
TL/DR
AIとWeb3がそれぞれ互いに活用し、コンピューティングネットワーク、プロキシプラットフォーム、消費者アプリケーションなどのさまざまな垂直産業で互いに補完する方法について説明しました。データリソースの垂直分野に焦点を当てるとき、新興Webプロジェクトは、データ収集、共有、利用のための新しい可能性を提供します。
-
従来のデータプロバイダーは、特に透明性、ユーザー制御、プライバシー保護の観点から、高品質でリアルタイムの検証可能なデータに対するAIおよびその他のデータ駆動型産業のニーズを満たすのが困難です。
-
Web3ソリューションは、データエコシステムを再構築するために機能しています。MPC、ゼロ知識証明、TLS公証人などのテクノロジーは、データがデータのリアルタイム処理のための柔軟性と効率性を高める一方で、データが複数のソース間でデータが循環する場合に信頼性とプライバシー保護を保証します。
-
で分散型データネットワークこの新興インフラストラクチャは、いくつかの代表的なプロジェクト、OpenLayer(モジュラーリアルデータレイヤー)、草(ユーザーアイドル帯域幅と分散型クローラーノードネットワークを使用)、VANA(ユーザーデータ主権層1ネットワーク)とは異なる技術的なパスが発生し、技術的なパスが異なります。 AIトレーニングとアプリケーションフィールド。
-
クラウドソーシング能力、信頼性のない抽象化レイヤー、トークンベースのインセンティブメカニズムにより、分散型データインフラストラクチャは、Web2ハイパースケールのサービスプロバイダーよりもプライベートで安全で効率的なソリューションを提供し、ユーザーがデータとそのリソースを使用することができます、よりオープンで安全で相互接続されたデジタルエコシステムを構築します。
1。データ需要の波
データは、さまざまな業界におけるイノベーションと意思決定の重要な推進力となっています。UBSは、2020年から2030年の間にグローバルなデータ量が10倍以上660 ZBに増加すると予測しており、世界の各人は463 EB(1EB = 1EB = 10億GB)のデータを1人あたり1人あたり1人あたり1人あたり1人あたり生成します。日。サービスとしてのデータ(DAAS)市場は急速に拡大しており、Grand View Researchのレポートによると、世界のDAAS市場は2023年に143億6000万米ドルと評価されており、CAGRが28.1%のCAGRで成長すると予想されます。 2030年、最終的に768に達しました。1億ドル。これらの高成長数の背後にあるのは、複数の産業分野での高品質でリアルタイムの信頼できるデータの需要です。
AIモデルトレーニングは、パターンを識別し、パラメーターを調整するために、大量のデータ入力に依存しています。トレーニング後、モデルのパフォーマンスと一般化機能をテストするには、データセットも必要です。さらに、AIエージェントは、将来予見可能な新たなインテリジェントなアプリケーションフォームとして、正確な意思決定とタスクの実行を確保するために、リアルタイムで信頼できるデータソースを必要とします。
(出典:Leewewhertz)
ビジネス分析の需要も多様で広範囲になり、企業の革新を促進するためのコアツールになりました。たとえば、ソーシャルメディアプラットフォームや市場調査会社は、トレンドの戦略と洞察を策定するために信頼できるユーザー行動データを必要とし、複数のソーシャルプラットフォームから複数のデータを統合し、より包括的なポートレートを構築します。
Web3エコシステムの場合、いくつかの新しい金融商品をサポートするために、信頼性の高い実際のデータもオンチェーンで必要です。革新的な製品の開発とリスク管理をサポートするために、ますます多くの新しい資産がトークン化されているため、柔軟で信頼できるデータインターフェイスが必要であり、検証可能なリアルタイムデータに基づいてスマートコントラクトを実行できるようにします。
上記に加えて、科学的研究、モノのインターネット(IoT)などがあります。新しいユースケースさまざまな業界での多様なリアルタイムデータの需要は増加していますが、従来のシステムは急速に成長するデータ量と需要の変化に対処するのに苦労する可能性があります。
2。従来のデータ生態学の制限と問題
典型的なデータエコシステムには、データ収集、ストレージ、処理、分析、アプリケーションが含まれます。集中化されたモデルは、集中化されたデータ収集とストレージ、管理と運用とメンテナンスがコアエンタープライズITチームによって特徴付けられ、厳格なアクセス制御が実装されています。
たとえば、Googleのデータエコシステムは、検索エンジン、GmailからAndroidオペレーティングシステムまでの複数のデータソースをカバーし、これらのプラットフォームを使用してユーザーデータを収集し、グローバルに分散したデータセンターに保存し、アルゴリズムを使用して処理および分析してさまざまなサポートをサポートします。製品とサービスの開発と最適化。
