
出典:Tencent Technology
Nvidiaの共同設立者兼CEO Huang Renxunは、Computex 2024(2024 Taipei International Computer Exhibition)で基調講演を行い、人工知能の時代がグローバルな新しい産業革命をどのように促進できるかを共有しました。
このスピーチの重要なポイントは次のとおりです。
Huang Renxunは、最新の大量生産バージョンのBlackwell Chipsを披露し、2025年にBlackwell Ultra AIチップを発売すると述べました。 「年に一度」、「ムーア」を破る「法」。
Huang Renxunは、Nvidiaが大規模な言語モデルの誕生を促進し、2012年以降にGPUアーキテクチャを変更し、すべての新しいテクノロジーを単一のコンピューターに統合したと主張しました。
nvidiaの加速コンピューティングテクノロジーは、レートの100倍の増加を達成するのに役立ちましたが、消費電力は3倍に増加し、コストは1.5倍です。
Huang Renxunは、次世代のAIが物理的な世界を理解する必要があることを期待しています。彼が与えた方法は、AIにビデオと合成データを通じて学習させ、AIがお互いから学習できるようにすることです。
Huang Renxunは、PPT -CI Yuanでのトークンの中国語翻訳を完成させました。
Huang Renxunは、ロボットの時代が到着し、すべての移動オブジェクトが将来独立して動作すると述べました。

以下は、Tencentテクノロジーによって編集された2時間の音声の完全な成績証明書です。
親愛なるゲスト、私は再びここに来ることができてとても光栄です。まず第一に、この体育館をイベントの会場として提供してくれた台湾大学に感謝したいと思います。私が最後にここに来たのは、台湾大学で学位を取得したときでした。今日、私たちが探求しようとしているものがたくさんあるので、私はメッセージを迅速かつ明確な方法でスピードアップして伝えなければなりません。私たちには多くのトピックについて話すべきものがあり、あなたと共有するエキサイティングな物語がたくさんあります。
私たちのパートナーの多くがここにいる中国の台湾にここにいることをとてもうれしく思います。実際、これはNvidiaの開発史の不可欠な部分であるだけでなく、私たちとパートナーが世界に革新を共同で促進するための重要なノードでもあります。私たちは多くのパートナーと協力して、世界中の人工知能インフラストラクチャを構築しています。今日、私はあなたといくつかの重要なトピックについて話したいです:
1)私たちの共同作業でどのような進歩があり、これらの進歩の重要性は何ですか?
2)生成的人工知能とは何ですか?それは私たちの業界、そしてすべての業界でさえどのように影響しますか?
3)私たちがどのように前進することができるか、そしてこの信じられないほどの機会をどのようにつかむかについての青写真ですか?
次に何が起こりますか?生成的AIとその深い影響、当社の戦略的な青写真はすべて、私たちが探求しようとしているエキサイティングなトピックです。私たちはコンピューター業界の再起動の出発点に立っており、あなたによって作成され、あなたによって作成された新しい時代が始まります。今、あなたは次の重要な旅の準備ができています。
1。コンピューティングの新しい時代が始まっています
しかし、詳細な議論を始める前に、私は1つのことを強調したいと思います。Nvidiaは、私たちの会社の魂を形成するコンピューターグラフィック、シミュレーション、人工知能の交差点にあります。今日、私があなたに見せることはすべてシミュレーションに基づいています。これらは単なる視覚効果ではなく、数学、科学、コンピューターサイエンス、息をのむようなコンピューターアーキテクチャの本質です。事前に作られたアニメーションはありません。すべてが私たち自身のチームの傑作です。それがNvidiaが理解していることであり、私たちが誇りに思っているOmniverse Virtual Worldにすべてを組み込みます。さあ、ビデオをお楽しみください!
世界中のデータセンターの消費電力は急激に増加していますが、計算コストも上昇しています。私たちは計算インフレの厳しい課題に直面していますが、これは明らかに長い間維持することはできません。データは指数関数的に増加し続けますが、CPUのパフォーマンスの拡大は以前と同じように迅速に拡張することが困難です。ただし、より効率的なアプローチが出現しています。
ほぼ20年間、私たちは加速コンピューティング研究に取り組んできました。CUDAテクノロジーは、CPUの機能を強化し、特別なプロセッサがより効率的に完了できるタスクをオフロードおよび加速します。実際、CPUパフォーマンスの拡大が減速または停滞しているため、加速コンピューティングの利点はますます重要になっています。すべての処理集約型アプリケーションが加速され、近い将来、すべてのデータセンターが完全に加速されると予測します。

現在、加速コンピューティングを選択することは賢明な動きであり、業界のコンセンサスになっています。アプリケーションが完了するまでに100単位の時間がかかると想像してください。100秒であろうと100時間であろうと、多くの場合、数日または数か月にわたって実行されるAIアプリケーションに耐えることができません。
これらの100時間ユニットのうち、1回のユニットには、この時点で実行する必要があるコードが含まれます。オペレーティングシステムの制御ロジックは不可欠であり、命令シーケンスに従って厳密に実行する必要があります。ただし、コンピューターグラフィックス、画像処理、物理シミュレーション、組み合わせ最適化、グラフ処理、データベース処理など、特に並列処理による加速に適したリニア代数など、多くのアルゴリズムがあります。これを達成するために、GPUとCPUを完全に組み合わせた革新的なアーキテクチャを発明しました。
専用のプロセッサは、それ以外の場合は時間のかかるタスクを信じられないほどの速度までスピードアップできます。2つのプロセッサは並行して動作できるため、それぞれ独立して独立して実行されます。これは、もともと100単位の時間を必要としたタスクが、わずか1単位で完了できることを意味します。この加速効果は信じられないほど聞こえますが、今日は一連の例でこのステートメントを検証します。

このパフォーマンスの改善の利点は驚くべきものであり、100倍の加速度で、電力が約3倍で、コストが約50%増加しています。私たちはすでにPC業界でこの戦略を実践しています。500ドルのGEFORCE GPUをPCに追加すると、パフォーマンスが大幅に向上し、全体の値が1,000ドルに増加します。データセンターでは、同じアプローチを採用しています。10億ドルのデータセンターは、5億ドルのGPUを追加した後、即座に強力な人工知能工場に変身しました。今日、この変化は世界中で起こっています。
コスト削減も同様に衝撃的です。投資された1ドルごとに、最大60倍のパフォーマンスの向上が得られます。加速度は100倍ですが、電力はわずか3倍で、コストはわずか1.5倍です。節約は本物です!
