
Quelle: Tencent Technology
Der Mitbegründer und CEO von NVIDIA, Huang Renxun, hielt eine Keynote-Rede unter ComputEx 2024 (2024 Taipei International Computer Exhibition) und teilte mit, wie die Ära der künstlichen Intelligenz die globale neue industrielle Revolution fördern kann.
Das Folgende sind die wichtigsten Punkte dieser Rede:
① Huang Renxun zeigte die neueste Massenversion von Blackwell Chips und sagte, dass er 2025 Blackwell Ultra AI Chips starten wird. Die nächste Generation der AI-Plattform heißt Rubin. „Einmal im Jahr“, brach „Moore“ Gesetz.
② Huang Renxun behauptete, Nvidia habe die Geburt eines großen Sprachmodells gefördert, das die GPU -Architektur nach 2012 veränderte und alle neuen Technologien auf einem einzigen Computer integrierte.
Die beschleunigte Computertechnologie von NVIDIA hat dazu beigetragen, eine 100-fache Zunahme zu erzielen, während der Stromverbrauch nur auf das dreifache und die Kosten 1,5-fach erhöht wird.
④ Huang Renxun erwartet, dass die nächste Generation von KI die physische Welt verstehen muss.Die Methode, die er gab, besteht darin, KI durch Video- und synthetische Daten zu lernen und KI voneinander zu lernen.
⑤ Huang Renxun hat sogar eine chinesische Übersetzung für Token in PPT – CI Yuan abgeschlossen.
⑥ Huang Renxun sagte, dass die Ära der Roboter eingetroffen ist und alle bewegenden Objekte in Zukunft unabhängig operieren werden.

Das Folgende ist das vollständige Transkript der zweistündigen Rede, die von Tencent Technology zusammengestellt wurde:
Liebe Gäste, es ist mir eine große Ehre, wieder hier zu sein.Zunächst möchte ich mich bei der Taiwan University dafür bedanken, dass sie uns dieses Gymnasium als Veranstaltungsort für Veranstaltungen zur Verfügung gestellt hat.Das letzte Mal, als ich hierher kam, war, als ich meinen Abschluss an der Taiwan University bekam.Heute gibt es eine Menge Dinge, die wir erkunden werden, also muss ich schnell und klar beschleunigen und die Nachricht vermitteln.Wir haben viele Themen zu sprechen, und ich habe viele aufregende Geschichten zu Ihnen.
Ich freue mich sehr, hier in Taiwan, China, zu sein, wo viele unserer Partner hier sind.Tatsächlich ist dies nicht nur ein unverzichtbarer Bestandteil der Entwicklungsgeschichte von Nvidia, sondern auch ein wichtiger Knoten für uns und unsere Partner, um die Innovation der Welt gemeinsam zu fördern.Wir arbeiten mit vielen Partnern zusammen, um eine künstliche Intelligenzinfrastruktur weltweit aufzubauen.Heute möchte ich mit Ihnen mehrere wichtige Themen besprechen:
1) Welche Fortschritte werden in unserer gemeinsamen Arbeit erzielt und welche Bedeutung hat diese Fortschritte?
2) Was genau ist generative künstliche Intelligenz?Wie wirkt sich dies auf unsere Branche und sogar auf jede Branche aus?
3) Eine Blaupause darüber, wie wir uns vorwärts bewegen können und wie wir diese unglaubliche Gelegenheit nutzen können?
Was wird als nächstes passieren?Generative KI und ihre tiefgreifenden Auswirkungen, unser strategischer Blaupause, sind alles aufregende Themen, die wir erforschen werden.Wir stehen am Ausgangspunkt des Neustarts der Computerindustrie, und eine neue Ära, die von Ihnen erstellt und von Ihnen erstellt wurde, steht kurz vor dem Beginn.Jetzt sind Sie bereit für die nächste wichtige Reise.
1.Eine neue Ära des Computers beginnt
Bevor ich jedoch mit der detaillierten Diskussion beginne, möchte ich eines hervorheben: Nvidia befindet sich an der Schnittstelle von Computergrafiken, Simulation und künstlicher Intelligenz, die die Seele unseres Unternehmens bildet.Heute basiert alles, was ich Ihnen zeigen werde, auf Simulation.Dies sind nicht nur visuelle Effekte, sondern die Essenz von Mathematik, Wissenschaft und Informatik sowie die atemberaubende Computerarchitektur.Keine Animation ist vorgefertigt, alles ist ein Meisterwerk unseres eigenen Teams.Das versteht Nvidia und wir nehmen alles in die virtuelle Welt der Omniverse ein, auf die wir stolz sind.Nun, bitte genießen Sie das Video!
Der Stromverbrauch in Rechenzentren auf der ganzen Welt steigt stark, während auch die Computerkosten steigen.Wir stehen vor der strengen Herausforderung der Computerinflation, die offensichtlich nicht lange nicht aufrechterhalten werden kann.Die Daten werden weiter exponentiell wachsen, während die CPU -Leistungserweiterung so schnell wie zuvor schwer zu erweitern ist.Es gibt jedoch einen effizienteren Ansatz.
Seit fast zwei Jahrzehnten arbeiten wir an einer beschleunigten Computerforschung.Die CUDA -Technologie verbessert die Funktionen der CPU, die Aufgaben abladen und beschleunigen, die spezielle Prozessoren effizienter erledigen können.Tatsächlich werden die Vorteile des beschleunigten Computers aufgrund der Verlangsamung oder sogar Stagnation der CPU -Leistungsverwaltung immer deutlicher.Ich gehe davon aus, dass jede verarbeitungsintensive Anwendung beschleunigt wird, und in naher Zukunft wird jedes Rechenzentrum vollständig beschleunigt.

Die Wahl des beschleunigten Computers ist nun ein kluger Schritt, der zu einem Branchenkonsens geworden ist.Stellen Sie sich vor, dass eine Bewerbung 100 Einheiten Zeit benötigt, um abzuschließen.Egal, ob es sich um 100 Sekunden oder 100 Stunden handelt, wir können die KI -Anwendung, die tagelang oder sogar Monate läuft, oft nicht ausstehen.
Unter diesen 100 Zeiteinheiten beinhaltet eine Zeiteinheit Code, die nacheinander ausgeführt werden müssen.Die Kontrolllogik des Betriebssystems ist unverzichtbar und muss gemäß der Anweisungssequenz streng ausgeführt werden.Es gibt jedoch viele Algorithmen, wie Computergrafiken, Bildverarbeitung, physikalische Simulation, kombinatorische Optimierung, Graphenverarbeitung und Datenbankverarbeitung, insbesondere lineare Algebra, die im Deep -Lernen weit verbreitet sind, die für die Beschleunigung durch parallele Verarbeitung gut geeignet sind.Um dies zu erreichen, haben wir eine innovative Architektur erfunden, die die GPU perfekt mit der CPU kombiniert.
Ein dedizierter Prozessor kann ansonsten zeitaufwändige Aufgaben zu unglaublichen Geschwindigkeiten beschleunigen.Da die beiden Prozessoren parallel arbeiten können, laufen sie jeweils unabhängig und unabhängig.Dies bedeutet, dass Aufgaben, die ursprünglich 100 Zeiteinheiten benötigten, jetzt in nur 1 Zeiteinheit erledigt werden können.Obwohl dieser Beschleunigungseffekt unglaublich klingt, werde ich diese Aussage heute mit einer Reihe von Beispielen validieren.

Die Vorteile dieser Leistungsverbesserung sind mit 100 -facher Beschleunigung erstaunlich, während nur etwa 3x Strom und nur etwa 50% der Kosten steigt.Wir haben diese Strategie bereits in der PC -Branche geübt.Das Hinzufügen einer Geforce -GPU von 500 US -Dollar zu Ihrem PC wird seine Leistung erheblich verbessern und gleichzeitig den Gesamtwert auf 1.000 US -Dollar erhöhen.Im Rechenzentrum haben wir den gleichen Ansatz gewählt.Ein Rechenzentrum von Milliarden Dollar verwandelte sich sofort in eine leistungsstarke Fabrik für künstliche Intelligenz, nachdem sie eine GPU von 500 Millionen US-Dollar hinzugefügt hatte.Heute passiert diese Veränderung weltweit.
Die Kosteneinsparungen sind gleichermaßen schockierend.Für jeden investierten $ investierten US -Dollar erzielen Sie bis zu 60x -Leistungsgewinne.Die Beschleunigung beträgt 100 Mal, während die Stromversorgung nur dreimal beträgt und die Kosten nur 1,5 -mal beträgt.Die Ersparnisse sind echt!
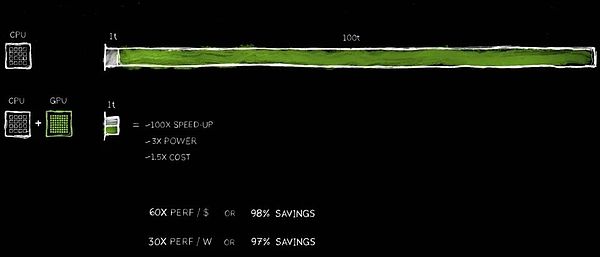
Anscheinend geben viele Unternehmen Hunderte Millionen Dollar für die Verarbeitung von Daten in der Cloud aus.Das Speichern von Hunderten von Millionen Dollar wird angemessen, wenn die Daten schneller verarbeitet werden.Warum passiert das?Der Grund ist einfach, dass wir im allgemeinen Computer einen langfristigen Effizienz Engpass erlebt haben.
Jetzt erkennen wir dies endlich und beschlossen, es zu beschleunigen.Durch die Übernahme eines engagierten Prozessors können wir viele zuvor übersehene Leistungsgewinne wiedererlangen und viel Geld und Energie einsparen.Deshalb sage ich, je mehr Sie kaufen, desto mehr sparen Sie.
Jetzt habe ich dir die Zahlen gezeigt.Obwohl sie für einige Dezimalstellen nicht präzise sind, spiegelt dies die Fakten genau wider.Dies kann als „CEO Mathematics“ bezeichnet werden.Obwohl CEO -Mathematik keine extreme Genauigkeit verfolgt, ist die Logik dahinter korrekt – je mehr beschleunigte Rechenleistung Sie kaufen, desto mehr Kosten sparen Sie.
2.350 Funktionsbibliotheken helfen dabei, neue Märkte zu eröffnen
Die Ergebnisse des beschleunigten Computers sind in der Tat außergewöhnlich, aber der Implementierungsprozess ist nicht einfach.Warum spart es so viel Geld, aber die Leute haben diese Technologie nicht früher übernommen?Der Grund dafür ist, dass es zu schwierig ist, umzusetzen.
