
Nota: Este artículo es la segunda parte de la serie de artículos publicados recientemente por Vitalik, fundador de Ethereum, «El futuro del acuerdo de Ethereum»Posibles futuros para el Protocolo Ethereum, Parte 2: El aumento«, La primera parte se muestra en el informe anterior de la visión de Bittain»¿Qué más se puede mejorar en Ethereum POS?«Compilado por Deng Tong, el siguiente es el texto completo de la segunda parte:
Al principio, había dos estrategias de escala en la hoja de ruta de Ethereum.
Uno de ellos es «fragmentar»: Cada nodo solo necesita verificar y almacenar una pequeña porción de transacciones, no todas las transacciones en la cadena.Así es como funciona cualquier otra red entre pares (por ejemplo, BitTorrent), por lo que ciertamente podemos hacer que la cadena de bloques funcione de la misma manera.
El otro es el protocolo de 2 capas:Las redes estarán en la cima de Ethereum, lo que les permitirá beneficiarse completamente de su seguridad mientras mantiene la mayoría de los datos y la computación lejos de la cadena principal.El «Protocolo de capa 2» se refiere al canal de estado 2015, el Plasma 2017 y los rollups 2019.Los rollups son más potentes que los canales de estado o el plasma, pero requieren mucho ancho de banda de datos en la cadena.
Afortunadamente, para 2019, Sharding Research ha abordado el tema de la verificación a gran escala de la «disponibilidad de datos».Como resultado, los dos caminos se fusionaron y obtuvimos una hoja de ruta centrada en el rollo, que todavía es la estrategia de escala de Ethereum hoy en día.
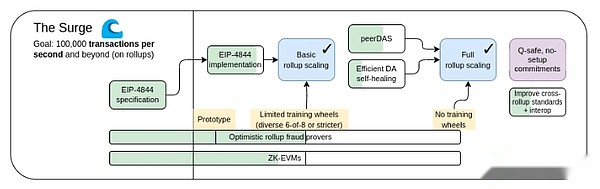
The Surge, 2023 Roadmap Edition.
La hoja de ruta centrada en el rollup propone una división simple del trabajo: Ethereum L1 se enfoca en convertirse en una capa de base fuerte y descentralizada, mientras que L2 realiza la tarea de ayudar a la escala del ecosistema.Este es un patrón recurrente en toda la sociedad: el sistema judicial (L1) no es para súper rápido y eficiente, sino para proteger los contratos y los derechos de propiedad, mientras que el empresario (L2) necesita construir una capa de base sólida sobre esta base y llevar a los humanos a (metafóricamente y literalmente) Marte.
Este año, la hoja de ruta centrada en el rollo ha logrado un éxito significativo: el ancho de banda de datos de Ethereum L1 ha aumentado significativamente a través de las blobs EIP-4844, y los múltiples rollups EVM ahora están en la fase uno.Implementaciones muy heterogéneas y diversificadas de fragmentos, donde cada L2 actúa como un «fragmento» con sus propias reglas y lógica internas es ahora una realidad.Pero como hemos visto, ir a este camino tiene sus propios desafíos únicos.por lo tanto,Ahora nuestra misión es completar la hoja de ruta centrada en el rollup y resolver estos problemas mientras retiene la robustez y la descentralización que distingue a Ethereum L1.
Surge: objetivos clave
L1+ L2 en más de 100,000 tps
Mantener la descentralización y la robustez de L1
Al menos algunos L2s heredan completamente los atributos centrales de Ethereum (sin censura, sin censura)
Interoperabilidad máxima entre L2S.Ethereum debe sentirse como un ecosistema, no 34 blockchains diferentes.
La tríada de escalabilidad
El triángulo imposible de escalabilidad es una idea propuesta en 2017 que cree que existe tensión entre las tres propiedades de blockchain: descentralización (más específicamente: bajo costo de los nodos en ejecución), escalabilidad (más específicamente: maneja una gran cantidad de transacciones) y seguridad de seguridad (Más específicamente: un atacante necesita destruir la mayoría de los nodos en toda la red para hacer que una sola transacción falle).
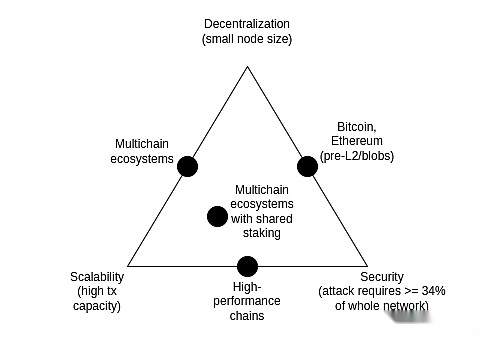
Vale la pena señalar que el dilema de la tríada no es un teorema, y las publicaciones que introducen el dilema de la tríada no vienen con pruebas matemáticas.Da un argumento matemático heurístico: si un nodo amigable descentralizado (como una computadora portátil de consumo) puede verificar n transacciones por segundo, y tiene una cadena que procesa k*n transacciones por segundo, entonces (i) cada transacción solo se puede ver En los nodos de 1/k, lo que significa que un atacante solo puede romper unos pocos nodos para impulsar transacciones malas, o (ii) su nodo se volverá fuerte y su cadena no está descentralizada.El propósito de este artículo es nunca mostrar que romper la tríada es imposible;
Con los años, algunas cadenas de alto rendimiento a menudo han afirmado que resolvieron la tríada sin tomar medidas inteligentes a nivel de infraestructura, a menudo mediante el uso de habilidades de ingeniería de software para optimizar los nodos.Esto siempre es engañoso, y ejecutar nodos en tales cadenas siempre es mucho más difícil que en Ethereum.Esta publicación explora muchas sutilezas de por qué esto sucede (y por qué la ingeniería de software del cliente L1 no puede escalar Ethereum solo).
Sin embargo,La combinación de muestreo de disponibilidad de datos (DAS) y Snark resuelve la tríada: Permite al cliente verificar que hay una cierta cantidad de datos disponibles y si un cierto número de pasos de cálculo se realiza correctamente, mientras que solo se descarga una pequeña parte de esos datos y la cantidad de cálculos se ejecutan mucho.Snark no es creíble.El muestreo de disponibilidad de datos tiene un modelo sutil de confianza minoritaria N, pero conserva las propiedades básicas que tienen las cadenas no escalables, e incluso el 51% de los ataques no pueden obligar a la red a aceptar bloques malos.
