
はじめに:AI+Web3の開発
過去数年間、人工知能(AI)とWeb3テクノロジーの急速な発展は、世界中で広範囲にわたる注目を集めています。人間の知能をシミュレートして模倣する技術として、AIは顔認識、自然言語加工、機械学習などの分野で大きなブレークスルーを行いました。AIテクノロジーの急速な発展は、あらゆる人生に大きな変化と革新をもたらしました。
AI産業の市場規模は2023年に2,000億米ドルに達しました。業界の巨人やOpenai、Character.ai、Midjourneyなどの優れたプレーヤーは、雨の後にキノコのように出現し、AIの流行をリードしています。
同時に、Emerging NetworkモデルとしてのWeb3は、インターネットの理解と使用を徐々に変えています。分散化されたブロックチェーンテクノロジーに基づいて、Web3はデータ共有と制御可能性、ユーザーの自律性、信頼メカニズムを、スマートコントラクト、分散ストレージ、分散認証などの機能を介して実現します。Web3のコアコンセプトは、集中化された権威ある組織からのデータを解放し、ユーザーにデータを制御し、データ値を共有する権利を提供することです。
現在、Web3業界の市場価値は25兆に達しました。 Web3業界に参加してください。
AIとWeb3の組み合わせは、東部と西部のビルダーとVCの両方が非常に心配していることを簡単に見つけることができます。
この記事では、AI+Web3の現在の開発状況に焦点を当て、この統合の潜在的な価値と影響を調査します。最初にAIとWeb3の基本的な概念と機能を紹介し、次にそれらの関係を調査します。次に、AI+Web3プロジェクトの現在のステータスを分析し、直面している制限と課題について詳しく説明します。このような研究を通じて、関連業界の投資家や実務家に貴重な参照と洞察を提供することを期待しています。
AIがWeb3とどのように相互作用するか
AIとWeb3の開発は、バランスの両側に似ています。それでは、どのようなスパークがAIとWeb3を衝突させることができますか?次に、AIおよびWeb3 Industriesが直面する困難と改善スペースを分析し、お互いがこれらの困難をどのように解決できるかを議論します。
-
AI業界のジレンマと潜在的な改善スペース
-
Web3業界のジレンマと潜在的な改善スペース
2.1 AI業界が直面しているジレンマ
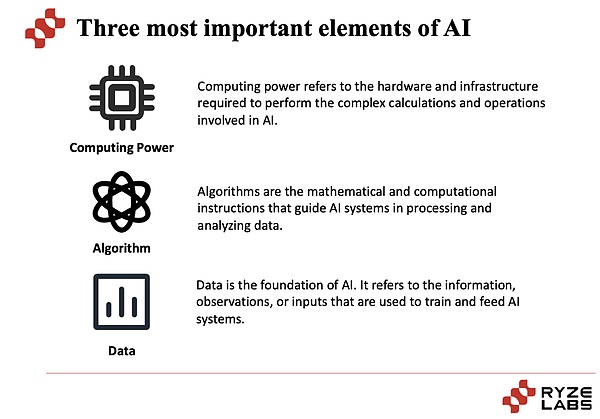
AI業界が直面する困難を調査したい場合は、まずAI業界の本質を見てみましょう。AI業界の中核は、コンピューティングパワー、アルゴリズム、データの3つの要素から切り離せません。
-
まず、コンピューティングパワー:コンピューティングパワーとは、大規模な計算と処理を実行する機能を指します。AIタスクでは、多くの場合、大量のデータを処理し、深いニューラルネットワークモデルのトレーニングなどの複雑な計算を実行する必要があります。高強度コンピューティングパワーは、モデルトレーニングと推論プロセスを加速し、AIシステムのパフォーマンスと効率を改善することができます。近年、グラフィックプロセッサ(GPU)や専用のAIチップ(TPUなど)などのハードウェアテクノロジーの開発により、コンピューティングパワーの改善がAI業界の開発を促進する上で重要な役割を果たしてきました。近年、株を急上昇しているNvidiaは、GPUプロバイダーとして大きな市場シェアを占め、高い利益を上げています。
-
アルゴリズムとは何ですか:アルゴリズムはAIシステムのコアコンポーネントであり、問題を解決してタスクを実装するために使用される数学的および統計的方法です。AIアルゴリズムは、従来の機械学習アルゴリズムとディープラーニングアルゴリズムに分けることができ、その中で深い学習アルゴリズムが近年大きなブレークスルーを行っています。アルゴリズムの選択と設計は、AIシステムのパフォーマンスと有効性にとって重要です。継続的に改善された革新的なアルゴリズムは、AIシステムの精度、堅牢性、一般化機能を改善できます。異なるアルゴリズムには異なる効果があるため、アルゴリズムを改善することも、タスクを完了する効果にとって重要です。
-
データが重要な理由:AIシステムの中心的なタスクは、学習とトレーニングを通じてデータのパターンとルールを抽出することです。
データは、大規模なデータサンプルを介してトレーニングと最適化の基礎となります。豊富なデータセットは、より包括的で多様な情報を提供することができ、モデルを目に見えないデータにより一般化し、AIシステムが実際の問題をよりよく理解し解決できるようにします。
AIの3つのコア要素を理解した後、AIが最初に遭遇する困難と課題を見てみましょう。特に深い学習モデルの観点から、推論。ただし、大規模なコンピューティングパワーの取得と管理は、高価で複雑な課題です。高性能コンピューティング機器のコスト、エネルギー消費、メンテナンスはすべて問題です。特にスタートアップや個々の開発者にとって、十分なコンピューティングパワーを獲得するのは難しい場合があります。
アルゴリズムに関しては、深い学習アルゴリズムは多くの分野で大きな成功を収めていますが、まだいくつかのジレンマと課題があります。たとえば、深いニューラルネットワークのトレーニングには、大量のデータとコンピューティングリソースが必要であり、一部のタスクでは、説明と解釈可能なモデルが不十分な場合があります。さらに、アルゴリズムの堅牢性と一般化能力も重要な問題であり、目に見えないデータに関するモデルのパフォーマンスは不安定である可能性があります。多くのアルゴリズムの中で、最適なサービスを提供するために最適なアルゴリズムを見つける方法は、継続的な調査を必要とするプロセスです。
