
ライティング:Preda出典:ChainFeeds
まとめ
コンピューターの並列履歴を見る:最初のレベルの並列性は命令レベルの平行エッセンス指導レベルの並列は、20世紀の過去20年間のパフォーマンスを改善する主な方法です。命令レベルの並列性は、プログラムがバイナリ互換であるという前提でのパフォーマンスを向上させることができます。並行して2種類の指示があります。1つは、類似点、つまり命令アセンブリラインです。組み立てラインは、車の生産が自動車の生産を待っているのを待っています、複数のプロセスで複数の車を同時に生産します。もう1つは、スペースの平行、つまり、より多くの起動、または標準を超えることです。マルチラーンは、マルチレーンの道路のようなものであり、オーダーの実行は、過剰な量を追い越すことができます。1980年代にRISCが出現した後、その後の20年間の命令レベルの並列開発は、2010年以降、さらにタッピングするためのスペースが大きくなりました。
第2レベルの並列性はですデータ – レベルの並列、それは主に単一のストリーム(SIMD)のベクトル構造を指します。初期のデータレベルの平行線がENIACに表示されました。1960年代と1970年代にクレイに代表されるベクトルマシンは、Cray-1、Cray-2からCray Y-MPまで非常に人気がありました。Cray-4まで、Simdはしばらく沈黙していましたが、今では再び活力を回復し始め、ますます使用されました。たとえば、X86のAVXマルチメディア命令は256ビットチャネルを使用して、4つの64ビット操作または8つの32ビット操作を作成できます。SIMDは、並行指示の効果的なサプリメントとして、ストリーミングメディアの分野で重要な役割を果たしてきました。
並列処理の第3レベルはですミッションレベルの平行エッセンスインターネットアプリケーションには、多数のタスクレベルの並列があります。タスクレベルのパラレルの代表は、マルチコアプロセッサとマルチスレッドプロセッサであり、パフォーマンスを改善するための現在のコンピューターアーキテクチャの主な方法です。タスクレベルの平行の並列粒度は大きく、スレッドには数百以上の命令が含まれています。
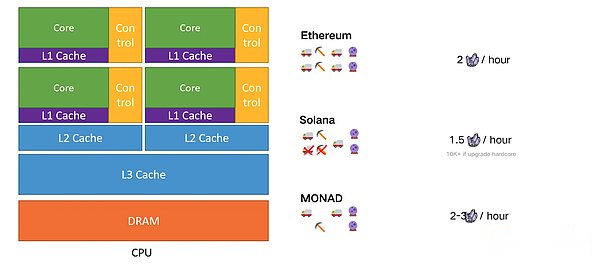
並列コンピューティング開発の観点から見ると、現在ブロックチェーンの最初のレベルにあるのは、第1レベルから第2レベルへの移行プロセスです。主流のブロックチェーンシステムは、通常、シングルまたはマルチチェーンアーキテクチャの2つのアーキテクチャを採用しています。一般的なビットコインやイーサリアムなど、システム全体には、完全に一貫したチェーン状態を維持するために、チェーンの各ノードがまったく同じスマートコントラクトトランザクションを実行します。各ブロックチェーンノードでは、スマートコントラクトトランザクションは通常、シリアル実行中に実行され、システム全体のスループットが低くなります。
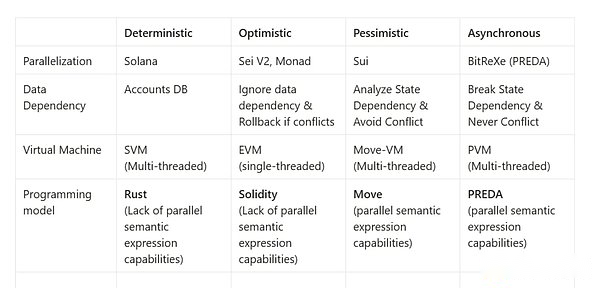
最近の高性能ブロックチェーンシステムの一部は、単一鎖アーキテクチャが採用されていますが、スマートコントラクトトランザクションの並行した実行もサポートしています。ブラウン大学とイェール大学のトーマス・ディッカーソンとモーリス・ヘルリーは、PODC’17論文でSTM(ソフトウェアトランザクションメモリ)に基づいて並列実行モデルを提案しました。 、STMを介したステータスロールバックを完了し、シリアル化されたこれらの州の紛争トランザクションを連続して実行します。このような方法は、APTOS、SEI、Monadを含む複数の高性能ブロックチェーンプロジェクトに適用されています。それに対応して、別の並列実行モデルは、悲観的な同時性(悲観的な並列)に基づいています。