Auteur: Wuyue, Geek Web3
Aujourd’hui, la technologie de la blockchain devient de plus en plus rapide, l’optimisation des performances est devenue un problème clé.
Dans les articles précédents –« En regardant l’optimisation de l’EVM parallèle de Reddio »Dans cet article, nous avons brièvement résumé les idées de conception EVM parallèles de Reddio, et dans l’article d’aujourd’hui, nous fournirons une interprétation plus approfondie de ses solutions techniques et de ses scénarios combinés avec l’IA.
Étant donné que la solution technique de Reddio adopte CUEVM, il s’agit d’un projet qui utilise GPU pour améliorer l’efficacité d’exécution de l’EVM, nous commencerons par CUEVM.
Aperçu de CUDA
CueVM est un projet qui accélère EVM avec des GPU, qui convertit l’opcode de Ethereum EVM en noyaux Cuda pour une exécution parallèle sur les GPU NVIDIA.Grâce à la puissance de calcul parallèle du GPU, l’efficacité d’exécution des instructions EVM est améliorée.Peut-être que les utilisateurs de n par carte entendront souvent le mot cuda –
Calculez l’architecture de l’appareil unifié, qui est en fait une plate-forme informatique parallèle et un modèle de programmation développé par NVIDIA.Il permet aux développeurs d’utiliser la puissance de calcul parallèle des GPU pour effectuer l’informatique générale (comme l’exploitation minière dans la crypto, les opérations ZK, etc.),Non seulement limité au traitement graphique.
En tant que cadre informatique parallèle ouvert, CUDA est essentiellement une extension de la langue C / C ++, et tout programmeur sous-jacent qui connaît C / C ++ peut rapidement commencer.Un concept très important dans CUDA est le noyau (fonction du noyau), qui est également une fonction C ++.

Mais contrairement aux fonctions C ++ régulières qui ne sont exécutées qu’une seule fois, ces fonctions de noyau sont démarrées de syntaxe& lt; & lt; & lt; ... & gt; & gt; & gt;Lorsqu’il est appelé, n différents threads CUDA seront exécutés n fois en parallèle.
Chaque thread de CUDA se voit attribuer un ID de thread indépendant et adopte une hiérarchie de threads, attribuant des threads en blocs et grilles pour faciliter la gestion d’un grand nombre de threads parallèles.Grâce au compilateur NVCC de NVIDIA, nous pouvons compiler le code CUDA dans des programmes qui peuvent s’exécuter sur le GPU.

Flux de travail de base de CUEVM
Après avoir compris une série de concepts de base de CUDA, vous pouvez jeter un œil au flux de travail de CueVM.
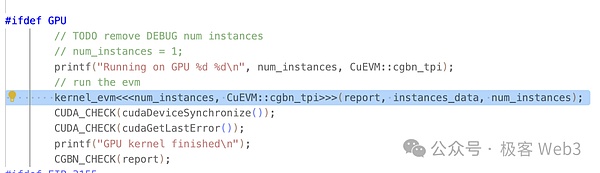
L’entrée principale de CueVM est Run_interpreter.À partir des cas d’utilisation du projet, nous pouvons voir que toutes les entrées sont du contenu EVM standard, et il n’est pas nécessaire que les développeurs soient traités, traduites, etc.

Comme vous pouvez le voir dans run_interpreter (), il appelle la fonction du noyau Kernel_evm () à l’aide de la syntaxe définie par CUDA.Comme nous l’avons mentionné ci-dessus, les fonctions du noyau sont appelées en parallèle dans le GPU.
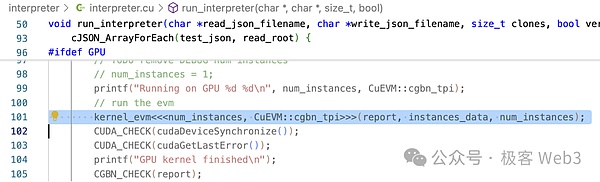
EVM- & gt; run () sera appelé dans la méthode kernel_evm ().