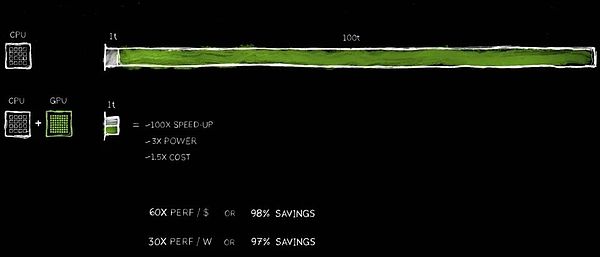
どうやら、多くの企業は、クラウド内のデータの処理に数億ドルを費やしています。データがより速く処理されると、数億ドルを節約することが妥当になります。なぜこれが起こっているのですか?その理由は簡単です。一般的なコンピューティングで長期的な効率のボトルネックを経験しました。
今、私たちはついにこれを認識し、それをスピードアップすることにしました。専用のプロセッサを採用することで、以前に見落とされがちなパフォーマンスの向上を多く取り戻し、多くのお金とエネルギーを節約できます。だから私が言うのは、あなたが買うほど、あなたはより多くを節約します。
今、私はあなたに数字を示しました。それらはいくつかの小数の場所には正確ではありませんが、これは事実を正確に反映しています。これは「CEO数学」と呼ぶことができます。CEOの数学は極端な精度を追求していませんが、その背後にあるロジックは正しいです – 購入するコンピューティングパワーが増えるほど、より多くのコストを節約できます。
2。350機能ライブラリは、新しい市場の開設に役立ちます
加速コンピューティングの結果は実際には並外れていますが、実装プロセスは容易ではありません。なぜそんなにお金を節約しますが、人々はこのテクノロジーを以前に採用していませんか?その理由は、実装が難しすぎるからです。
コンパイラを加速するだけで実行できる既製のソフトウェアはなく、アプリケーションは即座に100回高速化できます。これは論理的でも現実的でもありません。それがとても簡単だったら、CPUメーカーはこれをずっと前にやっていたでしょう。
実際、加速を達成するには、ソフトウェアを完全に書き直す必要があります。これはプロセスの最も挑戦的な部分です。ソフトウェアは、元々CPUで実行されていたアルゴリズムをアクセルで並行して実行できる形式に変換するために、再設計および再設計する必要があります。
このコンピューターサイエンスの調査は困難ですが、過去20年間で大きな進歩を遂げてきました。たとえば、ニューラルネットワークの加速の処理を専門とする人気のあるCudnn Deep Learning Libraryを立ち上げました。また、物理的法則の順守を必要とする流体ダイナミクスなどのアプリケーションのための人工知能物理シミュレーションのライブラリを提供します。さらに、CUDAを使用して5Gラジオテクノロジーを加速するAerialと呼ばれる新しいライブラリがあり、ソフトウェアを使用してソフトウェア定義のインターネットネットワークなどの通信ネットワークを定義および加速することができます。

これらの加速機能は、パフォーマンスを改善するだけでなく、通信産業全体をクラウドコンピューティングと同様のコンピューティングプラットフォームに変えるのにも役立ちます。さらに、Coolitho Computing Lithographyプラットフォームも良い例であり、チップ製造プロセスの最も計算的に集中的な部分であるマスク製造の効率を大幅に改善します。TSMCなどの企業は、すでにEnergyを大幅に節約するだけでなく、コストを大幅に削減するだけでなく、生産にCoolithoの使用を開始しています。彼らの目標は、テクノロジースタックを加速することにより、より深く狭いトランジスタを作るために必要なアルゴリズムのさらなる開発と巨大なコンピューティング能力に備えることです。
レンガのペアは、世界をリードする遺伝子シーケンススループットを備えた誇り高き遺伝子シーケンスライブラリです。Co Optは、ルート計画、旅程の最適化、旅行代理店の問題などの複雑な問題を解決できる驚くべき組み合わせ最適化ライブラリです。一般に、これらの問題は量子コンピューターによって解決する必要があると考えられていますが、加速したコンピューティングテクノロジーを通じて非常に高速なアルゴリズムを作成し、今日まで23の世界記録を維持しています。
クーデターQuantumは、私たちが開発した量子コンピューターシミュレーションシステムです。信頼できるシミュレータは、量子コンピューターまたは量子アルゴリズムを設計したい研究者にとって不可欠です。実際の量子コンピューターがなければ、Nvidia cuda(私たちが世界で最も速いコンピューターと呼んでいるもの)が彼らの好みのツールになりました。量子コンピューターの動作をシミュレートし、研究者が量子コンピューティングの分野でブレークスルーを行うのに役立つシミュレーターを提供します。このシミュレーターは、世界中の数十万人の研究者によって広く使用されており、すべての主要な量子コンピューティングフレームワークに統合されており、世界中の科学的スーパーコンピューティングセンターに強力なサポートを提供しています。
さらに、データ処理ライブラリKudieffを起動しました。これは、データ処理を加速するために特別に設計されています。データ処理は、今日のクラウド支出の大部分を占めるため、データ処理の加速はコスト削減に不可欠です。QDFは、Spark、Pandas、Polar、NetworkXグラフ処理データベースなど、世界の主要なデータ処理ライブラリのパフォーマンスを大幅に改善できるように開発した加速ツールです。
これらのライブラリはエコシステムの重要なコンポーネントであり、加速コンピューティングを広く使用できるようにします。Cudnnなどの慎重に作成されたドメイン固有のライブラリがなければ、CUDAとTensorflowやPytorchなどの深い学習フレームワークで使用されるアルゴリズムの間には大きな違いがあるため、世界中の深い学習科学者がCUDAでその可能性を完全に活用することはできないかもしれません。これは、OpenGLなしでコンピューターグラフィックを実行したり、SQLなしでデータを処理するのと同じくらい非現実的です。
これらのドメイン固有のライブラリは当社の宝物であり、現在350以上のライブラリがあります。これらの図書館が私たちを公開し、市場に先んじています。今日は、もっとエキサイティングな例を紹介します。
先週、GoogleはクラウドにQDFSを展開し、パンダを成功裏に加速したことを発表しました。Pandasは世界で最も人気のあるデータサイエンスライブラリであり、世界中で1,000万人のデータサイエンティストが使用しており、最大1億7000万回の毎月のダウンロードがあります。それは、データを処理するための右側のアシスタントであるデータサイエンティストのExcelのようなものです。
これで、GoogleのCloud Data Center Platform Colabをクリックするだけで、QDFが加速したパンダがもたらす強力なパフォーマンスを体験できます。この加速は本当に驚くべきものであり、今見たデモと同じように、データ処理タスクがほぼ瞬時に完了します。
3。Cudaは高潔なサイクルを実現します
Cudaは人々が重要なポイントと呼ぶものに到達しましたが、現実はそれよりも優れています。CUDAは、好工場サイクルを達成しました。歴史とさまざまなコンピューティングアーキテクチャやプラットフォームの開発を振り返ってみると、このようなループは一般的ではないことがわかります。マイクロプロセッサCPUを例として取り上げますが、その加速コンピューティングは長年にわたって根本的に変化していません。
新しいコンピューティングプラットフォームの作成は、しばしば「最初に鶏がいるか、最初に卵がいる」というジレンマに直面しています。開発者のサポートがなければ、プラットフォームがユーザーを引き付けることは困難です。このジレンマは、過去20年間の複数のコンピューティングプラットフォームの開発を悩ませてきました。
ただし、ドメイン固有のライブラリと加速ライブラリを継続的に展開することにより、このジレンマを首尾よく壊しました。今日、私たちは世界中に500万人の開発者がいて、CUDAテクノロジーを使用して、ヘルスケア、金融サービスからコンピューター業界、自動車産業まで、ほぼすべての主要な産業と科学分野にサービスを提供しています。
顧客ベースが拡大し続けるにつれて、OEMSとクラウドサービスプロバイダーも当社のシステムへの関心を高め始めており、さらに多くのシステムが市場に参入するように促進しています。この高潔なサイクルは、私たちにとって大きな機会を生み出し、私たちの規模を拡大し、R&D投資を増やすことができ、それにより、より多くのアプリケーションの加速開発を促進することができます。
各アプリケーションの加速とは、コンピューティングコストが大幅に削減されることを意味します。前に示したように、100倍の加速により、最大97.96%、または98%近くのコスト削減が可能になります。計算の加速を100倍から200倍から1000倍に増やすと、計算の限界費用が減少し続け、顕著な経済的利益を示しています。
