
Auteur: YBB Capital Zeke
Préface
Le 16 février, OpenAI a annoncé le dernier modèle de diffusion de génération vidéo contrôlée par texte « Sora », qui démontre une autre étape importante de l’IA générative grâce à une génération de vidéos de haute qualité d’un large éventail de types de données visuels couverts par plusieurs segments.Contrairement à PIKA, les outils de génération de vidéos AI sont toujours dans l’état de génération de vidéos pendant plusieurs secondes avec plusieurs images, Sora a atteint la génération de vidéos évolutive en s’entraînant dans l’espace latent compressé de la vidéo et des images et en les décomposant dans des patchs de position spatiale.De plus, le modèle reflète également la capacité de simuler le monde physique et le monde numérique.
En termes de méthodes de construction, Sora a poursuivi le chemin technique précédent du modèle GPT « source-transformateur-diffusion-émergence », ce qui signifie que son développement et sa maturité nécessitent également une puissance de calcul en tant que moteur, et puisque la quantité de données requise pour La formation vidéo est beaucoup plus grande que celle du texte. La quantité de données formées augmentera encore la demande de puissance de calcul.Cependant, nous avons déjà discuté de l’importance de la puissance de calcul à l’ère de l’IA dans le premier article « Popular Track Preview Des projets sur le marché.Donc, en plus de Depin, quel type d’étincelles l’entrelacement de Web3 et AI peut-il entrer en collision?Quelles autres opportunités contiennent cette piste?L’objectif principal de cet article est de mettre à jour et de compléter les articles passés et de réfléchir aux possibilités de Web3 à l’ère AI.
Trois directions majeures de l’histoire du développement de l’IA
L’intelligence artificielle est une science et une technologie émergentes conçues pour simuler, développer et améliorer l’intelligence humaine.Depuis sa naissance dans les années 1950 et 1960, l’intelligence artificielle est devenue une technologie importante pour promouvoir les changements dans la vie sociale et tous les horizons après plus d’un demi-siècle de développement.Dans ce processus, le développement entrelacé des trois directions de recherche du symbolisme, de la connectivité et du comportementalisme est devenue la pierre angulaire du développement rapide de l’IA aujourd’hui.
Symbolisme
Également connu sous le nom de logicisme ou de règlements, il estime qu’il est possible de simuler l’intelligence humaine en traitant les symboles.Cette méthode utilise des symboles pour représenter et exploiter des objets, des concepts et leurs interrelations dans le domaine du problème, et utilise un raisonnement logique pour résoudre les problèmes, en particulier dans les systèmes experts et les représentations des connaissances.La vision centrale du symbolisme est que le comportement intelligent peut être obtenu par le fonctionnement et le raisonnement logique des symboles, où les symboles représentent un degré élevé d’abstraction du monde réel;
Connexionnisme
Ou des méthodes de réseau neuronal, conçues pour réaliser l’intelligence en imitant la structure et les fonctions du cerveau humain.Cette méthode permet l’apprentissage en construisant un réseau de nombreuses unités de traitement simples (comme les neurones) et en ajustant la résistance de la connexion entre ces unités (comme les synapses).Le connexionnisme met l’accent sur la capacité d’apprendre et de généraliser à partir des données, et est particulièrement adapté à la reconnaissance des modèles, à la classification et à des problèmes de cartographie des entrées et de la sortie continues.Le Deep Learning, en tant que développement du connectivisme, a fait des percées dans des domaines tels que la reconnaissance d’image, la reconnaissance vocale et le traitement du langage naturel;
Behaviorisme
Le comportementalisme est étroitement lié à la recherche de la robotique bionique et des systèmes intelligents autonomes, soulignant que les agents peuvent apprendre par interaction avec l’environnement.Contrairement aux deux premiers, le comportementalisme ne se concentre pas sur la simulation de représentations internes ou de processus de réflexion, mais réalise plutôt un comportement adaptatif à travers un cycle de perception et d’action.Le comportementalisme estime que l’intelligence se manifeste par l’interaction dynamique et l’apprentissage avec l’environnement, ce qui est particulièrement efficace lorsqu’il est appliqué aux robots mobiles et aux systèmes de contrôle adaptatif qui nécessitent une action dans des environnements complexes et imprévisibles.