たとえば、金融市場では、データとインフラストラクチャLSEG(以前のRefinitiv)は、リアルタイムおよび履歴データを使用してグローバルな取引所、銀行、その他の主要な金融機関を取得し、独自のロイターニュースネットワークを使用して市場関連のニュースと使用を収集します。その独自のアルゴリズムとモデルは、分析データとリスク評価を追加の製品として生成します。
(出典:kdnuggets.com)
従来のデータアーキテクチャは専門サービスに効果的ですが、集中モデルの制限はますます明らかになっています。特に、従来のデータエコシステムは、新たなデータソースのカバレッジ、透明性、ユーザープライバシー保護の点で課題に直面しています。ここにいくつかの例があります:
-
不十分なデータカバレッジ:従来のデータプロバイダーは、ソーシャルメディアセンチメント、IoTデバイスデータなどの新しいデータソースを迅速にキャプチャおよび分析する際に課題を抱えています。集中型システムは、多数の小規模または非メインストリームソースから「ロングテール」データを効率的に取得および統合することが困難です。
たとえば、2021年のGameStop事件は、ソーシャルメディアの感情を分析する際の従来の金融データプロバイダーの限界を明らかにしています。Redditなどのプラットフォームへの投資家の感情は市場動向を急速に変えましたが、ブルームバーグやロイターなどのデータ端末はこれらのダイナミクスをタイムリーにキャプチャできず、市場予測に遅れをとっています。
-
データアクセシビリティは限られています:独占はアクセシビリティを制限します。多くの従来のプロバイダーは、API/クラウドサービスを通じてデータの一部を開きますが、高アクセスコストと複雑な承認プロセスにより、データ統合の難しさが依然として増加しています。
オンチェーン開発者が信頼できるオフチェーンデータに迅速にアクセスすることは困難であり、高品質のデータは少数の巨人によって独占されており、アクセスコストが高くなります。
-
データの透明性と信頼性の問題:多くの集中データプロバイダーは、データの収集方法と処理方法に透明性がなく、大規模なデータの信頼性と完全性を検証するための効果的なメカニズムがありません。大規模なリアルタイムデータの検証は複雑な問題のままであり、集中化の性質により、データが改ざんまたは操作されるリスクも高まります。
-
プライバシー保護とデータの所有権:大規模なテクノロジー企業は、大規模にユーザーデータを使用しています。プライベートデータの作成者として、ユーザーがふさわしい報酬を得ることは困難です。ユーザーは、データがどのように収集、処理、使用されているかわからないことが多く、データを使用する範囲と方法を決定することも困難です。それを過剰に回収して使用すると、深刻なプライバシーリスクにもつながります。
たとえば、FacebookのCambridge Analyticaインシデントは、従来のデータプロバイダーが透明性とプライバシーをどのように使用できるかについて大きな脆弱性を明らかにしました。
-
データアイランド:さらに、さまざまなソースと形式からのリアルタイムデータを迅速に統合することは困難であり、包括的な分析の可能性に影響します。多くのデータが組織内にロックされていることが多く、業界や組織間でデータ共有と革新を制限し、データサイロ効果はクロスドメインのデータ統合と分析を妨げます。
たとえば、消費者業界では、ブランドは電子商取引プラットフォーム、物理店、ソーシャルメディア、市場調査からのデータを統合する必要がありますが、これらのデータは、プラットフォーム形式の一貫性や検疫のために統合するのが難しい場合があります。たとえば、UberやLyftのような共有旅行会社は、ユーザーからの輸送、乗客のニーズ、地理的位置に関する大量のリアルタイムデータを収集していますが、競争のために提案および共有および統合されることはできません。
さらに、コスト効率や柔軟性などの問題もあります。従来のデータプロバイダーはこれらの課題に積極的に対応していますが、新しいWeb3テクノロジーは、これらの問題を解決するための新しいアイデアと可能性を提供します。
3。Web3データエコシステム
2014年にIPFS(惑星間ファイルシステム)などの分散型ストレージソリューションがリリースされて以来、従来のデータエコシステムの制限を解決することを約束して、業界で一連の新興プロジェクトが登場しています。分散型データソリューションは、データ生成、ストレージ、交換、処理と分析、検証とセキュリティ、プライバシーと所有権など、データライフサイクルのすべての段階をカバーするマルチレベルの相互接続されたエコシステムを形成していることがわかります。
-
