
Por qué la IA necesita estar abierta
Discutamos «por qué la inteligencia artificial debe ser abierta».Mi experiencia es el aprendizaje automático, y he estado trabajando en varios trabajos de aprendizaje automático durante unos diez años en mi carrera.Pero antes de involucrarme en criptográfico, comprensión del lenguaje natural y fundación cerca, trabajé en Google.Ahora desarrollamos un marco que impulsa la mayor parte de la inteligencia artificial moderna llamada Transformer.Después de dejar Google, comencé una empresa de aprendizaje automático para que podamos enseñar a las máquinas a programar, lo que cambia la forma en que interactuamos con las computadoras.Pero no hicimos esto en 2017 o 2018, era demasiado pronto y no había poder informático y datos para hacer esto en ese momento.

Lo que hicimos en ese momento era atraer personas de todo el mundo para hacer el trabajo de etiquetar datos para nosotros, en su mayoría estudiantes.Están en China, Asia y Europa del Este.Muchos de ellos no tienen cuentas bancarias en estos países.Estados Unidos no está dispuesto a enviar dinero fácilmente, por lo que comenzamos a querer usar blockchain como una solución a nuestro problema.Queremos pagar a las personas de todo el mundo de manera programática, sin importar dónde se encuentren, para que esto sea más fácil.Por cierto, el desafío actual de la criptografía es que, aunque Near resuelve muchos problemas ahora, generalmente debe comprar un poco de criptografía primero para hacer transacciones en la cadena de bloques para ganar.
Al igual que las empresas, dirían, oye, antes que nada, necesitas comprar algo de capital en la empresa para usarlo.Este es uno de los muchos problemas que cerca está resolviendo.Ahora discutamos el aspecto de inteligencia artificial un poco en profundidad.Los modelos de idiomas no son nuevos, existieron en la década de 1950.Es una herramienta estadística que se usa ampliamente en las herramientas de lenguaje natural.Durante mucho tiempo, a partir de 2013, se ha comenzado una nueva innovación a medida que se reinicia el aprendizaje profundo.Esta innovación es que puede igualar las palabras, agregarlas a vectores multidimensionales y convertirlas en formas matemáticas.Esto funciona bien con los modelos de aprendizaje profundo, son solo muchas funciones de multiplicación y activación de matriz.

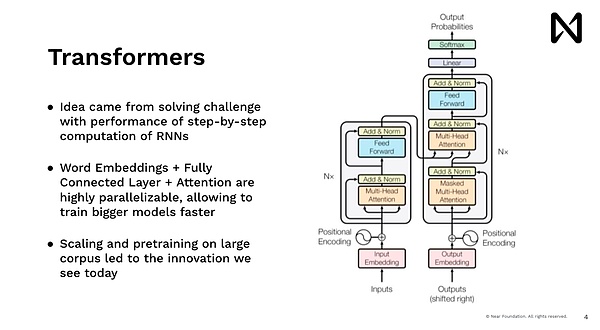
Esto nos permite comenzar a hacer un aprendizaje profundo avanzado y capacitar a nuestros modelos para hacer muchas cosas divertidas.Mirando hacia atrás ahora, lo que estábamos haciendo en ese momento eran las redes neuronales neuronales, que en gran medida imitaban los modelos humanos, y podríamos leer una palabra a la vez.Entonces, es muy lento hacer esto, claro.Si intenta mostrar algo de contenido a los usuarios en Google.com, nadie esperará para leer Wikipedia, digamos, cinco minutos antes de dar la respuesta, pero desea obtener la respuesta de inmediato.Por lo tanto, el modelo Transformers, es decir, el modelo que impulsa ChatGPT, MidJourney y todos los progresos recientes, proviene de la misma idea, y todo esperan que haya una manera de procesar datos en paralelo, inferir y dar respuestas de inmediato.
Entonces, una innovación importante en esta idea aquí es que cada palabra, cada token, cada bloque de imágenes se procesa en paralelo, aprovechando nuestra GPU y otros aceleradores con potencia informática altamente paralela.Al hacerlo, podemos razonar al respecto en una escala.Esta escala puede ampliar la escala de capacitación y, por lo tanto, procesar datos de capacitación automática.Entonces, después de esto, vemos la dopamina, que hizo un trabajo increíble en poco tiempo, logrando un entrenamiento explosivo.Tiene una gran cantidad de texto y comienza a lograr resultados sorprendentes en el razonamiento y la comprensión del lenguaje del mundo.
La dirección ahora es acelerar la inteligencia artificial innovadora, que anteriormente era una herramienta que los científicos de datos y los ingenieros de aprendizaje automático usarían, y luego explicar de alguna manera qué hay en sus productos o puede discutir datos con los tomadores de decisiones.Ahora tenemos este modelo de IA comunicando directamente con las personas.Es posible que ni siquiera sepa que se está comunicando con el modelo porque en realidad está oculto detrás del producto.Así que pasamos por este cambio de aquellos que entendieron cómo trabajaba AI antes, a comprender y poder usarla.

