著者:Cynic、Shigeru
ガイド:アルゴリズム、コンピューティングのパワー、データの力を使用して、AIテクノロジーの進歩は、データ処理とインテリジェントな意思決定の境界を再定義しています。同時に、Depinは、集中インフラストラクチャ上の集中およびブロックチェーンベースのネットワークパラダイムを表します。
世界がデジタルトランスフォーメーションに向かって移動するにつれて、AIとDepin(分散型の物理インフラストラクチャ)は、あらゆる人生の改革を促進するための基本的な技術となっています。AIとdepinの融合は、技術の迅速な反復と適用を促進するだけでなく、より安全で透明で効率的なサービスモデルを開いて、世界経済に遠くの変化をもたらします。
デピン:分散化と不足、デジタル経済の主力
Depinは、分散型の物理インフラストラクチャの略語です。狭い意味では、Depinは主に、パワーネットワーク、通信ネットワーク、ポジショニングネットワークなどの分散型台帳技術によってサポートされる従来の物理インフラストラクチャの分散ネットワークを指します。広い意味で、物理機器でサポートされるすべての分散ネットワークは、ストレージネットワークやコンピューティングネットワークなど、Depinと呼ばれます。
>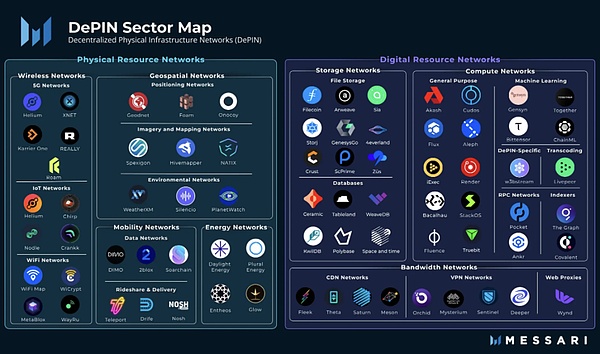
From:Messari
Cryptoが金融レベルで分散化された変化をもたらした場合、Depinは実際の経済における分散型ソリューションです。Pow Mining MachineはDepinであると言えます。初日から、DepinはWeb3の核となる柱です。
ai 3つの要素 – アルゴリズム、コンピューティングパワー、データ、depinはそれを独占します
通常、人工知能の開発は、アルゴリズム、コンピューティングパワー、データの3つの重要な要素に依存すると見なされます。アルゴリズムは、ドライブAIシステムの数学的モデルとプログラムロジックを指します。
>
3つの要素のうち、最も重要なのはどれですか?ChatGptが登場する前は、人々は通常、それがアルゴリズムであると考えています。そうでなければ、アカデミック会議やジャーナルペーパーはアルゴリズムによる細かい調整で満たされません。Intelligent LLMをサポートするChatGptとLLMの登場後、人々は後者2の重要性を認識し始めました。大規模なコンピューティングパワーは、モデルの生成の前提条件であり、コンピューターは強力で効率的なAIシステムを確立するために不可欠です。
大規模なモデルの時代では、AIは細かい彫刻から激しく飛んでいるレンガに変化し、データが正確に提供されています。トークンは、長いテール市場を活用することに触発されています。
AIの分散化はオプションではなく、強制オプションです
もちろん、一部の人々は、AWSのコンピュータールームで利用可能であり、中央のサービスの代わりにdepinを選択するよりもdepinよりも優れています。
この声明は、瞬間、ほとんどすべての大規模なモデルがGeminiの背後にある大規模なインターネット企業によって開発されています。なぜ?なぜなら、大規模なインターネット企業のみが十分な高品質データと強力な財源によってサポートされているコンピューティングパワーを持っているからです。しかし、これは間違っています。人々はもはやインターネットの巨人によって操作されたくありません。
