
مقدمة: تطوير AI+Web3
في السنوات القليلة الماضية ، اجتذب التطور السريع للذكاء الاصطناعي (AI) و Web3 تقنيات اهتمامًا واسع النطاق في جميع أنحاء العالم.كتقنية تحاكي وتقلد الذكاء البشري ، حققت الذكاء الاصطناعى اختراقات كبيرة في مجالات التعرف على الوجه ، ومعالجة اللغة الطبيعية ، والتعلم الآلي ، إلخ.لقد جلب التطور السريع لتكنولوجيا الذكاء الاصطناعي تغييرات وابتكارات هائلة لجميع مناحي الحياة.
بلغ حجم السوق لصناعة الذكاء الاصطناعى 200 مليار دولار أمريكي في عام 2023. لقد ظهر عمالقة الصناعة واللاعبين البارزين مثل Openai و Farky.ai و Midjourney مثل الفطر بعد هطول الأمطار ، مما أدى إلى جنون الذكاء الاصطناعي.
في الوقت نفسه ، يقوم Web3 ، كنموذج شبكة ناشئ ، بتغيير فهمنا واستخدامنا للإنترنت تدريجياً.استنادًا إلى تقنية blockchain اللامركزية ، يدرك Web3 مشاركة البيانات وإمكانية التحكم فيها ، واستقلالية المستخدم وآليات الثقة من خلال وظائف مثل العقود الذكية ، والتخزين الموزع والتوثيق اللامركزي.المفهوم الأساسي لـ Web3 هو تحرير البيانات من المؤسسات الموثوقة المركزية ومنح المستخدمين الحق في التحكم في البيانات ومشاركة قيمة البيانات.
في الوقت الحالي ، وصلت القيمة السوقية لصناعة Web3 إلى 25 تريليون انضم إلى صناعة Web3.
من السهل أن تجد أن الجمع بين الذكاء الاصطناعي و Web3 هو مجال يهم كل من البناة و VC في الشرق والغرب للغاية.
ستركز هذه المقالة على حالة التطوير الحالية لـ AI+Web3 واستكشاف القيمة المحتملة وتأثير هذا التكامل.سنقدم أولاً المفاهيم والميزات الأساسية لـ AI و Web3 ، ثم استكشاف علاقتهما.سنقوم بعد ذلك بتحليل الوضع الحالي لمشاريع AI+Web3 ومناقشة التعمق في القيود والتحديات التي يواجهونها.من خلال مثل هذا البحث ، نتوقع توفير مرجع ورؤى قيمة للمستثمرين والممارسين في الصناعات ذات الصلة.
كيف تتفاعل الذكاء الاصطناعي مع Web3
إن تطوير الذكاء الاصطناعي و Web3 يشبه كلا الجانبين من التوازن.فما نوع الشرر الذي يمكن أن يصطدم به AI و Web3؟بعد ذلك ، سنقوم بتحليل الصعوبات ومساحة التحسين التي تواجهها صناعات AI و Web3 ، ثم نناقش كيف يمكن لبعضنا البعض المساعدة في حل هذه الصعوبات.
-
معضلة ومساحة تحسين محتملة لصناعة الذكاء الاصطناعي
-
معضلة ومساحة تحسين محتملة لصناعة Web3
2.1 معضلة تواجهها صناعة الذكاء الاصطناعى
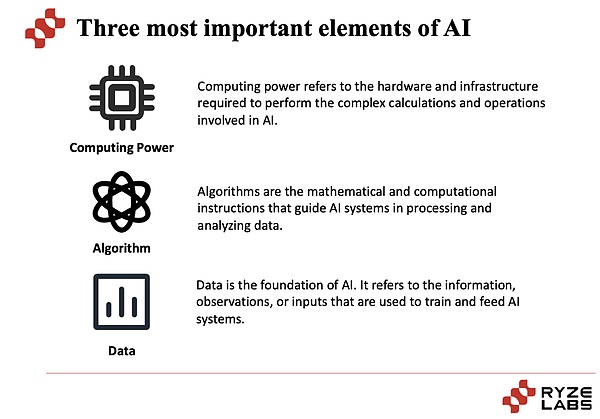
إذا كنت ترغب في استكشاف الصعوبات التي تواجهها صناعة الذكاء الاصطناعي ، فلننظر أولاً إلى جوهر صناعة الذكاء الاصطناعي.لا ينفصل جوهر صناعة الذكاء الاصطناعي عن ثلاثة عناصر: قوة الحوسبة والخوارزميات والبيانات.
-
بادئ ذي بدء ، طاقة الحوسبة: تشير قوة الحوسبة إلى القدرة على إجراء حسابات واسعة النطاق والمعالجة.غالبًا ما تتطلب مهام الذكاء الاصطناعي معالجة كميات كبيرة من البيانات وإجراء عمليات حسابية معقدة ، مثل تدريب نماذج الشبكة العصبية العميقة.يمكن للطاقة الحاسوبية عالية الكثافة تسريع عمليات التدريب والاستدلال النموذجية وتحسين أداء وكفاءة أنظمة الذكاء الاصطناعى.في السنوات الأخيرة ، مع تطوير تقنيات الأجهزة ، مثل معالجات الرسومات (GPUS) ورقائق الذكاء الاصطناعى المخصصة (مثل TPUS) ، لعب تحسين قوة الحوسبة دورًا مهمًا في تعزيز تطوير صناعة الذكاء الاصطناعي.احتلت Nvidia ، التي ارتفعت الأسهم في السنوات الأخيرة ، حصة كبيرة في السوق كمزود GPU وحقق أرباحًا عالية.
-
ما هي الخوارزمية: الخوارزميات هي المكونات الأساسية لأنظمة الذكاء الاصطناعي ، وهي طرق رياضية وإحصائية تستخدم لحل المشكلات وتنفيذ المهام.يمكن تقسيم خوارزميات AI إلى خوارزميات التعلم الآلي التقليدي وخوارزميات التعلم العميق ، من بينها خوارزميات التعلم العميق حققت اختراقات كبيرة في السنوات الأخيرة.يعد اختيار الخوارزميات وتصميمها أمرًا بالغ الأهمية لأداء وفعالية أنظمة الذكاء الاصطناعي.يمكن أن تحسن الخوارزميات المحسنة والمبتكرة بشكل مستمر من دقة أنظمة الذكاء الاصطناعي والمتانة والتعميم.سيكون للخوارزميات المختلفة تأثيرات مختلفة ، لذا فإن تحسين الخوارزمية أمر بالغ الأهمية أيضًا لتأثير إكمال المهام.
-
لماذا البيانات مهمة: المهمة الأساسية لأنظمة الذكاء الاصطناعي هي استخراج الأنماط والقواعد في البيانات من خلال التعلم والتدريب.
البيانات هي الأساس للتدريب وتحسين النماذج.يمكن أن توفر مجموعات البيانات الغنية معلومات أكثر شمولاً ومتنوعة ، مما يسمح للمواد المعممة بشكل أفضل بعدم مراسلي البيانات ، مما يساعد أنظمة الذكاء الاصطناعى على فهم مشاكل في العالم الحقيقي بشكل أفضل.
