Auteur: Lucas Tcheyan, Arjun Yenamandra, Source: Galaxy Research, compilé par: Bitchain Vision
Introduction
L’année dernière, Galaxy Research a publié son premier article sur l’intersection de la crypto-monnaie et de l’intelligence artificielle. L’article explore comment la crypto-monnaie sans confiance et infrastructure sans autorisation peut devenir le fondement de l’innovation de l’IA.Il s’agit notamment de l’émergence d’un marché décentralisé pour le traitement de la puissance (ou de l’informatique) qui a émergé en réponse à la pénurie de processeurs graphiques (GPU);Les premières applications de l’apprentissage automatique des connaissances zéro (ZKML) dans le raisonnement vérifiable sur la chaîne; et le potentiel des agents d’IA autonomes pour simplifier les interactions complexes et utiliser les crypto-monnaies comme support indigène d’échange.
À cette époque, bon nombre de ces initiatives étaient à leurs balbutiements, mais n’étaient qu’une preuve convaincante de concepts qui impliquent qu’ils avaient des avantages pratiques par rapport aux solutions centralisées, mais n’avaient pas encore suffisamment élargie pour remodeler le paysage de l’IA.Cependant, au cours de l’année depuis lors, l’IA décentralisée a fait des progrès significatifs pour y parvenir.Pour saisir cette élan et découvrir les progrès les plus prometteurs, Galaxy Research publiera une série d’articles au cours de l’année à venir pour explorer des verticales spécifiques dans les frontières de l’intelligence artificielle du chiffrement +.
Cet article a été publié pour la première fois dans une formation décentralisée, en se concentrant sur des projets dédiés à la mise en œuvre de la formation sans autorisation des modèles de base à l’échelle mondiale.Les motivations de ces projets sont doubles.D’un point de vue pratique, ils ont reconnu qu’un grand nombre de GPU inactifs dans le monde peuvent être utilisés pour la formation modèle, offrant aux ingénieurs d’IA du monde entier un processus de formation autrement insupportable et faisant du développement d’IA open source une réalité.Dans une perspective conceptuelle, ces équipes sont motivées par le contrôle strict de l’une des révolutions technologiques les plus importantes de notre temps et le besoin urgent de créer des alternatives ouvertes.
Plus largement, pour le champ de cryptage, la mise en œuvre de la formation décentralisée et ultérieure du modèle de base est une étape clé pour construire une pile AI en pleine chaîne qui ne nécessite aucune autorisation et est accessible à chaque couche.Le marché du GPU peut accéder aux modèles et fournir le matériel requis pour la formation et l’inférence.Les fournisseurs ZKML peuvent être utilisés pour vérifier la sortie du modèle et protéger la confidentialité.Les agents de l’IA peuvent agir comme des éléments constitutifs composables qui combinent des modèles, des sources de données et des protocoles dans des applications d’ordre supérieur.
Ce rapport explore l’architecture sous-jacente du protocole d’intelligence artificielle décentralisée, les problèmes techniques qu’il vise à résoudre et les perspectives d’une formation décentralisée.La prémisse sous-jacente des crypto-monnaies et de l’intelligence artificielle reste la même il y a un an.Les crypto-monnaies fournissent à l’IA une couche de règlement de transfert de valeur sans permission, sans confiance et sans confiance.Le défi est maintenant de prouver que les approches décentralisées peuvent apporter des avantages pratiques par rapport aux approches centralisées.
Bases de la formation des modèles
Avant de plonger dans les dernières avancées de la formation décentralisée, il est nécessaire d’avoir une compréhension de base des modèles de grandes langues (LLM) et de leur architecture sous-jacente.Cela aidera les lecteurs à comprendre comment ces projets fonctionnent et les principaux problèmes qu’ils essaient de résoudre.
Transformateur
Les modèles de grande langue (LLMS) (tels que Chatgpt) sont alimentés par une architecture appelée Transformer. Transformer a d’abord proposé dans un journal Google 2017 et est l’une des innovations les plus importantes dans le domaine du développement de l’intelligence artificielle.En bref, le transformateur extrait les données (appelés jetons) et applique divers mécanismes pour apprendre la relation entre ces jetons.
La relation entre les entrées est modélisée à l’aide de poids.Les poids peuvent être considérés comme les millions à des milliards de boutons qui composent le modèle, qui sont constamment ajustés jusqu’à ce que la prochaine entrée de la séquence puisse être prédite de manière cohérente.Une fois la formation terminée, le modèle peut essentiellement capturer les modèles et les significations derrière le langage humain.
Les composantes clés de la formation des transformateurs comprennent:
-
Livraison vers l’avant:Dans la première étape du processus de formation, le transformateur entre dans un lot de jetons à partir d’un ensemble de données plus large. Sur la base de ces entrées, le modèle essaie de prédire quel devrait être le prochain token.Au début de l’entraînement, les poids du modèle sont aléatoires.
-
Calcul des pertes:Les prévisions de propagation à l’avant sont ensuite utilisées pour calculer le score de perte, qui mesure l’écart entre ces prévisions et les marques réelles dans le lot de données d’origine du modèle d’entrée.En d’autres termes, comment les prédictions produites par le modèle pendant la propagation directe se comparent-elles aux marqueurs réels utilisés pour le former dans le plus grand ensemble de données?Pendant l’entraînement, l’objectif est de réduire ce score de perte pour améliorer la précision du modèle.
-
Rétropropagation:Le gradient de chaque poids est ensuite calculé en utilisant le score de perte.Ces gradients indiquent au modèle comment ajuster les poids pour réduire les pertes avant la propagation vers l’avant suivante.
-
Optimiseurrenouveler:OptimiserrL’algorithme lit ces gradients et ajuste chaque poids pour réduire la perte.
-
répéter:Répétez les étapes ci-dessus jusqu’à ce que toutes les données soient consommées et que le modèle commence à atteindre la convergence–En d’autres termes, lorsque une optimisation plus approfondie ne se traduit plus par une réduction significative des pertes ou une amélioration des performances.
Formation (pré-formation et post-formation)
Le processus complet de formation du modèle se compose de deux étapes indépendantes: pré-formation et post-formation. Les étapes ci-dessus sont un composant central du processus de pré-formation.Une fois terminé, ils génèrent un modèle de base pré-formé, communément appelé modèle de base.
Cependant, les modèles nécessitent souvent une amélioration supplémentaire après la pré-entraînement, ce qui est appelé post-entraînement.Le post-formation est utilisé pour améliorer davantage le modèle de base de diverses manières, notamment l’amélioration de sa précision ou la personnalisation de cas d’utilisation spécifiques tels que la traduction ou le diagnostic médical.
Le post-formation est une étape clé pour faire aujourd’hui d’un outil puissant de grands modèles de langue (LLMS).Il existe plusieurs façons de s’entraîner par la suite. Les deux plus populaires sont:
-
Réglage fin supervisé (SFT):SFT est très similaire au processus de pré-formation ci-dessus.La principale différence est que le modèle de base est formé sur des ensembles de données ou des conseils et réponses plus soigneusement planifiés, afin qu’il puisse apprendre à suivre des instructions spécifiques ou à se concentrer sur un certain champ.
-
Apprentissage par renforcement (RL):RL n’améliore pas le modèle en entrant de nouvelles données, mais plutôt en évaluant la sortie du modèle et en laissant le modèle à mettre à jour le poids pour maximiser cette récompense. Récemment, le modèle d’inférence (décrit ci-dessous) a utilisé RL pour améliorer sa sortie.Ces dernières années, avec des problèmes de mise à l’échelle avant la formation émergents, des progrès significatifs ont été réalisés dans l’utilisation des modèles RL et d’inférence après l’entraînement, car il améliore considérablement les performances du modèle sans données supplémentaires ou de grandes quantités de calcul.
Plus précisément, la formation post-RL est idéale pour résoudre les obstacles confrontés à une formation dispersée (décrite ci-dessous).En effet, la plupart du temps dans RL, le modèle utilise des passes vers l’avant (le modèle fait des prédictions mais n’a pas encore changé) pour générer une grande quantité de sortie.Ces laissez-passer avant ne nécessitent pas de coordination ou de communication entre les machines et peuvent être effectuées de manière asynchrone.Ils sont également parallèles, ce qui signifie qu’ils peuvent être décomposés en sous-tâches indépendantes qui peuvent être effectuées simultanément sur plusieurs GPU.En effet, chaque déploiement peut être calculé indépendamment et ajouter simplement le calcul pour augmenter le débit grâce à la course d’entraînement.Ce n’est qu’après que la meilleure réponse sera sélectionnée que le modèle mettra à jour ses poids internes, réduisant la fréquence à laquelle la machine doit être synchronisée.
Une fois le modèle formé, le processus de l’utilisation pour générer une sortie est appelé inférence.Contrairement à la formation qui nécessite des ajustements à des millions, voire des milliards de poids, le raisonnement maintient ces poids inchangés et les applique simplement à de nouvelles intrants.Pour les modèles de grande langue (LLM), le raisonnement signifie prendre une invite, l’exécuter vers diverses couches du modèle et étape par étape prédire le balisage le plus probable.Étant donné que l’inférence ne nécessite pas de rétropropagation (le processus d’ajustement des poids en fonction de l’erreur du modèle) ou des mises à jour de poids, elle nécessite beaucoup moins de calcul que la formation, mais en raison de l’énorme échelle des modèles modernes, il est toujours à forte intensité de ressources.
En bref: le raisonnement est le moteur des applications telles que les chatbots, les assistants de code et les outils de traduction.À ce stade, le modèle met ses «connaissances apprises» en pratique.
Formation des frais généraux
La promotion du processus de formation ci-dessus nécessite des logiciels et du matériel hautement spécialisés en ressources et hautement spécialisés pour s’exécuter à grande échelle.Les investissements dans les principaux laboratoires d’intelligence artificielle du monde ont atteint des niveaux sans précédent, allant de centaines de millions à des milliards de dollars.Le PDG d’OpenAI, Sam Altman, a déclaré que le GPT-4 coûtait plus de 100 millions de dollars, tandis que le PDG d’Anthropic Dario Amodei a déclaré que plus d’un milliard de dollars de programmes de formation étaient déjà en cours.
Une grande partie de ces coûts provient des GPU.Les meilleurs GPU comme H100 ou B200 de NVIDIA coûtent jusqu’à 30 000 $, et OpenAI prévoit de déployer plus d’un million de GPU d’ici la fin de 2025. Cependant, il ne suffit pas d’avoir le pouvoir du GPU seul.Ces systèmes doivent être déployés dans des centres de données haute performance équipés d’une infrastructure de communication à ultra-haute vitesse.Des technologies telles que NVIDIA NVLINK prennent en charge l’échange rapide de données entre les GPU dans le serveur, tandis que InfinIBand se connecte aux clusters de serveur afin qu’ils puissent s’exécuter en une seule structure informatique unifiée.