Es gibt keine fertige Software, die einfach durch Beschleunigung des Compilers ausgeführt werden kann, und die Anwendung kann sofort um das 100-fache beschleunigt werden.Dies ist weder logisch noch realistisch.Wenn es so einfach wäre, hätten die CPU -Hersteller dies schon lange getan.
Um eine Beschleunigung zu erreichen, muss die Software vollständig umschreiben.Dies ist der schwierigste Teil des Prozesses.Die Software muss neu gestaltet und neu gestaltet werden, um Algorithmen zu konvertieren, die ursprünglich auf der CPU in Formate ausgeführt wurden, die parallel auf dem Gaspedal ausgeführt werden können.
Obwohl diese Informatikforschung schwierig ist, haben wir in den letzten 20 Jahren erhebliche Fortschritte erzielt.Zum Beispiel haben wir die beliebte Cudnn Deep Learning Library gestartet, die sich auf die Beschleunigung der neuronalen Netzwerke spezialisiert hat.Wir bieten auch eine Bibliothek für Physiksimulationen für künstliche Intelligenz für Anwendungen wie Fluiddynamik, die die Einhaltung physischer Gesetze erfordern.Darüber hinaus verfügen wir über eine neue Bibliothek namens Aerial, in der CUDA 5G-Radio-Technologie beschleunigt, mit der wir Software verwenden können, um Telekommunikationsnetzwerke wie softwaredefinierte Internetnetzwerke zu definieren und zu beschleunigen.

Diese Beschleunigungsfunktionen verbessern nicht nur die Leistung, sondern helfen uns auch, die gesamte Telekommunikationsbranche in eine Computerplattform zu verwandeln, die dem Cloud Computing ähnelt.Darüber hinaus ist die Coolitho Computing -Lithographieplattform auch ein gutes Beispiel, das die Effizienz der Maskenherstellung erheblich verbessert, dem rechnerischsten Teil des Chipherstellungsprozesses.Unternehmen wie TSMC haben bereits mit dem Einsatz von Coolitho für die Produktion begonnen, was nicht nur wesentlich Energie spart, sondern auch die Kosten erheblich senkt.Ihr Ziel ist es, sich auf die Weiterentwicklung von Algorithmen und die riesige Rechenleistung vorzubereiten, die erforderlich ist, um tiefere und engere Transistoren durch Beschleunigen des Technologiestapels zu machen.
Paar von Bricks ist unsere stolze Gene -Sequenzbibliothek, die den weltweit führenden Gene -Sequenzierungs -Durchsatz hat.CO OPT ist eine bemerkenswerte Bibliothek für Kombinationsoptimierungsbibliothek, die komplexe Probleme wie Routenplanung, Reiseroutenoptimierung und Probleme mit Reisebüros lösen kann.Es wird allgemein angenommen, dass diese Probleme von Quantencomputern gelöst werden müssen, aber wir haben durch beschleunigte Computertechnologie einen extrem schnellen Algorithmus geschaffen, der 23 Weltrekorde erfolgreich brechen kann.
Cloup Quantum ist ein Quanten -Computer -Simulationssystem, das wir entwickelt haben.Ein zuverlässiger Simulator ist für Forscher, die Quantencomputer oder Quantenalgorithmen entwerfen möchten, unerlässlich.Ohne tatsächliche Quantencomputer wurde Nvidia CUDA – was wir den schnellsten Computer der Welt nennen – zu ihrem bevorzugten Werkzeug.Wir bieten einen Simulator, der den Betrieb von Quantencomputern simulieren und Forschern helfen kann, Durchbrüche im Bereich Quantencomputer zu erzielen.Dieser Simulator wurde von Hunderttausenden von Forschern auf der ganzen Welt weit verbreitet und in alle führenden Quantum Computing -Frameworks integriert und bietet eine starke Unterstützung für wissenschaftliche Supercomputationszentren auf der ganzen Welt.
Darüber hinaus haben wir die Datenverarbeitungsbibliothek Kudieff gestartet, die speziell für die Beschleunigung der Datenverarbeitung entwickelt wurde.Die Datenverarbeitung berücksichtigt die überwiegende Mehrheit der heutigen Cloud -Ausgaben. Daher ist die Beschleunigung der Datenverarbeitung von entscheidender Bedeutung für die Kosteneinsparungen.QDF ist ein Beschleunigungswerkzeug, das wir entwickelt haben, mit dem die Leistung wichtiger Datenverarbeitungsbibliotheken in der Welt erheblich verbessern kann, wie z.
Diese Bibliotheken sind eine Schlüsselkomponente des Ökosystems und ermöglichen es, das beschleunigte Computer weit verbreitet zu werden.Ohne unsere sorgfältig gefertigten domänenspezifischen Bibliotheken wie Cudnn können Deep-Learning-Wissenschaftler auf der ganzen Welt ihr Potenzial mit CUDA möglicherweise nicht voll ausschöpfen, da es signifikante Unterschiede zwischen CUDA und Algorithmen gibt, die in tiefen Lernrahmen wie Tensorflow und Pytorch verwendet werden.Dies ist so unpraktisch wie Computergrafiken ohne OpenGL oder Verarbeitungsdaten ohne SQL.
Diese domänenspezifischen Bibliotheken sind Schätze unseres Unternehmens und wir haben derzeit über 350 solcher Bibliotheken.Es sind diese Bibliotheken, die uns offen und vor dem Markt offen halten.Heute werde ich Ihnen mehr aufregende Beispiele zeigen.
Erst letzte Woche gab Google bekannt, dass sie QDFs in der Cloud bereitgestellt und Pandas erfolgreich beschleunigt hatten.Pandas ist die beliebteste Datenwissenschaftsbibliothek der Welt, die von 10 Millionen Datenwissenschaftlern auf der ganzen Welt verwendet wird und monatlich von bis zu 170 Millionen Mal heruntergeladen wird.Es ist wie bei der Excel von Data Scientists, ihrem rechten Assistenten für die Verarbeitung von Daten.
Klicken Sie nun einfach auf die Cloud Cloud Center-Plattform von Google Colab, und Sie können die leistungsstarke Leistung von QDF-Beschleunigten Pandas erleben.Diese Beschleunigung ist wirklich erstaunlich, genau wie die von Ihnen gerade gesehene Demo, die die Datenverarbeitungsaufgabe fast sofort abgeschlossen hat.
3.Cuda erkennt einen tugendhaften Zyklus
Cuda hat das erreicht, was die Menschen als kritischen Punkt bezeichnen, aber die Realität ist besser als das.CUDA hat einen tugendhaften Entwicklungszyklus erreicht.Wenn wir auf die Geschichte und die Entwicklung verschiedener Computerarchitekturen und -plattformen zurückblicken, können wir feststellen, dass solche Schleifen nicht üblich sind.Nehmen Sie die Mikroprozessor -CPU als Beispiel.
Das Erstellen einer neuen Computerplattform steht häufig vor dem Dilemma von „Es gibt zuerst Hühner oder Eier“.Ohne die Unterstützung von Entwicklern ist es für die Plattform schwierig, Benutzer anzulocken.Dieses Dilemma hat die Entwicklung mehrerer Computerplattformen in den letzten 20 Jahren geplagt.
Wir haben dieses Dilemma jedoch erfolgreich gebrochen, indem wir domänenspezifische Bibliotheken und beschleunigte Bibliotheken kontinuierlich eingeführt haben.Heute haben wir 5 Millionen Entwickler auf der ganzen Welt, die CUDA -Technologie nutzen, um fast jeden großen Bereich der Industrie und Naturwissenschaften zu dienen, von Gesundheitswesen über Finanzdienstleistungen bis hin zur Computerindustrie, der Automobilindustrie.
Während der Kundenstamm weiter expandiert, haben OEMs und Cloud -Dienstanbieter begonnen, Interesse an unseren Systemen zu entwickeln, was weitere Systeme zum Eintritt in den Markt fördert.Dieser tugendhafte Zyklus hat uns große Möglichkeiten geschaffen, sodass wir unsere Skala erweitern und die F & E -Investitionen erhöhen und so die beschleunigte Entwicklung weiterer Anwendungen fördern.
Die Beschleunigung der einzelnen Anwendungen bedeutet eine erhebliche Reduzierung der Rechenkosten.Wie ich bereits gezeigt habe, kann eine 100 -fache Beschleunigung bis zu 97,96% oder fast 98% Kosteneinsparungen einbringen.Wenn wir die Berechnungsbeschleunigung von 100 -mal auf das 200 -fache und dann auf das 1000 -fache erhöhen, sinkt die Grenzkosten der Berechnung weiter, was bemerkenswerte wirtschaftliche Vorteile aufweist.
Natürlich glauben wir, dass durch erhebliche Reduzierung der Rechenkosten, Märkte, Entwickler, Wissenschaftler und Erfinder neue Algorithmen, die mehr Rechenressourcen konsumieren, weiterhin entdecken werden.Bis irgendwann wird eine tiefgreifende Veränderung leise stattfinden.Wenn die Grenzkosten für die Berechnung so niedrig werden, wird eine brandneue Methode zur Verwendung von Computern entsteht.
Tatsächlich findet diese Veränderung vor unseren Augen statt.In den letzten zehn Jahren haben wir spezifische Algorithmen verwendet, um die Grenzkosten für die Berechnung durch erstaunliche 1 Million Mal zu senken.Heute ist es zu einer logischen und natürlichen Wahl geworden, alle Daten im Internet zu schulen, um große Sprachmodelle zu schulen, und wird heute nicht mehr in Frage gestellt.
Die Idee – einen Computer zu erstellen, der massive Datenmengen und Programme selbst verarbeiten kann – ist der Eckpfeiler des Aufstiegs der künstlichen Intelligenz.Der Aufstieg der künstlichen Intelligenz ist möglich, weil wir fest davon überzeugt sind, dass es immer enorme Zwecke geben wird, wenn wir Computer billiger machen.Heute hat Cudas Erfolg die Machbarkeit dieses tugendhaften Zyklus bewiesen.
Mit der kontinuierlichen Erweiterung der Installationsstiftung und der kontinuierlichen Reduzierung der Rechenkosten können immer mehr Entwickler ihr innovatives Potenzial ausschöpfen und mehr Ideen und Lösungen vorschlagen.Diese Innovation hat zu einem Anstieg der Marktnachfrage gesteuert.Jetzt stehen wir an einem großen Wendepunkt.Bevor ich es jedoch weiter zeige, möchte ich betonen, dass das, was ich unten zeigen möchte, ohne den Durchbruch von Cuda und modernen KI -Technologien – insbesondere der generativen KI – nicht möglich wäre.