Bien qu’il existe des différences essentielles dans ces trois directions de recherche, elles peuvent également interagir et s’intégrer dans la recherche et l’application réelles de l’IA pour promouvoir conjointement le développement du domaine de l’IA.
Présentation du principe AIGC
Le contenu généré par l’intelligence artificielle (AIGC), qui est actuellement en cours de développement explosif, est une évolution et une application de la connectivité.Ces modèles sont formés à l’aide de grands ensembles de données et d’algorithmes d’apprentissage en profondeur pour apprendre les structures, les relations et les modèles sous-jacents qui existent dans les données.Générez des résultats de sortie nouveaux et uniques basés sur des invites d’entrée utilisateur, y compris les images, les vidéos, les codes, la musique, la conception, les traductions, les réponses de questions et le texte.L’AIGC actuel se compose essentiellement de trois éléments: l’apprentissage en profondeur (DL), les mégadonnées et la puissance de calcul à grande échelle.
Apprentissage en profondeur
Le Deep Learning est un sous-champ de l’apprentissage automatique (ML), et les algorithmes d’apprentissage en profondeur sont des réseaux de neurones modélisés selon le cerveau humain.Par exemple, le cerveau humain contient des millions de neurones interdépendants qui travaillent ensemble pour apprendre et traiter les informations.De même, les réseaux de neurones en profondeur (ou réseaux de neurones artificiels) sont composés de neurones artificiels multicouches qui travaillent ensemble à l’intérieur d’un ordinateur.Les neurones artificiels sont des modules logiciels appelés nœuds qui utilisent des calculs mathématiques pour traiter les données.Les réseaux de neurones artificiels sont des algorithmes d’apprentissage en profondeur qui utilisent ces nœuds pour résoudre des problèmes complexes.
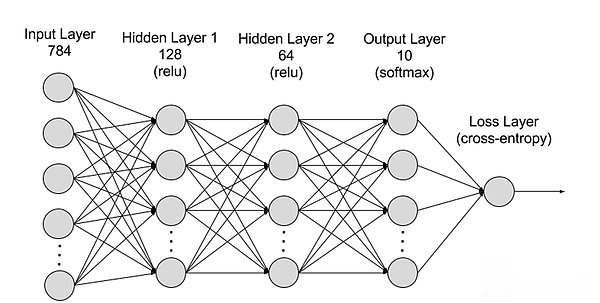
La division des réseaux de neurones d’une hiérarchie peut être divisée en couche d’entrée, couche cachée et couche de sortie, et les paramètres sont connectés entre différentes couches.
-
Couche d’entrée: La couche d’entrée est la première couche du réseau neuronal, qui est responsable de la réception des données d’entrée externes.Chaque neurone de la couche d’entrée correspond à une caractéristique des données d’entrée.Par exemple, lors du traitement des données d’image, chaque neurone peut correspondre à une valeur de pixel de l’image;
-
Couche cachée: La couche d’entrée traite les données et la transmet à une nouvelle couche dans le réseau neuronal.Ces couches cachées traitent les informations à différents niveaux et ajustent leur comportement lors de la réception de nouvelles informations.Les réseaux d’apprentissage en profondeur ont des centaines de couches cachées qui peuvent être utilisées pour analyser les problèmes sous plusieurs angles différents.Par exemple, si vous obtenez une image d’un animal inconnu qui doit être classé, vous pouvez le comparer avec un animal que vous connaissez déjà.Par exemple, nous pouvons juger de quel animal cela est basé sur la forme de l’oreille, le nombre de jambes et la taille des élèves.Les couches cachées dans des réseaux de neurones profonds fonctionnent de la même manière.Si un algorithme d’apprentissage en profondeur essaie de classer les images animales, chacune de ses couches cachées traite différentes caractéristiques de l’animal et tente de les classer avec précision;
-
Couche de sortie: La couche de sortie est la dernière couche du réseau neuronal, qui est responsable de la génération de la sortie du réseau.Chaque neurone de la couche de sortie représente une catégorie ou une valeur de sortie possible.Par exemple, dans un problème de classification, chaque neurone de couche de sortie peut correspondre à une catégorie, tandis que dans un problème de régression, la couche de sortie peut ne pas avoir un seul neurone, dont la valeur représente le résultat de prédiction;
-
paramètre: Dans les réseaux de neurones, les connexions entre différentes couches sont représentées par des paramètres de poids et de biais, qui sont optimisés lors de la formation pour permettre au réseau d’identifier avec précision les modèles dans les données et de faire des prédictions.L’augmentation des paramètres peut augmenter la capacité du modèle du réseau neuronal, c’est-à-dire la capacité du modèle à apprendre et à représenter des modèles complexes dans les données.Mais l’augmentation correspondante des paramètres augmentera la demande de puissance de calcul.