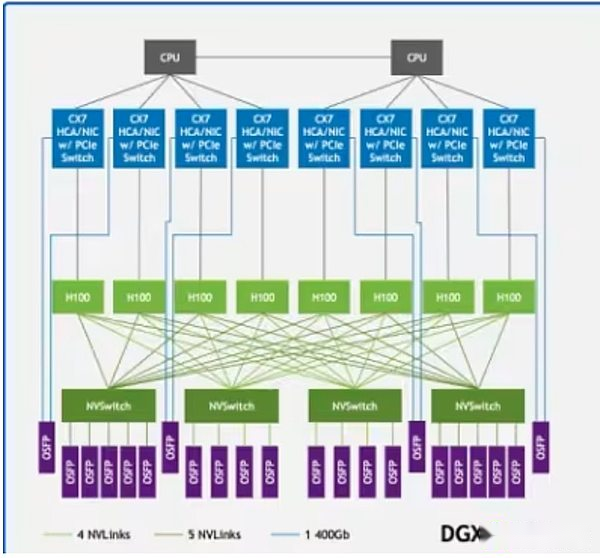 NvLink dans l’architecture d’échantillon DGX H100 relie les GPU (rectangles vert clair) dans le système, tandis qu’Infiniband relie les serveurs (lignes vertes) dans un réseau unifié
NvLink dans l’architecture d’échantillon DGX H100 relie les GPU (rectangles vert clair) dans le système, tandis qu’Infiniband relie les serveurs (lignes vertes) dans un réseau unifié
Par conséquent, la plupart des modèles de base sont développés par des laboratoires AI centralisés tels que OpenAI, Anthropic, Meta, Google et XAI. Seuls ces géants ont les riches ressources nécessaires à la formation.Bien que cela ait provoqué une percée importante dans la formation et les performances des modèles, il a également concentré le contrôle du développement de modèles de base de premier plan entre les mains de quelques entités.En outre, il existe des preuves de plus en plus que la loi de l’échelle peut fonctionner, limitant l’efficacité de l’amélioration de l’intelligence des modèles pré-entraînés en ajoutant simplement un calcul ou des données.
Pour relever ce défi, au cours des dernières années, un groupe d’ingénieurs d’IA a commencé à développer de nouvelles méthodes de formation de modèle pour essayer de répondre à ces complexités techniques et de réduire les exigences d’énormes ressources.Cet article appelle cet effort «formation décentralisée».
Formation décentralisée et distribuée
Le succès de Bitcoin prouve que l’informatique et le capital peuvent être coordonnées de manière décentralisée, assurant ainsi la sécurité des grands réseaux économiques.La formation décentralisée vise à construire un réseau décentralisé en utilisant les caractéristiques des crypto-monnaies, y compris des mécanismes sans autorisation, sans confiance et incitatifs, à former un puissant modèle de base comparable aux prestataires centralisés.
Dans une formation décentralisée, les nœuds situés à différents endroits du monde entier travaillent sur des réseaux incitatifs sans autorisation, contribuant à la formation de modèles d’intelligence artificielle.Ceci est différent de la formation distribuée, qui fait référence au modèle formé dans différentes régions mais effectué par une ou plusieurs entités agréées (c’est-à-dire par le biais d’un processus de liste blanche).Cependant, la faisabilité d’une formation décentralisée doit être basée sur une formation distribuée.De nombreux laboratoires centralisés, conscients des limites strictes de leurs milieux de formation, ont commencé à explorer des moyens de mettre en œuvre une formation distribuée pour obtenir des résultats comparables aux paramètres existants.
Il existe des obstacles pratiques qui empêchent la formation décentralisée de devenir une réalité:
-
Offres de communication:Lorsque les nœuds sont dispersés géographiquement, ils ne peuvent pas accéder à l’infrastructure de communication ci-dessus.Une formation décentralisée nécessite une prise en compte de la vitesse du réseau standard, une transmission fréquente de grandes quantités de données et une synchronisation du GPU pendant la formation.
-
vérifier:Les réseaux de formation décentralisés sont essentiellement sans licence et sont conçus pour permettre à quiconque de contribuer sa puissance de calcul.Par conséquent, ils doivent développer des mécanismes de vérification pour empêcher les contributeurs de tenter de détruire le réseau par des intrants incorrects ou malveillants, ou d’exploiter les vulnérabilités du système pour obtenir des récompenses sans contribuer à un travail efficace.
-
calculer: Quelle que soit la taille, les réseaux décentralisés doivent rassembler suffisamment de puissance de calcul pour former des modèles.Bien que cela donne certains des avantages des réseaux décentralisés, qui ont été conçus pour permettre à quiconque avec un GPU de participer au processus de formation, il apporte également de la complexité, car ces réseaux doivent coordonner l’informatique hétérogène.
-
Incitations / financement / propriété et monétisation:Les réseaux de formation décentralisés doivent concevoir des mécanismes d’incitation et des modèles de propriété / monétisation pour assurer efficacement l’intégrité du réseau et récompenser la contribution des fournisseurs informatiques, des validateurs et des concepteurs de modèles.Cela contraste fortement avec le laboratoire centralisé où la construction et la monétisation du modèle sont effectuées par une entreprise.
Malgré ces limites, de nombreux projets mettent toujours en œuvre une formation décentralisée parce qu’elles croient que le contrôle du modèle sous-jacent ne devrait pas être entre les mains de quelques entreprises.Leur objectif est de faire face aux risques posés par une formation centralisée, tels que des défaillances de points uniques en raison de leur compréhension de quelques produits centralisés;Confidentialité et censure des données; évolutivité;et cohérence et biais dans l’intelligence artificielle. Plus largement, ils croient que le développement de l’intelligence artificielle open source est une nécessité, pas facultative.Sans infrastructure ouverte et vérifiable, l’innovation sera supprimée, l’accès sera limité à quelques classes privilégiées et la société héritera des systèmes d’IA façonnés par des incitations étroites.De ce point de vue, une formation décentralisée ne consiste pas seulement à construire des modèles compétitifs, mais aussi à créer un écosystème résilient, transparent et participatif qui reflète les intérêts collectifs plutôt que les intérêts propriétaires.
Aperçu du projet
Ci-dessous, nous donnerons un aperçu approfondi des mécanismes sous-jacents de plusieurs projets de formation décentralisés.
Réserve
arrière-plan
Fondée en 2022, la recherche sur les États-Unis est une institution de recherche sur l’IA open source. L’équipe a commencé comme un groupe informel de chercheurs et de développeurs d’IA open source travaillant pour répondre aux limites du code d’IA open source. Sa mission est de «créer et fournir le meilleur modèle open source».
L’équipe a longtemps considéré la formation décentralisée comme un obstacle majeur.Plus précisément, ils ont réalisé que les outils pour accéder aux GPU et pour coordonner la communication entre les GPU ont été développés principalement pour répondre à de grandes sociétés d’IA centralisées, qui ont laissé des organisations limitées en ressources avec peu de place pour participer à un développement significatif.Par exemple, les derniers GPU Blackwell de NVIDIA (comme le B200) peuvent communiquer entre eux en utilisant un système de commutation NVLink à des vitesses allant jusqu’à 1,8 To par seconde.Ceci est comparable à la bande passante totale de l’infrastructure Internet traditionnelle et ne peut être obtenu que dans des déploiements centralisés à l’échelle du centre de données.Par conséquent, il est presque impossible pour les réseaux petits ou distribués d’atteindre les performances de grands laboratoires d’IA sans repenser les stratégies de communication.
Avant de se lancer dans la résolution du problème de la formation décentralisée, nous a apporté des contributions importantes au domaine de l’intelligence artificielle.En août 2023, nous a publié « YARN: Extension de fenêtre de contexte efficace pour les modèles de gros langues ».Cet article résout un problème simple mais important: la plupart des modèles d’IA ne peuvent se souvenir et traiter une quantité fixe de texte à la fois (c’est-à-dire leur « fenêtre de contexte »).Par exemple, un modèle formé avec une limite de 2 000 mots commencera bientôt à oublier ou à perdre des informations si le document d’entrée est plus long.Le fil présente un moyen d’étendre cette limitation davantage sans recycler le modèle à partir de zéro.Il ajuste la façon dont le modèle suit la position des mots (comme les signets dans un livre) afin qu’il puisse toujours suivre le flux d’informations même si le texte représente des dizaines de milliers de mots.La méthode permet au modèle de traiter des séquences de jusqu’à 128 000 marqueurs – sur la longueur des aventures de Mark Twain de Huckleberry Finn, en utilisant beaucoup moins de puissance de calcul et de données d’entraînement en même temps que l’ancienne méthode.En bref, le fil permet aux modèles AI de «lire» et de comprendre des documents, des conversations ou des ensembles de données plus longs à la fois.Il s’agit d’une avancée majeure dans l’expansion des capacités de l’IA et a été adoptée par une communauté de recherche plus large, notamment Openai et Deepseek en Chine.
Démo et distribution
En mars 2024, Dous a publié une percée dans le domaine de la formation distribuée appelée « Optimisation du moment découplé » (démo). Demo a été développé par les chercheurs de l’EA Bowen Peng et Jeffrey Quesnellle en collaboration avec Diederik P. Kingma, co-fondateur d’Openai et inventeur d’Adamw Optimizer.Il s’agit du principal élément constitutif de la pile d’entraînement décentralisée de l’OVE, qui réduit les frais généraux de communication dans les paramètres de formation des modèles parallèles de données distribuées en réduisant la quantité de données échangées entre les GPU.Dans la formation parallèle de données, chaque nœud enregistre une copie complète des poids du modèle, mais l’ensemble de données est divisé en blocs traités par différents nœuds.
L’ADAMW est l’un des optimisateurs les plus couramment utilisés dans la formation des modèles.Une fonction clé de l’ADAMW est de lisser ce qu’on appelle la dynamique, la moyenne de fonctionnement des poids du modèle qui changent dans le passé.Essentiellement, ADAMW aide à éliminer le bruit introduit lors de l’entraînement parallèle des données, améliorant ainsi l’efficacité de la formation.La recherche sur les États-Unis crée un tout nouvel optimiseur basé sur ADAMW et Demo, divisant l’élan en pièces locales et partagées sur différents formateurs.Cela réduit la quantité de trafic requise entre les nœuds en limitant la quantité de données qui doivent être partagées entre les nœuds.
Demo se concentre sélectivement sur les paramètres les plus changeants lors de chaque itération du GPU.La logique est simple: les paramètres avec des variations plus importants sont cruciaux pour l’apprentissage et doivent être synchronisés entre les travailleurs avec une priorité plus élevée.Dans le même temps, les paramètres de changement plus lents peuvent être temporairement décalés sans affecter de manière significative la convergence.En fait, cela filtre les mises à jour du bruit tout en conservant les mises à jour les plus significatives.Nous utilise également des techniques de compression, y compris une méthode de transformée en cosinus discrète (DCT) similaire aux images compressées JPEG pour réduire davantage la quantité de données envoyées.En synchronisant uniquement les mises à jour les plus importantes, la démo réduit les frais généraux de communication de 10 à 1 000 fois (selon la taille du modèle).
En juin 2024, l’équipe de Dous a lancé sa deuxième innovation majeure, The Distributed Training Optimizer (Distro).Demo propose des innovations d’optimiseur de base, tandis que la distribution les intègre dans un cadre d’optimiseur plus large qui comprime davantage les informations partagées entre les GPU et aborde des problèmes tels que la synchronisation du GPU, la tolérance aux pannes et l’équilibrage de la charge.En décembre 2024, Dous a utilisé la distribution pour former un modèle avec 15 milliards de paramètres sur une architecture de type lama, prouvant la faisabilité de la méthode.
Psyché
En mai, nous sortiez Psyché, un cadre pour coordonner la formation décentralisée, d’autres innovations dans les architectures de démo et d’optimiseur. Les principales mises à niveau techniques de Psyché comprennent une formation asynchrone améliorée en permettant au GPU d’envoyer des mises à jour du modèle lors du démarrage de la prochaine étape de formation.Cela minimise le temps d’inactivité et rapproche l’utilisation du GPU plus près des systèmes centralisés et étroitement couplés.Psyché a encore amélioré la technologie de compression introduite par la distribution, ce qui réduit encore la charge de communication de 3 fois.
