
Autor: YBB Capital Zeke
Prefacio
El 16 de febrero, OpenAI anunció el último modelo de difusión de generación de videos controlado por texto «SORA», que demuestra otro hito en IA generativa a través de la generación de videos de alta calidad de una amplia gama de tipos de datos visuales cubiertos por múltiples segmentos.A diferencia de PIKA, las herramientas de generación de videos de IA todavía están en el estado de generación de videos durante varios segundos con múltiples imágenes, Sora ha logrado la generación de videos escalables mediante el entrenamiento en el espacio latente comprimido de videos e imágenes y descomponiéndolas en parches de posición espacio-tiempo.Además, el modelo también refleja la capacidad de simular el mundo físico y el mundo digital.
En términos de métodos de construcción, SORA continuó la ruta técnica previa del modelo GPT «fuente de datos-transformador-emergencia de difusión», lo que significa que su desarrollo y madurez también requieren energía informática como motor, y desde la cantidad de datos requeridos para La capacitación en video es mucho mayor que la del texto La cantidad de datos capacitados aumentará aún más la demanda de energía informática.Sin embargo, ya hemos discutido la importancia de la potencia informática en la era de la IA en el artículo inicial «Vista previa de la pista popular: mercado de energía informática descentralizada», y con la reciente creciente popularidad de la IA, ya hay una gran cantidad de energía informática Proyectos en el mercado.Entonces, además de Depin, ¿qué tipo de chispas pueden colisionar el intercambio de Web3 y la IA?¿Qué otras oportunidades contiene esta pista?El objetivo principal de este artículo es actualizar y completar artículos pasados, y pensar en las posibilidades de Web3 en la era de la IA.
Tres direcciones principales en la historia del desarrollo de la IA
La inteligencia artificial es una ciencia y tecnología emergentes diseñadas para simular, expandir y mejorar la inteligencia humana.Desde su nacimiento en las décadas de 1950 y 1960, la inteligencia artificial se ha convertido en una tecnología importante para promover cambios en la vida social y todos los ámbitos de la vida después de más de medio siglo de desarrollo.En este proceso, el desarrollo entrelazado de las tres direcciones de investigación de simbolismo, conectividad y conductismo se ha convertido en la piedra angular del rápido desarrollo de la IA hoy.
Simbolismo
También conocido como logicismo o reglas, cree que es factible simular la inteligencia humana mediante el procesamiento de símbolos.Este método utiliza símbolos para representar y operar objetos, conceptos y sus interrelaciones dentro del área del problema, y utiliza un razonamiento lógico para resolver problemas, especialmente en sistemas expertos y representaciones de conocimiento.La visión central del simbolismo es que el comportamiento inteligente se puede lograr a través de la operación y el razonamiento lógico de los símbolos, donde los símbolos representan un alto grado de abstracción del mundo real;
Conectismo
O métodos de red neuronal, diseñados para lograr la inteligencia imitando la estructura y las funciones del cerebro humano.Este método permite el aprendizaje construyendo una red de numerosas unidades de procesamiento simples (como las neuronas) y ajustar la resistencia de la conexión entre estas unidades (como las sinapsis).El conexionismo enfatiza la capacidad de aprender y generalizar a partir de datos, y es particularmente adecuado para el reconocimiento de patrones, la clasificación y los problemas continuos de mapeo de entrada y salida.El aprendizaje profundo, como el desarrollo del conectivismo, ha realizado avances en áreas como el reconocimiento de imágenes, el reconocimiento de voz y el procesamiento del lenguaje natural;
Behaviorismo
El conductismo está estrechamente relacionado con la investigación de la robótica biónica y los sistemas inteligentes autónomos, enfatizando que los agentes pueden aprender a través de la interacción con el medio ambiente.A diferencia de los dos primeros, el conductismo no se centra en simular representaciones internas o procesos de pensamiento, sino que logra el comportamiento adaptativo a través de un ciclo de percepción y acción.El conductismo cree que la inteligencia se manifiesta a través de la interacción dinámica y el aprendizaje con el entorno, que es particularmente efectivo cuando se aplica a robots móviles y sistemas de control adaptativo que requieren acción en entornos complejos e impredecibles.
Aunque existen diferencias esenciales en estas tres direcciones de investigación, también pueden interactuar e integrar en la investigación y aplicación reales de IA para promover conjuntamente el desarrollo del campo AI.
Descripción general del principio AIGC
El contenido generado por inteligencia artificial (AIGC), que actualmente está en desarrollo explosivo, es una evolución y aplicación de conectividad.Estos modelos se entrenan utilizando grandes conjuntos de datos y algoritmos de aprendizaje profundo para aprender las estructuras, relaciones y patrones subyacentes que existen en los datos.Genere resultados de salida novedosos y únicos basados en indicaciones de entrada del usuario, incluidas imágenes, videos, códigos, música, diseño, traducciones, respuestas de preguntas y texto.El AIGC actual consta básicamente de tres elementos: aprendizaje profundo (DL), big data y potencia informática a gran escala.