Big data
Pour une formation efficace, les réseaux de neurones nécessitent généralement des données importantes, diverses, de haute qualité et multi-sources.C’est la base de la formation et de la vérification du modèle d’apprentissage automatique.En analysant les mégadonnées, les modèles d’apprentissage automatique peuvent apprendre des modèles et des relations dans les données pour faire des prédictions ou des classifications.
Puissance de calcul à grande échelle
La structure complexe multicouches des réseaux de neurones, un grand nombre de paramètres, des exigences de traitement des mégadonnées, des méthodes de formation itératives (au stade de la formation, le modèle doit itérater à plusieurs reprises et pendant le processus de formation, il est nécessaire de propager et de se rétrécir Chaque couche de calcul, y compris les fonctions d’activation, le calcul de la fonction de perte, le calcul du gradient et la mise à jour des poids, les exigences du calcul de haute précision, la puissance de calcul parallèle, la technologie d’optimisation et de régularisation et les processus d’évaluation et de vérification du modèle ont LED à leur demande de puissance de calcul élevée.

Sora
En tant que dernier modèle d’IA de génération vidéo d’OpenAI, Sora représente une énorme progression de la capacité de l’intelligence artificielle à traiter et à comprendre diverses données visuelles.En adoptant le réseau de compression vidéo et la technologie des patchs d’espace, Sora peut convertir des données visuelles massives tirées de différents appareils du monde entier en une forme d’expression unifiée, réalisant ainsi un traitement et une compréhension efficaces du contenu visuel complexe.S’appuyant sur le modèle de diffusion conditionné en texte, Sora peut générer des vidéos ou des images hautement adaptées basées sur des invites de texte, montrant une créativité et une adaptabilité extrêmement élevées.
Cependant, malgré les percées de Sora dans la génération de vidéos et la simulation des interactions du monde réel, il fait toujours face à certaines limites, notamment la précision des simulations du monde physique, la cohérence de la génération vidéo longue, la compréhension des instructions de texte complexes et l’efficacité de la formation et de la génération.Essentiellement, Sora poursuit l’ancien chemin technique de « Big Data-Transformateur-Diffusion-Emergence » par le biais de la puissance de l’informatique de monopole d’Openai et de l’avantage de premier ordre, et a obtenu une esthétique violente. .
Bien que Sora ait peu à voir avec la blockchain, je pense personnellement que cela prendra les prochaines années.Étant donné que l’influence de Sora obligera d’autres outils de génération d’IA de haute qualité pour émerger et se développer rapidement, et irrader sur plusieurs pistes telles que GameFi, les réseaux sociaux, les plateformes créatives et Depin dans Web3, il est nécessaire d’avoir une compréhension générale de Sora. La façon dont l’IA à l’avenir sera efficacement combinée avec web3 peut être un point clé auquel nous devons penser.