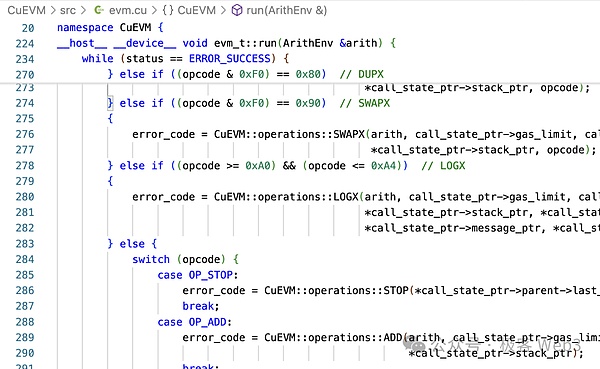
En prenant l’addition OPCode OP_ADD dans EVM à titre d’exemple, vous pouvez voir qu’il convertit ajouter en CGBN_ADD.CGBN (Groupes coopératifs Big Numbers) est la bibliothèque de l’opération arithmétique entière multi-précision de CUDA.

Ces deux étapes convertissent l’opcode EVM en opération CUDA.On peut dire que CUEVM est également une implémentation de toutes les opérations EVM sur CUDA.Enfin, la méthode run_interpreter () renvoie le résultat de l’opération, c’est-à-dire l’état mondial et d’autres informations.
À ce stade, la logique de fonctionnement de base de CUEVM a été introduite.
CUEVM a la capacité de traiter les transactions en parallèle, mais l’objectif de l’établissement du projet CUEVM (ou les principaux cas d’utilisation) est utilisé pour les tests de fuzzing:Fuzzing est une technologie de test de logiciels automatisée qui identifie les erreurs potentielles et les problèmes de sécurité en entrant de grandes quantités de données invalides, inattendues ou aléatoires dans un programme pour observer la réponse du programme.
Nous pouvons voir que le fuzzing est très adapté au traitement parallèle.CUEVM ne gère pas les conflits de transaction et d’autres problèmes, ce qui n’est pas le problème qui les préoccupe.Si vous souhaitez intégrer CUEVM, vous devez également gérer les transactions conflictuelles.
Notre article précédent« En regardant l’optimisation de l’EVM parallèle de Reddio »Le mécanisme de gestion des conflits utilisé par Reddio a été introduit dans cet article et ne sera pas discuté ici.Après que Reddio ait trier les transactions avec le mécanisme de traitement des conflits, il peut être envoyé à CueVM.En d’autres termes, le mécanisme de tri des transactions de Reddio L2 peut être divisé en deux parties: Traitement des conflits + exécution parallèle CUEVM.
Couche2, EVM parallèle, intersection à trois voies de l’IA
Comme mentionné précédemment, le parallèle EVM et L2 ne sont que le point de départ de Reddio, et sa future feuille de route le combinera clairement avec le récit de l’IA.Reddio, qui utilise GPU pour les transactions parallèles à grande vitesse, convient naturellement aux opérations de l’IA dans de nombreuses fonctionnalités:
-
Les GPU ont de fortes capacités de traitement parallèle et conviennent pour effectuer des opérations de convolution en profondeur, qui sont essentiellement des multiplications matricielles à grande échelle, et les GPU sont optimisés pour de telles tâches.
-
La structure hiérarchique du thread de GPU peut correspondre à la correspondance entre les différentes structures de données dans l’informatique de l’IA, l’amélioration de l’efficacité informatique et le masquage de latence de la mémoire par le biais des unités de sumission des threads et d’exécution de la chaîne.
-
La force de calcul est un indicateur clé pour mesurer les performances de calcul de l’AI.
Alors, comment combinons-nous l’IA et le L2?
