Auteur: Cynique, Shigeru
Guide:En utilisant la puissance des algorithmes, la puissance de calcul et les données, l’avancement de la technologie de l’IA est de redéfinir la frontière entre le traitement des données et la prise de décision intelligente.Dans le même temps, DePin représente le paradigme de réseau centralisé et basé sur la blockchain sur l’infrastructure centralisée.
Alors que le monde évolue vers la transformation numérique, l’IA et Depin (infrastructure physique décentralisée) sont devenus les technologies de base pour promouvoir la réforme de tous les horizons.La fusion de l’IA et de DePin peut non seulement favoriser l’itération et l’application rapides de la technologie, mais également ouvrir un modèle de service plus sûr, transparent et efficace pour apporter des changements de grande envergure à l’économie mondiale.
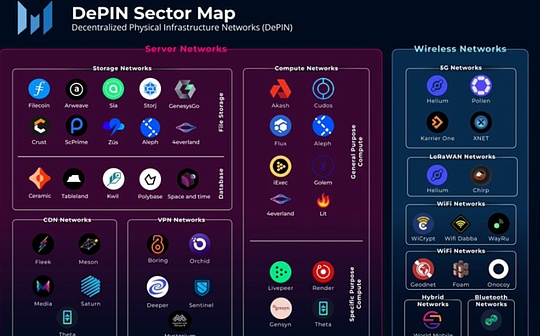
Depin: Décentralisation et carence, le pilier de l’économie numérique
Depin est une abréviation d’infrastructures physiques décentralisées.Dans un sens étroit, Depin se réfère principalement au réseau distribué d’infrastructures physiques traditionnelles soutenues par la technologie du grand livre distribué, telles que les réseaux électriques, les réseaux de communication et les réseaux de positionnement.Dans un sens large, tous les réseaux distribués pris en charge par l’équipement physique peuvent être appelés Depin, tels que les réseaux de stockage et les réseaux informatiques.
>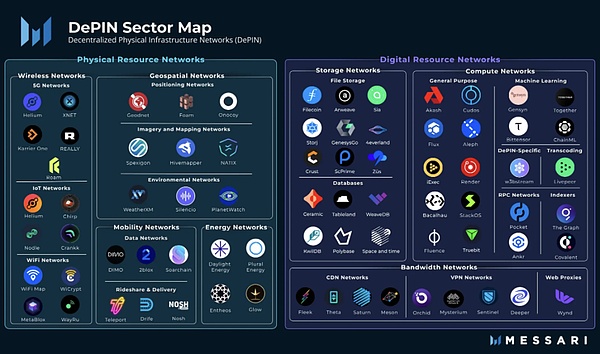
De: Messari
Si la crypto a apporté des changements décentralisés au niveau financier, alors Depin est une solution décentralisée dans l’économie réelle.On peut dire que la machine à miner POW est un depin.Dès le premier jour, Depin est le pilier de base de Web3.
AI trois éléments -algorithme, puissance de calcul, données, dépin monopolize
Le développement de l’intelligence artificielle est généralement considéré comme dépend de trois éléments clés: les algorithmes, la puissance de calcul et les données.L’algorithme fait référence au modèle mathématique et à la logique du programme du système Drive AI.
>
Lequel des trois éléments est le plus important?Avant l’apparition de Chatgpt, les gens pensent généralement qu’il s’agit d’un algorithme, sinon les conférences académiques et les journaux ne seront pas remplis de fin de trégration par des algorithmes.Après l’apparition de Chatgpt et LLM, qui soutient son LLM intelligent, les gens ont commencé à réaliser l’importance des deux derniers.La puissance de calcul massive est la condition préalable à la production du modèle.
À l’ère des grands modèles, l’IA est passée de la sculpture fine aux briques volantes vigoureusement.Les jetons sont inspirés pour tirer parti du marché à long terme.
La décentralisation de l’IA n’est pas une option, mais une option obligatoire
Bien sûr, certaines personnes demanderont, la puissance de calcul et les données sont disponibles dans les salles informatiques d’AWS, et elles sont meilleures que Depin en termes de stabilité et d’expérience.
Cette déclaration est naturellement logique.Pourquoi?Parce que seules les grandes sociétés Internet ont suffisamment de données de haute qualité et la puissance informatique soutenue par de solides ressources financières.Mais c’est faux, les gens ne veulent plus être manipulés par les géants d’Internet.
D’une part, l’IA centralisée présente des risques de confidentialité et de sécurité des données, qui peuvent être examinés et contrôlés;
>
De: https://www.gensyn.ai//
Les êtres humains ne devraient pas avoir besoin d’un âge de l’IA Martin Luther, et les gens devraient avoir le droit de parler directement à Dieu.