Otra forma de resolver la tríada es la arquitectura de plasma, que utiliza técnicas inteligentes para impulsar la responsabilidad de monitorear la disponibilidad de datos a los usuarios de una manera compatible incentivada.En 2017-2019, cuando todo lo que necesitábamos para escalar la informática era a prueba de fraude, las capacidades de seguridad de Plasma eran muy limitadas, pero la creación de la transmisión de la arquitectura de plasma hizo que la arquitectura de plasma fuera más adecuada para una gama más amplia de casos de uso que antes.
Más progreso en DAS
¿Qué problemas queremos resolver?
A partir del 13 de marzo de 2024, cuando la actualización de Dencun se puso en marcha, la cadena de bloques Ethereum tenía 3 «blobs» de aproximadamente 125 kb cada período de 12 segundos, o aproximadamente 375 kb de datos disponibles de ancho de banda por período.Suponiendo que los datos de la transacción se publiquen directamente en la cadena, la transmisión ERC20 es de aproximadamente 180 bytes, por lo que el TPS máximo de rollups en Ethereum es:
375000 / 12/180 = 173.6 TPS
Si agregamos los callicos de Ethereum (máximo teórico: 30 millones de gas por ranura / 16 gas por byte = 1,875,000 bytes por ranura), esto se convertirá en 607 TPS.Para Peerdas, se planea aumentar el objetivo de recuento de blob a 8-16, lo que nos dará un campo de llamada de 463-926 TPS.
Esta es una mejora significativa sobre Ethereum L1, pero eso no es suficiente.Queremos más escalabilidad.Nuestro objetivo a mitad de período es de 16 MB por ranura, que, si se combina con mejoras en la compresión de datos de sumidero, nos dará alrededor de 58,000 TP.
¿Qué es Peerdas y cómo funciona?
Peerdas es una implementación relativamente simple de «muestreo unidimensional».Cada blob en Ethereum es un polinomio de 4096 orden en el dominio Prime de 253 bits.Transmitimos las «acciones» del polinomio, donde cada acción consta de 16 evaluaciones en 16 coordenadas adyacentes tomadas de un conjunto total de 8192 coordenadas.El Blob puede ser restaurado por cualquier 4096 de 8192 evaluaciones (utilizando los parámetros recomendados actualmente: cualquier 64 de 128 muestras posibles).
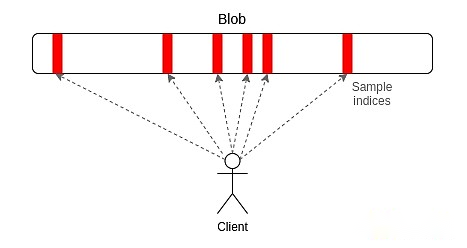
Peerdas funciona haciendo que cada cliente escuche una pequeña red cuántica, donde la subred i-th transmita la muestra i-th de cualquier blob y también solicita lo que se necesita en otras subredes preguntando a los compañeros en la red global de P2P (quién lo hará. Escuche diferentes subredes).La versión más conservadora de subnetas usa solo el mecanismo de la subred y no tiene capas de pares de solicitud adicionales.La recomendación actual es que los nodos que participan en la prueba de estaca de uso subnetas y los otros nodos (es decir, el «cliente») usan Peerdas.
En teoría, podemos escalar el muestreo 1D bastante lejos: si aumentamos el recuento de blob como máximo a 256 (por lo que el objetivo es 128), llegaremos al objetivo de 16 MB, mientras que el muestreo de disponibilidad de datos solo cuesta 16 muestras de nodo* 128 Blobs* 512 bytes por blob por muestra = 1 Mb de ancho de banda de datos por ranura.Esto está solo dentro de nuestra tolerancia: es factible, pero significa que los clientes de ancho de banda limitado no pueden probar.Podemos optimizar esto reduciendo la cantidad de blobs y aumentando el tamaño de las blobs, pero esto hace que la reconstrucción sea más costosa.
Entonces, en última instancia, queremos ir un paso más allá y hacer un muestreo 2D, que no solo muestras al azar dentro del blob, sino también entre blobs.Las propiedades lineales prometidas por KZG se utilizan para «extender» el blob establecido en un bloque al codificar redundantemente las nuevas listas de «blobs virtuales».
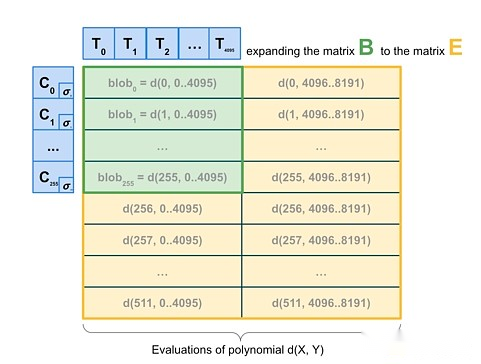
2D Muestreo.
De manera crucial, la escala computacionalmente prometida no requiere blobs, por lo que el esquema es fundamentalmente amigable para la construcción de bloques distribuidos.Los nodos que realmente construyen el bloque solo necesitan tener promesas de blob kzg y pueden confiar en DAS para verificar la disponibilidad de blobs.1D DAS también es esencialmente amigable con la construcción de bloques distribuidos.
¿Cuáles son las conexiones con la investigación existente?
Artículo original que presenta la disponibilidad de datos (2018):https://github.com/ethereum/research/wiki/a-note-on-data-availability-and-erasure-coding
Documentos de seguimiento:https://arxiv.org/abs/1809.09044
Post de intérprete para Das, paradigma:https://www.paradigm.xyz/2022/08/das
KZG prometió disponibilidad 2D:https://ethresear.ch/t/2d-data-availability-with-kate-commitments/8081
Peerdas en EthResear.CH:https://ethresear.ch/t/peerdas-a-simpler-ras-parroach-using-battle-tested-p2p-components/16541Y documentos:https://eprint.iacr.org/2024/1362
EIP-7594:https://eips.ethereum.org/eips/eip-7594
Subnetas en ethresear.ch:https://ethresear.ch/t/subnetdas-an-intermediate-das-parcoach/17169
Diferencias sutiles en la capacidad de recuperación en el muestreo 2D:https://ethresear.ch/t/nuances-of-data-recoverability-in-data-availability-sampling/16256
¿Qué más hay que hacer y qué compensaciones deben sopesarse?