データに関しては、データはAIの原動力ですが、高品質で多様なデータを取得することは依然として課題です。医療分野の敏感な健康データなど、一部の分野のデータを取得するのは難しい場合があります。さらに、データの品質、精度、ラベリングも問題であり、不完全または偏ったデータは、モデルの誤った動作やバイアスにつながる可能性があります。同時に、データのプライバシーとセキュリティを保護することも重要な考慮事項です。
さらに、解釈可能性や透明性などの問題があり、AIモデルのブラックボックスの特性は一般的な関心事です。金融、ヘルスケア、正義などの一部のアプリケーションでは、モデルの意思決定プロセスは解釈可能かつ追跡可能である必要がありますが、既存の深い学習モデルは透明性に欠けていることがよくあります。モデルの意思決定プロセスを説明し、信頼できる説明を提供することは課題です。
さらに、多くのAIプロジェクトの起業家精神のビジネスモデルはそれほど明確ではなく、多くのAI起業家が混乱していると感じさせます。
2.2 Web3業界が直面しているジレンマ
Web3業界では、Web3のデータ分析、Web3製品のユーザーエクスペリエンスの低下、またはスマート契約コードの脆弱性とハッカー攻撃の問題であっても、多くの困難を解決する必要があります。改善の余地。生産性を向上させるためのツールとして、AIには、これらの側面で開発の余地がたくさんあります。
まず第一に、データ分析と予測機能の改善:データ分析と予測におけるAIテクノロジーの適用は、Web3業界に大きな影響をもたらしました。AIアルゴリズムのインテリジェントな分析とマイニングを通じて、Web3プラットフォームは、大規模なデータから貴重な情報を抽出し、より正確な予測と決定を行うことができます。これは、地方分権化された財務(DEFI)の分野におけるリスク評価、市場予測、および資産管理にとって非常に重要です。
さらに、ユーザーエクスペリエンスとパーソナライズされたサービスの改善も達成できます。AIテクノロジーのアプリケーションにより、Web3プラットフォームはユーザーエクスペリエンスとパーソナライズされたサービスを向上させることができます。ユーザーデータの分析とモデリングを通じて、Web3プラットフォームは、ユーザーにパーソナライズされた推奨事項、カスタマイズされたサービス、インテリジェントなインタラクティブエクスペリエンスを提供できます。これにより、ユーザーのエンゲージメントと満足度が向上し、たとえば、多くのWeb3プロトコルがChatGPTなどのAIツールに接続されています。
セキュリティとプライバシー保護の観点から、AIの適用はWeb3業界にも大きな影響を与えます。AIテクノロジーを使用して、サイバー攻撃を検出および防御し、異常な行動を特定し、より強力なセキュリティを提供することができます。同時に、AIはデータプライバシー保護にも使用できます。また、データ暗号化やプライバシーコンピューティングなどのテクノロジーを通じて、Web3プラットフォーム上のユーザーの個人情報を保護できます。スマートコントラクト監査の観点から、スマート契約の執筆と監査における脆弱性とセキュリティリスクの可能性があるため、AIテクノロジーを使用して契約監査と脆弱性検出を自動化して、契約のセキュリティと信頼性を向上させることができます。
AIは、Web3業界が直面している困難と潜在的な改善スペースの多くの側面に参加し、支援を提供できることがわかります。
AI+Web3プロジェクトの現在のステータスの分析
AIとWeb3を組み合わせたプロジェクトは、主に2つの主要な側面から始まり、ブロックチェーンテクノロジーを使用してAIプロジェクトのパフォーマンスを改善し、AIテクノロジーを使用してWeb3プロジェクトの改善に役立ちます。
IO.NET、Gensyn、Ritualなどのさまざまなプロジェクトを含むこのパスを探求するために、多数のプロジェクトが登場しました現在の状況と開発。
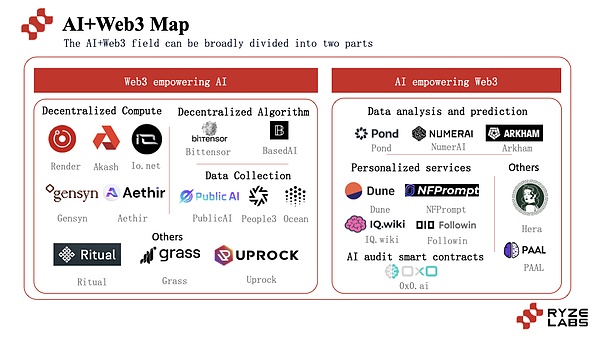
3.1 Web3はAIに役立ちます
3.1.1分散型コンピューティングパワー
Openaiは2022年の終わりにChatGptを発売して以来、AIの波をトリガーしてから100万人に達し、Instagramは100万人のダウンロードに達しました。その後、CHATGPTは非常に迅速に努力し、毎月のアクティブユーザーの数は2か月以内に1億人に達しました。ChatGptの出現により、AIフィールドは、ニッチなトラックから非常に視聴された業界に急速に爆発しました。
Trendforceのレポートによると、CHATGPTには実行するには30,000のNVIDIA A100 GPUが必要であり、GPT-5は将来、より多くの規模の計算を必要とします。これにより、さまざまなAI企業間の軍レースが開かれました。
