
Pourquoi l’IA doit être ouvert
Discutons de « pourquoi l’intelligence artificielle doit être ouverte ».Mon expérience est l’apprentissage automatique et je travaille dans divers travaux d’apprentissage automatique depuis environ dix ans dans ma carrière.Mais avant de m’impliquer dans la crypto, la compréhension du langage naturel et la fondation de près, j’ai travaillé chez Google.Nous développons maintenant un cadre qui anime la majeure partie de l’intelligence artificielle moderne appelée Transformer.Après avoir quitté Google, j’ai lancé une entreprise d’apprentissage automatique afin que nous puissions enseigner aux machines à programmer, ce qui modifie la façon dont nous interagissons avec les ordinateurs.Mais nous n’avons pas fait cela en 2017 ou 2018, il était trop tôt et il n’y avait pas de puissance de calcul et de données pour le faire à ce moment-là.

Ce que nous avons fait à l’époque était d’attirer des gens du monde entier pour faire le travail d’étiquetage des données pour nous, principalement des étudiants.Ils se trouvent en Chine, en Asie et en Europe de l’Est.Beaucoup d’entre eux n’ont pas de comptes bancaires dans ces pays.Les États-Unis ne sont pas disposés à envoyer de l’argent facilement, nous avons donc commencé à vouloir utiliser la blockchain comme solution à notre problème.Nous voulons payer aux gens du monde entier de manière programmatique, peu importe où ils se trouvent, pour faciliter cela.Soit dit en passant, le défi actuel de la crypto est que, bien que près de résoudre beaucoup de problèmes maintenant, vous devez généralement acheter de la crypto pour effectuer des transactions sur la blockchain pour gagner.
Comme les entreprises, ils diraient, hé, tout d’abord, vous devez acheter des capitaux propres dans l’entreprise pour l’utiliser.C’est l’un des nombreux problèmes que nous proches est de résoudre.Discutons maintenant un peu de l’aspect de l’intelligence artificielle en profondeur.Les modèles linguistiques ne sont pas nouveaux, ils existaient dans les années 1950.Il s’agit d’un outil statistique qui est largement utilisé dans les outils en langage naturel.Pendant longtemps, à partir de 2013, une nouvelle innovation a commencé alors que l’apprentissage en profondeur est redémarré.Cette innovation est que vous pouvez faire correspondre les mots, les ajouter à des vecteurs multidimensionnels et les convertir en formes mathématiques.Cela fonctionne bien avec les modèles d’apprentissage en profondeur, ce ne sont que beaucoup de fonctions de multiplication et d’activation de la matrice.