もちろん、コンピューティングコストを大幅に削減することにより、市場、開発者、科学者、発明者がより多くのコンピューティングリソースを消費する新しいアルゴリズムを発掘し続けると考えています。ある時点まで、深い変化が静かに起こります。コンピューティングの限界費用が非常に低くなると、コンピューターを使用するまったく新しい方法が生まれます。
実際、この変化は私たちの目の前で起こっています。過去10年間で、特定のアルゴリズムを使用して、驚くべき100万回のコンピューティングの限界費用を削減しました。今日、インターネット上のすべてのデータを使用して大規模な言語モデルをトレーニングすることは、論理的で自然な選択になり、もはや疑問視されていません。
アイデア – 膨大な量のデータとプログラム自体を処理できるコンピューターを構築するというアイデアは、人工知能の台頭の基礎です。人工知能の台頭は完全に可能です。なぜなら、コンピューティングを安くすると常に大きな用途があると固く信じているからです。今日、CUDAの成功は、この高潔なサイクルの実現可能性を証明しています。
インストール財団の継続的な拡大とコンピューティングコストの継続的な削減により、ますます多くの開発者が革新的な可能性を実現し、より多くのアイデアとソリューションを提案することができます。この革新により、市場の需要が急増しています。今、私たちは大きなターニングポイントに立っています。ただし、さらに説明する前に、以下に表示したいことは、CUDAと現代のAIテクノロジー、特に生成AIのブレークスルーがなければ不可能であることを強調したいと思います。
これは地球2プロジェクトです。つまり、地球のデジタル双子を作成するという野心的なアイデアです。地球全体の動きをシミュレートして、将来の変化を予測します。このようなシミュレーションにより、災害を防ぎ、気候変動の影響をより深く理解し、これらの変化により適応し、行動や習慣を変え始めることさえできます。
地球2プロジェクトは、おそらく世界で最も挑戦的で野心的なプロジェクトの1つです。私たちは毎年この分野で大きな進歩を遂げており、今年の結果は特に目立っています。さて、これらのエキサイティングな進歩を見せてください。
近い将来、地球上のあらゆる平方キロメートルをカバーする継続的な気象予測機能があります。気候がどのように変化するかを常に理解します。この予測は、非常に限られたエネルギーを必要とするAIを訓練するため、引き続き実行されます。それは信じられないほどの成果です。皆さんがそれを楽しむことを願っています。さらに重要なことに、この予測は実際にはジェンセンAIによって行われました。私はそれを設計しましたが、最終的な予測はJensen AIによって提示されます。
パフォーマンスを継続的に改善し、コストを削減するよう努めているため、研究者は2012年にCUDAを発見しました。私たちは、深い学習を可能にするために科学者と緊密に協力するという賢明な選択をしたので、その日は私たちにとって重要です。Alexnetの出現は、コンピュータービジョンの大きなブレークスルーを達成しました。
4。AIスーパーコンピューターの台頭は最初は認識されませんでした
しかし、より重要な知恵は、私たちが一歩後退し、深い学習の性質を深く理解していることです。その基礎は何ですか?その長期的な影響は何ですか?その可能性は何ですか?このテクノロジーは、数十年前に発明され発明され発見されたアルゴリズムを拡大し続ける大きな可能性があることを認識しています。より多くのデータ、より大きなネットワーク、重要なコンピューティングリソースを組み合わせて、深い学習はアルゴリズムが到達できない人間のタスクを突然達成できます。
さて、アーキテクチャをさらに拡張し、より大きなネットワーク、より多くのデータ、およびコンピューティングリソースを持っているとどうなるか想像してみてください。だから私たちはすべてを再発明することにコミットしています。2012年以来、GPUのアーキテクチャを変更し、テンソルコアを追加し、NV-Linkを発明し、Cudnn、Tensort、Nickelを発射し、Mellanoxを取得し、Triton Incerence Serverを起動しました。
これらのテクノロジーは、新しいコンピューターに統合されており、当時のすべての想像力を上回りました。誰もそのような要求をしなかったとは思っていませんでしたし、誰もその潜在能力を完全に理解していませんでした。実際、誰かがそれを買いたいかどうかはわかりません。
しかし、GTC会議では、この技術を正式にリリースしました。Openaiと呼ばれるサンフランシスコのスタートアップは、私たちの結果にすぐに気づき、デバイスを提供するように頼みました。私は個人的に世界初の人工知能スーパーコンピューターDGXをOpenaiに送りました。
2016年、R&Dスケールの拡大を続けました。単一の人工知能スーパーコンピューターから単一の人工知能アプリケーションまで、2017年に大規模で強力なスーパーコンピューターの発売に拡大しました。テクノロジーの継続的な進歩により、世界は変圧器の台頭を目撃しました。このモデルの出現により、大量のデータを処理し、長いスパンにわたって連続パターンを特定して学習することができます。
今日、私たちはこれらの大規模な言語モデルを訓練して、自然言語の理解において大きなブレークスルーを達成する能力を持っています。しかし、私たちはそこで止まらず、前進し続け、より大きなモデルを構築しました。2022年11月までに、非常に強力な人工知能スーパーコンピューターで、トレーニングには数万のNvidia GPUを使用しています。
わずか5日後、OpenaiはChatGptに100万人のユーザーがいることを発表しました。この驚くべき成長率は、わずか2か月で1億人のユーザーに上昇し、アプリケーション史上最速の成長記録を樹立しました。その理由は非常にシンプルです-ChatGptのユーザーエクスペリエンスは便利で魔法のようなものです。
ユーザーは、まるで実際の人々と通信しているかのように、コンピューターと自然かつスムーズにやり取りできます。退屈な指示や明確な説明がなければ、ChatGptはユーザーの意図とニーズを理解することができます。
ChatGptの出現はエポック作りの変化を示しており、このスライドはこの重要なひねりをキャプチャします。私にあなたのためにそれを見せてもらってください。
ChatGptの出現まで、世界に生成された人工知能の無限の可能性を真に明らかにしました。長い間、人工知能の焦点は、自然言語の理解、コンピュータービジョン、音声認識、人間の知覚能力のシミュレーションに特化した技術など、知覚の分野に焦点を合わせてきました。しかし、ChatGptは、認識に限定されるだけでなく、初めて生成的人工知能の力を実証する定性的な飛躍をもたらしました。
トークンを1つずつ生成します。これは、単語、画像、チャート、テーブル、さらには曲、テキスト、音声、ビデオなどです。トークンは、それが化学物質、タンパク質、遺伝子、または前述の天候パターンであろうと、明確な意味を持つあらゆるものを表すことができます。
この生成的人工知能の台頭は、物理的現象を学習してシミュレートできることを意味し、人工知能モデルが物理世界でさまざまな現象を理解し、生成できるようにします。私たちはもはやスコープとフィルタリングを絞り込むことに制限するのではなく、代わりに世代を通じて無限の可能性を探求します。
今日、私たちは、それが車のステアリングホイールコントロール、ロボットアームの関節の動き、または現時点で学ぶことができるものであろうと、ほとんど価値のあるものにトークンを生成できます。したがって、私たちはもはや人工知能の時代ではなく、生成的人工知能が導く新しい時代です。
さらに重要なことは、もともとスーパーコンピューターとして登場していたこのデバイスは、現在、効率的で効率的な人工知能データセンターに進化しています。トークンを生成するだけでなく、価値を生み出す人工知能工場も生成し続けています。この人工知能ファクトリーは、大きな市場の可能性を備えた新しい商品を生み出し、作成し、生産しています。
ニコラテスラが19世紀の終わりにオルタネーターを発明し、エレクトロニクスの安定した流れをもたらしたように、Nvidiaの人工知能ジェネレーターは、無限の可能性を備えたトークンも継続的に生成しています。どちらも巨大な市場機会を持ち、すべての業界で変化することが期待されています。これは確かに新しい産業革命です!
