المؤلف: لوكاس تشيان ، أرجون يناماندرا ، المصدر: Galaxy Research ، تم تجميعه بواسطة: Baitchain Vision
مقدمة
في العام الماضي ، نشرت Galaxy Research مقالتها الأولى حول تقاطع العملة المشفرة والذكاء الاصطناعي. يستكشف المقال كيف يمكن أن تصبح العملة المشفرة دون ثقة وبنية تحتية بدون إذن أساس ابتكار الذكاء الاصطناعي.وتشمل هذه: ظهور سوق لا مركزي للمعالجة (أو الحوسبة) التي ظهرت استجابة لنقص معالجات الرسومات (GPU) ؛التطبيقات المبكرة للتعلم الآلي المعرفة الصفرية (ZKML) في التفكير المنطقي على السلسلة ؛ وإمكانات عوامل الذكاء الاصطناعى المستقلة لتبسيط التفاعلات المعقدة واستخدام العملات المشفرة كوسيلة أصلية للتبادل.
في ذلك الوقت ، كانت العديد من هذه المبادرات في مهدها ، ولكنها كانت مجرد دليل مقنع على المفاهيم التي تعني أنها كانت لها مزايا عملية على الحلول المركزية ، لكنها لم توسع بعد بما يكفي لإعادة تشكيل مشهد الذكاء الاصطناعي.ومع ذلك ، في العام منذ ذلك الحين ، أحرزت الذكاء الاصطناعى اللامركزية تقدمًا ذا مغزى في تحقيقه.للاستيلاء على هذا الزخم واكتشاف التقدم الأكثر واعدة ، ستقوم Galaxy Research بإصدار سلسلة من المقالات في العام المقبل لاستكشاف رؤوس محددة في حدود التشفير + الذكاء الاصطناعي.
تم نشر هذه المقالة لأول مرة في التدريب اللامركزي ، مع التركيز على المشاريع المخصصة لتنفيذ التدريب بدون إذن للنماذج الأساسية على نطاق عالمي. دوافع هذه المشاريع مزدوجة.من منظور عملي ، أدركوا أنه يمكن استخدام عدد كبير من وحدات معالجة الرسومات الخاملة في جميع أنحاء العالم للتدريب النموذجي ، مما يوفر لمهندسي الذكاء الاصطناعى في جميع أنحاء العالم عملية تدريب لا تطاق على خلاف ذلك وجعل تطوير AI مفتوح المصدر حقيقة واقعة.من المنظور المفاهيمي ، يتم تحفيز هذه الفرق من خلال السيطرة الصارمة على واحدة من أهم الثورات التكنولوجية في عصرنا والحاجة الملحة لإنشاء بدائل مفتوحة.
على نطاق أوسع ، بالنسبة لحقل التشفير ، فإن تنفيذ التدريب اللامركزي واللائم للنموذج الأساسي هو خطوة أساسية في بناء كومة AI على السلسلة بالكامل لا تتطلب أي إذن ويمكن الوصول إليها في كل طبقة.يمكن لسوق GPU الوصول إلى النماذج وتوفير الأجهزة اللازمة للتدريب والاستدلال.يمكن استخدام مزودي ZKML للتحقق من إخراج النموذج وحماية الخصوصية.يمكن أن يكون عوامل الذكاء الاصطناعى بمثابة كتل بناء قابلة للتكامل تجمع بين النماذج ومصادر البيانات والبروتوكولات في تطبيقات ذات ترتيب أعلى.
يستكشف هذا التقرير الهندسة المعمارية الأساسية لبروتوكول الذكاء الاصطناعي اللامركزي ، والمشاكل الفنية التي يهدف إلى حلها ، وآفاق التدريب اللامركزي.لا تزال الفرضية الأساسية للعملات المشفرة والذكاء الاصطناعي كما هو الحال قبل عام.تزود العملات المشفرة من الذكاء الاصطناعى بطبقة تسوية نقل القيمة عديمة الإذن وغير موثوقة وقابلة للتأليف.التحدي الآن هو إثبات أن الأساليب اللامركزية يمكن أن تجلب مزايا عملية على الأساليب المركزية.
أساسيات التدريب النموذجي
قبل الغوص في أحدث التطورات في التدريب اللامركزي ، من الضروري أن يكون لديك فهم أساسي لنماذج اللغة الكبيرة (LLMs) والهندسة المعمارية الأساسية.سيساعد ذلك القراء على فهم كيفية عمل هذه المشاريع والمشاكل الرئيسية التي يحاولون حلها.
محول
يتم تشغيل نماذج اللغة الكبيرة (LLMS) (مثل ChatGPT) بواسطة بنية تسمى Transformer. تم اقتراح Transformer لأول مرة في ورقة Google 2017 وهو أحد أهم الابتكارات في مجال تطوير الذكاء الاصطناعي.باختصار ، يقوم المحول باستخراج البيانات (المسمى الرموز) ويطبق آليات مختلفة لتعلم العلاقة بين هذه الرموز.
يتم تصميم العلاقة بين الإدخالات باستخدام الأوزان.يمكن اعتبار الأوزان هي الملايين إلى تريليونات من المقابض التي تشكل النموذج ، والتي يتم ضبطها باستمرار حتى يمكن التنبؤ بالمدخل التالي في التسلسل باستمرار.بعد الانتهاء من التدريب ، يمكن للنموذج التقاط الأنماط والمعاني وراء اللغة البشرية بشكل أساسي.