つまり、トランザクションが実行される前に、トランザクションアクセスの状態のみに競合があります。 。このタイプの方法では、通常、プレコンピュートメソッドを使用してプログラム分析ツールを使用して静的分析を行い、非ループグラフ(DAG)の方向などのスマートコントラクトコードにステータス依存関係を構築します。同時トランザクションがシステムに提出されると、システムは、トランザクションニーズの状態とトランザクションニーズ間の依存関係の関係に応じて、トランザクションを並列に実行できるかどうかを決定します。状態依存関係のないトランザクションのみが互いに並行して実行されます。この種の方法は、Zilliqa(Cosplitバージョン)およびSUIなどの高性能ブロックチェーンプロジェクトに適用されます。上記の並列実行モデルは、システムのスループットを大幅に改善できます。これらの2つのスキームは、上記の類似の命令レベルに対応しています。ただし、これらのタスクには2つの問題があります。1)スケーラビリティの問題と2)並列セマンティック表現の問題については、以下で詳しく説明します。
並列設計
典型的なSolana and Monadプロジェクトを、並列アーキテクチャ設計を分解する例として使用します。これには、並列化分類、データ依存関係などが含まれます。
ソラナ
より高いレベルから、Solanaの設計コンセプトは、ハードウェアの進歩によりブロックチェーンのイノベーションが発展するはずだということです。ムーアの法律に従ってハードウェアの継続的な改善により、ソラナはより高いパフォーマンスとスケーラビリティの恩恵を受けることを目指しています。Solana Co -Founder Anatoly Yakovenkoは、5年以上前にSolanaの並列化アーキテクチャを最初に設計しました。
ソラナの使用解体並列性(決定論的な並列化)、これは、過去に組み込みシステムを使用したアナトリーの経験から生まれ、開発者は通常、すべての状態を事前に宣言します。これにより、CPUはすべての依存関係を理解して、メモリの必要な部分を好むようになります。その結果、システムの実装を最適化しますが、同じように、開発者は事前に追加の作業を行う必要があります。Solanaでは、プログラムのすべてのメモリ依存関係が必要であり、コンストラクター(つまり、アクセスリスト)で説明して、ランタイムが効率的に複数のトランザクションを調整して実行できるようにします。
Solana Architectureの次の主なコンポーネントは次のとおりですSeaLevel VM、、、、検証装置のコア数量に従って、複数の契約とトランザクションを並行してサポートします。ブロックチェーンの検証は、ネットワーク参加者であり、トランザクションの検証と確認、新しいブロックの提案、ブロックチェーンの整合性とセキュリティの維持を担当しています。アカウントを読み書きしてロックする必要があるトランザクションの事前ステートは、Solanaスケジューリングプログラムを同時に実行できるトランザクションを決定できます。このため、検証中、「ブロック生産者」またはリーダーは、数千の処理トランザクション、および非重複トランザクションの並列調整を並べ替えることができます。
モナド
Monadは、完全な平行EVMを備えた平行EVMの最初の層を構築しています。Monadの独自性は、その平行エンジンだけでなく、バックグラウンドに構築した最適化エンジンでもあります。Monadは、パイプライン、非同期I/O、分離コンセンサスと実行、MonADDBなど、いくつかの重要な機能を組み合わせて、全体的な設計にユニークな方法を使用しています。
SEIと同様に、Monadブロックチェーンの使用「楽観主義とパスコントロール(OCC)」トランザクションを実行してください。システム内に複数のトランザクションが同時に存在する場合、同時トランザクションが発生します。このトランザクション方法には、実行と検証の2つの段階があります。