現在、すべての業界向けに前例のない貴重な新製品を生産できる新しい工場を歓迎しています。この方法は非常にスケーラブルであるだけでなく、完全に再現可能です。現在、さまざまな人工知能モデルが毎日絶えず出現していることに注意してください。特に生成的な人工知能モデルです。今日、すべての業界が参加するために競争しています。これは前例のない壮大な機会です。
3兆ドルのIT業界は、100兆ドルの業界に直接役立つ革新的な成果を生み出しています。それはもはや情報ストレージやデータ処理のための単なるツールではなく、すべての業界でインテリジェンスを生成するためのエンジンです。これは新しいタイプの製造業になりますが、従来のコンピューター製造業ではなく、コンピューターを使用した製造の新しいモデルです。このような変化は以前に起こったことがなく、それは確かに驚くべきことです。
5。生成AIは、ソフトウェアのフルスタックの再形成を促進し、NIM Cloud-Nativeマイクロサービスを実証します
これにより、加速コンピューティングの新しい時代が開かれ、人工知能の急速な発展が促進され、生成的人工知能の台頭が生まれました。そして今、私たちは産業革命を経験しています。その影響を詳しく見てみましょう。
この変化の影響は、私たちの業界にとって非常に広範囲に及んでいます。前にも言ったように、これは過去60年ぶりに、コンピューティングのすべての層が変換を受けています。CPUの汎用コンピューティングからGPUの加速コンピューティングまで、各変化はテクノロジーの飛躍を示しています。
過去には、コンピューターは操作を実行するための指示に従う必要がありましたが、今ではLLM(Big Language Model)および人工知能モデルをより多く扱っています。過去のコンピューティングモデルは検索に基づいており、ほぼ携帯電話を使用するたびに、事前に保存されたテキスト、画像、またはビデオを取得し、推奨システムに従ってこれらのコンテンツを再結合して提示します。
しかし、将来的には、コンピューターはできるだけ多くのコンテンツを生成し、必要な情報のみを取得します。これは、データを生成すると情報を取得するときにエネルギーを消費するエネルギーが少ないためです。さらに、生成されたデータはコンテキストの関連性が高く、ニーズをより正確に反映できます。答えが必要な場合は、コンピューターに「その情報を取得してください」または「そのファイルを与える」ように明示的に指示する必要はなく、単に「答えをください」と言うだけです。
さらに、コンピューターはもはや私たちが使用するツールではなく、スキルを生み出し始めます。タスクを実行し、もはや生産ソフトウェア業界ではありません。これは、1990年代初頭の破壊的なアイデアでした。覚えて?Microsoftが提案するソフトウェアパッケージの概念は、PC業界を完全に変えました。パッケージ化されたソフトウェアがなければ、当社のPCはその機能のほとんどを失います。このイノベーションは、業界全体の発展を促進しています。
これで、新しい工場、新しいコンピューターがあり、これに基づいて新しいタイプのソフトウェアが実行されています。NIM(nvidia Inferenceマイクロサービス)と呼ばれます。この新しい工場で実行されているNIMは、人工知能である事前に訓練されたモデルです。

このAI自体は非常に複雑ですが、AIを実行するコンピューティングスタックは非常に複雑です。ChatGptのようなモデルを使用する場合、その背後には巨大なソフトウェアスタックがあります。このスタックは複雑で巨大です。モデルには数十億ドルから数十億のパラメーターがあり、1つのコンピューターだけでなく、複数のコンピューターで一緒に動作するためです。
効率を最大化するには、システムは、テンソル並列性、パイプライン並列性、データ並列性、専門家の並列性など、さまざまな並列処理のために複数のGPUにワークロードを割り当てる必要があります。このような割り当ては、工場ではスループットが収益、サービスの質、および提供できる顧客の数に直接関係するため、できるだけ早く作業を完了できるようにすることです。今日、私たちはデータセンターのスループット利用が重要な時代にいます。
過去には、スループットは重要であると考えられていましたが、決定的な要因ではありませんでした。ただし、データセンターが真の「工場」になったため、起動時間、実行時間、使用率、スループットまでのすべてのパラメーターが正確に測定されます。この工場では、運用効率は会社の財務パフォーマンスに直接関係しています。
この複雑さを考えると、AIを展開する際にほとんどの企業が直面する課題を知っています。したがって、展開して管理しやすいボックスにAIをカプセル化する統合されたAIコンテナソリューションを開発しました。このボックスには、Cuda、Cudacnn、Tensortなどのソフトウェアの膨大なコレクションと、Triton Inferenceサービスが含まれています。クラウドネイティブ環境をサポートし、Kubernetes(コンテナテクノロジーに基づいた分散アーキテクチャソリューション)環境での自動スケーリングを可能にし、ユーザーが人工知能サービスの運用状況を監視できるように管理サービスを提供します。
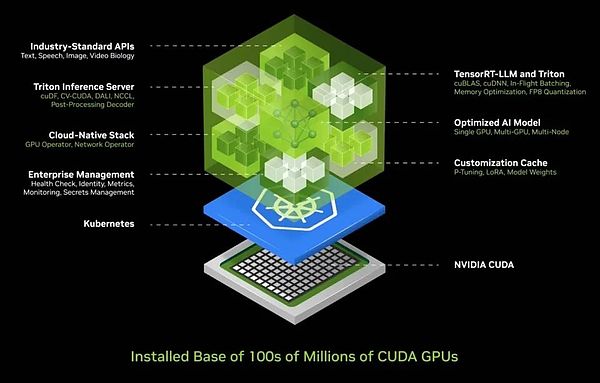
さらにエキサイティングなのは、このAIコンテナが普遍的な標準APIインターフェイスを提供し、ユーザーが「ボックス」と直接対話できることです。ユーザーは、NIMをダウンロードしてCUDA対応コンピューターで実行するだけで、AIサービスを簡単に展開および管理できます。今日、CUDAはどこにでもあり、主要なクラウドサービスプロバイダーをサポートしており、ほとんどすべてのコンピューターメーカーがCUDAサポートを提供しており、数億個のPCで見つけることができます。
NIMをダウンロードすると、CHATGPTとの会話のようにスムーズに通信するAIアシスタントがすぐにあります。現在、すべてのソフトウェアが合理化され、1つの容器に統合されており、以前は面倒な400の依存関係がすべて最適化されています。NIMの厳密なテストを実施し、Pascal、Ampere、最新のホッパーなどのGPUのさまざまなバージョンを含む、各優先モデルがクラウドインフラストラクチャで完全にテストされました。これらのバージョンはさまざまなもので、ほとんどすべての要件をカバーしています。
ニムの発明は間違いなく偉業であり、私の最も誇りに思う成果の1つです。今日、私たちは、ヘルスケアやデジタル生物学などの特定の業界向けの言語、ビジョン、画像、カスタムバージョンなどの複数の分野をカバーする大規模な言語モデルとさまざまな事前訓練モデルを構築する機能を備えています。

詳細またはこれらのバージョンを試すには、ai.nvidia.comにアクセスしてください。今日、私たちは完全に最適化されたLlama 3 Nimを抱きしめてリリースしました。どのクラウドプラットフォームを選択しても、簡単に実行できます。もちろん、このコンテナをデータセンターにダウンロードし、自分でホストし、顧客にサービスを提供することもできます。
前述したように、複数の言語をサポートする物理学、セマンティック検索、視覚言語など、さまざまなフィールドをカバーするNIMバージョンがあります。これらのマイクロサービスは、大規模なアプリケーションに簡単に統合できます。最も有望なアプリケーションの1つはカスタマーサービスエージェントです。これは、ほぼすべての業界で標準であり、1兆ドルのグローバルカスタマーサービス市場を代表しています。
看護師は、顧客サービスの中核として、小売、ファーストフード、金融サービス、保険、その他の業界で重要な役割を果たすことに言及する価値があります。今日、言語モデルと人工知能技術の助けを借りて、数千万人のカスタマーサービススタッフが大幅に強化されています。これらの拡張ツールの中心にあるのは、まさにあなたがNIMを見るものです。
いくつかは推論エージェントと呼ばれ、タスクが割り当てられた場合、目標と計画を特定することができます。情報の取得が得意な人もいれば、検索に熟練している人もいれば、COPなどのツールを使用したり、SAPで実行されている特定の言語をABAPなどの特定の言語を学習したり、SQLクエリを実行する必要がある場合もあります。これらのいわゆる専門家は現在、効率的で協力的なチームに形成されています。
アプリケーションレイヤーも変更されました。過去には、アプリケーションは指示によって作成されましたが、現在では人工知能チームの組み立てによって構築されています。プログラムを書くには専門知識が必要ですが、ほとんど誰もが問題を解決してチームを形成する方法を知っています。したがって、私は将来のすべての企業がNIMの膨大なコレクションを持っていると固く信じています。専門家を必要に応じて選択して、チームに接続できます。
さらに驚くべきことは、それらを接続する方法を理解する必要さえないことです。タスクをエージェントに割り当てるだけで、NIMはタスクを分解する方法をインテリジェントに決定し、最高の専門家に割り当てます。彼らはアプリケーションやチームの中央リーダーのようなものであり、チームメンバーの仕事を調整し、最終的に結果を提示することができます。
プロセス全体は、人間のチームワークと同じくらい効率的で柔軟です。これは将来の傾向であるだけでなく、私たちの周りで現実になりそうです。これは、アプリケーションが将来提示するまったく新しい外観です。
6。PCは、デジタルの人々の主要キャリアになります
大規模なAIサービスとのやり取りについて話すとき、テキストと音声プロンプトでこれを行うことができます。しかし、将来を楽しみにして、私たちはより人道的な方法で、つまりデジタルの人々と交流したいと考えています。Nvidiaは、デジタルヒューマンテクノロジーの分野で大きな進歩を遂げています。

デジタルの人々は優れたインタラクティブなエージェントになる可能性があるだけでなく、より魅力的であり、より高い共感を示す可能性があります。しかし、この信じられないほどのギャップを越えて、デジタルの人々をより自然に見えるようにするには、まだ大きな努力が必要です。これは私たちのビジョンだけでなく、私たちの絶え間ない目標でもあります。
現在の成果を示す前に、中国の台湾に温かい挨拶を表現できるようにしてください。ナイトマーケットの魅力を詳細に探索する前に、まずデジタルヒューマンテクノロジーの最先端のダイナミクスに感謝します。
これは確かに信じられないほどです。ACE(Avatar Cloud Engine)は、クラウドで効率的に動作するだけでなく、PC環境とも互換性があります。すべてのRTXファミリにテンソルコアGPUの将来の見通し統合があり、AI GPUの時代の到着を示しており、これに完全に備えています。
その背後にあるロジックは非常に明確です。新しいコンピューティングプラットフォームを構築するには、最初に強固な基盤を築く必要があります。強固な基盤により、アプリケーションは自然に現れます。そのような基盤が不足している場合、アプリケーションは問題外になります。したがって、私たちがそれを構築するときにのみ、アプリケーションの繁栄が可能になります。
したがって、現在、すべてのRTX GPUにテンソルコア処理ユニットを統合しています。1億GEFORCE RTX AI PCは世界中で使用されており、この数はまだ増加しており、2億ユニットに達すると予想されています。最近のComputex展では、4つの新しいAIラップトップを発売しました。
これらのデバイスには、人工知能を実行する機能があります。未来のラップトップとPCは、人工知能のキャリアになり、バックグラウンドでの助けとサポートを静かに提供します。同時に、これらのPCは人工知能によって強化されたアプリケーションも実行します。写真編集、書き込み、または他のツールを使用しているかどうかにかかわらず、人工知能によってもたらされる利便性と強化効果を享受できます。

さらに、PCは人工知能を備えたデジタルヒューマンアプリケーションをホストすることができ、AIをより多様な方法で提示し、PCに適用できます。明らかに、PCは重要なAIプラットフォームになります。では、次にどのように開発しますか?