تشمل المكونات الرئيسية لتدريب المحولات:
-
التسليم إلى الأمام:في الخطوة الأولى من عملية التدريب ، يدخل المحول مجموعة من الرموز من مجموعة بيانات أكبر. بناءً على هذه المدخلات ، يحاول النموذج التنبؤ بما يجب أن يكون الرمز المميز التالي.في بداية التدريب ، تكون أوزان النموذج عشوائيًا.
-
حساب الخسارة:ثم يتم استخدام تنبؤات الانتشار الأمامي لحساب درجة الخسارة ، والتي تقيس الفجوة بين هذه التنبؤات والعلامات الفعلية في دفعة البيانات الأصلية لنموذج الإدخال.بمعنى آخر ، كيف تقارن التنبؤات الناتجة عن النموذج أثناء الانتشار إلى الأمام بالعلامات الفعلية المستخدمة لتدريبها في مجموعة البيانات الأكبر؟أثناء التدريب ، يتمثل الهدف في تقليل درجة الخسارة هذه لتحسين دقة النموذج.
-
backpropagation:ثم يتم حساب التدرج من كل وزن باستخدام درجة الخسارة.تخبر هذه التدرجات بالنموذج كيفية ضبط الأوزان لتقليل الخسائر قبل الانتشار التالي.
-
مُحسّنالتجديد:تحسينصتقرأ الخوارزمية هذه التدرجات وتعدل كل وزن لتقليل الخسارة.
-
يكرر:كرر الخطوات المذكورة أعلاه حتى يتم استهلاك جميع البيانات ويبدأ النموذج في الوصول إلى التقارب–بمعنى آخر ، عندما لم يعد التحسين الإضافي يؤدي إلى انخفاض كبير في الخسارة أو تحسين الأداء.
التدريب (ما قبل التدريب وما بعد التدريب)
تتكون عملية التدريب النموذجية الكاملة من خطوتين مستقلتين: ما قبل التدريب وما بعد التدريب. الخطوات المذكورة أعلاه هي مكون أساسي لعملية التدريب قبل التدريب.عند الانتهاء ، يقومون بإنشاء نموذج قاعدة تدريب مسبقًا ، يُعرف باسم النموذج الأساسي.
ومع ذلك ، غالبًا ما تتطلب النماذج مزيد من التحسن بعد التدريب ، والذي يسمى بعد التدريب.يتم استخدام ما بعد التدريب لزيادة تحسين النموذج الأساسي بعدة طرق ، بما في ذلك تحسين دقتها أو تخصيص حالات الاستخدام المحددة مثل الترجمة أو التشخيص الطبي.
ما بعد التدريب هو خطوة أساسية في صنع نماذج لغة كبيرة (LLMS) أداة قوية اليوم.هناك عدة طرق مختلفة للتدريب بعد ذلك. أكثرهما شعبية هما:
-
صقل خاضع للإشراف (SFT):SFT مشابه جدًا لعملية التدريب المسبقة أعلاه.الفرق الرئيسي هو أن النموذج الأساسي يتم تدريبه على مجموعات البيانات أو الإجابات المخطط لها بعناية ، بحيث يمكن أن تتعلم اتباع تعليمات محددة أو التركيز على حقل معين.
-
التعلم التعزيز (RL):لا يقوم RL بتحسين النموذج عن طريق إدخال بيانات جديدة ، بل عن طريق تصنيف إخراج النموذج والسماح للنموذج بتحديث الوزن لزيادة هذه المكافأة. في الآونة الأخيرة ، استخدم نموذج الاستدلال (الموضح أدناه) RL لتحسين إنتاجه.في السنوات الأخيرة ، مع ظهور مشاكل التحجيم قبل التدريب ، تم إحراز تقدم كبير في استخدام نماذج RL ونماذج الاستدلال بعد التدريب ، لأنه يحسن أداء النموذج بشكل كبير دون بيانات إضافية أو كميات كبيرة من الحساب.
على وجه التحديد ، يعد التدريب بعد RL مثاليًا لحل العقبات التي تواجه التدريب المشتت (الموضح أدناه).وذلك لأن معظم الوقت في RL ، يستخدم النموذج تمريرات للأمام (النموذج يجعل التنبؤات ولكن لم يغير نفسه بعد) لإنشاء كمية كبيرة من الإخراج.لا تتطلب هذه التمريرات الأمامية التنسيق أو التواصل بين الآلات ويمكن القيام به بشكل غير متزامن.كما أنها موازية ، مما يعني أنه يمكن تقسيمها إلى مهام مستقلة يمكن تنفيذها في وقت واحد على وحدات معالجة الرسومات المتعددة.وذلك لأنه يمكن حساب كل عملية تشغيل بشكل مستقل ، وإضافة الحساب ببساطة لزيادة الإنتاجية من خلال تشغيل التدريب.فقط بعد تحديد أفضل إجابة ، سيقوم النموذج بتحديث أوزانه الداخلية ، مما يقلل من التردد الذي يحتاج إليه الجهاز إلى مزامنة.