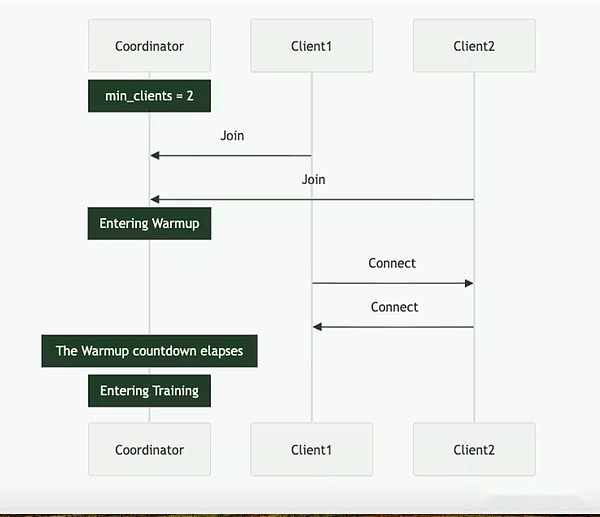
La psyché peut être réalisée grâce à une configuration entièrement en chaîne (via Solana) ou hors chaîne. Il contient trois acteurs principaux: le coordinateur, le client et le fournisseur de données.Le coordinateur stocke toutes les informations nécessaires pour faciliter l’opération de formation, y compris le dernier état du modèle, les clients participants et l’allocation des données et la vérification de la sortie.Le client est le fournisseur de GPU réel qui effectue des tâches de formation pendant les séries d’entraînement.En plus de la formation des modèles, ils sont impliqués dans le processus des témoins (décrit ci-dessous).Le fournisseur de données (le client peut le stocker par lui-même) fournit les données nécessaires à la formation.
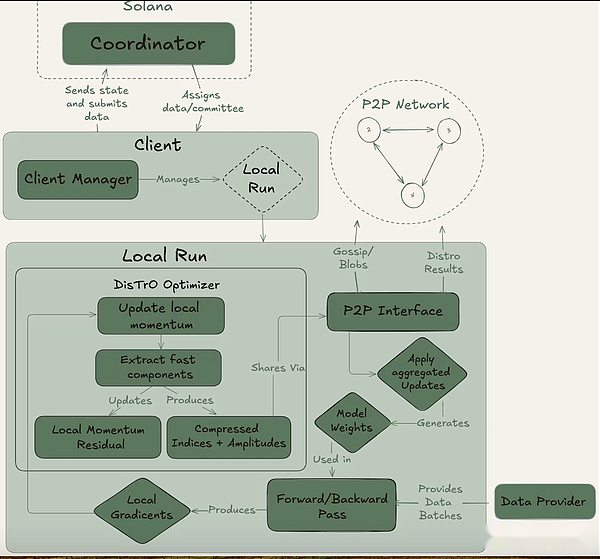 La psyché divise la formation en deux étapes différentes: l’époque et le pas.Cela crée des points d’entrée et de sortie naturels pour les clients afin qu’ils puissent participer sans investir dans une formation complète.Cette structure aide à minimiser les coûts d’opportunité pour les fournisseurs de GPU, car ils peuvent ne pas être en mesure d’investir des ressources tout au long de la course.
La psyché divise la formation en deux étapes différentes: l’époque et le pas.Cela crée des points d’entrée et de sortie naturels pour les clients afin qu’ils puissent participer sans investir dans une formation complète.Cette structure aide à minimiser les coûts d’opportunité pour les fournisseurs de GPU, car ils peuvent ne pas être en mesure d’investir des ressources tout au long de la course.
Au début d’une époque, le coordinateur définit les paramètres clés: l’architecture du modèle, l’ensemble de données à utiliser et le nombre de clients requis.Vient ensuite une brève phase d’échauffement, où le client se synchronisera avec le dernier point de contrôle du modèle, qui peut provenir d’une source publique ou d’une synchronisation point à point.Après le début de la formation, chaque client se verra attribuer une partie des données et formé localement.Après la mise à jour du calcul, le client diffuse ses résultats au reste du réseau avec la promesse de cryptage (le hachage SHA-256 qui prouve que le travail est effectué correctement).
Une partie du client est sélectionnée au hasard comme témoins à chaque tour et sert de principal mécanisme de vérification de la psyché.Ces témoins s’entraînent comme d’habitude, mais vérifient également quelles mises à jour des clients sont reçues et valides.Ils soumettent des filtres Bloom au coordinateur, une structure de données légère qui résume efficacement ces participations.Alors que nous lui-même admet que l’approche n’est pas parfaite car elle peut produire de faux positifs, les chercheurs sont prêts à accepter ce compromis pour l’efficacité.Une fois qu’un témoin mis à jour confirme que le quorum atteint, le coordinateur applique la mise à jour au modèle global et permet à tous les clients de synchroniser leur modèle avant d’entrer dans le tour suivant.
Surtout, la conception de Psyché permet un chevauchement dans la formation et la vérification.Une fois que le client a soumis la mise à jour, il peut immédiatement commencer à former le prochain lot sans attendre que le coordinateur ou d’autres clients terminent le cycle de formation précédent.Cette conception qui se chevauche, combinée à la technologie de compression de Distro, garantit que les frais généraux de communication sont maintenus minimes et que le GPU n’est pas inactif.
 En mai 2025, les recherches de Dous ont lancé la plus grande formation à ce jour: Consilience, un transformateur avec 40 milliards de paramètres, pré-formation d’environ 20 billions de jetons dans le réseau de formation Psyche Decentralized.La formation est toujours en cours.Jusqu’à présent, l’opération a été essentiellement stable, mais certains pics de perte se sont produits, ce qui indique que la trajectoire d’optimisation s’est brièvement déviée de la convergence.Pour ce faire, l’équipe est revenue au dernier point de contrôle de la santé et a encapsulé l’optimiseur en utilisant la protection à saut d’Olmo, qui saute automatiquement toute mise à jour de toute perte ou de gradient qui diffèrent de plusieurs écarts-types par rapport à la moyenne, réduisant le risque de pics futurs.
En mai 2025, les recherches de Dous ont lancé la plus grande formation à ce jour: Consilience, un transformateur avec 40 milliards de paramètres, pré-formation d’environ 20 billions de jetons dans le réseau de formation Psyche Decentralized.La formation est toujours en cours.Jusqu’à présent, l’opération a été essentiellement stable, mais certains pics de perte se sont produits, ce qui indique que la trajectoire d’optimisation s’est brièvement déviée de la convergence.Pour ce faire, l’équipe est revenue au dernier point de contrôle de la santé et a encapsulé l’optimiseur en utilisant la protection à saut d’Olmo, qui saute automatiquement toute mise à jour de toute perte ou de gradient qui diffèrent de plusieurs écarts-types par rapport à la moyenne, réduisant le risque de pics futurs.
Le rôle de Solana
Bien que Psyché puisse fonctionner dans un environnement hors chaîne, il est conçu pour être utilisé sur la blockchain Solana. Solana agit comme la couche de confiance et de responsabilité pour le réseau de formation, enregistrant les engagements des clients, les épreuves des témoins et les métadonnées de formation sur la chaîne.Cela crée une piste d’audit immuable pour chaque cycle de formation, permettant une vérification transparente de qui a apporté des contributions, quel travail a été fait et s’il est passé.
Dous prévoit également d’utiliser Solana pour faciliter la distribution des récompenses de formation.Bien que le projet n’ait pas publié l’économie de jetons formelle, la documentation de Psyche décrit un système dans lequel le coordinateur suivra les contributions de calcul du client et alloue des points en fonction des travaux validés.Ces points peuvent ensuite être échangés contre des jetons en agissant comme des contrats intelligents financiers en déformation.Les clients qui effectuent des étapes de formation efficaces peuvent recevoir des récompenses directement du contrat en fonction de leurs contributions.Psyché n’a pas encore utilisé le mécanisme de récompense lors de la formation, mais une fois officiellement lancé, le système devrait jouer un rôle central dans l’attribution des jetons de crypto-Nous.
Série de modèles Hermès
En plus de ces contributions à la recherche, nous a établi son premier statut de développeur de modèles open source avec sa série Hermes de modèles de grande langue réglés par l’instruction (LLM).En août 2024, l’équipe a lancé Hermes-3, une suite de modèles à paramètre à part entière basée sur LLAMA 3.1, qui a obtenu des résultats compétitifs dans le classement public, bien que relativement petit, comparable aux modèles propriétaires plus grands.
Récemment, nous a publié la série Hermes-4 Model en août 2025, la série de modèles la plus avancée à ce jour. HERMES-4 se concentre sur l’amélioration des capacités de raisonnement étape par étape du modèle, tout en se produisant parfaitement dans l’exécution régulière des instructions.Il a bien fonctionné en mathématiques, en programmation, en compréhension et en tests de bon sens.L’équipe adhère à la mission open source de nous et libère publiquement tous les poids Hermes-4 pour que tout le monde puisse utiliser et construire.En outre, Nous a publié une interface d’accessibilité du modèle appelé Nous Chat, qui sera disponible gratuitement au cours de la première semaine de version.
La publication du modèle Hermes ciments non seulement la crédibilité en tant qu’organisation de construction de modèles, mais fournit également une validation pratique pour son programme de recherche plus large.Chaque libération d’Hermès prouve que des capacités de pointe peuvent être obtenues dans un environnement ouvert, jetant les bases des percées de formation décentralisées des équipes (démo, distribution et psyché) et, finalement, conduisant à la course ambitieuse de la conslience 40b.
Atropos
Comme mentionné ci-dessus, l’apprentissage du renforcement joue un rôle de plus en plus important dans la post-formation en raison des progrès des modèles d’inférence et des limites d’expansion de la pré-formation. Atropos est la solution de Nous pour renforcer l’apprentissage dans un environnement décentralisé.Il s’agit d’un cadre d’apprentissage de renforcement modulaire plug-and-play pour LLM, en s’adaptant à différents backends d’inférence, méthodes de formation, ensembles de données et environnements d’apprentissage de renforcement.
Lorsque l’apprentissage post-renforcement est formé de manière décentralisée en utilisant un grand nombre de GPU, la sortie instantanée générée par le modèle pendant la formation aura des délais d’achèvement différents.ATROPOS agit comme un processeur de déploiement, c’est-à-dire un coordinateur central, qui coordonne la génération et l’achèvement des tâches entre les appareils, permettant ainsi une formation d’apprentissage en renforcement asynchrone.
La version initiale d’Atropos a été publiée en avril, mais ne contient actuellement qu’un cadre environnemental qui coordonne les tâches d’apprentissage du renforcement.Nous prévoit de publier un cadre de formation et de raisonnement complémentaire dans les prochains mois.
Intellect de premier ordre
arrière-plan
Fondée en 2024, Prime Intellect s’engage à construire une infrastructure de développement d’IA décentralisée à grande échelle. Fondée par Vincent Weisser et Johannes Hagemann, l’équipe s’est initialement concentrée sur l’intégration des ressources informatiques de fournisseurs centralisés et décentralisés pour soutenir la formation distribuée collaborative des modèles d’IA avancés.La mission de Prime Intellect est de démocratiser le développement de l’IA, permettant aux chercheurs et aux développeurs du monde entier d’accéder aux ressources informatiques évolutives et de posséder conjointement l’innovation ouverte de l’IA.
OpenDiloco, Intellect-1 et Prime
En juillet 2024, Prime Intellect a publié OpenLiloco, une version open source de DILOCO, une méthode de formation de modèle à faible communication développée par Google DeepMind pour une formation parallèle de données.Google a développé le modèle basé sur l’opinion que «la formation par rétro-compagation standard à une échelle moderne présente des défis d’ingénierie et d’infrastructure sans précédent… il est difficile de coordonner et de synchroniser étroitement un grand nombre d’accélérateurs.» Bien que cette déclaration se concentre sur l’aspect pratique de la formation à grande échelle plutôt que sur l’esprit de développement open source, il est par défaut les limites de la formation centralisée à long terme et la nécessité d’alternatives distribuées.