Quatre chemins majeurs vers AI x Web3
Comme mentionné ci-dessus, nous pouvons savoir qu’il n’y a en fait que trois bases sous-jacentes requises pour une AI générative: algorithmes, données et alimentation informatique. .Le plus grand rôle de la blockchain est deux: reconstruire les relations de production et la décentralisation.Je pense donc personnellement qu’il existe quatre façons de générer une collision entre les deux:
Puissance de calcul décentralisée
Étant donné que nous avons écrit des articles connexes dans le passé, l’objectif principal de ce paragraphe est de mettre à jour la situation récente de la piste de puissance informatique.En ce qui concerne l’IA, la puissance de calcul est toujours un lien difficile à contourner.La grande demande de pouvoir de calcul de l’IA est déjà inimaginable après la naissance de Sora.Récemment, lors du Forum économique mondial de 2024 à Davos, en Suisse, le PDG d’Openai Ultraman a déclaré que la puissance et l’énergie informatiques sont les plus grandes chaînes à ce stade, et l’importance des deux à l’avenir sera même équivalente à la monnaie.Le 10 février, Ultraman Sam a publié un plan extrêmement étonnant pour collecter 7 billions de dollars américains (équivalent à 40% du PIB national de la Chine en 23 ans) pour réécrire la structure actuelle de l’industrie des semi-conducteurs.Lors de la rédaction d’articles liés à la puissance de calcul, mon imagination est toujours limitée au blocage national et les géants le monopolisent.
Par conséquent, l’importance de la puissance de calcul décentralisée est naturellement évidente.Du point de vue de l’IA, l’utilisation de la puissance de calcul peut être divisée en deux directions: le raisonnement et la formation. La demande est destinée à être une direction avec un seuil extrêmement élevé et extrêmement difficile à mettre en œuvre.Le raisonnement est relativement simple.
L’espace d’imagination du marché de la puissance de l’informatique centralisée est énorme, et il est souvent lié au mot-clé « billion de niveaux ».Cependant, à en juger par le grand nombre de projets qui ont émergé récemment, la plupart d’entre eux sont toujours sur les étagères et profitent de la popularité.Tenez toujours haut la bannière correcte de la décentralisation, mais gardez le silence sur l’inefficacité des réseaux décentralisés.Et il y a un degré élevé d’homogénéité dans la conception, et un grand nombre de projets sont très similaires (conception minière en un clic), ce qui peut éventuellement conduire à un gâchis. suivre une telle situation.
Algorithme et système de collaboration modèle
Les algorithmes d’apprentissage automatique se réfèrent à ces algorithmes qui peuvent apprendre des lois et des modèles à partir des données et prendre des prédictions ou des décisions basées sur eux.Les algorithmes sont à forte intensité de technologie car leur conception et leur optimisation nécessitent une expertise approfondie et une innovation technologique.Les algorithmes sont au cœur de la formation des modèles d’IA, qui définissent comment les données se traduisent par des idées ou des décisions utiles.Les algorithmes génératifs d’IA plus courants tels que les réseaux adversaires génératifs (GAN), les autoencodeurs variationnels (VAES) et les transformateurs. Et puis un modèle d’IA dédié est formé à travers des algorithmes.
Tant d’algorithmes et de modèles ont leurs propres avantages.Bittensor, qui a été populaire récemment, est le leader dans cette direction.Commune AI (Code Collaboration) et d’autres aspects sont également principalement basés sur cette direction.
Par conséquent, le récit de l’écosystème de la collaboration AI est nouveau et intéressant.Après tout, les algorithmes de source fermée et les modèles de principales sociétés d’IA ont des capacités très solides dans les mises à jour, les itérations et l’intégration. Les modèles de génération.
Big Data décentralisé
D’un point de vue simple, l’utilisation de données privées pour alimenter les données AI et TAG est une direction très cohérente avec la blockchain. les projets bénéficient.Dans une perspective complexe, l’utilisation de données de blockchain pour l’apprentissage automatique (ML) pour résoudre l’accessibilité des données de blockchain est également une direction intéressante (l’une des directions d’exploration de Giza).