AIが台頭する前に、GPUの最大のプロバイダーであるNvidiaは、AWS、Azure、およびGCPの3つの主要なクラウドサービスに焦点を当てていました。人工知能の台頭により、大手ハイテク企業のメタ、オラクル、その他のデータプラットフォームやAIスタートアップなど、多数の新しいバイヤーが登場し、すべてがGPUを装備するために戦争に参加してAIモデルを訓練しました。MetaやTeslaなどの大規模なハイテク企業は、カスタマイズされたAIモデルと内部研究の購入を増やしています。SnopflakeやDatabricksなどの人類やデータプラットフォームなどの基本モデル企業は、顧客がAIサービスを提供するのを支援するために、より多くのGPUを購入しました。
昨年のセミ分析「GPU RichとGPU Poor」で述べたように、いくつかの企業は20,000以上のA100/H100 GPUを持っており、チームメンバーはプロジェクトに100〜1,000 GPUを使用できます。これらの企業は、Openai、Google、Meta、人類、変曲、テスラ、オラクル、ミストラルなどを含むクラウドプロバイダーまたは自営業のLLMのいずれかです。
ただし、ほとんどの企業はGPU貧困層であり、GPUの数がはるかに少ないだけで、生態系の開発を促進するのがより困難なものに多くの時間とエネルギーを費やすことができます。そして、この状況はスタートアップに限定されません。最もよく知られているAI企業のいくつか – 顔、Databricks(MosaicML)、一緒に、さらにはSnowflakeでさえ、A100/H100の数で20K未満です。これらの企業は世界クラスの技術的才能を持っていますが、GPUの供給によって制限されており、人工知能の競争で大企業と比較して不利です。
この不足は、2023年の終わりでさえ、AIトラックのリーダーであっても、十分なGPUを取得できないため、有料登録をオフにする必要がありました。 GPU供給。
AIの急速な発展により、GPUの需要と供給の側面の間に深刻な不一致があり、供給不足の問題が差し迫っていることがわかります。
この問題を解決するために、一部のWeb3プロジェクトパーティーは、Akash、Render、Gensynなどを含むWeb3の技術的特性に基づいて分散型コンピューティングパワーサービスを提供しようとし始めています。このタイプのプロジェクトでよくあるのは、トークンがユーザーにアイドル状態のGPUコンピューティングパワーを提供するようにユーザーを奨励し、AI顧客にコンピューティングパワーを提供するためのコンピューティングパワーの供給側になることです。
サプライサイドのポートレートは、主にクラウドサービスプロバイダー、暗号通貨鉱夫、企業の3つの側面に分けることができます。
クラウドサービスプロバイダーには、大規模なクラウドサービスプロバイダー(AWS、Azure、GCPなど)やGPUクラウドサービスプロバイダー(CoreWeave、Lambda、Crusoeなど)が含まれ、ユーザーはアイドルクラウドサービスプロバイダーのコンピューティングパワーを再販して収益を獲得できます。 。Crypto Minersは、EthereumがPOWからPOSからPOSに切り替えると、IDLE GPUコンピューティングパワーも重要な潜在的な供給側になりました。さらに、戦略的レイアウトのために多数のGPUを購入したTeslaやMetaのような大企業は、供給側としてアイドルGPUコンピューティングパワーを使用することもできます。
現在、トラック上のプレイヤーは2つのカテゴリにほぼ分割されています。1つはAI推論に分散型コンピューティングパワーを使用することであり、もう1つはAIトレーニングに分散型コンピューティングパワーを使用することです。前者はレンダリングなどです(レンダリングに焦点を当てていますが、AIコンピューティングパワーを提供することもできます)、Akash、Aethirなどです。 、Gensyn、2つの最大の違いはコンピューティングです。
最初に以前のAI推論プロジェクトについて話しましょう。力。このようなプロジェクトの紹介と分析は、ラボの前のDepinに関する調査報告書に記載されています。チェックアウトしてください。
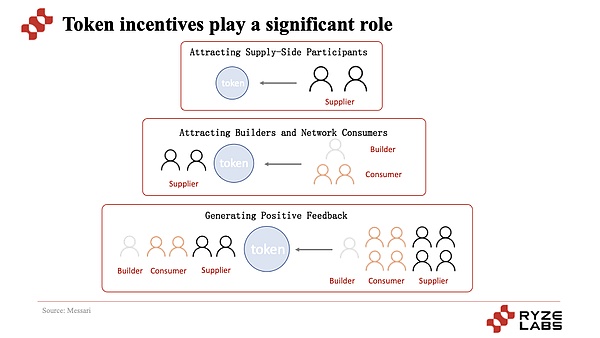
最も核となる点は、トークンのインセンティブメカニズムを通じて、プロジェクトが最初にサプライヤーを引き付け、次にユーザーを使用するために使用することです。したがって、プロジェクトのコールドスタートとコア操作メカニズムが実現し、さらに拡大および開発できます。このサイクルでは、供給側はますます貴重なトークンのリターンを備えており、需要とはより安価で費用対効果の高いサービスがあり、需要と供給の両方の参加者が増加しています価格は、より多くの参加者と投機家を引き付け、参加して価値をキャプチャします。
別のタイプは、Gensyn、IO.Net(AIトレーニング、AIの推論もそれをサポートできる)など、AIトレーニングに分散型コンピューティングパワーを使用することです。実際、このタイプのプロジェクトの操作ロジックとAI推論プロジェクトの間には大きな違いはありません。
その中でも、IO.NETは分散型コンピューティングパワーネットワークであり、現在500,000を超えるGPUがあり、さらに分散型コンピューティングパワープロジェクトでは、レンダリングとファイルコインのコンピューティングパワーも統合されています。生態学的プロジェクト。

さらに、Gensynは、機械学習のためのタスクの割り当てと報酬を促進できるスマートコントラクトを通じてAIトレーニングを実現します。以下の図に示すように、Gensynの機械学習トレーニング作業は1時間あたり約0.4ドルかかります。これは、AWSとGCPのコストよりもはるかに低く、2ドル以上です。