Diloco réduit la fréquence et la quantité d’informations partagées entre les GPU lors des modèles de formation. Dans des paramètres centralisés, les GPU partagent tous les gradients mis à jour les uns avec les autres après chaque étape de la formation.À Diloco, la fréquence de partage des gradients de mise à jour est plus faible pour réduire les frais généraux de communication.Cela crée une double architecture d’optimisation: les GPU individuels (ou clusters GPU) exécutent des optimisations internes, mettant à jour le poids de leurs propres modèles après chaque étape;Et les optimisations externes, les optimisations internes sont partagées entre les GPU, et tous les GPU sont ensuite mis à jour en fonction des modifications apportées.
OpenDiloco a démontré 90% à 95% de l’utilisation du GPU dans sa version initiale, ce qui signifie qu’en dépit d’être distribué sur deux continents et trois pays, peu de machines sont inactives.OpenDiloco est capable de reproduire des résultats et des performances de formation considérables, tandis que le volume de trafic est réduit de 500 fois (comme indiqué dans la ligne violette rattrapant la ligne bleue dans la figure ci-dessous).
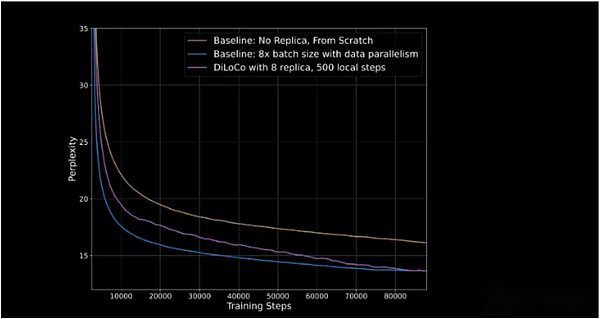
L’axe vertical représente la perplexité, qui mesure la capacité du modèle à prédire le marqueur suivant dans une séquence. Plus la perplexité est faible, plus les prédictions du modèle sont confiantes et plus la précision est élevée.
En octobre 2024, Prime Intellect commence à entraîner l’intellect-1, Il s’agit du premier modèle de langue des paramètres de 10 milliards de paramètres formé de manière distribuée. La formation a pris 42 jours et le modèle a été ouvert après cela. La formation est menée dans cinq pays sur trois continents.Le suivi de la formation démontre l’amélioration progressive de la formation distribuée, le taux d’utilisation de toutes les ressources informatiques atteignant 83%, et aux États-Unis seulement, le taux d’utilisation de la communication entre les nœuds atteint 96%.Le GPU utilisé par ce projet provient des fournisseurs Web2 et Web3, y compris les marchés GPU crypto tels que Akash, Hyperbolic et Olas.
Intellect-1 adopte le nouveau cadre de formation de Prime Intellect Prime, qui permet à Prime Intellect Training Systems de s’adapter lors du calcul de l’entrée inattendue et de la sortie de la formation continue.Il introduit des technologies innovantes telles que ElasticDeviceMesh, permettant aux contributeurs de rejoindre ou de quitter à tout moment.
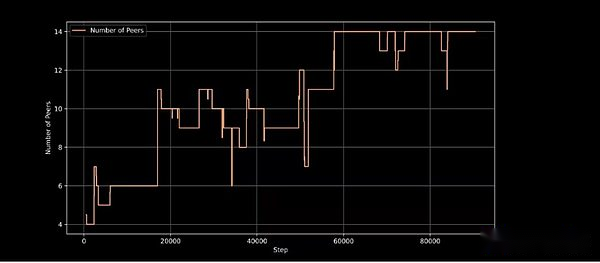
Nœuds de formation actifs à l’étape de formation, démontrant la capacité de l’architecture de formation à gérer la participation dynamique des nœuds
L’Intellect-1 est une validation importante de l’approche de formation décentralisée de Prime Intellect et a été félicité par des leaders d’opinion de l’IA tels que Jack Clark (co-fondateur d’Anthropic), et est considéré comme une démonstration viable d’une formation décentralisée.
Protocole
En février de cette année, Prime Intellect a ajouté une autre couche à sa pile, lancement du protocole.Protocol relie tous les outils de formation de Prime Intellect ensemble pour créer un réseau point à point pour une formation de modèle décentralisée.Ceux-ci incluent:
-
Calcule le GPU Switch pour faciliter les courses de formation.
-
Le cadre de formation principal réduit les frais généraux de communication et améliore la tolérance aux défauts.
-
Une bibliothèque open source appelée Genesys pour une génération et une validation de données synthétiques utiles dans le réglage RL Fine.
-
Un système de vérification léger appelé TOPLOC pour valider la sortie de l’exécution du modèle et des nœuds participants.
Le rôle de Protocol est similaire à la psyché de Nous, avec quatre acteurs principaux:
-
Travailleurs: un logiciel qui permet aux utilisateurs de contribuer leurs ressources informatiques à la formation ou à d’autres produits principaux liés à l’intellect AI.
-
Vérificateur: Vérifiez les contributions de calcul et prévenir les comportements malveillants.Prime Intellect s’efforce d’appliquer l’algorithme de vérification inférence de pointe TOPLOC à une formation décentralisée.
-
Orchestrateur: Un moyen de calculer les créateurs de piscines gérer les travailleurs.Il fonctionne similaire à l’orchestrateur de Dous.
-
Contrats intelligents: suivi des fournisseurs de ressources informatiques, réduisez le jalon des participants malveillants et payez les récompenses indépendamment.Actuellement, Prime Intellect fonctionne sur le réseau de test de Sepolia pour Ethereum L2 Base, mais Prime Intellect a déclaré qu’il préviendrait éventuellement de migrer vers sa propre blockchain.
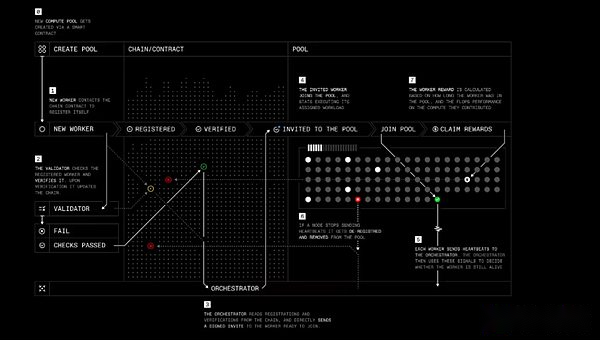 Formation protocole étape par étape
Formation protocole étape par étape
Le protocole vise finalement à permettre aux contributeurs de posséder des actions du modèle ou de recevoir des récompenses pour leur travail, tout en offrant aux projets d’IA open source avec de nouvelles façons de financer et de gérer le développement grâce à des contrats intelligents et des incitations collectives.
Intellect 2 et apprentissage du renforcement
En avril de cette année, Prime Intellect a commencé à former un modèle de paramètres de 32 milliards appelé Intellect-2.Intellect-1 se concentre sur la formation du modèle de base, tandis que l’intellect-2 utilise l’apprentissage du renforcement pour former des modèles d’inférence sur un autre modèle open source (QWQ-32B d’Alibaba).
L’équipe a introduit deux composantes d’infrastructure critiques pour rendre cette formation RL décentralisée pratique:
-
Prime-RL est un cadre d’apprentissage de renforcement pleinement asynchrone qui divise le processus d’apprentissage en trois étapes indépendantes: générer des réponses candidates; formation des réponses sélectionnées; et diffuser des poids de modèle mis à jour.Ce mécanisme de découplage permet au système de s’étendre sur les réseaux peu fiables, lents ou géographiquement distribués.Le processus de formation utilise une autre innovation de Prime Intellect, Genesys, pour générer des milliers de questions mathématiques, logiques et codantes, et est équipée d’un vérificateur automatique qui peut immédiatement dire si la réponse est correcte ou non.
-
Shardcast est un nouveau système pour distribuer rapidement des fichiers volumineux (tels que les poids du modèle mis à jour) sur le réseau.Shardcast ne télécharge pas toutes les mises à jour du serveur central, mais adopte une structure qui partage les mises à jour entre les machines.Cela maintient le réseau efficace, rapide et résilient.
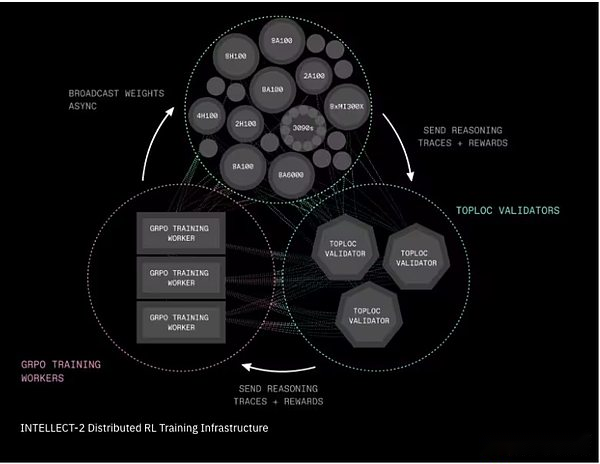 Intellect-2 Infrastructure de formation d’apprentissage en renforcement distribué
Intellect-2 Infrastructure de formation d’apprentissage en renforcement distribué
Pour Intellect-2, les contributeurs doivent également mettre le jeton Crypto Testnet pour participer à la formation. S’ils contribuent un travail efficace, ils recevront automatiquement des récompenses. Sinon, leur jalonnement peut être coupé.Bien qu’aucun financement réel n’ait été impliqué lors de ce test, cela met en évidence la forme initiale de certaines expériences crypto-économiques.Plus d’expériences sont nécessaires dans ce domaine, et nous nous attendons à de nouveaux changements dans l’application de l’économie cryptographique en termes de mécanismes de sécurité et d’incitation.En plus de l’intellect-2, Prime Intellect continue de mener à bien plusieurs programmes importants non couverts dans ce rapport, notamment:
-
Synthétique-2, un cadre de nouvelle génération pour générer et valider les tâches d’inférence;
-
Prime Collective Communications Library, qui met en œuvre des opérations de communication collective efficaces et tolérantes aux pannes (par exemple, la réduction via IP), et fournit un mécanisme de synchronisation de l’état partagé pour garder les pairs synchronisés, et permet une jonction dynamique et laissant les pairs à tout moment pendant la formation, ainsi qu’une optimisation automatique de la topologie de la bande passante;
-
Améliorez en continu la fonctionnalité de TOPLOC pour activer les preuves d’inférence évolutives et à faible coût pour vérifier la sortie du modèle;
-
Améliorations du protocole Intellect Prime et de l’économie cryptographique basée sur les leçons tirées de l’Intellect2 et du synthétique1
Recherche du pluralis
Alexander Long est un chercheur australien à l’apprentissage automatique avec un doctorat de l’Université de la Nouvelle-Galles du Sud. Il estime que la formation des modèles open source dépend trop des principaux laboratoires d’intelligence artificielle pour fournir les modèles de base aux autres pour s’entraîner.En avril 2023, il a fondé Pluralis Research, visant à ouvrir un chemin différent.
Pluralis Research utilise une approche appelée «apprentissage du protocole» pour résoudre le problème de formation décentralisé, qui est décrit comme «une bande passante basse, multi-participants hétérogènes, une formation et un raisonnement parallèles de modèle».Une caractéristique notable majeure de Pluralis est son modèle économique, qui fournit des gains de type actions aux contributeurs des modèles de formation pour inciter les contributions informatiques et attirer les meilleurs chercheurs de logiciels open source.Ce modèle économique est basé sur l’attribut de base de « l’innescutabilité »: c’est-à-dire qu’aucun participant ne peut obtenir un ensemble complet de poids, qui est étroitement lié à l’utilisation des méthodes de formation et du parallélisme du modèle.
Parallélisme modèle
L’architecture de formation de Pluralis utilise le parallélisme du modèle, qui est différent de l’approche du parallélisme des données mises en œuvre par la recherche-nous et l’intellect de premier ordre dans la formation initiale.À mesure que la taille du modèle augmente, même le rack H100, l’une des configurations GPU les plus avancées, est difficile à transporter un modèle complet.Le parallélisme du modèle fournit une solution à ce problème en divisant les composants individuels d’un seul modèle sur plusieurs GPU.