El siguiente paso es completar la implementación y el despliegue de Peerdas.Desde entonces, aumentar el recuento de blob en Peerdas es un esfuerzo gradual, mientras observa cuidadosamente la red y mejora el software para la seguridad.Al mismo tiempo, esperamos hacer más trabajo académico sobre la formalización de DAS y otras versiones de DAS y su interacción con problemas como la seguridad de las reglas de selección de bifurcaciones.
En el futuro, necesitamos hacer más para descubrir la versión ideal de 2D DAS y demostrar sus características de seguridad.También esperamos migrar eventualmente de KZG a una alternativa resistente a la cuántica sin una configuración confiable.Por el momento, no sabemos qué candidatos son amigables con la construcción de bloques distribuidos.Incluso la costosa técnica «fuerte» para usar Stark recursivo para generar pruebas de validez para reconstruir filas y columnas no es suficiente, porque técnicamente el tamaño de hash de Stark es o (log (n) * log (log (n))) (con agitación ), Stark es en realidad casi tan grande como todo el lugar.
A la larga, creo que el camino de la realidad es:
-
Herramienta DAS 2D ideal;
-
Sigue a 1D DAS, sacrificando la eficiencia del ancho de banda de muestreo por simplicidad y robustez y aceptando límites de datos más bajos;
-
(Pivote duro) Renuncia a DA y abrazca el plasma por completo como la arquitectura principal de nivel 2 en la que nos centramos.
Podemos verlos sopesando el alcance:
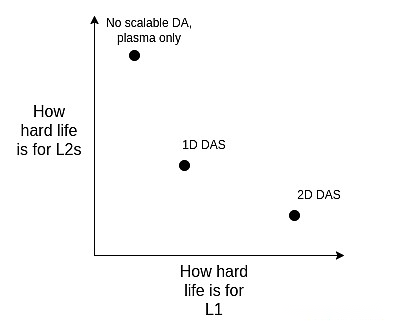
Tenga en cuenta que incluso si decidimos extender la ejecución directamente en L1, esta elección permanece.Esto se debe a que si L1 manejará una gran cantidad de TPS, los bloques L1 se volverán muy grandes y el cliente necesitará una forma eficiente de verificar que sean correctos, por lo que tenemos que usar las mismas técnicas que admiten el acurrucado (ZK -Evm y Das) y L1.
¿Cómo interactúa con el resto de la hoja de ruta?
Si se implementa la compresión de datos (ver más abajo), la demanda de DAS 2D se reducirá, o al menos se retrasará, y si el plasma se usa ampliamente, la demanda de DAS 2D se reducirá aún más.DAS también presenta desafíos a los protocolos y mecanismos de construcción de bloques distribuidos: aunque DAS es teóricamente amigable con la reconstrucción distribuida, debe combinarse en la práctica con el mecanismo de selección de la horquilla que incluye propuestas de listas y su entorno.
Compresión de datos
¿Qué problemas queremos resolver?
Cada transacción en el encierro ocupa mucho espacio de datos en la cadena: la transmisión ERC20 toma aproximadamente 180 bytes.Esto limita la escalabilidad del protocolo de capa 2 incluso cuando se usa el muestreo ideal de disponibilidad de datos.16 MB por ranura, obtenemos:
16000000 / 12/180 = 7407 TPS
¿Qué pasa si podemos resolver el denominador además de resolver el numerador y hacer que cada transacción en el encierro tome menos bytes en la cadena?
¿Qué es y cómo funciona?
Creo que la mejor explicación es esta imagen de hace dos años:
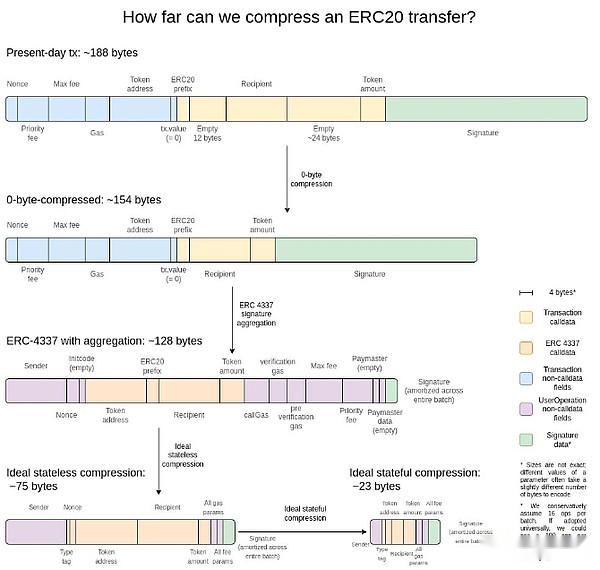
La ganancia más simple es la compresión de cero bytes: reemplace cada secuencia de cero bytes larga con dos bytes que representan el número de cero-bytes.Yendo más allá, aprovechamos las propiedades específicas de la transacción:
-
Agregación de la firma– Cambiamos de la firma ECDSA a la firma BLS, que tiene propiedades que pueden combinar muchas firmas juntas para formar una sola firma que demuestra la validez de todas las firmas originales.L1 no considera esto porque el costo computacional de la validación (incluso usando la agregación) es más alto, pero en entornos de datos escasos como L2, lo hacen posiblemente significativo.La función de agregación de ERC-4337 proporciona una forma de lograr esto.
-
Reemplazar la dirección con punteros-Si ha usado una dirección antes, podemos reemplazar la dirección de 20 bytes con un puntero de 4 bytes a la ubicación histórica.Esto es necesario para lograr la máxima ganancia, aunque requiere un esfuerzo para lograr, ya que requiere (al menos parte de) la historia de blockchain ser efectivamente parte del país.
-
Serialización personalizada de los valores de transacción– La mayoría de los valores de transacción tienen solo muy pocos números, por ejemplo.0.25 ETH se expresa como 250,000,000,000,000,000,000 Wei.Gas Max-Basefees funciona de manera similar a las tarifas prioritarias.Por lo tanto, podemos usar formatos de punto flotante decimales personalizados, o incluso diccionarios de valores particularmente comunes, que representan la mayoría de los valores monetarios de manera muy compacta.
