
Autor: YBB Capital Zeke
Vorwort
Am 16. Februar kündigte OpenAI das neueste Textgenerierungsdiffusionsmodell „Sora“ mit der Videogenerierung an, das einen weiteren Meilenstein in der generativen KI durch hochwertige Generation von Videos einer Vielzahl von visuellen Datentypen zeigt, die von mehreren Segmenten abgedeckt werden.Im Gegensatz zu PIKA sind die Tools für die Videogeneration von AI immer noch im Zustand der Generierung von Videos für mehrere Sekunden mit mehreren Bildern, und hat Sora durch Training im komprimierten latenten Raum von Video und Bildern eine skalierbare Videogenerierung erreicht und sie in Raumzeitpatches zerlegt.Darüber hinaus spiegelt das Modell die Fähigkeit wider, die physische Welt und die digitale Welt zu simulieren.
In Bezug auf Konstruktionsmethoden setzte Sora den vorherigen technischen Pfad des GPT-Modells „Quelldaten-Transformator-Diffusion-Anstrengung“ fort, was bedeutet Das Video -Training ist viel größer als die des Textes. Die Datenmenge wird die Nachfrage nach Rechenleistung weiter erhöhen.Wir haben jedoch bereits die Bedeutung der Rechenleistung in der KI -Ära im frühen Artikel „Populärer Track Preview: Dezentraler Computerstrommarkt“ erörtert, und mit der jüngsten steigenden Beliebtheit der KI gibt es bereits eine große Anzahl von Computerleistung Projekte auf dem Markt.Welche Art von Funken kann zusätzlich zu Depin die Verflechtung von Web3 und AI kollidieren?Welche anderen Möglichkeiten enthält dieser Track?Der Hauptzweck dieses Artikels besteht darin, vergangene Artikel zu aktualisieren und zu vervollständigen und über die Möglichkeiten von Web3 in der KI -Ära nachzudenken.
Drei Hauptanweisungen in der Geschichte der KI -Entwicklung
Künstliche Intelligenz ist eine aufstrebende Wissenschaft und Technologie, die die menschliche Intelligenz simulieren, erweitert und verbessert.Seit seiner Geburt in den 1950er und 1960er Jahren ist die künstliche Intelligenz zu einer wichtigen Technologie geworden, um Veränderungen im sozialen Leben und alle Lebensbereiche nach mehr als einem halben Jahrhundert der Entwicklung zu fördern.In diesem Prozess ist die wechselvolle Entwicklung der drei Forschungsrichtungen von Symbolik, Konnektivität und Behaviorismus zum Eckpfeiler der rasanten Entwicklung der KI heute geworden.
Symbolismus
Es ist auch als Logikismus oder Regelismus bekannt und ist der Ansicht, dass es möglich ist, die menschliche Intelligenz durch Verarbeitung von Symbolen zu simulieren.Diese Methode verwendet Symbole, um Objekte, Konzepte und ihre Wechselbeziehungen innerhalb des Problembereichs darzustellen und zu betreiben. Sie verwendet logische Argumentation, um Probleme zu lösen, insbesondere in Expertensystemen und Wissensdarstellungen.Die Kernansicht der Symbolik ist, dass intelligentes Verhalten durch Operation und logisches Argumentieren von Symbolen erreicht werden kann, bei denen Symbole ein hohes Maß an Abstraktion der realen Welt darstellen.
Verbindungismus
Oder neuronale Netzwerkmethoden, die Intelligenz durch Nachahmung der Struktur und Funktionen des menschlichen Gehirns entwickeln sollen.Diese Methode ermöglicht das Lernen, indem ein Netzwerk zahlreicher einfacher Verarbeitungseinheiten (wie Neuronen) erstellt und die Stärke der Verbindung zwischen diesen Einheiten (wie Synapsen) angepasst wird.Der Connectionism betont die Fähigkeit, Daten zu lernen und zu verallgemeinern, und eignet sich besonders für Mustererkennung, Klassifizierung und kontinuierliche Eingabe- und Ausgangskartierungsprobleme.Deep Learning als Entwicklung des Konnektivismus hat Durchbrüche in Bereichen wie Bilderkennung, Spracherkennung und Verarbeitung natürlicher Sprache erzielt.
