
المؤلف: Josh O’Sullivan ، Cointelegraph ؛
أقر المؤسس المشارك لـ Ethereum Vitalik Buterin الجديدToken for Image Tokenizer (TITOK) طريقة ضغط لتطبيقات blockchain المحتملة.
لا تخلط بين منصة التواصل الاجتماعي Tiktok ، فإن طريقة ضغط Titok الجديدة تقلل بشكل كبير من حجم الصورة ، مما يجعلها أكثر ملاءمة للتخزين على blockchain.
أبرز بورين إمكانات blockchain الخاصة بـ Titok على منصة التواصل الاجتماعي اللامركزية Farcaster ، قائلاً “320 بت هي أساسًا قيمة التجزئة. صغيرة بما يكفي للحصول على كل مستخدم على السلسلة”.
يمكن أن يكون لهذا التطوير تأثير كبير على تخزين الصور الرقمية لصور الملفات الشخصية (PFPs) ورموز غير قابلة للانتهاك (NFTS).
Titok ضغط الصورة
تم تطوير Titok بواسطة Bytedance والباحثين من جامعة ميونيخ التقنية.يمكن ضغط الصورة إلى 32 كتل بيانات صغيرة (بت) دون فقدان الجودة.
وفقًا لورقة الأبحاث التابعة لـ Titok ، يسمح ضغط الصورة المتقدمة للذكاء الاصطناعي (AI) لضغط صور 256×256 بكسل إلى “32 علامة منفصلة”.
Titok هو إطار رمز للصور أحادي البعد (1D) الذي “يكسر قيود الشبكة الموجودة في نهج الرمز المميز ثنائي الأبعاد” لإنتاج صورة أكثر مرونة وضغوطًا.
“لذلك يمكن أن يسرع بشكل كبير من عملية أخذ العينات (على سبيل المثال ، 410 مرة أسرع من DIT-XL/2) مع تحقيق جودة الجيل التنافسي.”

تُظهر ورقة الأبحاث Tiktok مقارنات بأحجام ضغط الصور.المصدر: Tiktok
صور التعلم الآلي
يستخدم Titok التعلم الآلي والذكاء الاصطناعي المتقدم لتحويل الصور إلى تمثيلات رمزية باستخدام النماذج القائمة على المحولات.
تستخدم هذه الطريقة التكرار في المنطقة ، مما يعني أنه يحدد ويستخدم معلومات زائدة في مناطق مختلفة من الصورة لتقليل حجم البيانات الكلي للمنتج النهائي.
“التطورات الحديثة في النماذج التوليدية تبرز الدور الهام لعلامات الصور في التوليف الفعال للصور عالية الدقة.”
وفقًا لورقة البحث ، يمكن أن ينتج عن “تمثيل كامن مضغوط” من Titok “تمثيلًا أكثر كفاءة وأكثر فاعلية من التكنولوجيا التقليدية”.
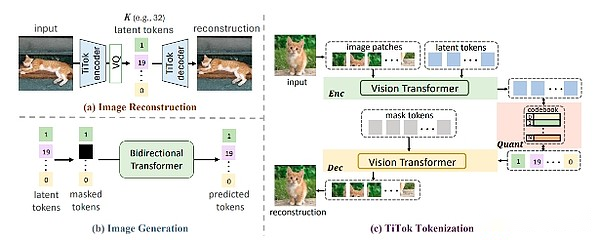
إعادة بناء الصور (أ) والجيل (ب) باستخدام إطار Titok (C).المصدر: تيتوك
تيخوك ، وليس تيخوك
على الرغم من الأسماء المماثلة ، لم يتم التعرف على منصة التواصل الاجتماعي Tiktok من قبل بورين.
أبرز المؤسسون المشاركون في Ethereum إمكانات Titok blockchain ، مما يضيف مصداقية إلى هذا النهج الجديد الذي يعمل به الذكاء الاصطناعي لضغط الصور.
“على عكس نماذج 2D VQ الحالية التي تعامل مع المساحة الكامنة للصورة مثل شبكة ثنائية الأبعاد ، فإننا نقدم صيغة أكثر إحكاما لتمييز الصور كسلسلة كامنة 1D.”
يمكن أن “النهج الجديد المقترح” يمكن أن يمثل الصور ذات العلامات الأقل من 8 إلى 64 مرة من “علامات ثنائية الأبعاد” ، ويأمل الفريق أن توفر هذه الدراسة مصدر إلهام لـ “تمثيل الصور الأكثر فعالية”.