بعد تدريب النموذج ، تسمى عملية استخدامه لإنشاء الإخراج.على عكس التدريب الذي يتطلب تعديلات على الملايين أو حتى مليارات الأوزان ، فإن التفكير يحافظ على هذه الأوزان دون تغيير ويطبقها ببساطة على مدخلات جديدة.بالنسبة لنماذج اللغة الكبيرة (LLM) ، فإن التفكير يعني أخذ موجه ، وتشغيله إلى طبقات مختلفة من النموذج ، وخطوة خطوة تتنبأ بالوقوف التالي على الأرجح.نظرًا لأن الاستدلال لا يتطلب الانتشار الخلفي (عملية ضبط الأوزان بناءً على خطأ النموذج) أو تحديثات الوزن ، فإنه يتطلب أقل من الناحية الحسابية من التدريب ، ولكن بسبب النطاق الضخم للنماذج الحديثة ، لا يزال كثيفة الموارد.
باختصار: المنطق هو القوة الدافعة وراء التطبيقات مثل chatbots ومساعدي الكود وأدوات الترجمة.في هذه المرحلة ، يضع النموذج “معرفته المستفادة” موضع التنفيذ.
تدريب النفقات العامة
يتطلب الترويج لعملية التدريب أعلاه برامج وأجهزة مكثفة ومتخصصة للغاية لتشغيلها على نطاق واسع.وصلت الاستثمارات في مختبرات الذكاء الاصطناعي الرائدة في العالم إلى مستويات غير مسبوقة ، والتي تتراوح من مئات الملايين إلى مليارات الدولارات.قال الرئيس التنفيذي لشركة Openai Sam Altman إن GPT-4 تكلف أكثر من 100 مليون دولار ، في حين أن الرئيس التنفيذي للأنثروبور داريو أمودي قال إن أكثر من مليار دولار في برامج التدريب جارية بالفعل.
جزء كبير من هذه التكاليف يأتي من وحدات معالجة الرسومات.تكلفة وحدات معالجة الرسومات الأعلى مثل NVIDIA H100 أو B200 تصل إلى 30،000 دولار ، ويقال إن Openai يخطط لنشر أكثر من مليون وحدات معالجة الرسومات بحلول نهاية عام 2025. ومع ذلك ، لا يكفي أن يكون لها قوة وحدة معالجة الرسومات وحدها.يجب نشر هذه الأنظمة في مراكز بيانات عالية الأداء مجهزة ببنية تحتية للاتصالات عالية السرعة.تدعم التقنيات مثل NVIDIA NVLINK تبادل البيانات السريعة بين وحدات معالجة الرسومات داخل الخادم ، بينما يتصل Infiniband بمجموعات الخادم حتى تتمكن من التشغيل كهيكل حوسبة موحد واحد.
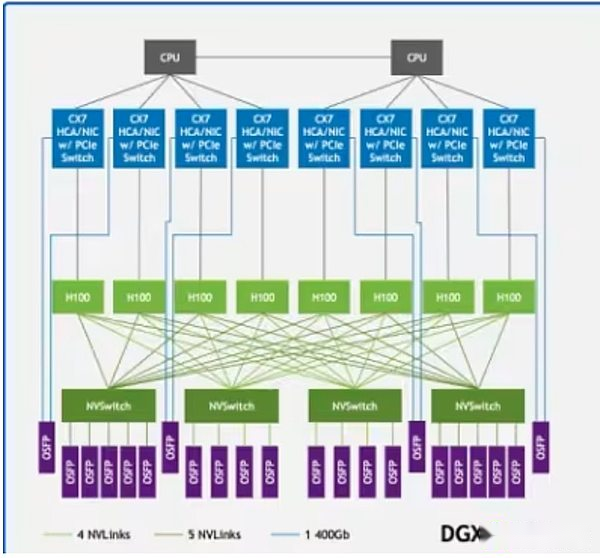 NVLink في بنية عينة DGX H100 تربط وحدات معالجة الرسومات (المستطيلات الخضراء الفاتحة) في النظام ، في حين أن Infiniband يربط الخوادم (الخطوط الخضراء) إلى شبكة موحدة
NVLink في بنية عينة DGX H100 تربط وحدات معالجة الرسومات (المستطيلات الخضراء الفاتحة) في النظام ، في حين أن Infiniband يربط الخوادم (الخطوط الخضراء) إلى شبكة موحدة
لذلك ، يتم تطوير معظم النماذج الأساسية بواسطة مختبرات الذكاء الاصطناعى المركزية مثل Openai و Anthropic و Meta و Google و Xai.هؤلاء العمالقة فقط لديهم الموارد الغنية اللازمة للتدريب.على الرغم من أن هذا قد أدى إلى تقدم كبير في التدريب والأداء النموذجي ، إلا أنه ركز أيضًا السيطرة على تطوير النماذج الأساسية الرائدة في أيدي كيانات قليلة.علاوة على ذلك ، هناك أدلة متزايدة على أن قانون التحجيم قد يعمل ، مما يحد من فعالية تعزيز ذكاء النماذج المسبقة عن طريق إضافة حساب أو بيانات.
لمواجهة هذا التحدي ، على مدى السنوات القليلة الماضية ، بدأت مجموعة من مهندسي الذكاء الاصطناعى في تطوير طرق تدريب نموذجية جديدة لمحاولة معالجة هذه التعقيدات التقنية وتقليل متطلبات الموارد الضخمة.تسمي هذه المقالة هذا الجهد “التدريب اللامركزي”.