بعد فهم العناصر الأساسية الثلاثة من الذكاء الاصطناعي ، دعنا نلقي نظرة على الصعوبات والتحديات التي تواجهها الذكاء الاصطناعي في هذه الجوانب الثلاثة. التفكير ، وخاصة من حيث نماذج التعلم العميق.ومع ذلك ، فإن الحصول على وإدارة قوة الحوسبة على نطاق واسع يمثل تحديًا مكلفًا ومعقدًا.التكلفة واستهلاك الطاقة وصيانة معدات الحوسبة عالية الأداء كلها مشكلات.خاصة بالنسبة للشركات الناشئة والمطورين الفرديين ، قد يكون الحصول على ما يكفي من قوة الحوسبة أمرًا صعبًا.
من حيث الخوارزميات ، على الرغم من أن خوارزميات التعلم العميق حققت نجاحًا كبيرًا في العديد من المجالات ، لا تزال هناك بعض المعضلات والتحديات.على سبيل المثال ، يتطلب تدريب الشبكات العصبية العميقة كمية كبيرة من البيانات وموارد الحوسبة ، وبالنسبة لبعض المهام ، قد يكون النموذج التوضيحي والقابل للتفسير غير كافٍ.بالإضافة إلى ذلك ، فإن قدرة الخوارزمية والتعميم والتعميم هي أيضًا مشكلة مهمة ، وقد يكون أداء النموذج على البيانات غير المرئية غير مستقر.من بين العديد من الخوارزميات ، كيفية العثور على أفضل خوارزمية لتوفير أفضل الخدمات هي عملية تتطلب استكشافًا مستمرًا.
فيما يتعلق بالبيانات ، فإن البيانات هي القوة الدافعة لـ AI ، ولكن الحصول على بيانات عالية الجودة ومتنوعة لا يزال يمثل تحديًا.قد يكون من الصعب الحصول على البيانات في بعض المناطق ، مثل البيانات الصحية الحساسة في المجال الطبي.بالإضافة إلى ذلك ، فإن جودة البيانات ودقةها ووضعها هي أيضًا مشاكل ، ويمكن أن تؤدي البيانات غير المكتملة أو المتحيزة إلى سلوك خاطئ أو تحيز في النموذج.في الوقت نفسه ، تعد حماية خصوصية البيانات والأمان أيضًا اعتبارًا مهمًا.
بالإضافة إلى ذلك ، هناك مشاكل مثل التفسير والشفافية ، وخصائص الصندوق الأسود لنموذج الذكاء الاصطناعي هي مصدر قلق عام.بالنسبة لبعض التطبيقات ، مثل التمويل والرعاية الصحية والعدالة ، يجب أن تكون عملية صنع القرار للنموذج قابلة للتفسير ويمكن تتبعها ، في حين أن نماذج التعلم العميق الحالية تفتقر إلى الشفافية.لا يزال شرح عملية صنع القرار للنموذج وتوفير تفسيرات جديرة بالثقة تحديًا.
بالإضافة إلى ذلك ، فإن نموذج أعمال العديد من ريادة الأعمال في مشروع الذكاء الاصطناعي ليس واضحًا للغاية ، مما يجعل العديد من رواد الأعمال من الذكاء الاصطناعي يشعرون بالارتباك.
2.2 معضلة تواجهها صناعة Web3
في صناعة Web3 ، يوجد حاليًا العديد من الصعوبات في الجوانب المختلفة التي يجب حلها ، سواء كان تحليل البيانات لـ Web3 ، أو تجربة المستخدم الضعيفة لمنتجات Web3 ، أو مشاكل ثغرات رمز العقد الذكي وهجمات القراصنة ، والكثير من غرفة للتحسين.كأداة لتحسين الإنتاجية ، لدى الذكاء الاصطناعى أيضًا مساحة كبيرة للتنمية في هذه الجوانب.
بادئ ذي بدء ، فإن تحسين قدرات تحليل البيانات وإمكانيات التنبؤ: أدى تطبيق تكنولوجيا الذكاء الاصطناعي في تحليل البيانات والتنبؤ إلى تأثير كبير على صناعة Web3.من خلال التحليل الذكي واستخراج خوارزميات الذكاء الاصطناعى ، يمكن لمنصة Web3 استخراج معلومات قيمة من البيانات الضخمة واتخاذ تنبؤات وقرارات أكثر دقة.هذا له أهمية كبيرة لتقييم المخاطر والتنبؤ في السوق وإدارة الأصول في مجال التمويل اللامركزي (DEFI).
بالإضافة إلى ذلك ، يمكن أيضًا تحقيق التحسينات في تجربة المستخدم والخدمات الشخصية: يمكّن تطبيق تقنية الذكاء الاصطناعى منصة Web3 من توفير تجربة مستخدم أفضل وخدمات شخصية.من خلال تحليل ونمذجة بيانات المستخدم ، يمكن لمنصة Web3 تزويد المستخدمين بتوصيات مخصصة وخدمات مخصصة وخبرة تفاعلية ذكية.يساعد ذلك في تحسين مشاركة المستخدم ورضاها ويعزز تطوير النظام البيئي لـ Web3.
فيما يتعلق بالأمان وحماية الخصوصية ، فإن تطبيق الذكاء الاصطناعى له أيضًا تأثير عميق على صناعة Web3.يمكن استخدام تقنية الذكاء الاصطناعي لاكتشاف الهجمات الإلكترونية والدفاع عنها ، وتحديد السلوكيات غير الطبيعية ، وتوفير أمان أقوى.في الوقت نفسه ، يمكن أيضًا استخدام الذكاء الاصطناعي لحماية خصوصية البيانات ، ومن خلال تقنيات مثل تشفير البيانات وحوسبة الخصوصية ، يمكنه حماية المعلومات الشخصية للمستخدمين على نظام Web3.فيما يتعلق بتدقيق العقد الذكي ، نظرًا لإمكانيات نقاط الضعف والمخاطر الأمنية في كتابة العقود الذكية ومراجعة التدقيق ، يمكن استخدام تقنية الذكاء الاصطناعي لأتمتة عمليات تدقيق العقود واكتشاف الضعف لتحسين أمان وموثوقية العقود.
يمكن ملاحظة أن الذكاء الاصطناعي يمكنه المشاركة وتقديم المساعدة في العديد من الجوانب في الصعوبات ومساحة التحسين المحتملة التي تواجه صناعة Web3.
تحليل الحالة الحالية لمشاريع AI+Web3
تبدأ المشاريع التي تجمع بين الذكاء الاصطناعي و Web3 بشكل أساسي من جانبين رئيسيين ، وتستخدم تقنية blockchain لتحسين أداء مشاريع الذكاء الاصطناعى ، واستخدام تقنية الذكاء الاصطناعي لخدمة تحسين مشاريع Web3.
ظهر عدد كبير من المشاريع لاستكشاف هذا المسار ، بما في ذلك المشاريع المختلفة مثل IO.NET و Gensyn و Ritual ، وما إلى ذلك ، ستستخدم هذه المقالة AI لمساعدة Web3 و Web3 لمساعدة المنافسات الفرعية المختلفة الوضع الحالي والتنمية.
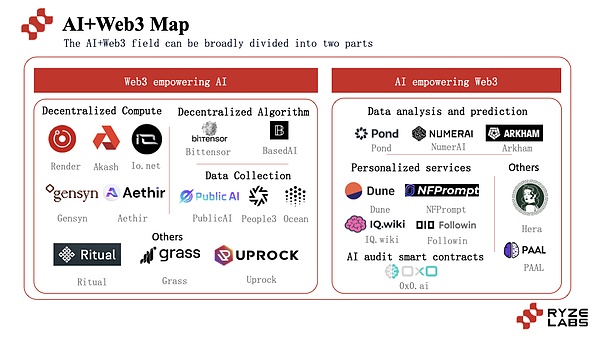
3.1 Web3 يساعد الذكاء الاصطناعي
3.1.1 قوة الحوسبة اللامركزية
منذ أن أطلقت Openai Chatgpt في نهاية عام 2022 ، أثارت موجة من الذكاء الاصطناعي.بعد ذلك ، بذل Chatgpt جهودًا كبيرة للغاية ، حيث وصل عدد المستخدمين النشطين الشهري إلى 100 مليون في غضون شهرين.مع ظهور Chatgpt ، انفجر حقل الذكاء الاصطناعى بسرعة من مسار متخصص إلى صناعة مراقبة للغاية.