Regardez Depin: la réduction des coûts et l’efficacité sont la clé
Même si vous mettez de côté le différend entre la décentralisation et les valeurs centralisées, du point de vue commercial, l’utilisation de Depin pour l’IA est toujours souhaitable.
Tout d’abord, nous devons clairement réaliser que bien que les géants de l’Internet aient maîtrisé un grand nombre de ressources de carte graphique haut de gamme, la combinaison de cartes graphiques de consommation disséminées dans les personnes peut également constituer un réseau d’alimentation informatique très considérable, c’est-à-dire, L’effet à long terme de la puissance de calcul.Ce type de carte graphique de consommation est en fait très élevé.Tant que les incitations données par DePin peuvent dépasser la facture d’électricité, l’utilisateur a la motivation de contribuer au réseau.Dans le même temps, toutes les installations physiques sont gérées par l’utilisateur lui-même.
Pour les données, le réseau Depin peut libérer la disponibilité de données potentielles grâce à l’informatique Edge et à d’autres méthodes et réduire les coûts de transmission.Dans le même temps, la plupart des réseaux de stockage distribués ont automatiquement des fonctions de lourdeur, réduisant le travail de nettoyage des données de formation d’IA.
Enfin, l’économie de la cryptographie apportée par DePin améliore l’espace de tolérance aux défauts du système, qui devrait atteindre une situation gagnante de prestataires, de consommateurs et de plateformes.
>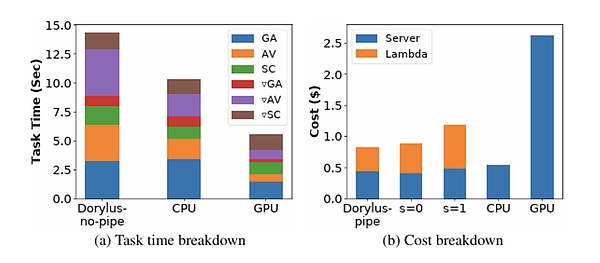
De: UCLA
Dans le cas où vous ne croyez pas, les dernières recherches de l’UCLA montrent que l’utilisation de calculs décentralisés dans le même coût a atteint 2,75 fois les performances par rapport au cluster GPU traditionnel.
Quels défis AixDepin rencontrera-t-il?
Nous choisissons d’aller sur la lune au cours de cette décennie et de faire l’autre chose, non pas parce qu’ils sont faciles, mais car ils sont Hart.
—— John Fitzgerald Kennedy
L’utilisation du stockage distribué Depin et de l’informatique distribuée pour construire un modèle d’intelligence artificielle sans confiance présente encore de nombreux défis.
Vérification du travail
Essentiellement, les modèles d’apprentissage en profondeur et l’exploitation de POW sont généralement calculés, et la couche inférieure est des changements de signal entre les circuits de porte.Dans la macro, l’extraction de POW est un « calcul inutile ». et la dérivation inverse calculent les valeurs des paramètres de chaque couche dans l’apprentissage en profondeur, créant ainsi un modèle d’IA efficace.
Le fait est que «l’informatique inutile» telle que Mining utilise des fonctions de hachage. La sortie de chaque couche est utilisée comme entrée de cette dernière couche.
>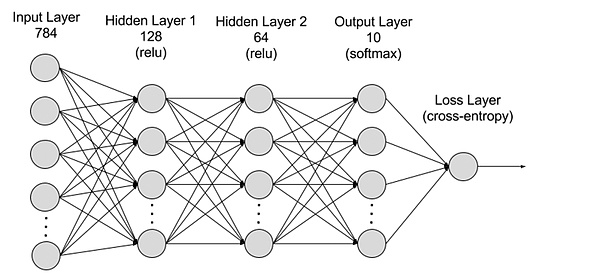
De: AWS
La vérification du travail est très critique.
Un type d’idée consiste à permettre à différents serveurs d’effectuer la même tâche informatique et de vérifier l’efficacité du travail en répétant et en testant si la même chose est la même.Cependant, la plupart des calculs du modèle ne sont pas certains, et les mêmes résultats ne peuvent pas être reproduits même dans un environnement de calcul exactement dans le même sens, et ils ne peuvent être similaires qu’en statistiquement.De plus, les calculs répétés entraîneront une augmentation rapide des coûts, ce qui est incompatible avec les principaux objectifs de la réduction et de l’efficacité des coûts de dépoi.
Un autre type d’idée est le mécanisme optimiste.
