Autor: Wuyue, Geek Web3
Heutzutage wird die Blockchain-Technologie immer schneller, die Optimierung der Leistung ist zu einem wichtigen Problem geworden.
In früheren Artikeln –„> „>“>“Betrachten Sie die Optimierung des parallelen EVM von Reddio“In diesem Artikel haben wir die parallelen EVM-Designideen von Reddio kurz zusammengefasst und in den heutigen Artikel werden wir eine eingehendere Interpretation seiner technischen Lösungen und seiner kombinierten Szenarien mit KI bereitstellen.
Da die technische Lösung von Reddio CueVM übernimmt, ist dies ein Projekt, bei dem GPU zur Verbesserung der Ausführungseffizienz von EVM verwendet wird, wir werden mit CueVM beginnen.
CUDA -Übersicht
CueVM ist ein Projekt, das EVM mit GPUs beschleunigt, das den Opcode von Ethereum EVM in Cuda -Kernel zur parallele Ausführung von Nvidia -GPUs umwandelt.Durch die parallele Rechenleistung der GPU wird die Ausführungseffizienz von EVM -Anweisungen verbessert.Vielleicht hören N -Kartenbenutzer oft das Wort cuda –
Berechnen Sie die einheitliche Gerätearchitektur, die eigentlich eine von NVIDIA entwickelte parallele Computerplattform und Programmiermodell ist.Es ermöglicht Entwicklern, die parallele Computerleistung von GPUs zur Durchführung allgemeiner Computing (z. B. Bergbau in Krypto, ZK -Operationen usw.) zu verwenden.Nicht nur auf Grafikverarbeitung beschränkt.
Als offenes Parallel -Computer -Framework ist CUDA im Wesentlichen eine Erweiterung der C/C ++ – Sprache, und jeder zugrunde liegende Programmierer, der mit C/C ++ vertraut ist, kann schnell beginnen.Ein sehr wichtiges Konzept in CUDA ist Kernel (Kernelfunktion), das auch eine C ++ – Funktion ist.

Im Gegensatz zu regulären C ++ – Funktionen, die nur einmal ausgeführt werden, werden diese Kernelfunktionen Syntax gestartet& lt; & lt; … & gt; & gt; & gt;Wenn Sie aufgerufen werden, werden n verschiedene CUDA -Threads parallel ausgeführt.
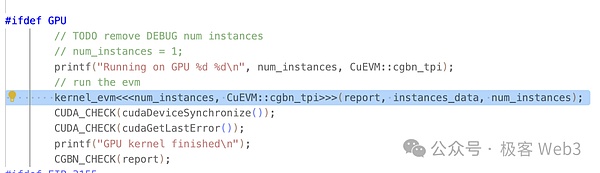
Jedem CUDA -Thread wird eine unabhängige Thread -ID zugewiesen und nimmt eine Thread -Hierarchie an, wodurch Threads Blöcke und Gitter zugewiesen werden, um die Verwaltung einer großen Anzahl paralleler Threads zu erleichtern.Durch den NVCC -Compiler von NVIDIA können wir CUDA -Code in Programme zusammenstellen, die auf der GPU ausgeführt werden können.

Grundlegender Workflow von Cuevm
Nach dem Verständnis einer Reihe von grundlegenden Konzepten von CUDA können Sie sich den Workflow von Cuevm ansehen.
Der Haupteingang von CueVM wird in Form einer JSON -Datei run_interpreter von hier eingeben, um parallel zu verarbeiten.Aus den Projektnutzungsfällen können wir feststellen, dass alle Eingaben Standard -EVM -Inhalte sind und Entwickler nicht verarbeiten, übersetzen usw. sind.

Wie Sie in Run_InterPreter () sehen können, ruft es die Kernel_evm () -Kernel-Funktion mit der CUDA-definierten & lt;… & gt; & gt;Wie oben erwähnt, werden Kernelfunktionen in der GPU parallel aufgerufen.
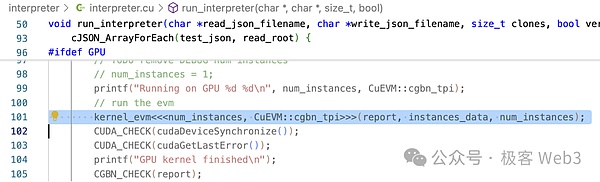
evm- & gt; run () wird in der Methode kernel_evm () aufgerufen.