¿Cuáles son las conexiones con la investigación existente?
Exploración de secuence.xyz:https://sequence.xyz/blog/compressing-calldata
CallData Optimization Contracts para L2, de Scopelift:https://github.com/scopelift/l2-optimizooors
Otra estrategia: Rollup (también conocido como ZKRollup) basada en la prueba de validez de las diferencias de estado de liberación en lugar de las transacciones:https://ethresear.ch/t/rollup-diff-compression-application-level-compression-strategies-to-reduce-the-l2-data-footprint-on-l1/9975-l2-Data Footprint
Billetera BLS – agregación BLS a través de ERC -4337:https://github.com/getwax/bls-wallet
¿Qué más hay que hacer y qué compensaciones deben sopesarse?
La tarea principal que queda por hacer es implementar el plan anterior.Las principales compensaciones son:
-
Cambiar a las firmas BLS requiere un gran esfuerzo y reduce la compatibilidad con chips de hardware de confianza que mejoran la seguridad.Puede ser reemplazado por el envoltorio ZK-Snark de otros esquemas de firma.
-
La compresión dinámica (como reemplazar la dirección con punteros) complica el código del cliente.
-
Publicar las diferencias de estado a una cadena en lugar de una transacción reduce la auditabilidad y hace que muchos software (como los navegadores de bloques) sean incapacitados.
¿Cómo interactúa con el resto de la hoja de ruta?
La adopción de ERC-4337, y la incorporación final de parte de su contenido en L2 EVM, puede acelerar en gran medida el despliegue de la tecnología de agregación.La incorporación de partes de ERC-4337 en L1 puede acelerar su despliegue en L2.
Plasma generalizado
¿Qué problemas queremos resolver?
Incluso con 16 manchas de MB y compresión de datos, 58,000 TP no es necesariamente suficiente para asumir completamente los pagos del consumidor, las áreas sociales descentralizadas u otras áreas de alto ancho de banda, lo cual es especialmente cierto si comenzamos a pensar en la privacidad, lo que podría hacer que la escalabilidad sea menos de 3 -8x.Para aplicaciones de gran capacidad y de bajo valor, una opción hoy es Validium, que pone los datos fuera de la cadena y tiene un modelo de seguridad interesante en el que los operadores no pueden robar los fondos de los usuarios, pero pueden desaparecer y congelar temporal o permanentemente todos los fondos de los usuarios .Pero podemos hacerlo mejor.
¿Qué es y cómo funciona?
Plasma es una solución de extensión que involucra a los operadores que publican bloques fuera de la cadena y colocan las raíces de Merkle de estos bloques en la cadena (a diferencia de los rollups, los rollups están colocando todo el bloque en la cadena).Para cada bloque, el operador envía una rama de Merkle a cada usuario, demostrando lo que sucedió o nada pasó con los activos de ese usuario.Los usuarios pueden extraer activos proporcionando rama de Merkle.Es importante destacar que la sucursal no tiene que estar enraizada en el último estado, por lo que incluso si la disponibilidad de datos falla, los usuarios aún pueden recuperar sus activos revocando el último estado disponible.Si un usuario envía una rama inválida (por ejemplo, salir de un activo que ha enviado a otra persona, o el operador crea un activo de la nada), el mecanismo de desafío en la cadena puede determinar a quién pertenece el activo correctamente.
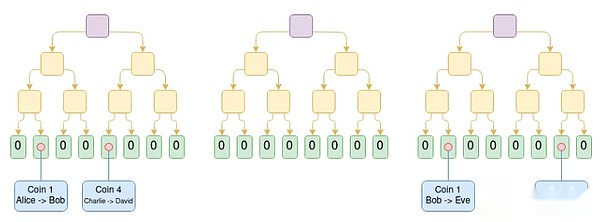
Diagrama de la cadena de efectivo de plasma.La transacción de la moneda de costo I se coloca en la posición I-Th en el árbol.En este ejemplo, suponiendo que todos los árboles anteriores son válidos, sabemos que Eve actualmente posee Coin 1, David tiene Moned 4 y George tiene Coin 6.
Las versiones tempranas de Plasma solo pueden manejar los casos de uso de pagos y no pueden promover más de manera efectiva.Sin embargo, si requerimos que cada raíz se verifique con Snark, entonces el plasma se vuelve más poderoso.Cada juego de desafío puede simplificarse enormemente porque eliminamos la mayoría de los caminos posibles para hacer trampa del operador.También se han abierto nuevas rutas, lo que permite que la tecnología de plasma se expanda a una gama más amplia de clases de activos.Finalmente, los usuarios pueden retirar fondos inmediatamente sin esperar una semana de desafío sin esperar el período de desafío.
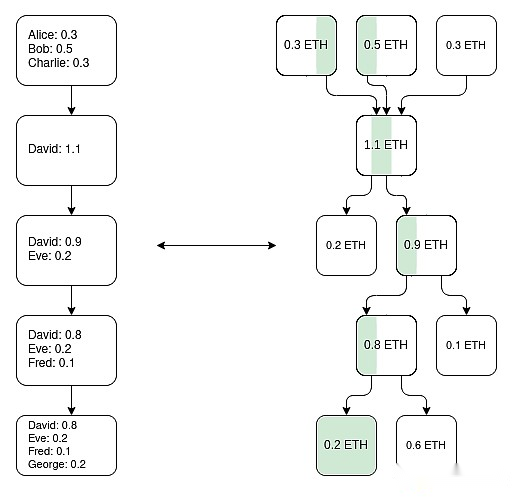
Una forma de hacer cadenas de plasma EVM (no es la única forma): construya un árbol Utxo paralelo usando ZK-snark, reflejando los cambios de equilibrio realizados por EVM y definiendo cuál es el mapeo único de la «misma moneda» en la historia.Entonces puede construir la estructura de plasma sobre esta base.
Una idea importante es que los sistemas de plasma no necesitan ser perfectos.Incluso si solo puede proteger una parte de sus activos (por ejemplo, incluso si son solo fichas que no se han movido en la semana pasada), ha mejorado enormemente el status quo de EVM hiperscalable, lo cual es una validación.
