
Fuente: Tecnología Tencent
El cofundador y CEO de NVIDIA, Huang Renxun, pronunció un discurso de apertura en Computex 2024 (2024 Taipei International Computer Exhibition), compartiendo cómo la era de la inteligencia artificial puede promover la nueva revolución industrial global.
Los siguientes son los puntos clave de este discurso:
① Huang Renxun mostró la última versión producida en masa de Blackwell Chips y dijo que lanzará Blackwell Ultra AI Chips en 2025. La próxima generación de la plataforma AI se llama Rubin Ultra se lanzará en 2027. El ritmo de actualización será «Una vez al año», rompiendo la ley «Moore».
② Huang Renxun afirmó que Nvidia promovió el nacimiento de un modelo de lenguaje grande, que cambió la arquitectura de GPU después de 2012 e integró todas las nuevas tecnologías en una sola computadora.
③ La tecnología informática acelerada de Nvidia ha ayudado a lograr un aumento de 100 veces en la tasa, mientras que el consumo de energía solo aumenta a 3 veces, y el costo es de 1,5 veces.
④ Huang Renxun espera que la próxima generación de IA necesite comprender el mundo físico.El método que dio es dejar que la IA aprenda a través de datos de video y sintéticos, y dejar que la IA aprenda unos de otros.
⑤ Huang Renxun incluso finalizó una traducción china para Token en PPT – Ci Yuan.
⑥ Huang Renxun dijo que la era de los robots ha llegado, y todos los objetos móviles funcionarán de forma independiente en el futuro.

La siguiente es la transcripción completa del discurso de dos horas compilado por Tencent Technology:
Queridos invitados, me siento muy honrado de volver a estar aquí.En primer lugar, me gustaría agradecer a la Universidad de Taiwán por proporcionarnos este gimnasio como lugar para eventos.La última vez que vine aquí fue cuando obtuve mi título de la Universidad de Taiwán.Hoy, hay muchas cosas que vamos a explorar, por lo que tengo que acelerar y transmitir el mensaje de manera rápida y clara.Tenemos muchos temas de los que hablar, y tengo muchas historias emocionantes para compartir con ustedes.
Estoy muy feliz de estar aquí en Taiwán, China, donde muchos de nuestros socios están aquí.De hecho, esta no es solo una parte indispensable de la historia del desarrollo de Nvidia, sino también un nodo clave para nosotros y nuestros socios para promover conjuntamente la innovación al mundo.Trabajamos con muchos socios para construir una infraestructura de inteligencia artificial en todo el mundo.Hoy me gustaría discutir varios temas clave con usted:
1) ¿Qué progreso se está haciendo en nuestro trabajo conjunto y cuál es el significado de estos progresos?
2) ¿Qué es exactamente la inteligencia artificial generativa?¿Cómo afectará a nuestra industria e incluso a todas las industrias?
3) Un plan sobre cómo podemos avanzar y cómo aprovecharemos esta increíble oportunidad?
¿Qué pasará después?La IA generativa y su profundo impacto, nuestro plan estratégico, son temas emocionantes que estamos a punto de explorar.Estamos parados en el punto de partida del reinicio de la industria informática, y una nueva era creada por usted y creada por usted está a punto de comenzar.Ahora estás listo para el próximo viaje importante.
1.Una nueva era de la informática está comenzando
Pero antes de comenzar la discusión en profundidad, quiero enfatizar una cosa: Nvidia se encuentra en la intersección de gráficos de computadora, simulación e inteligencia artificial, que forma el alma de nuestra empresa.Hoy, todo lo que te mostraré se basa en la simulación.Estos no son solo efectos visuales, son la esencia de las matemáticas, la ciencia y la informática, y la impresionante arquitectura informática.Ninguna animación está prefabricada, todo es una obra maestra de nuestro propio equipo.Eso es lo que NVIDIA entiende, y lo incorporamos todo en el mundo virtual omniverso del que estamos orgullosos.¡Ahora, por favor, disfruta del video!
El consumo de energía en los centros de datos en todo el mundo está aumentando bruscamente, mientras que los costos informáticos también están aumentando.Nos enfrentamos al severo desafío de la inflación computacional, que obviamente no se puede mantener durante mucho tiempo.Los datos continuarán creciendo exponencialmente, mientras que la expansión del rendimiento de la CPU es difícil de expandir tan rápido como antes.Sin embargo, surge un enfoque más eficiente.
Durante casi dos décadas, hemos estado trabajando en la investigación informática acelerada.La tecnología CUDA mejora las capacidades de la CPU, la descarga y las tareas de aceleración que los procesadores especiales pueden completar de manera más eficiente.De hecho, debido a la desaceleración o incluso el estancamiento de la expansión del rendimiento de la CPU, las ventajas de la computación acelerada son cada vez más significativas.Predigo que cada aplicación intensiva en procesamiento se acelerará, y en el futuro cercano, cada centro de datos se acelerará por completo.

Ahora, elegir la informática acelerada es un movimiento sabio, que se ha convertido en un consenso de la industria.Imagine que una solicitud tarda 100 unidades de tiempo en completarse.Ya sea por 100 segundos o 100 horas, a menudo no podemos soportar la aplicación AI que se ejecuta durante días o incluso meses.
Entre estas 100 unidades de tiempo, una unidad de tiempo involucra un código que necesita ser ejecutado secuencialmente.La lógica de control del sistema operativo es indispensable y debe ejecutarse estrictamente de acuerdo con la secuencia de instrucciones.Sin embargo, hay muchos algoritmos, como gráficos por computadora, procesamiento de imágenes, simulación física, optimización combinatoria, procesamiento de gráficos y procesamiento de bases de datos, especialmente álgebra lineal ampliamente utilizada en el aprendizaje profundo, que son adecuados para la aceleración a través del procesamiento paralelo.Para lograr esto, inventamos una arquitectura innovadora que combina perfectamente la GPU con la CPU.
Un procesador dedicado puede acelerar las tareas que requieren mucho tiempo a velocidades increíbles.Dado que los dos procesadores pueden trabajar en paralelo, cada uno se ejecutan de forma independiente e independiente.Esto significa que las tareas que originalmente requerían 100 unidades de tiempo ahora se pueden completar en solo 1 unidad de tiempo.Aunque este efecto de aceleración suena increíble, hoy validaré esta declaración con una serie de ejemplos.

Los beneficios de esta mejora del rendimiento son sorprendentes, con una aceleración de 100 veces, mientras que solo un aumento de aproximadamente 3 veces en la potencia y solo un aumento del 50% en el costo.Ya hemos practicado esta estrategia en la industria de las PC.Agregar una GPU de GeForce de $ 500 a su PC mejorará en gran medida su rendimiento, al tiempo que aumentará su valor general a $ 1,000.En el centro de datos, hemos adoptado el mismo enfoque.Un centro de datos de mil millones de dólares se transformó instantáneamente en una poderosa fábrica de inteligencia artificial después de agregar una GPU de $ 500 millones.Hoy, este cambio está sucediendo en todo el mundo.
Los ahorros de costos son igualmente impactantes.Por cada $ 1 invertido, obtiene hasta 60x ganancias de rendimiento.La aceleración es 100 veces, mientras que la potencia es solo 3 veces, y el costo es solo 1.5 veces.¡Los ahorros son reales!
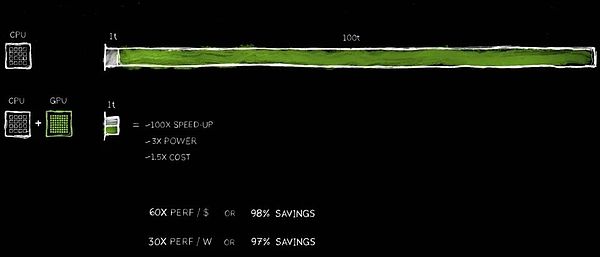
Aparentemente, muchas compañías gastan cientos de millones de dólares en procesar datos en la nube.Ahorrar cientos de millones de dólares se vuelve razonable cuando los datos se procesan más rápido.¿Por qué está sucediendo esto?La razón es simple, hemos experimentado un cuello de botella de eficiencia a largo plazo en la informática general.
Ahora, finalmente reconocemos esto y decidimos acelerarlo.Al adoptar un procesador dedicado, podemos recuperar muchas ganancias de rendimiento previamente pasadas por alto, ahorrando mucho dinero y energía.Por eso digo, cuanto más compras, más ahorrarás.
Ahora, te he mostrado los números.Aunque no son precisos para unos pocos lugares decimales, esto refleja con precisión los hechos.Esto se puede llamar «CEO Matemáticas».Aunque el CEO Mathematics no persigue una precisión extrema, la lógica detrás de esto es correcta: cuanto más acelerada potencia informática comprará, más costos ahorrará.
2.350 bibliotecas de funciones ayudan a abrir nuevos mercados
Los resultados de la computación acelerada son realmente extraordinarios, pero el proceso de implementación no es fácil.¿Por qué ahorra tanto dinero, pero la gente no ha adoptado esta tecnología antes?La razón es que es demasiado difícil de implementar.
