Titre original: Architectures de colle et de coprocesseur
Auteur: Vitalik, fondateur d’Ethereum;
Un merci spécial à Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra et divers contributeurs Flashbots pour leurs commentaires et commentaires.
Si vous analysez des calculs à forte intensité de ressources qui sont effectués dans le monde moderne avec des détails modérés, une fonctionnalité que vous trouverez à maintes reprises est que le calcul peut être divisé en deux parties:
-
Une quantité relativement petite de « logique commerciale » complexe mais pas très intensive en calcul;
-
Beaucoup de «travaux coûteux» intensifs mais très structurés.
Ces deux formes de calcul sont mieux gérées de différentes manières: la première, dont l’architecture peut être moins efficace mais doit être très polyvalente;
Quels sont les exemples de cette approche différente dans la pratique?
Tout d’abord, jetons un coup d’œil à l’environnement que je connais le mieux: Ethereum Virtual Machine (EVM).Voici le suivi de débogage Getth pour ma récente transaction Ethereum: Mettez à jour le hachage IPFS de mon blog sur ENS.La transaction a consommé un total de 46924 gaz et peut être classée comme suit:
-
Coût de base: 21 000
-
Données d’appel: 1 556
-
EVM Exécution: 24 368
-
Sload Opcode: 6 400
-
SSTORE OPCODE: 10100
-
Log Opcode: 2 149
-
Autres: 6 719

EVM Trace pour la mise à jour du hachage ENS.L’avant-dernière colonne est la consommation de gaz.
La morale de cette histoire est que la majeure partie de l’exécution (environ 73% si vous ne regardez que l’EVM, soit environ 85% si vous incluez la partie de coût de base couvrant le calcul) est concentrée dans quelques opérations coûteuses structurées: stocker la lecture et Écrivez, les journaux et le chiffrement (le coût de base comprend 3000 pour la vérification de la signature du paiement, et l’EVM comprend également 272 pour le hachage de paiement).Le reste de l’exécution est « Business Logic »: échangez le bit CallData pour extraire l’ID de l’enregistrement que j’essaie de définir et le hachage que je le définit, etc.Dans les transferts de jetons, cela comprendra l’ajout et la soustraction des soldes, dans des applications plus avancées, cela peut inclure la boucle, etc.
Dans EVM, ces deux formes d’exécution sont traitées de différentes manières.La logique commerciale avancée est écrite dans des langues plus avancées, généralement la solidité, qui peut être compilée en EVM.Le travail coûteux est toujours déclenché par EVM Opcodes (SLOAD, etc.), mais plus de 99% des calculs réels sont effectués dans des modules dédiés écrits directement dans le code client (ou même les bibliothèques).
Pour renforcer notre compréhension de ce modèle, explorons-le dans un autre contexte: code AI écrit en python à l’aide de la torche.
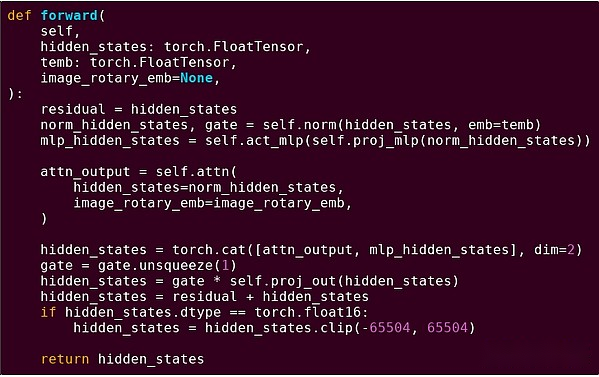
Livraison vers l’avant d’un bloc du modèle de transformateur
Qu’avons-nous vu ici?Nous voyons une quantité relativement faible de «logique commerciale» écrite en Python qui décrit la structure des opérations effectuées.Dans les applications pratiques, il existe un autre type de logique commerciale qui détermine les détails tels que la façon d’obtenir des entrées et quelles opérations sont effectuées sur la sortie.Cependant, si nous fouillons dans chaque opération individuelle elle-même (les étapes à l’intérieur de self.norm, torch.cat, +, *, self.attn…), nous voyons des calculs vectorisés: la même opération calcule un grand nombre de calculs parallèles dans un grand Nombre de cas de valeur.Semblable au premier exemple, une petite partie des calculs est utilisée pour la logique métier, et la plupart sont utilisés pour effectuer de grandes opérations de matrice structurée et vectorielle – en fait, la plupart ne sont que la multiplication matricielle.
