
Autor: Vitalik Buterin, @Vitalik.eth;
Eine Strategie für eine bessere Dezentralisierung in Anreizprotokollen ist die Bestrafung für Relevanz.Das heißt, wenn sich ein Teilnehmer nicht ordnungsgemäß verhält (einschließlich Unfälle), desto mehr andere Teilnehmer (gemessen von Totaleth), die sich mit ihnen nicht ordnungsgemäß verhalten, desto größer wird die Bestrafung, die er sein wird.Die Theorie besagt, dass, wenn Sie ein großer Teilnehmer sind, alle Fehler, die Sie machen, in allen „Identitäten“, die Sie kontrollieren, eher kopiert werden, auch wenn Sie Ihre Token in viele nominell unabhängige Konten verbreiten.
Diese Technologie wurde im Mechanismus des Ethereum -Schnitts (und wohl inaktiven Lecks) angewendet.Rand-Case-Anreize, die nur bei sehr besonderen Angriffen auftreten, erscheinen jedoch nie in der Praxis.Wahrscheinlich nicht genug, um die Dezentralisierung zu inspirieren.
Dieser Artikel schlägt vor, ähnliche Antikorrelationsanreize auf „triviale“ Fehlfälle wie fehlende Beweise auszudehnen, die fast alle Validatoren zumindest gelegentlich tun.Die Theorie legt nahe, dass größere Staker, einschließlich wohlhabender Personen und das Einstecken von Pools, viele Validatoren auf derselben Internetverbindung oder sogar auf demselben physischen Computer führen werden, was zu unverhältnismäßig verwandten Fehlern führt.Solche Staker können für jeden Knoten immer separate physikalische Einstellungen vornehmen, aber wenn sie dies tun, bedeutet dies, dass wir die Größenbekämpfungspflicht vollständig beseitigt haben.
Soliditätsprüfung: Sind Fehler von verschiedenen Validatoren in demselben „Cluster“ eher miteinander korrelieren?
Wir können dies überprüfen, indem wir zwei Datensätze kombinieren: (i) Beweisdaten aus jüngsten Zeiträumen, auszeigen, welche Validatoren während jedes Steckplatzes bewiesen werden sollen und welche Validatoren tatsächlich bewiesen sind, und (ii) die Validator -ID einem Cluster mit vielen Validatoren zuordnen (so wie als „Lido“, „Coinbase“, „Vitalik Buterin“).Du kannstHierAnwesendHierUndHierFinden Sie die Müllkopie des ersteren, inHierFinden Sie die Müllkippe des letzteren.
Wir führen dann ein Skript aus, um die Gesamtzahl der gemeinsamen Fehler zu berechnen: Zwei Instanzen von Validatoren im selben Cluster werden zugewiesen, um im gleichen Zeitfenster zu beweisen und in diesem Zeitfenster zu scheitern.
Wir berechnen auch das ErwarteteGemeinsamer Fehler:Wenn das Versagen ein Gesamtergebnis der zufälligen Chance ist, sollte die Anzahl der häufigen Fehler auftreten.
Angenommen, es gibt 10 Validatoren, eine der Clustergröße beträgt 4, die anderen sind unabhängig und 3 Validatoren scheitern: Zwei befinden sich im Cluster und einer liegt außerhalb des Clusters.
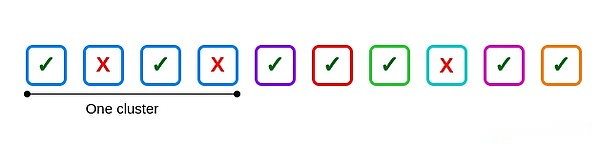
Hier ist ein häufiger Fehler: der zweite und vierte Validatoren im ersten Cluster.Wenn alle vier Validatoren im Cluster ausfallen, treten sechs gemeinsame Fehler auf, eine pro sechs möglichen Paare.
Aber wie viele häufige Fehler sollten vorgenommen werden?Dies ist eine schwierige philosophische Frage.Verschiedene Möglichkeiten zu beantworten:
Angenommen, die Anzahl der üblichen Fehler entspricht der Fehlerrate anderer Validatoren in diesem Slot, multipliziert mit der Anzahl der Validatoren im Cluster und senkt ihn in zwei Hälften, um die wiederholten Berechnungen auszugleichen.Für das obige Beispiel wird 2/3 gegeben.