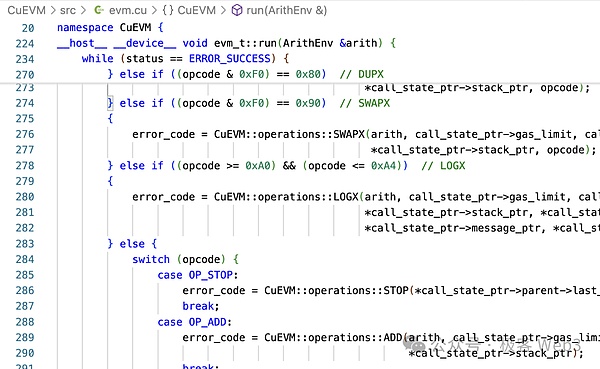
Wenn Sie als Beispiel den Addition Opcode OP_ADD in EVM nehmen, können Sie feststellen, dass es hinzugefügt wird, dass es in CGBN_ADD addiert.CGBN (Genossenschaftsgruppen große Zahlen) ist die Hochleistungs-Multi-Präzision-Ganzzahl-Arithmetikbibliothek von CUDA.

Diese beiden Schritte wandeln den EVM -Opcode in den CUDA -Betrieb um.Es kann gesagt werden, dass CueVM auch eine Implementierung aller EVM -Operationen auf CUDA ist.Schließlich gibt die Methode run_interpreter () das Betriebsergebnis zurück, dh den Weltstaat und andere Informationen.
Zu diesem Zeitpunkt wurde die grundlegende Betriebslogik von CueVM eingeführt.
CueVM kann parallele Transaktionen verarbeiten, aber der Zweck der CueVM -Projekteinrichtung (oder der Hauptanwendungsfälle) wird zum Fuzzing -Test verwendet:Fuzzing ist eine automatisierte Software -Test -Technologie, die potenzielle Fehler und Sicherheitsprobleme identifiziert, indem große Mengen von ungültigen, unerwarteten oder zufälligen Daten in ein Programm eingegeben werden, um die Antwort des Programms zu beobachten.
Wir können sehen, dass Fuzzing für die parallele Verarbeitung sehr geeignet ist.CueVM behandelt keine Transaktionskonflikte und andere Probleme, was nicht das Problem ist, über das es sich befasst.Wenn Sie CueVM integrieren möchten, müssen Sie auch widersprüchliche Transaktionen abwickeln.
Unser vorheriger Artikel„Betrachten Sie die Optimierung des parallelen EVM von Reddio“Der von Reddio verwendete Konfliktbearbeitungsmechanismus wurde in diesem Artikel eingeführt und wird hier nicht erörtert.Nachdem Reddio Transaktionen mit dem Konfliktverarbeitungsmechanismus sortiert, kann er an cuevm gesendet werden.Mit anderen Worten, der Transaktionssortiermechanismus von Reddio L2 kann in zwei Teile unterteilt werden: Konfliktverarbeitung + CueVM Parallele Ausführung.
Layer2, Parallele EVM, Drei-Wege-Schnittpunkt der KI
Wie bereits erwähnt, sind parallele EVM und L2 nur der Ausgangspunkt von Reddio, und seine zukünftige Roadmap wird es eindeutig mit KI -Erzählung kombinieren.Reddio, das GPU für Hochgeschwindigkeitsparalleltransaktionen verwendet, eignet sich von Natur aus für KI-Operationen in vielen Funktionen:
-
GPUs verfügen über starke parallele Verarbeitungsfunktionen und eignen sich zur Durchführung von Faltungsoperationen im Deep-Lernen, bei denen es sich im Wesentlichen um groß angelegte Matrix-Multiplikationen handelt, und GPUs sind für solche Aufgaben optimiert.
-
Die hierarchische Thread-Struktur der GPU kann mit der Korrespondenz zwischen verschiedenen Datenstrukturen in der AI-Computing, Verbesserung der Computereffizienz und der Maskierungsspeicherlatenz durch Thread-Overprovisionierungs- und Verzerrungsausführungseinheiten übereinstimmen.
-
Die Rechenstärke ist ein Schlüsselindikator für die Messung der AI -Computerleistung.
Wie kombinieren wir KI und L2?
Wir wissen, dass das gesamte Netzwerk in Rollups Architekturdesign nicht nur ein Sortierer ist, sondern auch einige Rollen, die den Vorgesetzten und Spediteuren ähneln, um Transaktionen zu überprüfen oder zu sammeln.In der traditionellen Rollup sind die Funktionen und Autorität dieser sekundären Rollen sehr begrenzt.