Gensynのシステムには、提出者、執行者、検証者、内部告発者の4人の参加者が含まれます。
-
提出:ユーザーはタスクの消費者であり、計算するタスクを提供し、AIトレーニングタスクの支払い
-
執行者:執行者は、モデルによってトレーニングされたタスクを実行し、検証者による検証のためにタスクを完了する証拠を生成します。
-
検証剤:非決定的トレーニングプロセスを決定論的線形計算にリンクし、エグゼキューターの証明を予想されるしきい値と比較します。
-
内部告発者:バリデーターの作業を確認し、発見されたときに利益を得るために質問を提起します。
Gensynは、グローバルな深い学習モデルのための超大規模で費用対効果の高いコンピューティングプロトコルになることを望んでいることがわかります。しかし、このトラックを見ると、なぜほとんどのプロジェクトは、トレーニングの代わりにAI推論のために分散化されたコンピューティングパワーを選択するのですか?
ここでは、AIのトレーニングと推論が2つの違いを導入することを理解していない友人を支援します。
-
AIトレーニング:人工知能を学生と比較すると、トレーニングは人工知能に多くの知識を提供することに似ており、例は頻繁にそれを呼ぶデータとして理解することもでき、人工知能はこれらの知識の例から学びます。学習の性質には大量の情報の理解と記憶が必要なため、このプロセスには多くのコンピューティングパワーと時間が必要です。
-
AI推論:では、推論とは何ですか?問題を解決するために学んだ知識を使用したり、推論段階で学んだ知識を使用して、新しい知識に従事するのではなく、理解することができます。 。
2つのコンピューティング要件は、AI推論とAIトレーニングにおける分散型コンピューティングパワーの可用性がまったく異なることがわかります。
さらに、儀式は、分散ネットワークとモデル作成者を組み合わせて、分散化とセキュリティを維持することを望んでいます。その最初の製品であるインターネットにより、ブロックチェーン上のスマートコントラクトがAIモデルオフチェーンにアクセスできるようになり、そのような契約が検証、分散化、プライバシーを維持する方法でAIにアクセスできます。
インターネットのコーディネーターは、ネットワーク内のノードの動作を管理し、消費者が発行したコンピューティング要求に対応する責任があります。ユーザーがインターネットを使用すると、推論、証明、およびその他の作業がチェーンから配置されると、出力結果がコーディネーターに返され、最終的に契約を通じてチェーンの消費者に渡されます。
分散化されたコンピューティングパワーネットワークに加えて、データ送信の速度と効率を改善するために、草などの分散型帯域幅ネットワークもあります。一般に、分散化されたコンピューティングパワーネットワークの出現により、AIのコンピューティング電源側の新しい可能性が提供され、AIがさらに方向に進むようになりました。
3.1.2分散型アルゴリズムモデル
第2章で述べたように、AIの3つのコア要素は、コンピューティングパワー、アルゴリズム、データです。コンピューティングパワーは、地方分権化を通じて供給ネットワークを形成できるため、アルゴリズムは同様のアイデアを持ち、アルゴリズムモデル供給ネットワークを形成できますか?
トラックプロジェクトを分析する前に、最初に分散型アルゴリズムモデルの重要性を理解しましょう。
本質的に、分散型アルゴリズムネットワークは、多くの異なるAIモデルをリンクする分散型AIアルゴリズムサービス市場です。回答を提供するために質問に答えます。Chat-GPTは、Openaiによって開発されたAIモデルであり、人間に似たテキストを理解して作成できます。
簡単に言えば、ChatGptはさまざまなタイプの問題を解決するための強力な能力を持つ生徒のようなものですが、分散型アルゴリズムネットワークは、長期的な観点から非常に能力がありますが、多くの生徒がいる学校のようなものです。 、世界中の生徒を募集できる学校には大きな可能性があります。
現在、分散型アルゴリズムモデルの分野では、その試みと探索にはいくつかのプロジェクトがあります。
両節では、アルゴリズムモデル(またはマイナー)の供給側が機械学習モデルをネットワークに提供します。これらのモデルはデータを分析し、洞察を提供できます。モデルプロバイダーは、貢献に対する報酬として暗号通貨トークンタオを受け取ります。
質問に対する回答の質を確保するために、Bittensorは一意のコンセンサスメカニズムを使用して、ネットワークが最良の回答に同意することを保証します。複数のモデルマイナーが尋ねられたときに回答を提供します。その後、ネットワーク内のバリデーターが動作を開始し、最良の答えを決定し、ユーザーに送り返します。
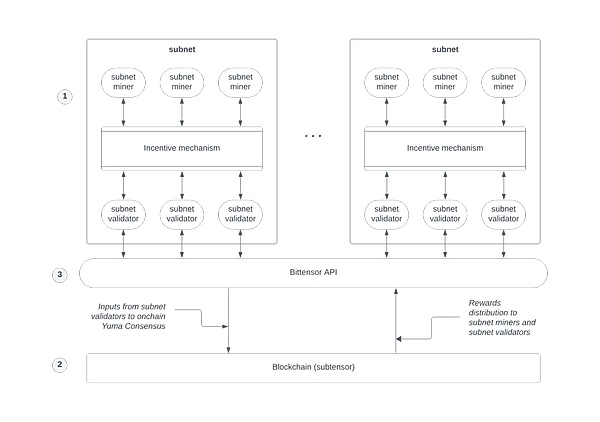
ビテンサーのトークンタオは、主にプロセス全体で2つの役割を果たしています。これは、ネットワークに貢献するために鉱夫を奨励するアルゴリズムモデルとして使用されます。ネットワークの完全なタスク。
Bittensorは分散化されているため、インターネットアクセスを持つ人なら誰でも、ユーザーが質問をすることと、回答を提供する鉱山労働者としてネットワークに参加できます。これにより、より多くの人々が強力な人工知能を使用することができます。