Il existe trois méthodes principales pour la parallélisation du modèle.
-
Parallélisme du pipeline: Les couches du modèle sont divisées sur différents GPU.Pendant l’entraînement, chaque petit lot de données traverse ces GPU comme un pipeline.
-
Parallélisme du tenseur (dans la couche): Au lieu de fournir la couche entière pour chaque GPU, le mathématique lourde dans chaque couche est séparé afin que plusieurs GPU puissent partager le travail d’une seule couche en même temps.
-
Parallèle mixte: En pratique, les grands modèles utilisent diverses méthodes, en utilisant des pipelines et des tenseurs en parallèle, et généralement en conjonction avec des données.
Le parallélisme du modèle est une avancée importante dans la formation distribuée car elle permet la formation de modèles à l’échelle de pointe, permettant au matériel de niveau inférieur de participer et à s’assurer que personne n’a accès à l’ensemble complet de poids du modèle.
Modèles d’apprentissage et de protocole de protocole
L’apprentissage du protocole est un cadre pour que Pluralis utilise la propriété et la monétisation du modèle dans un environnement de formation décentralisé. Pluralis met en évidence trois principes clés qui constituent le cadre d’apprentissage du protocole: la concentralisation, la motivation et la détruit.
La principale différence entre Pluralis et d’autres projets est l’accent mis sur la propriété du modèle.Étant donné que la valeur du modèle est principalement due à son poids, le modèle de protocole (Modèles de protocole) Essayez de diviser les poids du modèle afin qu’aucun participant unique pendant le processus de formation du modèle ne puisse avoir des poids complets.En fin de compte, cela donnera à chaque contributeur au modèle de formation une certaine propriété, partageant ainsi les avantages générés par le modèle.
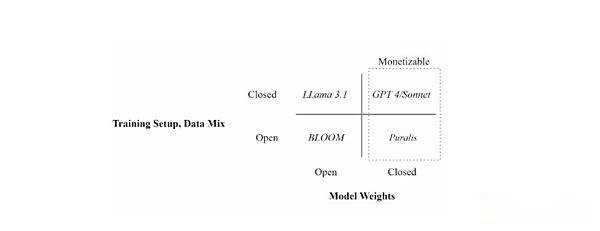 Positionnez différents modèles de langue à travers les paramètres de formation (ouverts vs données fermées) et la disponibilité du poids du modèle (ouvert vs fermé)
Positionnez différents modèles de langue à travers les paramètres de formation (ouverts vs données fermées) et la disponibilité du poids du modèle (ouvert vs fermé)
Il s’agit d’une approche fondamentalement différente de l’économie des modèles décentralisés par rapport aux exemples précédents. D’autres projets incitent les contributions en fournissant un pool de financement alloué aux contributeurs pendant le cycle de formation en fonction de mesures spécifiques (généralement le temps ou la puissance de calcul apportée).Les contributeurs de Pluralis sont motivés à consacrer des ressources uniquement aux modèles qui, selon eux, sont les plus susceptibles de réussir.La formation d’un modèle mal effectué gaspillera la puissance de calcul, l’énergie et le temps car les modèles mal exécutés ne généreront aucun chiffre d’affaires.
Ceci est différent de la méthode précédente.Premièrement, il ne nécessite pas que les personnes qui souhaitent former le modèle à lever les fonds initiaux pour payer les contributeurs, réduisant ainsi le seuil de formation et de développement du modèle.Deuxièmement, il coordonne mieux les mécanismes d’incitation entre les concepteurs de modèles et les fournisseurs informatiques, car les deux parties souhaitent que la version finale du modèle soit aussi parfaite que possible pour assurer son succès.Cela offre également la possibilité de l’émergence de la spécialisation de la formation des modèles.Par exemple, il peut y avoir plus de formateurs porteurs de risques fournissant des services informatiques à des modèles précoces / expérimentaux à la recherche de rendements plus élevés (similaires aux capital-risqueurs), tandis que les fournisseurs informatiques se concentrent uniquement sur les matures et plus susceptibles de postuler (similaires aux investisseurs en capital-investissement).
Bien que les PM puissent représenter une percée majeure dans la monétisation et les mécanismes d’incitation pour une formation décentralisée, le pluralis n’a pas développé ses méthodes de mise en œuvre spécifiques.Compte tenu de la forte complexité de l’approche, les problèmes qui n’ont pas encore été résolus comprennent la façon d’allouer la propriété du modèle, la façon d’allouer des avantages et même la façon de gérer les futures mises à niveau ou les cas d’utilisation du modèle.
Innovation de formation décentralisée
En plus des considérations économiques, l’apprentissage du protocole est confronté au même défi de base que les autres programmes de formation décentralisés, en utilisant des réseaux de GPU hétérogènes avec des limitations de communication pour former de grands modèles d’IA.
En juin de cette année, Pluralis a annoncé la formation réussie de 8 milliards de paramètres LLM basé sur l’architecture Llama 3 de Meta et a publié son article de modèle de protocole.Dans l’article, Pluralis montre comment réduire les frais généraux de communication entre les GPU qui effectuent un modèle de formation parallèle.Il le fait en limitant les signaux traversant chaque couche de transformateur à un minuscule sous-espace présélectionné, en compressant vers l’avant et vers l’arrière passe jusqu’à 99%, réduisant le trafic du réseau de 100 fois sans compromettre la précision ni ajouter des frais généraux significatifs.En bref, Pluralis a trouvé un moyen de comprimer les mêmes informations d’apprentissage à une petite fraction de la bande passante requise par les méthodes antérieures.
Il s’agit du premier entraînement décentralisé, et le modèle lui-même est dispersé sur les nœuds connectés par une bandon basse plutôt que dans la réplication.L’équipe a réussi à former un modèle LLAMA avec 8 milliards de paramètres sur des GPU de niveau grand public bas de gamme répartis sur quatre continents qui ne se connectent qu’à 80 mégaoctets par seconde de connexion Internet à domicile par jour.Dans l’article, Pluralis démontre que la convergence de ce modèle est aussi bonne que de fonctionner sur un cluster de centres de données de 100 Go. Dans la pratique, cela signifie que la formation décentralisée parallèle de modèles à grande échelle est désormais possible.
Enfin, un article de Pluralis sur l’entraînement asynchrone pour l’entraînement parallèle des pipelines a été reçu par l’ICML (l’une des principales conférences d’intelligence artificielle) en juillet.Lorsque la formation parallèle des pipelines est effectuée via Internet plutôt que dans les centres de données à haut débit, il fait également face à un goulot d’étranglement de communication car les nœuds fonctionnent dans un des pipelines essentiellement similaires, chaque nœud successif en attendant le nœud précédent pour mettre à jour le modèle.Cela peut conduire à une transmission d’informations obsolète et retardée du gradient.Le cadre de formation décentralisé démontré dans le document, Swarm, élimine deux goulots d’étranglement classiques qui entravent généralement la participation quotidienne du GPU à la formation: la capacité de la mémoire et la synchronisation serrée.L’élimination de ces deux goulets d’étranglement peut mieux utiliser tous les GPU disponibles, réduire le temps de formation et réduire les coûts, ce qui est essentiel pour mettre à l’échelle de grands modèles avec une infrastructure bénévole distribuée. Pour un bref aperçu de ce processus, regardez cette vidéo de Pluralis.
Pour l’avenir, Pluralis dit qu’il prévoit de lancer une formation en temps réel à laquelle n’importe qui peut participer bientôt, mais une date spécifique n’a pas été déterminée.Le lancement fournira une compréhension plus approfondie des aspects de l’accord qui n’ont pas encore été publiés, en particulier les modèles économiques et les infrastructures cryptographiques.
Temple
arrière-plan
Templar a été lancé en novembre 2024 et est un marché des tâches d’IA décentralisé motivé par des incitations basé sur le sous-réseau du protocole Bittensor.Il a commencé comme un cadre expérimental qui vise à rassembler les ressources GPU mondiales pour la pré-formation d’IA sans licence et vise à rendre la formation de modèles à grande échelle accessible, sécurisée et résiliente grâce aux incitations tokenisées de Bittensor, redéfinissant ainsi le développement de l’IA.
Dès le début, Templar a relevé le défi de coordonner la formation décentralisée pour la pré-formation LLM sur Internet.Il s’agit d’une tâche difficile, car la latence, les limitations de la bande passante et le matériel hétérogène rendent difficile pour les acteurs distribués d’atteindre l’efficacité des grappes centralisées, et les communications GPU sans faille de grappes centralisées permettent une itération rapide de modèles massifs.
Plus important encore, Templar donne la priorité à la participation qui est vraiment autorisée, permettant à toute personne disposant de ressources informatiques de participer à une formation en IA sans approbation, enregistrement ou gardien.Cette approche sans autorisation est cruciale pour la mission de Templar de démocratiser le développement de l’IA, car elle garantit que les capacités percée d’IA ne sont pas contrôlées par quelques entités centralisées mais peuvent émerger d’une collaboration ouverte dans le monde entier.
Templeformer
Templar utilise des données pour s’entraîner en parallèle, et il y a deux facteurs principaux:
-
mineur:Ces participants ont effectué des tâches de formation. Chaque mineur se synchronise avec le dernier modèle global, obtient des éclats de données uniques, s’entraîne localement en utilisant des passes vers l’avant et vers l’arrière, compresse les gradients à l’aide d’un optimiseur CCLOCO personnalisé (décrit ci-dessous) et soumet les mises à jour de gradient.
-
Vérificateur: le validateur télécharge et décompresse la mise à jour soumise par le mineur, l’applique à la copie locale du modèle et calculeAugmentation des pertes(Indicateurs qui mesurent le degré d’amélioration du modèle).Ces incréments sont utilisés pour marquer les contributions des mineurs via le système Gauntlet de Templar.
Pour réduire les frais généraux de communication, l’équipe de recherche de Templar a d’abord développé le bloc de compression Block Diloco (CCLOCO).Semblable à l’OVI, CCLOCO améliore les techniques de formation efficaces de communication telles que le cadre Google Diloco, réduisant les coûts de communication entre les nœuds par ordres de grandeur tout en réduisant les pertes souvent causées par de telles méthodes.Au lieu d’envoyer des mises à jour complètes à chaque étape, CCLOCO ne partage que les modifications les plus importantes à l’intervalle de définition et conserve un petit nombre de runs pour garantir qu’aucune donnée significative n’est perdue.Le système adopte un modèle basé sur la concurrence qui incite les mineurs à fournir des mises à jour à faible latence pour recevoir des récompenses.Pour recevoir des récompenses, les mineurs doivent suivre le réseau en déployant un matériel efficace.Cette structure concurrentielle est conçue pour garantir que seuls les participants qui maintiennent des performances suffisants peuvent participer au processus de formation, tandis que les contrôles d’assainissement légers filtrent des mises à jour sensiblement mauvaises ou mal formées.En août, Templar a officiellement publié l’architecture de formation mise à jour et l’a renommée SparSeloco.
Les vérificateurs utilisent le système Gauntlet de Templar pour suivre et mettre à jour la notation des compétences de chaque mineur en fonction des contributions de réduction de la perte de modèle observées.Avec la technologie appelée OpenSkill, les mineurs de haute qualité qui continuent d’être mis à jour efficacement recevront des cotes de compétences plus élevées, augmentant leur influence sur l’agrégation de modèles et gagnant plus de taos (jetons natifs du réseau de bittenseurs).Les mineurs avec des notes plus faibles seront rejetés pendant le processus d’agrégation.Après le score, les validateurs avec le plus haut engagement résumeront les mises à jour des meilleurs mineurs, signeront le nouveau modèle mondial et le publieront sur le stockage.Si le modèle est hors de synchronisation, les mineurs peuvent utiliser cette version du modèle pour rattraper leur retard.