Aprendizaje profundo
El aprendizaje profundo es un subcampo de aprendizaje automático (ML), y los algoritmos de aprendizaje profundo son redes neuronales modeladas según el cerebro humano.Por ejemplo, el cerebro humano contiene millones de neuronas interrelacionadas que trabajan juntas para aprender y procesar información.Del mismo modo, las redes neuronales de aprendizaje profundo (o redes neuronales artificiales) están compuestas de neuronas artificiales de varias capas que trabajan juntas dentro de una computadora.Las neuronas artificiales son módulos de software llamados nodos que usan cálculos matemáticos para procesar datos.Las redes neuronales artificiales son algoritmos de aprendizaje profundo que usan estos nodos para resolver problemas complejos.
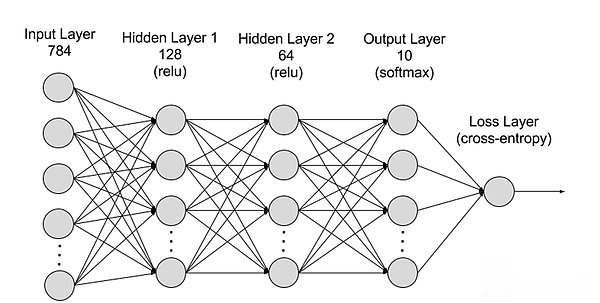
La división de redes neuronales de una jerarquía se puede dividir en la capa de entrada, la capa oculta y la capa de salida, y los parámetros están conectados entre diferentes capas.
-
Capa de entrada: La capa de entrada es la primera capa de la red neuronal, que es responsable de recibir datos de entrada externos.Cada neurona en la capa de entrada corresponde a una característica de los datos de entrada.Por ejemplo, al procesar datos de imagen, cada neurona puede corresponder a un valor de píxel de la imagen;
-
Capa oculta: La capa de entrada procesa los datos y los pasa a una capa adicional en la red neuronal.Estas capas ocultas procesan información en diferentes niveles y ajustan su comportamiento al recibir nueva información.Las redes de aprendizaje profundo tienen cientos de capas ocultas que pueden usarse para analizar problemas desde múltiples ángulos diferentes.Por ejemplo, si obtiene una imagen de un animal desconocido que debe clasificarse, puede compararlo con un animal que ya conoce.Por ejemplo, podemos juzgar qué animal se basa en la forma del oído, el número de piernas y el tamaño de los alumnos.Las capas ocultas en redes neuronales profundas funcionan de la misma manera.Si un algoritmo de aprendizaje profundo intenta clasificar las imágenes animales, cada una de sus capas ocultas procesa diferentes características del animal e intenta clasificarlas con precisión;
-
Capa de salida: La capa de salida es la última capa de la red neuronal, que es responsable de generar la salida de la red.Cada neurona en la capa de salida representa una posible categoría o valor de salida.Por ejemplo, en un problema de clasificación, cada neurona de capa de salida puede corresponder a una categoría, mientras que en un problema de regresión, la capa de salida puede tener solo una neurona, cuyo valor representa el resultado de la predicción;
-
parámetro: En las redes neuronales, las conexiones entre diferentes capas están representadas por los parámetros de pesos y sesgos, que se optimizan durante el entrenamiento para permitir que la red identifique con precisión los patrones en los datos y haga predicciones.El aumento de los parámetros puede aumentar la capacidad del modelo de la red neuronal, es decir, la capacidad del modelo para aprender y representar patrones complejos en los datos.Pero el aumento correspondiente en los parámetros aumentará la demanda de energía informática.
Big data
Para una capacitación efectiva, las redes neuronales generalmente requieren datos grandes, diversos, de alta calidad y de múltiples fuentes.Es la base para la capacitación y verificación del modelo de aprendizaje automático.Al analizar Big Data, los modelos de aprendizaje automático pueden aprender patrones y relaciones en los datos para hacer predicciones o clasificaciones.
Potencia informática a gran escala
La estructura compleja de múltiples capas de las redes neuronales, una gran cantidad de parámetros, requisitos de procesamiento de big data, métodos de entrenamiento iterativo (en la etapa de capacitación, el modelo necesita iterar repetidamente, y durante el proceso de capacitación, es necesario propagar y hacer backpropagar Cada capa de cálculo, incluidas las funciones de activación, el cálculo de la función de pérdida, el cálculo del gradiente y la actualización de los pesos, los requisitos de cálculo de alta precisión, potencia informática paralela, optimización y tecnología de regularización, y los procesos de evaluación y verificación del modelo. a su demanda de alta potencia informática.