実行段階では、トランザクションは楽観的であり、すべての読み取り/ライティングは、トランザクションの特定のストレージに一時的に保存されます。それ以来、各トランザクションは検証段階に入り、これは変更され、前のオフィスが作成したステータスに従って一時的な保管操作の情報を確認します。トランザクションが独立している場合、トランザクションは並行して実行されます。あるトランザクションが別のトランザクション変更のデータを読み取ると、競合が生成されます。
Monadが設計した主要な革新は、わずかなオフセットを備えたレールです。このオフセットにより、複数のインスタンスを同時に実行することにより、並列化により多くのプロセスが可能になります。したがって、組み立てラインは、パイプラインへのステータスアクセス、トランザクション実行パイプライン、コンセンサス、パイプライン、および以下のコンセンサスメカニズム自体のパイプリンなど、多くの機能を最適化するために使用されます。ワードローブ。
>
Monadでは、トランザクションはブロック内の線形でソートされますが、目標は並列実行を使用して最終状態を達成することです。モナド楽観的で並列性実行エンジンを設計するためのアルゴリズム。Monadのエンジンはトランザクションを同時に処理し、分析して、トランザクションが次々に実行された場合、結果が同じになることを確認します。競合がある場合は、再実行する必要があります。ここでの並列実行は比較的単純なアルゴリズムですが、それを他のMonadの重要な革新と組み合わせて、この方法を小説にします。ここで注意する必要があることの1つは、再解決が発生したとしても、通常は非常に安価であることです。無効な機関が必要とする入力は常にキャッシュを保持するため、これは簡単なキャッシュ検索になるためです。あなたが以前のトランザクションをすでに実行しているため、再解決は成功します。
実行の遅延に加えて、Monadは、実行とコンセンサスを分離することにより、パフォーマンスを向上させますSolanaとSeiに似ています。ここでのアイデアは、コンセンサスが完了したときに実行を完了するために条件をリラックスさせると、2つを並行して2つに余分な時間をもたらすことができるということです。もちろん、Monadは確実性アルゴリズムを使用してこの状況に対処するために、それらの1つがあまりにも走らず、追いつくことができないことを保証します。
楽観的な並列または悲観的な実行方法に関係なく、上記のシステムは、共有メモリをボトムレイヤーデータモデルの抽象化として使用します。つまり、並列ユニットがどれだけであっても、並列ユニットはすべてのデータを取得できます(ここではすべてのデータを参照します。ブロックチェーンデータでは、ステータスデータは、異なる並列実行によって直接アクセスできます(つまり、すべてのチェーン上のすべてのデータを並行して直接読み取り、書き込むことができます)。基礎となるデータモデルとして、共有メモリをブロックチェーンシステムとして使用します。
この種の並列メソッドは、スマート契約のエグゼクティブレイヤーのアーキテクチャを変更するだけで、システムコンセンサスレイヤーのロジックを変更する必要はありません。システム。したがって、データストレージのスライスがないため、ブロックチェーンネットワーク内の各ノードは、すべてのトランザクションを実行し、すべての状態を保存する必要がありますエッセンス同時に、分散型拡張機能に適した共有ノーミングアーキテクチャと比較して、これらの処理機能を抽象化するシステムを水平に拡張することはできません実行機能は、ブロックチェーンのスケーラビリティを根本的に解決することはできません。
それで、準備ができた解決策はありますか?