وفقًا لتقرير Trendforce ، يتطلب ChatGPT 30،000 وحدة معالجة الرسومات NVIDIA A100 لتشغيلها ، وسيتطلب GPT-5 المزيد من أوامر حسابات الحجم في المستقبل.وقد فتح هذا أيضًا سباق التسلح بين مختلف شركات الذكاء الاصطناعي.
قبل ظهور الذكاء الاصطناعي ، ركزت Nvidia ، أكبر مزود ل GPU ، عملائها على ثلاث خدمات سحابة رئيسية: AWS و Azure و GCP.مع ظهور الذكاء الاصطناعي ، ظهر عدد كبير من المشترين الجدد ، بما في ذلك Big Companies Meta و Oracle ، ومنصات البيانات الأخرى والشركات الناشئة من الذكاء الاصطناعي ، جميعهم ينضم إلى الحرب لتدريب نماذج AI.زادت شركات التكنولوجيا الكبيرة مثل Meta و Tesla من عمليات شراء نماذج الذكاء الاصطناعى المخصصة والأبحاث الداخلية.كما اشترت شركات النماذج الأساسية مثل الأنثروبور ومنصات البيانات مثل Snowflake و Databricks المزيد من وحدات معالجة الرسومات لمساعدة العملاء على تقديم خدمات الذكاء الاصطناعي.
كما ذكرها SEMI Analysis في العام الماضي ، “GPU Rich و GPU Poor” ، يوجد عدد قليل من الشركات في GPU A100/H100 ، ويمكن لأعضاء الفريق استخدام 100 إلى 1000 وحدة معالجة الرسومات للمشاريع.هذه الشركات هي إما مزودي سحابة أو LLMs المصممة ذاتيا ، بما في ذلك Openai و Google و Meta و Hone-Inthropection و Tesla و Oracle ، Mistral ، إلخ.
ومع ذلك ، فإن معظم الشركات فقيرة في GPU ولا يمكن أن تكافح إلا مع عدد أقل بكثير من وحدات معالجة الرسومات ، حيث تقضي الكثير من الوقت والطاقة على الأشياء التي يصعب دفعها لتطوير النظام الإيكولوجي.وهذا الوضع لا يقتصر على الشركات الناشئة.بعض شركات الذكاء الاصطناعى الأكثر شهرة – وجه المعانقة ، Databricks (Mosaicml) ، معًا وحتى ندفة الثلج لديها أقل من 20 ألف في عدد A100/H100.تتمتع هذه الشركات بمواهب فنية ذات مستوى عالمي ، ولكنها محدودة من خلال توفير وحدات معالجة الرسومات ، وهي في وضع غير مؤات مقارنة بالشركات الكبيرة في المنافسة في الذكاء الاصطناعي.
لا يقتصر هذا النقص على “GPU Poor”. مستلزمات GPU.
يمكن ملاحظة أنه مع التطور السريع لمنظمة العفو الدولية ، هناك عدم تطابق خطير بين جوانب الطلب والعرض في وحدات معالجة الرسومات ، ومشكلة نقص العرض وشيك.
من أجل حل هذه المشكلة ، بدأت بعض أطراف مشاريع Web3 في محاولة تقديم خدمات طاقة الحوسبة اللامركزية بناءً على الخصائص الفنية لـ Web3 ، بما في ذلك Akash ، Render ، Gensyn ، إلخ.ما هو شائع في هذا النوع من المشروع هو أن الرموز تستخدم لتحفيز المستخدمين لتوفير طاقة حوسبة GPU الخاملة ، وتصبح جانب التوريد من قوة الحوسبة لتزويد عملاء الذكاء الاصطناعى بقدرة الحوسبة.
يمكن تقسيم صورة جانب العرض بشكل أساسي إلى ثلاثة جوانب: مقدمي الخدمات السحابية ، عمال المناجم في العملة المشفرة ، والمؤسسات.
من بين مزودي الخدمات السحابية مزودي الخدمات السحابية السحابية (مثل AWS و Azure و GCP) ومقدمي خدمات GPU السحابية (مثل CoreWeave و Lambda و Crusoe ، إلخ) ، ويمكن للمستخدمين إعادة بيع قوة الحوسبة لمقدمي الخدمات السحابية الخاطئة لكسب الإيرادات .عمال مناجم التشفير أثناء تحول Ethereum من POW إلى POS ، أصبحت طاقة الحوسبة في GPU الخاملة جانبًا محتملًا مهمًا.بالإضافة إلى ذلك ، يمكن لشركات كبيرة مثل Tesla و Meta التي اشترت عددًا كبيرًا من وحدات معالجة الرسومات بسبب تخطيطها الاستراتيجي أيضًا استخدام طاقة الحوسبة في GPU الخاملة كجانب العرض.
حاليًا ، يتم تقسيم اللاعبين على المسار تقريبًا إلى فئتين: إحداهما هو استخدام قوة الحوسبة اللامركزية لمنطق الذكاء الاصطناعي ، والآخر هو استخدام قوة الحوسبة اللامركزية لتدريب الذكاء الاصطناعي.السابق مثل العرض (على الرغم من أنه يركز على التقديم ، ولكن يمكن استخدامه أيضًا كقوة حوسبة منظمة العفو الدولية) ، Akash ، Aethir ، إلخ. ، Gensyn ، الفرق الأكبر بين الاثنين هو الحوسبة.
دعنا نتحدث أولاً عن مشروع التفكير الذكري السابق. قوة.تم ذكر مقدمة وتحليل مثل هذه المشاريع في تقريرنا البحثي حول DePin قبل Ryze Labs.مرحبًا بك للتحقق من ذلك.
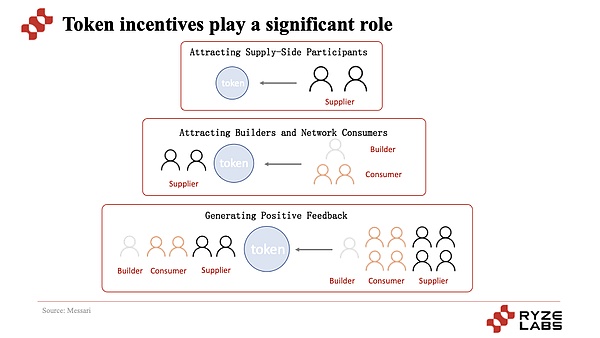
النقطة الأكثر أهمية هي أنه من خلال آلية الحوافز الرمزية ، يجذب المشروع أولاً الموردين ثم يجذب المستخدمين لاستخدامه ، وبالتالي تحقيق آلية التشغيل الباردة والتشغيل الأساسي للمشروع ، والتي يمكن أن توسع وتطور.بموجب هذه الدورة ، يحتوي جانب العرض على عائدات رمزية أكثر فأكثر ، ويظل جانب الطلب أرخص وأكثر فعالية من حيث التكلفة. تجذب الأسعار المزيد من المشاركين والمضاربين للمشاركة وتشكيل التقاط القيمة.