データストレージ:FilecoinとArweaveの急速な発展は、分散型ストレージ(DCS)がストレージスペースのパラダイムシフトになりつつあることを証明しています。DCSスキームは、分散アーキテクチャを通じて単一ポイント障害のリスクを軽減し、参加者により競争力のある費用対効果を抱えています。一連の大規模なアプリケーションケースの出現により、DCSストレージ容量は爆発的な成長を示しています(たとえば、ファイルコインネットワークの総貯蔵容量は2024年に22エクササイズに達しました)。
-
処理と分析:フルエンスなどの分散型データコンピューティングプラットフォームは、エッジコンピューティングテクノロジーを通じてデータ処理のリアルタイムと効率を改善し、特にリアルタイムのパフォーマンスを必要とするインターネット(IoT)やAI推論などのアプリケーションシナリオに特に適しています。Web3プロジェクトでは、フェデレートラーニング、差別的なプライバシー、信頼できる実行環境、完全な準同型暗号化などのテクノロジーを使用して、コンピューティングレイヤーの柔軟なプライバシー保護とトレードオフを提供します。
-
データ市場/交換プラットフォーム:データ値の定量化と循環を促進するために、Ocean Protocolは、従来の製造会社(Mercedes-Benz親会社Daimler)が協力してデータ交換市場の開発を支援するなど、トークン化とDEXメカニズムを通じて効率的かつオープンなデータ交換チャネルを作成しました。サプライチェーン管理におけるデータ共有を支援します。一方、Streamrは、IoTおよびリアルタイムの分析シナリオに適した許可のないサブスクリプションベースのデータストリーミングネットワークを作成しました。
データ交換と利用の頻度が増加するにつれて、データの信頼性、信頼性、プライバシーが無視できない重要な問題になりました。これにより、Web3エコシステムは、イノベーションをデータ検証とプライバシー保護の分野に拡張し、一連の画期的なソリューションを生み出しました。
3.1データ検証とプライバシー保護のイノベーション
多くのWeb3テクノロジーとネイティブプロジェクトは、データの信頼性とプライベートデータ保護の問題を解決するために取り組んでいます。ZKに加えて、MPCおよびその他の技術が広く使用されており、その中で輸送層のセキュリティプロトコル公証(TLS公証)は、新しい検証方法として特に注意に値します。
TLS公証の紹介
トランスポートレイヤーセキュリティプロトコル(TLS)は、クライアントとサーバー間のデータ送信のセキュリティ、整合性、機密性を確保することを目的とした、ネットワーク通信で広く使用されている暗号化プロトコルです。これは、最新のネットワーク通信で一般的な暗号化標準であり、HTTPS、電子メール、インスタントメッセージング、その他のシナリオで使用されています。
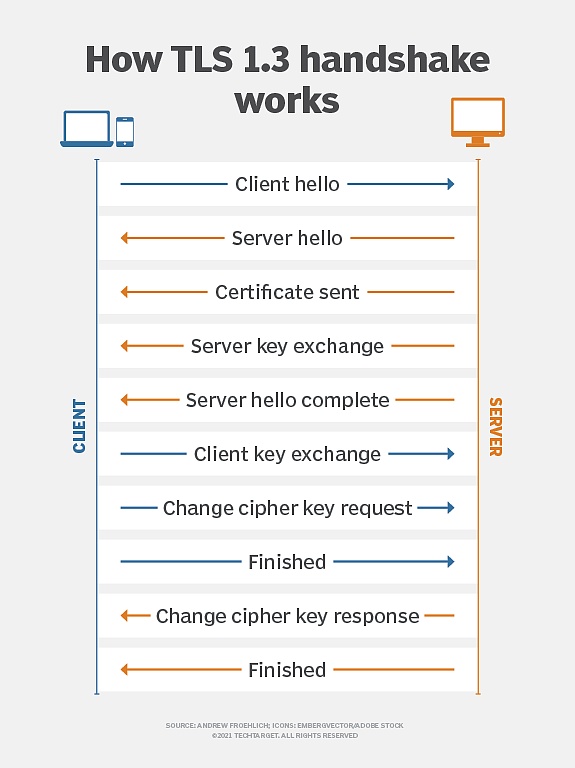
(TLS暗号化原則、出典:TechTarget)
10年前に生まれたとき、TLS Notaryの最初の目標は、クライアント(Prover)とサーバーの外でサードパーティの「公証人」を導入することにより、TLSセッションの信ity性を検証することでした。
キーセグメンテーションテクノロジーを使用して、TLSセッションのマスターキーは、クライアントと公証人が保持する2つの部分に分割されます。この設計により、公証人は信頼できる第三者として検証プロセスに参加することができますが、実際の通信コンテンツにアクセスすることはできません。この公証化メカニズムは、中間の攻撃を検出し、不正な証明書を防止し、伝送中に通信データが改ざんされないようにし、信頼できる第三者が通信プライバシーを保護しながらコミュニケーションの正当性を確認できるように設計されています。
したがって、TLS公証人は安全なデータ検証を提供し、検証要件とプライバシー保護を効果的にバランスさせます。
2022年、TLS公証人プロジェクトは、Ethereum Foundationのプライバシーおよび拡張探査(PSE)リサーチラボによって再建されました。TLS公証人プロトコルの新しいバージョンは、錆びた言語でゼロから書き直され、より高度な暗号化プロトコル(MPCなど)が組み込まれています。データコンテンツが漏れていません。元のTLS公証人コア検証関数を維持しながら、プライバシー保護機能を大幅に改善し、現在および将来のデータプライバシーのニーズにより適しています。
3.2 TLS公証人のバリエーションと拡張
近年、TLS公証技術も継続的に進化しており、開発に基づいて開発され、複数のバリエーションを生み出し、プライバシーと検証機能をさらに強化しました。
-
zktls:ZKPテクノロジーと組み合わせたTLS公証人のプライバシー強化バージョンでは、ユーザーは機密情報を公開せずに暗号化されたWebページデータの証明を生成できます。非常に高いプライバシー保護を必要とするコミュニケーションシナリオに適しています。