要するに、二文字などのネットワークを例にとると、アルゴリズムモデリングの分散化された分野は、人工知能モデルを安全で分散化した方法でトレーニング、共有、および利用できる、よりオープンで透明な状況を作成する可能性があります。さらに、もちろん、同様のことを試しているような分散型アルゴリズムモデルネットワークがあります。ZKを介してユーザーとモデルのインタラクティブなデータプライバシーを保護することです。
分散型アルゴリズムモデルプラットフォームが進化するにつれて、中小企業がトップAIツールを使用する際に大規模な組織と競争できるようになり、さまざまな産業に潜在的に大きな影響を与えます。
3.1.3分散型データ収集
AIモデルのトレーニングには、大量のデータ供給が不可欠です。ただし、ほとんどのWeb2企業は、たとえば、X、Reddit、Tiktok、Snapchat、Instagram、YouTubeなどのプラットフォームを使用しています。これは、AI業界の発展に対する大きな障害となっています。
ただし、一方で、一部のWeb2プラットフォームは、ユーザーとの利益を共有せずにユーザーデータをAI企業に販売しています。たとえば、RedditはGoogleと6,000万ドルの契約を結び、Googleが投稿でAIモデルをトレーニングさせました。これは、データ収集の権利が大規模な資本とビッグデータパーティーによって占有されていることにつながり、業界の超資産集約型開発につながります。
この現在の状況に直面して、一部のプロジェクトはWeb3とトークンのインセンティブを組み合わせて、分散型のデータ収集を実現します。publicaiを例として、Publicaiユーザーは2種類の役割として参加できます。
-
1つのカテゴリは、AIデータのプロバイダーです。
-
もう1つのカテゴリは、ユーザーがPublicaiデータセンターにログインして、投票するAIトレーニングの最も価値のあるデータを選択できるデータバリデーターです。
その見返りに、ユーザーはこれらの2種類の貢献を通じてトークンのインセンティブを取得し、それにより、データ貢献者と人工知能業界の開発との間の勝利関係を促進することができます。
AIトレーニングのデータを収集することを専門とするPublicaiのようなプロジェクトに加えて、多くのプロジェクトはトークンインセンティブを通じて分散型データを収集しています。 Dimoはユーザーのカーデータを収集し、WIHIは気象データなどを収集します。分散化を通じてデータを収集するこれらのプロジェクトは、潜在的なAIトレーニングの供給側でもあるため、大まかに言えば、AIを支援するためにWeb3のパラダイムに含めることもできます。 。
3.1.4 ZKは、AIのユーザープライバシーを保護します
分散化の利点に加えて、ブロックチェーンテクノロジーは、もう1つの非常に重要なもの、つまりゼロ知識の証明です。ゼロ知識技術を通じて、情報を確認しながらプライバシーを保護できます。
従来の機械学習では、通常、データは中央に保存および処理される必要があり、それがデータプライバシー侵害のリスクにつながる可能性があります。一方、データ暗号化やデータの識別などのデータプライバシーを保護する方法により、機械学習モデルの精度とパフォーマンスが制限される場合があります。
ゼロ認識証明技術は、このジレンマに直面し、プライバシー保護とデータ共有の対立を解決するのに役立ちます。
ZKML(ゼロ知識機械学習)により、ゼロ知識証明技術を使用して生データを明らかにすることなく、機械学習モデルのトレーニングと推論が可能になります。ゼロ知識の証明により、データの特性とモデルの結果は、実際のデータコンテンツを明らかにすることなく正しいことが証明されます。
ZKMLの中心的な目標は、プライバシー保護とデータ共有のバランスをとることです。医療および健康データ分析、財務データ分析、組織間協力など、さまざまなシナリオに適用できます。ZKMLを使用することにより、個人はデリケートなデータのプライバシーを保護しながら、データのプライバシー侵害のリスクを心配することなく、より広範な洞察と協力の機会のために他の人とデータを共有できます。
フィールドはまだ初期段階にあり、たとえばほとんどのプロジェクトはまだ調査中です。Zero Knowledge Large Language Model(ZK-LLM)を使用して、分散ネットワークインフラストラクチャの中心にプライバシーを埋め込み、ユーザーデータがネットワーク操作を通じてプライベートを維持することを保証しました。
ここでは、完全な同種暗号化(FHE)とは何かを簡単に説明します。完全に同種の暗号化は、暗号化された状態のデータを復号化せずに計算できる暗号化技術です。これは、FHEを使用して暗号化されたデータで実行されたさまざまな数学操作(追加、乗算など)を実行して、暗号化されていないデータで同じ操作を実行することで得られた結果を取得することができますユーザーデータの。
さらに、上記の4つのカテゴリに加えて、Web3のAIサポートに関しては、CORTEXのようなブロックチェーンプロジェクトもチェーン上のAIプログラムの実行をサポートしています。現在、従来のブロックチェーンでの機械学習プログラムの実行は、非複雑な機械学習モデルを実行するときに仮想マシンが非常に非効率的である課題に直面しています。したがって、ほとんどの人は、ブロックチェーンで人工知能を実行することは不可能だと考えています。Cortex Virtual Machine(CVM)はGPUを使用してチェーン上でAIプログラムを実行し、EVMと互換性があります。言い換えれば、皮質チェーンはすべてのイーサリアムDAPPを実行し、これに基づいてこれらのDAPPにAI機械学習を組み込むことができます。これにより、ネットワークコンセンサスがAI推論のあらゆるステップを検証するため、分散型で不変で透明な方法で機械学習モデルを動作させることができます。