Entonces, estoy aquí para darte algunos antecedentes, cuando decimos que estamos usando GPU para entrenar modelos, este no es el tipo de GPU de juego que usamos al jugar videojuegos en nuestro escritorio.

Cada máquina generalmente está equipada con ocho GPU, todas las cuales están conectadas entre sí a través de una placa base y luego se apilan en bastidores, cada una con aproximadamente 16 máquinas.Todos estos bastidores ahora también están conectados entre sí a través de cables de red dedicados para garantizar que la información se pueda transmitir directa y rápidamente entre las GPU.Por lo tanto, la información no es adecuada para la CPU.De hecho, no lo manejará en la CPU en absoluto.Todos los cálculos ocurren en la GPU.Así que esta es una configuración de supercomputadora.Nuevamente, esta no es la tradicional «Hola, esto es una cosa de GPU».Entonces, el modelo con una escala de GPU4 utilizó 10,000 H100 para capacitación en aproximadamente tres meses, y el costo fue de $ 64 millones.Todos saben cuál es el costo actual y cuánto costará capacitar a algunos modelos modernos.
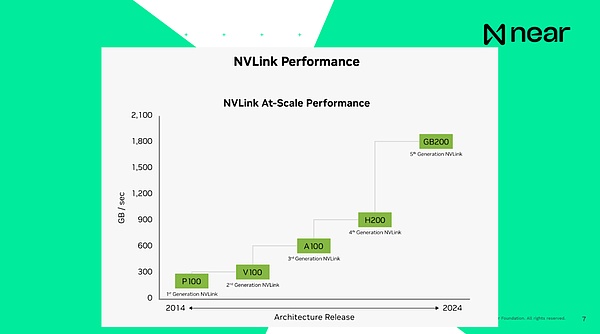
Lo importante es que cuando digo que los sistemas están conectados entre sí, la velocidad de conexión actual de H100, es decir, el producto de generación anterior, es de 900 GB por segundo, y la velocidad de conexión entre la CPU y la RAM dentro de la computadora es de 200 GB. por segundo, que es todo local para la computadora.Por lo tanto, enviar datos de una GPU a otra en el mismo centro de datos es más rápido que su computadora.Su computadora básicamente puede comunicarse por sí sola en la caja.La velocidad de conexión de la nueva generación de productos es básicamente 1.8TB por segundo.Desde el punto de vista de un desarrollador, esta no es una unidad informática individual.Estas son supercomputadoras que tienen una gran memoria y potencia informática que le proporcionan informática extremadamente a gran escala.
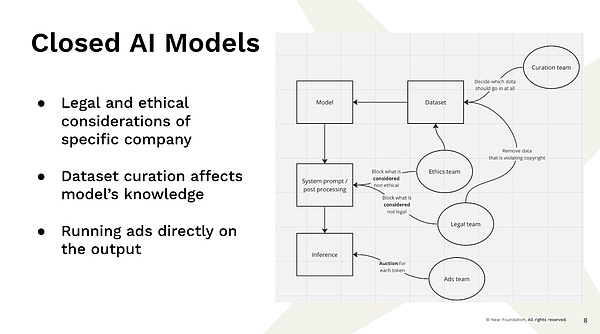
Ahora, esto lleva al problema que enfrentamos, que estas grandes empresas tienen los recursos y la capacidad de construir estos modelos que casi ya nos brindan ese tipo de servicio ahora, y no sé cuánto trabajo hay allí allí , ¿bien?Entonces este es un ejemplo, ¿verdad?Vaya a un proveedor de empresa completamente centralizado e ingresa una consulta.El resultado es que hay varios equipos que no son equipos de ingeniería de software, sino equipos que determinan cómo se muestran los resultados, ¿verdad?Tiene un equipo que decide qué datos entran en el conjunto de datos.
Por ejemplo, si solo gatea los datos de Internet, la cantidad de veces que Barack Obama nació en Kenia y Barack Obama nació en Hawai es exactamente el mismo porque a la gente le gusta especular sobre la controversia.Entonces tienes que decidir qué entrenar.Debe decidir filtrar alguna información porque no cree que sea cierto.Por lo tanto, si un individuo como este ha decidido qué datos se adoptarán y que existe los datos, estas decisiones están en gran medida influenciadas por la persona que los hizo.Tiene un equipo legal que decide que no podemos ver qué contenido tiene derechos de autor y qué es ilegal.Tenemos un «equipo ético» que determina lo que es inmoral y lo que no debemos mostrar.
Entonces, hasta cierto punto, hay muchos comportamientos de filtrado y manipulación.Estos modelos son modelos estadísticos.Serán elegidos de los datos.Si no hay nada en los datos, no sabrán la respuesta.Si hay algo en los datos, lo más probable es que lo traten como un hecho.Ahora, cuando obtienes una respuesta de AI, esto puede ser preocupante.Bien.Ahora, debería obtener respuestas del modelo, pero no hay garantía.No sabes cómo se generan los resultados.Una empresa puede vender su sesión específica al mejor postor para cambiar realmente los resultados.Imagine que si le pregunta qué automóvil debe comprar, Toyota decidió pensar que debería estar sesgado con Toyota, y Toyota le pagaría a la compañía 10 centavos para que lo haga.