Dies ist das Earth 2 -Projekt – eine ehrgeizige Idee, den digitalen Zwilling der Erde zu schaffen.Wir werden die Bewegung der gesamten Erde simulieren, um ihre zukünftigen Veränderungen vorherzusagen.Durch solche Simulationen können wir Katastrophen besser verhindern und ein tieferes Verständnis der Auswirkungen des Klimawandels haben, sodass wir uns besser an diese Veränderungen anpassen und jetzt sogar unsere Verhaltensweisen und Gewohnheiten ändern können.
Das Earth 2 -Projekt ist wahrscheinlich eines der herausforderndsten und ehrgeizigsten Projekte der Welt.Wir haben jedes Jahr erhebliche Fortschritte in diesem Bereich erzielt und die diesjährigen Ergebnisse sind besonders hervorragend.Erlauben Sie mir nun, Ihnen diese aufregenden Fortschritte zu zeigen.
In naher Zukunft werden wir kontinuierliche Wettervorhersagefähigkeiten haben, die jeden Quadratkilometer auf dem Planeten abdecken.Sie werden immer verstehen, wie sich das Klima verändert, und diese Vorhersage wird weiter laufen, da wir KI trainieren, was äußerst begrenzte Energie erfordert.Es wäre eine unglaubliche Leistung.Ich hoffe, euch wird es genießen, und was noch wichtiger ist, diese Vorhersage wurde tatsächlich von Jensen Ai gemacht, nicht von mir selbst.Ich habe es entworfen, aber die endgültigen Vorhersagen werden von Jensen AI präsentiert.
Als wir uns bemühen, die Leistung kontinuierlich zu verbessern und die Kosten zu senken, stellten die Forscher CUDA 2012 fest, was NVIDIA erster Kontakt mit künstlicher Intelligenz war.Dieser Tag ist für uns von entscheidender Bedeutung, da wir die kluge Entscheidung getroffen haben, eng mit Wissenschaftlern zusammenzuarbeiten, um ein tiefes Lernen zu ermöglichen.Die Entstehung von Alexnet hat einen großen Durchbruch in der Computer Vision erzielt.
4.Der Aufstieg der AI -Supercomputer wurde zunächst nicht anerkannt
Die wichtigere Weisheit ist jedoch, dass wir einen Schritt zurück treten und die Natur des tiefen Lernens tief verstehen.Was ist seine Grundlage?Was ist seine langfristige Auswirkungen?Was ist sein Potenzial?Wir wissen, dass diese Technologie ein großes Potenzial hat, um die vor Jahrzehnten erfundenen und entdeckten Algorithmen weiter zu erweitern, und mehr Daten, größere Netzwerke und entscheidende Rechenressourcen kombinieren. Deep Learning kann plötzlich Menschen auf Aufgaben erfüllen, die Algorithmen nicht erreichen können.
Stellen Sie sich nun vor, was passieren würde, wenn wir unsere Architektur weiter erweitern und ein größeres Netzwerk, mehr Daten und Rechenressourcen hätten?Wir sind also entschlossen, alles neu zu erfinden.Seit 2012 haben wir die Architektur der GPU geändert, den Tensor-Kern hinzugefügt, NV-Link erfunden, Cudnn, Tensorrt, Nickel, erworbenes Mellanox gestartet und den Triton-Inferenzserver gestartet.
Diese Technologien sind auf einen brandneuen Computer integriert, der zu dieser Zeit die Fantasie aller übertraf.Niemand erwartete, dass niemand eine solche Nachfrage machte, und niemand verstand sogar sein volles Potenzial.Tatsächlich bin ich mir nicht sicher, ob jemand es kaufen möchte.
Auf der GTC -Konferenz haben wir diese Technologie offiziell veröffentlicht.Ein Startup in San Francisco namens OpenAI bemerkte schnell unsere Ergebnisse und bat uns, ein Gerät bereitzustellen.Ich persönlich schickte die weltweit erste Supercomputer -Supercomputer -DGX der Welt nach Openai.
Im Jahr 2016 erweiterten wir unsere F & E -Skala weiter.Von einem einzigen Supercomputer für künstliche Intelligenz bis hin zu einer einzigen Anwendung für künstliche Intelligenz wurde er 2017 auf den Start eines größeren und leistungsstarken Supercomputers erweitert.Mit der kontinuierlichen Weiterentwicklung der Technologie hat die Welt den Aufstieg des Transformators erlebt.Die Entstehung dieses Modells ermöglicht es uns, massive Datenmengen zu verarbeiten und kontinuierliche Muster über lange Spannweiten zu identifizieren und zu lernen.
Heute können wir diese großen Sprachmodelle ausbilden, um wichtige Durchbrüche im Verständnis der natürlichen Sprache zu erzielen.Aber wir haben dort nicht angehalten, wir bewegten uns weiter vorwärts und bauten ein größeres Modell.Bis November 2022 verwenden wir über extrem leistungsstarke Supercomputer für künstliche Intelligenz Zehntausende von Nvidia -GPUs für das Training.
Nur 5 Tage später kündigte OpenAI an, dass Chatgpt 1 Million Nutzer hat.Diese erstaunliche Wachstumsrate ist in nur zwei Monaten auf 100 Millionen Benutzer gestiegen, was den schnellsten Wachstumsrekord in der Anwendungshistorie aufgestellt hat.Der Grund ist sehr einfach – die Benutzererfahrung von Chatgpt ist bequem und magisch.
Benutzer können natürlich und reibungslos mit Computern interagieren, als ob sie mit echten Menschen kommunizieren.Ohne mühsame Anweisungen oder klare Beschreibungen kann Chatgpt die Absichten und Bedürfnisse des Benutzers verstehen.
Die Entstehung von Chatgpt markiert eine epocherfende Änderung, und diese Folie erfasst diese kritische Wendung.Bitte erlauben Sie mir, es für Sie zu zeigen.
Erst als das Aufkommen von Chatgpt enthüllte es das unendliche Potenzial der generativen künstlichen Intelligenz in der Welt.Der Schwerpunkt der künstlichen Intelligenz konzentriert sich seit langer Zeit auf die Wahrnehmungsbereiche wie das Verständnis der natürlichen Sprache, das Computervision und die Spracherkennung, Technologien, die sich der Simulation menschlicher Wahrnehmungsfähigkeiten widmen.Chatgpt hat jedoch einen qualitativen Sprung gebracht, der nicht nur auf die Wahrnehmung beschränkt ist, sondern auch die Kraft generativer künstlicher Intelligenz zum ersten Mal demonstriert.
Es erzeugt Tokens einzeln, die Wörter, Bilder, Diagramme, Tabellen und sogar Songs, Text, Stimme und Videos sein können.Ein Token kann etwas mit klarer Bedeutung darstellen, sei es Chemikalien, Proteine, Gene oder die zuvor erwähnten Wettermuster.
Der Aufstieg dieser generativen künstlichen Intelligenz bedeutet, dass wir physikalische Phänomene lernen und simulieren können, sodass künstliche Intelligenzmodelle verschiedene Phänomene in der physischen Welt verstehen und generieren können.Wir beschränken uns nicht mehr darauf, den Umfang und die Filterung zu verengen, sondern erforschen unendliche Möglichkeiten durch die Generation.
Heute können wir Token für fast alles, was Wertvolles, egal ist, sei es die Lenkradkontrolle des Autos, die gemeinsame Bewegung des Roboterarms oder alles, was wir im Moment lernen können.Daher befinden wir uns nicht mehr in einer Ära künstlicher Intelligenz, sondern in einer neuen Ära, die von generativer künstlicher Intelligenz angeführt wird.
Noch wichtiger ist, dass dieses Gerät, das ursprünglich als Supercomputer auftrat, jetzt zu einem effizienten und effizienten Rechenzentrum für künstliche Intelligenz entwickelt wurde.Es produziert weiter, erzeugt nicht nur Token, sondern auch eine künstliche Intelligenzfabrik, die Wert schafft.Diese Fabrik für künstliche Intelligenz erzeugt, schafft und produziert neue Waren mit enormem Marktpotential.
So wie Nikola Tesla Ende des 19. Jahrhunderts die Lichtmaschine erfand und uns einen stetigen Strom von Elektronik lieferte, erzeugen die künstlichen Intelligenzgeneratoren von Nvidia ebenfalls kontinuierlich Token mit unendlichen Möglichkeiten.Beide haben enorme Marktchancen und werden voraussichtlich in jeder Branche verändern.Dies ist in der Tat eine neue industrielle Revolution!
Wir begrüßen jetzt eine brandneue Fabrik, die beispiellose und wertvolle neue Produkte für alle Branchen produzieren kann.Diese Methode ist nicht nur äußerst skalierbar, sondern auch vollständig wiederholbar.Bitte beachten Sie, dass derzeit verschiedene Modelle für künstliche Intelligenz täglich ständig entstehen, insbesondere modelle künstliche Intelligenz.Heutzutage kämpft jede Branche um die Teilnahme, was eine beispiellose große Anlässe darstellt.
In der IT -Branche in Höhe von 3 Billionen US -Dollar werden innovative Erfolge erzielt, die der Branche von 100 Billionen US -Dollar direkt dienen können.Es handelt sich nicht mehr nur um ein Tool zur Speicherung oder Datenverarbeitung, sondern um eine Engine zur Generierung von Intelligenz in jeder Branche.Dies wird zu einer neuen Art von Fertigungsindustrie, aber es handelt sich nicht um eine traditionelle Computerherstellungsindustrie, sondern ein neues Herstellungsmodell mit Computern.Eine solche Veränderung ist noch nie zuvor passiert, und es ist in der Tat eine bemerkenswerte Sache.
5.Generative KI fördert die Umformung der Software mit Vollstapel und demonstrieren nim-Cloud-native Microservices
Dies eröffnete eine neue Ära des beschleunigten Computers, förderte die schnelle Entwicklung künstlicher Intelligenz und brachte den Aufstieg generativer künstlicher Intelligenz hervor.Und jetzt erleben wir eine industrielle Revolution.Schauen wir uns die Auswirkungen genauer an.
Die Auswirkungen dieser Veränderung sind für unsere Branche ebenso weitreichend.Wie ich bereits sagte, ist dies das erste Mal in den letzten sechzig Jahren. Jede Computerschicht wird Transformation unterzogen.Vom allgemeinen Umsatzcomputer der CPU über das beschleunigte Computer von GPUs markiert jeder Änderungssprung einen technologischen Sprung.