一方では、集中型AIにはデータプライバシーとセキュリティリスクがあります。これは、インターネットの巨人によって作成されたAIが依存をさらに強化し、集中市場につながり、革新的な障壁を改善することができます。
>
From:https://www.gensyn.ai//
人間はAI時代のマーティン・ルーサーを必要とするべきではなく、人々は神と直接話す権利を持つべきです。
depinを見る:コスト削減と効率が重要です
ビジネスの観点から、分散化と集中価値の間の紛争を脇に置いたとしても、AIへのdepinの使用は依然として望ましい。
まず第一に、インターネットの巨人は多数のハイエンドグラフィックカードリソースを習得しているが、人々に散在する消費者グラフィックスカードの組み合わせは、非常にかなりのコンピューティングパワーネットワークを構成できることを明確に認識する必要があります。コンピューティングパワーの長いテール効果。このタイプの消費者グラフィックカードは、実際には非常に高くなっています。Depinによって与えられたインセンティブが電気料金を超えることができる限り、ユーザーはネットワークに貢献する動機を持っています。同時に、すべての物理的な施設は、ユーザー自体によって管理されます。
データの場合、Depinネットワークは、エッジコンピューティングやその他の方法を通じて潜在的なデータの可用性をリリースし、送信コストを削減できます。同時に、ほとんどの分散ストレージネットワークは自動的に機能しているため、AIトレーニングデータのクリーニング作業が削減されています。
最後に、Depinが提起した暗号経済学は、プロバイダー、消費者、プラットフォームの勝利の状況を達成することが期待されるシステムのフォールトトレランススペースを強化します。
>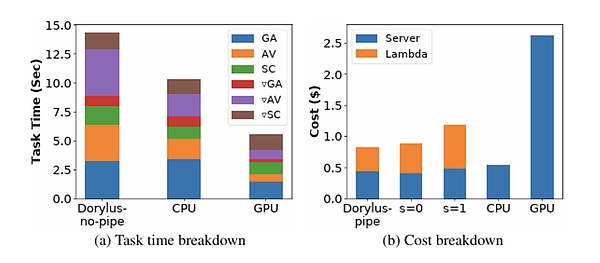
From:UCLA
あなたが信じていない場合、UCLAの最新の研究は、同じコストでの分散化された計算の使用が、具体的には1.22倍、4.83倍の安価であることを示しています。
AIXDEPINはどのような課題に遭遇しますか?
私たちはこの10年間で月に行くことを選択し、他のことをすることを選択します。簡単だからではなく、ハートだからです。
– ジョン・フィッツジェラルド・ケネディ
Depin分散ストレージと分散コンピューティングを使用して、信頼なしに人工知能モデルを構築することには、まだ多くの課題があります。
作業検証
本質的に、コンピューティングディープラーニングモデルとパウマイニングが一般に計算され、最下層はドア回路間の信号の変化です。マクロでは、「役に立たない計算」とハッシュ関数の計算を介して逆方向の導出は、ディープラーニングの各レイヤーのパラメーター値を計算し、それにより効率的なAIモデルを構築します。
事実、Pow Miningは、元の画像を計算するのが難しい場合、ハッシュ機能を使用しています。したがって、各レイヤーの出力は、後者のレイヤーの入力として使用されます。
>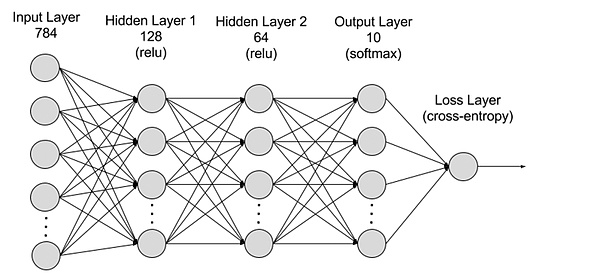
From:AWS
それ以外の場合、作業検証は非常に重要です。
1つのタイプのアイデアは、異なるサーバーが同じコンピューティングタスクを実行できるようにし、同じことが同じかどうかを繰り返してテストすることにより、作業の有効性を検証することです。ただし、ほとんどのモデル計算は確信がありません。同じ結果をまったく同じ計算環境でも再現することはできず、統計的にしか類似していません。さらに、繰り返し計算はコストの急速な上昇につながり、これはdepinのコスト削減と効率の重要な目標と矛盾しています。