Tout comme dans l’exemple EVM, ces deux types de travaux sont gérés de deux manières différentes.Advanced Business Logic Code est écrit en Python, un langage très général et flexible, mais aussi très lent, et nous acceptons simplement l’inefficacité car il ne concerne qu’une petite partie du coût informatique total.Pendant ce temps, les opérations intensives sont écrites en code hautement optimisé, généralement le code CUDA fonctionnant sur le GPU.Nous commençons encore de plus en plus à voir le raisonnement LLM se produire sur les ASIC.
La cryptographie programmable moderne, comme Snark, suit encore une fois un modèle similaire aux deux niveaux.Premièrement, le prover peut être écrit dans une langue de haut niveau, où le travail lourd se fait grâce à des opérations de vectorisation, tout comme l’exemple de l’IA ci-dessus.Mon code stark circulaire ici montre cela.Deuxièmement, les programmes exécutés dans la cryptographie peuvent eux-mêmes être écrits d’une manière qui divise entre la logique commerciale commune et le travail coûteux très structuré.
Pour comprendre comment cela fonctionne, nous pouvons jeter un œil à l’une des dernières tendances prouvées.Pour le général et facile à utiliser, l’équipe construit de plus en plus des provers frappants pour des machines virtuelles minimales largement adoptées telles que RISC-V.Tout programme qui doit prouver que l’exécution peut être compilé en RISC-V, et le rétrécis peut alors prouver l’exécution RISC-V du code.
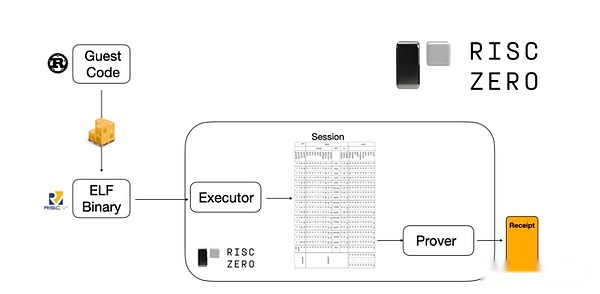
Graphiques de la documentation de Risczero
Ceci est très pratique: cela signifie que nous n’avons besoin d’écrire une logique de preuve qu’une seule fois, et à partir de là, tout programme qui a besoin de preuve peut être écrit dans n’importe quel langage de programmation « traditionnel » (comme Riskzero prend en charge la rouille).Cependant, il y a un problème: cette approche peut entraîner beaucoup de frais généraux.Le chiffrement programmable est déjà très coûteux;Ainsi, les développeurs ont proposé une astuce: identifier les opérations coûteuses spécifiques (généralement hachage et signatures) qui composent la plupart des calculs, puis créent des modules spécialisés pour les prouver très efficacement.Ensuite, vous pouvez tirer le meilleur parti des deux mondes en combinant simplement le système de preuve RISC-V inefficace mais universel avec le système de preuve efficace mais professionnel.
Un chiffrement programmable autre que ZK-SNARK, tel que l’informatique multipartite (MPC) et le chiffrement entièrement homomorphe (FHE), peuvent être optimisés à l’aide de méthodes similaires.
Dans l’ensemble, quel est le phénomène?
L’informatique moderne suit de plus en plus ce que j’appelle l’architecture de liaison et de coprocesse: vous avez des composants centraux de «liaison» qui sont très polyvalents mais inefficaces et responsables d’un ou plusieurs composants de coprocesseur.