Otro tipo de estructura es una estructura híbrida de plasma/rollups, como Intmax.Estas estructuras ponen una cantidad muy pequeña de datos en una cadena (por ejemplo, 5 bytes), y al hacerlo, puede obtener propiedades entre el plasma y el encierro: en el caso intmax, puede obtener la escalabilidad y la privacidad de muy altos niveles, incluso en el 16 MB World, la capacidad teórica es de aproximadamente 16,000,000 / 12 /5 = 266,667 TPS.
¿Cuáles son las conexiones con la investigación existente?
Papel de plasma original:https://plasma.io/plasma-deprecated.pdf
Efectivo de plasma:https://ethresear.ch/t/plasma-cash-plasma-with-much-less-per-user-data-chetking/1298
Flujo de efectivo de plasma:https://hackmd.io/dgzmjirjszcyvl4lujzxnq?view#-exit
Intmax (2023):https://eprint.iacr.org/2023/1082
¿Qué más hay que hacer y qué compensaciones deben sopesarse?
La tarea principal restante es poner el sistema de plasma en producción.Como se mencionó anteriormente, «Plasma y Validium» no son oposiciones binarias: cualquier validium puede mejorar al menos un poco de rendimiento de seguridad al agregar la funcionalidad de plasma al mecanismo de salida.La investigación tiene como objetivo obtener los mejores atributos del EVM (en términos de requisitos de confianza, el peor costo de gas L1 y la vulnerabilidad DOS) y las estructuras alternativas específicas de la aplicación.Además, el plasma tiene una mayor complejidad conceptual en comparación con los rollups y debe resolverse directamente estudiando y construyendo un mejor marco general.
El principal inconveniente del uso de diseños de plasma es que son más dependientes del operador y más difíciles de «basarse», aunque los diseños híbridos de plasma/rollup a menudo evitan esta debilidad.
¿Cómo interactúa con el resto de la hoja de ruta?
Cuanto más efectiva sea la solución de plasma, menos estrés tiene la L1 para tener capacidades de disponibilidad de datos de alto rendimiento.Mover la actividad a L2 también reduce la presión de MEV sobre L1.
Sistema maduro de prueba L2
¿Qué problemas queremos resolver?
Hoy, la mayoría de los rollups no son realmente confiables;En algunos casos, el sistema de prueba ni siquiera existe en absoluto, o incluso si existe, solo tiene una función de «consulta».Los principales son (i) algunos rollups específicos de la aplicación, como el combustible, que son confiables, y (ii) a partir de este escrito, optimismo y árbitro, dos rolups EVM completos han implementado la confianza parcial. fase».La razón por la cual los rollups no se desarrollaron más es preocuparse por los errores en el código.Necesitamos confiar en el acurrucado, por lo que necesitamos resolver este problema de frente.
¿Qué es y cómo funciona?
Primero, revisemos el sistema «etapa» que se introdujo originalmente en este artículo.Hay requisitos más detallados, pero el resumen es el siguiente:
-
Etapa 0:El usuario debe poder ejecutar el nodo y sincronizar la cadena.Si la verificación es completamente confiable/centralizada.
-
Fase 1:Debe haber un sistema de prueba (sin confianza) para garantizar que solo se acepten transacciones válidas.Hay un comité de seguridad que puede revocar el sistema de prueba, pero solo hay un umbral de votación del 75%.Además, la parte de bloqueo de quórum del consejo (es decir, más del 26%) debe ubicarse fuera de las principales compañías que construyeron el acurrucado.Se permiten mecanismos de actualización más débiles (como DAO), pero debe haber un retraso lo suficientemente largo para que si se aprueba una actualización maliciosa, los usuarios pueden salir de fondos antes de que la actualización se realice.
-
Fase 2:Debe haber un sistema de prueba (no confiable) para garantizar que solo se acepten transacciones válidas.El consejo puede intervenir solo si hay un error probado en el código, por ejemplo.Si dos sistemas de prueba redundantes son inconsistentes entre sí, o si un sistema de prueba acepta dos raíces posteriores al estado del mismo bloque (o no acepta nada durante el tiempo suficiente, como una semana).El mecanismo de actualización está permitido, pero debe haber un retraso largo.
Nuestro objetivo es llegar a la segunda etapa.El principal desafío para llegar a la segunda fase es ganar suficiente confianza para demostrar que el sistema es realmente lo suficientemente confiable.Hay dos formas principales de hacer esto:
-
Verificación formal:Podemos usar técnicas modernas matemáticas y computacionales para demostrar (optimista o validez) que el sistema acepta solo bloques que pasan la especificación EVM.Estas tecnologías han existido durante décadas, pero los avances recientes (como Lean 4) las hacen más prácticas, y los avances en las pruebas asistidas por AI pueden acelerar aún más esta tendencia.
-
Múltiples correctores:Hacer múltiples sistemas de pruebas y fondos de inversión en 2 de 3 (o más) de múltiples firmas entre estos sistemas de prueba y el Consejo de Seguridad (y/u otros widgets con suposiciones de confianza, como TEE).Si se demuestra que el sistema está de acuerdo, el consejo no tiene poder.Si no están de acuerdo, el consejo solo puede elegir uno de ellos y no puede imponer unilateralmente su propia respuesta.
Un diagrama estilizado de múltiples proveedores, que combina un sistema de prueba optimista, un sistema de prueba de efectividad y un comité de seguridad.
¿Cuáles son las conexiones con la investigación existente?
EVM K Semantics (trabajo de verificación formal desde 2017):https://github.com/runteverification/evm-semantics
Demostración sobre la idea de personas múltiples (2022):https://www.youtube.com/watch?v=6hfvzcwt6yi
Taiko planea usar múltiples pruebas:https://docs.taiko.xyz/core-concepts/multi-prests/
¿Qué más hay que hacer y qué compensaciones deben sopesarse?
Hay muchos para la verificación formal.Necesitamos crear una versión formal validada de todo el snark, el EVM.Este es un proyecto extremadamente complejo, aunque ya hemos comenzado.Hay un truco que puede simplificar significativamente las tareas: podemos hacer un prover de snark validado formalmente para la máquina virtual más pequeña, por ejemplo.RISC-V o El Cairo, luego escriba una implementación del EVM en esa VM mínima (y demuestra formalmente su equivalente a algunas otras especificaciones EVM).
