著程式設計師現在必須學習並行編程方法來利用這兩個核心。如果一個 CPU 可以同時執行兩個程序,那麼程式設計師必須編寫這兩個程序。但是,這可以轉化為兩倍的程序運行速度嗎?如果不能,那我們的 2×200 > 300 的想法是有問題的。如果一個核心沒有足夠的工作會怎麼樣?也就是說,只有一個核心是真正忙碌的,而另一個核心卻什麼都不做?這樣的話,還不如用一個 300 MHz 的單核。引入多核後,許多類似的問題就非常突出了,只有通過編程才能高效地利用這些核心。

在下圖我們將Bob和Alice想像成兩個淘金者,而淘金需要四個步驟:
-
開車去礦場
-
採礦
-
裝載礦石
-
儲存並拋光

整個採礦過程由四個獨立但有序的任務組成,每個任務需要 15 分鐘。當 Bob 和 Alice 同時進行時,他們可以在 1 個小時內完成兩倍的採礦工作量 —— 因為他們有自己的車,也可以共享道路,還可以分享打磨工具。
但是如果有一天,Bob 的採礦車發生了故障。他把採礦車留在修理廠,並把採礦的鐵鎬忘在了採礦車裡內。回到加工廠的時候已經太遲了,但他們仍然有工作要做。只使用 Alice 的採礦車和裡面的 1 把鐵鎬,他們還能每分鐘採到兩份礦石嗎?
在上述的類比中,採礦的四個步驟就是線程,採礦車就是核心 (Core);礦則是智能合約需要執行的數據單元;鐵鎬則是執行單元;該程序由兩個互相依賴的線程組成:在線程 1 執行結束之前,你無法執行線程 2。收穫的礦產數量意味著程序性能。性能越高,Bob 和 Alice 掘金的收益就越高。可以將礦場看作內存,你可以從中獲得一個數據單元(金礦),這樣在線程 1 中摘取一顆礦石的過程就類似於從內存中讀取數據單元。
現在,讓我們看看如果 Bob 的採礦車發生故障後會發生什麼。Bob 和 Alice 需要共用一輛車,這在最初並沒有什麼問題,而在保證採礦效率的前提下,採礦設備升級了以後,事情就變得不一樣了;採礦可以裝下礦石的數量就變成了整體效率的瓶頸,因為不管使用的採礦機器效率有多高,可以被送到打磨加工的礦石數量被 「礦車最大可容納礦產」所制約。
這也是 Solana 的並行 VM 本質,核心共享。
核心共享
Solana 的最終設計元素是 「管道化」 。當數據需要通過一系列步驟進行處理並且不同的硬體負責每個步驟時,就會出現流水線操作。這裡的關鍵思想是獲取需要串行運行的數據並使用管道將其並行化。這些管道可以並行運行,每個管道階段可以處理不同的事務批次。硬體(採礦車裝載能力)的處理速度越高,並行化的 Throughout 就越高。如今,Solana 的硬體節點要求已經使得其節點運營商只有一種選擇 —— 數據中心,這帶來了效率但是背離了區塊鏈的初衷。
數據依賴性未拆分(內存資源共享)
在升級了採礦車以後,因為挖礦產能跟不上,導致很多時候採礦車裝不滿。於是 Bob 又花高價採購了採礦機,提高了採礦的效率(執行單元升級)。同樣的 15 分鐘之內可以產出 10 份礦產了,但是因為礦石打磨工作還是像之前由手工完成,更多單位時間產生的礦石並沒有辦法轉化成更多的金子,更多的礦石被擠壓在了倉庫;這個例子展示了當訪問內存是我們程序執行速度的限制因素時會發生什麼。處理數據的速度有多快(即核心運行速度)已無關緊要。我們將受到數據獲取速度的限制。
較慢的 I/O 速度會嚴重困擾我們,因為 I/O 是計算機中速度最慢的部分,數據的異步讀取(Asynchronous I/O)將變得至關重要。
即使 Bob 一把可以在 15 分鐘內挖到 10 份礦產的採礦機,但如果存在內存訪問競爭,他們仍然會被限制為每 15 分鐘 2 份礦產。現有的並行區塊鏈方案對該問題提出的解決方案分為兩派 —— 悲觀執行和樂觀執行。
其中前者要求在數據寫入和讀取前要清楚地定義數據狀態的依賴,這要求開發人員做預先的靜態控制依賴假設,而在智能合約編程領域,這些假設往往都偏離了現實情況。後者對寫入數據不做任何的假設和限制,如果發生了衝突則回滾。
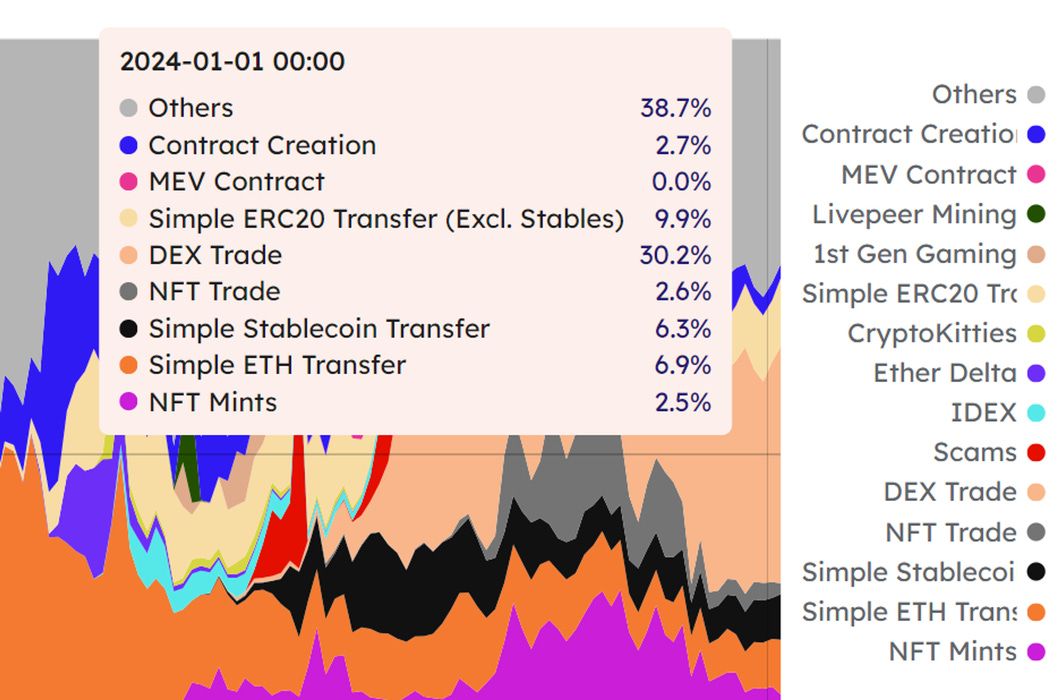
以 Monad 的樂觀執行方案舉例:現實情況是大部分的工作量是交易執行,並行發生的場景並沒有想像的那麼多。下圖是以太坊一天的 Gas Fee 消耗來源類型;你會發現,雖然這個分布沒有流行的智能合約佔比那麼高,但是其實不同類型的交易類型確實存在分布沒有那麼均勻的情況。而樂觀執行的並行邏輯在 Web2 時代是可行的,因為 Web2 應用的請求有很大一部分都是訪問,而不是修改;比如淘寶和抖音,你其實沒有太多機會去修改這些 APP 的狀態。但是 Web3 領域則恰恰相反,大部分智能合約的請求恰恰就是修改狀態 —— 更新帳本,實際上這會帶來預期之外更多的回滾,使得鏈不可用。