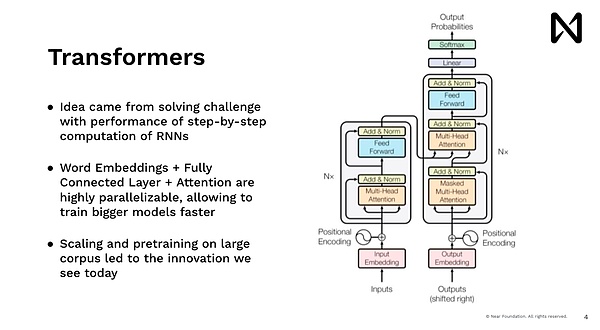
Cela nous permet de commencer à faire un apprentissage en profondeur avancé et de former nos modèles à faire beaucoup de choses amusantes.En regardant en arrière maintenant, ce que nous faisions à l’époque était les réseaux de neurones neuronaux, qui imitaient largement les modèles humains, et nous pouvions lire un mot à la fois.Donc, c’est très lent de le faire, non.Si vous essayez d’afficher du contenu aux utilisateurs sur Google.com, personne n’attendra de lire Wikipedia, disons, cinq minutes avant de donner la réponse, mais vous voulez obtenir la réponse tout de suite.Par conséquent, le modèle Transformers, c’est-à-dire le modèle qui anime Chatgpt, MidJourney et tous les progrès récents, provient de la même idée, et tout espère qu’il existe un moyen de traiter les données en parallèle, déduire et donner des réponses immédiatement.
Ainsi, une innovation majeure dans cette idée ici est que chaque mot, chaque jeton, chaque bloc d’image est traité en parallèle, tirant parti de notre GPU et d’autres accélérateurs avec une puissance de calcul très parallèle.Ce faisant, nous sommes en mesure de raisonner à ce sujet sur une échelle.Cette échelle peut augmenter l’échelle de formation et ainsi traiter les données de formation automatique.Donc, après cela, nous voyons la dopamine, qui a fait un travail incroyable en peu de temps, réalisant une formation explosive.Il a une grande quantité de texte et commence à obtenir des résultats incroyables dans le raisonnement et la compréhension de la langue du monde.
La direction est maintenant d’accélérer l’intelligence artificielle innovante, qui était auparavant un outil que les scientifiques des données et les ingénieurs d’apprentissage automatique utiliseraient, puis expliquer en quelque sorte ce qu’il y a dans leurs produits ou peut discuter des données avec les décideurs.Nous avons maintenant ce modèle d’IA communiquant directement avec les gens.Vous ne savez peut-être même pas que vous communiquez avec le modèle car il est en fait caché derrière le produit.Nous avons donc traversé ce changement de ceux qui ont compris comment l’IA fonctionnait auparavant, pour comprendre et pouvoir l’utiliser.

Donc, je suis ici pour vous donner des antécédents, lorsque nous disons que nous utilisons des GPU pour former des modèles, ce n’est pas le genre de GPU de jeu que nous utilisons lors de la lecture de jeux vidéo sur notre bureau.

