
Writing: Preda Source: Chainfeeds
summary
Looking at the parallel history of the computer: the parallelism of the first level isInstruction level parallelEssenceInstruction -level parallel is the main way to improve performance in the last 20 years of the 20th century.Instruction -level parallelism can improve performance on the premise that the program is binary compatible, which is particularly liked by programmers.There are two types of instructions in parallel.One is the time parallel, that is, the instruction assembly line.The order of the assembly line is just like the assembly line of the factory production of a car. The car production plant will not wait for a car to install it. After the production of a car, start the production of the next car. Instead, it will produce multiple cars at the same time in multiple processes.The other is space parallel, that is, more launch, or exceeding the standard.Multi-launch is like a multi-lane road, and the Out-OF-Order Execution is allowed to overtake on multi-lanes. Excessive amounts and sequential execution are often used together to improve efficiency.After the emergence of RISC in the 1980s, the subsequent 20 -year instruction level parallel development reached a peak. After 2010, the space for further tapping instruction levels was not large.
The parallelism of the second level isData -level parallel, It mainly refers to the vector structure of the single stream (SIMD).The earliest data -level parallel line appeared on ENIAC.The vector machine represented by CRAY in the 1960s and 1970s was very popular. From CRAY-1, CRAY-2, to later Cray X-MP, Cray Y-MP.Until Cray-4, SIMD was silent for a while, and now he began to recover vitality again, and it was used more and more.For example, the AVX multimedia instructions in X86 can use 256 -bit channels to make four 64 -bit operations or eight 32 -bit operations.SIMD, as an effective supplement of parallel instructions, has played an important role in the field of streaming media. It was mainly used in special processors in the early days, and it has now become the standard for general processors.
The third level of parallelism isMission -level parallelEssenceA large number of task -level parallel is in the Internet application.The representative of the task -level parallel is a multi -core processor and a multi -threaded processor, which is the main method for the current computer architecture to improve performance.The parallel granularity of the task -level parallel is large, and a thread contains hundreds of or more instructions.
From the perspective of parallel computing development, what is now in the first level of the blockchain is the process of transition from the first level to the second level.The mainstream blockchain system usually adopts two architecture: single or multi -chain architecture.Single chain, such as common Bitcoin and Ethereum, the entire system has only one chain. Each node of the chain executes exactly the same smart contract transactions to maintain a completely consistent chain state.In each blockchain node, smart contract transactions are usually executed in serial execution, resulting in a low throughput of the entire system.
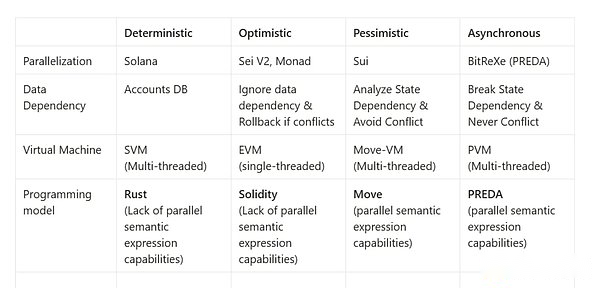
Some of the recent high -performance blockchain systems, although the single -chain architecture is adopted, also supports parallel execution of smart contract transactions.Thomas Dickerson and Maurice Herlihy of Brown University and Yale University first proposed a parallel execution model based on STM (Software Transactional Memory) in its Podc’17 paper. MoreThe transaction is executed parallel. If the transaction encounters a state access conflict during parallel execution, it will complete the status rollback through STM, and then perform these state conflict transactions serialized serially.Such methods have been applied to multiple high -performance blockchain projects, including Aptos, SEI and Monad.Correspondingly, another parallel execution model is based on PESSIMISTIC Concurrency (pessimistic parallel), that is, before the transaction is executed parallel execution, there is a conflict between the state of transaction access. Only a transaction that does not have conflicts can be executed parallel.This type of method usually uses a pre-compute method to use program analysis tools to make static analysis and construct status dependencies on smart contract code, such as the direction of non-loop graph (DAG).When the concurrent transaction is submitted to the system, the system determines whether the transaction can be executed parallel according to the state of the transaction needs and the dependency relationship between the transaction needs.Only transactions that have no state -dependent relationship between each other will be executed parallel.This kind of method is applied to Zilliqa (COSPLIT version) and high -performance blockchain projects such as SUI.The above parallel execution models can significantly improve the throughput of the system.These two schemes correspond to the instruction level mentioned above parallel.However, there are two problems in these tasks: 1) scalability problems and 2) Parallel semantic expression issues, we will explain in detail below.