Behaviorismus
Behaviorismus ist eng mit der Erforschung bionischer Robotik und autonomer intelligenter Systeme verbunden und betont, dass Agenten durch Interaktion mit der Umwelt lernen können.Im Gegensatz zu den ersten beiden konzentriert sich der Behaviorismus nicht auf die Simulation interner Darstellungen oder Denkprozesse, sondern erreicht das adaptive Verhalten durch einen Zyklus von Wahrnehmung und Handeln.Behaviorismus ist der Ansicht, dass sich die Intelligenz durch dynamische Interaktion und Lernen mit der Umgebung manifestiert, was besonders effektiv ist, wenn es auf mobile Roboter und adaptive Steuerungssysteme angewendet wird, die Maßnahmen in komplexen und unvorhersehbaren Umgebungen erfordern.
Obwohl es in diesen drei Forschungsrichtungen wesentliche Unterschiede gibt, können sie auch interagieren und in die tatsächliche AI -Forschung und -anwendung integrieren, um die Entwicklung des KI -Bereichs gemeinsam zu fördern.
AIGC -Prinzipübersicht
Die künstliche Intelligenz erzeugte Inhalte (AIGC), die derzeit explosive Entwicklung erfolgt, eine Entwicklung und Anwendung des Konnektivitätsanwalts.Diese Modelle werden mit großen Datensätzen und tiefen Lernalgorithmen geschult, um die zugrunde liegenden Strukturen, Beziehungen und Muster zu lernen, die in den Daten vorhanden sind.Generieren Sie neuartige und eindeutige Ausgabeergebnisse basierend auf Eingabeinforderungen der Benutzer, einschließlich Bildern, Videos, Codes, Musik, Design, Übersetzungen, Frage -Antworten und Text.Das aktuelle AIGC besteht im Grunde genommen aus drei Elementen: Deep Learning (DL), Big Data und groß angelegte Computerleistung.
Tiefes Lernen
Deep Learning ist ein Unterfeld des maschinellen Lernens (ML), und Deep -Lern -Algorithmen sind neuronale Netzwerke, die nach dem menschlichen Gehirn modelliert werden.Zum Beispiel enthält das menschliche Gehirn Millionen von miteinander verbundenen Neuronen, die zusammenarbeiten, um Informationen zu lernen und zu verarbeiten.In ähnlicher Weise bestehen Deep Learning Neural Networks (oder künstliche neuronale Netzwerke) aus vielschichtigen künstlichen Neuronen, die in einem Computer zusammenarbeiten.Künstliche Neuronen sind Softwaremodule, die als Knoten bezeichnet werden und mathematische Berechnungen verwenden, um Daten zu verarbeiten.Künstliche neuronale Netze sind tiefe Lernalgorithmen, die diese Knoten verwenden, um komplexe Probleme zu lösen.
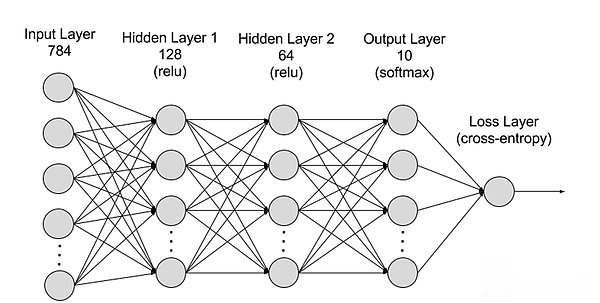
Das Teilen neuronaler Netzwerke aus einer Hierarchie kann in die Eingabebereich, die versteckte Schicht und die Ausgangsschicht unterteilt werden, und die Parameter werden zwischen verschiedenen Schichten verbunden.