別のタイプのアイデアは、まず、結果が効果的に計算されると考えています。
並列化
前述のように、Depinのpr索は主に長いテールの消費者レベルのコンピューティング市場であり、単一のデバイスが提供できるコンピューティング能力は比較的限られていることが運命づけられています。大規模なAIモデルの場合、単一のデバイスでのトレーニング時間は非常に長くなり、トレーニングに必要な時間を短縮する必要があります。
ディープラーニングトレーニングの並列化の主な難しさは、この依存関係のタスク間の依存性です。
現在、ディープラーニングトレーニングの並列化は、主に並列とモデルの平行に分割されています。
データの並列とは、複数のマシン上のデータの分布を指します。モデルのすべてのパラメーターを保存し、トレーニングにローカルデータを使用し、最後に各マシンのパラメーターを集計します。データの並列は、データの量が多い場合に効果的ですが、パラメーターを集計するために同期する必要があります。
モデルの平行は、モデルサイズを単一のマシンに配置できず、モデルを複数のマシンで分割でき、各マシンがモデルのパラメーターの一部を保存する場合です。フォワード通信と逆通信の間で通信するには、さまざまなマシンが必要です。モデルの平行には、モデルが大きい場合は利点がありますが、広がりのあるときの通信オーバーヘッドは大きいです。
異なるレイヤー間の勾配情報の場合、同期の更新と非同期更新に分けることができます。同期アップデートはシンプルで直接的ですが、待機時間が短くなります。
>
From:スタンフォード大学、並行および分散の深い学習
プライバシー
世界は個人のプライバシーの保護の波を引き起こしており、さまざまな国の政府が個人データのプライバシーとセキュリティの保護を強化しています。AIは多数のパブリックデータセットを使用していますが、異なるAIモデルの独自のユーザーデータでもあります。
プライバシーを公開せずに、トレーニングプロセス中に独自のデータの利点を取得する方法は?構築されたAIモデルパラメーターが漏れないようにする方法は?
これらは、プライバシーの2つの側面、データプライバシーとモデルプライバシーです。データプライバシーはユーザーによって保護されており、モデルのプライバシー保護はモデル組織を構築することです。現在の場合、データプライバシーはモデルのプライバシーよりもはるかに重要です。
さまざまなソリューションがプライバシーの問題を解決しようとしています。連邦学習はデータのソースで訓練され、データは局所的に残され、モデルパラメーターはデータのプライバシーを確保するために送信されます。
ケース分析:市場での高品質のプロジェクトは何ですか?
ジェネシン
Gensynは、AIモデルをトレーニングするための分散コンピューティングネットワークです。ネットワークは、Polkadotに基づいたブロックチェーンの層を使用して、深い学習タスクが正しく実行されているかどうかを確認し、コマンドごとに支払いをトリガーします。2020年に設立された、2023年6月に4,300万ドルの資金調達が開示され、A16ZがLEDが開示されました。
Gensynは、勾配ベースの最適化プロセスに基づいて勾配ベースのメタデータを使用して実行作業の証明書を構築し、再操作と検証作業と一貫性を可能にするために、マルチグレイン、グラフィックベースの正確なプロトコルと交差緩和デバイスによって実装されています。 。仕事の検証の信頼性をさらに強化するために、Gensynはインセンティブを作成するという誓約を導入しました。