Parallel Design
We will use the typical Solana and Monad project as an example to disassemble their parallel architecture design. This includes parallelization classification, data dependence, etc. It will affect the key indicators of parallelism and TPS.
Solana
From a higher level, Solana’s design concept is that blockchain innovation should develop with the advancement of hardware.With the continuous improvement of hardware according to Moore’s law, Solana aims to benefit from higher performance and scalability.Solana co -founder Anatoly Yakovenko initially designed the parallelization architecture of Solana more than five years ago. Nowadays, the parallelism as a blockchain design principle is rapidly spreading.
Solana useDefirmation parallelism(Deterministic Parallelization), which comes from Anatoly’s experience in using embedded systems in the past, developers usually declare all states in advance.This enables the CPU to understand all dependencies, so as to prefers the necessary part of memory.The result is to optimize the implementation of the system, but the same, it requires developers to do additional work in advance.On Solana, all the memory dependencies of the program are necessary, and explain in the constructor (that is, the access list), so that the runtime can efficiently tune and perform multiple transactions.
The next main component of the Solana architecture isSealevel vm,,It supports multiple contracts and transactions in parallel according to the core quantity of the verification device.The verifications in the blockchain are network participants, responsible for verifying and confirming transactions, proposing new blocks, and maintaining the integrity and security of the blockchain.Since the transaction pre -states which accounts need to be read and write and locked, the Solana scheduling program can determine which transactions can be executed concurrently.Because of this, during verification, “block producers” or leaders can sort thousands of to be processed transactions, and parallel adjustment of non -overlapping transactions.
Monad
Monad is building the first layer of parallel EVM with a complete parallel EVM.The uniqueness of Monad lies not only its parallel engine, but also the optimization engine they built in the background.Monad uses a unique method for its overall design, combining several key functions, including pipelines, asynchronous I/O, separation consensus and execution, and MonaddB.
Similar to SEI, Monad blockchain use“Optimism and Pass Control (OCC)”Come to execute the transaction.When multiple transactions exist in the system at the same time, concurrent transactions occur.There are two stages of this transaction method: execution and verification.
During the execution stage, transactions are optimistic, and all reading/writing is temporarily stored in a specific storage of transactions.Since then, each transaction will enter the verification stage, which will be changed to check the information in the temporary storage operation according to any status made by the previous office.If the transaction is independent, the transaction runs parallel.If one transaction reads the data of another transaction modification, conflict will be generated.
A key innovation designed by Monad is a rail with a slight offset.This offset allows more processes in parallelization by running multiple instances at the same time.Therefore, the assembly line is used to optimize many functions, such as status access to Pipeline, transaction execution PIPELINE, consensus and PIPELINE, and PIPELIN in the consensus mechanism itself. In the figure below, laundry, drying, stacking clothes and putting them into the wardrobe.
>
In Monad, transactions are sorted in linear in the block, but the goal is to achieve the final state by using parallel execution.MonadOptimistic and parallelismA algorithm to design the execution engine.Monad’s engine handles the transaction at the same time and then analyze to ensure that if the transaction is executed one after another, the results will be the same.If there are conflicts, you need to re -execute.The parallel execution here is a relatively simple algorithm, but it combines it with other key innovations of Monad to make this method novel.One thing that needs to be noted here is that even if re -execution occurs, it is usually very cheap, because the input required by invalid agencies always always keeps the cache, so this will be a simple cache search.Re -execution will be successful because you have already executed the previous transactions.
In addition to delaying execution,Monad also improves performance by separating execution and consensusSimilar to Solana and SEI.The idea here is that if you relax the conditions to complete the execution when the consensus is completed, the two can be run parallel to bring extra time to the two.Of course, Monad uses a certainty algorithm to deal with this situation to ensure that one of them will not run too far and cannot catch up.