No existe un software listo que se pueda ejecutar simplemente acelerando el compilador, y la aplicación se puede acelerar instantáneamente 100 veces.Esto no es lógico ni realista.Si fuera tan fácil, entonces los fabricantes de CPU lo habrían hecho hace mucho tiempo.
De hecho, para lograr la aceleración, el software debe reescribirse por completo.Esta es la parte más desafiante del proceso.El software debe ser rediseñado y recodificado para convertir los algoritmos que originalmente se ejecutaban en la CPU en formatos que se pueden ejecutar en paralelo en el acelerador.
Aunque esta investigación en ciencias de la computación es difícil, hemos hecho un progreso significativo en los últimos 20 años.Por ejemplo, lanzamos la popular Biblioteca Cudnn Deep Learning, que se especializa en el manejo de la aceleración de la red neuronal.También proporcionamos una biblioteca para simulaciones de física de inteligencia artificial para aplicaciones como la dinámica de fluidos que requieren el cumplimiento de las leyes físicas.Además, tenemos una nueva biblioteca llamada Aerial, que utiliza CUDA para acelerar la tecnología de radio 5G, lo que nos permite usar el software para definir y acelerar las redes de telecomunicaciones como redes de Internet definidas por software.

Estas capacidades de aceleración no solo mejoran el rendimiento, sino que también nos ayudan a transformar toda la industria de las telecomunicaciones en una plataforma informática similar a la computación en la nube.Además, la plataforma de litografía Coolitho Computing también es un buen ejemplo, que mejora en gran medida la eficiencia de la fabricación de máscaras, la parte más intensiva computacionalmente del proceso de fabricación de chips.Empresas como TSMC ya han comenzado a usar Coolitho para la producción, lo que no solo ahorra energía significativamente, sino que también reduce significativamente los costos.Su objetivo es prepararse para el desarrollo adicional de los algoritmos y el enorme poder informático requerido para hacer transistores más profundos y más estrechos acelerando la pila de tecnología.
Par de ladrillos es nuestra orgullosa biblioteca de secuenciación de genes, que tiene el rendimiento principal de secuenciación de genes del mundo.CO OPT es una notable biblioteca de optimización de combinación que puede resolver problemas complejos, como la planificación de rutas, la optimización del itinerario y los problemas de la agencia de viajes.En general, se cree que estos problemas deben ser resueltos mediante computadoras cuánticas, pero hemos creado un algoritmo extremadamente rápido a través de la tecnología informática acelerada, que rompen con éxito 23 récords mundiales.
Coup Quantum es un sistema de simulación de computadora cuántica que desarrollamos.Un simulador confiable es esencial para los investigadores que desean diseñar computadoras cuánticas o algoritmos cuánticos.Sin computadoras cuánticas reales, Nvidia Cuda, lo que llamamos la computadora más rápida del mundo, se convirtió en su herramienta preferida.Proporcionamos un simulador que puede simular el funcionamiento de las computadoras cuánticas y ayudar a los investigadores a hacer avances en el campo de la computación cuántica.Este simulador ha sido ampliamente utilizado por cientos de miles de investigadores en todo el mundo y se ha integrado en todos los marcos de computación cuántica líderes, proporcionando un fuerte apoyo para los centros de supercomputación científicos en todo el mundo.
Además, hemos lanzado la biblioteca de procesamiento de datos Kudieff, que está especialmente diseñado para acelerar el procesamiento de datos.El procesamiento de datos representa la gran mayoría del gasto en la nube actual, por lo que acelerar el procesamiento de datos es crucial para los ahorros de costos.QDF es una herramienta de aceleración que desarrollamos que puede mejorar significativamente el rendimiento de las principales bibliotecas de procesamiento de datos en el mundo, como las bases de datos de procesamiento de gráficos Spark, Pandas, Polar y NetworkX.
Estas bibliotecas son un componente clave del ecosistema, y permiten que la computación acelerada se use ampliamente.Sin nuestras bibliotecas específicas de dominio cuidadosamente elaboradas como CUDNN, los científicos de aprendizaje profundo de todo el mundo podrían no ser capaces de utilizar completamente su potencial con CUDA, porque existen diferencias significativas entre CUDA y algoritmos utilizados en marcos de aprendizaje profundo como Tensorflow y Pytorch.Esto es tan poco práctico como hacer gráficos por computadora sin OpenGL o procesar datos sin SQL.
Estas bibliotecas específicas de dominio son tesoros de nuestra empresa y actualmente tenemos más de 350 bibliotecas de este tipo.Son estas bibliotecas las que mantienen abiertas y por delante del mercado.Hoy, te mostraré ejemplos más emocionantes.
La semana pasada, Google anunció que habían implementado QDF en la nube y aceleraron con éxito los pandas.Pandas es la biblioteca de ciencia de datos más popular del mundo, utilizada por 10 millones de científicos de datos en todo el mundo, con descargas mensuales de hasta 170 millones de veces.Es como Excel de los científicos de datos, su asistente de la derecha para procesar datos.
Ahora, simplemente haga clic en la plataforma Cloud Data Center Colab de Google y puede experimentar el poderoso rendimiento traído por los pandas acelerados por QDF.Esta aceleración es realmente sorprendente, al igual que la demostración que acaba de ver, completa la tarea de procesamiento de datos casi al instante.
3.Cuda se da cuenta de un ciclo virtuoso
Cuda ha llegado a lo que la gente llama un punto crítico, pero la realidad es mejor que eso.CUDA ha logrado un ciclo de desarrollo virtuoso.Mirando hacia atrás en la historia y el desarrollo de diversas arquitecturas y plataformas informáticas, podemos encontrar que tales bucles no son comunes.Tome la CPU del microprocesador como ejemplo.
La creación de una nueva plataforma informática a menudo enfrenta el dilema de «primero hay pollos o huevos».没有开发者的支持,平台很难吸引用户;而没有用户的广泛采用,又难以形成庞大的安装基础来吸引开发者。Este dilema ha afectado el desarrollo de múltiples plataformas informáticas en los últimos 20 años.
Sin embargo, hemos roto con éxito este dilema al implementar continuamente bibliotecas específicas de dominio y bibliotecas aceleradas.如今,我们已在全球拥有500万开发者,他们利用CUDA技术服务于从医疗保健、金融服务到计算机行业、汽车行业等几乎每一个主要行业和科学领域。
随着客户群的不断扩大,OEM和云服务提供商也开始对我们的系统产生兴趣,这进一步推动了更多系统进入市场。这种良性循环为我们创造了巨大的机遇,使我们能够扩大规模,增加研发投入,从而推动更多应用的加速发展。
La aceleración de cada aplicación significa una reducción significativa en los costos informáticos.Como he demostrado antes, una aceleración de 100x puede generar hasta un 97.96%, o cerca del 98% de ahorro de costos.A medida que aumentamos la aceleración del cálculo de 100 veces a 200 veces y luego a 1000 veces, el costo marginal del cálculo continúa disminuyendo, mostrando notables beneficios económicos.
Por supuesto, creemos que al reducir significativamente los costos informáticos, los mercados, los desarrolladores, los científicos e inventores continuarán desenterrando nuevos algoritmos que consumen más recursos informáticos.Hasta algún punto, ocurrirá un cambio profundo en silencio.Cuando el costo marginal de la informática se vuelve tan bajo, surge una nueva forma de usar computadoras.
De hecho, este cambio está sucediendo ante nuestros ojos.Durante la última década, hemos utilizado algoritmos específicos para reducir el costo marginal de la computación en un asombroso 1 millón de veces.Hoy, el uso de todos los datos en Internet para capacitar a modelos de idiomas grandes se ha convertido en una opción lógica y natural y ya no se cuestiona.
La idea, construir una computadora que pueda procesar cantidades masivas de datos y programas en sí mismo, es la piedra angular del surgimiento de la inteligencia artificial.El aumento de la inteligencia artificial es posible completamente porque creemos firmemente que si hacemos que la informática sea más barata, siempre habrá grandes usos.Hoy, el éxito de Cuda ha demostrado la viabilidad de este ciclo virtuoso.
Con la expansión continua de la Fundación de Instalación y la reducción continua de los costos informáticos, cada vez más desarrolladores pueden realizar su potencial innovador y proponer más ideas y soluciones.Esta innovación ha impulsado un aumento en la demanda del mercado.Ahora estamos parados en un importante punto de inflexión.Sin embargo, antes de mostrarlo más, quiero enfatizar que lo que quiero mostrar a continuación no sería posible sin el avance de CUDA y las tecnologías de IA modernas, especialmente la IA generativa.