並列プログラミングモデル
Predaを紹介する前に、私たちは自然な質問をすることを望んでいます::なぜ並列プログラミングを使用するのですか?1970年代、1980年代、さらには1990年代の一部でさえ、単一の読み取りプログラミング(またはシリアルプログラミング)に非常に満足していました。タスクを完了するためのプログラムを作成できます。実行が終了した後、結果が得られます。タスクが完了し、誰もがとても幸せになります!タスクは完了しましたが、数百万または数十億の計算された粒子シミュレーションを1秒あたりにしている場合、または数千のピクセル画像で処理されている場合、プログラムをより速く実行する必要があります。これは、より高速なCPUが必要であることを意味します。
2004年以前は、CPUメーカーIBM、Intel、およびAMDは、MHzをより高速で高速なプロセッサを提供できます。 CPU。しかし、2004年までに、技術的な制限により、CPU速度を上げる傾向は継続できません。これには、より高いパフォーマンスを提供し続けるには、他のテクノロジーが必要です。CPUメーカーのソリューションは、2つのCPUの作業速度が単一のCPUよりも低い場合でも、2つのCPUを1つのCPUに入れることです。たとえば、300 MHzの速度での単一コアCPUと比較して、200 MHz速度で2つのCPU(メーカーはそれらをコアと呼びます)は、1秒あたりより多くの計算を実行できます(つまり、直感的な直感的な直感、2×200の直感的な外観>
夢のように聞こえますが、「シングルCPUマルチコア」ストーリーは現実になります。つまり、プログラマーはこれらの2つのコアを使用するために並行プログラミング方法を学習する必要があります。CPUが2つのプログラムを同時に実行できる場合、プログラマーはこれら2つのプログラムを作成する必要があります。しかし、これはプログラムの実行速度の2倍に変換できますか?そうでない場合は、2×200とGTのアイデアに問題があります。コアに十分な作業がない場合はどうなりますか?言い換えれば、1つのコアだけが本当に忙しいですが、もう一方のコアは何もしませんか?この場合、300 MHzの単一のコアを使用する方が良いです。マルチコアの導入後、多くの同様の問題は非常に顕著です。
>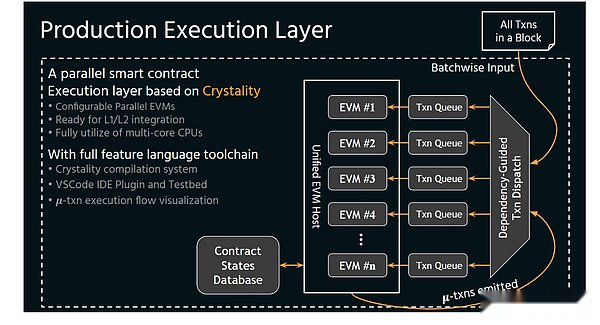
以下の図では、ボブとアリスが2人のゴールドラシストとして想像しています。ゴールドラッシュには4つのステップが必要です。
-
鉱山まで車で行きます
-
マイニング
-
鉱石の積み込み
-
保管して洗練されています
>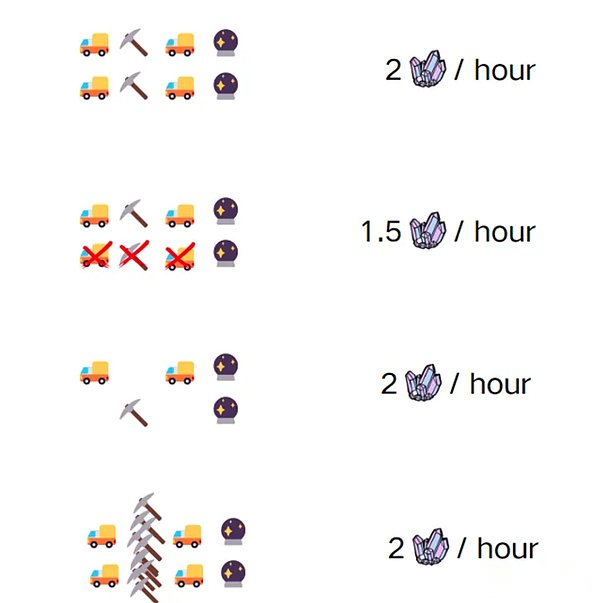
マイニングプロセス全体は、4つの独立したが秩序あるタスクで構成されており、各タスクには15分かかります。ボブとアリスが同時に継続しているとき、彼らは自分の車を持っているため、道路を共有することができ、研磨ツールを共有することができるため、1時間で2倍のマイニングワークロードを完了することができます。
しかし、ある日、ボブの採掘車両が失敗します。彼は鉱山車を修理店で出発し、鉱山鉱山車のアイアンピックを忘れました。加工工場に戻るには遅すぎましたが、彼らにはまだやるべき仕事がありました。彼らはアリスの鉱山車両と内部のハンドルを使用できますか?