Entonces, incluso si usa estos modelos como una base de conocimiento que debe ser neutral y representar los datos, en realidad hay muchas cosas que sesgarán los resultados de una manera muy específica antes de obtenerlos.Esto ha causado muchos problemas, ¿verdad?Esta es básicamente una semana de diferentes demandas legales entre grandes empresas y los medios de comunicación.Sec, ahora casi todos están tratando de demandarse porque estos modelos aportan tanta incertidumbre y poder.Y, si mira hacia adelante, el problema es que las grandes empresas tecnológicas siempre tendrán una motivación para continuar aumentando sus ingresos, ¿verdad?Por ejemplo, si usted es una empresa pública, debe informar los ingresos y debe continuar creciendo.
Para lograr esto, si ya ocupa el mercado objetivo, por ejemplo, ya tiene 2 mil millones de usuarios.No hay más usuarios nuevos en Internet.No tiene muchas opciones, aparte de maximizar los ingresos promedio, lo que significa que necesita extraer más valor de los usuarios, y pueden tener poco valor, o necesita cambiar su comportamiento.La IA generativa es muy buena para manipular y cambiar el comportamiento del usuario, especialmente si las personas piensan que viene en forma de toda la inteligencia intelectual.Por lo tanto, enfrentamos esta situación muy peligrosa donde la presión regulatoria es alta y los reguladores no entienden completamente cómo funciona esta tecnología.Tenemos poco para proteger a nuestros usuarios de la manipulación.

Contenido manipulador, contenido engañoso, incluso sin anuncios, puede tomar capturas de pantalla de algo, cambiar el título, publicarlo en Twitter y la gente se volverá loca.Tiene un mecanismo de incentivos económicos que le hace maximizar continuamente sus ingresos.Y, en realidad, no es como si estuvieras haciendo cosas malvadas dentro de Google, ¿verdad?Cuando decida qué modelo comenzar, hará una prueba A o B para ver cuál traerá más ingresos.Por lo tanto, maximizará continuamente sus ingresos extrayendo más valor de sus usuarios.Además, los usuarios y la comunidad no tienen información sobre el contenido del modelo, los datos utilizados y los objetivos realmente intentaron alcanzar.Este es el caso con el usuario de la aplicación.Este es un tipo de ajuste.
Es por eso que promueve constantemente la integración de la Web 3 y la IA.Esta es la dirección general de todo el desarrollo de la IA Web 3.