-
3P-TLS(3パーティTLS):クライアント、サーバー、監査人が紹介され、監査人が通信コンテンツを漏らすことなく通信のセキュリティを確認できるようにします。このプロトコルは、透明性が必要なシナリオで非常に役立ちますが、コンプライアンスレビューや金融取引の監査など、プライバシー保護が必要です。
Web3プロジェクトは、これらの暗号化テクノロジーを使用して、データの検証とプライバシー保護を強化し、データの独占を破り、信頼できる送信の問題を解決し、ソーシャルメディアアカウントや銀行の信用履歴のショッピング記録を明らかにすることなくプライバシーを証明できるようにします、専門的なバックグラウンドとアカデミック認証情報:
-
Reclaim Protocolは、ZKTLSテクノロジーを使用してHTTPSトラフィックのゼロ知識証明を生成し、ユーザーが機密情報を公開することなく外部Webサイトからアクティビティ、評判、IDデータを安全にインポートできるようにします。
-
ZKPassは、3P-TLSテクノロジーを組み合わせて、ユーザーがKYC、クレジットサービス、その他のシナリオで広く使用され、HTTPSネットワークと互換性があることを確認できます。
-
Ofacity NetworkはZKTLSに基づいており、ユーザーはこれらのプラットフォームのAPIに直接アクセスすることなく、さまざまなプラットフォーム(Uber、Spotify、Netflixなど)でのアクティビティを安全に証明できます。クロスプラットフォームアクティビティプルーフを実装します。
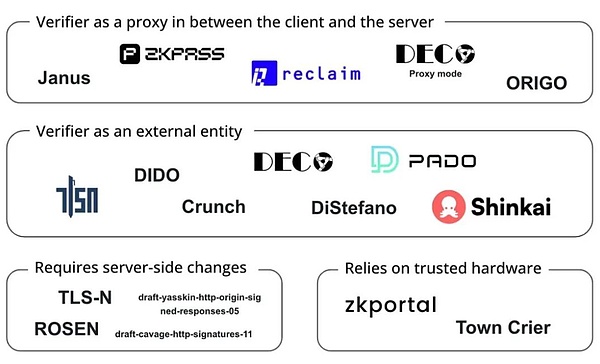
(on TLS Oracles、出典:Bastian Wetzel)
データエコシステムチェーンの重要なリンクとして、Web3データ検証には、そのエコシステムの繁栄がよりオープンでダイナミックでユーザー中心のデジタル経済を導いています。ただし、信頼性検証テクノロジーの開発は、新しい世代のデータインフラストラクチャの構築の始まりにすぎません。
4。分散データネットワーク
上記のデータ検証テクノロジーを組み合わせて、データエコシステムの上流、つまりデータのトレーサビリティ、分散データ収集、信頼できる伝送でより詳細な調査を行います。次世代のデータインフラストラクチャの構築におけるユニークな可能性を示しているOpenLayer、Grass、Vanaのいくつかの代表的なプロジェクトがあります。
4.1 OpenLayer
OpenLayerは、A16Z Crypto 2024 Spring 2024 Crypto Antrepreneurship Accelerator Projectsの1つであり、最初のモジュール式Realデータレイヤーとして機能し、Web2およびWeb3企業の両方の企業が必要とするためのデータ収集、検証、変換を調整するための革新的なモジュラーソリューションを提供することを約束します。OpenLayerは、Geometry Ventures、Longhash Venturesなど、有名なファンドやエンジェル投資家からの支援を集めています。
従来のデータレイヤーには複数の課題があります。信頼できる検証メカニズムの欠如、集中アーキテクチャへの依存はアクセスの制限につながり、異なるシステム間のデータには相互運用性と流動性がなく、公正なデータ値割り当てメカニズムもありません。
より具体的な問題は、AIトレーニングデータが今日ますます乏しくなっていることです。パブリックインターネットでは、多くのWebサイトがAI企業が大規模にデータをraw索するのを防ぐために反クローラー制限を使用し始めています。
とでプライベートおよび独自のデータ一方では、状況はより複雑です。この現状の下では、ユーザーはプライベートデータを提供することで直接的な利益を安全に得ることができないため、この機密データを共有することを嫌がります。
これらの問題を解決するために、OpenLayerはデータ検証技術を使用してモジュール式の本物のデータレイヤーを構築し、Web2およびWeb3企業にデータ収集、検証、および変換プロセスを調整しましたインフラストラクチャー。
4.1.1 OpenLayerモジュラー設計のコアコンポーネント
OpenLayerは、データ収集、信頼できる検証、変換のプロセスを簡素化するためのモジュラープラットフォームを提供します。
a)OpenNodes
OpenNodesは、OpenLayerエコシステムの分散データ収集のコアコンポーネントです。
OpenNodesは、さまざまなタイプのタスクのニーズを満たすために3つの主要なデータ型をサポートしています。
-
公開されているインターネットデータ(財務データ、気象データ、スポーツデータ、ソーシャルメディアストリームなど)