نوع آخر هو استخدام قوة الحوسبة اللامركزية لتدريب الذكاء الاصطناعى ، مثل Gensyn و IO.NET (يمكن أن يدعمها تدريب الذكاء الاصطناعى ومنطق الذكاء الاصطناعي).في الواقع ، لا يوجد فرق أساسي بين منطق تشغيل هذا النوع من المشروع ومشروع التفكير في الذكاء الاصطناعي.
من بينها ، IO.NET شبكة طاقة حوسبة لا مركزية ، مع أكثر من 500000 وحدة معالجة الرسومات ، وهي معلقة في مشاريع الطاقة الحوسبة اللامركزية. المشروع البيئي.

بالإضافة إلى ذلك ، يدرك Gensyn تدريب الذكاء الاصطناعي من خلال العقود الذكية التي يمكن أن تعزز تخصيص المهام والمكافآت للتعلم الآلي.كما هو موضح في الشكل أدناه ، يكلف عمل تدريب Gensyn في التعلم الآلي حوالي 0.4 دولار في الساعة ، وهو أقل بكثير من تكلفة AWS و GCP لأكثر من 2 دولار.
يتضمن نظام Gensyn أربعة مشاركين: مقدم ، منفذ ، Verifier و Whistleblower.
-
تم تقديمه بواسطة: المستخدم هو مستهلك المهمة ، ويوفر المهام التي يتم حسابها ، ودفع مهام تدريب الذكاء الاصطناعى
-
المنفذ: ينفذ المنفذ المهمة التي تم تدريبها بواسطة النموذج وإنشاء دليل على إكمال المهمة للتحقق من قبل التحقق.
-
Verifier: ربط عملية التدريب غير المحدود بالحساب الخطي الحتمي ، ومقارنة دليل المنفذ على العتبة المتوقعة.
-
المبلغين عن المخالفات: تحقق من عمل المدقق ، وطرح أسئلة للحصول على الربح عند اكتشافه.
يمكن ملاحظة أن Gensyn يأمل أن يصبح بروتوكول حوسبة فائقة النطاق وفعالة من حيث التكلفة لنماذج التعلم العميق العالمي.لكن بالنظر إلى هذا المسار ، لماذا تختار معظم المشاريع قوة الحوسبة اللامركزية لمنطق الذكاء الاصطناعي بدلاً من التدريب؟
نحن هنا نساعد أيضًا الأصدقاء الذين لا يفهمون تدريب الذكاء الاصطناعي والمنطق على تقديم الاختلافات بين الاثنين:
-
تدريب الذكاء الاصطناعي: إذا قارنا الذكاء الاصطناعي مع الطالب ، فإن التدريب يشبه توفير الذكاء الاصطناعي مع الكثير من المعرفة ، ويمكن أيضًا فهم الأمثلة على أنها بيانات نسميها غالبًا ، والذكاء الاصطناعي يتعلم من أمثلة المعرفة هذه.نظرًا لأن طبيعة التعلم تتطلب فهم وذاكرة كمية كبيرة من المعلومات ، فإن هذه العملية تتطلب الكثير من قوة الحوسبة والوقت.
-
المنطق منظمة العفو الدولية: إذن ما هو المنطق؟يمكن فهمه على أنه استخدام المعرفة التي تم تعلمها لحل المشكلات أو إجراء الامتحانات في مرحلة التفكير. .
يمكن ملاحظة أن متطلبات القدرة الحاسوبية للثاني مختلفين تمامًا.
بالإضافة إلى ذلك ، تأمل الطقوس في الجمع بين الشبكات الموزعة مع المبدعين النماذج للحفاظ على اللامركزية والأمن.يتيح منتجه الأول ، الإنترنت ، العقود الذكية على blockchain الوصول إلى نماذج الذكاء الاصطناعى خارج السلسلة ، مما يسمح لهذه العقود بالوصول إلى الذكاء الاصطناعي بطريقة تحافظ على التحقق واللامركزية والخصوصية.
منسق الإنترنت مسؤولاً عن إدارة سلوك العقد في الشبكة والاستجابة لطلبات الحوسبة الصادرة عن المستهلكين.عندما يستخدم المستخدم الإنترنت ، سيتم وضع الاستدلال والإثبات وغيره من الأعمال من السلسلة ، سيتم إرجاع نتائج الإخراج إلى المنسق ، وأخيراً تم نقلها إلى المستهلكين على السلسلة من خلال العقد.
بالإضافة إلى شبكات طاقة الحوسبة اللامركزية ، هناك أيضًا شبكات عرض النطاق الترددي اللامركزية مثل العشب لتحسين سرعة وكفاءة نقل البيانات.بشكل عام ، يوفر ظهور شبكات طاقة الحوسبة اللامركزية إمكانية جديدة لجانب إمدادات طاقة الحوسبة من الذكاء الاصطناعي ، مما دفع الذكاء الاصطناعي إلى المضي قدمًا في اتجاه آخر.
3.1.2 نموذج الخوارزمية اللامركزية
كما هو مذكور في الفصل 2 ، فإن العناصر الأساسية الثلاثة من الذكاء الاصطناعى هي حوسبة الطاقة والخوارزميات والبيانات.نظرًا لأن طاقة الحوسبة يمكن أن تشكل شبكة إمداد من خلال اللامركزية ، هل يمكن أن يكون للخوارزمية أفكار مماثلة لتشكيل شبكة إمداد نموذج الخوارزمية؟
قبل تحليل مشروع المسار ، دعنا نفهم أولاً أهمية نموذج الخوارزمية اللامركزية.
في جوهرها ، فإن شبكة الخوارزمية اللامركزية هي سوق خوارزمية منظمة العفو الدولية التي تربط العديد من نماذج الذكاء الاصطناعي. للإجابة على الأسئلة لتقديم إجابات.Chat-GPT هو نموذج منظمة العفو الدولية التي طورتها Openai ، والتي يمكنها فهم وإنتاج نصوص مشابهة للبشر.
ببساطة ، تشبه ChatGPT طالبًا يتمتع بقدرات قوية للمساعدة في حل أنواع مختلفة من المشكلات ، في حين أن شبكة الخوارزمية اللامركزية تشبه المدرسة مع العديد من الطلاب للمساعدة في حل المشكلات. المدارس التي يمكنها تجنيد الطلاب من جميع أنحاء العالم لديها إمكانات كبيرة.
حاليًا ، في مجال نماذج الخوارزمية اللامركزية ، هناك أيضًا بعض المشاريع في محاولاتها واستكشافها.
في Bittensor ، يساهم جانب العرض من النموذج الخوارزمي (أو عمال المناجم) في نماذج التعلم الآلي الخاصة بهم إلى الشبكة.يمكن لهذه النماذج تحليل البيانات وتوفير رؤى.سيحصل مقدمو النماذج على رمز العملة المشفرة Tao كمكافأة لمساهماتهم.
لضمان جودة الإجابات على الأسئلة ، يستخدم Bittensor آلية إجماع فريدة لضمان توافق الشبكة على أفضل الإجابات.يقدم عمال مناجم النماذج المتعددة إجابات عند الطلب.ثم يبدأ المدقق في الشبكة في العمل ، ويحدد أفضل إجابة ، ويرسلها إلى المستخدم.