Una vez más, este no es un problema puramente de IA, aunque los modelos de lenguaje han traído una gran influencia y han ampliado a las personas para manipular y utilizar información.Lo que quieres es una reputación de criptografía rastreable y rastreable que aparecerá cuando miras contenido diferente.Así que imagine que tiene algunos nodos comunitarios que realmente están encriptados y se pueden encontrar en cada página de cada sitio web.Ahora, si va más allá de eso, todas estas plataformas de distribución se verán interrumpidas, ya que estos modelos ahora leerán casi todo esto y le darán resumen personalizado y producción personalizada.
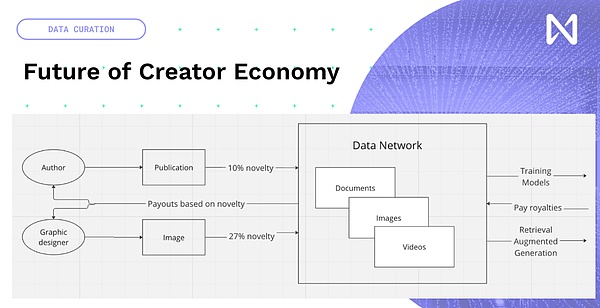
Así que en realidad tenemos la oportunidad de crear un nuevo contenido creativo en lugar de tratar de reinventarlo, agregemos blockchain y NFT al contenido existente.La economía de los nuevos creadores en torno a la capacitación de modelos y el tiempo de inferencia, los datos que las personas crean, ya sean nuevas publicaciones, fotos, YouTube o música que cree, ingresará a una red basada en cuánto contribuye a la capacitación modelo.Entonces, según esto, se puede obtener alguna compensación a nivel mundial en función del contenido.Así que hacemos la transición del llamativo modelo económico ahora impulsado por la red publicitaria a la que realmente aporta información innovadora e interesante.
Una cosa importante que quiero mencionar es que mucha incertidumbre proviene de las operaciones de puntos flotantes.Todos estos modelos implican muchas operaciones de puntos flotantes y multiplicación.Todas estas son operaciones inciertas.
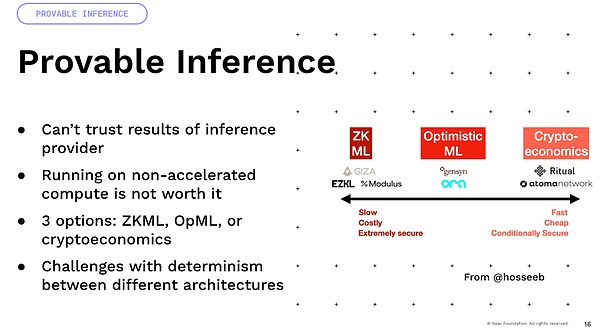
Ahora, si los multiplica en GPU de diferentes arquitecturas.Entonces, si toma un A100 y un H100, el resultado será diferente.Por lo tanto, muchos métodos que dependen de la certeza, como la economía criptográfica y el optimismo, en realidad encuentran muchas dificultades y requieren mucha innovación para lograr esto.Finalmente, hay una idea interesante de que hemos estado creando monedas programables y activos programables, pero si puede imaginar que les agrega esta inteligencia, puede tener activos inteligentes que no están definidos por código ahora, en cambio, se define por La capacidad del lenguaje natural para interactuar con el mundo, ¿verdad?Así es como podemos tener mucha optimización interesante de ganancias y Defi, y podemos llevar a cabo estrategias comerciales dentro del mundo.

El desafío ahora es que todos los eventos actuales no poseen un comportamiento sólido fuerte.No están entrenados para ser adversarmente potentes, porque el propósito del entrenamiento es predecir el siguiente token.Por lo tanto, será más fácil convencer a un modelo de que le dé todo el dinero.Antes de continuar, en realidad es muy importante resolver este problema.Así que te dejaré esta idea, estamos en una encrucijada, ¿verdad?Hay un ecosistema de IA cerrado que tiene incentivos extremos y volantes porque cuando lanzan un producto, generan muchos ingresos y luego ponen esos ingresos en el producto de construcción.Sin embargo, el producto nace para maximizar los ingresos de la compañía y, por lo tanto, maximizar el valor extraído de los usuarios.O tenemos este método abierto, propiedad del usuario, y los usuarios controlan la situación.

Estos modelos son realmente buenos para usted, tratando de maximizar sus intereses.Le proporcionan una forma de protegerlo realmente de muchos peligros en Internet.Por eso necesitamos Ai X Crypto para un mayor desarrollo y aplicaciones.Gracias a todos.