-
ユーザープライベートデータ(Netflixの表示履歴、Amazon Order Historyなど)
-
安全なソースからの自己報告データ(独自の所有者によって署名されたデータや、特定の信頼できるハードウェアによって検証されたデータなど)。
開発者は、新しいデータ型を簡単に追加し、新しいデータソース、要件、データ検索方法を指定し、ユーザーは報酬と引き換えに識別されたデータを提供することを選択できます。この設計により、システムは継続的に拡張して、多様なデータソースに適応することができます。
b)openvalidators
OpenValidatorsは、収集後のデータ検証に責任を負い、データ消費者がユーザーが提供するデータがデータソースと正確に一致していることを確認できるようにします。提供されたすべての検証方法は、暗号化によって検証でき、検証結果はその後検証できます。同じタイプの証明については、サービスを提供するための複数の異なるプロバイダーがあります。開発者は、ニーズに応じて最も適切な検証プロバイダーを選択できます。
特にインターネットAPIのパブリックデータまたはプライベートデータの初期ユースケースでは、OpenLayerはTLSNotaryを検証ソリューションとして使用して、Webアプリケーションからデータをエクスポートし、プライバシーを損なうことなくデータの信頼性を証明します。
tlsnotaryに限定されないように、そのモジュール設計のおかげで、検証システムは他の検証方法に簡単にアクセスして、さまざまな種類のデータや検証のニーズに合わせて簡単にアクセスできますが、以下に限定できません。
-
証明されたTLS接続:信頼できる実行環境(TEE)を使用して、認定されたTLS接続を確立して、送信中のデータの整合性と信頼性を確保します。
-
セキュアエンクレーブ:ハードウェアレベルの安全な分離環境(Intel SGXなど)を使用して、機密データを処理および検証して、より高いレベルのデータ保護を提供します。
-
ZKプルーフジェネレーター:統合されたZKP。元のデータを表示せずにデータプロパティまたは計算結果の検証を可能にします。
c)openconnect
OpenConnectは、データ変換と可用性の実現、さまざまなソースからのデータの処理、さまざまなシステム間のデータの相互運用性を確保し、さまざまなアプリケーションのニーズを満たすことを担当するOpenLayerエコシステムのコアモジュールです。例えば:
-
データをオンチェーンOracle形式に変換します。これは、スマートコントラクトの直接使用に便利です。
-
非構造化された生データを構造化されたデータに変換し、AIトレーニングおよびその他の目的のために前処理を実行します。
ユーザーのプライベートアカウントからのデータの場合、OpenConnectは、プライバシーを保護するためのデータ脱感作を提供し、データ共有中のセキュリティを強化し、データ侵害と虐待を減らすためのコンポーネントを提供します。AIやブロックチェーンなどのアプリケーションのリアルタイムデータのニーズを満たすために、OpenConnectは効率的なリアルタイムデータ変換をサポートします。
現在、Eigenlayerとの統合を通じて、OpenLayer AVSオペレーターモニターデータ要求タスクは、データをrawってデータを検証する責任があり、その結果を報告して、Eigenlayerを介して資産を誓約または再ステークするために、その行動の財政的保証を提供するために資産を誓約または再ステークすることを報告します。悪意のある行動が確認された場合、あなたは誓約された資産から罰金を科され、没収されるリスクに直面します。Eigenlayer Main Networkで最も初期のAVS(アクティブ検証サービス)の1つとして、OpenLayerは50人以上のオペレーターと40億ドルの再ステーキング資産を引き付けました。
一般に、OpenLayerによって構築された分散型のデータレイヤーは、実用性と効率を犠牲にすることなく、利用可能なデータの範囲と多様性を拡大し、暗号化技術と経済的インセンティブを通じてデータの信頼性を確保します。そのテクノロジーには、オフチェーン情報を取得しようとするWeb3 Dappsの幅広い実用的なケース、トレーニングと推測に実際の入力を必要とするAIモデル、および既存のアイデンティティと評判に基づいてユーザーをセグメント化して見つけたい企業があります。ユーザーは、プライベートデータを評価することもできます。
4.2草
Grassは、Wynd Networkによって開発されたフラッグシッププロジェクトであり、分散型Web CrawlerとAIトレーニングデータプラットフォームを作成します。2023年の終わりに、グラスプロジェクトは、ポリカインキャピタルと部族の首都が率いる350万ドルのシードラウンドを完了しました。その直後、2024年9月、このプロジェクトは、PolyChain、Delphi、Lattice、Brevan Howardなどの有名な投資機関とともに、HACKVCが率いるシリーズAファイナンスに導かれました。