以前にデータセンターの拡張について話しましたが、各拡張には新しい変更が伴います。DGXから大規模なAIスーパーコンピューターに拡張したとき、巨大なデータセットにトランスの効率的なトレーニングを実装しました。これは大きな変化を示しています。最初は、データには人間の監督が必要であり、人工知能は人間のマーキングを通じて訓練されます。ただし、人間がタグを付けることができるデータの量は限られています。現在、変圧器の開発により、教師のない学習が可能になりました。
今日、Transformerは、それ自体で膨大な量のデータ、ビデオ、画像を探索し、隠されたパターンと関係を学び、発見することができます。人工知能をより高いレベルに促進するために、次世代の人工知能は物理的法則の理解に根ざしている必要がありますが、ほとんどの人工知能システムは物理的な世界の深い理解を欠いています。現実的な画像、ビデオ、3Dグラフィックスを生成し、複雑な物理現象をシミュレートするために、物理学の法則を理解して適用できるようにする必要がある物理ベースの人工知能を緊急に開発する必要があります。
これを達成する主な方法は2つあります。第一に、ビデオから学ぶことで、人工知能は物理的な世界の知識を徐々に蓄積することができます。第二に、合成データを使用して、人工知能システムに豊富で制御可能な学習環境を提供できます。さらに、データとコンピューターの間のシミュレートされた学習も効果的な戦略です。この方法は、Alphagoの自己ゲームモードに似ており、同じ2つのエンティティが長い間互いに学習する能力を持つことができるため、インテリジェンスレベルを継続的に改善します。したがって、このタイプの人工知能が将来徐々に出現することを予測できます。
7。ブラックウェルは完全に生産に入れられ、そのコンピューティングパワーは8年で1,000回増加しました
人工知能データが合成によって生成され、強化学習技術と組み合わされると、データ生成率が大幅に改善されます。データ生成が増加するにつれて、コンピューティングパワーの需要もそれに応じて増加します。私たちは、人工知能が物理学の法則を学び、物理的世界からのデータに基づいて意思決定と行動をとることができる新しい時代に入ろうとしています。したがって、AIモデルが拡大し続け、GPUパフォーマンスの要件がますます高くなると予想しています。
このニーズを満たすために、ブラックウェルは存在しました。新世代の人工知能をサポートするように設計されたこのGPUには、いくつかの重要な技術があります。このチップサイズは、業界で最高です。2つのチップを可能な限り大きく使用し、世界の最も高度なセルド(高性能インターフェイスまたは接続テクノロジー)と組み合わせた秒あたり10テラバイトの高速リンクを介してしっかりと接続します。さらに、このような2つのチップをコンピューターノードに配置し、Grace CPUを介して効率的に調整します。
Grace CPUは多用途であり、トレーニングシナリオに適しているだけでなく、迅速なチェックポイントや再開など、推論と生成に重要な役割を果たします。さらに、コンテキストを保存でき、AIシステムがメモリを持ち、ユーザーの会話のコンテキストを理解できるようにします。これは、相互作用の連続性と流encyさを高めるために重要です。
第2世代の変圧器エンジンは、人工知能のコンピューティング効率をさらに向上させます。このエンジンは、コンピューティング層の精度と範囲の要件に応じて精度を低下させるために動的に調整でき、それによりパフォーマンスを維持しながらエネルギー消費を減らします。一方、Blackwell GPUには、ユーザーがサービスプロバイダーに盗難や改ざんから保護するように依頼できるようにするための安全な人工知能機能もあります。
GPUの相互接続に関しては、第5世代のNVリンクテクノロジーを採用しました。これにより、複数のGPUを簡単に接続できます。さらに、Blackwell GPUには、すべてのトランジスタ、トリガー、メモリ、オフチップメモリをチップ上でテストしてサイトで正確に判断できるようにすることができる革新的なテクノロジーである、第1世代の信頼性と可用性エンジン(RASシステム)が装備されています。特定のチップが障害(MTBF)間の平均時間を満たすかどうか。
信頼性は、大規模なスーパーコンピューターにとって特に重要です。10,000 GPUのスーパーコンピューターの平均障害間隔時間は数時間である可能性がありますが、GPUの数が100,000に増加すると、平均障害間隔時間は数分に短縮されます。したがって、スーパーコンピューターが数か月かかる可能性のある複雑なモデルをトレーニングするために長い間安定して実行できるようにするには、技術革新を通じて信頼性を改善する必要があります。信頼性の改善は、システムの稼働時間を増やすだけでなく、コストを効果的に削減することもできます。
最後に、Blackwell GPUに高度な減圧エンジンも統合します。データ処理に関しては、減圧速度が重要です。このエンジンを統合することにより、既存のテクノロジーよりも20倍速くストレージからデータを引き出すことができ、データ処理の効率を大幅に改善できます。
Blackwell GPUの上記の機能により、注目すべき製品になります。以前のGTC会議で、プロトタイプ状態でBlackwellを見せました。そして今、私たちはこの製品が生産に入れられたことを発表してうれしいです。

これは、誰もがブラックウェルです。信じられないほどのテクノロジーを使用しています。これは私たちの傑作であり、今日の世界で最も複雑で最もパフォーマンスの高いコンピューターです。その中で、特に巨大なコンピューティングパワーを搭載したGrace CPUに言及したいと思います。これらの2つのブラックウェルチップをご覧ください、それらは密接に接続されています。気づきましたか?これは世界最大のチップであり、1秒あたり最大A10TBのリンクを使用して、そのような2つのチップを1つにブレンドします。
それで、ブラックウェルとは正確には何ですか?そのパフォーマンスは信じられないほどです。これらのデータを注意深く観察してください。わずか8年で、当社のコンピューティング能力、浮動小数点算術、および人工知能の浮動小数点算術機能が1,000倍増加しました。この速度は、ムーアの法律の最良の成長をほぼ上回ります。
ブラックウェルのコンピューティングパワーの成長は驚くべきものです。言及する価値があるのは、コンピューティングパワーが増加するたびに、コストが常に低下していることです。何か見せてください。コンピューティングパワーを改善することにより、GPT-4モデル(2兆パラメーターと8兆トークン)のトレーニングに使用されるエネルギーは350回減少しました。
Pascalが同じトレーニングを行うと、最大1000 GWhのエネルギーを消費すると想像してください。これは、GWデータセンターがサポートするために必要であることを意味しますが、そのようなデータセンターは世界には存在しません。たとえそれが存在していても、継続的に実行するには1か月かかります。また、100 MWのデータセンターの場合、トレーニング時間は1年ほどです。
明らかに、誰もそのようなデータセンターを望んでいないか、作成することができません。そのため、8年前、ChatGptのような大きな言語モデルは私たちにとってまだ遠い夢でした。しかし今、私たちはパフォーマンスを向上させ、エネルギー消費を減らすことでこれを達成しています。
ブラックウェルを使用して、そうでなければ最大1,000 gWhを必要とするエネルギーをわずか3 gWhに削減しました。これは間違いなく衝撃的なブレークスルーです。1,000 GPUを使用することを想像してみてください。彼らが消費するエネルギーは、一杯のコーヒーのカロリーと同等です。また、10,000 GPUは約10日間で同じタスクを完了できます。これらの8年間で行われた進歩は、単に信じられないほどです。