In der Vergangenheit mussten Computer Anweisungen befolgen, um Operationen auszuführen, aber jetzt kümmerte sie sich mehr mit LLM (Big Language Model) und künstlichen Intelligenzmodellen.Frühere Computermodelle basierten auf dem Abrufen. Fast jedes Mal, wenn Sie Ihr Telefon verwenden, werden vorgespannte Text, Bilder oder Videos für Sie abgerufen und diese Inhalte gemäß dem Empfehlungssystem rekombiniert, um sie Ihnen zu präsentieren.
In Zukunft wird Ihr Computer jedoch so viel Inhalt wie möglich generieren und nur die erforderlichen Informationen abrufen, da das Generieren von Daten beim Erhalten von Informationen weniger Energie verbraucht.Darüber hinaus haben die generierten Daten eine höhere kontextbezogene Relevanz und können Ihre Bedürfnisse genauer widerspiegeln.Wenn Sie eine Antwort benötigen, müssen Sie den Computer nicht mehr explizit anweisen, „mir diese Informationen zu erhalten“ oder „mir diese Datei zu geben“. Sag einfach einfach: „Gib mir eine Antwort.“
Darüber hinaus sind Computer nicht mehr nur Tools, die wir verwenden, sondern sie beginnen Fähigkeiten zu generieren.Es führt Aufgaben aus und ist keine Produktionssoftware -Branche mehr, die Anfang der neunziger Jahre eine störende Idee war.Erinnern?Das von Microsoft vorgeschlagene Softwareverpackungskonzept hat die PC -Branche vollständig verändert.Ohne verpackte Software verliert unser PC den größten Teil seiner Funktionalität.Diese Innovation hat die Entwicklung der gesamten Branche getrieben.
Jetzt haben wir eine neue Fabrik, einen neuen Computer, und auf dieser Basis handelt es sich um eine neue Art von Software – wir nennen es NIM (Nvidia Inference Microservices).Nim Laufen in dieser neuen Fabrik ist ein vorgebildetes Modell, das eine künstliche Intelligenz ist.

这个人工智能本身相当复杂,但运行人工智能的计算堆栈更是复杂得令人难以置信。当你使用ChatGPT这样的模型时,其背后是庞大的软件堆栈。Dieser Stapel ist komplex und riesig, da das Modell Milliarden bis Billionen von Parametern hat und nicht nur auf einem Computer ausgeführt wird, sondern auch auf mehreren Computern zusammenarbeitet.
Um die Effizienz zu maximieren, muss das System für verschiedene parallele Verarbeitung Arbeitslast für verschiedene GPUs zuweisen, wie z.Eine solche Zuordnung soll sicherstellen, dass die Arbeiten so schnell wie möglich abgeschlossen werden können, da der Durchsatz in einem Werk in direktem Zusammenhang mit den Einnahmen, der Servicequalität und der Anzahl der Kunden steht, die bedient werden können.如今,我们身处一个数据中心吞吐量利用率至关重要的时代。
过去,虽然吞吐量被认为重要,但并非决定性的因素。Jetzt wird jedoch jeder Parameter aus Startzeit, Laufzeit, Auslastung und Durchsatz zur Leerlaufzeit genau gemessen, da das Rechenzentrum zu einer echten „Fabrik“ geworden ist.In dieser Fabrik steht die operative Effizienz in direktem Zusammenhang mit der finanziellen Leistung des Unternehmens.
Angesichts dieser Komplexität wissen wir, welche Herausforderungen die meisten Unternehmen beim Einsatz von KI gegenüberstehen.Daher haben wir eine integrierte KI -Containerlösung entwickelt, die KI in einer Box zusammenfasst, die einfach zu bereitstellen und verwalten zu können.Diese Box enthält eine riesige Sammlung von Software wie Cuda, Cudacnn und Tensorrt sowie den Triton -Inferenzdienst.Es unterstützt Cloud-native Umgebungen, ermöglicht die automatische Skalierung in Kubernetes (eine verteilte Architekturlösung basierend auf Container-Technologie) und bietet Managementdiensten, um den Benutzern den Betriebsstatus künstlicher Intelligenzdienste zu überwachen.
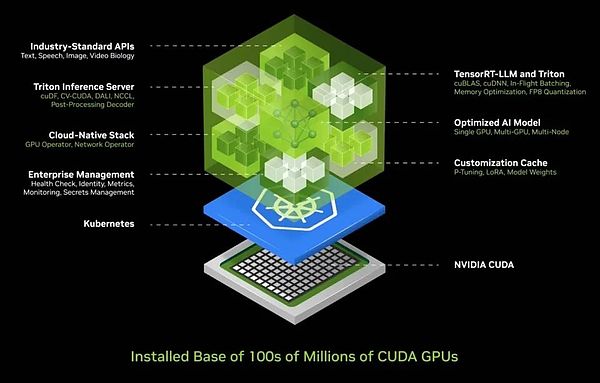
Noch aufregender ist, dass dieser KI -Container eine universelle Standard -API -Schnittstelle bietet, mit der Benutzer direkt mit dem „Box“ interagieren können.Benutzer können AI-Dienste einfach bereitstellen und verwalten, indem sie einfach NIM herunterladen und auf einem CUDA-fähigen Computer ausgeführt werden.Heute ist CUDA überall, es unterstützt große Cloud -Service -Anbieter, und fast alle Computerhersteller bieten CUDA -Unterstützung an und finden Sie in Hunderten von Millionen PCs.
Wenn Sie NIM herunterladen, haben Sie sofort einen KI -Assistenten, der reibungslos wie ein Gespräch mit ChatGPT kommuniziert.Jetzt wurde die gesamte Software optimiert und in einen Container integriert, und alle bisher umständlichen 400 Abhängigkeiten sind zentral optimiert.Wir führten strenge Tests von NIM durch, und jedes vorbereitete Modell wurde vollständig auf unserer Cloud -Infrastruktur getestet, einschließlich verschiedener Versionen von GPUs wie Pascal, Ampere und dem neuesten Hopper.Diese Versionen sind von einer großen Vielfalt und deckt fast alle Anforderungen ab.
Nims Erfindung ist zweifellos eine Leistung und es ist eine meiner stolzensten Errungenschaften.Heute können wir große Sprachmodelle und verschiedene vorgebreitete Modelle erstellen, die mehrere Felder wie Sprache, Vision, Bilder und benutzerdefinierte Versionen für bestimmte Branchen wie Gesundheitswesen und digitale Biologie abdecken.

Um mehr zu erfahren oder diese Versionen auszuprobieren, besuchen Sie einfach ai.nvidia.com.Heute haben wir das vollständig optimierte Lama 3 nim on umarmt, das Sie sofort erleben und sogar kostenlos mitnehmen können.Unabhängig davon, für welche Cloud -Plattform Sie sich entscheiden, können Sie sie einfach ausführen.Natürlich können Sie diesen Container auch in Ihr Rechenzentrum herunterladen, ihn selbst hosten und Ihre Kunden bedienen.
Wie ich bereits erwähnt habe, haben wir NIM -Versionen, die verschiedene Felder abdecken, einschließlich Physik, semantischer Suche, visueller Sprache usw., die mehrere Sprachen unterstützen.这些微服务可以轻松集成到大型应用中,其中最具潜力的应用之一是客户服务代理。Es ist in fast jeder Branche Standard und stellt einen globalen Billionen-Dollar-Kundendienstmarkt dar.
Erwähnenswert ist, dass Krankenschwestern als Kern des Kundendienstes eine wichtige Rolle in Einzelhandel, Fastfood, Finanzdienstleistungen, Versicherungen und anderen Branchen spielen.Heute wurden zig Millionen von Kundendienstmitarbeitern mit Hilfe von Sprachmodellen und Technologie für künstliche Intelligenz erheblich verbessert.Im Zentrum dieser Verbesserungstools ist genau das, was Sie Nim sehen.
Einige werden als Argumentationsmittel bezeichnet, und wenn sie Aufgaben zugewiesen haben, können sie Ziele identifizieren und planen.Einige sind gut darin, Informationen abzurufen, einige sind in der Suche nachher und einige können Tools wie Coop verwenden oder bestimmte Sprachen lernen, die auf SAP ausgeführt werden, wie ABAP, oder sogar SQL -Abfragen ausführen.Diese sogenannten Experten werden jetzt zu einem effizienten und kollaborativen Team geformt.
Die Anwendungsschicht hat sich ebenfalls geändert: In der Vergangenheit wurden Anwendungen durch Anweisungen verfasst, aber jetzt werden sie durch Zusammenstellung künstlicher Intelligenzteams gebaut.Während das Schreiben eines Programms Expertise erfordert, weiß fast jeder, wie man Probleme aufschließt und ein Team bildet.Daher bin ich fest davon überzeugt, dass jedes Unternehmen in Zukunft eine große Sammlung von NIM haben wird.Sie können Experten auswählen, wie Sie möchten, und sie mit einem Team in Verbindung bringen.
Noch erstaunlicher ist, dass Sie nicht einmal herausfinden müssen, wie man sie verbindet.Weisen Sie dem Agenten einfach eine Aufgabe zu.Sie sind wie zentrale Führungskräfte von Anwendungen oder Teams, die die Arbeit der Teammitglieder koordinieren und Ihnen letztendlich die Ergebnisse vorstellen können.
Der gesamte Prozess ist so effizient und flexibel wie die menschliche Teamarbeit.Dies ist nicht nur ein Trend in der Zukunft, sondern auch in der Nähe von uns.Dies ist ein völlig neuer Look, den Anwendungen in Zukunft aufweisen werden.
6.PC wird der Hauptträger digitaler Menschen
Wenn wir über Interaktionen mit großen KI -Diensten sprechen, können wir dies jetzt mit Text- und Sprachaufforderungen tun.Aber ich freue mich auf die Zukunft und hoffen, dass wir auf humanere Weise interagieren, nämlich digitale Menschen.Nvidia hat im Bereich der digitalen menschlichen Technologie erhebliche Fortschritte erzielt.

Digitale Menschen haben nicht nur das Potenzial, ausgezeichnete interaktive Agenten zu sein, sondern auch ansprechender und können höhere Empathie aufweisen.Es erfordert jedoch immer noch große Anstrengungen, um diese unglaubliche Lücke zu überschreiten und digitale Menschen natürlicher aussehen und sich mehr fühlen.Dies ist nicht nur unsere Vision, sondern auch unser unablässiges Ziel.