التدريب اللامركزي والموزع
يثبت نجاح Bitcoin أنه يمكن تنسيق الحوسبة ورأس المال بطريقة لا مركزية ، وبالتالي ضمان أمن الشبكات الاقتصادية الكبيرة.يهدف التدريب اللامركزي إلى بناء شبكة لا مركزية باستخدام ميزات العملات المشفرة ، بما في ذلك آليات بدون إذن ، غير موثوقة وحوفيات ، لتدريب نموذج أساسي قوي مماثل لمقدمي الخدمات المركزية.
في التدريب اللامركزي ، تعمل العقد الموجودة في مواقع مختلفة في جميع أنحاء العالم على شبكات محسّنة بدون إذن ، مما يساهم في تدريب نماذج الذكاء الاصطناعي.هذا يختلف عن التدريب الموزع ، والذي يشير إلى أن النموذج الذي يتم تدريبه في مناطق مختلفة ولكن يتم تنفيذه بواسطة كيان واحد أو أكثر مرخصة (أي من خلال عملية القائمة البيضاء).ومع ذلك ، يجب أن تستند جدوى التدريب اللامركزي إلى التدريب الموزع.بدأت العديد من المختبرات المركزية ، على دراية بالقيود الصارمة في إعدادات التدريب الخاصة بها ، في استكشاف طرق لتنفيذ التدريب الموزع لتحقيق نتائج مماثلة للإعدادات الحالية.
هناك بعض العقبات العملية التي تمنع التدريب اللامركزي من أن يصبح حقيقة:
-
اتصالات الاتصال:عندما يتم تفريق العقد جغرافيا ، لا يمكنهم الوصول إلى البنية التحتية للاتصالات أعلاه.يتطلب التدريب اللامركزي النظر في سرعة الشبكة القياسية ، ونقل متكرر لكميات كبيرة من البيانات ، ومزامنة GPU أثناء التدريب.
-
يؤكد:شبكات التدريب اللامركزية خالية من الترخيص بشكل أساسي وهي مصممة للسماح لأي شخص بالمساهمة في قوة الحوسبة.لذلك ، يجب عليهم تطوير آليات التحقق لمنع المساهمين من محاولة تدمير الشبكة من خلال مدخلات غير صحيحة أو ضارة ، أو استغلال نقاط الضعف في النظام للحصول على المكافآت دون المساهمة في العمل الفعال.
-
حساب: بغض النظر عن الحجم ، يجب أن تجمع الشبكات اللامركزية طاقة حوسبة كافية لتدريب النماذج.في حين أن هذا يعطي بعض مزايا الشبكات اللامركزية ، والتي تم تصميمها للسماح لأي شخص لديه وحدة معالجة الرسومات بالمشاركة في عملية التدريب ، فإنها تجلب أيضًا التعقيد ، حيث يجب على هذه الشبكات تنسيق الحوسبة غير المتجانسة.
-
الحوافز/التمويل/الملكية والتخصيص:يجب على شبكات التدريب اللامركزية تصميم آليات الحوافز ونماذج الملكية/الدخل لضمان سلامة الشبكة بفعالية ومكافأة مساهمة مقدمي الحوسبة والمقدمين ومصممي النماذج.هذا في تناقض حاد مع المختبر المركزي حيث تتم الشركة من قبل الشركة.
على الرغم من هذه القيود ، لا تزال العديد من المشاريع تنفذ التدريب اللامركزي لأنهم يعتقدون أن السيطرة على النموذج الأساسي لا ينبغي أن تكون في أيدي بعض الشركات.هدفهم هو التعامل مع المخاطر التي يطرحها التدريب المركزي ، مثل فشل النقطة الواحدة بسبب الاعتماد على عدد قليل من المنتجات المركزية ؛ خصوصية البيانات والرقابة ؛ قابلية التوسع والاتساق والتحيز في الذكاء الاصطناعي.على نطاق أوسع ، يعتقدون أن تطوير الذكاء الاصطناعي مفتوح المصدر ضروري ، وليس اختياريًا.بدون بنية تحتية مفتوحة يمكن التحقق منها ، سيتم قمع الابتكار ، وسيقتصر الوصول على عدد قليل من الطبقات المميزة ، وسوف يرث المجتمع أنظمة منظمة العفو الدولية التي تشكلها حوافز الشركات الضيقة.من هذا المنظور ، لا يتعلق التدريب اللامركزي فقط ببناء نماذج تنافسية ، ولكن أيضًا حول إنشاء نظام بيئي مرن وشفاف وتشاركي يعكس المصالح الجماعية بدلاً من المصالح الملكية.
نظرة عامة على المشروع
أدناه ، سنقدم نظرة عامة متعمقة على الآليات الأساسية للعديد من مشاريع التدريب اللامركزية.