Chaque machine est généralement équipée de huit GPU, qui sont tous connectés les uns aux autres via une carte mère, puis empilés dans des racks, chacun avec environ 16 machines.Tous ces racks sont désormais également connectés les uns aux autres via des câbles de réseau dédiés pour s’assurer que les informations peuvent être transmises directement et rapidement entre les GPU.Par conséquent, les informations ne conviennent pas au CPU.En fait, vous ne le gérez pas du tout sur le CPU.Tous les calculs se produisent sur le GPU.Il s’agit donc d’une configuration de supercalculateur.Encore une fois, ce n’est pas le traditionnel « Hé, c’est une chose GPU ».Ainsi, le modèle avec une échelle de GPU4 a utilisé 10 000 H100 pour la formation en environ trois mois, et le coût était de 64 millions de dollars.Tout le monde sait quel est le coût actuel et combien il en coûtera pour former des modèles modernes.
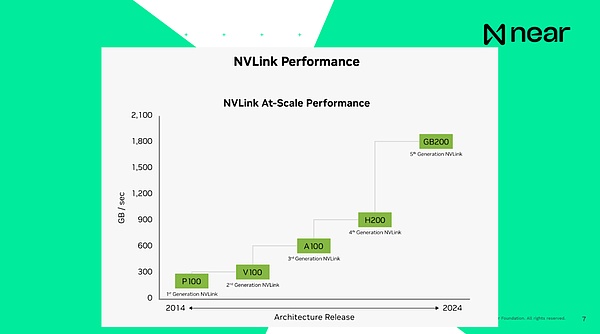
Ce qui est important, c’est que lorsque je dis que les systèmes sont connectés les uns aux autres, la vitesse de connexion actuelle de H100, c’est-à-dire le produit de génération précédente, est de 900 Go par seconde, et la vitesse de connexion entre le CPU et la RAM à l’intérieur de l’ordinateur est de 200 Go par seconde, qui est tout local de l’ordinateur.Par conséquent, l’envoi de données d’un GPU à un autre dans le même centre de données est plus rapide que votre ordinateur.Votre ordinateur peut essentiellement communiquer seul dans la boîte.La vitesse de connexion de la nouvelle génération de produits est essentiellement de 1,8 To par seconde.Du point de vue d’un développeur, ce n’est pas une unité informatique individuelle.Ce sont des supercalculateurs qui ont une énorme mémoire et une puissance de calcul qui vous fournit un calcul extrêmement à grande échelle.
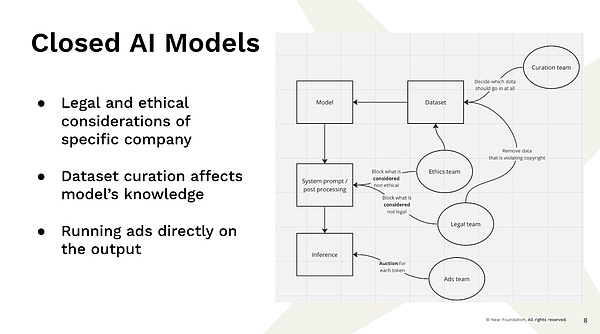
Maintenant, cela mène au problème auquel nous sommes confrontés, que ces grandes entreprises ont les ressources et la capacité de construire ces modèles qui nous fournissent presque déjà ce type de service maintenant, et je ne sais pas combien de travail il y a là-dedans , droite?C’est donc un exemple, non?Vous allez chez un fournisseur d’entreprises entièrement centralisé et entrez dans une requête.Le résultat est qu’il existe plusieurs équipes qui ne sont pas des équipes d’ingénierie logicielle, mais des équipes qui déterminent comment les résultats sont affichés, non?Vous avez une équipe qui décide quelles données entrent dans l’ensemble de données.
Par exemple, si vous rampez des données sur Internet, le nombre de fois que Barack Obama est né au Kenya et que Barack Obama est né à Hawaï est exactement le même parce que les gens aiment spéculer sur la controverse.Vous devez donc décider sur quoi vous entraîner.Vous devez décider de filtrer certaines informations parce que vous ne croyez pas que c’est vrai.Par conséquent, si une personne comme celle-ci a décidé quelles données seront adoptées et que les données existent, ces décisions sont largement influencées par la personne qui les a fabriqués.Vous avez une équipe juridique qui décide que nous ne pouvons pas voir quel est le contenu protégé par le droit d’auteur et ce qui est illégal.Nous avons une « équipe éthique » qui détermine ce qui est immoral et ce que nous ne devons pas montrer.
Donc, dans une certaine mesure, il y a beaucoup de tels comportements de filtrage et de manipulation.Ces modèles sont des modèles statistiques.Ils seront choisis dans les données.S’il n’y a rien dans les données, ils ne connaîtront pas la réponse.S’il y a quelque chose dans les données, ils le traiteront très probablement comme un fait.Maintenant, lorsque vous obtenez une réponse de l’IA, cela peut être inquiétant.Droite.Maintenant, vous devriez obtenir des réponses du modèle, mais il n’y a aucune garantie.Vous ne savez pas comment les résultats sont générés.Une entreprise peut vendre votre session spécifique au plus offrant pour modifier réellement les résultats.Imaginez si vous demandez quelle voiture vous devez acheter, Toyota a décidé de penser qu’elle devrait être biaisée envers Toyota, et Toyota paierait 10 cents à l’entreprise pour ce faire.