Para múltiples moteros, hay dos partes principales restantes.Primero, necesitamos tener suficiente confianza en al menos dos sistemas de prueba diferentes, cada uno de los cuales es bastante seguro, y si se bloquean, se bloquearán por razones diferentes e irrelevantes (por lo que no se bloquearán al mismo tiempo).En segundo lugar, necesitamos obtener un nivel de seguridad muy alto en la lógica subyacente del sistema de prueba de fusión.Este es un pequeño código.Hay varias formas de hacerlo muy pequeño, solo fondos de la tienda en un contrato seguro de múltiples firmas cuya firma es un contrato que representa un sistema de prueba personal, pero esto tiene un alto costo de gas en la cadena.Es necesario encontrar algún equilibrio entre eficiencia y seguridad.
¿Cómo interactúa con el resto de la hoja de ruta?
La actividad móvil a L2 reduce la presión de MEV en L1.
Mejoras de interoperabilidad Cross-L2
¿Qué problemas queremos resolver?
Uno de los mayores desafíos en el ecosistema L2 de hoy es que es difícil para los usuarios manipularse.Además, el enfoque más fácil a menudo reintroduce suposiciones de confianza: puentes centralizados, clientes de RPC, etc.Si tomamos la idea de que L2 es parte de Ethereum en serio, debemos hacer que el uso del ecosistema L2 se sienta como usar un ecosistema unificado de Ethereum.
Un ejemplo de un patológicamente malo (incluso peligroso: personalmente perdí $ 100 por la selección de cadena incorrecta aquí) en L2 UX, mientras que esto no es culpa del Polymarket, la interoperabilidad de L2 debe ser para la comunidad de estándares de billetera y Ethereum (ERC).En un ecosistema de Ethereum bien administrado, enviar tokens de L1 a L2 o de un L2 a otro debería ser como enviar tokens en el mismo L1.
¿Qué es y cómo funciona?
Hay muchas categorías de mejoras de interoperabilidad Cross-L2.En términos generales, la forma de hacer estas preguntas es tener en cuenta que, en teoría, el Ethereum centrado en el rollo es lo mismo que L1 realizando fragmentos, y luego preguntar qué aspectos de la versión actual de Ethereum L2 están en práctica, en términos de brechas entre los ideales y la versión actual de Ethereum L2.Aquí hay algunos:
-
Dirección específica del enlace:La cadena (L1, Optimismo, Arbitrum …) debe ser parte de la dirección.Una vez implementado, puede implementar el proceso de envío de Cross-L2 simplemente colocando la dirección en el campo «Enviar», y la billetera puede descubrir cómo enviar en segundo plano (incluido el uso del protocolo del puente).
-
Solicitudes de pago específicas de la cadena:Hacer mensajes en forma de «Enviarme un token Y tipo X en la cadena Z» debe ser simple y estandarizado.Hay dos casos de uso principales para esto: (i) pago, ya sea un individuo para un individuo o un individuo para un servicio comercial, y (ii) un DAPP que solicita fondos, por ejemplo.El ejemplo de PolyMarket anterior.
-
Intercambio de cadena cruzada y pago de gas:Debe haber un protocolo abierto estandarizado para expresar operaciones de cadena cruzada, como «Envío 1 ETH en optimismo a alguien que envía 0.9999 ETH en el árbitro» y «Envío 0.0001 ETH en el optimismo», cualquiera incluye esto en las transacciones de árbitro «. 7683 es un intento para el primero, mientras que RIP-7755 es un intento para el segundo, aunque ambos son más generales que estos casos de uso específicos.
-
Cliente de luz:Los usuarios deberían poder verificar la cadena con la que están interactuando, en lugar de solo confiar en el proveedor de RPC.Helios de la criptomoneda A16Z hizo esto por Ethereum mismo, pero necesitamos extender esta sin confianza a L2.ERC-3668 (CCIP-Read) es una estrategia para lograr esto.
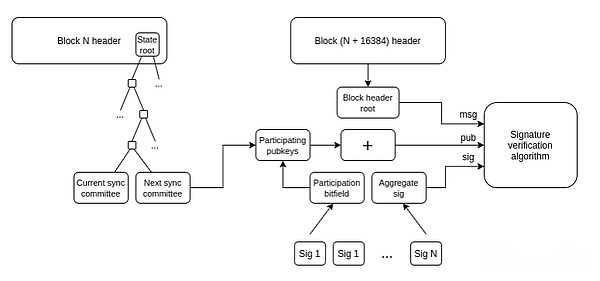
Cómo los clientes ligeros actualizan la vista de su cadena de encabezado Ethereum.Una vez que tenga una cadena de encabezado, puede usar Merkle Prueba para verificar cualquier objeto de estado.Una vez que tenga el objeto de estado L1 correcto, puede verificar cualquier objeto de estado en L2 usando Merkle Proof (o tal vez firma si desea verificar la preconfirmación).HeliosHe hecho lo primero.Extenderse a este último es un desafío de la estandarización.
-
Billetera de la tienda de claves:Hoy, si desea actualizar la clave que controla una billetera de contrato inteligente, debe hacerlo en todas las cadenas N donde se encuentra esa billetera.Una billetera de almacenamiento de claves es una técnica que permite que la clave exista en una ubicación (ya sea en L1 o posterior en L2) y luego lea desde cualquier L2 que tenga una copia de la billetera.Esto significa que la actualización solo debe suceder una vez.Para mejorar la eficiencia, la billetera del almacén de claves requiere que L2 tenga una forma estandarizada de leer L1 sin costo;
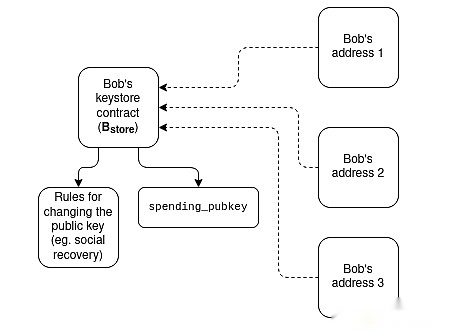
Un diagrama estilizado de cómo funciona una billetera de almacenamiento clave.