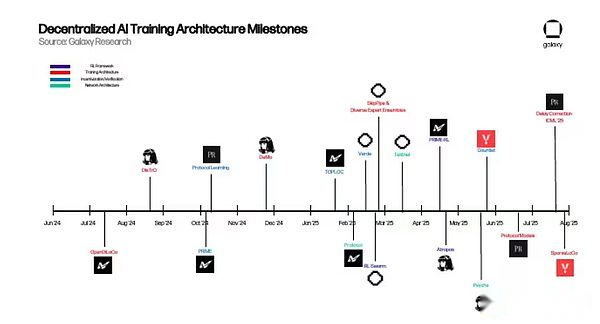
منتجع نوس
خلفية
تأسست Nous Research في عام 2022 ، وهي مؤسسة أبحاث مفتوحة المصدر. بدأ الفريق كمجموعة غير رسمية من الباحثين والمطورين من الذكاء الاصطناعي مفتوح المصدر الذين يعملون على معالجة قيود رمز AI مفتوح المصدر. مهمتها هي “إنشاء وتوفير أفضل نموذج مفتوح المصدر.”
لقد اعتبر الفريق منذ فترة طويلة التدريب اللامركزي بمثابة عقبة رئيسية.على وجه التحديد ، أدركوا أن الأدوات اللازمة للوصول إلى وحدات معالجة الرسومات وتنسيق الاتصالات بين وحدات معالجة الرسومات تم تطويرها في المقام الأول لتلبية شركات الذكاء الاصطناعى المركزية الكبيرة ، والتي تركت المؤسسات المقيدة للموارد مع مساحة صغيرة للمشاركة في تطوير ذي معنى.على سبيل المثال ، يمكن لآخر وحدات معالجة الرسومات في NVIDIA BLACKWELL (مثل B200) التواصل مع بعضها البعض باستخدام نظام تبديل NVLINK بسرعات تصل إلى 1.8 تيرابايت في الثانية.هذا مشابه لإجمالي عرض النطاق الترددي للبنية التحتية للإنترنت الرئيسية ولا يمكن تحقيقه إلا في عمليات النشر المركزية على نطاق البيانات.لذلك ، يكاد يكون من المستحيل على الشبكات الصغيرة أو الموزعة تحقيق أداء مختبرات الذكاء الاصطناعي الكبيرة دون إعادة التفكير في استراتيجيات الاتصال.
قبل الشروع في حل مشكلة التدريب اللامركزي ، قدمت NOUS مساهمات كبيرة في مجال الذكاء الاصطناعي.في أغسطس 2023 ، نشرت NOUS “Yarn: Context Window Extension لنماذج اللغة الكبيرة”.تحل هذه الورقة مشكلة بسيطة ولكنها مهمة: يمكن أن تتذكر معظم نماذج الذكاء الاصطناعى ومعالجة كمية ثابتة من النص في وقت واحد (أي “نافذة السياق”).على سبيل المثال ، سيبدأ النموذج المدرب بحد أقصى قدره 2000 كلمة في نسيان أو فقدان المعلومات إذا كانت مستند الإدخال أطول.يقدم Yarn طريقة لتوسيع هذا القيد بشكل أكبر دون إعادة تدريب النموذج من الصفر.يقوم بضبط كيفية تتبع النموذج وضع Word (مثل الإشارات المرجعية في كتاب) بحيث لا يزال بإمكانه تتبع تدفق المعلومات حتى لو كان النص عشرات الآلاف من الكلمات.تتيح الطريقة للنموذج معالجة تسلسل ما يصل إلى 128000 علامة – حول طول مغامرات Mark Twain في Huckleberry Finn – باستخدام بيانات الطاقة والتدريب أقل بكثير في نفس الوقت من الطريقة القديمة.باختصار ، يمكّن الغزل نماذج الذكاء الاصطناعى من “القراءة” وفهم المستندات أو المحادثات أو مجموعات البيانات لفترة أطول.هذا تقدم كبير في توسع قدرات الذكاء الاصطناعي وقد تم تبنيه من قبل مجتمع أبحاث أوسع بما في ذلك Openai و Deepseek في الصين.
التجريبي والتوزيع
في مارس 2024 ، نشرت NOUS اختراقًا في مجال التدريب الموزع يسمى “تحسين الزخم المنفصل” (العرض التوضيحي). تم تطوير Demo من قبل الباحثين Nous Bowen Peng و Jeffrey Quesnelle بالتعاون مع Diverik P. Kingma ، المؤسس المشارك لـ Openai ومخترع Adamw Optimizer.هذا هو لبنة البناء الرئيسية لمكدس التدريب اللامركزي nous ، مما يقلل من الاتصالات العامة في إعدادات التدريب الموازية للبيانات الموزعة عن طريق تقليل كمية البيانات المتبادلة بين وحدات معالجة الرسومات.في التدريب الموازي للبيانات ، تقوم كل عقدة بحفظ نسخة كاملة من أوزان النموذج ، ولكن يتم تقسيم مجموعة البيانات إلى كتل تتم معالجتها بواسطة عقد مختلفة.
Adamw هو واحد من أكثر الأمراض استخدامًا في التدريب النموذجي.تتمثل إحدى الوظائف الرئيسية لـ Adamw في تهدئة ما يسمى الزخم ، وهو متوسط الأوزان النموذجية التي تتغير في الماضي.في الأساس ، يساعد Adamw على التخلص من الضوضاء التي تم تقديمها أثناء التدريب الموازي للبيانات ، وبالتالي تحسين كفاءة التدريب.تقوم Nous Research بإنشاء مُحسّن جديد تمامًا يعتمد على Adamw و Demo ، مما يؤدي إلى تقسيم الزخم إلى أجزاء محلية ومشتركة عبر مدربين مختلفين.هذا يقلل من مقدار حركة المرور المطلوبة بين العقد عن طريق الحد من كمية البيانات التي يجب مشاركتها بين العقد.