Este es el proyecto Earth 2, una idea ambiciosa para crear el gemelo digital de la Tierra.Simularemos el movimiento de toda la Tierra para predecir sus cambios futuros.通过这样的模拟,我们可以更好地预防灾难,更深入地理解气候变化的影响,从而让我们能够更好地适应这些变化,甚至现在就开始改变我们的行为和习惯。
El proyecto Earth 2 es probablemente uno de los proyectos más desafiantes y ambiciosos del mundo.Hemos hecho un progreso significativo en este campo todos los años, y los resultados de este año son particularmente excepcionales.Ahora, permíteme mostrarte este emocionante progreso.
En el futuro cercano, tendremos capacidades continuas de pronóstico del clima que cubren cada kilómetro cuadrado del planeta.Siempre comprenderá cómo cambiará el clima, y esta predicción continuará funcionando porque entrenaremos la IA, lo que requiere energía extremadamente limitada.Sería un logro increíble.Espero que ustedes lo disfruten y, lo que es más importante, esta predicción fue realizada por Jensen Ai, no yo.Lo diseñé, pero las predicciones finales son presentadas por Jensen AI.
A medida que nos esforzamos por mejorar continuamente el rendimiento y reducir los costos, los investigadores descubrieron CUDA en 2012, que fue el primer contacto de Nvidia con la inteligencia artificial.Ese día es crucial para nosotros porque tomamos la sabia elección de trabajar estrechamente con los científicos para hacer posible el aprendizaje profundo.La aparición de Alexnet ha logrado un gran avance en la visión por computadora.
4.El surgimiento de las supercomputadoras de IA no fue reconocido al principio
Pero la sabiduría más importante es que damos un paso atrás y entendemos profundamente la naturaleza del aprendizaje profundo.¿Cuál es su base?¿Cuál es su impacto a largo plazo?¿Cuál es su potencial?Nos damos cuenta de que esta tecnología tiene un gran potencial para continuar expandiendo los algoritmos inventados y descubiertos hace décadas, combinando más datos, redes más grandes y recursos informáticos cruciales, el aprendizaje profundo puede lograr repentinamente tareas humanas que los algoritmos no pueden alcanzar.
Ahora, imagine lo que sucedería si ampliáramos más nuestra arquitectura y tuviéramos una red más grande, más datos y recursos informáticos.Entonces estamos comprometidos a reinventar todo.Desde 2012, hemos cambiado la arquitectura de la GPU, agregamos el núcleo de tensor, inventó NV-Link, lanzó Cudnn, Tensorrt, Nickel, adquirió Mellanox y lanzó el servidor de Inferencias Triton.
Estas tecnologías están integradas en una computadora nueva, que superó la imaginación de todos en ese momento.Nadie esperaba que nadie hiciera tal demanda, y nadie incluso entendió todo su potencial.De hecho, no estoy seguro de si alguien querría comprarlo.
Pero en la conferencia GTC, lanzamos oficialmente esta tecnología.Una startup de San Francisco llamada OpenAI se dio cuenta rápidamente de nuestros resultados y nos pidió que proporcionáramos un dispositivo.Personalmente envié la primera supercomputadora de inteligencia artificial del mundo DGX a OpenAI.
En 2016, continuamos expandiendo nuestra escala de I + D.Desde una sola supercomputadora de inteligencia artificial hasta una sola aplicación de inteligencia artificial, se ha expandido al lanzamiento de una supercomputadora más grande y poderosa en 2017.Con el continuo avance de la tecnología, el mundo ha sido testigo del ascenso de Transformer.La aparición de este modelo nos permite procesar cantidades masivas de datos e identificar y aprender patrones continuos en largos tramos.
Hoy, tenemos la capacidad de entrenar estos grandes modelos de idiomas para lograr avances importantes en la comprensión del lenguaje natural.Pero no nos detuvimos allí, continuamos avanzando y construimos un modelo más grande.Para noviembre de 2022, en supercomputadoras de inteligencia artificiales extremadamente poderosas, utilizamos decenas de miles de GPU NVIDIA para capacitación.
Solo 5 días después, Openai anunció que ChatGPT tiene 1 millón de usuarios.Esta sorprendente tasa de crecimiento ha aumentado a 100 millones de usuarios en solo dos meses, estableciendo el registro de crecimiento más rápido en el historial de aplicaciones.La razón es muy simple: la experiencia de usuario de ChatGPT es conveniente y mágica.
Los usuarios pueden interactuar de forma natural y suave con las computadoras, como si se comuniquen con personas reales.Sin instrucciones tediosas o descripciones claras, ChatGPT puede comprender las intenciones y necesidades del usuario.
La aparición de ChatGPT marca un cambio de época, y esta diapositiva captura este giro crítico.Permítame mostrarlo por usted.
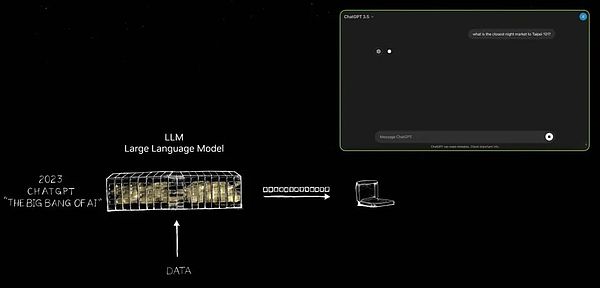
No fue hasta el advenimiento de ChatGPT que realmente reveló el potencial infinito de la inteligencia artificial generativa al mundo.Durante mucho tiempo, el enfoque de la inteligencia artificial se ha centrado en los campos de la percepción, como la comprensión del lenguaje natural, la visión por computadora y el reconocimiento de voz, las tecnologías dedicadas a simular las habilidades de percepción humana.Pero ChatGPT ha traído un salto cualitativo, no solo limitado a la percepción, sino que demuestra el poder de la inteligencia artificial generativa por primera vez.
Genera tokens uno por uno, que pueden ser palabras, imágenes, gráficos, tablas e incluso canciones, texto, voz y videos.Un token puede representar cualquier cosa con un significado claro, ya sean productos químicos, proteínas, genes o los patrones climáticos que mencionamos anteriormente.
El aumento de esta inteligencia artificial generativa significa que podemos aprender y simular fenómenos físicos, permitiendo que los modelos de inteligencia artificial comprendan y generen varios fenómenos en el mundo físico.Ya no nos limitamos a reducir el alcance y el filtrado, sino que exploramos infinitas posibilidades a través de la generación.
Hoy, podemos generar tokens para casi cualquier cosa valiosa, ya sea el control del volante del automóvil, el movimiento articular del brazo robótico o cualquier cosa que podamos aprender en este momento.Por lo tanto, ya no estamos en una era de inteligencia artificial, sino una nueva era dirigida por la inteligencia artificial generativa.
Más importante aún, este dispositivo, que originalmente apareció como una supercomputadora, ahora se ha convertido en un centro de datos de inteligencia artificial eficiente y eficiente.Continúa produciendo, no solo genera tokens, sino también una fábrica de inteligencia artificial que crea valor.Esta fábrica de inteligencia artificial está generando, creando y produciendo nuevos productos con un gran potencial de mercado.
Así como Nikola Tesla inventó el alternador a fines del siglo XIX, trayendo un flujo constante de electrónica, los generadores de inteligencia artificial de Nvidia también generan tokens continuamente con posibilidades infinitas.Ambos tienen grandes oportunidades de mercado y se espera que cambien en todas las industrias.¡Esta es de hecho una nueva revolución industrial!
Ahora estamos dando la bienvenida a una nueva fábrica que puede producir nuevos productos sin precedentes y valiosos para todas las industrias.Este método no solo es extremadamente escalable, sino que también es completamente repetible.Tenga en cuenta que en la actualidad, varios modelos de inteligencia artificial están constantemente emergiendo cada día, especialmente modelos generativos de inteligencia artificial.Hoy en día, cada industria compite para participar, que es una gran ocasión sin precedentes.
La industria de TI de $ 3 billones está a punto de producir logros innovadores que pueden servir directamente a la industria de $ 100 billones.Ya no es solo una herramienta para el almacenamiento de información o el procesamiento de datos, sino un motor para generar inteligencia en cada industria.Esto se convertirá en un nuevo tipo de industria manufacturera, pero no es una industria tradicional de fabricación de computadoras, sino un nuevo modelo de fabricación con computadoras.Tal cambio nunca ha sucedido antes, y de hecho es algo notable.
5.La IA generativa promueve la remodelación de software de la pila completa, demostrando microservicios nativos de nube NIM
Esto abrió una nueva era de computación acelerada, promovió el rápido desarrollo de la inteligencia artificial y, por lo tanto, dio a luz al surgimiento de la inteligencia artificial generativa.Y ahora, estamos experimentando una revolución industrial.Echemos un vistazo más de cerca a su impacto.
El impacto de este cambio es tan largo para nuestra industria.Como dije antes, esta es la primera vez en los últimos sesenta años, cada capa de computación está experimentando transformación.Desde la computación de uso general de CPU hasta la computación acelerada de GPU, cada cambio marca un salto en la tecnología.