Reddio wird eine dezentrale Sortierarchitektur übernehmen, und Bergleute stellen GPU als Knoten zur Verfügung.Das gesamte Reddio -Netzwerk kann sich von einem reinen L2 zu einem umfassenden Netzwerk L2+ AI entwickeln, das einige AI+ Blockchain -Anwendungsfälle implementieren kann:
Das grundlegende interaktive Netzwerk des AI -Agenten
Mit der kontinuierlichen Entwicklung der Blockchain -Technologie kann AI Agent ein großes Anwendungspotential in Blockchain -Netzwerken haben.Nehmen wir den KI-Agenten, der als Beispiel Finanztransaktionen durchführt.L1 ist jedoch im Grunde genommen unmöglich, beim Umgang mit solchen intensiven Operationen enorme Transaktionslasten zu führen.

Als L2 -Projekt kann Reddio durch GPU -Beschleunigung die transaktion parallelen Verarbeitungsfunktionen erheblich verbessern.Im Vergleich zu L1 weist L2, das eine parallele Transaktionsausführung unterstützt, einen höheren Durchsatz auf und kann hochfrequente Transaktionsanforderungen von einer großen Anzahl von AI-Agenten effizient verarbeiten, um den reibungslosen Betrieb des Netzwerks sicherzustellen.
Im Hochfrequenzhandel haben KI-Agenten äußerst strenge Anforderungen an die Transaktionsgeschwindigkeit und die Reaktionszeit.L2 reduziert die Überprüfungs- und Ausführungszeit von Transaktionen, wodurch die Latenz erheblich verringert wird.Dies ist für KI -Agenten von entscheidender Bedeutung, die Antworten auf Millisekunden erfordern.Durch die Migration einer großen Anzahl von Transaktionen auf L2 wurde auch das Überlastungsproblem im Hauptnetzwerk effektiv gelindert.KI-Agenten kostengünstiger machen.
Mit der Reife von L2 -Projekten wie Reddio wird AI Agent eine wichtigere Rolle bei Blockchain spielen und Innovationen bei der Kombination von Defi und anderen Blockchain -Anwendungsszenarien mit KI fördern.
Dezentraler Computerstrommarkt
In Zukunft wird Reddio eine dezentrale Sortierarchitektur anwenden, und die Bergleute werden die GPU -Rechenleistung verwenden, um die Sortierrechte zu bestimmen.
Erstellen Sie einen dezentralen Markt für GPU-Computerstärke, um kostengünstigere Rechenressourcen für KI-Schulungen und -Angründungen bereitzustellen.Von kleinen bis großen Rechenleistung, von Personalcomputern bis hin zu Computerraumclustern kann die GPU -Rechenleistung aller Ebenen auf dem Markt beitragen, um ihre Idle -Computer -Leistung beizutragen und Gewinne zu verdienen. .
In den Anwendungsfällen des dezentralen Rechenleistungspunkts ist der Sortierer möglicherweise nicht hauptsächlich für die direkte Berechnung von KI verantwortlich.Für die Rechenleistung und die Zuweisung von Aufgaben gibt es zwei Modi:
-
Top-Down-Zentralzuweisung.Aufgrund des Sortiers kann der Sortierer die empfangenen Rechenleistungsermächtigungen an Knoten zuweisen, die den Anforderungen entsprechen und einen guten Ruf haben.Obwohl diese Verteilungsmethode theoretisch zentralisierte und unfaire Probleme hat, übersteigt die Effizienzvorteile auf lange Sicht weit über die Positionen des gesamten Netzwerks. Es gibt implizite, aber direkte Einschränkungen sicher, dass der Sortierer keine zu schwerwiegende Verzerrung hat.
-
Bottom-up Spontane Task Auswahl.Benutzer können auch KI-Betriebsanfragen an Knoten von Drittanbietern senden, was in bestimmten AI-Anwendungsfeldern offensichtlich effizienter ist, als sie direkt an den Sortierer zu senden, und können auch die Überprüfung und Verzerrung des Sortierers verhindern.Nach Abschluss der Berechnung synchronisiert der Knoten die Berechnungsergebnisse mit dem Sortierer und setzt sie auf die Verbindung.
In der L2 + AI -Architektur hat der Computer -Strommarkt in der L2 + -Ai -Architektur äußerst hohe Flexibilität und kann Rechenleistung aus zwei Richtungen sammeln, um die Ressourcenauslastung zu maximieren.