يركز العرض التوضيحي بشكل انتقائي على المعلمات الأسرع أثناء كل تكرار GPU.المنطق بسيط: المعلمات ذات الاختلافات الأكبر حاسمة في التعلم ويجب أن تتم مزامنتها بين العمال ذوي الأولوية الأعلى.في الوقت نفسه ، يمكن أن تتخلف المعلمات البطيئة المتغيرة مؤقتًا دون التأثير بشكل كبير على التقارب.في الواقع ، يقوم هذا بتصفية تحديثات الضوضاء مع الحفاظ على التحديثات الأكثر أهمية.يستخدم NOUS أيضًا تقنيات الضغط ، بما في ذلك طريقة تحويل جيب التمام (DCT) المنفصلة مماثلة لصور JPEG المضغوطة لزيادة تقليل كمية البيانات المرسلة.من خلال مزامنة التحديثات الأكثر أهمية فقط ، يقلل العرض التوضيحي من 10 إلى 1000 مرة (اعتمادًا على حجم النموذج).
في يونيو 2024 ، أطلق فريق NOUS الابتكار الرئيسي الثاني ، وهو محسن التدريب الموزع (Distro).يوفر Demo ابتكارات Core Optimizer ، بينما تقوم Distro بدمجها في إطار عمل مُحسّن أوسع يزيد من ضغوط المعلومات المشتركة بين وحدات معالجة الرسومات ومعالجة مشكلات مثل مزامنة GPU ، وتحمل الأعطال وموازنة التحميل.في ديسمبر 2024 ، استخدمت NOUS توزيعات لتدريب نموذج مع 15 مليار معلمة على بنية تشبه LLAMA ، مما يثبت جدوى الطريقة.
نفسية
في مايو ، أصدرت Nous Psyche ، وهي إطار لتنسيق التدريب اللامركزي ، ومزيد من الابتكارات في بنية العرض التجريبي والتوزيع. تشمل الترقيات الفنية الرئيسية لـ Psyche التدريب غير المتزامن المحسّن من خلال السماح ل GPU بإرسال تحديثات النموذج عند بدء الخطوة التالية من التدريب.هذا يقلل من وقت الخمول ويجعل استخدام GPU أقرب إلى أنظمة مركزية مقترنة بإحكام.قامت Psyche بتحسين تقنية الضغط التي أدخلتها Distro ، مما يقلل من حمل الاتصالات بمقدار 3 مرات.
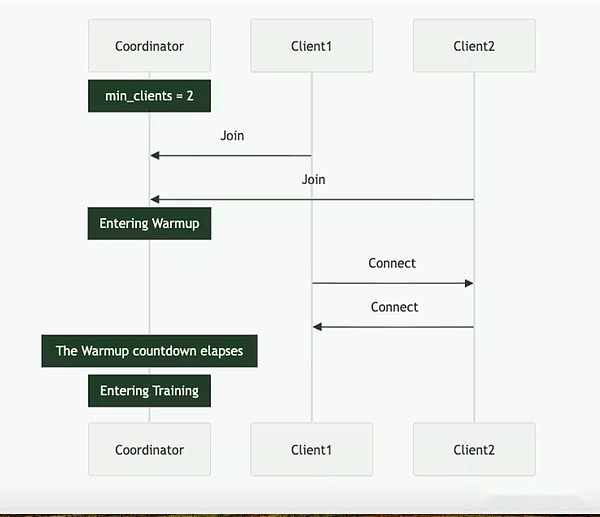
يمكن تحقيق النفس من خلال مجموعة كاملة على السلسلة (عبر سولانا) أو الإعداد خارج السلسلة.أنه يحتوي على ثلاثة لاعبين رئيسيين: المنسق والعميل ومزود البيانات.يقوم المنسق بتخزين جميع المعلومات اللازمة لتسهيل عملية التدريب ، بما في ذلك أحدث حالة من النموذج ، والعملاء المشاركين ، وتخصيص البيانات والتحقق من الإخراج.العميل هو مزود GPU الفعلي الذي يؤدي مهام التدريب أثناء تشغيل التدريب.بالإضافة إلى التدريب النموذجي ، يشاركون في عملية الشهود (الموضحة أدناه).يوفر مزود البيانات (يمكن للعميل تخزينه بمفرده) البيانات اللازمة للتدريب.
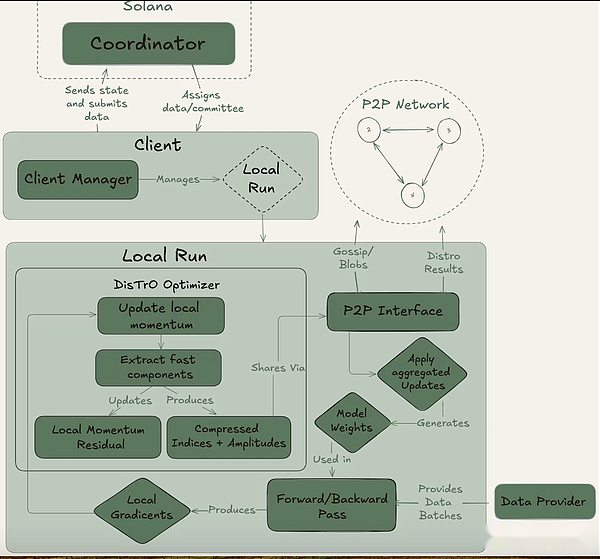 نفسية تقسيم التدريب إلى مرحلتين مختلفتين: العصر والخطوة.هذا يخلق نقاط الدخول والخروج الطبيعي للعملاء حتى يتمكنوا من المشاركة دون الاستثمار في التدريب الكامل.يساعد هذا الهيكل في تقليل تكاليف الفرصة البديلة لمقدمي خدمات GPU ، حيث قد لا يكونون قادرين على استثمار الموارد طوال المدى.