Sora
Como el último modelo de AI de generación de videos de OpenAI, SORA representa un gran avance en la capacidad de la inteligencia artificial para procesar y comprender diversos datos visuales.Al adoptar la red de compresión de video y la tecnología de parche de tiempo espacial, SORA puede convertir datos visuales masivos tomados de diferentes dispositivos en todo el mundo en una forma de expresión unificada, lo que logró un procesamiento eficiente y una comprensión del contenido visual complejo.Confiando en el modelo de difusión condicionado por el texto, Sora puede generar videos o imágenes altamente coincidentes basados en indicaciones de texto, mostrando una creatividad y adaptabilidad extremadamente alta.
Sin embargo, a pesar de los avances de Sora en la generación de videos y simulando las interacciones del mundo real, todavía enfrenta algunas limitaciones, incluida la precisión de las simulaciones del mundo físico, la consistencia de la generación de videos largos, la comprensión de las instrucciones de texto complejas y la eficiencia de entrenamiento y generación.En esencia, Sora continúa la vieja ruta técnica de la «big data-transformer-difusion-emergence» a través del poder informático de Monopoly de Opense y la ventaja de primer movimiento, y ha logrado una estética violenta que todavía tiene la curva de tecnología. .
Aunque Sora tiene poco que ver con Blockchain, personalmente creo que tomará los próximos uno o dos años.Debido a que la influencia de Sora obligará a otras herramientas de generación de IA de alta calidad a emerger y desarrollarse rápidamente, y irradiará a múltiples pistas como GameFI, redes sociales, plataformas creativas y depender en Web3, es necesario tener una comprensión general de Sora. Cómo la IA en el futuro se combinará efectivamente con Web3 puede ser un punto clave en el que debemos pensar.
Cuatro caminos principales a AI X Web3
Como se mencionó anteriormente, podemos saber que en realidad solo hay tres bases subyacentes requeridas para la IA generativa: algoritmos, datos y potencia informática. .El papel más importante de Blockchain es dos: reconstruir las relaciones de producción y la descentralización.Así que personalmente creo que hay cuatro formas de generar una colisión entre los dos:
Potencia informática descentralizada
Dado que hemos escrito artículos relacionados en el pasado, el objetivo principal de este párrafo es actualizar la situación reciente de la pista de alimentación informática.Cuando se trata de IA, la alimentación informática siempre es un enlace difícil para omitir.La gran demanda de poder informático de la IA ya es inimaginable después de que nació Sora.Recientemente, durante el Foro Económico Mundial de 2024 en Davos, Suiza, el CEO de OpenAi, Ultraman, dijo sin rodeos que el poder y la energía informáticos son los grilletes más grandes en esta etapa, y la importancia de los dos en el futuro incluso será equivalente a la moneda.El 10 de febrero, Ultraman Sam lanzó un plan extremadamente sorprendente para recaudar 7 billones de dólares (equivalente al 40% del PIB nacional de China en 23 años) para reescribir la actual estructura de la industria de semiconductores globales fundados.Al escribir artículos relacionados con el poder informático, mi imaginación todavía está limitada al bloqueo nacional y los gigantes lo monopolizan.
Por lo tanto, la importancia del poder informático descentralizado es naturalmente evidente.Desde la perspectiva de la IA, el uso de la potencia informática se puede dividir en dos direcciones: razonamiento y capacitación. La demanda está destinada a ser una dirección con un umbral extremadamente alto y extremadamente difícil de implementar.El razonamiento es relativamente simple.
El espacio de imaginación del mercado centralizado de energía informática es enorme, y a menudo está vinculado a la palabra clave «billón de niveles».Sin embargo, a juzgar por la gran cantidad de proyectos que han surgido recientemente, la mayoría de ellos todavía están en los estantes y aprovechan la popularidad.Siempre mantenga en alto el banner correcto de la descentralización, pero mantén en silencio sobre la ineficiencia de las redes descentralizadas.Y hay un alto grado de homogeneidad en el diseño, y una gran cantidad de proyectos son muy similares (un clic L2 Plus Mining de diseño), lo que eventualmente puede conducir a un desastre. rastrear en tal situación.
Sistema de colaboración de algoritmo y modelo
Los algoritmos de aprendizaje automático se refieren a estos algoritmos que pueden aprender leyes y patrones de los datos y tomar predicciones o decisiones basadas en ellas.Los algoritmos son intensivos en tecnología porque su diseño y optimización requieren una profunda experiencia e innovación tecnológica.Los algoritmos están en el corazón de la capacitación de modelos AI, que definen cómo los datos se traducen en ideas o decisiones útiles.Los algoritmos de IA generativos más comunes, como las redes adversas generativas (GAN), los autoencoders variacionales (VAE) y los transformadores. y luego un modelo de IA dedicado se capacita a través de algoritmos.