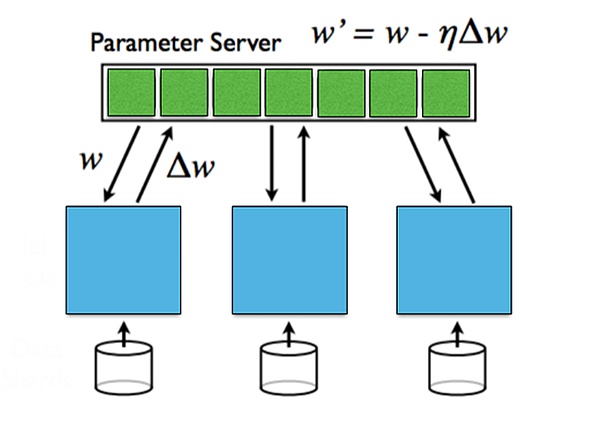
Parallélisation
Comme mentionné précédemment, le Prying de DePin est principalement le marché de l’informatique au niveau des consommateurs à longue queue, qui est destiné que la puissance de calcul qu’un seul appareil peut fournir est relativement limitée.Pour les grands modèles d’IA, le temps de formation sur un seul appareil sera très long.
La principale difficulté de la parallélisation de la formation en profondeur est la dépendance entre les tâches de l’avant et de l’arrière.
À l’heure actuelle, la parallélisation de la formation d’apprentissage en profondeur est principalement divisée en parallèle et parallèle parallèle.
Les données parallèles se réfèrent à la distribution des données sur plusieurs machines.Les données parallèles sont efficaces lorsque la quantité de données est grande, mais elle doit être synchronisée pour les paramètres agrégés.
Le modèle parallèle est lorsque la taille du modèle ne peut pas être placée dans une seule machine et que le modèle peut être divisé sur plusieurs machines, et chaque machine enregistre une partie des paramètres du modèle.Différentes machines sont nécessaires pour communiquer entre la communication directe et inversée.Le parallèle du modèle a un avantage lorsque le modèle est grand, mais les frais généraux de communication lorsqu’il se propage est grand.
Pour les informations de dégradé entre différentes couches, elle peut être divisée en mises à jour synchrones et mises à jour asynchrones.La mise à jour synchrone est simple et directe, mais elle augmentera le temps d’attente; l’algorithme de mise à jour asynchrone est court, mais le problème de la stabilité sera introduit.
>
De: Stanford University, parallèle et distribué Deep Learning
confidentialité
Le monde déclenche la vague de protection de la vie privée, et les gouvernements de divers pays renforcent la protection de la confidentialité et de la sécurité des données personnelles.Bien que l’IA utilise un grand nombre d’ensembles de données publiques, il s’agit également d’une données utilisateur propriétaires de différents modèles d’IA.
Comment obtenir les avantages des données propriétaires pendant le processus de formation sans exposer la vie privée?Comment s’assurer que les paramètres du modèle AI construits ne sont pas divulgués?
Ce sont deux aspects de la confidentialité, de la confidentialité des données et de la confidentialité du modèle.La confidentialité des données est protégée par les utilisateurs et la protection de la confidentialité du modèle consiste à créer une organisation modèle.Dans les cas actuels, la confidentialité des données est beaucoup plus importante que la confidentialité du modèle.
Une variété de solutions tentent de résoudre le problème de la vie privée.L’apprentissage fédéral est formé à la source des données, et les données sont laissées localement, et les paramètres du modèle sont transmis pour garantir la confidentialité des données;
Analyse de cas: Quels sont les projets de haute qualité sur le marché?
Gènes
Gensyn est un réseau informatique distribué pour la formation des modèles d’IA.Le réseau utilise une couche de blockchain basée sur Polkadot pour vérifier si la tâche d’apprentissage en profondeur a été exécutée correctement et déclenche le paiement par commande.Créée en 2020, un financement round A de 43 millions de dollars a été divulgué en juin 2023 et A16Z a mené.
Gensyn utilise des métadonnées basées sur le gradient basées sur le processus d’optimisation basé sur le gradient pour construire le certificat de travail d’exécution, et est implémenté par un protocole précis et un dispositif de réduction basé sur le graphique et la cohérence de la réévaluation et de la vérification de la réévaluation pour permettre la réévaluation et la vérification et la cohérence et la cohérence . En fin de compte, la chaîne est confirmée pour assurer l’efficacité du calcul.Afin de renforcer davantage la fiabilité de la vérification du travail, Gensyn a introduit l’engagement de créer des incitations.
Il existe quatre types de participants dans le système: les soumissionnaires, la solution, les vérifications et les journalistes.
• Les auteurs sont le système du système, fournissant des tâches à calculer et payez l’unité de travail terminée.
• Le dispositif de solution est le principal travailleur du système.
• Le dispositif de vérification est la clé pour lier le processus de formation non confirmé avec le calcul linéaire.
• Le journaliste est la dernière ligne de défense.