过去,计算机需要遵循指令执行操作,而现在,它们更多地是处理LLM(大语言模型)和人工智能模型。Los modelos de computación pasados se basaron en la recuperación, y casi cada vez que usa su teléfono, recupera texto, imágenes o videos pre-almacenados para usted y recombina estos contenidos de acuerdo con el sistema de recomendaciones para presentarlos.
Pero en el futuro, su computadora generará la mayor cantidad de contenido posible y recuperará solo la información necesaria, porque generar datos consume menos energía al obtener información.Además, los datos generados tienen mayor relevancia contextual y pueden reflejar con mayor precisión sus necesidades.Cuando necesite una respuesta, ya no necesita instruir explícitamente a la computadora para que «consiga esa información» o «dame ese archivo», simplemente diga: «Dame una respuesta».
Además, las computadoras ya no son solo herramientas que usamos, comienzan a generar habilidades.Realiza tareas y ya no es una industria de software de producción, lo cual fue una idea disruptiva a principios de la década de 1990.¿Recordar?El concepto de empaque de software propuesto por Microsoft ha cambiado por completo la industria de las PC.Sin software empaquetado, nuestra PC perderá la mayor parte de su funcionalidad.Esta innovación ha impulsado el desarrollo de toda la industria.
Ahora tenemos una nueva fábrica, una nueva computadora y, sobre esta base, es un nuevo tipo de software que se ejecuta: lo llamamos NIM (microservicios de inferencia NVIDIA).NIM Running en esta nueva fábrica es un modelo previamente capacitado, que es una inteligencia artificial.

Esta IA en sí es bastante compleja, pero la pila informática que ejecuta IA es increíblemente compleja.Cuando usa un modelo como ChatGPT, detrás de esto hay una gran pila de software.Esta pila es compleja y enorme porque el modelo tiene miles de millones de billones de parámetros y se ejecuta no solo en una computadora, sino que funciona en conjunto en múltiples computadoras.
Para maximizar la eficiencia, el sistema necesita asignar cargas de trabajo a múltiples GPU para varios procesos paralelos, como el paralelismo tensor, el paralelismo de la tubería, el paralelismo de datos y el paralelismo experto.Dicha asignación es garantizar que el trabajo se pueda completar lo más rápido posible, porque en una planta, el rendimiento está directamente relacionado con los ingresos, la calidad del servicio y la cantidad de clientes que se pueden atender.Hoy, estamos en una era donde la utilización de rendimiento del centro de datos es crucial.
En el pasado, aunque el rendimiento se consideraba importante, no era un factor decisivo.Sin embargo, ahora cada parámetro desde el tiempo de inicio, el tiempo de ejecución, la utilización, el rendimiento al tiempo de inactividad se mide con precisión porque el centro de datos se ha convertido en una verdadera «fábrica».En esta fábrica, la eficiencia operativa está directamente relacionada con el desempeño financiero de la compañía.
Dada esta complejidad, conocemos los desafíos que enfrentan la mayoría de las empresas al implementar la IA.Por lo tanto, desarrollamos una solución integrada de contenedores de IA que encapsula IA en una caja que es fácil de implementar y administrar.Esta caja contiene una gran colección de software como CUDA, Cudacnn y Tensorrt, así como el Servicio de Inferencia Triton.Admite entornos nativos de la nube, permite la escala automática en el entorno de Kubernetes (una solución de arquitectura distribuida basada en la tecnología de contenedores) y proporciona servicios de gestión para facilitar a los usuarios monitorear el estado operativo de los servicios de inteligencia artificial.
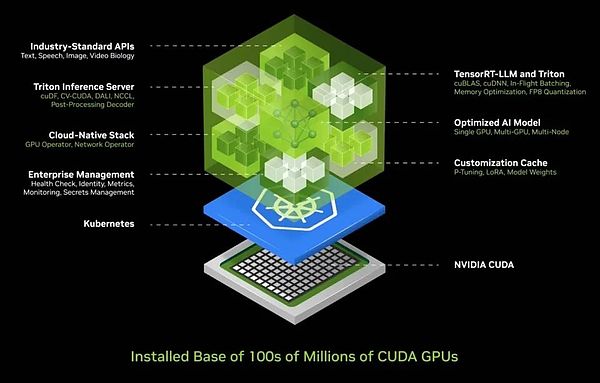
Lo que es aún más emocionante es que este contenedor de IA proporciona una interfaz API estándar universal, que permite a los usuarios interactuar directamente con la «caja».Los usuarios pueden implementar y administrar fácilmente los servicios de IA simplemente descargando NIM y ejecutándose en una computadora habilitada para CUDA.Hoy, CUDA está en todas partes, admite los principales proveedores de servicios en la nube, y casi todos los fabricantes de computadoras brindan soporte CUDA, y se puede encontrar en cientos de millones de PC.
Cuando descarga NIM, inmediatamente tiene un asistente de IA que se comunica sin problemas como una conversación con ChatGPT.Ahora, todo el software se ha simplificado e integrado en un contenedor, y todas las 400 dependencias previamente engorrosas están optimizadas centralmente.Realizamos pruebas rigurosas de NIM, y cada modelo previo al estado previo se probó completamente en nuestra infraestructura en la nube, incluidas diferentes versiones de GPU como Pascal, amperios y la última tolva.Estas versiones son de una amplia variedad, que cubre casi todos los requisitos.
La invención de Nim es, sin duda, una hazaña, y es uno de mis logros más orgullosos.Hoy, tenemos la capacidad de construir modelos de idiomas grandes y varios modelos previamente capacitados que cubren múltiples campos, como lenguaje, visión, imágenes y versiones personalizadas para industrias específicas como la atención médica y la biología digital.

Para obtener más información o probar estas versiones, solo visite ai.nvidia.com.Hoy, lanzamos la Llama 3 NIM completamente optimizada en Hugging Face, que puedes experimentar de inmediato e incluso llevarte de forma gratuita.No importa qué plataforma en la nube elija, puede ejecutarla fácilmente.Por supuesto, también puede descargar este contenedor a su centro de datos, alojarlo usted mismo y servir a sus clientes.
Como mencioné anteriormente, tenemos versiones NIM que cubren diferentes campos, incluyendo física, búsqueda semántica, lenguaje visual, etc., que admiten múltiples idiomas.Estos microservicios se pueden integrar fácilmente en grandes aplicaciones, una de las aplicaciones más prometedoras es el agente de servicio al cliente.Es estándar en casi todas las industrias y representa un mercado global de servicio al cliente de billones de dólares.
Vale la pena mencionar que las enfermeras, como el núcleo del servicio al cliente, juegan un papel importante en la venta minorista, la comida rápida, los servicios financieros, los seguros y otras industrias.Hoy, decenas de millones de personal de servicio al cliente se han mejorado significativamente con la ayuda de modelos de idiomas y tecnología de inteligencia artificial.En el corazón de estas herramientas de mejora está exactamente lo que ves NIM.
Algunos se llaman agentes de razonamiento, y cuando se asignan tareas, pueden identificar objetivos y planos.Algunos son buenos para recuperar información, otros son competentes en la búsqueda y algunos pueden usar herramientas como COOP o necesitan aprender idiomas específicos que se ejecutan en SAP, como ABAP, o incluso ejecutar consultas SQL.Estos llamados expertos ahora se forman en un equipo eficiente y colaborativo.
La capa de aplicación también ha cambiado: en el pasado, las aplicaciones fueron escritas por instrucciones, pero ahora se construyen ensamblando equipos de inteligencia artificial.Si bien escribir un programa requiere experiencia, casi todos saben cómo desglosar los problemas y formar un equipo.Por lo tanto, creo firmemente que todas las empresas en el futuro tendrán una gran colección de NIM.Puede seleccionar expertos según lo desee y conectarlos a un equipo.
Aún más sorprendente es que ni siquiera necesitas descubrir cómo conectarlos.Simplemente asigne una tarea al agente, NIM decidirá de manera inteligente cómo desglosar la tarea y asignarla al mejor experto.Son como líderes centrales de aplicaciones o equipos, capaces de coordinar el trabajo de los miembros del equipo y, en última instancia, presentarle los resultados.
Todo el proceso es tan eficiente y flexible como el trabajo en equipo humano.Esto no es solo una tendencia en el futuro, sino que está a punto de convertirse en una realidad a nuestro alrededor.Este es un aspecto completamente nuevo que las aplicaciones presentarán en el futuro.
6.La PC se convertirá en el principal portador de personas digitales
Cuando hablamos de interacciones con grandes servicios de IA, ahora podemos hacer esto con mensajes de texto y indicaciones de voz.Pero esperando el futuro, esperamos interactuar de una manera más humana, a saber, personas digitales.Nvidia ha progresado significativamente en el campo de la tecnología humana digital.