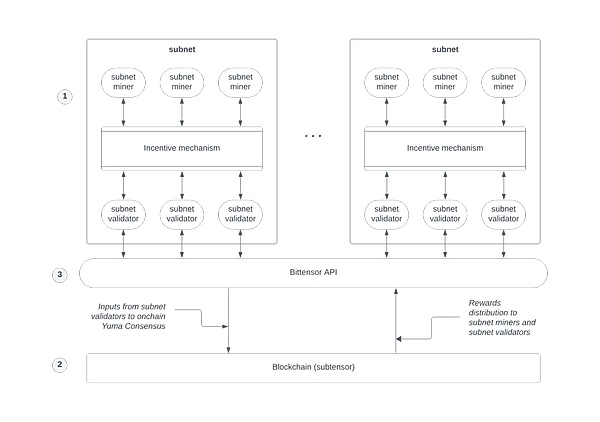
رمز Bittensor Tao يلعب بشكل أساسي دورين في العملية بأكملها. شبكة كاملة المهام.
نظرًا لأن Bittensor لا مركزية ، يمكن لأي شخص لديه إمكانية الوصول إلى الإنترنت الانضمام إلى الشبكة ، كمستخدم يطرح أسئلة وكعدلى يقدم إجابات.هذا يسمح لمزيد من الناس باستخدام الذكاء الاصطناعي القوي.
باختصار ، إن أخذ شبكات مثل Bittensor كمثال ، فإن المجال اللامركزي للنمذجة الخوارزمية لديه القدرة على خلق موقف أكثر انفتاحًا وشفافية حيث يمكن تدريب نماذج الذكاء الاصطناعي ومشاركتها واستخدامها بطريقة آمنة ولامركزية.بالإضافة إلى ذلك ، هناك شبكات طراز خوارزمية غير مركزية مثل Training There Things.
مع تطور منصات النموذج الخوارزمية اللامركزية ، ستمكّن الشركات الصغيرة من التنافس مع المؤسسات الكبيرة في استخدام أدوات AI العليا ، وبالتالي لها تأثير كبير على الصناعات المختلفة.
3.1.3 جمع البيانات اللامركزية
لتدريب نماذج الذكاء الاصطناعى ، يعد كمية كبيرة من إمدادات البيانات ضرورية.ومع ذلك ، لا تزال معظم شركات Web2 تأخذ بيانات المستخدمين لأنفسهم.لقد أصبح عقبة كبيرة أمام تطوير صناعة الذكاء الاصطناعي.
ومع ذلك ، من ناحية أخرى ، تبيع بعض منصات Web2 بيانات المستخدم لشركات الذكاء الاصطناعى دون مشاركة أي ربح للمستخدمين.على سبيل المثال ، ألقى Reddit صفقة بقيمة 60 مليون دولار مع Google للسماح لـ Google Train AI على مشاركاتها.وهذا يؤدي إلى حقوق جمع البيانات التي تشغلها أطراف رأس المال الكبيرة والبيانات الكبيرة ، مما يؤدي إلى تطور الصناعة المكثفة في الصناعة.
في مواجهة هذا الوضع الحالي ، تجمع بعض المشاريع بين Web3 مع حوافز رمزية لتحقيق جمع البيانات اللامركزية.أخذ Publicai كمثال ، يمكن للمستخدمين المشاركة كنوعين من الأدوار:
-
فئة واحدة هي مزود بيانات AI .
-
فئة أخرى هي صحة البيانات ، حيث يمكن للمستخدمين تسجيل الدخول إلى مركز بيانات Publicai وتحديد البيانات الأكثر قيمة لتدريب الذكاء الاصطناع للتصويت.
في المقابل ، يمكن للمستخدمين الحصول على حوافز رمزية من خلال هذين النوعين من المساهمات ، وبالتالي تشجيع علاقة مربحة بين المساهمين على البيانات وتطوير صناعة الذكاء الاصطناعي.
بالإضافة إلى مشاريع مثل Publicai المتخصصة في جمع البيانات لتدريب الذكاء الاصطناعي ، تقوم العديد من المشاريع بجمع البيانات اللامركزية من خلال حوافز الرمز المميز. تقوم DIMO بجمع بيانات سيارة المستخدم ، ويجمع WIHI بيانات الطقس ، وما إلى ذلك. هذه المشاريع التي تجمع البيانات من خلال اللامركزية هي أيضًا جانب التوريد من التدريب المحتملة على الذكاء الاصطناعي ، لذلك من الناحية على نطاق واسع ، يمكن تضمينها أيضًا في نموذج Web3 لمساعدة الذكاء الاصطناعي .
3.1.4 ZK يحمي خصوصية المستخدم في الذكاء الاصطناعي
بالإضافة إلى مزايا اللامركزية ، تجلب تقنية blockchain شيئًا مهمًا للغاية ، وهو دليل على المعرفة الصفرية.من خلال تقنية المعرفة الصفرية ، يمكن حماية الخصوصية أثناء التحقق من المعلومات.
في التعلم الآلي التقليدي ، عادة ما يجب تخزين البيانات ومعالجتها مركزيًا ، مما قد يؤدي إلى خطر انتهاك خصوصية البيانات.من ناحية أخرى ، فإن الطرق التي تحمي خصوصية البيانات ، مثل تشفير البيانات أو إلغاء تحديد البيانات ، قد تحد من دقة وأداء نماذج التعلم الآلي.
يمكن أن تساعد تقنية إثبات المعرفة الصفرية في مواجهة هذه المعضلة وحل التعارض بين حماية الخصوصية ومشاركة البيانات.
يتيح ZKML (التعلم الآلي المعرفة الصفري) التدريب والاستدلال على نماذج التعلم الآلي دون الكشف عن البيانات الأولية باستخدام تقنية إثبات المعرفة الصفرية.يتيح إثبات المعرفة الصفري خصائص البيانات ونتائج النموذج بشكل صحيح دون الكشف عن محتوى البيانات الفعلي.
الهدف الأساسي لـ ZKML هو تحقيق توازن بين حماية الخصوصية ومشاركة البيانات.يمكن تطبيقه على سيناريوهات مختلفة ، مثل تحليل البيانات الطبية والصحية ، وتحليل البيانات المالية ، والتعاون عبر المنظمات.باستخدام ZKML ، يمكن للأفراد حماية خصوصية بياناتهم الحساسة أثناء مشاركة البيانات مع الآخرين للحصول على رؤى أوسع للتعاون دون القلق بشأن خطر انتهاكات خصوصية البيانات.
لا يزال الحقل في مراحله المبكرة ولا يزال يتم استكشاف معظم المشاريع.تم تضمين الخصوصية في قلب البنية التحتية لشبكاتها الموزعة باستخدام نموذج اللغة الكبير المعرفة الصفري (ZK-LLM) لضمان بقاء بيانات المستخدم خاصة خلال عملية الشبكة.
نوضح هنا باختصار ما هو التشفير المتجانس الكامل (FHE).التشفير المتجانس بالكامل هو تقنية تشفير يمكنها حساب البيانات في حالة مشفرة دون فك التشفير.هذا يعني أنه يمكن إجراء عمليات رياضية مختلفة (مثل الإضافة والضرب وما إلى ذلك) على البيانات المشفرة باستخدام FHE مع الحفاظ على البيانات المشفرة والحصول على النتائج التي تم الحصول عليها من خلال تنفيذ نفس العمليات على البيانات الأصلية غير المشفرة. بيانات المستخدم.