Bevor ich Ihnen unsere aktuellen Errungenschaften zeige, können Sie mir bitte meine warme Grüße nach Taiwan, China, ausdrücken.Bevor wir den Charme der Nachtmärkte ausführlich untersuchen, schätzen wir zunächst die hochmodernen Dynamik der digitalen menschlichen Technologie.
Das ist in der Tat unglaublich.ACE (Avatar Cloud Engine) läuft nicht nur in der Cloud effizient, sondern ist auch mit PC -Umgebungen kompatibel.Wir haben eine zukunftsgerichtete Integration von Tensor-Kern-GPUs in alle RTX-Familien, was die Ankunft der Ära der AI-GPUs markiert, und wir sind darauf voll vorbereitet.
Die Logik dahinter ist sehr klar: Um eine neue Computerplattform zu erstellen, muss eine solide Grundlage an erster Stelle gelegt werden.Mit einer soliden Fundament entstehen natürlich Anwendungen.Wenn eine solche Stiftung fehlt, wird die Anwendung nicht in Frage kommen.Nur wenn wir es bauen, kann der Wohlstand der Anwendung möglich sein.
Daher haben wir in jeder RTX -GPU Tensor -Kernverarbeitungseinheiten integriert.Auf der jüngsten ComputEx -Ausstellung haben wir vier neue AI -Laptops gestartet.
Diese Geräte können künstliche Intelligenz durchführen.Laptops und PCs der Zukunft werden Träger künstlicher Intelligenz und bieten Ihnen stillschweigend Hilfe und Unterstützung im Hintergrund.Gleichzeitig werden diese PCs auch Anwendungen ausführen, die durch künstliche Intelligenz verbessert werden und ob Sie die Bearbeitung, Schreiben oder Verwendung anderer Tools ausführen, die Bequemlichkeits- und Verbesserungseffekte durch künstliche Intelligenz genießen.

Darüber hinaus kann Ihr PC in der Lage sein, digitale menschliche Anwendungen mit künstlicher Intelligenz zu veranstalten, sodass KI auf vielfältigere Weise präsentiert und auf Ihrem PC angewendet werden kann.Offensichtlich wird PC eine entscheidende KI -Plattform.Wie werden wir uns als nächstes entwickeln?
Ich habe zuvor über die Erweiterung unserer Rechenzentren gesprochen, und jede Expansion wird von neuen Änderungen begleitet.Als wir von DGX auf große KI -Supercomputer erweitert wurden, haben wir eine effiziente Schulung von Transformer in riesigen Datensätzen implementiert.Dies ist eine große Verschiebung: Zu Beginn erfordern Daten die menschliche Aufsicht und künstliche Intelligenz wird durch menschliche Markierungen geschult.Die Datenmenge, die Menschen markieren können, ist jedoch begrenzt.Mit der Entwicklung des Transformators ist das unbeaufsichtigte Lernen möglich geworden.
Heute kann Transformer massive Mengen an Daten, Videos und Bildern selbst untersuchen, lernen und entdecken versteckte Muster und Beziehungen.Um künstliche Intelligenz auf einer höheren Ebene zu fördern, muss die nächste Generation künstlicher Intelligenz auf das Verständnis der physischen Gesetze verwurzelt werden, aber die meisten künstlichen Intelligenzsysteme fehlen ein tiefes Verständnis der physischen Welt.Um realistische Bilder, Videos, 3D-Grafiken zu generieren und komplexe physikalische Phänomene zu simulieren, müssen wir dringend physikbasierte künstliche Intelligenz entwickeln, wodurch es in der Lage ist, die Gesetze der Physik zu verstehen und anzuwenden.
Es gibt zwei Hauptmethoden, um dies zu erreichen.Erstens kann künstliche Intelligenz durch das Lernen aus Videos nach und nach Wissen über die physische Welt sammeln.Zweitens können wir mit synthetischen Daten eine reichhaltige und kontrollierbare Lernumgebung für künstliche Intelligenzsysteme bereitstellen.Darüber hinaus ist das simulierte Lernen zwischen Daten und Computern auch eine effektive Strategie.Diese Methode ähnelt dem Selbstspielmodus von Alphago und ermöglicht zwei Entitäten mit der gleichen Fähigkeit, lange Zeit voneinander zu lernen und damit ihre Intelligenzstufe kontinuierlich zu verbessern.Daher können wir voraussehen, dass diese Art von künstlicher Intelligenz in Zukunft allmählich entstehen wird.
7.Blackwell wird vollständig in die Produktion gesteckt, und seine Rechenleistung hat in acht Jahren um das 1.000 -fache gestiegen
Wenn Daten für künstliche Intelligenz durch Synthese generiert und mit der Verstärkungslernentechnologie kombiniert werden, wird die Datenerzeugung erheblich verbessert.Mit zunehmender Datenerzeugung wird auch die Nachfrage nach Rechenleistung entsprechend zunehmen.Wir sind kurz davor, in eine neue Ära einzutreten, in der künstliche Intelligenz in der Lage sein wird, die Gesetze der Physik zu lernen, zu verstehen und Entscheidungen und Handlungen auf der Grundlage von Daten aus der physischen Welt zu treffen.Wir erwarten daher, dass das KI -Modell weiter erweitert wird und die Anforderungen an die GPU -Leistung immer höher werden.
Um dieses Bedürfnis zu erfüllen, wurde Blackwell entstanden.Diese GPU wurde entwickelt, um eine neue Generation künstlicher Intelligenz zu unterstützen, und verfügt über mehrere Schlüsseltechnologien.Diese Chipgröße ist die beste in der Branche.Wir verwenden zwei Chips so groß wie möglich und verbinden sie eng mit einem Hochgeschwindigkeitsverbindung von 10 Terabyte pro Sekunde in Kombination mit den fortschrittlichsten Serden der Welt (Hochleistungsschnittstelle oder Verbindungstechnologie).Darüber hinaus legen wir zwei solcher Chips auf einen Computerknoten und koordinieren effizient über die Grace -CPU.
Grace -CPUs sind vielseitig und nicht nur für Trainingsszenarien geeignet, sondern spielen auch eine Schlüsselrolle bei Inferenz und Generation, wie z. B. schneller Checkpointing und Neustart.Darüber hinaus kann es Kontexte speichern, sodass KI -Systeme Speicher haben und den Kontext von Benutzerkonversationen verstehen können, was für die Verbesserung der Kontinuität und Flüssigkeit von Interaktionen von entscheidender Bedeutung ist.
Unsere Transformator-Motor der zweiten Generation verbessert die Recheneffizienz der künstlichen Intelligenz weiter.Dieser Motor kann sich dynamisch auf eine geringere Genauigkeit entsprechend den Genauigkeit und den Bereichsanforderungen der Rechenschicht einstellen und damit den Energieverbrauch verringern und gleichzeitig die Leistung aufrechtzuerhalten.In der Zwischenzeit verfügt Blackwell GPUs auch sichere Funktionen für künstliche Intelligenz, um sicherzustellen, dass Benutzer Dienstanbieter bitten können, sie vor Diebstahl oder Manipulationen zu schützen.
In Bezug auf die GPU -Verbindungsverbindung haben wir die NV -Link -Technologie der fünften Generation übernommen, mit der wir mehrere GPUs problemlos anschließen können.Darüber hinaus sind Blackwell GPUs mit der ersten Generation von Zuverlässigkeits- und Verfügbarkeitsmotoren (RAS Systems) ausgestattet, einer innovativen Technologie, mit der jeden Transistor, Trigger, Speicher und Off-Chip-Speicher auf dem Chip getestet werden können, um sicherzustellen, dass wir genau vor Ort beurteilen können Ob ein bestimmter Chip die durchschnittliche Zeit zwischen Fehlern (MTBF) entspricht.
Zuverlässigkeit ist besonders für große Supercomputer entscheidend.Die durchschnittliche Ausfallintervallzeit für einen Supercomputer mit 10.000 GPUs kann in Stunden betragen. Wenn jedoch die Anzahl der GPUs auf 100.000 steigt, wird die durchschnittliche Ausfallintervallzeit auf Minuten reduziert.Um sicherzustellen, dass Supercomputer lange stabil laufen können, um komplexe Modelle zu schulen, die Monate dauern können, müssen wir die Zuverlässigkeit durch technologische Innovation verbessern.Die Verbesserung der Zuverlässigkeit kann nicht nur die Laufzeit des Systems erhöhen, sondern auch die Kosten effektiv reduzieren.
Schließlich integrieren wir auch eine fortschrittliche Dekompressionsmotor in die Blackwell -GPU.In Bezug auf die Datenverarbeitung ist die Dekompressionsgeschwindigkeit von entscheidender Bedeutung.Durch die Integration dieser Engine können wir Daten 20 -mal schneller aus dem Speicher ziehen als die vorhandene Technologie, was die Datenverarbeitungseffizienz erheblich verbessert.
Die obigen Merkmale der Blackwell -GPU machen es zu einem bemerkenswerten Produkt.Auf der vorherigen GTC -Konferenz habe ich Ihnen Blackwell im Prototypstaat gezeigt.Und jetzt freuen wir uns, Ihnen mitteilen zu können, dass dieses Produkt in Produktion gestellt wurde.

Dies ist Blackwell, jeder, der unglaubliche Technologie verwendet.Dies ist unser Meisterwerk, das komplexeste und leistungsstärkste Computer der Welt heute.Unter ihnen möchten wir besonders die Grace -CPU erwähnen, die enorme Rechenleistung bietet.Bitte sehen Sie, diese beiden Blackwell -Chips sind eng miteinander verbunden.Hast du es bemerkt?Dies ist der größte Chip der Welt, und wir verwenden Links bis zu A10TB pro Sekunde, um zwei solcher Chips in einen zu mischen.
Also, was genau ist Blackwell?Seine Leistung ist unglaublich.Bitte beachten Sie diese Daten sorgfältig.In nur acht Jahren haben unsere Rechenleistung, die arithmetische und künstliche Intelligenz arithmetische Funktionen der arithmetischen und künstlichen Intelligenz um das 1.000-fache gestiegen.Diese Geschwindigkeit übertrifft fast das Wachstum von Moores Law in der besten Zeit.
Das Wachstum der Rechenleistung von Blackwell ist einfach erstaunlich.Erwähnenswertes ist, dass die Kosten ständig sinken, wenn unsere Rechenleistung steigt.Lass mich dir etwas zeigen.Durch die Verbesserung der Rechenleistung ist die Energie, die zum Training von GPT-4-Modellen (2 Billionen Parameter und 8 Billionen Token) verwendet wird, um 350 Mal gesunken.