En théorie, les données de blockchain sont accessibles à tout moment, reflétant l’état de toute la blockchain.Mais pour ceux qui en dehors de l’écosystème de la blockchain, il n’est pas facile d’obtenir ces énormes quantités de données.Pour stocker entièrement une blockchain, il faut une riche expertise et une grande quantité de ressources matérielles spécialisées.Pour surmonter le défi d’accès aux données de la blockchain, plusieurs solutions ont émergé dans l’industrie.Par exemple, les fournisseurs de RPC accèdent aux nœuds via les API, tandis que les services d’indexation rendent la possible extraction des données via SQL et GraphQL, qui jouent tous deux un rôle clé dans la résolution de problèmes.Cependant, ces méthodes ont des limites.Les services RPC ne conviennent pas aux scénarios d’utilisation à haute densité qui nécessitent de grandes quantités de requêtes de données et ne peuvent souvent pas répondre aux besoins.Pendant ce temps, bien que les services d’indexation fournissent un moyen plus structuré de récupérer les données, la complexité du protocole Web3 rend extrêmement difficile la création de requêtes efficaces, nécessitant parfois des centaines, voire des milliers de lignes de code complexe.Cette complexité est un énorme obstacle pour les praticiens généraux des données et ceux qui n’ont pas une compréhension approfondie des détails de Web3.L’effet cumulatif de ces limitations met en évidence la nécessité d’un moyen plus facile d’accéder et d’utiliser des données de blockchain qui peuvent faciliter une application et une innovation plus larges dans le domaine.
Ensuite, via ZKML (Zero Knowledge Proof Machine Learning, réduisant la charge de la chaîne d’apprentissage automatique) combinée à des données de blockchain de haute qualité, il peut être possible de créer des ensembles de données qui résolvent l’accessibilité de la blockchain, tandis que l’IA peut réduire considérablement la blockchain .
Ai autorise Dapp
Étant donné que ChatGpt3 est devenu populaire dans 23 ans, l’IA autonomisant les DAPP est devenue une direction très courante.L’IA générative avec une utilité extrêmement répandue est accessible via des API, simplifiant et analysant ainsi intelligemment les plates-formes de données, échangeant des robots, l’encyclopédie blockchain et d’autres applications.D’un autre côté, vous pouvez également jouer comme un chatbot (comme MyShell) ou un compagnon AI (IA sans sommeil), et même créer des PNJ dans les jeux de chaîne via une IA générative.Cependant, en raison des faibles barrières techniques, la plupart d’entre eux sont affinés après avoir accédé à une API, et la combinaison avec le projet lui-même n’est pas parfaite, il est donc rarement mentionné.
Mais après l’arrivée de Sora, je crois personnellement que la direction de l’autonomisation de l’IA (y compris les plates-formes créatives de Metaverse) sera l’objectif du prochain objectif.En raison de la nature ascendante du champ Web3, il est certainement difficile de produire des produits qui rivalisent avec les jeux traditionnels ou les entreprises créatives, et l’émergence de Sora est susceptible de briser ce dilemme (peut-être seulement deux à trois ans).À en juger par la démo de Sora, il a déjà le potentiel de rivaliser avec les sociétés de drame de micro-short. -Dedouing Les industries traditionnelles seront brisées.
Conclusion
Avec l’avancement continu des outils d’IA génératifs, nous connaîtrons plus de «moments iPhone» de fabrication d’époches à l’avenir.Bien que de nombreuses personnes se moquent de la combinaison de l’IA et du Web3, je pense en fait que la plupart de la direction actuelle n’est pas un problème, et il n’y a en fait que trois points de douleur qui doivent être résolus, à savoir la nécessité, l’efficacité et l’ajustement.Bien que l’intégration des deux soit au stade d’exploration, elle n’empêche pas cette piste de devenir le courant dominant du prochain marché haussier.
Le maintien de la curiosité et de l’acceptation de nouvelles choses est toujours une mentalité nécessaire. manquer l’opportunité.