3.2 AIはWeb3を支援します
AIとWeb3の間の衝突では、Web3のAIへの助けに加えて、Web3業界に対するAIの助けも注目に値します。人工知能の中心的な貢献は、生産性の改善にあります。そのため、AI監査スマート契約、データ分析と予測、パーソナライズされたサービス、セキュリティ、プライバシー保護には多くの試みがあります。
3.2.1データ分析と予測
現在、多くのWeb3プロジェクトは、既存のAIサービス(CHATGPTなど)を統合するか、独自のサービスを開発して、Web3ユーザーにデータ分析と予測サービスを提供し始めています。AIアルゴリズムを介した投資戦略の提供、オンチェーン分析AIツール、価格、市場予測など、幅広い範囲をカバーしています。
たとえば、PondはAIグラフアルゴリズムを使用して、将来的に貴重なアルファトークンを予測し、ユーザーと機関に投資支援アドバイスを提供します。予測価格の傾向をサポートし、ユーザーが利益と利益を得るのに役立ちます。
Numeraiなどの投資競争プラットフォームもあります。Numeraiは、これらの予測が来月にどのように機能するかを計算し、出場者はモデルでNMRに賭けて、モデルのパフォーマンスに基づいてお金を稼ぐことができます。
さらに、Arkhamなどのチェーンデータ分析プラットフォームもAIをサービス用に組み合わせています。Arkhamは、ブロックチェーンアドレスを取引所、資金、巨大なクジラなどのエンティティにリンクし、ユーザーにこれらのエンティティの主要なデータと分析を提供して、意思決定の利点をユーザーに提供します。AIとの組み合わせの一部は、Arkham Ultraがアルゴリズムを使用して、Arkham Coreの貢献者がPalantirとOpenaiの創設者を3年にわたって支援して開発した実際のエンティティとアドレスを一致させることです。
3.2.2パーソナライズされたサービス
Web2プロジェクトでは、AIには検索と推奨の分野に多くのアプリケーションシナリオがあり、ユーザーのパーソナライズされたニーズに応えています。同じことがWeb3プロジェクトでも当てはまります。
たとえば、よく知られているデータ分析プラットフォームであるDuneは、最近、大規模な言語モデルの助けを借りてSQLクエリを作成するためのWandツールを起動しました。WAND CREATE関数を介して、ユーザーは自然言語の問題に基づいてSQLクエリを自動的に生成でき、SQLを理解していないユーザーも非常に簡単に検索できます。
さらに、一部のWeb3コンテンツプラットフォームは、たとえば、ChatGptを統合し始めています。領域ブロックチェーンテクノロジーと暗号通貨に関連するすべての客観的および質の高い知識の主なソースにより、ブロックチェーンはグローバルスケールで容易になり、Wiki記事を要約するためにGPT-4を統合します。 LLMに基づいた検索エンジンであるKaitoは、Web3検索プラットフォームになり、Web3が情報を取得する方法を変更することに取り組んでいます。
作成に関しては、ユーザーの作成コストを削減するNFPROMPTのようなプロジェクトもあります。NFPROMPTを使用すると、ユーザーはAIを介してNFTをより簡単に生成できるため、ユーザーの創造コストが削減され、作成に関して多くのパーソナライズされたサービスが提供されます。
3.2.3 AI監査スマートコントラクト
Web3フィールドでは、スマートコントラクトの監査も非常に重要なタスクです。スマートコントラクトコードの監査は、コードの脆弱性をより効率的かつ正確に識別できます。
Vitalikがかつて述べたように、暗号通貨スペースが直面している最大の課題の1つは、コードのエラーです。そして、期待される可能性の1つは、人工知能(AI)が正式な検証ツールの使用を大幅に簡素化して、特定の属性を満たすコードのセットを証明できることです。これを行うことができれば、エラーのないSEK EVM(イーサリアム仮想マシンなど)がある可能性があります。エラーの数を減らすほど、セキュリティが増加し、AIはこれを達成するのに非常に役立ちます。
たとえば、0x0.AIプロジェクトは、高度なアルゴリズムを使用してスマートコントラクトを分析し、潜在的な脆弱性または詐欺やその他のセキュリティリスクにつながる可能性のある問題を特定するツールである、人工知能スマートコントラクト監査人を提供します。監査人は機械学習手法を使用してコード内のパターンと例外を特定し、さらなるレビューのために潜在的な問題をマークします。
上記の3つのカテゴリに加えて、AIを使用してWeb3フィールドを支援するネイティブケースもありますAIを使用して、トークン全体のトークンと最高のトークンパスを提供するマルチチェーンDex Aggregation Heraは、TokenレベルのヘルパーとしてWeb3を支援します。
AI+Web3プロジェクトの制限と課題
4.1分散化されたコンピューティングパワーにおける実際の障害
AIを支援する現在のプロジェクトの中で、Web3をサポートするプロジェクトの大部分は、分散型のコンピューティングパワーに焦点を当てています。また、解決する必要があるいくつかの実際的な問題もあります。