Tantos algoritmos y modelos tienen sus propias ventajas.Bittensor, que ha sido popular recientemente, es el líder en esta dirección.Commune AI (colaboración en código) y otros aspectos también se basan principalmente en esta dirección.
Por lo tanto, la narración del ecosistema de colaboración AI es novedosa e interesante.Después de todo, los algoritmos de código cerrado y los modelos de las principales compañías de IA tienen capacidades muy fuertes en actualizaciones, iteraciones e integración. Los modelos de generación.
Big data descentralizados
Desde un punto de vista simple, el uso de datos privados para alimentar los datos de la IA y la etiqueta es una dirección muy consistente con blockchain. Los proyectos se benefician.Desde una perspectiva compleja, el uso de datos blockchain para el aprendizaje automático (ml) para resolver la accesibilidad de los datos de blockchain también es una dirección interesante (una de las direcciones de exploración de Giza).
En teoría, se puede acceder a los datos de blockchain en cualquier momento, lo que refleja el estado de toda la cadena de bloques.Pero para aquellos fuera del ecosistema blockchain, no es fácil obtener estas enormes cantidades de datos.Para almacenar completamente una cadena de bloques requiere una rica experiencia y una gran cantidad de recursos de hardware especializados.Para superar el desafío de acceder a los datos de blockchain, han surgido varias soluciones en la industria.Por ejemplo, los proveedores de RPC acceden a nodos a través de API, mientras que los servicios de indexación hacen posible la extracción de datos a través de SQL y GraphQL, los cuales juegan un papel clave en la resolución de problemas.Sin embargo, estos métodos tienen limitaciones.Los servicios de RPC no son adecuados para escenarios de uso de alta densidad que requieren grandes cantidades de consultas de datos y, a menudo, no pueden satisfacer las necesidades.Mientras tanto, aunque los servicios de indexación proporcionan una forma más estructurada de recuperar datos, la complejidad del protocolo Web3 hace que sea extremadamente difícil construir consultas eficientes, a veces que requieren cientos o incluso miles de líneas de código complejo.Esta complejidad es un gran obstáculo para los profesionales de datos generales y aquellos que no comprenden profundamente los detalles de Web3.El efecto acumulativo de estas limitaciones resalta la necesidad de una forma más fácil de acceder y utilizar datos de blockchain que pueden facilitar una aplicación e innovación más amplias en el campo.
Luego, a través de ZKML (ZKML (Aprendizaje automático a prueba de conocimiento cero, reduciendo la carga de la cadena de aprendizaje automático) combinada con datos blockchain de alta calidad, puede ser posible crear conjuntos de datos que resuelvan la accesibilidad de blockchain, mientras que la IA puede reducir significativamente blockchain .
AI empodera a Dapp
Desde que ChatGPT3 se hizo popular en 23 años, AI Empodering Dapps se ha convertido en una dirección muy común.Se puede acceder a la IA generativa con una utilidad extremadamente extendida a través de API, simplificando y analizando de manera inteligente plataformas de datos, comercio de robots, enciclopedia blockchain y otras aplicaciones.Por otro lado, también puedes jugar como chatbot (como Myshell) o AI Companion (IA de insomnio), e incluso crear NPC en juegos de cadena a través de IA generativa.Sin embargo, debido a las bajas barreras técnicas, la mayoría de ellas están ajustadas después de acceder a una API, y la combinación con el proyecto en sí no es perfecta, por lo que rara vez se menciona.
Pero después de que llega Sora, personalmente creo que la dirección de AI empodera a GameFi (incluido el Metaverse) y las plataformas creativas serán el foco del próximo enfoque.Debido a la naturaleza ascendente del campo Web3, definitivamente es difícil producir productos que compitan con juegos tradicionales o compañías creativas, y es probable que la aparición de Sora rompa este dilema (tal vez solo dos o tres años).A juzgar por la demostración de Sora, ya tiene el potencial de competir con las compañías de drama micro-short. -dodo de las industrias tradicionales se romperán.
Conclusión
Con el avance continuo de las herramientas generativas de IA, experimentaremos más «momentos de iPhone» en el futuro.Aunque muchas personas se burlan de la combinación de IA y Web3, en realidad creo que la mayor parte de la dirección actual no es un problema, y en realidad solo hay tres puntos débiles que deben resolverse, es decir, necesidad, eficiencia y ajuste.Aunque la integración de los dos está en la etapa de exploración, no evita que esta pista se convierta en la corriente principal del próximo mercado alcista.
Mantener suficiente curiosidad y aceptación de las cosas nuevas es una mentalidad necesaria para nosotros. perder la oportunidad.