上記の類推では、マイニングの4つのステップはコアです(コア) :スレッド1を実行する前に、スレッド2を実行することはできません。収穫された鉱物の数は、プログラムのパフォーマンスを意味します。パフォーマンスが高いほど、ボブとアリスの利点が高くなります。鉱山をメモリと見なすことができ、そこからデータユニット(金鉱山)を入手できるため、スレッド1で鉱石を選択するプロセスは、メモリからデータユニットの読み取りに似ています。
それでは、ボブの採掘車両が失敗した場合に何が起こるか見てみましょう。ボブとアリスは、最初は鉱業の効率が異なるため、最初は問題ではありません。洗練された鉱石の数は、「最大鉱山車が鉱物を収容できる」によって制限されています。
これは、ソラナ、コア共有の並行VMの性質でもあります。
コア共有
Solanaの最終的なデザイン要素はです「パイプライン」エッセンス一連のステップを介してデータを処理する必要があり、各ステップに対して異なるハードウェアが責任を負う場合、アセンブリライン操作が表示されます。ここで重要なアイデアは、シリアル操作を必要とするデータを取得し、パイプラインを使用して並列にすることです。これらのパイプは並行して実行でき、各パイプラインは異なるトランザクションバッチを処理できます。ハードウェアの処理速度(マイニングビークルの負荷容量)が高いほど、全体の並列化が高くなります。今日、Solanaのハードウェアノードでは、ノードオペレーターには1つの選択肢-Dataセンターしかないことが必要です。
データの依存は分割されていません(メモリリソース共有)
採掘車両をアップグレードした後、採掘能力が追いつくことができないため、採掘車両が何度も不満を抱いています。そのため、ボブはマイニングマシンを購入するために高い価格を費やし、マイニングの効率を改善しました(実行ユニットのアップグレード)。鉱物のコピーは同じ15分で生産できますが、粉砕作業はまだ手作業で行われているため、より多くの時間単位で生成された鉱石はより多くの金に変換されておらず、より多くの鉱石が絞られています倉庫。この例は、メモリにアクセスするときに何が起こるかを示しています。処理データの速さ(つまり、コア操作速度)は無関係です。データ収集速度によって制限されます。
I/Oの速度が遅くなると、I/Oはコンピューターの最も遅い部分であり、データの非同期読み取り(非同期I/O)が重要になるため、私たちをひどく困らせるでしょう。
ボブが15分で10個のマイニングマシンを掘ることができたとしても、メモリアクセス競合が存在している場合、15分ごとに2部の2部のマイニングに制限されます。既存の並列ブロックチェーンスキームは、この問題によって提案されたソリューションの出来事と楽観的な実行 – 2つの派ionsに分かれています。
前者は、データの記述と読み取りの前にデータステータスの依存を必要とします。後者は、データの書き込みに関する仮定や制限を行いません。
Monadの楽観的な実行計画で調べられた:現実には、ワークロードのほとんどはトランザクションの実行であり、並行して発生するシーンは予想通りではありません。以下の写真は、Ethereumのガス料金消費源タイプです。ただし、この分布で人気のないスマートコントラクトの割合は非常に高いことがわかります。Web2アプリケーションのリクエストの大部分は、TaobaoやDouyinなどのアクセスであるため、楽観的な実行の並列ロジックはWeb2時代で実行可能です。ただし、Web3フィールドは、ほとんどのスマートコントラクトの要求がまさに逆になっていることです。