集中化されたコンピューティング電源サービスプロバイダーと比較して、分散化されたコンピューティングパワー製品は通常、世界中に配布されるノードと参加者に依存してコンピューティングリソースを提供します。これらのノード間のネットワーク接続には遅延と不安定性がある可能性があるため、パフォーマンスと安定性は集中化されたコンピューティングパワー製品よりも悪い場合があります。
さらに、分散化されたコンピューティングパワー製品の利用可能性は、需要と供給の一致度の影響を受けます。十分なサプライヤーがない場合、または需要が高すぎる場合、リソースが不十分またはユーザーのニーズを満たすことができないことにつながる可能性があります。
最後に、分散化されたコンピューティング電源製品には、通常、集中化されたコンピューティングパワー製品よりも多くの技術的な詳細と複雑さが含まれます。ユーザーは、分散ネットワーク、スマートコントラクト、暗号通貨の支払いに関する知識を理解して処理する必要があり、ユーザーの理解と使用のコストが高くなります。
多数の分散化されたコンピューティングパワープロジェクトとの詳細な議論の後、現在の分散型コンピューティングパワーは、AIトレーニングではなくAI推論に限定できることがわかりました。
次に、4つの小さな質問を使用して、その背後にある理由を理解するのに役立ちます。
1.なぜほとんどの分散コンピューティングパワープロジェクトがAIトレーニングの代わりにAI推論を行うことを選択するのですか?
2。Nvidiaはどこに素晴らしいですか?分散化されたコンピューティングパワートレーニングが難しい理由は何ですか?
3.分散化されたコンピューティングパワーの終了(レンダリング、Akash、io.netなど)はどのようになりますか?
4.分散型アルゴリズム(Bittensor)の終わりはどのようになりますか?
次に、レイヤーごとにcoco層を剥がしましょう。
1)このトラックを見ると、ほとんどの分散化されたコンピューティングパワープロジェクトは、トレーニングの代わりにAI推論を行うことを選択します。コアは、電力と帯域幅を計算するためのさまざまな要件です。
みんなをよりよく理解できるようにするには、AIを学生と比較しましょう。
AIトレーニング:人工知能を学生と比較すると、トレーニングは人工知能に多くの知識を提供することに似ており、例としてもよく理解できます。学習の性質には大量の情報の理解と記憶が必要なため、このプロセスには多くのコンピューティングパワーと時間が必要です。
AI推論:では、推論とは何ですか?問題を解決するために学んだ知識を使用したり、推論段階で学んだ知識を使用して、新しい知識に従事するのではなく、理解することができます。 。
2つの難易度の違いは、基本的に大規模なモデルAIトレーニングには膨大な量のデータと高速データ通信に必要な帯域幅が必要であることがわかります。 。ただし、データと帯域幅の推論の必要性ははるかに小さく、実装の可能性は大きくなります。
大きなモデルの場合、最も重要なことは安定性です。一方、上記のAI推論や、いくつかの特定のシナリオの垂直小型および中型モデルのトレーニングなど、比較的低いコンピューティングパワー要件が可能ですこれらの比較的大きなコンピューティングパワーのニーズに応えることができるコンピューティングパワーネットワークで。
2)では、データと帯域幅のジャムポイントはどこにありますか?分散型トレーニングが達成するのが難しいのはなぜですか?
これには、大規模なモデルトレーニングの2つの重要な要素が含まれます。シングルカードコンピューティングパワーと複数のカードが並行して接続されています。
シングルカードコンピューティングパワー:現在、大きなモデルのトレーニングを必要とするすべてのセンターでは、スーパーコンピューティングセンターと呼ばれています。全員の理解を促進するために、人体を比phorとして使用できます。単一のセル(GPU)のコンピューティング能力が非常に強い場合、全体的なコンピューティング能力(単一セルX数)も非常に強い可能性があります。
マルチカードの並列接続:大規模なモデルのトレーニングは、1,000億GBの大規模なモデルの場合、少なくとも1万レベルA100をベースとして使用する必要があります。したがって、これらのトレーニングのためにこれらの数万のカードを動員する必要があります。部分的には、さまざまなグラフィックカードでのトレーニングには、AをトレーニングするときにBの結果が必要になる場合があるため、複数のカードが並行して関与します。
なぜNvidiaはそれほど強力で、その市場価値が離陸しているのに、AMDと国内のHuaweiとHorizonが追いつくことは困難です。コアは、シングルカードコンピューティングパワー自体ではなく、CUDAソフトウェア環境とNVLinkマルチカード通信の2つの側面です。
一方では、NVIDIAのCUDAシステムの構築など、ハードウェアに適応できるソフトウェアエコシステムがあるかどうかが非常に重要です。
一方、それはマルチカード通信です。複数のカード間の送信は、情報の出力、並行してそれを接続する方法、そしてそれを送信する方法です。NVLinkの存在のため、NVIDIAカードとAMDカードを接続することは不可能です。世界中。
最初のポイントは、AMD、Huawei、およびHorizonが現在追いつくのが難しい理由を説明しています。
3)分散化されたコンピューティングパワーの終わりはどのようになりますか?