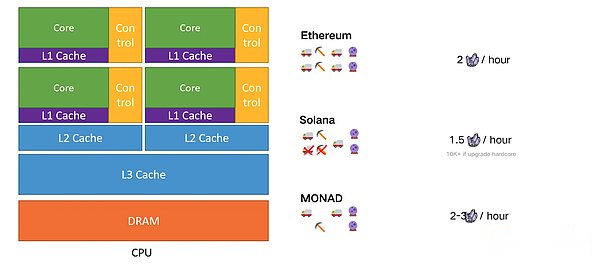
Regardless of whether optimistic parallel or pessimistic execution methods, the above systems use Shared-Memory as the bottom-layer data model abstraction, that is, no matter how much parallel units are, parallel units can obtain all data (here refers to all the data on the blockchain data), Status data can be directly accessed by different parallel executions (that is, all data on all chains can be read and write directly in parallel).Use Shared-Memory as a blockchain system as the underlying data model. Its concurrency is usually limited to a single physical node (Solana).Each thread supports a virtual machine).
This kind of parallel method in this node only needs to modify the architecture of the executive layer of the smart contract, and does not need to modify the logic of the system consensus layer, which is very suitable for improving the throughput of the single -chain system.Therefore, because there is no slice of data storage,Each node in the blockchain network still needs to execute all transactions and store all statesEssenceAt the same time, compared to the Shared-Nothing architecture that is more suitable for distributed extensions, these use Shared-Memory as an abstract system abstraction of the underlying data model. Their processing capabilities cannot be expanded horizontally.System status storage and expansion of execution capabilities cannot fundamentally solve the scalability of the blockchain.
So is there a ready -made solution?
Parallel Programming Model
Before introducing Preda, we hope to ask a natural question::Why use parallel programming?In part of the 1970s, 1980s, and even part of the 1990s, we were very satisfied with single -threaded programming (or serial programming).You can write a program to complete a task.After the execution is over, it will give you a result.The task is completed, everyone will be very happy!Although the task has been completed, but if you are making millions or even billions of calculated particle simulation per second, or you are processed with thousands of pixel images, you will want the program to run fasterThis means that you need a faster CPU.
Before 2004, the CPU manufacturer IBM, Intel and AMD can provide you with a faster and faster processor.MHz, 466 MHz ⋯ ⋯ look like they can constantly increase the speed of the CPU, that is, they can continuously improve the performance of the CPU.But by 2004, due to technical restrictions, the trend of increasing the CPU speed cannot continue.This requires other technologies to continue to provide higher performance.The CPU manufacturer’s solution is to put the two CPUs in one CPU, even if the two CPUs work speed lower than a single CPU.For example, compared with the single -core CPU at the speed of 300 MHz, two CPUs (manufacturers call them the core) at 200 MHz speed can perform more calculations per second (that is, intuitive intuitive intuition, intuitiveLook at 2 × 200 & gt; 300).
It sounds like a dream “single CPU multi -core” story becomes reality, which means that programmers must now learn parallel programming methods to use these two cores.If a CPU can perform two programs at the same time, the programmer must write these two programs.But can this be transformed into two times the program running speed?If not, then the idea of our 2 × 200 & gt; 300 is problematic.What if a core does not have enough work?In other words, only one core is really busy, but the other core does nothing?In this case, it is better to use a single core of 300 MHz.After the introduction of multi -core, many similar problems are very prominent. Only through programming can we use these cores efficiently.