-
Eingangsschicht: Die Eingabeschicht ist die erste Ebene des neuronalen Netzwerks, die für den Empfang externer Eingabedaten verantwortlich ist.Jedes Neuron in der Eingangsschicht entspricht einer Funktion der Eingabedaten.Bei der Verarbeitung von Bilddaten kann jedes Neuron einem Pixelwert des Bildes entsprechen.
-
Versteckte Schicht: Die Eingabeschicht verarbeitet die Daten und übergibt sie im neuronalen Netzwerk an eine weitere Ebene.Diese versteckten Ebenen verarbeiten Informationen auf unterschiedlichen Ebenen und passen ihr Verhalten an, wenn sie neue Informationen erhalten.Deep Learning Networks haben Hunderte von versteckten Schichten, mit denen Probleme aus mehreren verschiedenen Blickwinkeln analysiert werden können.Wenn Sie beispielsweise ein Bild eines unbekannten Tieres erhalten, das klassifiziert werden muss, können Sie es mit einem Tier vergleichen, das Sie bereits kennen.Zum Beispiel können wir beurteilen, welches Tier dies auf der Form des Ohrs, der Anzahl der Beine und der Größe der Schüler basiert.Versteckte Schichten in tiefen neuronalen Netzwerken funktionieren auf die gleiche Weise.Wenn ein tiefer Lernalgorithmus versucht, Tierbilder zu klassifizieren, verarbeitet jeder seiner verborgenen Schichten verschiedene Merkmale des Tieres und versucht, sie genau zu klassifizieren.
-
Ausgangsschicht: Die Ausgangsschicht ist die letzte Ebene des neuronalen Netzwerks, die für die Generierung der Ausgabe des Netzwerks verantwortlich ist.Jedes Neuron in der Ausgangsschicht repräsentiert eine mögliche Ausgangskategorie oder einen möglichen Wert.In einem Klassifizierungsproblem kann beispielsweise jedes Ausgangsschicht -Neuron einer Kategorie entsprechen, während in einem Regressionsproblem die Ausgangsschicht nur ein Neuron haben kann, dessen Wert das Vorhersageergebnis darstellt;
-
Parameter: In neuronalen Netzwerken werden die Verbindungen zwischen verschiedenen Schichten durch Gewichte und Verzerrungsparameter dargestellt, die während des Trainings optimiert werden, damit das Netzwerk Muster in den Daten genau identifizieren und Vorhersagen treffen kann.Die Erhöhung der Parameter kann die Modellkapazität des neuronalen Netzwerks erhöhen, d. H. Die Fähigkeit des Modells, komplexe Muster in den Daten zu lernen und darzustellen.Der entsprechende Anstieg der Parameter erhöht jedoch die Nachfrage nach Rechenleistung.
Big Data
Für eine effektive Schulung erfordern neuronale Netze in der Regel große, vielfältige, qualitativ hochwertige und Multi-Source-Daten.Es ist die Grundlage für das Modell und die Überprüfung des Modells für maschinelles Lernen.Durch die Analyse von Big Data können maschinelle Lernmodelle Muster und Beziehungen in den Daten lernen, um Vorhersagen oder Klassifizierungen vorzunehmen.
Große Computerleistung
Die mehrschichtige komplexe Struktur neuronaler Netzwerke, eine große Anzahl von Parametern, Anforderungen an die Big-Data-Verarbeitung, iterative Trainingsmethoden (in der Trainingsphase muss das Modell wiederholt iteriert, und während des Trainingsprozesses müssen sich verbreiten und zurückpropagieren Jede Berechnungsschicht, einschließlich Aktivierungsfunktionen Die Berechnung der Verlustfunktion, die Berechnung des Gradienten und die Aktualisierung von Gewichten, die Anforderungen der Berechnung der Hochvorbereitungsberechnung, der parallelen Rechenleistung, der Optimierung und der Regularisierungstechnologie sowie der Modellbewertung und Überprüfungsprozesse haben LED- zu ihrer Nachfrage nach hoher Rechenleistung.