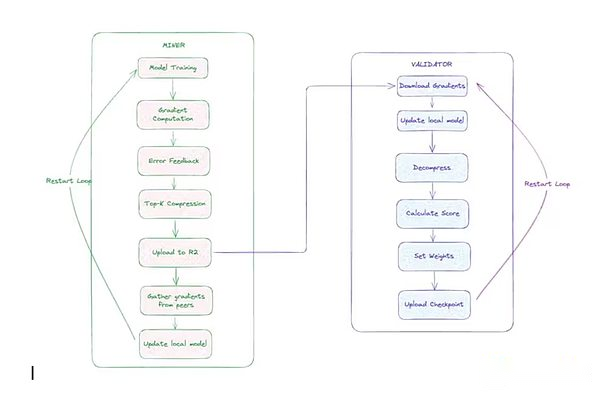 Architecture de formation décentralisée des Templiers
Architecture de formation décentralisée des Templiers
Templar a commencé trois cycles d’entraînement jusqu’à présent: Templar I, Templar II et Templar III.Templar I est un modèle avec 1,2 milliard de paramètres, déploiement de près de 200 GPU dans le monde.Templar II est en cours, forment un modèle avec 8 milliards de paramètres et prévoit de commencer une formation plus importante bientôt.Templar se concentre actuellement sur les modèles de formation avec des paramètres plus petits, un choix bien pensé conçu pour garantir que les mises à niveau de l’architecture de formation décentralisée (comme mentionné ci-dessus) peuvent fonctionner efficacement avant d’étendre à de plus grandes échelles de modèle.Des stratégies d’optimisation et de la planification aux itérations de recherche et aux incitations, ces idées sont validées sur 8 milliards de modèles avec des paramètres plus petits, permettant aux équipes d’itérer rapidement et de manière rentable.Après les progrès récents et la libération formelle de l’architecture de formation, l’équipe a lancé Templar III en septembre, un modèle avec 70 milliards de paramètres et la plus grande course de pré-formation dans le domaine décentralisé à ce jour.
Tao et mécanismes d’incitation
Une caractéristique clé de Templar est son modèle d’incitation qui est lié à Tao.Les récompenses sont allouées en fonction des contributions pondérées en fonction des compétences formées par le modèle.La plupart des protocoles (tels que Pluralis, Nous, Prime Intellect) ont des courses ou des prototypes sous licence, tandis que Templar fonctionne entièrement sur le réseau en temps réel de Bittensor.Cela fait de Templar le seul protocole qui a intégré une couche économique sans licence en temps réel dans son cadre de formation décentralisé.Ce déploiement de production en temps réel permet à Templar d’itérer son infrastructure dans des scénarios de course de formation en temps réel.
Chaque sous-réseau Bittensor fonctionne avec son propre jeton «Alpha», qui agit comme un signal de marché pour le mécanisme de récompense et les sous-réseaux pour percevoir la valeur. Le jeton alpha de Templar est appelé gamma.Les jetons alpha ne peuvent pas être échangés librement sur les marchés externes;Ils ne peuvent être échangés contre Taos que par le biais d’un pool de liquidités dédié à leur sous-réseau à l’aide d’un marché automatisé (AMM).Les utilisateurs peuvent engager Tao d’obtenir un gamma ou échanger le gamma en tant que Tao, mais ils ne peuvent pas échanger directement le gamma contre des jetons alpha à d’autres sous-réseaux.Le système dynamique Tao (DTAO) de Bittensor utilise le prix du marché des jetons alpha pour déterminer les allocations d’émission entre les sous-réseaux.Lorsque le prix du gamma augmente par rapport aux autres jetons alpha, cela indique que la confiance du marché dans les capacités de formation décentralisées de Templar a augmenté, entraînant une augmentation de l’émission Tao du sous-réseau.Au début de septembre, l’émission quotidienne de Templar représentait environ 4% de la circulation de Tao, se classant dans les six premiers des 128 sous-réseaux du réseau Tao.
Le mécanisme d’émission du sous-réseau est le suivant: dans chaque bloc de 12 secondes, la chaîne de bittenseurs émettra les jetons Tao et Alpha à son pool de liquidités en fonction du rapport de prix des jetons alpha de sous-réseau par rapport aux autres sous-réseaux.Chaque bloc émet jusqu’à un jeton alpha complet au sous-réseau (taux d’émission initial, qui peut être divisé par deux) au sous-réseau pour inciter les contributeurs de sous-réseau, dont 41% sont alloués aux mineurs, 41% sont alloués aux validateurs (et à leurs parties prenantes) et 18% sont attribués aux propriétaires de sous-réseaux.
Cette incitation entraîne une contribution au réseau Bittensor en liant les récompenses économiques à la valeur fournie par les participants.Les mineurs sont motivés à fournir des sorties d’IA de haute qualité, telles que des tâches de formation modèle ou d’inférence, pour obtenir des notes plus élevées des validateurs et donc une plus grande part de production.Les vérificateurs (et leurs stakers) reçoivent des récompenses pour évaluer et maintenir avec précision l’intégrité du réseau.
L’évaluation du marché des jetons alpha est déterminée par des activités de jalonnement, garantissant que les sous-réseaux qui présentent une plus grande praticité peuvent attirer davantage d’entrées et d’émissions de tao, créant ainsi un environnement concurrentiel qui encourage l’innovation, la spécialisation et le développement durable.Les propriétaires de sous-réseaux recevront un pourcentage de récompenses, qui sont motivés pour concevoir des mécanismes efficaces et attirer des contributeurs, et finalement construire un écosystème d’IA décentralisé sans autorisation qui permet à la participation mondiale de promouvoir conjointement les progrès de l’intelligence collective.
Le mécanisme introduit également de nouveaux défis d’incitation tels que le maintien de l’honnêteté des validateurs, la résistance aux attaques des sorcières et la réduction de la complot.Les sous-réseaux Bittensor sont souvent troublés par les jeux de chat et de souris entre les validateurs ou les mineurs et les créateurs de sous-réseaux, le premier essayant de jouer avec le système et le second essayant de les gêner.À long terme, ces difficultés devraient faire du système l’un des plus puissants, car les propriétaires de sous-réseaux apprennent à surmonter les acteurs malveillants.
Gensyn
Gensyn a publié son premier livre blanc rationalisé en février 2022, expliquant le cadre de la formation décentralisée (Gensyn est le seul protocole de formation décentralisé couvert dans notre premier article l’année dernière sur la compréhension de l’intersection de la technologie du cryptage et de l’intelligence artificielle).À ce moment-là, le protocole s’est concentré principalement sur la vérification des charges de travail liées à l’IA, permettant aux utilisateurs de soumettre des demandes de formation au réseau, traitées par le fournisseur informatique et de s’assurer que ces demandes ont été exécutées comme promis.
La vision initiale a également mis en évidence la nécessité d’accélérer la recherche appliquée d’apprentissage appliqué (ML).En 2023, Gensyn s’appuie sur cette vision pour proposer clairement un besoin plus large d’acquérir des ressources informatiques d’apprentissage automatique dans le monde entier pour desservir des applications d’IA spécifiques.Gensyn a présenté le principe fantomatique comme un cadre que ces protocoles doivent rencontrer: universalité, hétérogénéité, frais généraux, évolutivité, inutile et latence.Gensyn s’est concentré sur la construction d’infrastructures informatiques, et la collaboration marque son expansion formelle à d’autres ressources clés au-delà de l’informatique.
Le cœur de Gensyn divise sa pile de technologies d’entraînement en quatre parties distinctes: l’exécution, la vérification, la communication et la coordination.La partie d’exécution est responsable de la gestion des opérations sur n’importe quel appareil du monde qui peut effectuer des opérations d’apprentissage automatique.La section de communication et de coordination permet aux appareils d’envoyer des informations les uns aux autres de manière standardisée. La section Vérification garantit que toutes les opérations peuvent être calculées sans confiance.
Exécution – RL Swarm
La première implémentation de Gensyn sur cette pile est un système de formation appelé RL Swarm, un mécanisme de coordination décentralisé pour l’apprentissage du renforcement post-entraînement.
RL Swarm est conçu pour permettre à plusieurs fournisseurs informatiques de participer à la formation d’un seul modèle dans un environnement sans autorisation et minimisé de confiance.Le protocole est basé sur un cycle en trois étapes: répondre, examiner et résoudre.Tout d’abord, chaque participant génère une sortie du modèle (réponse) en fonction de l’invite.Les autres participants ont ensuite évalué la sortie à l’aide d’une fonction de récompense partagée et ont soumis des commentaires (revue).Enfin, ces avis seront utilisés pour sélectionner la meilleure réponse et les inclure dans la prochaine version du modèle (résolu). L’ensemble du processus se déroule de manière point à point sans s’appuyer sur un serveur central ou une organisation de confiance.
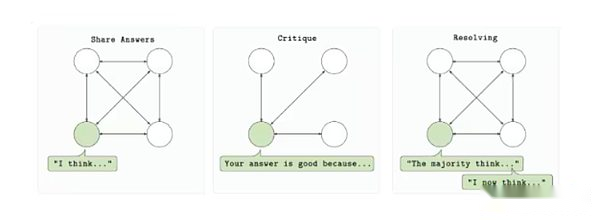 Boucle de formation RL Swarm
Boucle de formation RL Swarm
L’essaim d’apprentissage du renforcement est basé sur l’importance croissante de l’apprentissage du renforcement dans la formation post-modèle.Alors que le modèle atteint la limite supérieure de l’échelle au stade préalable, l’apprentissage du renforcement fournit un mécanisme pour améliorer la capacité d’inférence, la capacité de conformité de l’enseignement et la factualité sans recyclage sur des ensembles de données massifs.Le système de Gensyn réalise cette amélioration dans un environnement décentralisé en décomposant les boucles d’apprentissage du renforcement en différents rôles, chaque rôle peut être vérifié indépendamment.Surtout, il introduit une exécution asynchrone tolérant aux pannes, ce qui signifie que les contributeurs n’ont pas besoin d’être en ligne ou de rester parfaitement synchronisés pour participer.
Il est également de nature modulaire. Le système ne nécessite pas l’utilisation d’une architecture de modèle spécifique, d’un type de données ou d’une structure de récompense, permettant aux développeurs de personnaliser les boucles de formation en fonction de leurs cas d’utilisation spécifiques.Qu’il s’agisse de modèles de codage de formation, d’agents d’inférence ou de modèles avec des ensembles d’instructions spécifiques, RL Swarm fournit un cadre de fonctionnement à grande échelle fiable pour les workflows RL décentralisés.
Verde
Jusqu’à présent, l’un des aspects les moins discutés de ce rapport sur la formation décentralisée est la vérification.Gensyn construit une couche Verde Trust pour son marché GPU.Avec Verde, Gensyn a introduit un nouveau mécanisme de vérification afin que les utilisateurs de protocole puissent faire confiance aux gens de l’autre côté de la situation.
Chaque tâche de formation ou d’inférence est prévue à un certain nombre de fournisseurs indépendants déterminés par la demande.Si leur sortie correspond exactement, la tâche est acceptée. Si les sorties sont différentes, le protocole de l’arbitre localise la première étape dans laquelle les deux trajectoires sont divergentes et recalcule l’opération uniquement. La partie dont le nombre correspond à l’arbitre conserve son paiement, tandis que l’autre partie perd ses intérêts.