>
In the figure below, we imagine BOB and Alice as two gold rushists, and the gold rush requires four steps:
-
Drive to the mine
-
mining
-
Loading ore
-
Store and polished
>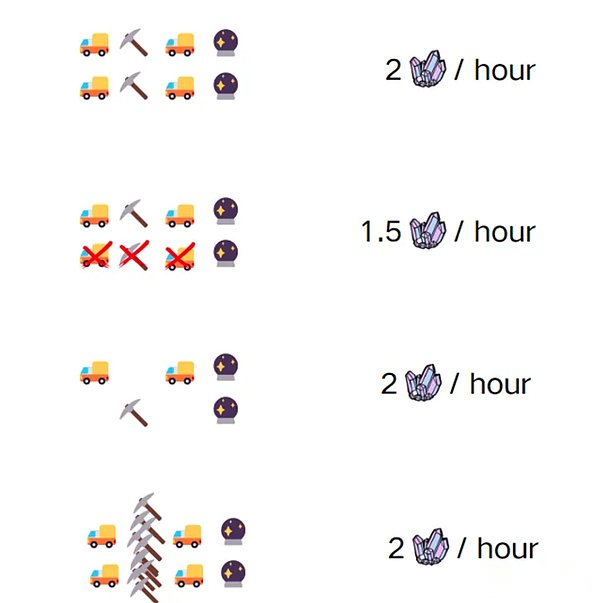
The entire mining process consists of four independent but orderly tasks, and each task takes 15 minutes.When BOB and Alice are ongoing at the same time, they can complete twice the mining workload in one hour -because they have their own cars, they can share the road, and they can share the polishing tool.
But if one day, the BOB mining vehicle fails.He left the mining car in the repair shop and forgot the iron pick of the mining mining car.It was too late to return to the processing plant, but they still had a job to do.Can they use Alice’s mining vehicle and a handle inside, can they still pick two ore per minute?
In the above -mentioned analogy, the four steps of mining are threads, and mining cars are core (Core); mining is the data unit that intelligent contracts need to execute; iron picks are executed units; this program consists of two interdependent threads composition: Before the execution of thread 1, you cannot execute thread 2.The number of harvested minerals means program performance.The higher the performance, the higher the benefits of Bob and Alice.You can think of the mine as memory, and you can get a data unit (gold mine) from it, so that the process of picking a ore in thread 1 is similar to reading data units from memory.
Now, let’s see what will happen if the BOB’s mining vehicle fails.Bob and Alice need to share a car, which is not a problem at first. Under the premise of ensuring the efficiency of mining, the mining equipment becomes different.The overall efficiency bottleneck, because the efficiency of the mining machine used is high, the number of ore that can be sent to polished is restricted by the “maximum mining car can accommodate minerals”.
This is also the parallel VM nature of Solana, core sharing.
Core sharing
Solana’s final design element is“Pipeline”EssenceWhen the data needs to be processed through a series of steps and different hardware is responsible for each step, the assembly line operation appears.The key idea here is to obtain data that requires serial operation and use the pipeline to make it parallel.These pipes can run parallel, and each pipeline can handle different transaction batches.The higher the processing speed of the hardware (mining vehicle loading capacity), the higher the parallelization Throughout.Today, Solana’s hardware node requires that its node operators have only one choice -data center, which brings efficiency but departs from the original intention of the blockchain.
Data dependence is not split (memory resource sharing)
After upgrading the mining vehicle, because the mining capacity cannot keep up, many times the mining vehicle is dissatisfied.So BOB spent a high price to purchase mining machines, which improved the efficiency of mining (execution unit upgrade).10 copies of minerals can be produced in the same 15 minutes, but because the grinding work is still done by hand, the ore generated by more units of time has not been converted into more gold, and more ore is squeezed by squeezing.In the warehouse; this example shows what happens when accessing memory is a limited factors for our program execution speed.How fast the processing data is (that is, the core operation speed) is irrelevant.We will be limited by data acquisition speed.
The slower I/O speed will seriously trouble us, because I/O is the slowest part of the computer, and the asynchronous reading of the data (ASYNCHRONOUS I/O) will become crucial.
Even if BOB can dig 10 mining machines in 15 minutes, if the memory access competition is existing, they will still be limited to 2 mining of 2 parts every 15 minutes.The existing parallel blockchain schemes are divided into two factions -pessimistic execution and optimistic execution of the solution proposed by this issue.
The former requires the dependence of data status before data writing and reading. This requires developers to make pre -static control dependencies. In the field of smart contract programming, these assumptions often deviate from reality.The latter does not make any assumptions and restrictions on writing data.