ブラックウェルは推論に適しているだけでなく、トークン生成のパフォーマンスの改善はさらに人目を引くものです。パスカル時代には、各トークンは最大17,000のエネルギージュールを消費しました。これは、2日間走る2つの電球のエネルギーに関するものでした。GPT-4トークンを生成するには、2日間走るのに2つの200ワットの電球がほぼ2つの電球が必要です。単語を生成するのに約3トークンかかることを考えると、これは確かに巨大なエネルギー消費です。
ただし、今では状況は完全に異なります。ブラックウェルは、各トークンを生成するために0.4ジュールのエネルギーのコストしかかかりません。トークンの世代は驚くべき速度で非常に低いエネルギー消費量です。これは間違いなく大きな飛躍です。しかし、それでも、私たちはまだ満足していません。より大きなブレークスルーのために、より強力なマシンを構築する必要があります。
これは私たちのDGXシステムであり、Blackwellチップは埋め込まれます。このシステムは空気冷却技術を使用しており、そのような8つのGPUが内部に装備されています。これらのGPUのヒートシンクを見てください、それらのサイズは驚くべきものです。システム全体の消費電力は約15 kWで、これは空冷によって完全に達成されます。このバージョンはX86と互換性があり、出荷されたサーバーに適用されています。
ただし、液体冷却技術を好む場合は、真新しいシステム、MGXもあります。これは、「モジュラー」システムと呼ばれるこのマザーボード設計に基づいています。MGXシステムのコアは2つのブラックウェルチップにあり、各ノードは4つのブラックウェルチップを統合します。液体冷却技術を採用して、効率的で安定した動作を確保しています。
システム全体には、9つのノードがあり、合計72 GPUがあり、巨大なコンピューティングクラスターを形成しています。これらのGPUは、新しいNVリンクテクノロジーを介して密接に接続されており、シームレスなコンピューティングネットワークを形成します。NVリンクスイッチは技術的な奇跡です。現在、世界で最も高度なスイッチであり、驚くべきデータ送信レートがあります。これらのスイッチにより、各ブラックウェルチップが効率的に接続され、巨大な72 GPUクラスターが形成されます。
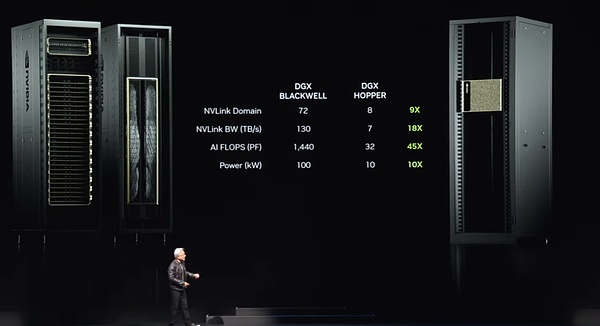
このクラスターの利点は何ですか?まず、GPUドメインでは、単一の超大型GPUのように機能します。この「スーパーGPU」には72 GPUのコア機能があり、パフォーマンスは8つのGPUの前世代の9倍です。同時に、帯域幅は18倍に増加し、AIフロップ(1秒あたりの浮動小数点操作)が45倍増加し、電力が10倍しか増加しませんでした。つまり、そのようなシステムの1つは100キロワットの強力なパワーを提供できますが、前世代はわずか10キロワットでした。
もちろん、これらのシステムをより多く接続して、より大きなコンピューティングネットワークを形成することもできます。しかし、本当の奇跡は、このNVリンクチップが大きな言語モデルのサイズが増加するにつれてますます大きくなっているという事実にあります。これらの大規模な言語モデルは、単一のGPUまたはノードでの実行には適していないため、GPUラック全体を一緒に動作させる必要があります。先ほど述べた新しいDGXシステムと同様に、数百兆のパラメーターを備えた大規模な言語モデルに対応できます。
NVリンクスイッチ自体は、500億トランジスタ、74ポート、ポートあたり最大400 GBのデータレートを備えた技術的な奇跡です。しかし、さらに重要なことは、スイッチは数学的操作関数を統合し、削減操作を直接実行できることです。これは、深い学習において非常に重要です。これは、現在のDGXシステムの新しい外観です。
多くの人が私たちに興味があります。彼らは、Nvidiaのビジネス範囲の誤解があることに疑問を呈した。GPUを作るだけで、Nvidiaがどのようにして非常に大きくなるのか疑問に思います。したがって、多くの人々は、GPUが特定の方法で見えるはずであるという印象を形成しています。
しかし、私が今あなたに見せたいのは、これが実際にGPUであるということですが、それはあなたがそうだと思うようなものではありません。これは世界で最も先進的なGPUの1つですが、主にゲーム分野で使用されています。しかし、私たちは皆、GPUの真の力がそれ以上であることを知っています。
みんな、これを見てください、これはGPUの本当の形です。これは、深い学習用に設計されたDGX GPUです。このGPUの背面は、5,000ラインで構成されるNVリンクバックボーンに接続されており、長さは3キロメートルです。これらの行は、70 GPUを接続して強力なコンピューティングネットワークを形成するNVリンクバックボーンです。これは、トランシーバーが銅線の全長にわたって信号を駆動できる電子機械的な奇跡です。
したがって、このNVリンクスイッチは、NVリンクバックボーンを介して銅線上のデータを送信し、単一のラックで20 kWの電力を節約できるようになりました。これは現在、データ処理に完全に使用されています。これは、NVリンクバックボーンのパワーです。
8。生成AIのイーサネットを宣伝します
しかし、これは、特に大規模なAI工場にとって需要を満たすのに十分ではないため、別の解決策があります。高速ネットワークを使用してこれらのAI工場を接続する必要があります。InfinibandとEthernetの2つのネットワークオプションがあります。その中で、Infinibandは世界中のスーパーコンピューティングおよび人工知能工場で広く使用されており、急速に成長しています。ただし、すべてのデータセンターがイーサネットエコシステムに多額の投資を行っているため、すべてのデータセンターが直接使用できるわけではなく、インフニバンドスイッチとネットワークの管理には専門知識とテクノロジーが必要です。
したがって、私たちの解決策は、Infinibandのパフォーマンスをイーサネットアーキテクチャに持ち込むことですが、これは簡単ではありません。その理由は、各ノード、各コンピューターは通常、インターネット上の異なるユーザーに接続されているが、実際にはほとんどの通信がデータセンター内で発生するため、つまり、データセンターとインターネットの反対側のユーザー間のデータ送信が発生します。 。ただし、人工知能工場の深い学習シナリオでは、GPUはインターネット上のユーザーと通信するのではなく、頻繁かつ集中的なデータ交換を互いに交換します。
彼らはすべて結果の一部を収集しているので、彼らは互いにコミュニケーションを取ります。その後、これらの部分的な結果を減らして再配布する必要があります。この通信モードは、非常にバーストトラフィックによって特徴付けられます。重要なのは平均的なスループットではなく、到着する最後のデータです。なぜなら、あなたがすべての人から部分的な結果を収集している場合、最後のパケットが遅れて到着した場合、操作全体が遅れるからです。 。遅延は、AI工場にとって重要な問題です。
したがって、私たちの焦点は平均的なスループットではなく、最後のパケットが時間通りに、エラーなしで到着するようにすることです。ただし、従来のイーサネットは、このような高度に同期された低レイテンシー要件のために最適化されていません。このニーズを満たすために、NIC(ネットワークインターフェイスカード)を可能にし、通信を切り替えるエンドツーエンドアーキテクチャを創造的に設計しました。これを達成するために、4つの重要なテクノロジーを採用しました。
まず、NVIDIAには、業界をリードするRDMA(リモートダイレクトメモリアクセス)テクノロジーがあります。現在、イーサネットネットワークレベルにRDMAがあり、素晴らしい仕事をしています。
第二に、輻輳制御メカニズムを導入しました。スイッチにはリアルタイムのテレメトリ関数があり、ネットワーク内の輻輳を迅速に識別して応答できます。GPUまたはNICから送信されたデータの量が大きすぎると、スイッチはすぐに信号を送信して、伝送速度を遅くするために信号を送信し、それによってネットワークホットスポットの生成を効果的に回避します。