Nous savons que dans la conception de l’architecture de Rollup, l’ensemble du réseau n’est pas seulement un trieur, mais aussi des rôles similaires aux superviseurs et aux transitaires pour vérifier ou collecter des transactions.Dans le Rollup traditionnel, les fonctions et l’autorité de ces rôles secondaires sont très limitées.
Reddio adoptera une architecture de trieur décentralisée et les mineurs fournissent un GPU comme nœuds.L’ensemble du réseau Reddio peut passer d’un L2 pur à un réseau complet L2 + AI, qui peut bien implémenter certains cas d’utilisation AI + Blockchain:
Le réseau interactif de base de l’agent d’IA
Avec l’évolution continue de la technologie blockchain, l’agent d’IA a un grand potentiel d’application dans les réseaux de blockchain.Prenons l’exemple de l’agent d’IA qui exécute les transactions financières.Cependant, L1 est fondamentalement impossible à transporter d’énormes charges de transaction lors de la gestion de ces opérations intensives.

En tant que projet L2, Reddio peut considérablement améliorer les capacités de traitement parallèle des transactions grâce à l’accélération du GPU.Par rapport à L1, L2, qui prend en charge l’exécution des transactions parallèles, a un débit plus élevé et peut gérer efficacement les demandes de transaction à haute fréquence à un grand nombre d’agents d’IA pour assurer un fonctionnement en douceur du réseau.
Dans le trading à haute fréquence, les agents de l’IA ont des exigences extrêmement strictes sur la vitesse de transaction et le temps de réponse.L2 réduit le temps de vérification et d’exécution des transactions, réduisant ainsi considérablement la latence.Ceci est crucial pour les agents de l’IA qui nécessitent des réponses en millisecondes.En migrant un grand nombre de transactions vers L2, le problème de congestion sur le réseau principal a également été efficacement atténué.Rendre les agents d’IA plus rentables.
Avec la maturité de projets L2 tels que Reddio, l’agent AI jouera un rôle plus important dans la blockchain et promouvra l’innovation dans la combinaison de Defi et d’autres scénarios d’application de la blockchain avec l’IA.
Marché de la puissance de calcul décentralisée
À l’avenir, Reddio adoptera une architecture de trieur décentralisée, et les mineurs utiliseront le pouvoir de calcul du GPU pour déterminer les droits de tri.
Construisez un marché de l’énergie informatique GPU décentralisée pour fournir des ressources de puissance informatique à moindre coût pour la formation et le raisonnement de l’IA.De la petite puissance de calcul, des ordinateurs personnels aux grappes de salles d’ordinateur, la puissance de calcul du GPU de tous les niveaux peut rejoindre le marché pour contribuer leur puissance de calcul inactive et gagner des bénéfices. . Développement et application du modèle AI.
Dans les cas d’utilisation du marché de la puissance de calcul décentralisée, le trieur peut ne pas être principalement responsable de l’informatique directe de l’IA.Quant à la puissance de calcul et à l’allocation des tâches, il y a deux modes:
-
Allocation centralisée descendante.En raison du trieur, le trieur peut attribuer les demandes de puissance de calcul reçues aux nœuds qui répondent aux besoins et ont une bonne réputation.Bien que cette méthode de distribution ait des problèmes théoriquement centralisés et déloyaux, en fait, les avantages d’efficacité qu’elle apporte de loin dépassent ses inconvénients. , il y a des contraintes implicites mais directes garantissent que le trieur n’a pas de biais trop grave.
-
Sélection de tâches spontanées ascendante.Les utilisateurs peuvent également soumettre des demandes de fonctionnement de l’IA aux nœuds tiers, ce qui est évidemment plus efficace dans des champs d’application d’IA spécifiques que de les soumettre directement au trieur, et peut également empêcher l’examen et le biais du trieur.Une fois le calcul terminé, le nœud synchronise les résultats du calcul au trieur et les met sur le lien.