AIトレーニングには新しいデータ露出が必要であり、ソリューションの1つは複数のIPを使用してデータアクセス許可を突破し、AIデータをフィードすることです。草はこれから始まり、分散クローラーノードネットワークを作成しました。ユーザーのアイドル帯域幅を使用して、分散型の物理インフラストラクチャの形でAIトレーニングの検証可能なデータセットを収集および提供することに専念しています。ノードは、ユーザーのインターネット接続を介してWeb要求をルーティングし、パブリックWebサイトにアクセスし、構造化されたデータセットをコンパイルします。エッジコンピューティングテクノロジーを使用して、予備データのクリーニングとフォーマットを実行して、データ品質を向上させます。
草は、ソラナ上に構築されたソラナ層2データロールアップアーキテクチャを採用して、処理効率を向上させます。Grassは、バリデーターを使用して、ノードからWebトランザクションを受信、検証、バッチにし、ZKプルーフを生成してデータの信頼性を確保します。検証済みのデータは、データ台帳(L2)に保存され、対応するL1チェーンプルーフにリンクされています。
4.2.1草の主要コンポーネント
a)草の結節
openNodesと同様に、Cエンドユーザーは草のアプリケーションまたはブラウザ拡張機能をインストールして実行し、アイドル帯域幅を使用してネットワーククロール操作を実行し、ノードルートWeb要求をユーザーのインターネット接続を介してルートWeb要求、パブリックWebサイトにアクセスし、構造化されたデータセットをコンパイルし、エッジコンピューティングを使用します。実行するテクノロジー。ユーザーは、帯域幅と貢献したデータの量に基づいて草のトークンの報酬を受け取ります。
b)ルーター
草のノードとバリデーターを接続し、ノードネットワークを管理し、帯域幅をリレーします。ルーターは、報酬比率の割合の割合の割合を総検証帯域幅に対する割合の割合を通過させるために、報酬を操作して受信するように奨励されます。
c)バリデーター
ルーターからWebトランザクションを受信、検証、バッチトランザクション、ZKプルーフを生成し、一意のキーセットを使用してTLS接続を確立し、ターゲットWebサーバーとの通信のために適切な暗号スイートを選択します。グラスは現在、集中化されたバリデーターを使用しており、将来的にはバリデーター委員会に移動する予定です。
d)ZKプロセッサ(ZKプロセッサ)
Verifierから各ノードセッションデータを生成する証明、すべてのWebリクエストの有効性のバッチプルーフを受け取り、レイヤー1(Solana)に送信します。
e)草のデータ台帳(草L2)
完全なデータセットを保存し、対応するL1チェーン(Solana)にリンクします。
f)エッジ埋め込みモデル
非構造化されたWebデータをAIでトレーニングできる構造化モデルに変換する責任があります。
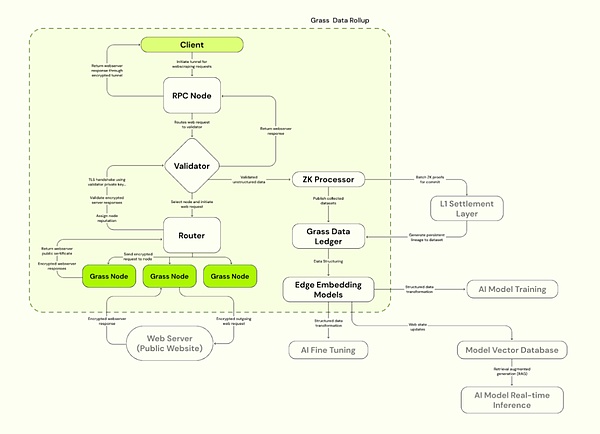
出典:草
草とオープンレイヤーの分析と比較
OpenLayerとGrass Leveragyの両方の分散ネットワークは、企業がオープンなインターネットデータと認証を必要とする閉じた情報にアクセスする機会を提供します。インセンティブメカニズムは、データ共有と高品質のデータ生成を促進します。どちらも、データ収集のアクセスと検証の問題を解決するために分散型のデータレイヤーを作成することに取り組んでいますが、わずかに異なる技術的パスとビジネスモデルを採用しています。
さまざまな技術アーキテクチャ
Grassは、Solanaのレイヤー2データロールアップアーキテクチャを使用しており、現在、集中検証メカニズムと単一の検証装置を使用しています。AVSの最初のバッチとして、OpenLayerはEigenlayerに基づいて構築されており、経済的インセンティブと没収メカニズムを使用して達成します分散検証メカニズム。また、データ検証サービスのスケーラビリティと柔軟性を強調して、モジュラー設計も採用しています。
製品の違い
どちらもC製品と同様のもので、ユーザーはノードを介してデータの値を収益化できるようにします。Bot Buseケースでは、Grassは興味深いデータ市場モデルを提供し、L2を使用して完全なデータを口頭で保存して、AI企業に構造化された高品質の検証可能なトレーニングセットを提供します。OpenLayerには一時的な専用のデータストレージコンポーネントはありませんが、AIのデータを提供することに加えて、より幅広いリアルタイムデータフロー検証サービス(VAA)を提供します。 RWA/Defi/Prediction Market Project Feedの価格フィードについては、リアルタイムのソーシャルデータなどを提供します。