第三に、適応ルーティングテクノロジーを採用しています。従来のイーサネットは固定順序でデータを送信しますが、アーキテクチャでは、リアルタイムネットワーク条件に基づいて柔軟に調整できます。輻輳が見つかった場合、または一部のポートがアイドル状態にある場合、これらのアイドル状態のポートにパケットを送信し、反対側のブルーフィールドデバイスでそれらを再注文して、データが正しい順序で返されるようにします。この適応ルーティングテクノロジーは、ネットワークの柔軟性と効率を大幅に改善します。
第4に、ノイズ分離技術を実装しました。データセンターでは、複数のモデルによって生成される騒音とトラフィックが同時にトレーニングが互いに干渉し、ジッターを引き起こす可能性があります。ノイズ分離技術は、これらのノイズを効果的に分離し、重要なデータパケットの送信が影響を受けないようにします。
これらのテクノロジーを採用することにより、AI工場に高性能で低遅延のネットワークソリューションを成功裏に提供しました。数十億ドルのデータセンターでは、ネットワークの利用率が40%増加し、トレーニング時間が20%短縮された場合、これは実際には50億ドルのデータセンターがパフォーマンスの60億ドルのデータセンターに相当することを意味します。全体的な費用対効果に関するネットワークパフォーマンスの。
幸いなことに、Spectrum Xを搭載したイーサネットテクノロジーは、ネットワークパフォーマンスを大幅に改善し、データセンター全体に比べてネットワークコストをほとんど無視できるようにします。これは間違いなく、私たちがネットワークテクノロジーの分野で行った大きな成果です。
強力なイーサネット製品のラインナップがあり、その中で最も注目すべきはスペクトルx800です。1秒あたり51.2 TBと256パス(RADIX)サポートにより、このデバイスは数千のGPUへの効率的なネットワーク接続を提供します。次に、1年でX800ウルトラを起動する予定です。これにより、最大512パスの512基数がサポートされ、ネットワークの容量とパフォーマンスがさらに向上します。X1600は、より大きなデータセンター用に設計されており、数百万のGPUの通信ニーズを満たすことができます。

テクノロジーの継続的な進歩により、数百万のGPUのデータセンター時代はすぐにあります。この傾向の背後には深い理由があります。一方で、私たちはより大きくて複雑なモデルを訓練することに熱心です。これらのAIは、動作し、ビデオ、画像、テキスト、さらにはデジタルの人々を生成するために機能し、やり取りします。したがって、コンピューターと相互作用するほとんどすべての相互作用は、生成的人工知能の参加と切り離せません。そして、それに接続された生成的AIが常にあり、一部はローカルで実行され、一部はデバイスで実行され、多くはクラウドで実行される場合があります。
これらの生成的な人工知能には、強力な推論能力があるだけでなく、回答の質を向上させるための回答を繰り返し最適化します。これは、将来的に大規模なデータ生成ニーズを生成することを意味します。今夜、私たちはこの技術革新の力を一緒に目撃しました。
Nvidiaプラットフォームの第1世代であるBlackwellは、発売以来多くの注目を集めています。今日、生成的人工知能の時代は、世界を導き出しており、新しい産業革命の始まりであり、すべての角が人工知能工場の重要性を認識しています。すべてのOEM(オリジナル機器メーカー)、コンピューターメーカー、CSP(クラウドサービスプロバイダー)、GPUクラウド、ソブリンクラウド、電気通信会社など、あらゆる場所からの広範な支援を受けたことを深く光栄に思います。
ブラックウェルの成功、広範な養子縁組、そしてそれに対する業界の熱意が前例のないレベルに達したことに深く嬉しく思います。しかし、私たちのペースは止まりません。この急速に発展している時代には、製品のパフォーマンスを改善し、トレーニングと推論のコストを削減し、人工知能の能力を継続的に拡大して、すべての企業が利益を得られるように努力し続けます。パフォーマンスの改善により、コストがさらに削減されると固く信じています。ホッパープラットフォームは、間違いなく歴史上最も成功したデータセンタープロセッサです。
9。ブラックウェルウルトラは来年リリースされ、次世代プラットフォームはルービンと呼ばれます
これは確かに衝撃的なサクセスストーリーです。ご覧のとおり、Blackwellプラットフォームの誕生は単一のコンポーネントではなく、CPU、GPU、NVLink、Nick(特定の技術コンポーネント)、NVLinkスイッチなどの複数の要素を統合する完全なシステムです。大型の超高速スイッチを使用して、各世代を介してすべてのGPUを緊密に接続して、巨大で効率的なコンピューティングドメインを形成することに取り組んでいます。
プラットフォーム全体をAI工場に統合しますが、より重要なことに、このプラットフォームを世界中の顧客にモジュール形式で提供します。これの当初の意図は、すべてのパートナーが、さまざまなスタイルのデータセンター、さまざまな顧客グループ、多様なアプリケーションシナリオに適応するために、独自のニーズに基づいて独自の革新的な構成を作成することを期待することです。エッジコンピューティングから電気通信まで、システムが開いている限り、あらゆる種類のイノベーションが可能になります。
自由に革新できるようにするために、統合されたプラットフォームを設計しましたが、同時に分解して提供され、モジュラーシステムを簡単に構築できるようになりました。現在、Blackwellプラットフォームが完全に発売されました。
Nvidiaは常に年次更新リズムを順守しています。私たちの中核哲学は非常に明確です。1)データセンターのスケール全体をカバーするソリューションを構築します。極端に、TSMCのプロセステクノロジー、パッケージングテクノロジー、メモリテクノロジー、または光学技術であろうと、私たちは皆、究極のパフォーマンスを追求しています。
ハードウェアの究極の課題を完了した後、この完全なプラットフォームですべてのソフトウェアがスムーズに実行されるように最善を尽くします。コンピューター技術では、ソフトウェアの慣性が重要です。コンピュータープラットフォームが後方互換性があり、アーキテクチャが既存のソフトウェアと完全に互換性がある場合、市場への製品の速度が大幅に改善されます。したがって、Blackwellプラットフォームが発売されたとき、ビルドソフトウェアエコシステムファンデーションを最大限に活用して、驚くべき市場対応速度を達成することができました。来年、ブラックウェルウルトラを歓迎します。
私たちが発売したH100およびH200シリーズと同様に、ブラックウェルウルトラはまた、新世代の製品の流行をリードし、前例のない革新的な体験をもたらします。同時に、テクノロジーの限界に挑戦し続け、業界での最初の試みである次世代スペクトルスイッチを開始します。この主要なブレークスルーは成功裏に達成されましたが、私はまだこの決定を公開することを少しためらっています。
Nvidia内では、コード名を使用し、いくつかの機密性を維持することに慣れています。多くの場合、社内のほとんどの従業員でさえ、これらの秘密をあまりよく知らない。ただし、次世代のプラットフォームはRubinという名前です。ここではルービンの詳細については説明しません。私はみんなの好奇心を知っていますが、謎を守ってください。あなたは写真を撮ったり、それらの小さなキャラクターを注意深く勉強したいと思っているかもしれませんので、自由にそうしてください。
Rubinプラットフォームを持っているだけでなく、1年でRubin Ultraプラットフォームも起動します。ここに示されているすべてのチップは完全な開発段階にあり、すべての詳細が慎重に洗練されるようにします。私たちの更新ペースはまだ年に1回であり、常にすべての製品が100%のアーキテクチャの互換性を維持することを保証しながら、常に究極のテクノロジーを追求しています。