所以結論是 Monad 確實可以達到並行,但是 並行度(Concurrency)存在理論上限,也就是落在 2 倍至 3 倍的區間 ,而不是其宣傳的 100K。其次,這一上限沒有辦法通過增加虛擬機的方式進行擴容,也就是沒有辦法達到多核等於增加處理能力。最後也是老生常談的問題,因為沒有對數據進行分片,Monad 其實沒有回答鏈上狀態膨脹後帶來的對節點的要求,以下是其對節點的要求,這已經超過了一個家庭電腦可以承載的極限,而隨著其主網上線,如果不對數據進行分片,我們也許不可避免地看到 Monad 走向Solana的道路。而最後也是最重要的一點,樂觀執行不適合區塊鏈領域的並行。

採礦一段時間後,Bob 問了自己一個問題:「為什麼我要等 Alice 回來以後再進行打磨?當他打磨時,我可以裝車子,因為裝車和打磨需要的時間完全相同,我們肯定不會遇到需要等待打磨空閒的狀態。在 Alice 完成採礦之前,我會開車繼續去挖礦,這樣我們倆都可以是 100% 的忙碌。」」這個天才的想法讓他們重新回到兩倍的效率,甚至不需要額外的採礦車。重要的是,Bob 重新設計了程序,也就是線程執行的順序,讓所有的線程永遠都不會陷入等待核心內部共享資源(比如採礦車及石鎬)的狀態。
這才是並行的正確版本,通過對智能合約的狀態拆分,使得訪問共享資源既不會導致某個線程進入排隊,也不會因為數據 I/O 的 Pipeline 限制最終原子性達成的速度。
PREDA 模型通過將合約代碼執行時刻對合約狀態的訪問結構暴露給執行層,使得執行層可以輕易合理調度,完全避免執行結果的回滾。這種並行模式又稱異步並行。
異步並行