بالإضافة إلى ذلك ، بالإضافة إلى الفئات الأربع المذكورة أعلاه ، من حيث دعم AI الخاص بـ Web3 ، هناك أيضًا مشاريع blockchain مثل القشرة التي تدعم تنفيذ برامج الذكاء الاصطناعي على السلسلة.في الوقت الحالي ، يواجه تنفيذ برامج التعلم الآلي على blockchains التقليدية تحديًا ، حيث تكون الأجهزة الافتراضية غير فعالة للغاية عند تشغيل أي نموذج تعلم آلي غير معقدة.لذلك ، يعتقد معظم الناس أنه من المستحيل تشغيل الذكاء الاصطناعي على blockchains.يستخدم Cortex Virtual Machine (CVM) وحدات معالجة الرسومات لتنفيذ برامج الذكاء الاصطناعي على السلسلة ومتوافقة مع EVM.بمعنى آخر ، يمكن لسلسلة القشرة تنفيذ جميع DAPPs Ethereum ودمج التعلم الآلي AI في هذه DAPPs على هذا الأساس.يتيح ذلك تشغيل نماذج التعلم الآلي بطريقة لا مركزية ، غير قابلة للتغيير والشفافة ، حيث أن إجماع الشبكة يتحقق من صحة كل خطوة من خطوات الذكاء الاصطناعي.
3.2 AI يساعد Web3
في الاصطدام بين الذكاء الاصطناعي و Web3 ، بالإضافة إلى مساعدة Web3 إلى AI ، فإن مساعدة AI في صناعة Web3 تستحق الاهتمام أيضًا.تكمن المساهمة الأساسية للذكاء الاصطناعي في تحسين الإنتاجية ، لذلك هناك العديد من المحاولات في عقود مراجعة الذكاء الاصطناعي ، وتحليل البيانات والتنبؤ بها ، والخدمات الشخصية ، والأمان وحماية الخصوصية.
3.2.1 تحليل البيانات والتنبؤ بها
في الوقت الحالي ، بدأت العديد من مشاريع Web3 في دمج خدمات الذكاء الاصطناعى الحالية (مثل ChatGPT) أو تطوير خدماتها الخاصة لتوفير خدمات تحليل البيانات وخدمات التنبؤ لمستخدمي Web3.ويغطي نطاقًا واسعًا ، بما في ذلك توفير استراتيجيات الاستثمار من خلال خوارزميات الذكاء الاصطناعى ، وأدوات الذكاء الاصطناعي على السلسلة ، وتوقعات الأسعار والتوقعات في السوق ، إلخ.
على سبيل المثال ، يستخدم Pond خوارزمية الرسم البياني من الذكاء الاصطناعي للتنبؤ برموز ألفا القيمة في المستقبل ، وتوفير نصيحة للمساعدة الاستثمارية للمستخدمين والمؤسسات. الدعم توقع اتجاهات الأسعار ، ومساعدة المستخدمين على الحصول على الأرباح والأرباح.
هناك أيضًا منصات منافسة الاستثمار مثل Numerai.يحسب Numerai كيفية أداء هذه التنبؤات خلال الشهر المقبل ، ويمكن للمتسابقين المراهنة على الرنين المغناطيسي النووي على النموذج وكسب المال بناءً على أداء النموذج.
بالإضافة إلى ذلك ، تجمع منصات تحليل البيانات على السلسلة مثل Arkham أيضًا بين الذكاء الاصطناعي للخدمات.يربط Arkham عناوين blockchain مع كيانات مثل التبادلات والصناديق والحيتان العملاقة ، ويعرض المستخدمين على بيانات وتحليلات رئيسية لهذه الكيانات لتزويد المستخدمين بمزايا صنع القرار.جزء من مزيجها مع الذكاء الاصطناعى هو أن Arkham Ultra يستخدم الخوارزميات لمطابقة العناوين مع الكيانات الواقعية ، التي طورها مساهمون Arkham Core بدعم من Palantir ومؤسسي Openai على مدار ثلاث سنوات.
3.2.2 الخدمة الشخصية
في مشاريع Web2 ، لدى AI العديد من سيناريوهات التطبيق في مجالات البحث والتوصية ، وخدمة الاحتياجات الشخصية للمستخدمين.وينطبق الشيء نفسه في مشاريع Web3.
على سبيل المثال ، أطلقت Dune ، وهي منصة تحليل البيانات المعروفة ، أداة WAND مؤخرًا لكتابة استعلامات SQL بمساعدة نماذج اللغة الكبيرة.من خلال وظيفة إنشاء العصا ، يمكن للمستخدمين إنشاء استعلامات SQL تلقائيًا بناءً على مشاكل اللغة الطبيعية ، بحيث يمكن للمستخدمين الذين لا يفهمون SQL البحث بسهولة بالغة.
بالإضافة إلى ذلك ، بدأت بعض منصات محتوى Web3 في دمج ملخص المحتوى. المساحة المصدر الرئيسي لجميع المعرفة الموضوعية والعالية الجودة المتعلقة بتكنولوجيا blockchain والعملات المشفرة تجعل blockchain أسهل في اكتشافها على نطاق عالمي ، وتوفر للمستخدمين معلومات يمكنهم الوثوق بها أيضًا. تلتزم Kaito ، وهو محرك بحث يعتمد على LLM ، أن تصبح منصة بحث Web3 وتغيير طريقة الحصول على معلومات Web3.
فيما يتعلق بالإنشاء ، هناك أيضًا مشاريع مثل NFPrompt تقلل من تكاليف إنشاء المستخدم.يتيح NFPrompt للمستخدمين إنشاء NFTS بسهولة أكبر من خلال الذكاء الاصطناعي ، وبالتالي تقليل التكاليف الإبداعية للمستخدم وتقديم العديد من الخدمات الشخصية من حيث الإنشاء.
3.2.3 منظمة العفو الدولية تدقيق العقد الذكي
في حقل Web3 ، يعد تدقيق العقود الذكية مهمة مهمة للغاية.
كما ذكر Vitalik ذات مرة ، فإن أحد أكبر التحديات التي تواجه مساحة العملة المشفرة هي الأخطاء في الكود لدينا.أحد الاحتمالات المتوقعة هو أن الذكاء الاصطناعي (AI) يمكنه تبسيط استخدام أدوات التحقق الرسمية بشكل كبير لإثبات أن مجموعة من الرموز تفي بسمات محددة.إذا استطعنا القيام بذلك ، فمن المحتمل أن يكون لدينا SEK EVMs خالية من الأخطاء (مثل الأجهزة الافتراضية Ethereum).كلما زادت عدد الأخطاء ، زادت أمان المساحة ، و AI مفيدة للغاية في تحقيق ذلك.
على سبيل المثال ، يوفر مشروع 0x0.ai مدققًا ذكيًا للذكاء الاصطناعي ، وهي أداة تستخدم خوارزميات متقدمة لتحليل العقود الذكية وتحديد نقاط الضعف أو المشكلات المحتملة التي قد تؤدي إلى الاحتيال أو غيرها من المخاطر الأمنية.يستخدم المدققون تقنيات التعلم الآلي لتحديد الأنماط والاستثناءات في الكود ، مما يمثل المشكلات المحتملة لمزيد من المراجعة.
بالإضافة إلى الفئات الثلاث المذكورة أعلاه ، هناك أيضًا بعض الحالات الأصلية التي تستخدم حقل Web3 تجميع Multi-Cain Dex Hera ، الذي يستخدم AI لتوفير أوسع نطاق من الرموز وأفضل مسارات التداول بين أي زوج من الرمز المميز.