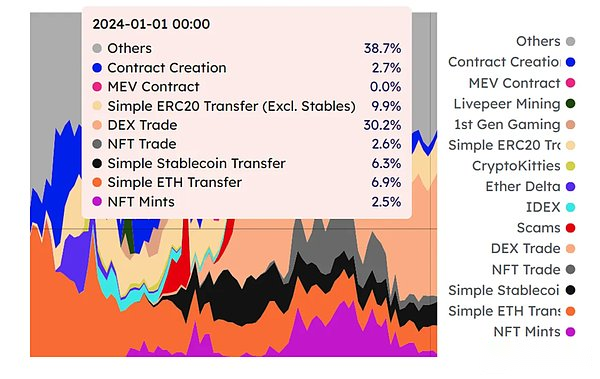
Exampled by Monad’s optimistic execution plan: The reality is that most of the workload is transaction execution, and the scenes that occur in parallel are not as expected.The picture below is Ethereum’s GAS Fee consumption source type; you will find that although the proportion of smart contracts with no popularity in this distribution is so high, in fact, different types of transaction types do have no uniform distribution.The parallel logic of optimistic execution is feasible in the web2 era, because a large part of the Web2 application requests are access, not modification; such as Taobao and Douyin, you don’t actually have much opportunity to modify the status of these apps.However, the web3 field is just the opposite. The request of most smart contracts is exactly the modification state -updating the ledger, which will actually bring more rollbacks in addition to expectations, making the chain unavailable.
>
So the conclusion is that Monad can indeed reach parallel, butConcurrency exists in the theoretical limit, that is, it falls in the interval of 2 to 3 times, Not the 100K of its propaganda.Secondly, there is no way to expand this upper limit by increasing the virtual machine, that is, there is no way to achieve multi -core equivalent to increasing the processing ability.Finally, it is a problem that is always talking, because there is no slicing data, Monad does not actually answer the requirements of the node after the expansion of the state expansion.And with its main network, if the data is not sliced, we may inevitably see Monad’s way to Solana.In the end, the most important point is that optimistic implementation is not suitable for parallel in the blockchain field.
>
After the mining for a while, Bob asked himself a question: “Why should I wait for Alice to come back and then polish? When he is polished, I can load the car, because the time for loading and polishing is exactly the same, we must not encounter it.Until waiting to be polished and idle. Before Alice completes the mining, I will drive to continue mining so that both of us can be 100% busy.No additional mining carts are needed.The important thing is that the BOB has redesigned the program, that is, the order of thread execution, so that all threads will never fall into the state of waiting for the core sharing resources (such as mining cars and stone picks).
This is the correct version of parallel. Through the division of the state of smart contracts, accessing shared resources will neither cause a thread to enter the queue, nor will it limit the speed of the final atomicity due to the pipeline of data I/O.
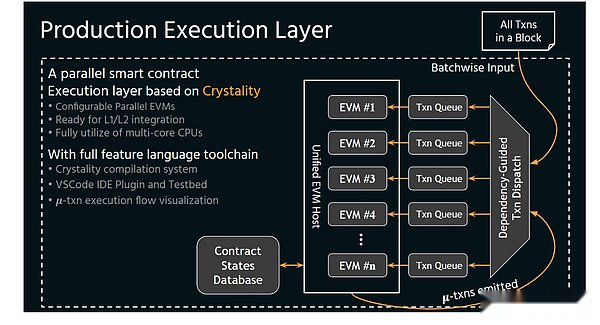
The Preda model is exposed to the execution layer by exposing the access structure of the contract code at the time of the contract code, so that the execution layer can easily schedule and completely avoid the rollback of the results.This parallel mode is also called asynchronous.