Stellen Sie sich vor, Pascal macht das gleiche Training, es würde bis zu 1000 GWh Energie verbrauchen.Dies bedeutet, dass ein GW -Rechenzentrum benötigt wird, um es zu unterstützen, aber solche Rechenzentren existieren nicht in der Welt.Selbst wenn es existiert, dauert es einen Monat, bis es kontinuierlich laufen kann.Und wenn es sich um ein 100 -MW -Rechenzentrum handelt, beträgt die Trainingszeit bis zu einem Jahr.
Natürlich will oder kann niemand ein solches Rechenzentrum erstellen.Deshalb waren vor acht Jahren große Sprachmodelle wie Chatgpt für uns immer noch ein entfernter Traum.Aber jetzt erreichen wir dies, indem wir die Leistung erhöhen und den Energieverbrauch verringern.
Wir haben Blackwell verwendet, um die Energie zu reduzieren, die sonst bis zu 1.000 GWh auf nur 3 GWh benötigt, eine Leistung, die zweifellos ein schockierender Durchbruch ist.Stellen Sie sich vor, Sie verwenden 1.000 GPUs, die Energie, die sie verbrauchen, entspricht nur den Kalorien einer Tasse Kaffee.Und 10.000 GPUs können die gleiche Aufgabe in fast 10 Tagen erledigen.Diese Fortschritte in acht Jahren sind einfach unglaublich.

Blackwell ist nicht nur für Inferenz geeignet, sondern seine Verbesserung der Leistung der Token-Generation ist noch mehr auffälliger.In der Pascal -Ära verbrauchte jedes Token bis zu 17.000 Joule Energie, was ungefähr die Energie von zwei Glühbirnen ist, die zwei Tage lang laufen.Um ein GPT-4-Token zu erzeugen, benötigt es fast zwei 200-Watt-Glühbirnen, um zwei Tage lang zu laufen.In Anbetracht der Tatsache, dass es ungefähr 3 Token braucht, um ein Wort zu erzeugen, ist dies in der Tat ein großer Energieverbrauch.
Die Situation ist jetzt jedoch völlig anders.Blackwell kostet nur 0,4 Joule Energie, um jedes Token zu erzeugen, und die Token -Generation ist mit erstaunlicher Geschwindigkeit und extrem geringem Energieverbrauch.Dies ist zweifellos ein großer Sprung.Trotzdem sind wir immer noch nicht zufrieden.Für einen größeren Durchbruch müssen wir leistungsstärkere Maschinen bauen.
Dies ist unser DGX -System, und der Blackwell -Chip wird darin eingebettet.Dieses System verwendet die Luftkühltechnologie und ist mit 8 solchen GPUs im Inneren ausgestattet.Schauen Sie sich die Kühlkörper an diesem GPUs an, ihre Größe ist erstaunlich.Der Stromverbrauch des gesamten Systems beträgt etwa 15 kW, was durch Luftkühlung vollständig erreicht wird.Diese Version ist mit X86 kompatibel und wurde auf unsere versendeten Server angewendet.
Wenn Sie jedoch die Flüssigkühlungstechnologie bevorzugen, haben wir auch ein brandneues System – das MGX.Es basiert auf diesem Motherboard -Design, das wir als „modulares“ System bezeichnen.Der Kern des MGX -Systems liegt in zwei Blackwell -Chips, und jeder Knoten integriert vier Blackwell -Chips.Es verwendet die Flüssigkühlungstechnologie, um einen effizienten und stabilen Betrieb zu gewährleisten.
Im gesamten System gibt es neun solcher Knoten, insgesamt 72 GPUs, die einen riesigen Computercluster bilden.Diese GPUs sind durch die neue NV -Link -Technologie eng miteinander verbunden, um ein nahtloses Computernetzwerk zu bilden.NV -Link -Switches sind ein technisches Wunder.Es ist derzeit der fortschrittlichste Wechsel der Welt mit einer erstaunlichen Datenübertragungsrate.Diese Schalter machen jeden Blackwell -Chip effizient angeschlossen und bilden einen riesigen 72 GPU -Cluster.
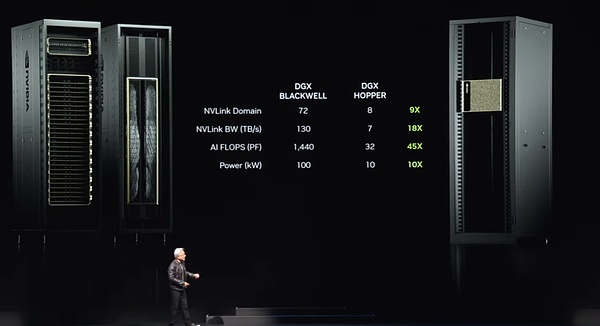
Was sind die Vorteile dieses Clusters?Erstens wirkt es in der GPU-Domäne jetzt wie eine einzelne, super große GPU.Diese „Super GPU“ verfügt über die Kernfunktionen von 72 GPUs und die Leistung ist 9 -mal höher als die vorherige Generation von 8 GPUs.Gleichzeitig hat sich die Bandbreite um das 18 -fache erhöht, die KI -Flops (schwimmende Punktvorgänge pro Sekunde) haben sich um das 45 -fache und die Leistung haben nur das 10 -fache gestiegen.Das heißt, ein solches System kann eine starke Leistung von 100 Kilowatt liefern, während die vorherige Generation nur 10 Kilowatt betrug.
Natürlich können Sie auch mehr dieser Systeme mit einem größeren Computernetzwerk verbinden.Das wirkliche Wunder liegt jedoch in der Tatsache, dass dieser NV -Link -Chip mit zunehmender Größe des großen Sprachmodells immer großer wird.Da diese großsprachigen Modelle nicht mehr zum Laufen auf einer einzelnen GPU oder einem Knoten geeignet sind, müssen das gesamte GPU -Rack zusammenarbeiten.Genau wie das neue DGX -System, das ich gerade erwähnt habe, kann es große Sprachmodelle mit Hunderten von Billionen von Parametern aufnehmen.
Der NV Link Switch selbst ist ein technologisches Wunder mit 50 Milliarden Transistoren und 74 Ports und jeder Port hat eine Datenrate von bis zu 400 GB.Noch wichtiger ist jedoch, dass der Switch auch mathematische Betriebsfunktionen integriert, die direkte Reduktionsvorgänge ausführen können, was für das tiefgreifende Lernen von großer Bedeutung ist.Dies ist das neue Erscheinungsbild des aktuellen DGX -Systems.
Viele Menschen sind neugierig auf uns.Sie fragten sich, dass es ein Missverständnis des Geschäftsbereichs von Nvidia gab.Die Leute fragen sich, wie Nvidia so groß werden könnte, nur durch GPUs zu machen.Daher haben viele Menschen den Eindruck erweckt, dass die GPU auf eine bestimmte Art und Weise aussehen sollte.
Was ich Ihnen jetzt zeigen möchte, ist, dass dies tatsächlich eine GPU ist, aber es ist nicht die Art, die Sie denken.Dies ist einer der fortschrittlichsten GPUs der Welt, wird aber hauptsächlich im Spielfeld verwendet.Aber wir alle wissen, dass die wahre Kraft des GPUs viel mehr ist.
Jeder, bitte schauen Sie sich das an, dies ist die wahre Form der GPU.Dies ist eine DGX -GPU, die für tiefes Lernen entwickelt wurde.Die Rückseite dieser GPU ist mit dem NV -Link -Rückgrat verbunden, das aus 5.000 Linien besteht und 3 Kilometer lang ist.Diese Zeilen sind das NV Link Backbone, das 70 GPUs mit einem leistungsstarken Computernetzwerk verbindet.Dies ist ein elektronisches mechanisches Wunder, bei dem der Transceiver Signale über die gesamte Länge am Kupferdraht fahren kann.
Daher überträgt dieser NV -Link -Switch die Daten auf dem Kupferkabel über das NV -Link -Backbone, sodass wir 20 kW Strom in einem einzelnen Rack sparen können, das nun für die Datenverarbeitung verwendet wird. Dies ist in der Tat eine faszinierende Tatsache unglaubliche Leistung.Dies ist die Kraft des NV -Link -Rückgrates.
8.Fördern Sie Ethernet für generative KI
Dies reicht jedoch nicht aus, um die Nachfrage zu befriedigen, insbesondere für große KI -Fabriken, also haben wir eine andere Lösung.Wir müssen diese KI-Fabriken mit Hochgeschwindigkeitsnetzwerken verbinden.Wir haben zwei Netzwerkoptionen: Infiniband und Ethernet.Unter ihnen wurde Infiniband in Supercomputing- und künstlichen Intelligenzfabriken auf der ganzen Welt häufig eingesetzt und wächst rasant.Allerdings kann nicht jedes Rechenzentrum Infiniband direkt verwenden, da sie erhebliche Investitionen in das Ethernet -Ökosystem getätigt haben, und die Verwaltung von Infiniband -Switches und -Netzwerken erfordert etwas Fachwissen und Technologie.
Daher ist es unsere Lösung, die Leistung von Infiniband in die Ethernet -Architektur zu bringen, was nicht einfach ist.Der Grund dafür ist, dass jeder Knoten, jeder Computer, normalerweise mit verschiedenen Benutzern im Internet verbunden ist, aber der größte Teil der Kommunikation tritt tatsächlich innerhalb des Rechenzentrums auf, d. H. Der Datenübertragung zwischen dem Rechenzentrum und den Benutzern am anderen Ende des Internets .Im Deep -Lern -Szenario von Fabriken für künstliche Intelligenz kommunizieren die GPUs jedoch nicht mit Benutzern im Internet, sondern häufig und intensiver Datenaustausch miteinander.
Sie kommunizieren miteinander, weil sie alle einen Teil der Ergebnisse sammeln.Sie müssen dann diese Teilergebnisse reduzieren und sie umverteilen.Dieser Kommunikationsmodus zeichnet sich durch stark geplatzten Verkehr aus.Was zählt, ist nicht der durchschnittliche Durchsatz, sondern die letzten Daten, die eintreffen, denn wenn Sie teilweise Ergebnisse von allen sammeln und ich versuche, alle Ihre Teilergebnisse zu erhalten, wird sich die gesamte Operation verzögern, wenn das letzte Paket spät eintrifft, dann wird sich die gesamte Operation verzögern .Latenz ist ein entscheidendes Problem für KI -Fabriken.