Ainsi, même si vous utilisez ces modèles comme une base de connaissances qui devrait être neutre et représenter les données, il y a en fait beaucoup de choses qui biaiseront les résultats d’une manière très spécifique avant de les obtenir.Cela a causé beaucoup de problèmes, non?Il s’agit essentiellement d’une semaine de poursuites judiciaires différentes entre les grandes entreprises et les médias.Sec, maintenant presque tout le monde essaie de se poursuivre parce que ces modèles apportent tellement d’incertitude et de puissance.Et, si vous attendez avec impatience, le problème est que les grandes entreprises technologiques auront toujours une motivation pour continuer à augmenter leurs revenus, non?Par exemple, si vous êtes une entreprise publique, vous devez générer des revenus et vous devez continuer à croître.
Pour y parvenir, si vous occupez déjà le marché cible, par exemple, vous avez déjà 2 milliards d’utilisateurs.Il n’y a plus de nouveaux utilisateurs sur Internet.Vous n’avez pas beaucoup d’options, à part maximiser les revenus moyens, ce qui signifie que vous devez extraire plus de valeur des utilisateurs, et ils peuvent avoir peu de valeur, ou vous devez modifier leur comportement.L’IA générative est très bonne pour manipuler et modifier le comportement des utilisateurs, surtout si les gens pensent que cela prend la forme de toute intelligence intellectuelle.Nous sommes donc confrontés à cette situation très dangereuse où la pression réglementaire est élevée et les régulateurs ne comprennent pas pleinement le fonctionnement de cette technologie.Nous n’avons pas grand-chose à protéger nos utilisateurs contre la manipulation.

Contenu manipulateur, contenu trompeur, même sans publicité, vous pouvez simplement prendre des captures d’écran de quelque chose, changer le titre, le publier sur Twitter et les gens deviendront fous.Vous avez un mécanisme d’incitation économique qui vous fait maximiser continuellement vos revenus.Et, ce n’est pas vraiment comme si vous faisiez des choses mauvaises à l’intérieur de Google, non?Lorsque vous décidez du modèle à commencer, vous ferez un test ou B pour voir lequel rapportera plus de revenus.Vous maximirez donc en permanence vos revenus en extrayant plus de valeur de vos utilisateurs.De plus, les utilisateurs et la communauté n’ont aucune contribution sur le contenu du modèle, les données utilisées et les objectifs ont réellement tenté d’atteindre.C’est le cas avec l’utilisateur de l’application.Ceci est une sorte d’ajustement.
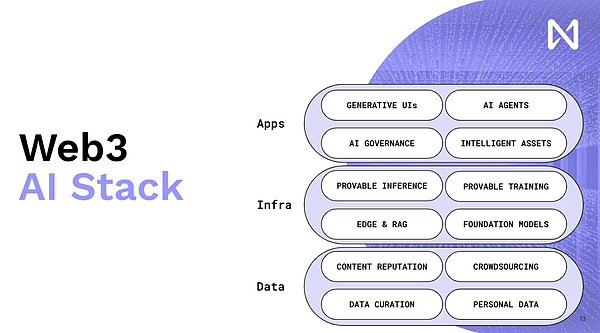
C’est pourquoi nous faisons constamment la promotion de l’intégration de Web 3 et AI.C’est la direction générale de l’ensemble du développement de l’IA Web.