システムには、提出者、ソリューション、検証、記者の4種類の参加者がいます。
•提出者はシステムのシステムであり、計算するタスクを提供し、完成した作業ユニットの支払いを提供します。
•ソリューションデバイスは、システムのメインワーカーです。
•検証装置は、非構成トレーニングプロセスを線形計算にリンクするための鍵です。
•レポーターは、最後の防衛線です。
解決策は誓約する必要があり、レポーターは解決策の仕事を検査します。
Gensynの予測によると、この計画は、トレーニングコストを集中型サプライヤーの1/5に削減すると予想されています。
>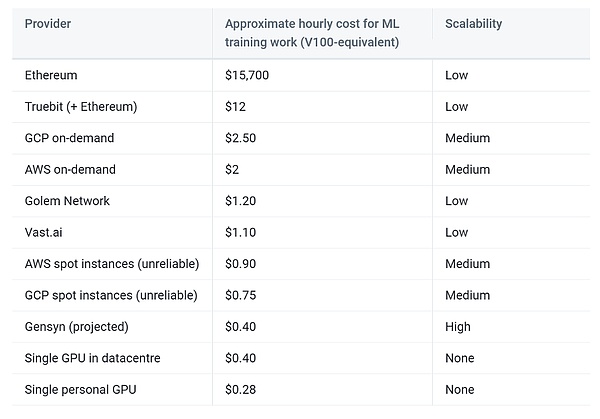
From:Gensyn
FedMl
FEDMLは、どこでもあらゆる規模で分散化および共同AIのための分散型協力機械学習プラットフォームです。より具体的には、FEDMLは、機械学習モデルをトレーニング、展開、監視、継続的に改善できるMLOPSエコシステムを提供し、同時にプライバシーを保護する方法で組み合わせデータ、モデル、コンピューティングリソースに協力します。2022年に設立されたFEDMLは、2023年3月に600万ドルのシードラウンドファイナンスを開示しました。
FEDMLは、それぞれFedML-APIとFEDML-COREの2つの重要なコンポーネントで構成されており、それぞれハイエンドAPIと基礎となるAPIを表しています。
FEDML-COREには、分散通信とモデルトレーニングの2つの独立したモジュールが含まれています。通信モジュールは、MPIに基づいて、異なる労働者/クライアント間の基礎となる通信を担当します。
FEDML-APIは、FEDML-CORE上に構築されています。FEDML-COREを使用すると、クライアントプログラミングインターフェイスを使用して、新しい分散アルゴリズムを簡単に実現できます。
FEDMLチームの最新の作業は、FEDML Nexus AIを使用して、AI100の20倍安価と1.88倍高速であるAIモデルの推論を実施することを証明しています。
>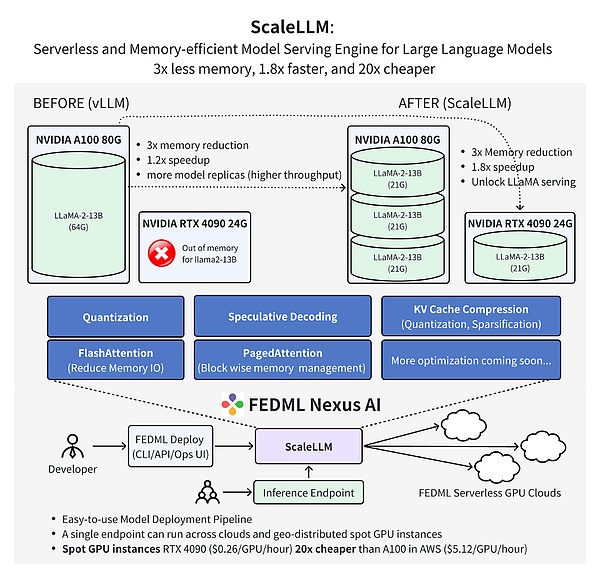
FROM:FEDML
将来の見通し:デピンはAI民主主義をもたらします
ある日、AIはAGIにさらに発展しました。
AIとDepinの統合により、新しい技術的成長点が開かれ、人工知能の発展に大きな機会が提供されました。Depinは、AIに大量の分散コンピューティングパワーとデータを提供します。これは、より大きなスケールモデルを訓練し、より強力なインテリジェンスを実現するのに役立ちます。同時に、DepinはAIをよりオープンで安全で信頼性の高い方向に発展させ、単一のセンターのインフラストラクチャへの依存を減らしました。
未来を楽しみにして、AIとDepinは引き続き発展します。分散ネットワークは、特大のモデルをトレーニングするための強力な基盤を提供し、これらのモデルはdepinアプリケーションで重要な役割を果たします。プライバシーとセキュリティを保護しながら、AIはDepinネットワークプロトコルとアルゴリズムの最適化を支援します。AIとDepinは、より効率的で公正で、より信頼できるデジタルワールドをもたらすことを楽しみにしています。