Daher liegt unser Fokus nicht im durchschnittlichen Durchsatz, sondern darauf, dass das letzte Paket rechtzeitig und ohne Fehler eintrifft.Das herkömmliche Ethernet wurde jedoch für so stark synchronisierte Latenzanforderungen nicht optimiert.Um diesen Bedarf zu erfüllen, haben wir kreativ eine End-to-End-Architektur entwickelt, mit der NICS (Netzwerk-Schnittstellenkarten) und Schalter kommunizieren können.Um dies zu erreichen, haben wir vier Schlüsseltechnologien eingesetzt:
Erstens verfügt Nvidia über die branchenführende RDMA-Technologie (Remote Direct Memory Access).Jetzt haben wir RDMA auf Ethernet Network Level und es macht einen großartigen Job.
Zweitens haben wir einen Überlastungskontrollmechanismus eingeführt.Der Switch verfügt über eine Echtzeit-Telemetriefunktion, die schnell über eine Überlastung im Netzwerk identifiziert und reagieren kann.Wenn die von der GPU oder NIC gesendete Datenmenge zu groß ist, sendet der Schalter sofort ein Signal, um sie zu informieren, um die Übertragungsrate zu verlangsamen, wodurch die Erzeugung von Netzwerk -Hotspots effektiv vermieden wird.
Drittens verwenden wir adaptive Routing -Technologie.Traditionelles Ethernet überträgt die Daten in einer festen Reihenfolge, aber in unserer Architektur können wir uns basierend auf Echtzeit-Netzwerkbedingungen flexibel anpassen.Wenn eine Überlastung gefunden oder einige Ports im Leerlauf sind, können wir Pakete an diese Leerlaufanschlüsse senden und sie am anderen Ende vom Bluefield -Gerät neu ordnen, um sicherzustellen, dass die Daten in der richtigen Reihenfolge zurückgegeben werden.Diese adaptive Routing -Technologie verbessert die Flexibilität und Effizienz des Netzwerks erheblich.
Viertens haben wir Rauschisolationstechnologie implementiert.In einem Rechenzentrum können Geräusche und Verkehr, die von mehreren Modellen gleichzeitig erzeugt werden, einander beeinträchtigen und Jitter verursachen.Unsere Rauschisolierungstechnologie kann diese Geräusche effektiv isolieren und sicherstellen, dass die Übertragung kritischer Datenpakete nicht beeinträchtigt wird.
Durch die Einführung dieser Technologien haben wir KI-Fabriken erfolgreich leistungsstarke Netzwerklösungen mit geringem Latenz geliefert.In einem Datenzentrum von mehreren Milliarden Dollar, wenn die Netzwerkauslastung um 40% steigt und die Schulungszeit um 20% verringert wird, bedeutet dies tatsächlich, dass ein Rechenzentrum von 5 Milliarden US der Netzwerkleistung bei der Gesamtkosteneffizienz.
Glücklicherweise ist die Ethernet -Technologie mit Spectrum X der Schlüssel zu unserer Leistung, die die Netzwerkleistung erheblich verbessert und die Netzwerkkosten in Bezug auf das gesamte Rechenzentrum nahezu vernachlässigbar macht.Dies ist zweifellos eine großartige Leistung, die wir im Bereich der Netzwerktechnologie erzielt haben.
Wir haben eine starke Ethernet -Produktaufstellung, von denen das bemerkenswerteste das Spektrum x800 ist.Mit 51,2 TB pro Sekunde und 256 Pfadunterstützung (Radix) bietet dieses Gerät eine effiziente Netzwerkkonnektivität zu Tausenden von GPUs.Als nächstes planen wir, das X800 Ultra in einem Jahr zu starten, das 512 Radix mit bis zu 512 Pfaden unterstützt und die Netzwerkkapazität und -leistung weiter verbessert.Der X1600 ist für größere Rechenzentren ausgelegt und kann den Kommunikationsbedarf von Millionen von GPUs erfüllen.

Mit der kontinuierlichen Weiterentwicklung der Technologie steht die Rechenzentrums -Ära von Millionen von GPUs gleich um die Ecke.Es gibt tiefgreifende Gründe für diesen Trend.Einerseits sind wir bestrebt, größere und komplexere Modelle auszubilden.Diese AIs werden mit uns arbeiten und interagieren, um Videos, Bilder, Texte und sogar digitale Personen zu generieren.Daher ist fast jede Interaktion, die wir mit Computern interagieren, untrennbar mit der Teilnahme generativer künstlicher Intelligenz.Und es gibt immer eine generative KI, die mit ihr angeschlossen ist, einige laufen lokal, einige laufen auf Ihrem Gerät und viele können in der Cloud ausgeführt werden.
Diese generativen künstlichen Intelligenzen haben nicht nur starke Argumentationsfunktionen, sondern optimieren auch iterativ Antworten, um die Qualität der Antworten zu verbessern.Dies bedeutet, dass wir in Zukunft massive Anforderungen an die Datenerzeugung generieren werden.Heute Abend haben wir die Kraft dieser technologischen Innovation zusammen gesehen.
Blackwell als erste Generation der Nvidia -Plattform hat seit ihrer Einführung viel Aufmerksamkeit auf sich gezogen.Heute führt die Ära der generativen künstlichen Intelligenz in der Welt, der Beginn einer neuen industriellen Revolution, und jede Ecke ist sich der Bedeutung künstlicher Intelligenzfabriken bewusst.Es ist uns eine große Ehre, von allen Lebensbereichen umfassende Unterstützung erhalten zu haben, einschließlich aller OEM (Original -Ausrüstungshersteller), Computerhersteller, CSP (Cloud -Dienstleister), GPU -Cloud, Sovereign Cloud und Telekommunikationsunternehmen.
Wir freuen uns sehr, dass Blackwells Erfolg, die weit verbreitete Akzeptanz und die Begeisterung der Branche für sie beispiellose Ebenen erreicht haben, und wir möchten Ihnen unsere aufrichtige Dankbarkeit aussprechen.Unser Tempo wird jedoch nicht aufhören.In dieser sich schnell entwickelnden Ära werden wir weiterhin hart daran arbeiten, die Produktleistung zu verbessern, die Kosten für Schulungen und Argumente zu senken, während wir die Fähigkeiten der künstlichen Intelligenz kontinuierlich erweitern, damit jedes Unternehmen davon profitieren kann.Wir sind fest davon überzeugt, dass die Kosten mit der Verbesserung der Leistung weiter gesenkt werden.Die Hopper -Plattform ist zweifellos der erfolgreichste Rechenzentrumsprozessor in der Geschichte.
9.Blackwell Ultra wird nächstes Jahr veröffentlicht und die Plattform der nächsten Generation heißt Rubin
Dies ist in der Tat eine schockierende Erfolgsgeschichte.Wie Sie sehen können, ist die Geburt der Blackwell -Plattform keine einzige Komponente, sondern ein vollständiges System, das mehrere Elemente wie CPU, GPU, NVLink, Nick (bestimmte technische Komponenten) und NVLink -Switches integriert.Wir sind bestrebt, die gesamte GPUs durch jede Generation mit großen, ultrahochgeschwindigen Schalter fest zu verbinden, um eine riesige und effiziente Computerdomäne zu bilden.
Wir integrieren die gesamte Plattform in unsere KI -Fabrik, aber kritischer, aber wir bieten diese Plattform für Kunden auf der ganzen Welt in modularer Form.Die ursprüngliche Absicht davon ist, dass wir erwarten, dass jeder Partner eine einzigartige und innovative Konfiguration erstellt, die auf seinen eigenen Bedürfnissen basiert, um sich an verschiedene Arten von Rechenzentren, verschiedenen Kundengruppen und unterschiedlichen Anwendungsszenarien anzupassen.Von Edge Computing bis zur Telekommunikation werden alle Arten von Innovationen möglich, solange das System offen bleibt.
Damit Sie frei innovieren können, haben wir eine integrierte Plattform entworfen, die Ihnen jedoch gleichzeitig in der Zersetzung zur Verfügung gestellt werden, sodass Sie modulare Systeme problemlos erstellen können.Jetzt wurde die Blackwell -Plattform vollständig gestartet.
Nvidia hält sich immer an den jährlichen Update -Rhythmus.Unsere Kernphilosophie ist sehr klar: 1) Lösungen erstellen, die die gesamte Rechenzentrumsskala abdecken; Extrem, ob es sich um die Prozesstechnologie, die Verpackungstechnologie, die Speichertechnologie oder die optische Technologie von TSMC handelt, verfolgen wir alle die ultimative Leistung.
Nachdem wir die ultimative Herausforderung der Hardware abgeschlossen haben, werden wir unser Bestes tun, um sicherzustellen, dass alle Software auf dieser kompletten Plattform reibungslos ausgeführt werden.In der Computertechnologie ist Software -Trägheit von entscheidender Bedeutung.Wenn unsere Computerplattform rückwärts kompatibel ist und die Architektur perfekt mit der vorhandenen Software kompatibel ist, wird die Marktgeschwindigkeit auf dem Markt erheblich verbessert.Als die Blackwell -Plattform gestartet wurde, konnten wir daher die gebaute Software -Ökosystemstiftung voll ausnutzen, um eine erstaunliche Geschwindigkeit des Marktes zu erreichen.Nächstes Jahr werden wir das Blackwell Ultra begrüßen.
Genau wie in der H100- und H200 -Serie, die wir auf den Markt gebracht haben, wird auch der Blackwell Ultra den Wahnsinn einer neuen Produktgeneration leiten und beispiellose innovative Erfahrungen bringen.Gleichzeitig werden wir weiterhin die Grenzen der Technologie herausfordern und den Spektrum-Switch der nächsten Generation starten, was der erste Versuch in der Branche ist.Dieser große Durchbruch wurde erfolgreich erreicht, obwohl ich immer noch ein wenig zögerlich bin, diese Entscheidung öffentlich zu machen.
Innerhalb von NVIDIA werden wir es gewohnt, Codenamen zu verwenden und eine gewisse Vertraulichkeit zu verwalten.Oft kennen selbst die meisten Mitarbeiter im Unternehmen diese Geheimnisse nicht sehr gut.Unsere Plattform der nächsten Generation wurde jedoch Rubin genannt.Ich werde hier nicht auf Details zu Rubin eingehen.Ich kenne die Neugier aller, aber bitte erlauben Sie mir, etwas Rätsel zu behalten.Möglicherweise sind Sie bestrebt, Fotos sorgfältig zu machen oder diese kleinen Charaktere sorgfältig zu studieren.