نفسية تقسيم التدريب إلى مرحلتين مختلفتين: العصر والخطوة.هذا يخلق نقاط الدخول والخروج الطبيعي للعملاء حتى يتمكنوا من المشاركة دون الاستثمار في التدريب الكامل.يساعد هذا الهيكل في تقليل تكاليف الفرصة البديلة لمقدمي خدمات GPU ، حيث قد لا يكونون قادرين على استثمار الموارد طوال المدى.
في بداية الحقبة ، يحدد المنسق المعلمات الرئيسية: بنية النموذج ، ومجموعة البيانات التي سيتم استخدامها ، وعدد العملاء المطلوبين.التالي هو مرحلة الاحماء المختصرة ، حيث سيقوم العميل بمزامنة مع أحدث نقطة تفتيش النموذج ، والتي يمكن أن تكون من مصدر عام أو من عملاء العملاء الآخرين من نقطة إلى نقطة.بعد بدء التدريب ، سيتم تعيين جزء من البيانات وتدريبه محليًا.بعد تحديث الحساب ، يقوم العميل ببث نتائجه إلى بقية الشبكة جنبًا إلى جنب مع وعد التشفير (تجزئة SHA-256 التي تثبت أن العمل يتم بشكل صحيح).
يتم اختيار جزء من العميل بشكل عشوائي كشهود في كل جولة ويعمل كآلية للتحقق الرئيسية للنفسية.يتدرب هؤلاء الشهود كالمعتاد ، ولكنهم أيضًا يتحققون من تحديثات العميل التي يتم استلامها وصالحها.يقومون بتقديم مرشحات بلوم إلى المنسق ، وهي بنية بيانات خفيفة الوزن تلخص بشكل فعال هذه المشاركة.بينما يعترف Nous نفسه بأن النهج ليس مثاليًا لأنه قد ينتج إيجابيات كاذبة ، فإن الباحثين على استعداد لقبول هذه المفاضلة للكفاءة.بمجرد أن يؤكد الشاهد المحدث أن النصاب القانوني يصل ، يطبق المنسق التحديث على النموذج العالمي ويسمح لجميع العملاء بمزامنة نموذجهم قبل الدخول إلى الجولة التالية.
بشكل حاسم ، يسمح تصميم Psyche بالتداخل في التدريب والتحقق.بمجرد أن يقدم العميل التحديث ، يمكن أن يبدأ على الفور تدريب الدفعة التالية دون انتظار المنسق أو العملاء الآخرين لإكمال الجولة السابقة من التدريب.يضمن هذا التصميم المتداخل ، جنبًا إلى جنب مع تقنية ضغط Distro ، أن يتم الحفاظ على النفقات العامة للاتصال في الحد الأدنى وأن وحدة معالجة الرسومات ليست خاملة.
 في مايو 2025 ، أطلقت NOUS Research أكبر تدريب حتى الآن: Consilience ، محول مع 40 مليار معلمة ، قبل التدريب حوالي 20 تريليون رمز في شبكة التدريب اللامركزية النفسية.التدريب لا يزال قيد التقدم.حتى الآن ، كانت العملية مستقرة بشكل أساسي ، ولكن حدثت بعض قمم الخسارة ، مما يشير إلى أن مسار التحسين قد انحرف لفترة وجيزة عن التقارب.للقيام بذلك ، عاد الفريق إلى آخر نقطة تفتيش صحية وتغليف المُحسّن باستخدام حماية خطوة Skip Olmo ، والتي تتخطى أي تحديثات لأي خسارة أو قواعد التدرج التي تختلف من خلال العديد من الانحرافات المعيارية عن المتوسط ، مما يقلل من خطر الذروة المستقبلية.
في مايو 2025 ، أطلقت NOUS Research أكبر تدريب حتى الآن: Consilience ، محول مع 40 مليار معلمة ، قبل التدريب حوالي 20 تريليون رمز في شبكة التدريب اللامركزية النفسية.التدريب لا يزال قيد التقدم.حتى الآن ، كانت العملية مستقرة بشكل أساسي ، ولكن حدثت بعض قمم الخسارة ، مما يشير إلى أن مسار التحسين قد انحرف لفترة وجيزة عن التقارب.للقيام بذلك ، عاد الفريق إلى آخر نقطة تفتيش صحية وتغليف المُحسّن باستخدام حماية خطوة Skip Olmo ، والتي تتخطى أي تحديثات لأي خسارة أو قواعد التدرج التي تختلف من خلال العديد من الانحرافات المعيارية عن المتوسط ، مما يقلل من خطر الذروة المستقبلية.