したがって、Grassのターゲット顧客ベースは、主にAI企業とデータサイエンティストを対象としており、大規模で構造化されたトレーニングデータセットを提供し、OpenLayerが一時的に対象とする多数のネットワークデータセットを必要とする研究機関と企業にもサービスを提供していますオフチェーンデータのニーズ。オンチェーン開発者、リアルタイム、検証可能なデータストリーム、および競合他社の使用履歴を確認するWeb2企業などの革新的なユーザー獲得戦略が必要です。
将来の潜在的な競争
ただし、業界の動向を考慮すると、2つのプロジェクトの機能は将来収束する可能性があります。また、草はリアルタイムの構造化データをすぐに提供する可能性があります。モジュラープラットフォームとして、OpenLayerは将来データセット管理に拡大して独自のデータ台帳を持つことができるため、2つの競争力のある領域が徐々に重複する可能性があります。
さらに、両方のプロジェクトは、データラベル付けを重要なリンクとして追加することを検討する場合があります。草は、220万枚以上のアクティブノードの大きなネットワークを持っているため、この点でより速く移動する可能性があります。この利点は、草にAIモデルを最適化するために大量のラベル付きデータを使用して、人間のフィードバックに基づいて強化学習(RLHF)サービスを提供する可能性を与えます。
ただし、データ検証とリアルタイム処理の専門知識を備えたOpenLayerは、データの品質と信頼性の利点を維持する可能性があります。さらに、EigenlayerのAVSの1つとして、OpenLayerは分散化された検証メカニズムにさらなる開発がある可能性があります。
2つのプロジェクトは特定の分野で競合する可能性がありますが、それぞれのユニークな強みと技術的ルートは、データエコシステムのさまざまなニッチを占有することにもつながる可能性があります。
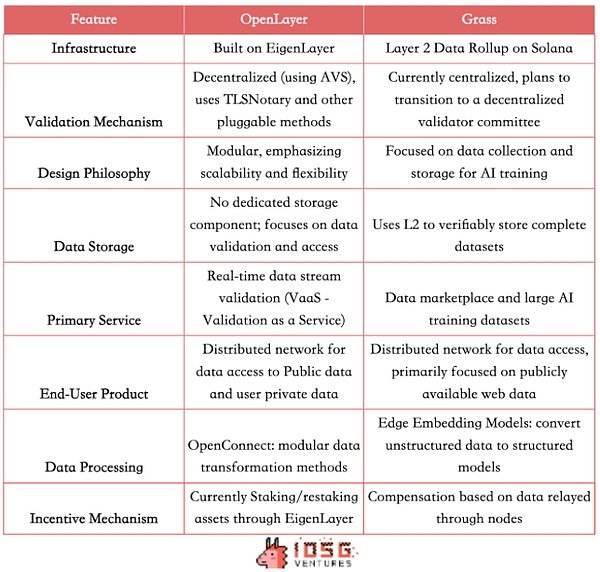
(出典:iOSG、デビッド)
4.3 Vava
ユーザー中心のデータプールネットワークとして、VANAはAIおよび関連アプリケーションに高品質のデータを提供することにも取り組んでいます。OpenLayerやGrassと比較して、Vanaはより異なるテクノロジーパスとビジネスモデルを採用しています。Vanaは、Coinbase Venturesが率いる500万ドルの資金調達を完了しました。
もともとMITの研究プロジェクトとして2018年に発売されたVanaは、ユーザープライベートデータ専用に設計されたレイヤー1ブロックチェーンになることを目指しています。データの所有権と価値配分の革新により、ユーザーはデータでトレーニングされたAIモデルから利益を得ることができます。ヴァナの中核は、信頼のない、私的で、帰属することですデータ流動性プールそして革新的です貢献の証明プライベートデータの循環と価値を実現するメカニズム:
4.3.1データ流動性プール
VANAは、データ流動性プール(DLP)のユニークな概念を導入します。VANAネットワークのコアコンポーネントとして、各DLPは特定のタイプのデータ資産を集約するための独立したピアツーピアネットワークです。ユーザーは、プライベートデータ(ショッピング履歴、習慣の閲覧、ソーシャルメディアアクティビティなど)を特定のDLPにアップロードし、このデータを使用するために特定の第三者に承認するかどうかを柔軟に選択できます。データは、これらの流動性プールを通じて統合および管理されており、AIモデルトレーニングや市場調査などの商用アプリケーションにデータを参加できるようにしながら、ユーザーのプライバシーを確保するために識別されます。
ユーザーはDLPにデータを送信し、対応するDLPトークンを受け取ります(各DLPには特定のトークンがあります)これらのトークンは、ユーザーのデータプールへの貢献を表します。 。ユーザーはデータを共有できるだけでなく、データへの後続の呼び出しから継続的な利益を得ることができます(および視覚的な追跡を提供します)。従来のシングルタイムデータ販売とは異なり、VANAはデータが経済サイクルに参加し続けることを許可しています。
4.3.2貢献メカニズム
Vanaの他のコアイノベーションの1つはです貢献の証明(貢献の証明)メカニズム。これは、データ品質を確保するためのVANAの重要なメカニズムであり、各DLPがその特性に基づいて一意の寄与証明関数をカスタマイズして、データの信頼性と整合性を検証し、AIモデルのパフォーマンス改善に対するデータの貢献度を評価できるようにします。このメカニズムにより、ユーザーのデータ貢献が定量化および記録されることを保証し、ユーザーに報酬を提供します。暗号通貨の「仕事の証明」と同様に、貢献の証明は、品質、ユーザーが提供するデータの量、および使用頻度に基づいてユーザーに利益を分配します。スマートコントラクトの自動実行により、貢献者が貢献と一致する報酬を受け取ることが保証されます。