Nous pouvons voir que dans l’architecture L2 + AI, le marché de la puissance de calcul a une flexibilité extrêmement élevée et peut rassembler la puissance de calcul à partir de deux directions pour maximiser l’utilisation des ressources.
Raisonnement de l’IA en chaîne
À l’heure actuelle, la maturité du modèle open source est suffisante pour répondre à divers besoins.Avec la normalisation des services de raisonnement d’IA,Explorez comment mettre la puissance de calcul sur la chaîne pour obtenir des prix automatisés.Cependant, cela nécessite de surmonter plusieurs défis techniques:
-
Distribution et enregistrement de demande efficace:Le raisonnement grand modèle nécessite une latence élevée et un mécanisme de distribution de demande efficace est très critique.Bien que les données des demandes et des réponses soient énormes et privées, et ne doivent pas être exposées sur la blockchain, il est également nécessaire de trouver un équilibre entre l’enregistrement et la vérification – par exemple, en stockant le hachage.
-
Vérification de la sortie du nœud d’alimentation du calcul:Le nœud a-t-il vraiment terminé les tâches informatiques formulées?Par exemple, le Node False Reporting utilise les résultats de calcul de petits modèles au lieu de grands modèles.
-
Raisonnement de contrat intelligent: Il est nécessaire d’utiliser des modèles d’IA en combinaison avec des contrats intelligents pour l’informatique dans de nombreux scénarios.Étant donné que le raisonnement de l’IA est incertain et ne peut pas être utilisé pour tous les aspects de la chaîne, la logique des futurs DAPP IA est susceptible d’être en partie située hors de la chaîne et l’autre partie est des contrats en chaîne. Les entrées fournies hors chaîne. et la légalité numérique est limitée.Dans l’écosystème Ethereum, la combinaison avec des contrats intelligents doit faire face à la sérialité inefficace de l’EVM.
-
Le trieur est beaucoup plus efficace que L1 et peut être considéré comme équivalent à l’efficacité de Web2.Quant à l’emplacement d’enregistrement et à la méthode de rétention des données, diverses solutions DA bon marché peuvent être résolues.
-
Les résultats de calcul de l’IA peuvent être finalement vérifiés par ZKP.La caractéristique de ZKP est que la vérification est très rapide, mais la génération de preuve est lente.La génération de ZKP est capable d’utiliser l’accélération GPU ou TEE.
-
Solidty → CUDA → GPU La ligne principale parallèle EVM est la base de Reddio.Ainsi, c’est la question la plus simple pour Reddio.Actuellement, Reddio travaille avec Eliza d’AII6Z pour présenter ses modules à Reddio, ce qui est une direction très valable à explorer.
Mais dans l’architecture de Reddio, ceux-ci sont relativement faciles à résoudre:
Résumer
Dans l’ensemble, les champs des solutions de couche
En tirant parti des caractéristiques informatiques parallèles des GPU, Reddio améliore la vitesse de transaction et l’efficacité sur la couche2, améliorant les performances de Ethereum Layer 2.L’intégration de la technologie de l’IA dans la blockchain est une tentative nouvelle et prometteuse.L’introduction de l’IA peut fournir une analyse intelligente et un soutien à la prise de décision pour les opérations sur la chaîne, réalisant ainsi des applications de blockchain plus intelligentes et dynamiques.Cette intégration transversale a sans aucun doute ouvert de nouvelles voies et opportunités pour le développement de l’ensemble de l’industrie.
Cependant, il convient de noter que ce domaine en est encore à ses débuts et nécessite encore beaucoup de recherche et d’exploration.L’itération et l’optimisation continue de la technologie, ainsi que l’imagination et les actions des pionniers du marché, seront le principal moteur qui anime cette innovation à la maturité.Reddio a fait un pas important et audacieux à cette intersection, et nous sommes impatients de voir plus de percées et de surprises dans ce domaine d’intégration à l’avenir.