On-Chain-KI-Argumentation
Derzeit reicht die Reife des Open -Source -Modells aus, um unterschiedliche Bedürfnisse zu erfüllen.Mit der Standardisierung von AI -Argumentationsdiensten,Erforschen Sie, wie die Rechenleistung in die Kette eingesetzt wird, um automatisierte Preise zu erzielen.Dies erfordert jedoch eine Überwindung mehrerer technischer Herausforderungen:
-
Effiziente Anforderungsverteilung und -aufzeichnung:Großes Modell ist eine hohe Latenz und ein effizienter Anforderungsverteilungsmechanismus ist sehr kritisch.Obwohl die Daten von Anfragen und Antworten riesig und privat sind und nicht in der Blockchain freigelegt werden sollten, ist es auch erforderlich, ein Gleichgewicht zwischen Aufzeichnung und Überprüfung zu finden – beispielsweise durch Speichern von Hash.
-
Überprüfung des Rechenleistungsknotenausgangs:Hat der Knoten die formulierten Computeraufgaben wirklich abgeschlossen?Beispielsweise verwendet Knoten False Reporting kleine Modellberechnungsergebnisse anstelle großer Modelle.
-
Smart Contract Argumenting: Es ist erforderlich, KI -Modelle in Kombination mit intelligenten Verträgen für die Berechnung in vielen Szenarien zu verwenden.Da die KI-Argumentation ungewiss ist und nicht für alle Aspekte der Kette verwendet werden kann, wird die Logik der zukünftigen AI-Dapps wahrscheinlich teilweise außerhalb der Kette gelegen, und der andere Teil ist auf Kettenverträge. Die Eingabe von der Kette und numerische Legalität sind begrenzt.Im Ethereum -Ökosystem muss die Kombination mit intelligenten Verträgen der ineffizienten Serialität von EVM ausgesetzt sein.
In Reddios Architektur sind diese jedoch relativ einfach zu lösen:
-
Der Sortierer ist weitaus effizienter als L1 und kann als gleichwertig der Effizienz von Web2 angesehen werden.Für die Daten- und Aufbewahrungsmethode von Daten können verschiedene billige DA -Lösungen gelöst werden.
-
Die Berechnungsergebnisse von AI können schließlich durch ZKP überprüft werden.Das Merkmal von ZKP ist, dass die Überprüfung sehr schnell ist, aber die Beweiserzeugung langsam ist.Die Erzeugung von ZKP kann zufällig eine GPU- oder TEE -Beschleunigung verwenden.
-
SolidTy → CUDA → GPU Die parallele EVM -Hauptlinie ist die Grundlage von Reddio.Auf der Oberfläche ist dies also die einfachste Frage für Reddio.Derzeit arbeitet Reddio mit Eliza von AII6Z zusammen, um seine Module in Reddio einzuführen.
Zusammenfassen
Insgesamt scheinen die Felder von Layer2 -Lösungen, parallelen EVM- und AI -Technologien irrelevant zu sein, aber Reddio kombiniert diese wichtigsten innovativen Felder geschickt, indem sie die Recheneigenschaften von GPUs voll ausnutzen.
Durch die Nutzung der parallelen Computereigenschaften von GPUs verbessert Reddio die Transaktionsgeschwindigkeit und -effizienz auf Layer2 und verbessert die Leistung von Ethereum Layer 2.Die Integration der KI -Technologie in Blockchain ist ein neuer und vielversprechender Versuch.Die Einführung von KI kann intelligente Analysen und Entscheidungsfindung für Onkain-Operationen leisten und damit intelligentere und dynamische Blockchain-Anwendungen erzielt werden.Diese Cross-Field-Integration hat zweifellos neue Wege und Möglichkeiten für die Entwicklung der gesamten Branche eröffnet.
Es ist jedoch zu beachten, dass sich dieses Feld noch in den frühen Stadien befindet und immer noch viel Forschung und Erforschung erfordert.Die kontinuierliche Iteration und Optimierung der Technologie sowie die Vorstellungskraft und Handlungen von Marktpionieren werden die wichtigste treibende Kraft sein, die diese Innovation zur Reife treibt.Reddio hat einen wichtigen und mutigen Schritt an dieser Kreuzung unternommen, und wir freuen uns darauf, in Zukunft mehr Durchbrüche und Überraschungen in diesem Integrationsbereich zu sehen.