Berechnen Sie die globale Ausfallrate, quadratisch und multiplizieren Sie sie mit [n*(n-1)]/2 für jeden Cluster.Dies ist gegeben [(3/10)^2]*6 = 0,54
Verteilern Sie die Misserfolge jedes Validators in seiner gesamten Geschichte zufällig.
Jede Methode ist nicht perfekt.Die ersten beiden Methoden berücksichtigen verschiedene Cluster mit unterschiedlichen Qualitätseinstellungen nicht.Gleichzeitig berücksichtigt die letzte Methode die Korrelationen, die sich aus verschiedenen Zeitfenster mit unterschiedlichen inhärenten Schwierigkeiten ergeben. Block hat die Posting ist außergewöhnlich spät.
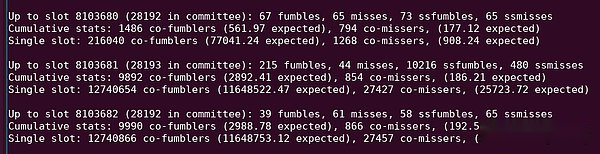
Siehe „10216 SSFumbles“ in dieser Python -Ausgabe.
Am Ende habe ich drei Methoden implementiert: die ersten beiden oben und ein komplexere Ansatz. Ich habe „tatsächliche Co-Failure“ mit „gefälschter Co-Failure“ verglich eine ähnliche Ausfallrate.
Ich habe auch deutlich unterschiedenFehlerUndvermissen.Meine Definition dieser Begriffe lautet wie folgt:
Fehler: Wenn der Verifizierer den Beweis in der aktuellen Periode verfehlt, aber in der Vorzeit korrekt beweist;
vermissen: Als der Verifizierer den Beweis in der aktuellen Periode verpasste und auch den Beweis in der vorherigen Periode verpasste.
Ziel ist es, zwei unterschiedliche Phänomene zu unterscheiden: (i) Netzwerkversagen während des normalen Betriebs und (ii) offline- oder langfristiges Versagen.
Ich mache diese Analyse auch gleichzeitig auf zwei Datensätzen: die maximale Frist und die Einzelschlitzfrist.Der erste Datensatz behandelt den Validator nur, wenn der Beweis überhaupt nicht enthalten ist.Wenn der Beweis nicht in einem einzigen Steckplatz enthalten ist, behandelt der zweite Datensatz den Validator als Fehler.
Hier sind die Ergebnisse meiner ersten beiden Methoden zur Berechnung erwarteter häufiger Fehler.SSFumbles und SSmiss hier beziehen sich auf Ziele und Fehler, die einen Einzel-Slot-Datensatz verwenden.
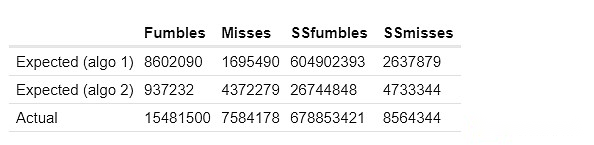
Für den ersten Ansatz unterscheiden sich das tatsächliche Verhalten, da für die Effizienz ein eingeschränkterer Datensatz verwendet wird:

Die „erwarteten“ und „gefälschten Cluster“ -Säulen zeigen, wie viele gemeinsame Fehler „im Cluster basierend auf den oben genannten Techniken sein sollten.Die tatsächliche Spalte zeigt, wie viele gemeinsame Fehler tatsächlich existieren.Wir sehen konsequent starke Hinweise auf „zu viele Korrelationsfehler“ innerhalb des Clusters: Zwei Validatoren im selben Cluster verpassen signifikant höhere Beweise gleichzeitig als zwei Validatoren in verschiedenen Clustern.
Wie wenden wir es auf die Strafregeln an?
Ich mache ein einfaches Argument: In jedem Schlitz, lasse P die Anzahl der derzeit übersehenen Slots unterteilen, die im Durchschnitt der letzten 32 Slots übersehen werden.
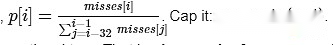
Die Strafe für den Nachweis dieses Slot sollte proportional zu p sein.