قيود وتحديات مشاريع AI+Web3
4.1 العقبات الفعلية في قوة الحوسبة اللامركزية
من بين المشاريع الحالية التي تساعد AI ، يركز جزء كبير من المشاريع التي تدعم Web3 على قوة الحوسبة اللامركزية. هناك أيضًا بعض المشكلات العملية التي يجب حلها:
بالمقارنة مع مقدمي خدمات الطاقة المركزية ، عادة ما تعتمد منتجات طاقة الحوسبة اللامركزية على العقد والمشاركين الموزعة في جميع أنحاء العالم لتوفير موارد الحوسبة.نظرًا لأن اتصالات الشبكة بين هذه العقد قد يكون لها الكمون وعدم الاستقرار ، فقد يكون الأداء والاستقرار أسوأ من منتج طاقة الحوسبة المركزي.
بالإضافة إلى ذلك ، يتأثر توفر منتجات الطاقة الحوسبة اللامركزية بدرجة المطابقة بين العرض والطلب.إذا لم يكن هناك ما يكفي من الموردين أو أن الطلب مرتفع للغاية ، فقد يؤدي ذلك إلى عدم كفاية موارد أو عدم القدرة على تلبية احتياجات المستخدم.
أخيرًا ، تتضمن منتجات طاقة الحوسبة اللامركزية عادةً تفاصيل فنية وتعقيد أكثر من منتجات طاقة الحوسبة المركزية.قد يحتاج المستخدمون إلى فهم المعرفة والتعامل معها حول الشبكات الموزعة والعقود الذكية ومدفوعات العملة المشفرة ، وستصبح تكلفة فهم المستخدم واستخدامه أعلى.
بعد مناقشة متعمقة مع عدد كبير من مشاريع طاقة الحوسبة اللامركزية ، وجدت أن قوة الحوسبة الحالية اللامركزية لا يمكن أن تقتصر إلا على التفكير في الذكاء الاصطناعي بدلاً من تدريب الذكاء الاصطناعي.
بعد ذلك ، سأستخدم أربعة أسئلة صغيرة لمساعدتك على فهم الأسباب وراء ذلك:
1. لماذا تختار معظم مشاريع الطاقة الحوسبة اللامركزية القيام بتفكير الذكاء الاصطناعي بدلاً من تدريب الذكاء الاصطناعي؟
2. أين نفيديا رهيبة؟ما هو سبب صعوبة التدريب على قوة الحوسبة اللامركزية؟
3. كيف ستبدو نهاية قوة الحوسبة اللامركزية (عرض ، أكاش ، io.net ، إلخ)؟
4. كيف ستبدو نهاية الخوارزمية اللامركزية (bittensor)؟
بعد ذلك ، دعنا نقشر طبقة شرنقة من الطبقة:
1) بالنظر إلى هذا المسار ، تختار معظم مشاريع قوة الحوسبة اللامركزية القيام بمنطق الذكاء الاصطناعي بدلاً من التدريب.جوهر هو المتطلبات المختلفة لحساب الطاقة وعرض النطاق الترددي.
لمساعدة الجميع على الفهم بشكل أفضل ، دعنا نقارن الذكاء الاصطناعي مع الطالب:
تدريب الذكاء الاصطناعي: إذا قارنا الذكاء الاصطناعي بطالب ، فإن التدريب يشبه توفير الذكاء الاصطناعي مع الكثير من المعرفة ، ويمكن أيضًا فهم الأمثلة على أنها بيانات نسميها غالبًا ، والذكاء الاصطناعي يتعلم من هذه الأمثلة المعرفة.نظرًا لأن طبيعة التعلم تتطلب فهم وذاكرة كمية كبيرة من المعلومات ، فإن هذه العملية تتطلب الكثير من قوة الحوسبة والوقت.
المنطق الذكاء: إذن ما هو المنطق؟يمكن فهمه على أنه استخدام المعرفة التي تم تعلمها لحل المشكلات أو إجراء الامتحانات في مرحلة التفكير. .
من السهل أن نجد أن الفرق في الصعوبة بين الاثنين هو في الأساس أن تدريب النموذج الكبير من الذكاء الاصطناعي يتطلب كمية كبيرة من البيانات وعرض النطاق الترددي اللازم للاتصال بالبيانات عالية السرعة ، لذلك من الصعب للغاية حاليًا تنفيذ قوة الحوسبة اللامركزية كتدريب .ومع ذلك ، فإن الحاجة إلى البيانات واستدلال النطاق الترددي أصغر بكثير ، وإمكانية التنفيذ أكبر.
بالنسبة للنماذج الكبيرة ، فإن الشيء الأكثر أهمية هو الاستقرار.من ناحية أخرى ، يكون متطلبات قوة الحوسبة المنخفضة نسبيًا ، مثل الاستدلال الذكري المذكور أعلاه ، أو تدريب النماذج الرأسية الصغيرة والمتوسطة لبعض السيناريوهات المحددة ، وهو أمر ممكن في اللامركزية. في شبكة طاقة الحوسبة التي يمكن أن تخدم احتياجات طاقة الحوسبة الكبيرة نسبيًا.
2) إذن أين هي نقطة مربى البيانات وعرض النطاق الترددي؟لماذا يصعب تحقيق التدريب اللامركزي؟
يتضمن ذلك عنصرين رئيسيين للتدريب على النماذج الكبيرة: يتم توصيل قوة حوسبة البطاقة المفردة والبطاقات المتعددة بالتوازي.
قوة الحوسبة ذات البطاقات الواحدة: في الوقت الحالي ، جميع المراكز التي تتطلب تدريب نماذج كبيرة ، نسميها مراكز الحوسبة الفائقة.لتسهيل فهم الجميع ، يمكننا استخدام جسم الإنسان كمعاجب.إذا كانت قوة الحوسبة لخلية واحدة (GPU) قوية جدًا ، فقد تكون قوة الحوسبة الشاملة (رقم الخلية الواحدة) قوية جدًا.
اتصال متوازي متعدد البطاقات: غالبًا ما يكون تدريب نموذج كبير 100 مليار جيجا بايت.لذلك ، نحتاج إلى تعبئة عشرات الآلاف من البطاقات للتدريب. في جزء منه ، قد يتطلب التدريب على بطاقات الرسومات المختلفة نتائج B عند التدريب A ، لذلك يتم تورط البطاقات المتعددة بالتوازي.
لماذا تعتبر Nvidia قوية جدًا وقيمت قيمتها السوقية ، ولكن من الصعب على AMD و Huawei و Horizon المحليين اللحاق بالركب.ليس جوهر قوة الحوسبة ذات البطاقات الواحدة نفسها ، ولكن جانبين: بيئة برنامج CUDA والاتصالات المتعددة البطاقات NVLink.
من ناحية ، من المهم للغاية ما إذا كان هناك نظام بيئي للبرامج يمكنه التكيف مع الأجهزة ، مثل نظام CUDA في NVIDIA.
من ناحية أخرى ، إنه اتصال متعدد البطاقات.بسبب وجود NVLink ، لا توجد طريقة لتوصيل بطاقات NVIDIA و AMD ، بالإضافة إلى ذلك موزعة في جميع أنحاء العالم.
تشرح النقطة الأولى سبب صعوبة اللحاق بالركب AMD و Huawei و Horizon في الصين.