Ce qui rend cela possible, ce sont les repeups, une bibliothèque d’opérateurs reproductibles « qui force les opérations mathématiques du réseau neuronal commune (multiplication matricielle, activation, etc.) pour s’exécuter dans un ordre fixe et déterministe sur n’importe quel GPU. Le déterminisme est crucial ici; Sinon, bien que les deux validateurs soient corrects, ils peuvent produire des résultats différents. Les fournisseurs honnêtes fourniront donc le même résultat petit à petit, permettant à Verde de voir le jeu comme une preuve de correction. Étant donné que l’arbitre ne rejoue qu’un seul microsphe, le coût ajouté n’est que quelques points de pourcentage, plutôt que les frais généraux de 10 000 fois de la preuve de cryptage complète couramment utilisée dans ces processus.
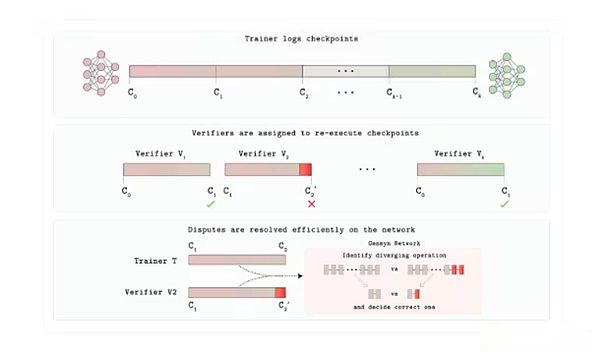
Architecture de protocole de vérification de Verde
En août, Gensyn a libéré le juge, un système d’évaluation Vérifiable d’IA qui contient deux composants principaux: Verde et un temps d’exécution reproductible, qui garantit un résultat bit par le même résultat sur le matériel.Pour le montrer, Gensyn a lancé un « jeu de révélation progressif » dans lequel les modèles d’IA parient sur les réponses à des questions complexes lors de la révélation de l’information, le juge valide de manière déterministe les résultats et récompense les prédictions précoces précises.
Le juge est important car il résout les problèmes de confiance et d’évolutivité dans l’IA / ml.Il permet des comparaisons de modèles fiables, améliore la transparence dans des environnements à haut risque et réduit le risque de biais ou de manipulation en permettant une vérification indépendante.En plus des tâches d’inférence, le juge peut soutenir d’autres cas d’utilisation tels que les marchés de règlement et de prédiction décentralisés, ce qui correspond à la mission de Gensyn de construire une infrastructure informatique de fiducie de confiance en IA.En fin de compte, des outils comme le juge peuvent améliorer la répétabilité et la responsabilité, ce qui est crucial à une époque où l’IA est de plus en plus au cœur de la société.
Communication et coordination: Intégration des experts en saut et en diversité
Skip-Pipe est une solution de Gensyn pour résoudre le problème du goulot d’étranglement de la bande passante qu’un seul modèle mégamo se produit lors de la tranche sur plusieurs machines.Comme mentionné précédemment, l’entraînement par pipeline traditionnel oblige chaque microbatch pour traverser toutes les couches en séquence, donc tout nœud plus lent provoquera une stagnation du pipeline.Le planificateur de Skip-Pipe peut sauter dynamiquement ou réorganiser les couches qui peuvent provoquer des retards, réduire les temps d’itération jusqu’à 55% et maintenir la disponibilité même lorsque la moitié des nœuds échouent.En réduisant le trafic entre les nœuds et en permettant à les couches d’être supprimées au besoin, il permet au formateur d’échec de très grands modèles aux GPU géo-distribués et à faible bande passante.
L’intégration d’experts diversifiée résout un autre puzzle de coordination: comment construire un puissant système « expert hybride » qui évite la diaphonie continue.L’intégration des experts du domaine hétérogène de Gensyn (HDEE) forme chaque modèle d’experts complètement indépendamment et se fusionne uniquement à la fin.Étonnamment, dans le même budget informatique global, l’intégration finale dans 20 des 21 zones d’essai a dépassé une référence unifiée.Puisqu’il n’y a pas de gradient ou de flux de fonctions d’activation entre les machines pendant l’entraînement, tout GPU inactif peut contribuer la puissance de calcul.
Le saut-pipe et HDE ensemble offrent à Gensyn une solution de communication efficace.Le protocole peut s’évanouir dans un seul modèle si nécessaire, ou former plusieurs petits experts en parallèle avec des coûts d’indépendance inférieurs sans utiliser un réseau de latence parfait et faible tel que traditionnellement utilisé.
Réseau de test
En mars, Gensyn a déployé un testnet sur un rollup Ethereum personnalisé. L’équipe prévoit de mettre à jour progressivement le réseau de test.Actuellement, les utilisateurs peuvent participer aux trois produits de Gensyn: RL Swarm, Blockassist et Judge.Comme mentionné ci-dessus, RL Swarm permet aux utilisateurs de participer aux processus de formation post-RL.En août, l’équipe a lancé Blockassist: «Il s’agit de la première démonstration à grande échelle de l’apprentissage assisté, un moyen de former des agents directement à partir d’un comportement humain sans taggage manuel ou RLHF.»Les utilisateurs peuvent télécharger Minecraft et utiliser Blockassist pour former des modèles Minecraft pour jouer au jeu.
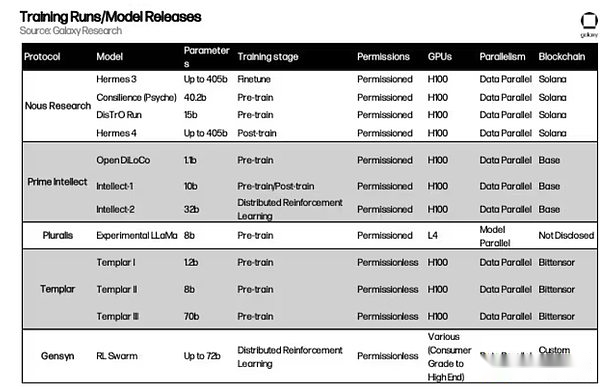
D’autres projets qui valent la peine d’être prêts
Les chapitres ci-dessus décrivent l’architecture dominante mise en œuvre pour réaliser une formation décentralisée.Cependant, de nouveaux projets émergent les uns après les autres.Voici quelques nouveaux projets dans le domaine de la formation décentralisée:
Quarante-deux: Quarantwo est construit sur la blockchain Monad et se concentre sur le raisonnement de groupe (SLM), où plusieurs modèles de petits langues (SLM) collaborent sur les requêtes dans un réseau de nœuds et génèrent des sorties évaluées par des pairs, améliorant ainsi la précision et l’efficacité.Le système utilise du matériel de qualité grand public tel que les ordinateurs portables inactifs, éliminant la nécessité d’utiliser des grappes GPU coûteuses comme l’IA centralisée.L’architecture comprend des fonctions d’exécution et de formation décentralisées, telles que la génération d’ensembles de données synthétiques pour des modèles dédiés.Le projet est désormais disponible sur le Monad Development Network.
Ambiant: Ambient est la prochaine blockchain de « preuve de travail » utile « , conçue pour prendre en charge les agents d’IA autonomes toujours en ligne sur la chaîne, leur permettant d’effectuer des tâches en continu, d’apprendre et d’évoluer dans un écosystème sans autorisation sans supervision centralisée. Il adoptera un seul modèle open source formé et amélioré par les mineurs de réseau en collaboration, et les contributeurs seront récompensés pour leurs contributions à la formation, à la construction et à l’utilisation de modèles d’IA. Bien que Ambient met l’accent sur le raisonnement décentralisé, en particulier dans l’aspect proxy, les mineurs sur le réseau seront également responsables de la mise à jour continue des modèles sous-jacents qui prennent en charge le réseau. Ambient utilise un nouveau mécanisme P ROOT-O F-Logits (dans ce système, les validateurs peuvent vérifier que les calculs du modèle sont correctement exécutés en vérifiant la valeur de sortie d’origine du mineur (appelé Logits).Le projet est construit sur une fourche de Solana et n’a pas encore été officiellement lancé.
Laboratoires de fleurs: Flower Labs développe un cadre open source pour l’apprentissage fédéré, Flower, qui soutient la formation collaborative sur le modèle d’IA à travers des sources de données décentralisées sans partager des données brutes, protégeant ainsi la confidentialité tout en agrégeant les mises à jour du modèle.Flower a été fondée pour aborder la centralisation des données, permettant aux institutions et aux individus de former des modèles à l’aide de données locales, telles que les soins de santé ou les finances, tout en contribuant à des améliorations mondiales grâce à un partage sécurisé des paramètres.Contrairement aux protocoles crypto-natifs qui mettent l’accent sur les récompenses en jetons et l’informatique vérifiable, Flower priorise la collaboration qui protège la confidentialité dans les applications du monde réel, ce qui en fait un choix idéal pour les industries réglementées sans blockchain.
Macrocosmos: Macrocosmos fonctionne sur le réseau Bittensor et développe un processus complet de création de modèle d’IA couvrant cinq sous-réseaux qui se concentrent sur la pré-formation, le réglage fin, la collecte de données et les sciences décentralisées.Il présente le cadre d’architecture de formation d’orchestration incitatif (IOTA) pour les modèles de grande langue pré-formation sur le matériel hétérogène, peu fiable et sans licence, et a initié un milliard de formations paramètres et prévoit de passer rapidement à des modèles de paramètres plus grands.
Troupeau.io: Flock est un écosystème de formation d’IA décentralisé qui combine l’apprentissage fédéré avec l’infrastructure de la blockchain pour réaliser le développement de modèles collaboratifs pour la protection de la vie privée dans un réseau modulaire incendiaire. Les participants peuvent contribuer des modèles, des données ou des ressources informatiques et recevoir des récompenses sur chaîne proportionnelles à leurs contributions.Pour protéger la confidentialité des données, le protocole adopte l’apprentissage fédéré.Cela permet aux participants de former des modèles mondiaux à l’aide de données locales qui ne sont pas partagées avec d’autres.Bien que cette configuration nécessite des étapes de vérification supplémentaires pour empêcher les données non pertinentes (souvent appelées intoxication des données) à entrer dans la formation des modèles, il s’agit d’une approche promotionnelle efficace pour les cas d’utilisation tels que les applications de soins de santé où plusieurs fournisseurs de soins de santé peuvent former des modèles mondiaux sans fuir des données médicales hautement sensibles.
Prospects et risques
Au cours des deux dernières années, une formation décentralisée est passée d’un concept intéressant en un réseau efficace exécutant dans un environnement réel. Bien que ces projets soient encore loin de l’état final attendu, ils font des progrès significatifs sur la voie d’une formation décentralisée.En regardant en arrière le modèle de formation décentralisé existant, certaines tendances commencent à émerger:
La preuve de concept en temps réel n’est plus un fantasme.Les premières vérifications telles que la consolience de nous et Intellect-2 de Prime Intellect sont entrées dans les opérations à l’échelle de la production au cours de la dernière année.Les percées telles que les modèles d’OpenLicoco et de protocole permettent une IA de haute performance sur les réseaux distribués, facilitant le développement de modèles rentable, résilient et transparent.Ces réseaux coordonnent des dizaines, voire des centaines de GPU, des modèles de taille moyenne pré-formation et de taille moyenne en temps réel, prouvant que la formation décentralisée peut aller au-delà des démonstrations fermées et des hackathons temporaires.Bien que ces réseaux ne soient toujours pas des réseaux sans autorisation, Templar se démarque à cet égard;Son succès renforce l’idée que la formation décentralisée passe de simplement prouver que la technologie sous-jacente est efficace pour pouvoir évoluer pour correspondre aux performances des modèles centralisés et à attirer les ressources GPU nécessaires pour produire les modèles sous-jacents à grande échelle.