La solution doit s’engager, le journaliste inspecte le travail de la solution.
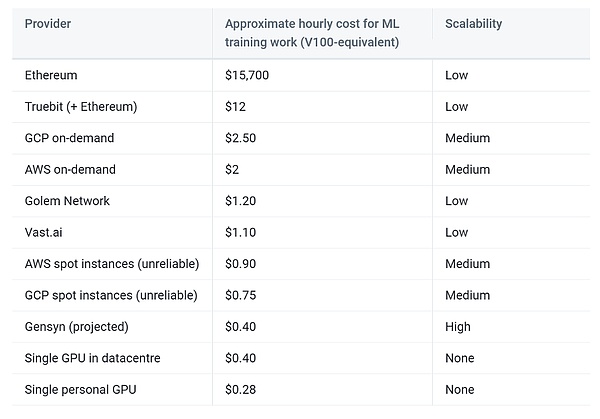
Selon les prévisions de Gensyn, le plan devrait réduire le coût de formation à 1/5 du fournisseur centralisé.
>
De: Gensyn
FedML
FedML est une plate-forme d’apprentissage automatique de coopération décentralisée pour la décentralisation et l’IA collaborative à n’importe quelle échelle n’importe où.Plus précisément, FedML fournit un écosystème MLOPS qui peut former, déployer, surveiller et améliorer en continu des modèles d’apprentissage automatique, et en même temps coopérer dans les données combinées, les modèles et les ressources informatiques en matière de protection de la confidentialité.Créée en 2022, FedML a révélé un financement du cycle de semences de 6 millions de dollars en mars 2023.
FedML est composé de deux composants clés: FedML-API et FedML-core, respectivement, représentant respectivement des API haut de gamme et des API sous-jacentes.
FedML-core comprend deux modules indépendants de communication distribuée et de formation des modèles.Le module de communication est responsable de la communication sous-jacente entre les différents travailleurs / clients, sur la base de MPI;
FEDML-API est construit sur FedMl-Core.Avec Fedml-Core, de nouveaux algorithmes distribués peuvent être facilement réalisés en utilisant une interface de programmation client.
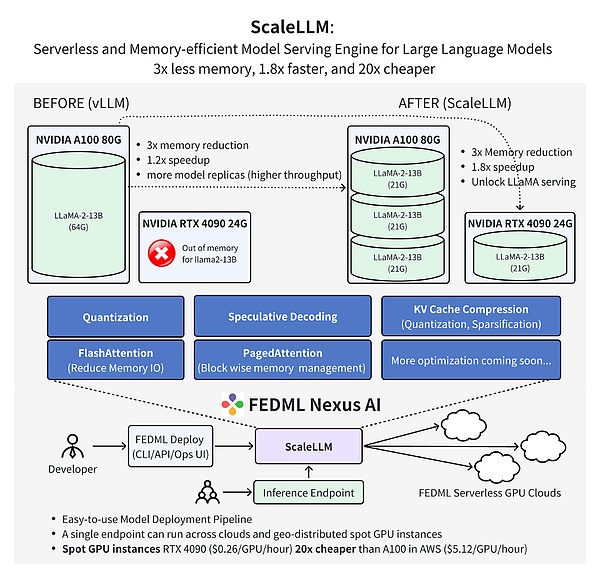
Le dernier travail de l’équipe FEDML prouve que l’utilisation de FedML Nexus AI pour effectuer un raisonnement de modèle AI sur le GPU Consumer GPU RTX 4090, ce qui est 20 fois moins cher que l’A100 et 1,88 fois plus rapidement.
>
De: Fedml
Perspectives futures: Depin apporte la démocratie de l’IA
Un jour, l’IA s’est développée en AGI.
La fusion de l’IA et de DePin a ouvert un nouveau point de croissance technologique, offrant d’énormes opportunités pour le développement de l’intelligence artificielle.Depin fournit à l’IA une grande quantité de puissance et de données de calcul distribuées, ce qui aide à former un modèle à l’échelle plus grande et à obtenir une intelligence plus forte.Dans le même temps, DePin a également fait un développement de l’IA dans une direction plus ouverte, sûre et fiable pour réduire la dépendance à l’infrastructure d’un seul centre.
Dans l’attente de l’avenir, l’IA et DePin continueront de se développer.Le réseau distribué fournira une base solide pour la formation de modèles surdimensionnés, et ces modèles joueront un rôle important dans les applications Depin.Tout en protégeant la confidentialité et la sécurité, l’IA aidera également le protocole de réseau DePin et l’optimisation des algorithmes.Nous attendons avec impatience l’IA et DePin apporte des mondes numériques plus efficaces, équitables et plus crédibles.