Las personas digitales no solo tienen el potencial de ser excelentes agentes interactivos, sino que son más atractivas y pueden mostrar una mayor empatía.Sin embargo, todavía se necesita un gran esfuerzo para cruzar esta increíble brecha y hacer que las personas digitales se vean y se sientan más naturales.Esta no es solo nuestra visión, sino también nuestra meta incesante.
Antes de mostrarle nuestros logros actuales, permíteme expresar mis cálidos saludos a Taiwán, China.Antes de explorar el encanto de los mercados nocturnos en profundidad, primero apreciamos la dinámica de vanguardia de la tecnología humana digital.
Esto es realmente increíble.ACE (Avatar Cloud Engine) no solo funciona de manera eficiente en la nube, sino que también es compatible con entornos de PC.Tenemos una integración prolongada de las GPU del núcleo de tensor en todas las familias RTX, lo que marca la llegada de la era de las GPU AI y estamos completamente preparados para esto.
La lógica detrás de esto es muy clara: para construir una nueva plataforma informática, primero se debe colocar una base sólida.Con una base sólida, las aplicaciones surgirán naturalmente.Si faltan dicha base, la aplicación estará fuera de discusión.Entonces, solo cuando construimos, puede ser posible la prosperidad de la aplicación.
Por lo tanto, hemos integrado unidades de procesamiento de tensor en cada GPU RTX.En la reciente exposición Computex, lanzamos cuatro nuevas computadoras portátiles de IA.
Estos dispositivos tienen la capacidad de ejecutar inteligencia artificial.Las computadoras portátiles y las PC del futuro se convertirán en portadores de inteligencia artificial, y en silencio le brindarán ayuda y apoyo en el fondo.Al mismo tiempo, estas PC también ejecutarán aplicaciones mejoradas por inteligencia artificial, y si está haciendo edición de fotos, escribiendo o utilizando otras herramientas, disfrutará de la conveniencia y los efectos de mejora traídos por la inteligencia artificial.

Además, su PC podrá alojar aplicaciones humanas digitales con inteligencia artificial, lo que permite que la IA se presente de manera más diversa y se aplique en su PC.Obviamente, la PC se convertirá en una plataforma de IA crucial.Entonces, ¿cómo nos desarrollaremos a continuación?
Hablé sobre la expansión de nuestros centros de datos antes, y cada expansión se acompaña de nuevos cambios.Cuando nos expandimos de DGX a grandes supercomputadoras de IA, implementamos una capacitación eficiente de Transformer en enormes conjuntos de datos.Esto marca un cambio importante: al principio, los datos requieren supervisión humana, y la inteligencia artificial se entrena a través de marcas humanas.Sin embargo, la cantidad de datos que los humanos pueden etiquetar es limitada.Ahora, con el desarrollo de Transformer, el aprendizaje no supervisado se ha vuelto posible.
Hoy, Transformer puede explorar cantidades masivas de datos, videos e imágenes por su cuenta, aprendiendo y descubriendo patrones y relaciones ocultas.Para promover la inteligencia artificial a un nivel superior, la próxima generación de inteligencia artificial debe estar arraigada en la comprensión de las leyes físicas, pero la mayoría de los sistemas de inteligencia artificial carecen de una comprensión profunda del mundo físico.Para generar imágenes realistas, videos, gráficos 3D y simular fenómenos físicos complejos, necesitamos urgentemente desarrollar inteligencia artificial basada en la física, lo que requiere que pueda comprender y aplicar las leyes de la física.
Hay dos formas principales de lograr esto.Primero, al aprender de los videos, la inteligencia artificial puede acumular gradualmente el conocimiento del mundo físico.En segundo lugar, utilizando datos sintéticos, podemos proporcionar un entorno de aprendizaje rico y controlable para los sistemas de inteligencia artificial.Además, el aprendizaje simulado entre datos y computadoras también es una estrategia efectiva.Este método es similar al modo de autogame de Alphago, lo que permite dos entidades con la misma capacidad de aprender unos de otros durante mucho tiempo, mejorando continuamente su nivel de inteligencia.Por lo tanto, podemos prever que este tipo de inteligencia artificial surgirá gradualmente en el futuro.
7.Blackwell se pone completamente en producción, y su potencia informática ha aumentado en 1,000 veces en ocho años
Cuando los datos de inteligencia artificial se generan a través de la síntesis y se combinan con la tecnología de aprendizaje de refuerzo, la tasa de generación de datos mejorará significativamente.A medida que crece la generación de datos, la demanda de energía informática también aumentará en consecuencia.Estamos a punto de ingresar a una nueva era en la que la inteligencia artificial podrá aprender las leyes de la física, comprender y tomar decisiones y acciones basadas en datos del mundo físico.Por lo tanto, esperamos que el modelo AI continúe expandiéndose y los requisitos para el rendimiento de la GPU se vuelvan cada vez más altos.
Para satisfacer esta necesidad, Blackwell surgió.Diseñado para apoyar una nueva generación de inteligencia artificial, esta GPU tiene varias tecnologías clave.Este tamaño de chip es el mejor en la industria.Usamos dos chips lo más grandes posible, conectándolos bien a través de un enlace de alta velocidad de 10 terabytes por segundo combinado con los serdes más avanzados del mundo (interfaz de alto rendimiento o tecnología de conexión).Además, colocamos dos chips de este tipo en un nodo de computadora y coordinamos de manera eficiente a través de la CPU de Grace.
Las CPU de Grace son versátiles y no solo adecuadas para escenarios de entrenamiento, sino que también juegan un papel clave en la inferencia y la generación, como el punto de control rápido y el reinicio.Además, puede almacenar contextos, lo que permite que los sistemas de IA tengan memoria y comprendan el contexto de las conversaciones de los usuarios, lo cual es crucial para mejorar la continuidad y la fluidez de las interacciones.
Nuestro motor de transformador de segunda generación mejora aún más la eficiencia informática de la inteligencia artificial.Este motor puede ajustarse dinámicamente a una menor precisión de acuerdo con los requisitos de precisión y rango de la capa informática, reduciendo así el consumo de energía mientras mantiene el rendimiento.Mientras tanto, las GPU de Blackwell también tienen capacidades seguras de inteligencia artificial para garantizar que los usuarios puedan pedir a los proveedores de servicios que los protejan del robo o la manipulación.
En términos de interconexión de GPU, hemos adoptado la tecnología de enlace NV de quinta generación, que nos permite conectar fácilmente múltiples GPU.Además, las GPU de Blackwell están equipadas con la primera generación de motores de confiabilidad y disponibilidad (RAS Systems), una tecnología innovadora que puede probar cada transistor, activador, memoria y memoria fuera de chip en el chip para garantizar que podamos juzgar con precisión el sitio en el sitio Si un chip en particular cumple con el tiempo promedio entre fallas (MTBF).
La fiabilidad es especialmente crítica para las grandes supercomputadoras.El tiempo de intervalo de falla promedio para una supercomputadora con 10,000 GPU puede ser en horas, pero cuando el número de GPU aumenta a 100,000, el tiempo de intervalo de falla promedio se reducirá a minutos.Por lo tanto, para garantizar que las supercomputadoras puedan funcionar de manera estable durante mucho tiempo para entrenar modelos complejos que puedan llevar meses, debemos mejorar la confiabilidad a través de la innovación tecnológica.La mejora de la confiabilidad no solo puede aumentar el tiempo de actividad del sistema, sino también reducir efectivamente los costos.
Finalmente, también integramos un motor de descompresión avanzado en la GPU de Blackwell.En términos de procesamiento de datos, la velocidad de descompresión es crucial.Al integrar este motor, podemos extraer datos del almacenamiento 20 veces más rápido que la tecnología existente, mejorando en gran medida la eficiencia del procesamiento de datos.
Las características anteriores de la GPU de Blackwell lo convierten en un producto notable.En la conferencia anterior de GTC, te mostré Blackwell en el estado prototipo.Y ahora, nos complace anunciar que este producto se ha puesto en producción.

Este es Blackwell, todos, utilizando tecnología increíble.Esta es nuestra obra maestra, la computadora más compleja y más realizada del mundo de hoy.Entre ellos, particularmente queremos mencionar la CPU Grace, que conlleva un gran poder informático.Consulte, estos dos chips Blackwell, están estrechamente conectados.¿Lo has notado?Este es el chip más grande del mundo, y utilizamos enlaces de hasta A10TB por segundo para mezclar dos de estos chips con uno.
Entonces, ¿qué es exactamente Blackwell?Su rendimiento es increíble.Observe estos datos cuidadosamente.En solo ocho años, nuestro poder informático, las capacidades aritméticas de aritmética de punto flotante e inteligencia artificial flotante han aumentado en 1,000 veces.Esta velocidad casi supera el crecimiento de la ley de Moore en el mejor período.
El crecimiento en el poder informático de Blackwell es simplemente increíble.Lo que vale la pena mencionar más es que cada vez que aumenta nuestra potencia informática, el costo está disminuyendo constantemente.Déjame mostrarte algo.Al mejorar la potencia informática, la energía utilizada para entrenar modelos GPT-4 (2 billones de parámetros y 8 billones de tokens) ha disminuido en 350 veces.