L’échelle du modèle continue de se développer, mais l’écart demeure.De 2024 à 2025, le nombre de modèles de paramètres pour les projets décentralisés est passé de chiffre à 30 milliards à 40 milliards.Cependant, le principal laboratoire AI a publié des milliards de paramètres du système et continue d’innover rapidement avec ses centres de données intégrés verticalement et son matériel de pointe.La formation décentralisée peut combler cet écart en tirant parti du matériel de formation du monde entier, d’autant plus que les méthodes de formation centralisées sont confrontées à des restrictions croissantes en raison de la nécessité d’un nombre croissant de centres de données hyperscale.Mais combler cet écart dépendra de nouvelles percées dans les optimisateurs et la compression de gradient pour des communications efficaces pour atteindre l’échelle globale, ainsi qu’une couche d’incitation et de vérification inopérable.
Le flux de travail après la formation devient un domaine de préoccupation.Le réglage fin supervisé, le RLHF et l’apprentissage du renforcement spécifique au domaine nécessitent une bande passante de synchronisation beaucoup plus faible que la pré-formation complète.Des cadres tels que Prime-RL et RL Swarm ont fonctionné sur des nœuds de niveau consommateur instables, permettant aux contributeurs de profiter des cycles inactifs tandis que les projets peuvent rapidement commercialiser des modèles personnalisés.Étant donné que la RL est bien adaptée à une formation décentralisée, son importance en tant que domaine d’intérêt pour les programmes de formation décentralisées peut devenir de plus en plus importante.Cela permet à une formation décentralisée d’être la première à trouver un marché de produits à grande échelle ajusté dans la formation RL, comme en témoigne le nombre croissant d’équipes lançant des cadres de formation spécifiques à RL.
Le mécanisme d’incitation et de vérification est en retard sur l’innovation technologique. Les mécanismes d’incitation et de vérification sont toujours à la traîne de l’innovation technologique.Seuls quelques réseaux, en particulier les Templiers, offrent des récompenses de pièces de monnaie en temps réel et des mécanismes de pénalité et de confiscation en chaîne, réduisant ainsi efficacement les mauvais comportements et ont été testés dans des environnements réels.Bien que d’autres programmes expérimentent les scores de réputation, les programmes de preuve de témoin ou de formation, ces systèmes ne sont toujours pas vérifiés.Même si les obstacles techniques sont surmontés, la gouvernance présentera des défis tout aussi difficiles, car les réseaux décentralisés doivent trouver des moyens de formuler des règles, d’appliquer les règles et de résoudre les différends sans les inefficacités répétées qui se produisent dans les Daos cryptographiques.La résolution des barrières techniques n’est que la première étape; La viabilité à long terme dépend de la combinaison avec des mécanismes de vérification fiables, des mécanismes de gouvernance efficaces et des structures convaincantes de monétisation / propriété pour garantir la confiance dans le travail effectué et pour attirer les talents et les ressources nécessaires pour évoluer.
La pile fusionne dans un pipeline de bout en bout.Aujourd’hui, la plupart des équipes de premier plan combinent des optimisateurs conscients de la bande passante (démo, distribution), des échanges informatiques décentralisés (Prime Compute, Basilicy) et des couches de coordination sur chaîne (Psyche, PM, Prime).Enfin, un pipeline ouvert modulaire est formé, qui reflète le flux de travail des laboratoires centralisés des données au déploiement, mais sans point de contrôle unique.Même si les projets n’intégrent pas directement leurs propres solutions, ou même s’ils sont intégrés, ils peuvent être accessibles avec d’autres projets cryptographiques axés sur les verticales requises pour une formation décentralisée, telles que les protocoles d’approvisionnement de données, les marchés GPU et les inférences, et les étagères de stockage décentralisées.Cette infrastructure périphérique fournit des composants plug-and-play pour des programmes de formation décentralisés qui peuvent être davantage exploités pour améliorer leurs produits et mieux rivaliser avec les pairs centralisés.
risque
L’optimisation matérielle et logicielle est un objectif en constante évolution – le laboratoire central se développe également dans ce domaine.La puce Blackwell B200 de Nvidia vient d’être annoncée. Dans la référence MLPERF, qu’il s’agisse de pré-formation avec 405 milliards de paramètres ou 70 milliards de lora fins, son débit de formation est de 2,2 à 2,6 fois plus rapide que la génération précédente, réduisant considérablement les coûts de temps et d’énergie pour les géants.En termes de logiciel, Pytorch 3.0 et TensorFlow 4.0 introduisent la fusion de graphes de niveau du compilateur et les grains de forme dynamique pour améliorer encore les performances sur la même puce.Avec des améliorations de l’optimisation matérielle et logicielle, ou l’avènement de nouvelles architectures de formation, les réseaux de formation décentralisés doivent également suivre le rythme des mises à jour continues pour s’adapter aux méthodes de formation les plus rapides et les plus avancées, attirant des talents et inspirant le développement significatif de modèles.Cela obligera l’équipe à développer un logiciel qui garantit une performance élevée continue, quel que soit le matériel sous-jacent, et une pile de logiciels qui permet à ces réseaux de s’adapter aux changements dans l’architecture de formation sous-jacente.
Le modèle open source de l’entreprise existante brouille les frontières entre une formation décentralisée et centralisée.La plupart des laboratoires d’IA centralisés gardent des modèles fermés, ce qui prouve en outre que la formation décentralisée est un moyen d’assurer l’ouverture, la transparence et la gouvernance communautaire.Bien que des projets récents tels que Deepseek, les versions Open Source et le LLAMA du GPT montrent leur évolution vers une ouverture supérieure, il n’est pas clair si cette tendance peut se poursuivre dans le contexte d’une concurrence croissante, d’une réglementation et de problèmes de sécurité.Même si les poids sont révélés, ils reflètent toujours les valeurs et les choix du laboratoire d’origine – la capacité de s’entraîner indépendamment est essentielle à l’adaptabilité, à la coordination avec différentes priorités et à garantir l’accès n’est pas limité par une poignée d’entreprises en place.
Le recrutement est toujours difficile.De nombreuses équipes nous le disent. Bien que la qualité des talents qui rejoigne les programmes de formation décentralisés se soit améliorée, ils n’ont pas les ressources solides qui dirigent des laboratoires d’IA (par exemple, Openai a récemment offert des millions de dollars de «récompenses spéciales» par employé, ou l’offre de 250 millions de dollars a proposée aux chercheurs de braconnage).Actuellement, des projets décentralisés attirent des chercheurs axés sur la mission qui apprécient l’ouverture et l’indépendance, tout en tirant des talents d’un pool de talents mondial plus large et d’une communauté open source dynamique.Cependant, afin de rivaliser à l’échelle, ils doivent faire leurs preuves en formant des modèles comparables aux entreprises existantes et en perfectionnant les incitations et les mécanismes de monétisation pour créer des avantages significatifs pour les contributeurs.Bien que les réseaux sans licence et les incitations crypto-économiques fournissent une valeur unique, l’incapacité à accéder à la distribution et à établir un flux de revenus durable peut entraver la croissance à long terme du secteur.
La résistance réglementaire existe, en particulier pour les modèles non censurés. Une formation décentralisée fait face à des défis réglementaires uniques: en termes de conception, tout le monde peut former n’importe quel type de modèle.Cette ouverture est certainement un avantage, mais elle augmente également les risques de sécurité, en particulier dans la biosécurité, les fausses informations ou d’autres domaines sensibles d’abus.L’UE et les décideurs américains ont signalé qu’ils renforceraient leur examen: la loi sur l’intelligence artificielle de l’UE établit des obligations supplémentaires sur les modèles de base à haut risque, tandis que les agences américaines envisagent de limiter les systèmes ouverts et les mesures potentielles de contrôle de style exportation.Les événements impliquant des modèles décentralisés à des fins nocives seuls peuvent déclencher une réglementation complète, menaçant le principe fondamental de la formation sans autorisation.
Distribution et monétisation: la distribution reste un défi majeur.Les principaux laboratoires, notamment OpenAI, anthropic et Google, présentent d’énormes avantages de distribution grâce à la notoriété de la marque, aux contrats d’entreprise, à l’intégration de la plate-forme cloud et à l’accès direct aux consommateurs.En revanche, les programmes de formation décentralisés n’ont pas ces canaux intégrés et plus d’efforts doivent être mis en place pour permettre à l’adoption de modèles, de gagner la confiance et intégrés dans des flux de travail réels.Étant donné que les crypto-monnaies sont encore à ses balbutiements dans leur intégration en dehors des applications de crypto (bien que cela change rapidement), cela peut être plus difficile.Une question très importante et non résolue est de savoir qui utilisera réellement ces modèles de formation décentralisés.Des modèles open source de haute qualité existent déjà, et une fois les nouveaux modèles avancés, il n’est pas particulièrement difficile pour les autres de les extraire ou de les ajuster.Au fil du temps, la nature open source des programmes de formation décentralisés devrait créer des effets de réseau qui résolvent le problème de distribution.Cependant, même s’ils peuvent résoudre le problème de distribution, l’équipe sera confrontée au défi de la monétisation des produits.Actuellement, les chefs de projet de Pluralis semblent le plus directement relever ces défis de monétisation.Ce n’est pas seulement un problème de cryptage x AI, mais un problème de chiffrement plus large qui met en évidence les défis futurs.
en conclusion
La formation décentralisée est rapidement passé d’un concept abstrait à un réseau efficace qui coordonne le fonctionnement de la formation globale réelle.Au cours de la dernière année, des projets tels que nous, Prime Intellect, Pluralis, Templar et Gensyn ont prouvé qu’il est possible de relier les GPU décentralisés ensemble, de comprimer efficacement les communications et même de commencer à expérimenter des incitations dans des environnements réels.Ces premières manifestations démontrent que la formation décentralisée peut aller au-delà de la théorie, bien que le chemin de la concurrence avec des laboratoires centralisés à l’échelle de pointe reste difficile.
Même si les modèles fondamentaux finalement formés par des projets décentralisés sont comparables aux principaux laboratoires d’intelligence artificielle d’aujourd’hui, ils sont confrontés au test le plus grave: prouver leurs avantages réalistes au-delà des exigences des idées.Ces avantages peuvent se manifester de manière endogène par une excellente architecture ou enrichissant les nouveaux schémas de propriété et de monétisation des contributeurs.Alternativement, ces avantages peuvent également être exogènes si les participants existants centralisés essaient d’étouffer l’innovation en gardant des poids fermés ou en injectant les biais d’alignement indésirables.
En plus des avancées technologiques, les attitudes envers le domaine ont également commencé à changer.Un fondateur a décrit les changements dans les émotions lors de grandes conférences d’IA au cours de la dernière année: il y a un an, il y avait peu d’intérêt pour une formation décentralisée, en particulier lorsqu’elle est utilisée en conjonction avec les crypto-monnaies; Il y a six mois, les participants ont commencé à reconnaître les problèmes potentiels mais ont exprimé des doutes quant à la faisabilité de la mise en œuvre à grande échelle;Et ces derniers mois, il y a eu une reconnaissance croissante selon laquelle les progrès continus peuvent permettre une formation décentralisée évolutive possible.L’évolution de ce concept montre que l’élan de la formation décentralisée augmente également non seulement dans le domaine de la technologie, mais aussi en termes de légitimité.
Les risques sont réels: les entreprises existantes conservent toujours leurs avantages matériels, talents et distribution; L’examen réglementaire est imminent;Les incitations et les mécanismes de gouvernance n’ont pas été testés à grande échelle. Cependant, ses avantages sont tout aussi frappants.La formation décentralisée représente non seulement une architecture technologique alternative, mais aussi un concept fondamental de construction de l’intelligence artificielle: aucune licence, la propriété mondiale et conforme à une communauté diversifiée plutôt qu’à quelques entreprises.Même si un seul projet peut prouver que l’ouverture peut se traduire par une itération plus rapide, une nouvelle architecture ou une gouvernance plus inclusive, elle marquera un moment percé pour les crypto-monnaies et l’intelligence artificielle.La route à venir est longue, mais les éléments fondamentaux du succès sont désormais fermement saisis.