-
Idea más radical de «puente de token compartido»:Imagine un mundo donde todo L2 es un rollup probado, con cada ranura dedicada a Ethereum.Incluso en este mundo, la transferencia de activos «locales» de un L2 a otro requiere retiro y depósito, lo que requiere una gran cantidad de gas L1.Una forma de resolver este problema es crear un acurrucado mínimo compartido cuya única función es mantener saldos de los cuales L2 tiene cuántos tipos de tokens y permitir que esos saldos se actualicen colectivamente a través de una serie de crossovers.L2 Enviar operación iniciada por cualquier L2.Esto permitirá la transmisión a través de L2 sin pagar el gas L1 por transmisión, y también sin la necesidad de tecnología basada en el proveedor de liquidez (como ERC-7683).
-
Composibilidad sincrónica:Permite llamadas sincrónicas entre L2 y L1 específicos o entre L2 múltiples.Esto puede ayudar a mejorar la eficiencia financiera del protocolo Defi.El primero se puede hacer sin ninguna coordinación Cross-L2;El rollup es automáticamente amigable con todas estas tecnologías.
¿Cuáles son las conexiones con la investigación existente?
Dirección específica de la cadena: ERC-3770:https://eips.ethereum.org/eips/eip-3770
ERC-7683:https://eips.ethereum.org/eips/eip-7683
RIP-7755:https://github.com/wilsoncusack/rips/blob/cross-l2-call-standard/rips/rip-7755.md
Diseño de la billetera de almacenamiento de llaves de desplazamiento:https://hackmd.io/@haichen/keystore
Helios:https://github.com/a16z/helios
ERC-3668 (a veces llamado CCIP-Read):https://eips.ethereum.org/eips/eip-3668
La propuesta de Justin Drake para «basada en la preconfirmación (compartida)»:https://ethresear.ch/t/based-preconfirmations/17353
L1SLOAD (RIP-7728):https://ethereum-magicians.org/t/rip-7728-l1sload-precompile/20388
Llamadas remotas optimistas:https://github.com/ethereum-optimism/ecosystem-contributions/issues/76
Agglayer, que incluye la idea de compartir el puente de token:https://github.com/agglayer
¿Qué más hay que hacer y qué compensaciones deben sopesarse?
Muchos de los ejemplos anteriores enfrentan el dilema estándar de cuándo estandarizar y qué capas de estandarización.Si la estandarización es demasiado temprano, puede estar en riesgo de soluciones de baja calidad.Si la estandarización es demasiado tarde, puede causar fragmentación innecesaria.En algunos casos, hay soluciones a corto plazo que son más débiles pero más fáciles de implementar, así como soluciones a largo plazo que son «finalmente correctas» pero tardan bastante en lograrlo.
Lo único de esta sección es que estas tareas no son solo problemas técnicos: son (¡quizás principalmente!) Problemas sociales.Necesitan L2 y billeteras y L1 para trabajar juntos.Nuestra capacidad de tratar con éxito este problema es una prueba de nuestra capacidad para unirnos como comunidad.
¿Cómo interactúa con el resto de la hoja de ruta?
La mayoría de estas sugerencias son estructuras «más altas» y, por lo tanto, no tienen mucho impacto en las consideraciones de L1.Una excepción es la clasificación compartida, que tiene un gran impacto en los MEV.
Ejecución extendida en L1
¿Qué problemas queremos resolver?
Si L2 se vuelve muy escalable y exitoso, pero L1 todavía solo puede manejar transacciones muy pequeñas, hay muchos riesgos en Ethereum:
-
La situación económica de los activos ETH se vuelve más peligrosa, lo que a su vez afecta la seguridad a largo plazo de la red.
-
Muchos L2 se benefician de una estrecha conexión con el ecosistema financiero altamente desarrollado en L1, y si este ecosistema se debilita enormemente, la motivación para convertirse en L2 (en lugar de un L1 separado) se debilitará.
-
El L2 lleva mucho tiempo tener exactamente la misma seguridad que el L1.
-
Si L2 falla (por ejemplo, debido a las operaciones maliciosas o a los operadores de desaparición), el usuario aún necesita pasar por L1 para recuperar sus activos.Por lo tanto, L1 debe ser lo suficientemente fuerte como para al menos poder lidiar realmente con el final del L2 altamente complejo y caótico al menos ocasionalmente.
Por estas razones, es valioso continuar expandiendo el L1 en sí y asegurarse de que pueda continuar adaptándose a más y más usos.
¿Qué es y cómo funciona?
La forma más fácil de expandirse es simplemente agregar límites de gas.Sin embargo, esto tiene el riesgo de centralizar L1, debilitando así otro atributo importante que hace que Ethereum L1 sea tan poderoso: su credibilidad como una capa subyacente fuerte.Ha habido debate sobre cómo se aumentan las restricciones de gas simples para ser sostenibles, y esto también variará según la implementación de otras tecnologías para facilitar la verificación de los bloques más grandes (por ejemplo, expiración histórica, prueba de validez de L1 EVM).Otra cosa importante que necesita una mejora continua es la eficiencia del software del cliente Ethereum, que está más optimizado hoy que hace cinco años.Una estrategia efectiva de aumento de la restricción de gas L1 implicará acelerar estas técnicas de verificación.
Otra estrategia de escala implica identificar características específicas y tipos de computación que pueden volverse más baratos sin comprometer la dispersión de la red o sus propiedades de seguridad.Ejemplos de esto incluyen:
-
EOF– Un nuevo formato de Bytecode EVM que es más amigable con el análisis estático y permite una implementación más rápida.Dadas estas eficiencias, se puede dar un costo de gas más bajo al Bytecode EOF.
-
Precios de gases multidimensionales– Establecer gastos básicos y limitaciones separados en la computación, datos y almacenamiento puede aumentar la capacidad promedio de Ethereum L1 sin aumentar su capacidad máxima (y así crear nuevos riesgos de seguridad).
-
Reducir los costos de gas para códigos de operación específicos y precompilados– Históricamente, hemos realizado varias rondas de aumento de costos de gas en ciertas operaciones subestimales para evitar ataques de denegación de servicios.Hemos hecho menos pero podemos hacer más, y es reducir el costo del gas para las operaciones caras.Por ejemplo, la adición es mucho más barata que la multiplicación, pero el costo de los códigos de operación ADD y MUL es actualmente el mismo.Podemos hacer que Agregar códigos de operación más baratos e incluso más simples (como Push) sea más barato.Hay muchos EOF en su conjunto.