Asynchronous
>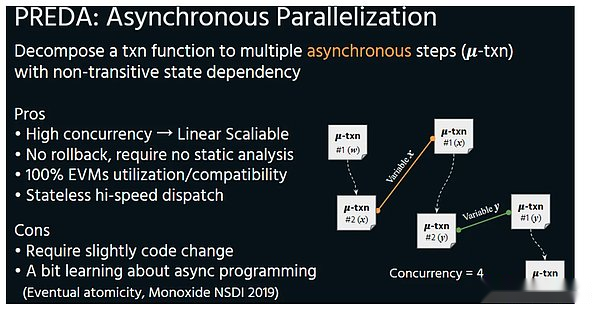
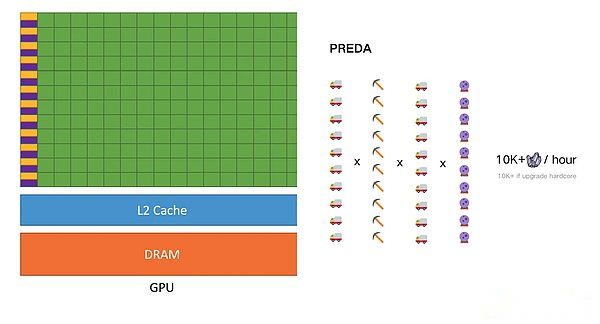
Because only in parallel is asynchronous, increasing threads will come to the linear improvement.Instead of upgrading the capacity of the mining vehicle like the previous example, but the mining vehicle runs empty because of the backward mining equipment.The parallel execution environment of Preda is the most essential difference between Solana -just like the difference between multi -core CPU and GPU.Data dependence, and more importantly, the parallelism of Porta’s parallel model will increase due to the increase in threads, which is the same as the GPU.In the logic of the blockchain, the increase of the thread (VM) will reduce the hardware demand of the entire node, thereby achieving performance improvement under the premise of ensuring decentralization.
>
>
In the end, the end of this parallel blockchain. In addition to the architecture design, but also the semantic expression of parallel programming language.
Semantic expression of parallel programming language
Just like NVIDIA requires CUDA, and the parallel blockchain also needs new programming languages: Preda.The developers of today’s smart contracts are expressed in parallel semantics, which cannot effectively use the support provided by the underlying multi -chain architecture (data sharding or execution of shards or both), and cannot achieve the effective parallel parallel of general smart contract transactions.All systems use traditional common smart contract programming languages such as Solidity, MOVE, Rust.These programming languages lack the ability of parallel semantic expression, that is, do not have the ability to control and data flow between parallel programming models and programming language expression like CUDA or parallel programming models in the field of high -performance computing or big data fields like CUDA.
The lack of parallel programming models and programming languages suitable for smart contracts will cause the application and algorithm from serial to parallel restructuring cannot be completed. As a result, the application and algorithm cannot be adapted with parallel execution capabilities with the bottom layer.Improve the implementation efficiency of applications and the overall throughput of the blockchain system.
This distributed programming model proposed by Preda, through the scope of a programmatic contract, conducts fine -granularity division of the contract status, and distributes transaction execution flow decomposition through functional relay delay through functional relay relay.Essence
This model also defines the division scheme of the contract status through the programmatic contract scope, allows developers to optimize according to the application access mode of the application.Through asynchronous functional relay, the transaction execution flow can be moved to the execution engine that needs to be accessed, and the movement of the execution process is moved instead of data movement.
This model realizes the distribution of distribution and transaction flow of the contract state without the need for developers to care about the details of the underlying multi -chain system.The experimental results show that the Preda model on the 256 execution engine can achieve a maximum of 18 times throughput, which is close to the theoretical parallel limit.Through the use of partition counter and exchange instructions, further enhances parallelism.
Conclusion
The blockchain system traditionally uses a single order execution engine (such as EVM) to handle all transactions, thereby limiting scalability.The multi -chain system runs a parallel execution engine, but each engine handles all transactions of smart contracts and cannot achieve scalability at the contract level.This article discusses the essential core sharing of the permanent parallelism represented by Solana, and why is it possible for the optimism and behavior represented by Monad to run & amp in the real blockchain application scenario.And introduced the parallel execution engine of Preda.The Preda team proposed a novel programming model that expands a single smart contract by dividing the status of smart contracts and allocating transaction flows across the engine.It introduces the scope of programmable contracts to define the division of contract status.Each scope runs on a dedicated execution engine.Asynchronous functional relay is used to decompose transaction execution streams, and moves it across the engine when staying elsewhere.
>
This combines transaction logic with the contract status partition, which allows inherent parallelism without data moving overhead.Its parallel model has split status not only at the smart contract, decoupled the dependence of the data release level, but also provides a MOVE Multi-Threaded executing engine cluster architecture.More importantly, it innovatively launched a new programming model Preda, which may be the last puzzle reached by the blockchain parallel.
>







{kind=link}
{kind=link}