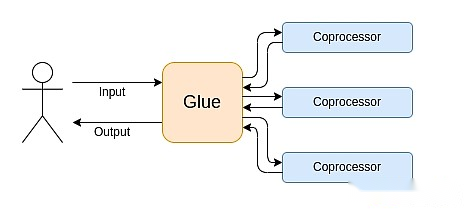
Il s’agit d’une simplification: dans la pratique, la courbe de compromis entre l’efficacité et l’universalité est presque toujours plus de deux niveaux.Les GPU et autres puces communément appelés «coprocesseurs» dans l’industrie sont moins polyvalents que les processeurs, mais plus polyvalents que les ASIC.Les compromis sur le degré de spécialisation sont complexes, en fonction des prédictions et de l’intuition sur les parties de l’algorithme resteront inchangées en cinq ans et quelles pièces changeront en six mois.Dans l’architecture de la preuve ZK, nous voyons souvent des spécialisations multipriaires similaires.Mais pour un modèle d’esprit large, il suffit de considérer deux niveaux.Il existe des situations similaires dans de nombreux domaines informatiques:
À en juger par les exemples ci-dessus, les calculs peuvent bien sûr être divisés de cette manière, ce qui semble être une loi naturelle.En fait, vous pouvez trouver des exemples de spécialisation informatique au fil des décennies.Cependant, je pense que cette séparation augmente.Je pense qu’il y a une raison à ceci:
Nous n’avons atteint que récemment la limite de l’amélioration de la vitesse de l’horloge du CPU, de sorte que d’autres avantages ne peuvent être obtenus que par parallélisation.Cependant, la parallélisation est difficile à raisonner, il est donc souvent plus pratique pour les développeurs de continuer à raisonner en séquence et de se produire sur le backend, et de l’emballer dans un module dédié conçu pour une opération spécifique.
L’informatique n’est devenue que récemment si rapide que le coût de calcul de la logique commerciale est devenu vraiment négligeable.Dans ce monde, il est logique d’optimiser les machines virtuelles sur la logique métier pour atteindre des objectifs autres que l’efficacité informatique: convivialité, familiarité, sécurité et autres objectifs similaires.Pendant ce temps, les modules dédiés au «coprocesseur» peuvent continuer à être conçus pour l’efficacité et à gagner leur sécurité et leur convivialité par les développeurs de leur «interface» relativement simple avec des adhésifs.
Quelle est l’opération la plus importante et la plus coûteuse devient plus claire.Ceci est le plus évident dans la cryptographie, où les types d’opérations coûteuses spécifiques sont les plus susceptibles d’être utilisées: opérations de module, combinaison linéaire de courbes elliptiques (également connues sous le nom de multiplication multi-traits), de transformée de Fourier rapide, etc.Cette situation est également devenue de plus en plus évidente dans l’intelligence artificielle, la plupart des calculs étant «principalement la multiplication matricielle» (bien que différents niveaux de précision).Des tendances similaires ont émergé dans d’autres domaines.Il y a beaucoup moins d’inconnues dans les calculs (à forte intensité de calcul) qu’il y a 20 ans.
qu’est-ce que cela signifie?
Un point clé est que le Gluer (colle) doit être optimisé pour être une bonne colle (colle), et le coprocesseur doit également être optimisé pour être un bon coprocesseur.Nous pouvons explorer la signification de cela dans plusieurs domaines clés.
EVM
Les machines virtuelles de blockchain (telles que les EVM) n’ont pas besoin d’être efficaces, elles ont juste besoin de les connaître.Il suffit d’ajouter le coprocesseur correct (alias « précompilé »), et le calcul dans une machine virtuelle inefficace peut être aussi efficace que le calcul dans une machine virtuelle native efficace.Par exemple, les frais généraux encourus par le registre 256 bits de l’EVM sont relativement faibles, tandis que la familiarité de l’EVM et les avantages de l’écosystème du développeur existant sont énormes et durables.Les équipes de développement optimisant les EVM ont même constaté que le manque de parallélisation n’est souvent pas un obstacle majeur à l’évolutivité.