>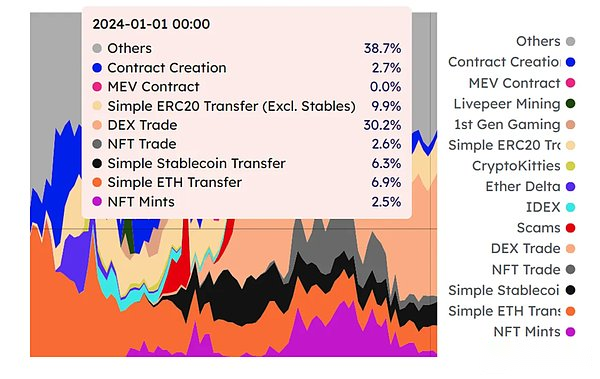
したがって、結論は、モナドが実際に並行することができるということですが、並行性は理論的な限界に存在します。つまり、2〜3倍の間隔に収まります、そのプロパガンダの100kではありません。第二に、仮想マシンを増やすことでこの上限を拡張する方法はありません。つまり、処理能力の向上に相当する多コアを達成する方法はありません。最後に、データがスライスされていないため、常に話している問題です。実際には、メインネットワークの拡張後にノードの要件に応答しません。必然的にモナドのソラナへの道を見るかもしれません。最終的に、最も重要なポイントは、楽観的な実装がブロックチェーンフィールドの並行に適していないことです。
>
しばらく採掘の後、ボブは質問をしました。「なぜアリスが戻ってきてから磨くのを待つ必要があるのですか?彼が磨かれたら、私は車を積み込むことができます。アリスが採掘を完了する前に、私たちの両方が100%忙しくなることができるようになるまで、私たちはそれに遭遇してはなりません。重要なことは、ボブがプログラム、つまりスレッドの実行の順序を再設計したことです。そのため、すべてのスレッドがコア共有リソース(マイニングカーやストーンピックなど)を待つ状態に陥ることはありません。
これは、スマートコントラクトの状態の分割を介して正しいバージョンです。 。
PredAモデルは、契約コードの時点で契約コードのアクセス構造を公開することにより実行レイヤーに公開され、実行レイヤーが結果のロールバックを簡単にスケジュールして完全に回避できるようにします。この並列モードは、非同期とも呼ばれます。
非同期
>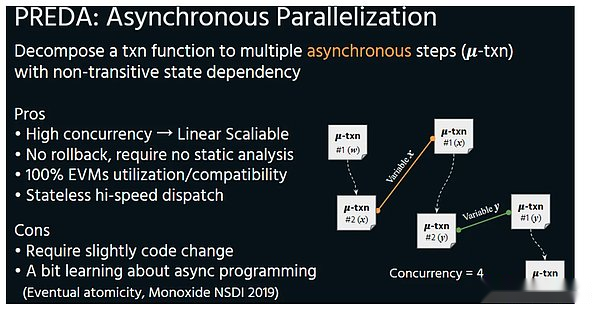
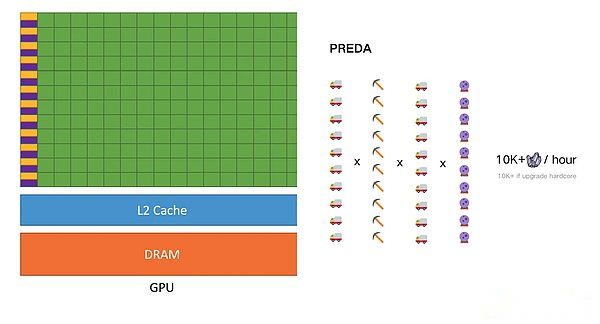
並行してのみ非同期であるため、増加するスレッドは線形改善になります。前の例のように、採掘車両の容量をアップグレードする代わりに、採掘車両は後方採掘装置のために空になります。Predaの並列実行環境は、Multi -Core CPUとGPUの違いのように、Solana-の間の最も本質的な違いです。 GPUと同じです。ブロックチェーンのロジックでは、スレッド(VM)の増加により、ノード全体のハードウェア需要が削減され、それにより、地方分権化を確保する前提の下でパフォーマンスの改善が得られます。
>
>
最後に、この並列ブロックチェーンの終わりに加えて、並列プログラミング言語のセマンティック表現もあります。
並列プログラミング言語の意味表現
NvidiaにはCudaが必要であり、並列ブロックチェーンには新しいプログラミング言語が必要です:Preda。今日のスマートコントラクトの開発者は、基礎となるマルチチェーンアーキテクチャ(シャードのデータシェルディングまたは実行またはその両方)によって提供されるサポートを効果的に使用することはできず、一般的なスマートコントラクトトランザクションの効果的な並列並列を達成することはできません。すべてのシステムは、堅牢性、移動、錆などの従来の一般的なスマートコントラクトプログラミング言語を使用しています。これらのプログラミング言語には、並列セマンティック表現の能力がありません。つまり、高性能コンピューティングまたはビッグの分野におけるCUDAや並列プログラミングモデルなどの並列プログラミングモデルとプログラミング言語表現の間の制御とデータフローを制御する能力がありません。 CUDAのようなデータフィールド。