Wir haben nicht nur die Rubin -Plattform, sondern werden auch die Rubin Ultra -Plattform in einem Jahr starten.Alle hier gezeigten Chips befinden sich in vollständiger Entwicklungsphase und stellen sicher, dass jedes Detail sorgfältig poliert wird.Unser Update -Tempo ist immer noch einmal im Jahr und verfolgt immer die ultimative Technologie und sorgt dafür, dass alle Produkte eine 100% ige architektonische Kompatibilität beibehalten.

Wenn wir auf die letzten 12 Jahre zurückblicken, sahen wir ab dem Moment, in dem Imagnet geboren wurde, die Zukunft des Computerfeldes voraus, die sich mit Erdschütteln veränderten.All dies ist Wirklichkeit geworden, was mit unserer ursprünglichen Idee zusammenfällt.Von GeForce vor 2012 bis heute hat das Unternehmen eine enorme Transformation erfahren.Hier möchte ich allen meinen Partnern aufrichtig für ihre Unterstützung und ihr Unternehmen danken.
10.Die Ära der Roboter ist angekommen
Dies ist die Blackwell -Plattform von Nvidia.
Physische künstliche Intelligenz führt eine neue Welle im Bereich der künstlichen Intelligenz.Zu diesem Zweck muss physische künstliche Intelligenz nicht nur ein genaues Weltmodell aufbauen, um zu verstehen, wie die Welt um sie herum interpretiert und wahrgenommen werden kann, sondern auch über hervorragende kognitive Fähigkeiten verfügen, um unsere Bedürfnisse tief zu verstehen und Aufgaben effizient auszuführen.
Mit Blick auf die Zukunft wird die Robotik kein außer Reichweite sein, sondern zunehmend in unser tägliches Leben integriert.Wenn sie über Robotik sprechen, denken die Menschen oft an humanoide Roboter, aber tatsächlich sind ihre Anwendungen viel mehr als das.Die Mechanisierung wird zur Norm, die Fabriken werden die Automatisierung vollständig erkennen und Roboter werden zusammenarbeiten, um eine Reihe von mechanisierten Produkten zu erstellen.Die Wechselwirkung zwischen ihnen wird näher sein und eine stark automatisierte Produktionsumgebung zusammen schaffen.
Um dies zu erreichen, müssen wir eine Reihe von technischen Herausforderungen bewältigen.Als nächstes werde ich diese hochmodernen Technologien über Video präsentieren.
Dies ist nicht nur eine Vision für die Zukunft, sondern wird allmählich Wirklichkeit.
Wir werden den Markt auf verschiedene Weise dienen.Erstens sind wir verpflichtet, Plattformen für verschiedene Arten von Robotersystemen zu erstellen: spezielle Plattformen für Roboterfabriken und Lagerhäuser, Roboterplattformen für Objektmanipulationen, mobile Roboterplattformen und humanoide Roboterplattformen.Wie viele unserer anderen Unternehmen stützen sich diese Roboterplattformen auf Computerbeschleunigungsbibliotheken und vorgeborene Modelle.
Wir verwenden Computerbeschleunigungsbibliotheken, vorgeschriebene Modelle und führen umfassende Tests, Schulungen und Integration in Omniverse durch.Wie das Video zeigt, lernen Roboter, wie man sich besser an die reale Welt anpasst.Natürlich ist das Ökosystem von Roboterlagern äußerst komplex und erfordert, dass viele Unternehmen, Werkzeuge und Technologien gemeinsam moderne Lagerhäuser aufbauen.Heute bewegen sich die Lagerhäuser allmählich in Richtung der vollen Mechanisierung und werden eines Tages vollständig automatisiert.
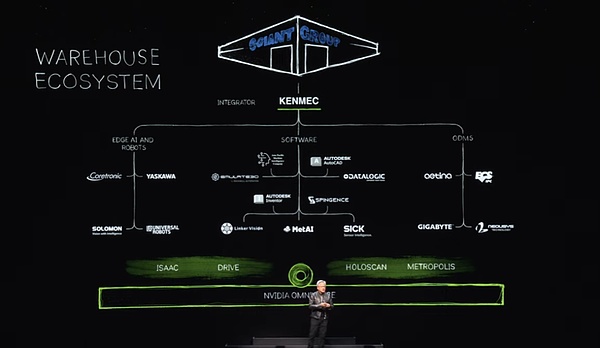
In einem solchen Ökosystem bieten wir SDK- und API -Schnittstellen für die Softwareindustrie, die Unternehmen für künstliche Intelligenz und Unternehmen und entwerfen dedizierte Systeme für SPS- und Robotersysteme, um die Bedürfnisse bestimmter Bereiche wie dem Verteidigungsministerium zu erfüllen.Diese Systeme werden durch Integratoren integriert, um letztendlich effiziente und intelligente Lagerhäuser für Kunden zu schaffen.Zum Beispiel baut Ken Mac ein Roboterlager für die riesige Riesengruppe.
Konzentrieren wir uns als nächstes auf das Fabrikfeld.Das Ökosystem der Fabrik ist sehr unterschiedlich.Nehmen wir Foxconn als Beispiel, sie bauen einige der fortschrittlichsten Fabriken der Welt auf.Die Ökosysteme dieser Fabriken behandeln auch Edge -Computer, Roboter -Software, zum Entwerfen von Werkslayouts, zur Optimierung von Workflows, Programmierrobotern und SPS -Computern, die zur Koordinierung digitaler Fabriken und Fabriken für künstliche Intelligenz verwendet werden.Wir bieten auch eine SDK -Schnittstelle für jeden Link in diesen Ökosystemen.
Solche Veränderungen finden weltweit statt.Foxconn und Delta bauen digitale Zwillinge für ihre Fabriken, um eine perfekte Mischung aus Realität und Digital zu erreichen, und Omniversum spielt eine entscheidende Rolle.Es ist auch erwähnenswert, dass Pegatron und Wistron auch den Trend verfolgen und digitale Zwillingseinrichtungen für ihre jeweiligen Roboterfabriken errichten.
Das ist wirklich aufregend.Bitte genießen Sie als nächstes ein wundervolles Video von Foxconns neuer Fabrik.
Die Roboterfabrik besteht aus drei Hauptcomputersystemen, die KI -Modelle auf der NVIDIA -AI -Plattform trainieren, und wir stellen sicher, dass der Roboter effizient auf dem lokalen System läuft, um die Fabrikprozesse zu orchestrieren.Gleichzeitig verwenden wir Omniverse, eine Simulationskollaborationsplattform, um alle Werkselemente einschließlich Roboterarme und AMR (autonomer mobiler Roboter) zu simulieren.Es ist erwähnenswert, dass diese Simulationssysteme den gleichen virtuellen Raum haben, um eine nahtlose Interaktion und Zusammenarbeit zu erreichen.
Wenn die Roboterarme und AMR in diesen gemeinsamen virtuellen Raum eintreten, können sie eine reale Fabrikumgebung im Omniversum simulieren, um eine angemessene Überprüfung und Optimierung vor der tatsächlichen Bereitstellung zu gewährleisten.
Um die Integrations- und Anwendungsreichweite von Lösungen weiter zu verbessern, bieten wir drei Hochleistungscomputer an, die mit Beschleunigungsschichten und vorgebildeten KI-Modellen ausgestattet sind.Darüber hinaus haben wir Nvidia Manipulator und Omniverse erfolgreich mit der industriellen Automatisierungssoftware und -Systeme von Siemens kombiniert.Diese Zusammenarbeit ermöglicht es Siemens, effizientere Roboterbetrieb und Automatisierung in Fabriken auf der ganzen Welt zu ermöglichen.
Neben Siemens haben wir auch kooperative Beziehungen zu vielen bekannten Unternehmen aufgebaut.Zum Beispiel hat Symantec Pick AI den Nvidia Isaac Manipulator integriert, während die somatische Pick AI Roboter von bekannten Marken wie ABB, Kuka und Yaskawa Motoman erfolgreich geführt und betrieben hat.
Die Ära der Robotik und der physischen künstlichen Intelligenz ist gekommen und sie werden überall weit verbreitet.Mit Blick auf die Zukunft werden Roboter in Fabriken zum Mainstream und sie werden alle Produkte herstellen, von denen zwei besonders auffällig sind.Erstens spielt Nvidia mit seinem umfassenden Technologiestapel autonome Autos oder Autos mit hoher Autonomie.Nächstes Jahr planen wir, uns dem Mercedes-Benz-Team zusammenzuschließen und dann 2026 mit dem Jaguar Land Rover (JLR) -Team zusammenzuarbeiten.Wir bieten einen kompletten Lösungsstapel an, aber Kunden können je nach ihren Bedürfnissen eine beliebige Teile oder Hierarchie auswählen, da der gesamte Treiberstapel offen und flexibel ist.
Als nächstes ist ein weiteres Produkt, das bei hohen Renditen aus Roboterfabriken hergestellt werden kann, humanoide Roboter.In den letzten Jahren wurden große Durchbrüche in kognitiven Fähigkeiten und Fähigkeiten des Weltverständnisses erzielt, und die Entwicklungsaussichten auf diesem Gebiet sind aufregend.Ich freue mich besonders über humanoide Roboter, weil sie sich am wahrscheinlichsten an die Welt anpassen, die wir für Menschen aufgebaut haben.
Das Training humanoischer Roboter erfordert viele Daten im Vergleich zu anderen Arten von Robotern.Da wir ähnliche Körperformen haben, ist die große Menge an Trainingsdaten, die durch Demonstrations- und Videofunktionen bereitgestellt werden, von großem Wert.Daher erwarten wir erhebliche Fortschritte in diesem Bereich.

Lassen Sie uns nun einige besondere Roboterfreunde begrüßen.Die Ära der Roboter ist angekommen, und dies ist die nächste Welle künstlicher Intelligenz.Es gibt eine Vielzahl von Computern in Taiwan, darunter herkömmliche Modelle, die mit Tastaturen, kleinen, leichten und tragbaren mobilen Geräten sowie professioneller Ausrüstung ausgestattet sind, die leistungsstarke Rechenleistung für Cloud -Rechenzentren bietet.Aber ich freue mich darauf, wir werden einen aufregenderen Moment miterleben – Computer erstellen, die herumlaufen und rollen können, nämlich intelligente Roboter.
Diese intelligenten Roboter haben auffällige technische Ähnlichkeiten mit Computern, wie wir sie kennen, und alle basieren auf fortschrittlichen Hardware- und Softwaretechnologien.Wir haben also Grund zu der Annahme, dass dies eine wirklich außergewöhnliche Reise sein wird!