Sora
Als das neueste KI -Modell von OpenAI ist Sora einen großen Fortschritt in der Fähigkeit der künstlichen Intelligenz, verschiedene visuelle Daten zu verarbeiten und zu verstehen.Durch die Einführung von Videokomprimierungsnetzwerk und Space Time Patch -Patch -Technologie kann Sora massive visuelle Daten von verschiedenen Geräten auf der ganzen Welt in eine einheitliche Expressionsform umwandeln und so eine effiziente Verarbeitung und das Verständnis komplexer visueller Inhalte erreichen.Sora, die sich auf das Text-konditionierte Diffusionsmodell stützt, kann hoch übereinstimmende Videos oder Bilder basierend auf Texteingabeaufforderungen erzeugen und extrem hohe Kreativität und Anpassungsfähigkeit zeigen.
Trotz der Durchbrüche von Sora in der Videogenerierung und der Simulation der realen Interaktionen konfrontiert jedoch einige Einschränkungen, einschließlich der Genauigkeit physischer Weltsimulationen, der Konsistenz der langen Videogenerierung, des Verständnisses komplexer Textanweisungen sowie der Trainings- und Erzeugungseffizienz.Im Wesentlichen setzt Sora den alten technischen Weg von „Big Data-Transformler-Diffusion-Emgenz“ durch OpenAs Monopol-Computermacht und First-Mover-Vorteil fort und hat eine gewalttätige Ästhetik erhalten .
Obwohl Sora wenig mit Blockchain zu tun hat, denke ich persönlich, dass es die nächsten ein oder zwei Jahre dauern wird.Da Soras Einfluss andere hochwertige KI-Generationstools dazu zwingen wird, sich schnell zu entwickeln und sich schnell zu entwickeln, und auf mehrere Spuren wie GameFi, soziale Netzwerke, kreative Plattformen und Depin in Web3 ausstrahlen, ist es notwendig, ein allgemeines Verständnis von Sora zu haben. Wie KI in der Zukunft effektiv mit Web3 kombiniert wird, kann ein wichtiger Punkt sein, über den wir nachdenken müssen.
Vier wichtige Wege zu AI X Web3
Wie oben erwähnt, können wir wissen, dass für generative AI tatsächlich nur drei Grundlagen erforderlich sind: Algorithmen, Daten und Rechenleistung. .Die größte Rolle der Blockchain ist zwei: Rekonstruktion von Produktionsbeziehungen und Dezentralisierung.Ich persönlich denke also, dass es vier Möglichkeiten gibt, eine Kollision zwischen den beiden zu erzeugen:
Dezentrale Rechenleistung
Da wir in der Vergangenheit verwandte Artikel geschrieben haben, besteht der Hauptzweck dieses Absatzes darin, die jüngste Situation des Rechenleistungspurs zu aktualisieren.Wenn es um KI geht, ist die Rechenleistung immer eine schwierige Verbindung zur Umgehung.Die große Nachfrage nach Rechenleistung von KI ist nach der Geburt von Sora bereits unvorstellbar.Kürzlich sagte Openai CEO Ultraman, während des Weltwirtschaftsforums 2024 in Davos, der Schweiz, die größten Fesseln in dieser Phase sind, und die Bedeutung der beiden in Zukunft wird sogar der Währung entsprechen.Am 10. Februar veröffentlichte Ultraman SAM einen äußerst erstaunlichen Plan, um 7 Billionen US -Dollar (entspricht 40% des nationalen BIP Chinas in 23 Jahren), um die derzeitige globale Halbleiterindustrie umzuschreiben.Beim Schreiben von Artikeln, die sich auf die Rechenleistung handeln, beschränkt sich meine Fantasie immer noch auf nationale Blockade und die Giants monopolisieren sie wirklich verrückt, um die globale Halbleiterindustrie zu kontrollieren.