3) كيف ستبدو نهاية قوة الحوسبة اللامركزية؟
من الصعب حاليًا تدريب قوة الحوسبة اللامركزية على النماذج الكبيرة.متطلباتها للاتصال الموازي للبطاقات المتعددة عالية جدًا ، ويقتصر عرض النطاق الترددي على المسافة المادية.تستخدم NVIDIA NVLINK لتحقيق التواصل متعدد البطاقات.
ولكن من ناحية أخرى ، يكون الطلب على قوة الحوسبة المنخفضة نسبيًا ، مثل استنتاج الذكاء الاصطناعي ، أو تدريب النماذج الرأسية الصغيرة والمتوسطة في بعض السيناريوهات المحددة ، وهو أمر ممكن في شبكات الطاقة الحوسبة اللامركزية. مقدمي خدمات العقدة الكبيرة ، لديهم القدرة على خدمة احتياجات طاقة الحوسبة الكبيرة نسبيا.بالإضافة إلى سيناريوهات الحوسبة مثل التقديم ، من السهل نسبيًا تنفيذها.
4) كيف ستبدو نهاية نموذج الخوارزمية اللامركزية؟
يعتمد نهاية نموذج الخوارزمية اللامركزية على نهاية الذكاء الاصطناعي في المستقبل. ليست هناك حاجة إلى ربط نموذج كبير لمنتج طبقة التطبيق ، ولكنه يتعاون مع نماذج كبيرة متعددة.
4.2 مزيج من الذكاء الاصطناعي+3 خشن نسبيا ، و 1+1> 2
حاليًا ، من بين المشاريع التي تجمع بين Web3 و AI ، وخاصة من حيث الذكاء الاصطناعي لمساعدة مشاريع Web3 ، لا تزال معظم المشاريع تستخدم الذكاء الاصطناعي على السطح ولا تعكس حقًا التكامل العميق بين الذكاء الاصطناعي والعملة المشفرة.ينعكس هذا النوع من التطبيقات السطحية بشكل أساسي في الجانبين التاليين:
-
بادئ ذي بدء ، سواء كان ذلك يستخدم الذكاء الاصطناعي لتحليل البيانات والتنبؤ بها ، أو استخدام الذكاء الاصطناعي في سيناريوهات التوصية والبحث ، أو إجراء عمليات تدقيق التعليمات البرمجية ، لا يوجد فرق كبير عن مجموعة مشاريع Web2 و AI.تستخدم هذه المشاريع ببساطة الذكاء الاصطناعي لتحسين الكفاءة والتحليل ، دون إظهار التقارب الأصلي والحلول المبتكرة بين الذكاء الاصطناعي والعملات المشفرة.
-
ثانياً ، تتحد العديد من فرق Web3 مع الذكاء الاصطناعي للاستفادة البحتة لمفهوم الذكاء الاصطناعي على مستوى التسويق.لقد استخدموا للتو تقنية الذكاء الاصطناعى في مناطق محدودة للغاية ، ثم بدأوا في تعزيز اتجاه الذكاء الاصطناعي ، مما يخلق وهمًا بأن المشاريع قريبة جدًا من الذكاء الاصطناعي.ومع ذلك ، لا يزال هناك الكثير من الفجوات في هذه المشاريع من حيث الابتكار الحقيقي.
على الرغم من أنه لا تزال هناك هذه القيود في مشاريع Web3 و AI الحالية ، إلا أننا يجب أن ندرك أن هذه مجرد مرحلة مبكرة من التطوير.في المستقبل ، يمكننا أن نتوقع المزيد من الأبحاث والابتكار المتعمرين لتحقيق تكامل أوثق بين AI و Cryptocurrency وخلق المزيد من الحلول الأصلية والهمية في مجالات مثل التمويل ، والمنظمات المستقلة اللامركزية ، والأسواق المتوقعة وخطة NFT.
4.3 يصبح الاقتصاد الرمزي عازلة لسرد مشروع الذكاء الاصطناعي
نظرًا لأن مشكلة نموذج العمل لمشاريع الذكاء الاصطناعى المذكورة في البداية ، حيث أن المزيد والمزيد من النماذج الكبيرة بدأت في فتح مصدر تدريجيًا ، فغالبًا ما يصعب تطوير عدد كبير من مشاريع AI+Web3 سرد Web3.
ولكن المفتاح الحقيقي هو ما إذا كان دمج الاقتصاد الرمزي يمكن أن يساعد حقًا مشاريع الذكاء الاصطناعي في حل الاحتياجات الفعلية ، أو ما إذا كانت مجرد قيمة سردية أو قصيرة الأجل ، فهي بحاجة فعليًا إلى الاستجواب.
في الوقت الحالي ، فإن معظم مشاريع AI+Web3 بعيدة عن الوصول إلى المرحلة العملية.
لخص
في الوقت الحاضر ، ظهرت العديد من الحالات والتطبيقات في مشاريع AI+Web3.بادئ ذي بدء ، يمكن لتكنولوجيا الذكاء الاصطناعي أن توفر Web3 سيناريوهات تطبيق أكثر كفاءة وذكية.من خلال قدرات تحليل بيانات الذكاء الاصطناعى ، يمكن أن يكون لدى مستخدمي Web3 أدوات أفضل في اتخاذ القرارات الاستثمارية وغيرها من السيناريوهات ؛في الوقت نفسه ، يمكن أن توفر تقنية الذكاء الاصطناعى أيضًا توصيات أكثر دقة وذكية وخدمات شخصية للتطبيقات اللامركزية لتحسين تجربة المستخدم.
في الوقت نفسه ، توفر اللامركزية وبرمجة Web3 أيضًا فرصًا جديدة لتطوير تكنولوجيا الذكاء الاصطناعي.من خلال الحوافز الرمزية ، توفر مشاريع الحوسبة اللامركزية حلولًا جديدة لمعضلة عدم كفاية قوة الحوسبة الذكية.لقد جلبت آليات وثيقة مستخدمي Web3 أيضًا إمكانيات جديدة لتطوير AI.
على الرغم من أن مشروع Crossover AI+3 الحالي لا يزال في مراحله المبكرة ، وهناك العديد من الصعوبات التي يجب مواجهتها ، إلا أنه يجلب أيضًا العديد من المزايا.على سبيل المثال ، تحتوي منتجات طاقة الحوسبة اللامركزية على بعض أوجه القصور ، لكنها تقلل من اعتمادها على المؤسسات المركزية ، وتوفر المزيد من الشفافية والمراجعة ، وتمكين المشاركة والابتكار الأوسع.قد تكون منتجات طاقة الحوسبة اللامركزية خيارًا قيمًا لحالات الاستخدام المحددة وتلبية احتياجات المستخدمين ؛ تغطية البيانات وتعزيز تنوع البيانات وإدراجها ، إلخ.في الممارسة العملية ، تحتاج هذه المزايا والعيوب إلى وزنها وإدارتها ، ويتم اتخاذ تدابير فنية للتغلب على التحديات لضمان أن يكون لمشاريع جمع البيانات اللامركزية تأثير إيجابي على تطوير الذكاء الاصطناعي.
بشكل عام ، يوفر دمج AI+Web3 إمكانيات غير محدودة للابتكار التكنولوجي في المستقبل والتنمية الاقتصادية.من خلال الجمع بين التحليل الذكي وقدرات صنع القرار في الذكاء الاصطناعى مع اللامركزية واستقلالية المستخدم لـ Web3 ، نعتقد أنه في المستقبل ، يمكننا بناء نظام اقتصادي أكثر ذكاءً وأكثر انفتاحًا وحتى اجتماعيًا.