過去12年間を振り返って、Imagenetが生まれた瞬間から、私たちは地球を揺るがす変化を起こすコンピューティング分野の未来を予測しています。さて、これはすべて現実になりました。これは私たちの元のアイデアと一致しています。2012年以前のGeForceから今日のNvidiaまで、同社は大きな変革を遂げました。ここでは、途中で彼らのサポートと会社のすべてのパートナーに心から感謝したいと思います。
10。ロボットの時代が到着しました
これは、NvidiaのBlackwellプラットフォームです。
物理的な人工知能は、人工知能の分野で新しい波をリードしています。この目的のために、物理的な人工知能は、周囲の世界を解釈して知覚する方法を理解するために正確な世界モデルを構築する必要があるだけでなく、ニーズを深く理解し、効率的にタスクを実行するための優れた認知能力を持つ必要があります。
今後、Roboticsはもはや手アクセスの概念ではありませんが、日常生活にますます統合されます。ロボット学について話すとき、人々はしばしばヒューマノイドロボットについて考えるが、実際、彼らのアプリケーションはそれ以上のものだ。機械化は標準になり、工場は自動化を完全に実現し、ロボットは協力して一連の機械化された製品を作成します。それらの間の相互作用はより密接になり、高度に自動化された生産環境が一緒になります。
これを達成するには、さまざまな技術的課題を克服する必要があります。次に、ビデオを通じてこれらの最先端のテクノロジーを紹介します。
これは単なる将来のビジョンではなく、徐々に現実になりつつあります。
私たちはさまざまな方法で市場にサービスを提供します。まず、さまざまな種類のロボットシステム向けのプラットフォームの作成に取り組んでいます。ロボット工場と倉庫、オブジェクト操作ロボットプラットフォーム、モバイルロボットプラットフォーム、ヒューマノイドロボットプラットフォーム向けの専用プラットフォームです。他の多くのビジネスと同様に、これらのロボットプラットフォームは、コンピューターの加速ライブラリと事前に訓練されたモデルに依存しています。
コンピューター加速ライブラリ、事前に訓練されたモデルを使用し、Omniverseでの包括的なテスト、トレーニング、統合を実施しています。ビデオが示すように、オムニバースは、ロボットが現実の世界によりよく適応する方法を学ぶ場所です。もちろん、ロボット倉庫の生態系は非常に複雑であり、最新の倉庫を共同で構築するために多くの企業、ツール、技術が必要です。今日、倉庫は徐々に完全な機械化に移行しており、いつか完全に自動化されます。
このようなエコシステムでは、ソフトウェア業界、Edge人工知能業界、企業向けのSDKおよびAPIインターフェイスを提供し、PLCおよびロボットシステム向けの専用システムを設計して、国防省などの特定の分野のニーズを満たしています。これらのシステムは、統合器を介して統合され、最終的に顧客向けの効率的でインテリジェントな倉庫を作成します。たとえば、Ken Macは巨大な巨人グループのためにロボット倉庫を構築しています。
次に、工場分野に焦点を当てましょう。工場の生態系は非常に異なっています。Foxconnを例として、彼らは世界で最も先進的な工場のいくつかを構築しています。これらの工場のエコシステムは、工場レイアウトの設計、ワークフローの最適化、プログラミングロボット、デジタル工場と人工知能工場の調整に使用されるPLCコンピューターのエッジコンピューター、ロボットソフトウェアもカバーしています。また、これらのエコシステムのすべてのリンクにSDKインターフェイスも提供します。
このような変更は世界中で行われています。FoxconnとDeltaは、工場のためにデジタル双子を構築して、現実とデジタルの完璧な融合を達成しており、Omniverseは重要な役割を果たしています。また、PegatronとWistronがトレンドに従っており、それぞれのロボット工場のデジタルツイン施設を確立していることにも言及する価値があります。
これは本当にエキサイティングです。次に、Foxconnの新しい工場の素晴らしいビデオをお楽しみください。
ロボット工場は、NVIDIA AIプラットフォームでAIモデルをトレーニングする3つの主要なコンピューターシステムで構成されており、ロボットがローカルシステムで効率的に実行して工場プロセスを調整することを保証します。同時に、シミュレーションコラボレーションプラットフォームであるOmniverseを使用して、Robotic ArmsやAMR(Autonomous Mobile Robot)を含むすべての工場要素をシミュレートします。これらのシミュレーションシステムは、シームレスな相互作用とコラボレーションを実現するために同じ仮想空間を共有することに言及する価値があります。
ロボットアームとAMRがこの共有された仮想空間を入力すると、オムニバースの実際の工場環境をシミュレートでき、実際の展開前に適切な検証と最適化を確保できます。
ソリューションの統合とアプリケーションの範囲をさらに強化するために、加速層と事前に訓練されたAIモデルを装備した3つの高性能コンピューターを提供します。さらに、NvidiaマニピュレーターとオムニバースとSiemensの産業用自動化ソフトウェアとシステムを組み合わせたことに成功しました。このコラボレーションにより、シーメンスは世界中の工場でより効率的なロボット操作と自動化を可能にします。
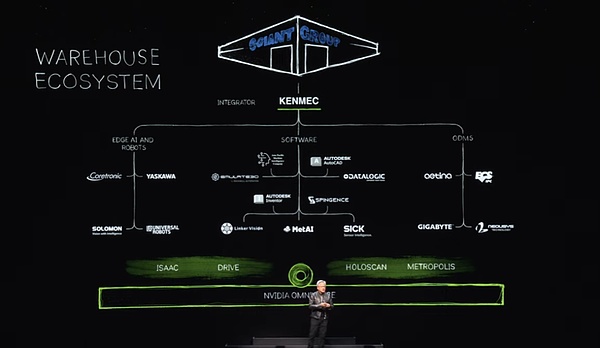
シーメンスに加えて、多くの有名な企業との協力関係も確立しています。たとえば、Symantec Pick AiはNvidia Isaacマニピュレーターを統合しましたが、Sos Somatic Pick AiはABB、Kuka、Yaskawa Motomanなどの有名なブランドのロボットを正常に実行および操作しました。
ロボット工学と物理的な人工知能の時代が到着し、どこでも広く使用されています。今後、工場のロボットが主流になり、すべての製品を作成します。そのうち2つは目を引くものです。第一に、自律性の高い自動運転車または車であるNvidiaは、包括的なテクノロジースタックでこの分野で再び中心的な役割を果たします。来年、私たちはメルセデス・ベンツチームと協力して、2026年にジャガー・ランド・ローバー(JLR)チームと協力する予定です。完全なソリューションスタックを提供しますが、ドライバースタック全体がオープンで柔軟であるため、顧客はニーズに基づいて任意の部分または階層を選択できます。
次に、ロボット工場から高収量で製造できる別の製品はヒューマノイドロボットです。近年、認知能力と世界理解能力で大きなブレークスルーが行われており、この分野の開発の見通しはエキサイティングです。ヒューマノイドロボットは、私たちが人間のために築いた世界に適応する可能性が最も高いため、特に興奮しています。
ヒューマノイドロボットのトレーニングには、他の種類のロボットと比較して多くのデータが必要です。同様のボディーシェイプがあるため、デモンストレーションとビデオ機能を通じて提供される大量のトレーニングデータは非常に価値があります。したがって、この分野では大きな進歩が期待されています。

さて、特別なロボットの友達を歓迎しましょう。ロボットの時代が到着し、これが人工知能の次の波です。台湾で作られた多種多様なコンピューターがあります。これには、キーボード、小、軽いモバイル、ポータブルモバイルデバイスを装備した従来のモデル、クラウドデータセンターに強力なコンピューティングパワーを提供するプロフェッショナルな機器が含まれます。しかし、楽しみにして、私たちはよりエキサイティングな瞬間を目撃します – 歩き回ることができるコンピューター、つまりインテリジェントロボットを作成します。
これらのインテリジェントロボットは、私たちが知っているようにコンピューターと顕著な技術的類似点を持っています。これらはすべて、高度なハードウェアおよびソフトウェアテクノロジーに基づいています。ですから、これが本当に並外れた旅になると信じる理由があります!