Vanaの技術アーキテクチャ
-
データ流動性レイヤー
これはVANAのコア層であり、DLPへのデータの貢献、検証、記録を担当し、転送可能なデジタル資産としてチェーンにデータを導入します。DLPクリエイターは、DLPスマートコントラクトを展開して、データの貢献、検証方法、貢献パラメーターの目的を設定します。データ貢献者とカストディアンは検証のためにデータを提出し、貢献の証明(POC)モジュールはデータ検証と価値評価を実行し、パラメーターに基づいてガバナンスの権利と報酬を付与します。
-
データ移植性レイヤー
これは、データ貢献者と開発者向けのオープンデータプラットフォームであり、VANAのアプリケーションレイヤーでもあります。データポータビリティレイヤーは、DLPに蓄積されたデータの流動性を使用してアプリケーションを構築するためのデータ貢献者と開発者がコラボレーションスペースを提供します。ユーザー所有モデルとAI DAPP開発の分散トレーニングのためのインフラストラクチャを提供します。
-
ユニバーサルコネクトーム
分散型台帳は、VANAエコシステム全体を使用して、VANAエコシステムでリアルタイムのデータトランザクションを記録するリアルタイムのデータフローチャートでもあります。DLPトークンの効果的な転送を確認し、アプリケーションへのCross-DLPデータアクセスを提供します。EVMと互換性があり、他のネットワーク、プロトコル、Defiアプリケーションとの相互運用性を可能にします。
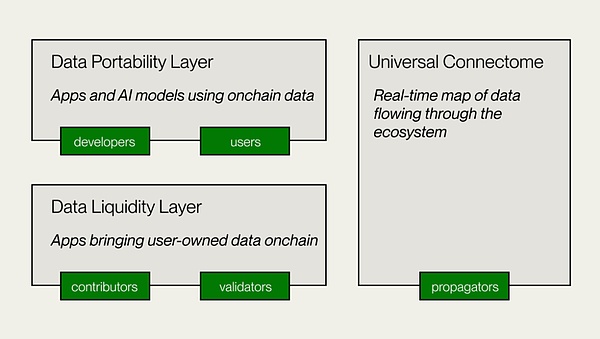
(出典:Vana)
VANAは、この分散データ交換モデルの流動性と価値のエンパワーメントに焦点を当てた比較的異なるパスを提供します相互運用性とライセンスは新しいソリューションを提供します。最終的に、ユーザーが独自のデータを所有および管理できるようにするオープンなインターネットエコシステムと、このデータから作成されたスマート製品を作成する。
5。分散型データネットワークの価値提案
データサイエンティストのClive Humbyは、2006年にデータは新しい時代のオイルであると述べました。過去20年間で、「精製」技術の急速な発展を目撃しました。ビッグデータ分析や機械学習などのテクノロジーにより、前例のないデータ値が可能になりました。IDCの予測によると、2025年までに、グローバルデータサークルは163 ZBに成長し、そのほとんどは個々のユーザーから生まれます。将来的には商品化される必要があります。
従来のソリューションの問題点:Web3のイノベーションのロックを解除します
分散ノードネットワークを通じて、Web3データソリューションは、従来の施設の制限を突破し、より幅広い効率的なデータ収集を実現し、特定のデータのリアルタイムの取得効率と検証の信頼性を改善します。このプロセスでは、Web3テクノロジーはデータの信ity性と整合性を保証し、ユーザーのプライバシーを効果的に保護し、それによってより公平なデータ利用モデルを達成できます。この分散化されたデータアーキテクチャは、データ収集を促進します民主化。
OpenLayerとGrassのユーザーノードモードであろうと、VANAのユーザープライベートデータの収益化であろうと、特定のデータ収集の効率を改善することに加えて、通常のユーザーはデータ経済の配当を共有し、ユーザー向けのWin-Winモデルを作成できます。開発者は、ユーザーがデータや関連するリソースを真に制御し、利益を得るようにします。
トークンエコノミーを通じて、Web3データソリューションはインセンティブモデルを再設計し、より公正なデータ値割り当てメカニズムを作成しました。データネットワーク全体の動作を調整および最適化するために、多数のユーザー、ハードウェアリソース、および資本を集めました。
彼らも持っていますモジュール性とスケーラビリティ:たとえば、OpenLayerのモジュラー設計は、将来の技術的反復と生態学的拡大に柔軟性を提供します。技術的特性のおかげで、AIモデルトレーニングのデータ収集方法を最適化して、より豊かで多様なデータセットを提供します。
データ生成、ストレージ、検証、交換、分析まで、Web3駆動型ソリューションは、独自の技術的利点を通じて従来の施設の多くの欠点を解決し、ユーザーに個人データを収益化する能力を提供し、データ経済モデルの基本的な変化を引き起こします。技術のさらなる開発と進化、アプリケーションシナリオの拡大により、分散型データレイヤーは、他のWeb3データソリューションとともに、次世代の重要なインフラストラクチャになると予想され、幅広いデータ駆動型業界をサポートします。