Imagínese si Pascal realiza el mismo entrenamiento, consumiría hasta 1000 gwh de energía.Esto significa que se necesita un centro de datos GW para apoyarlo, pero dichos centros de datos no existen en el mundo.Incluso si existe, llevará un mes correr continuamente.Y si se trata de un centro de datos de 100 MW, el tiempo de entrenamiento será tan largo como un año.
Obviamente, nadie quiere o puede crear dicho centro de datos.Es por eso que hace ocho años, los modelos de idiomas grandes como ChatGPT todavía eran un sueño lejano para nosotros.Pero ahora, logramos esto aumentando el rendimiento y reduciendo el consumo de energía.
Utilizamos Blackwell para reducir la energía que de otro modo requeriría hasta 1,000 GWH a solo 3 GWh, un logro que sin duda es un avance impactante.Imagine usar 1,000 GPU, la energía que consumen es solo equivalente a las calorías de una taza de café.Y 10,000 GPU pueden completar la misma tarea en casi 10 días.Este progreso realizado en ocho años es simplemente increíble.

Blackwell no solo es adecuado para la inferencia, sino que su mejora en el rendimiento de la generación de tokens es aún más llamativo.En la era de Pascal, cada token consumió hasta 17,000 julios de energía, que se trataba de la energía de dos bombillas que funcionaban durante dos días.Para generar un token GPT-4, casi se necesitan dos bombillas de 200 vatios para funcionar durante dos días.Teniendo en cuenta que se necesitan alrededor de 3 fichas para generar una palabra, este es un gran consumo de energía.
Sin embargo, la situación es completamente diferente ahora.Blackwell hace que solo cuesta 0.4 julios de energía generar cada token, y la generación de tokens es a una velocidad increíble y un consumo de energía extremadamente bajo.Este es, sin duda, un gran salto.Pero aun así, todavía no estamos satisfechos.Para un mayor avance, debemos construir máquinas más potentes.
Este es nuestro sistema DGX, y el chip Blackwell estará integrado en él.Este sistema utiliza la tecnología de enfriamiento de aire y está equipado con 8 de dichas GPU en el interior.Mire los disipadores de calor en estas GPU, su tamaño es increíble.El consumo de energía de todo el sistema es de aproximadamente 15 kW, que se logra completamente a través del enfriamiento del aire.Esta versión es compatible con X86 y se ha aplicado a nuestros servidores enviados.
Sin embargo, si prefiere la tecnología de enfriamiento de líquidos, también tenemos un sistema nuevo: el MGX.Se basa en este diseño de placa base, que llamamos un sistema «modular».El núcleo del sistema MGX se encuentra en dos chips Blackwell, y cada nodo integra cuatro chips Blackwell.Adopta tecnología de enfriamiento líquido para garantizar una operación eficiente y estable.
En todo el sistema, hay nueve nodos de este tipo, un total de 72 GPU, formando un gran clúster informático.Estas GPU están estrechamente conectadas a través de la nueva tecnología NV Link para formar una red informática perfecta.Los interruptores de enlace NV son milagro técnico.Actualmente es el interruptor más avanzado del mundo, con una asombrosa velocidad de transmisión de datos.Estos interruptores hacen que cada chip Blackwell conecte eficientemente, formando un enorme clúster de 72 GPU.
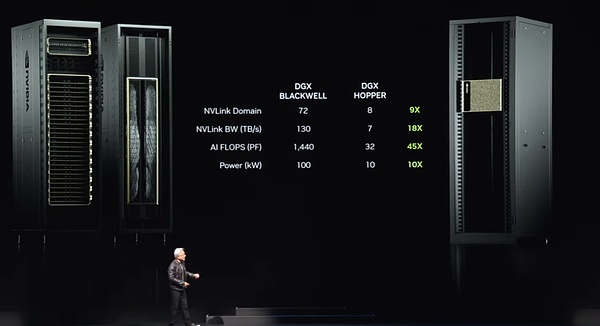
¿Cuáles son las ventajas de este clúster?Primero, en el dominio de GPU, ahora actúa como una GPU única y súper grande.Esta «Super GPU» tiene las capacidades centrales de 72 GPU, y el rendimiento es 9 veces mayor que la generación anterior de 8 GPU.Al mismo tiempo, el ancho de banda ha aumentado en 18 veces, los fracasos de IA (operaciones de punto flotante por segundo) han aumentado en 45 veces, y la potencia ha aumentado solo 10 veces.Es decir, uno de esos sistemas puede proporcionar una fuerte potencia de 100 kilovatios, mientras que la generación anterior era de solo 10 kilovatios.
Por supuesto, también puede conectar más de estos sistemas juntos para formar una red informática más grande.Pero el verdadero milagro radica en el hecho de que este chip de enlace NV se está volviendo cada vez más grande con el tamaño creciente del modelo de lenguaje grande.Debido a que estos modelos de lenguaje grande ya no son adecuados para ejecutarse en una sola GPU o nodo, requieren el funcionamiento de todo el estante de GPU juntos.Al igual que el nuevo sistema DGX que acabo de mencionar, puede acomodar modelos de lenguaje grandes con cientos de billones de parámetros.
El interruptor de enlace NV en sí es un milagro tecnológico, con 50 mil millones de transistores, 74 puertos y una velocidad de datos de hasta 400 GB por puerto.Pero lo más importante, el Switch también integra funciones de operación matemática, que pueden realizar directamente operaciones de reducción, lo cual es de gran importancia en el aprendizaje profundo.Este es el nuevo aspecto del sistema DGX actual.
Mucha gente siente curiosidad por nosotros.Cuestionaron que había un malentendido del alcance comercial de Nvidia.La gente se pregunta cómo Nvidia podría volverse tan grande con solo hacer GPU.Por lo tanto, muchas personas han formado la impresión de que la GPU debería verse de cierta manera.
Sin embargo, lo que quiero mostrarte ahora es que esta es de hecho una GPU, pero no es del tipo que crees que es.Esta es una de las GPU más avanzadas del mundo, pero se usa principalmente en el campo de juego.Pero todos sabemos que el verdadero poder de las GPU es mucho más que eso.
Todos, por favor, miren esto, esta es la verdadera forma de GPU.Esta es una GPU DGX diseñada para el aprendizaje profundo.La parte posterior de esta GPU está conectada a la columna vertebral del enlace NV, que consta de 5,000 líneas y tiene 3 kilómetros de largo.Estas líneas son la columna vertebral NV, que conecta 70 GPU para formar una poderosa red informática.Este es un milagro mecánico electrónico en el que el transceptor nos permite conducir señales a través de toda la longitud del cable de cobre.
Por lo tanto, este interruptor de enlace NV transmite datos en el cable de cobre a través de la columna vertebral del enlace NV, lo que nos permite ahorrar 20 kW de potencia en un solo bastidor, que ahora se usa completamente para el procesamiento de datos, que de hecho es un logro de hecho fascinante.Este es el poder de la columna vertebral del enlace NV.
8.Promover Ethernet para AI generativo
Pero esto no es suficiente para satisfacer la demanda, especialmente para las grandes fábricas de IA, por lo que tenemos otra solución.Tenemos que conectar estas fábricas de IA utilizando redes de alta velocidad.Tenemos dos opciones de red: Infiniband y Ethernet.Entre ellos, Infiniband se ha utilizado ampliamente en la supercomputación y las fábricas de inteligencia artificial en todo el mundo y está creciendo rápidamente.Sin embargo, no todos los centros de datos pueden usar Infiniband directamente porque han realizado inversiones significativas en el ecosistema Ethernet, y la gestión de InfiniBand Switches and Reds requiere cierta experiencia y tecnología.
Por lo tanto, nuestra solución es llevar el rendimiento de Infiniband a la arquitectura Ethernet, lo que no es fácil.La razón es que cada nodo, cada computadora, generalmente está conectado a diferentes usuarios en Internet, pero la mayor parte de la comunicación ocurre dentro del centro de datos, es decir, la transmisión de datos entre el centro de datos y los usuarios en el otro extremo de Internet .Sin embargo, en el escenario de aprendizaje profundo de las fábricas de inteligencia artificial, las GPU no se comunican con los usuarios en Internet, sino intercambios de datos frecuentes e intensivos entre sí.
Se comunican entre sí porque todos están recolectando parte de los resultados.Luego tienen que reducir estos resultados parciales y redistribuirlos.Este modo de comunicación se caracteriza por un tráfico altamente explosivo.Lo que importa no es el rendimiento promedio, sino los últimos datos que llegan, porque si está recopilando resultados parciales de todos y estoy tratando de recibir todos sus resultados parciales, si el último paquete llega tarde, toda la operación se retrasará .La latencia es un problema crucial para las fábricas de IA.