分散型コンピューティングパワーは、大規模なモデルのトレーニングをトレーニングすることが困難です。複数のカードの並列接続の要件は非常に高く、帯域幅は物理的な距離によって制限されます。NVIDIAはNVLinkを使用してマルチカード通信を実現しますが、Supercomputing Centerでは、NVLinkはグラフィックカード間の物理的距離を制限するため、分散コンピューティングパワーは大規模なトレーニングのためにコンピューティングパワーを形成できません。
しかし、一方、AI推論や、一部の分散コンピューティングパワーネットワークで可能ないくつかの特定のシナリオでの垂直および中型モデルのトレーニングなど、比較的低いコンピューティングパワーの需要が可能です大規模なノードサービスプロバイダーは、これらの比較的大きなコンピューティングパワーニーズに対応する可能性があります。レンダリングなどのエッジコンピューティングシナリオだけでなく、実装も比較的簡単です。
4)分散型アルゴリズムモデルの終わりはどのようになりますか?
分散型アルゴリズムモデルの終わりは、将来のAIの戦いに依存しています。アプリケーションレイヤー製品の1つの大きなモデルにバインドする必要はありませんが、このコンテキストでは、ビテンサーのモデルが大きな可能性を秘めています。
4.2 AI+Web3の組み合わせは比較的粗く、1+1> 2は達成されていません
現在、特にAIとAIを組み合わせたプロジェクトの中で、特にAIの点でWeb3プロジェクトを支援することで、ほとんどのプロジェクトは依然として表面上のAIを使用しており、AIと暗号通貨の間の深い統合を真に反映していません。この種の表面アプリケーションは、主に次の2つの側面に反映されています。
-
まず第一に、データ分析と予測にAIを使用しているか、推奨および検索シナリオでAIを使用するか、コード監査を実行するかにかかわらず、Web2プロジェクトとAIの組み合わせとは大きな違いはありません。これらのプロジェクトは、AIと暗号通貨の間でネイティブの収束と革新的なソリューションを実証することなく、AIを使用して効率を向上させ、分析します。
-
第二に、多くのWeb3チームがAIをさらに組み合わせて、マーケティングレベルでAIの概念を純粋に利用します。彼らは非常に限られた分野でAIテクノロジーを使用したばかりで、AIの傾向を促進し始め、プロジェクトがAIに非常に近いという幻想を生み出しました。ただし、実際のイノベーションの観点から、これらのプロジェクトにはまだ多くのギャップがあります。
現在のWeb3およびAIプロジェクトにはまだこれらの制限がありますが、これは開発の初期段階にすぎないことを認識する必要があります。将来的には、AIと暗号通貨の間の密接な統合を達成し、金融、分散型の自治組織、予測市場、NFTなどの分野でより多くのネイティブで意味のあるソリューションを作成することを期待できます。
4.3トークン経済学はAIプロジェクトの物語のバッファーになります
初めに言及されたAIプロジェクトのビジネスモデルの問題は、ますます多くの大規模なモデルが徐々にオープンソースになり始めているため、多数のAI+Web3プロジェクトをWeb2で開発および調達することが困難な場合が多いため、重ね合わせることを選択します。 Web3の物語。
しかし、本当の鍵は、トークン経済学の統合がAIプロジェクトが実際のニーズを本当に解決するのに本当に役立つか、それが単に物語であるか短期的な価値であるかを実際に疑問視する必要があるかどうかです。
現在、ほとんどのAI+Web3プロジェクトは、より現実的で思慮深いチームがAIプロジェクトの原動力として使用できるだけでなく、実際の需要シナリオを満たすことができることを願っています。
要約します
現在、AI+Web3プロジェクトで多くのケースとアプリケーションが登場しています。まず、AIテクノロジーは、より効率的でインテリジェントなアプリケーションシナリオをWeb3に提供できます。AIのデータ分析と予測機能を通じて、Web3ユーザーは、投資の意思決定やその他のシナリオのより良いツールを持つことができます。同時に、AIテクノロジーは、ユーザーエクスペリエンスを改善するために、分散型アプリケーションに、より正確でインテリジェントな推奨事項とパーソナライズされたサービスを提供することもできます。
同時に、Web3の分散化とプログラマ性は、AIテクノロジーの開発に新しい機会を提供します。トークンのインセンティブを通じて、分散型コンピューティングパワープロジェクトは、AIのコンピューティングパワーと分散ストレージメカニズムの供給のジレンマを提供します。Web3のユーザーの自律性と信頼のメカニズムは、AIの開発に新しい可能性をもたらしました。
現在のAI+Web3クロスオーバープロジェクトはまだ初期段階にあり、直面するのは多くの困難がありますが、多くの利点ももたらします。たとえば、分散型コンピューティングパワー製品にはいくつかの欠点がありますが、集中型機関への依存を減らし、透明性と監査可能性を高め、より広範な参加とイノベーションを可能にします。分散型コンピューティング電源製品は、特定のユースケースとユーザーのニーズに合わせて価値がありますデータのカバレッジと促進データの多様性と包含など。実際には、これらの利点と欠点を比較検討し、管理する必要があり、分散型のデータ収集プロジェクトがAIの開発にプラスの影響を与えることを保証するために課題を克服するために技術的な措置が講じられています。
一般に、AI+Web3の統合は、将来の技術革新と経済発展のために無制限の可能性を提供します。AIのインテリジェントな分析と意思決定能力を、Web3の分散化とユーザーの自律性と組み合わせることにより、将来的には、よりスマートで、よりオープンで公正な経済的、さらには社会システムを構築できると考えています。