因為只有並行是異步的,增加線程才會到來線性的提升。而不會像前面的例子一樣,升級了採礦車的容量但是因為採礦設備落後導致採礦車空跑。PREDA 的並行執行環境與 Moand,Solana 有最本質的區別 —— 就像多核 CPU 和 GPU 的區別一樣,其共享核心的處理效率並不會是並行度的瓶頸,也不存在 I/O 讀寫時數據依賴性的問題,而更重要的是,PREDA 的並行模型的並行度會因為線程的增加而增加,與 GPU 有異曲同工之處。在區塊鏈的邏輯中,線程的增加(VM)會降低全節點的硬體需求,從而達到在保證去中心化的前提下提升性能。


最後達到這一併行區塊鏈的終局,行業內缺乏的除了是架構設計,還缺乏並行程式語言的語義表達。
並行程式語言的語義表達
就像 Nvidia 需要 CUDA,並行區塊鏈也需要新的程式語言:PREDA。如今的智能合約的開發者並行語義進行表達,無法有效利用底層多鏈架構提供的支持(數據分片或執行分片或者兼而有之),無法實現通用智能合約交易的有效並行。所有系統在程式語言方面採用的都是 Solidity、Move、Rust 等傳統的常見的智能合約程式語言。這些程式語言缺少並行語義表達能力,即,不具備類似於CUDA這樣高性能計算或者大數據領域的並行編程模型和程式語言表達並行單元之間控制流與數據流的能力。
缺少適用於智能合約的並行編程模型及程式語言,會導致應用與算法從串行到並行的重構無法完成,導致應用與算法無法與底層具有並行執行能力的區塊鏈系統適配,從而不能提高應用的執行效率以及區塊鏈系統的整體吞吐率。
PREDA 提出的這一種分布式編程模型,通過程序化合約作用域對合約狀態進行細粒度劃分,並通過功能中繼語義(Functional Relay) 將交易執行流分解後分布在多個並行執行引擎上執行。
該模型還通過程序化合約作用域(Programmable Scope)定義合約狀態的劃分方案,允許開發者根據應用的訪問模式進行優化。通過異步功能中繼,可以將交易執行流移動到需要訪問狀態的執行引擎上繼續,實現了執行流程的移動而非數據的移動。
這種模型實現了合約狀態的分布式劃分和交易流量的分擔,而不需要開發者關心底層多鏈系統的細節。實驗結果表明,在 256 個執行引擎上 PREDA 模型可實現最高 18 倍的吞吐量提升,接近理論上的並行極限。通過使用分區計數器和可交換指令等技術,進一步提升了並行度。
Conclusion
區塊鏈系統傳統上使用單個順序執行引擎(例如 EVM)來處理所有交易,從而限制了可擴展性。多鏈系統運行並行執行引擎,但每個引擎都處理智能合約的所有交易,無法在合約級別實現可擴展性。本篇文章論述了以 Solana 為代表的確定性並行的本質核心共享,以及以 Monad 為代表的樂觀並行為何無法在真實的區塊鏈應用場景中穩定運行 & 面臨的高頻率回滾的可能。並介紹了 PREDA 的並行執行引擎。PREDA 團隊提出了一種新穎的編程模型,通過劃分智能合約的狀態並跨執行引擎分配交易流量來擴展單個智能合約。它引入了可編程合約範圍來定義合約狀態的劃分方式。每個作用域都在專用的執行引擎上運行。異步功能中繼(Asynchronous Functional Relay)用於分解事務執行流,並在所需狀態駐留在其他地方時將其跨執行引擎移動。

這將事務邏輯與合約狀態分區解耦,從而允許固有的並行性而無需數據移動開銷。其並行模型既在智能合約層面拆分了狀態,解耦了數據發布層面的依賴性,也提供了類似 Move 的 Multi-Threaded 執行引擎集群架構。更重要的是,其創新地推出了新的編程模型 PREDA,這也許會是區塊鏈並行達成的最後一塊拼圖。








{kind=link}
{kind=link}