Por lo tanto, nuestro enfoque no está en rendimiento promedio, sino en garantizar que el último paquete llegue a tiempo y sin error.Sin embargo, el Ethernet tradicional no se ha optimizado para requisitos de latencia de baja y altamente sincronizados.Para satisfacer esta necesidad, diseñamos creativamente una arquitectura de extremo a extremo que permite que las NIC (tarjetas de interfaz de red) se comuniquen.Para lograr esto, hemos adoptado cuatro tecnologías clave:
Primero, NVIDIA tiene la tecnología RDMA líder de la industria (acceso remoto a la memoria directa).Ahora tenemos RDMA a nivel de red de Ethernet y hace un gran trabajo.
En segundo lugar, introdujimos un mecanismo de control de congestión.El interruptor tiene una función de telemetría en tiempo real, que puede identificarse y responder rápidamente a la congestión en la red.Cuando la cantidad de datos enviados por la GPU o NIC es demasiado grande, el conmutador envía inmediatamente una señal para informarles para reducir la velocidad de la transmisión, evitando así la generación de puntos de acceso de red.
Tercero, adoptamos tecnología de enrutamiento adaptativa.Ethernet tradicional transmite datos en un orden fijo, pero en nuestra arquitectura podemos ajustar de manera flexible en función de las condiciones de la red en tiempo real.Cuando se encuentra la congestión o algunos puertos están inactivos, podemos enviar paquetes a estos puertos inactivos y reordenarlos por el dispositivo Bluefield en el otro extremo para garantizar que los datos se devuelvan en el orden correcto.Esta tecnología de enrutamiento adaptativa mejora enormemente la flexibilidad y la eficiencia de la red.
Cuarto, implementamos la tecnología de aislamiento de ruido.En un centro de datos, el ruido y el tráfico generados por múltiples modelos de entrenamiento simultáneamente pueden interferir entre sí y causar famosos.Nuestra tecnología de aislamiento de ruido puede aislar efectivamente estos ruidos, asegurando que la transmisión de paquetes de datos críticos no se vea afectado.
Al adoptar estas tecnologías, hemos proporcionado con éxito soluciones de red de alto rendimiento y baja latencia a las fábricas de IA.En un centro de datos multimillonario, si la utilización de la red aumenta en un 40% y el tiempo de entrenamiento se reduce en un 20%, esto en realidad significa que un centro de datos de $ 5 mil millones es equivalente a un centro de datos de $ 6 mil millones, revela el impacto significativo. del rendimiento de la red en la rentabilidad general.
Afortunadamente, la tecnología Ethernet con Spectrum X es la clave de nuestro logro, lo que mejora enormemente el rendimiento de la red, lo que hace que los costos de red sean casi insignificantes en relación con todo el centro de datos.Este es, sin duda, un gran logro que hemos logrado en el campo de la tecnología de red.
Tenemos una alineación de productos Ethernet fuerte, la más notable de la cual es el Spectrum X800.Con 51.2 TB por segundo y 256 rutas (RADIX) de soporte, este dispositivo proporciona conectividad de red eficiente a miles de GPU.A continuación, planeamos lanzar el X800 Ultra en un año, lo que admitirá 512 Radix con hasta 512 rutas, mejorando aún más la capacidad y el rendimiento de la red.El X1600 está diseñado para centros de datos más grandes y puede satisfacer las necesidades de comunicación de millones de GPU.

Con el avance continuo de la tecnología, la era del centro de datos de millones de GPU está a la vuelta de la esquina.Hay profundas razones detrás de esta tendencia.Por un lado, estamos ansiosos por entrenar modelos más grandes y complejos; pero, lo que es más importante, las futuras interacciones de Internet e informática dependerán cada vez más de la inteligencia artificial generativa basada en la nube.Estos AIS funcionarán e interactuarán con nosotros para generar videos, imágenes, textos e incluso personas digitales.Por lo tanto, casi todas las interacciones que interactúamos con las computadoras son inseparables de la participación de la inteligencia artificial generativa.Y siempre hay una IA generativa conectada a ella, algunas que se ejecutan localmente, otras que se ejecutan en su dispositivo y muchos pueden ejecutarse en la nube.
Estas inteligencias artificiales generativas no solo tienen fuertes capacidades de razonamiento, sino que también optimizan de manera iterativa las respuestas para mejorar la calidad de las respuestas.Esto significa que generaremos necesidades masivas de generación de datos en el futuro.Esta noche, fuimos testigos del poder de esta innovación tecnológica juntos.
Blackwell, como la primera generación de la plataforma Nvidia, ha atraído mucha atención desde su lanzamiento.Hoy, la era de la inteligencia artificial generativa está marcando el comienzo del mundo, el comienzo de una nueva revolución industrial, y cada esquina es consciente de la importancia de las fábricas de inteligencia artificial.Nos sentimos profundamente honrados de haber recibido un amplio apoyo de todos los ámbitos de la vida, incluidos todos los OEM (fabricante de equipos originales), fabricante de computadoras, CSP (proveedor de servicios en la nube), GPU Cloud, Sovereign Cloud y Telecomunications Companies.
Estamos profundamente contentos de que el éxito de Blackwell, la adopción generalizada y el entusiasmo de la industria por ello hayan alcanzado niveles sin precedentes, y nos gustaría expresarle nuestra sincera gratitud.Sin embargo, nuestro ritmo no se detendrá.En esta era de rápido desarrollo, continuaremos trabajando duro para mejorar el rendimiento del producto, reducir el costo de la capacitación y el razonamiento, al tiempo que ampliamos continuamente las capacidades de la inteligencia artificial para que cada empresa pueda beneficiarse de él.Creemos firmemente que con la mejora del rendimiento, los costos se reducirán aún más.La plataforma Hopper es, sin duda, el procesador de centros de datos más exitoso de la historia.
9.Blackwell Ultra se lanzará el próximo año, y la plataforma de próxima generación se llama Rubin
Esta es una historia de éxito impactante.Como puede ver, el nacimiento de la plataforma Blackwell no es un componente único, sino un sistema completo que integra múltiples elementos como CPU, GPU, NVLink, Nick (componentes técnicos específicos) y conmutadores NVLINK.Estamos comprometidos a conectar estrechamente todas las GPU a través de cada generación utilizando interruptores grandes de velocidad ultra alta para formar un dominio de computación enorme y eficiente.
Integramos toda la plataforma en nuestra fábrica de IA, pero más críticamente, proporcionamos esta plataforma a clientes de todo el mundo en forma modular.La intención original de esto es que esperamos que cada socio cree una configuración única e innovadora basada en sus propias necesidades para adaptarse a diferentes estilos de centros de datos, diferentes grupos de clientes y diversos escenarios de aplicaciones.Desde la computación de borde hasta las telecomunicaciones, todo tipo de innovación será posible mientras el sistema permanezca abierto.
Para permitirle innovar libremente, hemos diseñado una plataforma integrada, pero al mismo tiempo que se le proporciona en descomposición, lo que le permite construir fácilmente sistemas modulares.Ahora, la plataforma Blackwell se ha lanzado por completo.
Nvidia siempre se adhiere al ritmo de actualización anual.Nuestra filosofía principal es muy clara: 1) construir soluciones que cubren toda la escala del centro de datos). Extremo, ya sea la tecnología de proceso de TSMC, la tecnología de envasado, la tecnología de memoria u tecnología óptica, todos buscamos el rendimiento final.
Después de completar el desafío final del hardware, haremos todo lo posible para garantizar que todo el software se ejecute sin problemas en esta plataforma completa.En tecnología informática, la inercia del software es crucial.Cuando nuestra plataforma de computadora es compatible hacia atrás y la arquitectura es perfectamente compatible con el software existente, la velocidad de los productos al mercado mejorará significativamente.Por lo tanto, cuando se lanzó la plataforma Blackwell, pudimos hacer uso completo de la base de ecosistemas de software construido para lograr una sorprendente velocidad de respuesta al mercado.El año que viene, daremos la bienvenida al Blackwell Ultra.
Al igual que la serie H100 y H200 que hemos lanzado, el Blackwell Ultra también liderará la locura de una nueva generación de productos, trayendo experiencias innovadoras sin precedentes.Al mismo tiempo, continuaremos desafiando los límites de la tecnología y lanzando el Spectrum Switch de próxima generación, que es el primer intento en la industria.Este gran avance se ha logrado con éxito, aunque todavía dudo un poco en hacer pública esta decisión.
Dentro de NVIDIA, estamos acostumbrados a usar nombres de código y mantener cierta confidencialidad.Muchas veces, incluso la mayoría de los empleados de la empresa no conocen muy bien estos secretos.Sin embargo, nuestra plataforma de próxima generación ha sido llamada Rubin.No entraré en detalles sobre Rubin aquí.Conozco la curiosidad de todos, pero por favor permítame mantener algo de misterio.Es posible que esté ansioso por tomar fotos o estudiar a esos pequeños personajes con cuidado, así que no dude en hacerlo.