スマートコントラクトに適した並列プログラミングモデルとプログラミング言語の欠如により、アプリケーションと並列再編からアルゴリズムは完了できません。アプリケーションの実装効率とブロックチェーンシステムの全体的なスループットを改善します。
Predaによって提案されたこの分散プログラミングモデルは、プログラマティック契約の範囲を通じて、契約ステータスの細かい粒度分割を実施し、機能的リレーリレーを介して機能的なリレー遅延を介してトランザクション実行フロー分解を分散させます
また、このモデルは、プログラマティック契約範囲を介した契約ステータスの分割スキームを定義し、開発者がアプリケーションのアプリケーションアクセスモードに従って最適化できるようにします。非同期機能リレーを介して、トランザクション実行フローをアクセスする必要がある実行エンジンに移動でき、データの動きではなく実行プロセスの動きが移動されます。
このモデルは、開発者が基礎となるマルチチェーンシステムの詳細を気にする必要なく、契約状態の流通とトランザクションフローの分布を実現します。実験結果は、256実行エンジンのPredaモデルが最大18倍のスループットを達成できることを示しており、これは理論的な並列制限に近いことです。パーティションカウンターと交換の指示を使用することにより、並列性をさらに強化します。
結論
ブロックチェーンシステムは、従来、単一の注文実行エンジン(EVMなど)を使用してすべてのトランザクションを処理し、それによりスケーラビリティを制限しています。マルチチェーンシステムは並列実行エンジンを実行しますが、各エンジンはスマート契約のすべてのトランザクションを処理し、契約レベルでスケーラビリティを実現できません。この記事では、Solanaが代表する永続的な並列性の本質的なコア共有について説明します。そして、なぜMonadが代表する楽観主義と行動が実際のブロックチェーンアプリケーションシナリオで実行&AMPを実行することが可能なのかについて説明します。Predaの並列実行エンジンを導入しました。Predaチームは、スマートコントラクトのステータスを分割し、エンジン全体にトランザクションフローを割り当てることにより、単一のスマートコントラクトを拡張する新しいプログラミングモデルを提案しました。契約の分割を定義するために、プログラム可能な契約の範囲を導入します。各スコープは、専用の実行エンジンで実行されます。非同期機能リレーは、トランザクションの実行ストリームを分解するために使用され、他の場所にとどまるときにエンジン全体に移動します。
>
これにより、トランザクションロジックと契約ステータスパーティションと組み合わされます。これにより、データは頭上に移動することなく固有の並列性が可能になります。その並列モデルは、スマートコントラクトで分割されたステータスを分離し、データリリースレベルの依存性を分離しましたが、Move Multi-Threaded Execting Engine Clusterアーキテクチャも提供します。さらに重要なことは、新しいプログラミングモデルPredaを革新的に立ち上げたことです。これは、ブロックチェーンの並列によって到達した最後のパズルである可能性があります。
>







{kind=link}
{kind=link}