Daher ist die Bedeutung der dezentralen Rechenleistung natürlich selbstverständlich.Aus der Sicht der KI kann die Verwendung von Rechenleistung in zwei Richtungen unterteilt werden: Denkweise und Schulung. Die Nachfrage ist eine Richtung mit extrem hoher Schwelle und äußerst schwierig umzusetzen.Die Argumentation ist relativ einfach.
Der Vorstellungsraum des zentralen Rechenleistungspunkts ist riesig und ist häufig mit dem Schlüsselwort „Billionen) verbunden.Nach der großen Anzahl von Projekten zu urteilen, die in letzter Zeit entstanden sind, stehen die meisten immer noch in den Regalen und nutzen die Popularität.Halten Sie immer das richtige Banner der Dezentralisierung, aber schweigen Sie über die Ineffizienz dezentraler Netzwerke.Und es gibt ein hohes Maß an Homogenität im Design, und eine große Anzahl von Projekten ist sehr ähnlich (One-Click-L2-Plus-Bergbaudesign), was möglicherweise zu einem Chaos führen kann. Track in einer solchen Situation.
Algorithmus und Modellkollaborationssystem
Algorithmen für maschinelles Lernen beziehen sich darauf, dass diese Algorithmen in der Lage sind, Gesetze und Muster aus Daten zu erlernen und auf der Grundlage von ihnen Vorhersagen oder Entscheidungen zu treffen.Algorithmen sind technologisch intensiv, da ihr Design und ihre Optimierung ein tiefes Fachwissen und technologische Innovationen erfordern.Algorithmen sind im Mittelpunkt der Trainings -KI -Modelle, die definieren, wie Daten in nützliche Erkenntnisse oder Entscheidungen übersetzt werden.Häufiger generative AI -Algorithmen wie generative kontroverse Netzwerke (GANS), Variation Autocoder (VAES) und Transformers. Und dann wird ein dediziertes KI -Modell durch Algorithmen trainiert.
So viele Algorithmen und Modelle haben ihre eigenen Vorteile.Bittensor, das in letzter Zeit beliebt war, ist führend in dieser Richtung.Die KI (Code Collaboration) und andere Aspekte basieren auch hauptsächlich auf dieser Richtung.
Daher ist die Erzählung des KI -Kollaborationsökosystems neu und interessant.Schließlich haben die Closed-Source-Algorithmen und -modelle führender KI-Unternehmen sehr starke Fähigkeiten in Aktualisierungen, Iterationen und Integration. Generationsmodelle.
Dezentrale Big Data
Aus einfacher Sicht ist die Verwendung privater Daten zur Fütterung von KI und Tag -Daten eine sehr konsistente Richtung mit Blockchain Projekte profitieren.Aus komplexer Perspektive ist die Verwendung von Blockchain -Daten für maschinelles Lernen (ML) zur Lösung der Zugänglichkeit von Blockchain -Daten auch eine interessante Richtung (eine der Explorationsanweisungen von Giza).
Theoretisch können jederzeit auf Blockchain -Daten zugegriffen werden, was den Status der gesamten Blockchain widerspiegelt.Für diejenigen außerhalb des Blockchain -Ökosystems ist es jedoch nicht einfach, diese riesigen Datenmengen zu erhalten.Um eine Blockchain voll zu speichern, erfordert ein reichhaltiges Know -how und eine große Anzahl spezialisierter Hardware -Ressourcen.Um die Herausforderung des Zugriffs auf Blockchain -Daten zu überwinden, haben sich in der Branche mehrere Lösungen entstanden.Beispielsweise greifen RPC -Anbieter über APIs Knoten zu, während die Indexierungsdienste die Datenextraktion über SQL und GraphQL ermöglichen, die beide eine Schlüsselrolle bei der Lösung von Problemen spielen.Diese Methoden haben jedoch Einschränkungen.RPC-Dienste eignen sich nicht für Szenarien mit hoher Dichte, die große Mengen an Datenabfragen erfordern und die Bedürfnisse häufig nicht erfüllen können.Obwohl die Indexierungsdienste eine strukturiertere Möglichkeit zum Abrufen von Daten bieten, macht es die Komplexität des Web3 -Protokolls äußerst schwierig, effiziente Abfragen zu erstellen. Manchmal erfordert es Hunderte oder sogar Tausende von komplexen Code.Diese Komplexität ist ein großes Hindernis für allgemeine Datenpraktiker und diejenigen, die nicht ein tiefes Verständnis für Web3 -Details haben.Der kumulative Effekt dieser Einschränkungen unterstreicht die Notwendigkeit einer einfacheren Möglichkeit, Blockchain -Daten zuzugreifen und zu verwenden, die eine breitere Anwendung und Innovation im Bereich erleichtern können.