No solo tenemos la plataforma Rubin, sino que también lanzaremos la plataforma Rubin Ultra en un año.Todos los chips que se muestran aquí están en plena etapa de desarrollo, asegurando que cada detalle esté cuidadosamente pulido.Nuestro ritmo de actualización todavía es una vez al año, siempre persiguiendo lo último en tecnología al tiempo que garantiza que todos los productos mantengan el 100% de compatibilidad arquitectónica.

Mirando hacia atrás en los últimos 12 años, desde el momento en que nació Imagenet, previmos el futuro del campo informático que sufrirá cambios en la tierra.Ahora, todo esto se ha convertido en una realidad, que coincide con nuestra idea original.Desde GeForce antes de 2012 hasta Nvidia hoy, la compañía ha sufrido una gran transformación.Aquí, me gustaría agradecer sinceramente a todos mis socios por su apoyo y compañía en el camino.
10.La era de los robots ha llegado
Esta es la plataforma Blackwell de Nvidia.
La inteligencia artificial física lidera una nueva ola en el campo de la inteligencia artificial.Con este fin, la inteligencia artificial física no solo necesita construir un modelo mundial preciso para comprender cómo interpretar y percibir el mundo que lo rodea, sino que también necesita tener excelentes habilidades cognitivas para comprender profundamente nuestras necesidades y realizar tareas de manera eficiente.
Mirando hacia el futuro, la robótica ya no será un concepto fuera de alcance, sino que se integrará cada vez más en nuestra vida diaria.Cuando se habla de robótica, las personas a menudo piensan en robots humanoides, pero de hecho, sus aplicaciones son mucho más que eso.La mecanización se convertirá en la norma, las fábricas realizarán plenamente la automatización y los robots trabajarán juntos para crear una serie de productos mecanizados.La interacción entre ellos estará más cerca, creando un entorno de producción altamente automatizado juntos.
Para lograr esto, necesitamos superar una variedad de desafíos técnicos.A continuación, mostraré estas tecnologías de vanguardia a través de video.
Esta no es solo una visión para el futuro, sino que gradualmente se está convirtiendo en una realidad.
Serviremos al mercado de varias maneras.Primero, estamos comprometidos a crear plataformas para diferentes tipos de sistemas de robots: plataformas dedicadas para fábricas y almacenes de robots, plataformas de robot de manipulación de objetos, plataformas de robots móviles y plataformas de robot humanoides.Al igual que muchos de nuestros otros negocios, estas plataformas robóticas dependen de las bibliotecas de aceleración de la computadora y los modelos previamente capacitados.
Utilizamos bibliotecas de aceleración informática, modelos previamente capacitados y realizamos pruebas integrales, capacitación e integración en Omniverse.Como muestra el video, Omniverse es donde los robots aprenden cómo adaptarse mejor al mundo real.Por supuesto, el ecosistema de los almacenes de robots es extremadamente complejo y requiere muchas empresas, herramientas y tecnologías para construir conjuntamente almacenes modernos.Hoy, los almacenes se están moviendo gradualmente hacia la mecanización completa y algún día se automatizarán completamente.
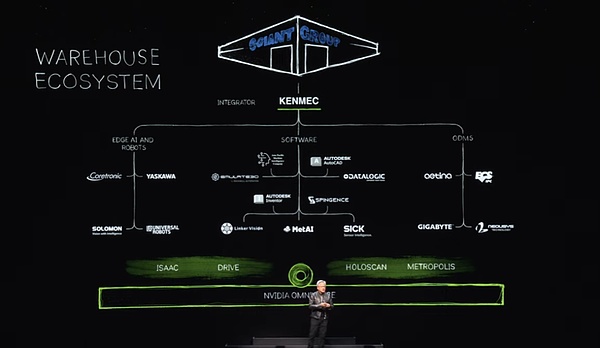
En dicho ecosistema, proporcionamos interfaces SDK y API para la industria del software, la industria y las empresas de inteligencia artificial de borde, y también diseñamos sistemas dedicados para sistemas PLC y robóticos para satisfacer las necesidades de campos específicos como el Ministerio de Defensa.Estos sistemas están integrados a través de integradores para finalmente crear almacenes eficientes e inteligentes para los clientes.Por ejemplo, Ken Mac está construyendo un almacén de robot para el grupo gigante gigante.
A continuación, centrémonos en el campo de la fábrica.El ecosistema de la fábrica es muy diferente.Tome Foxconn como ejemplo, están construyendo algunas de las fábricas más avanzadas del mundo.Los ecosistemas de estas fábricas también cubren las computadoras de borde, el software robótico, para diseñar diseños de fábricas, optimizar flujos de trabajo, programas de robots y computadoras PLC utilizadas para coordinar las fábricas digitales y las fábricas de inteligencia artificial.También proporcionamos una interfaz SDK para cada enlace en estos ecosistemas.
Tales cambios están teniendo lugar en todo el mundo.Foxconn y Delta están construyendo gemelos digitales para que sus fábricas logren una combinación perfecta de realidad y digital, y Omniverse juega un papel crucial.También vale la pena mencionar que Pegatron y Wistron también están siguiendo la tendencia y estableciendo instalaciones gemelas digitales para sus respectivas fábricas de robots.
Esto es realmente emocionante.A continuación, disfruta de un maravilloso video de la nueva fábrica de Foxconn.
La fábrica de robots consta de tres sistemas informáticos principales que entrenan modelos AI en la plataforma NVIDIA AI, y nos aseguramos de que el robot se ejecute de manera eficiente en el sistema local para orquestar los procesos de fábrica.Al mismo tiempo, utilizamos Omniverse, una plataforma de colaboración de simulación para simular todos los elementos de fábrica, incluidos los brazos robóticos y AMR (robot móvil autónomo).Vale la pena mencionar que estos sistemas de simulación comparten el mismo espacio virtual para lograr una interacción y colaboración perfecta.
Cuando las armas robóticas y el AMR ingresan a este espacio virtual compartido, pueden simular un entorno de fábrica real en omniverso, asegurando una verificación y optimización adecuadas antes de la implementación real.
Para mejorar aún más el rango de integración y aplicaciones de soluciones, ofrecemos tres computadoras de alto rendimiento, equipadas con capas de aceleración y modelos de IA pretrados.Además, hemos combinado con éxito NVIDIA Manipulator y Omniverse con el software y los sistemas de automatización industrial de Siemens.Esta colaboración permite a Siemens permitir una operación y automatización de robots más eficientes en las fábricas de todo el mundo.
Además de Siemens, también hemos establecido relaciones cooperativas con muchas compañías conocidas.Por ejemplo, Symantec Pick Ai ha integrado el manipulador Nvidia Isaac, mientras que Somatic Pick Ai ha ejecutado y operado con éxito robots de marcas conocidas como ABB, Kuka y Yaskawa Motoman.
La era de la robótica y la inteligencia artificial física ha llegado, y están siendo ampliamente utilizados en todas partes.Mirando hacia el futuro, los robots en las fábricas se convertirán en la corriente principal, y harán todos los productos, dos de los cuales son particularmente llamativos.Primero, los autos o autos autónomos con alta autonomía, Nvidia una vez más juega un papel central en este campo con su pila de tecnología integral.El año que viene, planeamos unirnos al equipo de Mercedes-Benz y luego trabajar con el equipo de Jaguar Land Rover (JLR) en 2026.Ofrecemos una pila de soluciones completa, pero los clientes pueden elegir cualquier parte o jerarquía en función de sus necesidades, ya que toda la pila de controladores está abierta y flexible.
A continuación, otro producto que puede fabricarse con altos rendimientos de las fábricas de robots son los robots humanoides.En los últimos años, se han realizado grandes avances en la capacidad cognitiva y la capacidad de comprensión mundial, y las perspectivas de desarrollo en este campo son emocionantes.Estoy particularmente entusiasmado con los robots humanoides porque es más probable que se adapten al mundo que hemos construido para los humanos.
El entrenamiento de robots humanoides requiere muchos datos en comparación con otros tipos de robots.Dado que tenemos formas corporales similares, la gran cantidad de datos de entrenamiento proporcionados a través de capacidades de demostración y video será de gran valor.Por lo tanto, esperamos un progreso significativo en esta área.

Ahora, damos la bienvenida a algunos amigos de robot especiales.La era de los robots ha llegado, y esta es la próxima ola de inteligencia artificial.Hay una amplia variedad de computadoras hechas en Taiwán, incluidos modelos tradicionales equipados con teclados, dispositivos móviles pequeños, ligeros y portátiles, así como equipos profesionales que proporcionan potencia informática para centros de datos en la nube.Pero mirando hacia el futuro, testificaremos un momento más emocionante: crear computadoras que puedan caminar y rodar, a saber, robots inteligentes.
Estos robots inteligentes tienen similitudes técnicas sorprendentes con las computadoras tal como las conocemos, y todos se basan en tecnologías avanzadas de hardware y software.Entonces, ¡tenemos razones para creer que este será un viaje realmente extraordinario!