Encore une fois, ce n’est pas un problème purement d’IA, bien que les modèles de langage aient apporté une grande influence et étendu pour que les gens manipulent et utilisent des informations.Ce que vous voulez, c’est une réputation de cryptographie traçable et traçable qui apparaîtra lorsque vous regardez différents contenus.Imaginez donc que vous avez des nœuds communautaires qui sont réellement cryptés et que vous pouvez être trouvé sur chaque page de chaque site Web.Maintenant, si vous allez au-delà de cela, toutes ces plates-formes de distribution seront perturbées, car ces modèles liront maintenant presque tout cela et vous donneront un résumé personnalisé et une sortie personnalisée.
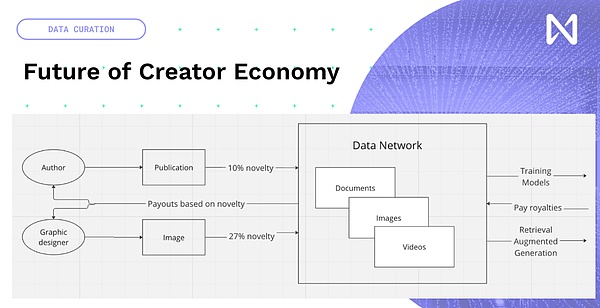
Nous avons donc la possibilité de créer de nouveaux contenus créatifs au lieu d’essayer de le réinventer, ajoutons la blockchain et les NFT au contenu existant.L’économie des nouveaux créateurs autour de la formation des modèles et du temps d’inférence, les données que les gens créent, qu’il s’agisse de nouvelles publications, de photos, de YouTube ou de la musique que vous créez, entrera dans un réseau en fonction de la quantité que cela contribue à la formation de modélisation.Ainsi, sur la base de cela, une certaine compensation peut être obtenue à l’échelle mondiale en fonction du contenu.Nous passons donc du modèle économique accrocheur désormais motivé par le réseau publicitaire à celui qui apporte vraiment des informations innovantes et intéressantes.
Une chose importante que je veux mentionner est que beaucoup d’incertitude vient des opérations de points flottants.Tous ces modèles impliquent de nombreuses opérations de points flottants et de multiplication.Ce sont toutes des opérations incertaines.
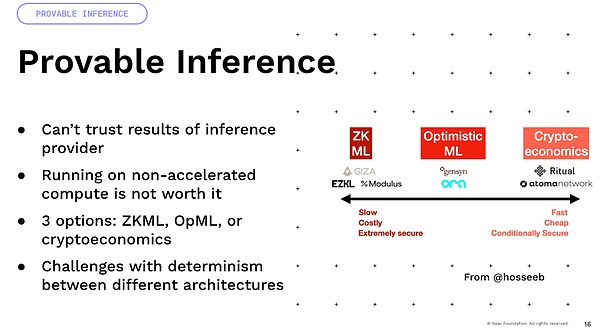
Maintenant, si vous les multipliez sur des GPU de différentes architectures.Donc, si vous prenez un A100 et un H100, le résultat sera différent.Par conséquent, de nombreuses méthodes qui reposent sur la certitude, comme l’économie de la cryptographie et l’optimisme, rencontrent en fait beaucoup de difficultés et nécessitent beaucoup d’innovation pour y parvenir.Enfin, il y a une idée intéressante que nous avons construit des devises programmables et des actifs programmables, mais si vous pouvez imaginer que vous y ajoutez cette intelligence, vous pouvez avoir des actifs intelligents qui ne sont pas définis par le code maintenant, à la place, il est défini par La capacité du langage naturel à interagir avec le monde, non?C’est ainsi que nous pouvons avoir beaucoup d’optimisation et de défi des bénéfices intéressants, et nous pouvons mener des stratégies de trading dans le monde.

Le défi est maintenant que tous les événements actuels ne possèdent pas un comportement robuste fort.Ils ne sont pas formés pour être adversariens puissants, car le but de la formation est de prédire le token suivant.Il sera donc plus facile de convaincre un modèle de vous donner tout l’argent.Avant de continuer, il est en fait très important de résoudre ce problème.Alors je vais vous laisser cette idée, nous sommes à la croisée des chemins, non?Il y a un écosystème d’IA fermé qui a des incitations et des volants extrêmes, car lorsqu’ils lancent un produit, ils génèrent beaucoup de revenus et mettent ensuite ces revenus dans le produit de construction.Cependant, le produit est né pour maximiser les revenus de l’entreprise et ainsi maximiser la valeur extraite des utilisateurs.Ou nous avons cette méthode ouverte et appartenant à l’utilisateur et les utilisateurs contrôlent la situation.

Ces modèles sont en fait bons pour vous, essayant de maximiser vos intérêts.Ils vous offrent un moyen de vraiment vous protéger de nombreux dangers sur Internet.C’est pourquoi nous avons besoin de crypto AI x pour plus de développement et d’applications.Merci à tous.