Durch ZKML (Zero Knowledge Proof Machine Learning, das die Belastung der Kette des maschinellen Lernens in Kombination mit hochwertigen Blockchain-Daten verringert, kann es möglich sein, Datensätze zu erstellen, die die Zugänglichkeit von Blockchain lösen, während KI Blockchain erheblich reduzieren kann Der Schwellenwert für die Zugänglichkeit von Daten, so dass Entwickler, Forscher und Enthusiasten im ML-Bereich im Laufe der Zeit auf mehr hochwertige, relevante Datensätze zum Aufbau effektiver und innovativer Lösungen zugreifen können.
KI ermächtigt Dapp
Seit Chatgpt3 in 23 Jahren populär wurde, ist KI die Stärkung von Dapps zu einer sehr häufigen Richtung geworden.Die generative KI mit äußerst weit verbreiteter Nützlichkeit kann über APIs zugegriffen werden, wodurch Datenplattformen, Handelsroboter, Blockchain -Enzyklopädie und andere Anwendungen vereinfacht und intelligent analysiert werden.Auf der anderen Seite können Sie auch als Chatbot (wie Myshell) oder AI -Begleiter (schlaflose KI) spielen und sogar NPCs in Kettenspielen durch generative KI erstellen.Aufgrund der niedrigen technischen Hindernisse sind die meisten nach dem Zugriff auf eine API fein abgestimmt, und die Kombination mit dem Projekt selbst ist nicht perfekt, so dass sie selten erwähnt wird.
Aber nachdem Sora eingetreten ist, glaube ich persönlich, dass die Richtung der KI -Stärkung von GameFi (einschließlich der Metaverse) und der kreativen Plattformen im Mittelpunkt des nächsten Fokus stehen wird.Aufgrund des Tiefpunkts des Web3-Feldes ist es definitiv schwierig, Produkte zu produzieren, die mit traditionellen Spielen oder kreativen Unternehmen konkurrieren, und die Entstehung von Sora wird wahrscheinlich dieses Dilemma brechen (vielleicht nur zwei bis drei Jahre).Nach Soras Demo zu beurteilen, kann es bereits das Potenzial haben, mit Micro-Short-Drama-Unternehmen zu konkurrieren. -Die traditionellen Industrien werden unterbrochen.
Abschluss
Mit der kontinuierlichen Weiterentwicklung generativer KI-Tools werden wir in Zukunft mehr „iPhone-Momente“ von Epochen machen.Obwohl viele Menschen über die Kombination von AI und Web3 spotteten, denke ich tatsächlich, dass der größte Teil der aktuellen Richtung kein Problem ist, und es gibt tatsächlich nur drei Schmerzpunkte, die gelöst werden müssen, nämlich Notwendigkeit, Effizienz und Passform.Obwohl sich die Integration der beiden in der Erkundungsstufe befindet, verhindert sie nicht, dass diese Strecke zum Mainstream des nächsten Bullenmarktes wird.
Immer Neugier und Akzeptanz neuer Dinge ist für uns eine notwendige Mentalität vermissen die Gelegenheit.