La meilleure façon d’améliorer l’EVM pourrait être (i) l’ajout d’opcodes mieux précompilés ou dédiés, tels qu’une combinaison d’EVM-max et de SIMD, et (ii) de l’amélioration des dispositions de stockage, telles que les changements d’arbres Verkle, comme effet secondaire, réduisent considérablement considérablement Le coût d’accès aux créneaux de stockage adjacents.
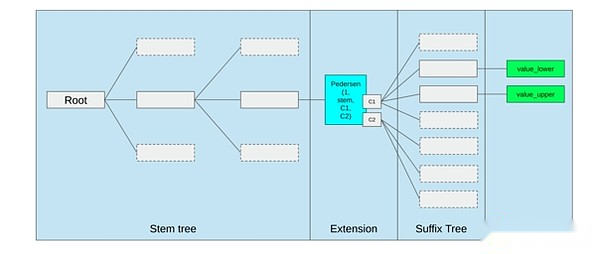
L’optimisation du stockage dans la proposition d’arbre Ethereum Verkle, assemblez les clés de stockage adjacentes et ajustez les coûts de gaz pour refléter cela.Des optimisations comme celle-ci, associées à une meilleure précompilation, peuvent être plus importantes que de peaufiner l’EVM lui-même.
Informatique sécurisée et matériel ouvert
L’un des défis de l’amélioration de la sécurité informatique moderne au niveau matériel est sa nature trop complexe et propriétaire: la puce est conçue pour être efficace, ce qui nécessite une optimisation propriétaire.La porte dérobée est facilement cachée et les vulnérabilités de canal latéral sont constamment découvertes.
Les gens continuent de travailler pour promouvoir des alternatives plus ouvertes et plus sûres sous plusieurs angles.Certains calculs se font de plus en plus dans un environnement d’exécution de confiance, y compris sur le téléphone de l’utilisateur, qui a amélioré la sécurité des utilisateurs.L’action pour conduire plus de matériel de consommation open source se poursuit, avec quelques victoires récentes comme les ordinateurs portables RISC-V exécutant Ubuntu.
Ordinateur portable RISC-V dirigeant Debian
Cependant, l’efficacité reste un problème.L’auteur de l’article lié ci-dessus a écrit:
Il est peu probable que les nouveaux conceptions de puces open source telles que RISC-V soient comparables à la technologie de processeur qui a existé et a été améliorée au fil des décennies.Il y a toujours un point de départ pour les progrès.
Des idées plus paranoïaques, comme cette conception pour la construction d’ordinateurs RISC-V sur les FPGA, sont confrontées à une plus grande surcharge.Mais que se passe-t-il si l’architecture de la colle et du coprocesseur signifie que cette surcharge n’est pas réellement importante?Si nous acceptons les puces ouvertes et sécurisées seront plus lentes que les puces propriétaires, si nécessaire, même abandonner les optimisations communes telles que l’exécution spéculative et la prédiction des succursales, mais essayez de compenser cela en ajoutant (propriétaire, si nécessaire) des modules ASIC qui sont utilisés pour les modules ASIC (propriétaires, si nécessaire) La plupart qu’est-ce qui arrive aux types de calculs spécifiques intensifs?L’informatique sensible peut être effectuée dans la « puce principale » qui sera optimisée pour la sécurité, la conception open source et la résistance aux canaux latéraux.Des calculs plus intensifs (par exemple, ZK Proof, AI) seront effectués dans le module ASIC, qui apprendra moins d’informations sur le calcul effectué (éventuellement, par le stabilisation du cryptage, et dans certains cas même zéro information).
Cryptographie
Un autre point clé est que tout cela est très optimiste quant à la cryptographie, en particulier la cryptographie programmable, devenant courant dominant.Nous avons vu certaines implémentations hyper-optimisées spécifiques de calculs hautement structurés dans Snark, MPC et autres paramètres: certaines fonctions de hachage ne sont que quelques centaines de fois plus chères que l’exécution directement de l’informatique, et l’IA (principalement la multiplication matricielle). très bas.D’autres améliorations telles que GKR peuvent réduire davantage ce niveau.Une exécution de machine virtuelle entièrement générale, en particulier lorsqu’elle est exécutée dans un interpréteur RISC-V, peut continuer à engager environ dix mille fois les frais généraux, mais pour les raisons décrites dans cet article, cela n’a pas d’importance: utilisez simplement des technologies efficaces et dédiées pour gérer séparément séparément séparer séparément les technologies Les parties les plus intensives du calcul, la surcharge totale est contrôlable.