Das heißt,Im Vergleich zu anderen jüngsten Slots ist die Strafe für nicht proportional zur Anzahl der fehlgeschlagenen Validatoren in diesem Slot.
Es gibt ein gutes Merkmal dieses Mechanismus, das heißt, es ist nicht einfach anzugreifen: Auf jeden Fall reduziert das Versagen Ihre Strafen, und das Manipulieren des Durchschnitts reicht aus, um eine Wirkung zu haben, bei der Sie viele Fehler selbst vornehmen müssen.
Lassen Sie uns nun versuchen, es tatsächlich auszuführen.Hier sind die Gesamtstrafe für große Cluster, mittlere Cluster, kleine Cluster und alle Validatoren (einschließlich Nichtkluster):
Basic:Ein Punkt wird für jeden Fehler abgezogen (dh, ähnlich der aktuellen Situation)
Basic_SS:Gleiches, aber müssen einen einzelnen Slot einbeziehen, um als Miss betrachtet zu werden
Überschritten:Verwenden Sie das oben berechnete P, um den P -Punkt zu bestrafen
Extra_SS:Verwenden Sie das oben berechnete P, um den P -Punkt zu bestrafen, und erfordert einen einzelnen Steckplatz, um keinen Miss enthalten zu haben

Unter Verwendung des „Basis“ -Schemas haben große Schemata etwa das 1,4-fache Vorteil gegenüber kleinen Schemata (etwa 1,2-mal in Einzel-Slot-Datensätzen).Unter Verwendung des „zusätzlichen“ Schemas sank der Wert auf das 1,3-fache (ungefähr 1,1-fach in einem einzelnen Slot-Datensatz).Durch mehrere andere Iterationen, die leicht unterschiedliche Datensätze verwenden, verengt das überschüssige Strafsystem einheitlich die Vorteile von „Big People“ gegenüber „Little People“.
Was ist los?
Es gibt nur sehr wenige Fehler pro Slot: Normalerweise nur ein paar Dutzend.Dies ist viel kleiner als fast jeder „große Anteil“.Tatsächlich ist es geringer als die Anzahl der in einem einzelnen Stecker aktiven Validatoren als die großen Staker (d. H. 1/32 ihres Gesamtbestandes).Wenn ein großer Staker viele Knoten auf demselben physischen Computer oder einer Internetverbindung ausführt, kann jeder Fehler alle seine Validatoren beeinflussen.
Das heisst:Wenn große Validatoren nachweisen, dass es sich um einen Beweisversagen handelt, ändern sie die Fehlerquote des aktuellen Steckplatzes im Alleingang, was wiederum ihre Strafe erhöht.Kleine Validatoren tun dies nicht.
Grundsätzlich können Hauptaktionäre dieses Bestrafungsschema umgehen, indem sie jeden Validator in eine separate Internetverbindung platzieren.Dies opfert jedoch die Volkswirtschaften, die große Stakeholder dieselbe physische Infrastruktur wiederverwenden können.
Weitere Analyse
-
Suchen Sie nach anderen Strategien, um das Ausmaß dieses Effekts zu bestätigen, bei dem Validatoren im selben Cluster wahrscheinlich gleichzeitig versagen.
-
Versuchen Sie, ein ideales (aber immer noch einfacher Überanpassung und Unutilisierung) Belohnungs-/Bestrafungsschema zu finden, um den durchschnittlichen Vorteil großer Validatoren gegenüber kleinen Validatoren zu minimieren.
-
Versuchen Sie, die Sicherheit solcher Anreizpläne zu demonstrieren und einen „Konstruktionsraum“ ideal zu identifizieren, in dem das Risiko eines seltsamen Angriffs (z. B. strategisch offline zu einem bestimmten Zeitpunkt zur Manipulation des Durchschnitts) zu teuer und nicht wert ist.
-
Cluster nach geografischer Lage.Dies kann bestimmen, ob der Mechanismus auch eine geografische Dezentralisierung inspirieren kann.
-
Clustering durch (Ausführungs- und Beacon-) Client -Software.Dies kann bestimmen, ob der Mechanismus auch die Verwendung einer kleinen Anzahl von Kunden anregen kann.