-
Evm-max y simd: EVM-Max («Extensiones aritméticas modulares») es una propuesta que permite matemáticas modulares nativas de gran número más eficiente como un módulo separado para EVM.Los valores calculados por los cálculos EVM-Max solo pueden acceder a los códigos de operación EVM-Max a menos que se exporte intencionalmente;SIMD («Instrucción única multidata») es una propuesta que permite una ejecución eficiente de las mismas instrucciones en una matriz de valores.Juntos, los dos pueden crear un poderoso coprocesador con EVM que puede usarse para implementar operaciones de cifrado de manera más eficiente.Esto es especialmente útil para los protocolos de privacidad y los sistemas de prueba L2, por lo que ayudará con la expansión L1 y L2.
Estas mejoras se discutirán con más detalle en futuros artículos sobre derroche.
Finalmente, la tercera estrategia es el acurrucado nativo (o «acumulación incorporado, rollups consagrados»): esencialmente, muchas copias de EVM que se ejecutan en paralelo, formando un modelo equivalente al rollup de los modelos que puede proporcionar, pero se integran más de manera más nativa en el protocolo.
¿Cuáles son las conexiones con la investigación existente?
Hoja de ruta de expansión Ethereum L1 de Polynya:https://polynya.mirror.xyz/epju72rsyncfb-jk52_uyi7huhj-w_zm735ndp7alkaq
Precios de gas multidimensionales:https://vitalik.eth.limo/general/2024/05/09/multidim.html
EIP-7706:https://eips.ethereum.org/eips/eip-7706
EOF:https://evmobjectformat.org/
EVM-Max:https://ethereum-magicians.org/t/eip-6601-evm-modular-arithmetic-extensions-evmmax/13168
Simd:https://eips.ethereum.org/eips/eip-616
Rollup nativo:https://mirror.xyz/ohotties.eth/p1qsccwj2fz9cqo3_6kyi4s2chw5k5tmegogk6io1ge
Entrevista con Max Resnick sobre el valor de extender L1:https://x.com/banklesshq/status/1831319419739361321
Justin Drake sobre extender con Snark y Native Rollup:https://www.reddit.com/r/ethereum/comments/1f81ntr/comment/llmfi28/
¿Qué más hay que hacer y qué compensaciones deben sopesarse?
Hay tres estrategias para las extensiones L1 que se pueden ejecutar individualmente o en paralelo:
-
Las tecnologías mejoradas (por ejemplo, código de cliente, cliente sin estado, vencimiento histórico) hacen que L1 sea más fácil de verificar y luego aumente los límites de gas
-
Reduzca el costo de una operación específica y aumente la capacidad promedio sin aumentar el riesgo de peor caso
-
Rollup nativo (es decir, «Crear n réplicas paralelas de EVM», aunque puede proporcionar mucha flexibilidad para los desarrolladores para implementar los parámetros de las réplicas)
Vale la pena entender que estas son tecnologías diferentes con diferentes compensaciones.Por ejemplo, el acurrucado nativo tiene muchas de las mismas debilidades que el encierro regular en términos de composibilidad: no puede enviar una sola transacción para realizar operaciones sincrónicamente en múltiples transacciones, al igual que puede manejar contratos en el mismo L1 (o L2).El aumento de las restricciones de gas priva a otros beneficios que se pueden lograr al hacer que L1 sea más fácil de verificar, como aumentar el porcentaje de usuarios que ejecutan nodos de verificación y aumentando las partes interesadas individuales.Hacer operaciones específicas en EVM más barata (dependiendo de cómo se opere) puede aumentar la complejidad general del EVM.
Una gran pregunta que cualquier hoja de ruta de expansión L1 necesita ser respondida es: ¿Cuál es la visión final de L1 y L2?Obviamente, es ridículo hacer todo en L1: los casos de uso potenciales tienen cientos de miles de transacciones por segundo, lo que hará que L1 sea completamente no verificado (a menos que tomemos la ruta nativa de rollo).Pero necesitamos algunos principios rectores para que podamos asegurarnos de que no causemos una situación en la que aumentemos el límite de gas en 10 veces, lastimando seriamente la descentralización del Ethereum L1 y descubriendo que solo estamos entrando en un mundo, no 99 % La actividad está en L2 y el 90% de la actividad está en L2, por lo que los resultados se ven casi iguales, excepto por la mayoría de las pérdidas irreversibles de la particularidad de Ethereum L1.
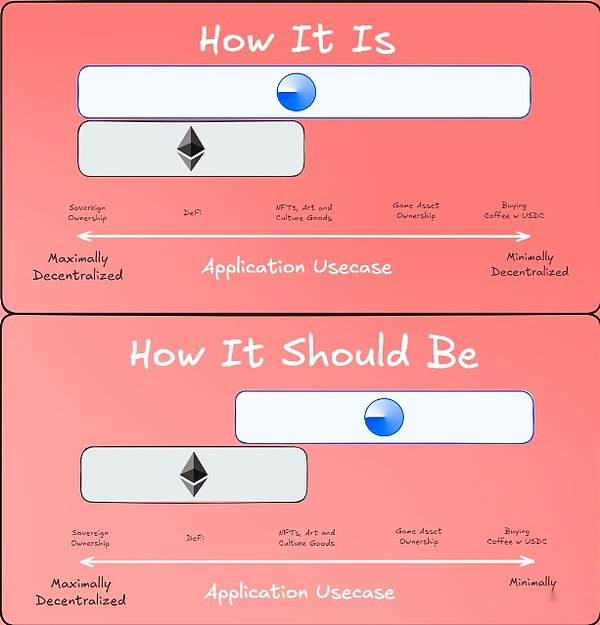
Una opinión propuesta sobre la «División del Trabajo» entre L1 y L2
¿Cómo interactúa con el resto de la hoja de ruta?
Contratar más usuarios en L1 significa mejorar no solo la escala sino otros aspectos de L1.Esto significa que más MEV permanecerán en L1 (en lugar de ser un problema con L2), por lo que es más urgente lidiar con él explícitamente.Aumenta en gran medida el valor del tiempo de ranura rápida en L1.También depende en gran medida de si la verificación L1 («el borde») fue suave.
Un agradecimiento especial a Justin Drake, Francesco, Hsiao-Wei Wang, @antonttc y Georgios Konstantopoulos