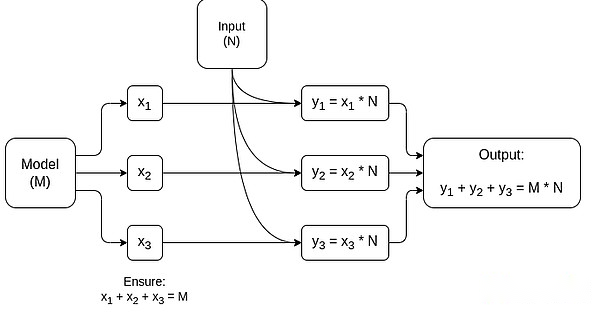
Un graphique simplifié de MPC dédié à la multiplication de la matrice, qui est le plus grand composant de l’inférence du modèle AI.Consultez cet article pour plus de détails, notamment comment garder les modèles et les entrées privés.
Une exception à l’idée que «les couches collées doivent seulement être familières, pas efficaces» est la latence et dans une moindre mesure la bande passante de données.Si le calcul implique des dizaines d’opérations lourdes répétitives sur les mêmes données (comme la cryptographie et l’intelligence artificielle), tout retard causé par la colle inefficace peut devenir le principal goulot d’étranglement de l’exécution.Par conséquent, la couche collée a également des exigences d’efficacité, bien que ces exigences soient plus spécifiques.
en conclusion
Dans l’ensemble, je pense que les tendances ci-dessus sont très positives sous plusieurs perspectives.Premièrement, c’est un moyen raisonnable de maximiser l’efficacité informatique tout en maintenant la convivialité des développeurs, et pouvoir obtenir plus des deux est bon pour tout le monde.En particulier, en se spécialisant du côté client pour améliorer l’efficacité, il améliore notre capacité à exécuter des calculs sensibles et très performants (par exemple, ZK Proof, raisonnement LLM) localement sur le matériel utilisateur.Deuxièmement, cela crée une énorme fenêtre d’opportunité pour s’assurer que la poursuite de l’efficacité ne nuise pas à une autre valeur, notamment la sécurité, l’ouverture et la simplicité: Sécurité et ouverture du canal latéral dans le matériel informatique, réduisant la complexité du circuit dans ZK-Snark et réduisant la complexité dans les machines virtuelles.Historiquement, la poursuite de l’efficacité a conduit ces autres facteurs à prendre un siège arrière.Avec l’architecture de colle et de coprocesseur, il n’est plus nécessaire.Une partie de la machine optimise l’efficacité, et l’autre partie optimise la polyvalence et d’autres valeurs, et les deux fonctionnent ensemble.
Cette tendance est également très bénéfique pour la cryptographie, qui est un exemple majeur de «calcul structuré coûteux» qui a accéléré le développement de cette tendance.Cela ajoute une autre occasion d’améliorer la sécurité.Dans le monde de la blockchain, des améliorations de la sécurité sont également possibles: nous pouvons nous soucier moins de l’optimisation des machines virtuelles et nous concentrer davantage sur l’optimisation de la précompilation et d’autres fonctions de coexistance avec les machines virtuelles.
Troisièmement, cette tendance offre aux plus petits participants aux petits participants de participer.Si les calculs deviennent moins célibataires et plus modulaires, cela réduira considérablement la barrière à l’entrée.Même avec un type d’ASIC informatique, il est possible de faire une différence.Il en va de même dans le champ ZK Proof et dans l’optimisation EVM.La rédaction de code avec une efficacité presque franc est plus facile et plus facile d’accès.L’audit et la vérification formelle de ce code deviennent plus faciles et plus faciles d’accès.Enfin, comme ces champs informatiques très différents convergent vers certains modèles communs, il y a plus de place pour la collaboration et l’apprentissage entre eux.