دور سولانا
على الرغم من أن Psyche يمكن أن تعمل في بيئة خارج السلسلة ، إلا أنها مصممة لاستخدامها في سولانا بلوكشين. تعمل Solana كطبقة ثقة ومساءلة لشبكة التدريب ، وتسجيل التزامات العملاء ، وإثبات الشهود ، وبيانات التعريف التدريبية على السلسلة.هذا يخلق مسار تدقيق غير قابل للتغيير لكل جولة من التدريب ، مما يسمح بالتحقق الشفاف من من قدم المساهمات ، وما هو العمل الذي تم إنجازه ، وما إذا كان قد مرت.
تخطط Nous أيضًا لاستخدام Solana لتسهيل توزيع المكافآت التدريبية.على الرغم من أن المشروع لم يصدر اقتصاديات رمزية رسمية ، إلا أن وثائق Psyche تحدد نظامًا يقوم فيه المنسق بتتبع مساهمات العميل الحسابية وتخصيص النقاط بناءً على العمل الذي تم التحقق منه.يمكن بعد ذلك تبادل هذه النقاط للرموز من خلال العمل مع العقود الذكية المالية التي تدمجها على السلسلة.يمكن للعملاء الذين يكملون خطوات التدريب الفعالة الحصول على مكافآت مباشرة من العقد بناءً على مساهماتهم.لم تستخدم Psyche بعد آلية المكافآت في سباق التدريب ، ولكن بمجرد إطلاقها رسميًا ، من المتوقع أن يلعب النظام دورًا رئيسيًا في تخصيص رموز Crypto Nous.
سلسلة هيرميس موديل
بالإضافة إلى هذه المساهمات البحثية ، أنشأت NOUS حالة مطور نموذج Open Source الرائدة مع سلسلة Hermes من نماذج اللغة الكبيرة التي تم ضبطها (LLM).في أغسطس 2024 ، أطلق الفريق HERMES-3 ، وهو مجموعة كاملة من المعلمات التي تم ضبطها على أساس LAMA 3.1 ، والتي حققت نتائج تنافسية على التصنيفات العامة ، على الرغم من أنها صغيرة نسبيًا ، مماثلة لنماذج الملكية الأكبر.
في الآونة الأخيرة ، أصدرت Nous سلسلة Hermes-4 Model Series في أغسطس 2025 ، وهي سلسلة طرازات الأكثر تقدماً حتى الآن.يركز Hermes-4 على تحسين قدرات التفكير الخطوة بخطوة من النموذج ، مع الأداء بشكل ممتاز في تنفيذ التعليمات المنتظمة.لقد كان أداءً جيدًا في اختبارات الرياضيات والبرمجة والتفاهم واختبارات الحس السليم.يلتزم الفريق بمهمة Nous Open Source ويصدر علنًا جميع أوزان نموذج Hermes-4 للجميع لاستخدامها وبناءها.بالإضافة إلى ذلك ، أصدرت NOUS واجهة إمكانية الوصول إلى النماذج تسمى NOUS Chat ، والتي ستكون متاحة مجانًا خلال الأسبوع الأول من الإصدار.
إن إصدار نموذج Hermes لا يعزز مصداقية Nous فقط كمؤسسة لبناء النماذج ، بل يوفر أيضًا التحقق العملي لجدول أعمال البحث الأوسع.يثبت كل إصدار من هيرميس أنه يمكن تحقيق إمكانات متطورة في بيئة مفتوحة ، ووضع الأساس لتحقيقات التدريب اللامركزية للفرق (التجريبية ، والتوزيع ، والنفسية) وتؤدي في نهاية المطاف إلى الجولة الطموحة 40B.
Atropos
كما ذكر أعلاه ، يلعب تعلم التعزيز دورًا متزايد الأهمية في ما بعد التدريب بسبب التقدم في نماذج الاستدلال وقيود التوسع في التدريب المسبق. Atropos هو حل Nous لتعزيز التعلم في بيئة لا مركزية.إنه إطار تعلم تعزيز التعزيز المعياري للتوصيل والتشغيل لـ LLM ، ويتكيف مع خلفية الاستدلال المختلفة ، وطرق التدريب ، ومجموعات البيانات ، وبيئات التعلم التعزيز.
عندما يتم تدريب تعلم ما بعد التعزيز بطريقة لا مركزية باستخدام عدد كبير من وحدات معالجة الرسومات ، سيكون للإخراج الفوري الناتج عن النموذج أثناء التدريب أوقات إكمال مختلفة.يعمل Atropos كمعالج بدء ، أي منسق مركزي ، ينسق توليد المهام وإكماله عبر الأجهزة ، وبالتالي تمكين التدريب على التعلم التعزيز غير المتزامن.
تم إصدار الإصدار الأولي من Atropos في أبريل ، ولكنه يحتوي حاليًا على إطار بيئي ينسق مهام التعلم التعزيز.تخطط Nous لإصدار إطار تدريب وتفكير تكميلي في الأشهر المقبلة.
الفكر الرئيسي
خلفية
تأسست Prime Intellect في عام 2024 ، ملتزمة ببناء بنية تحتية لتطوير الذكاء الاصطناعي على نطاق واسع. أسس الفريق في فنسنت فايسر وجوهانس هاجمان ، ركز الفريق في البداية على دمج موارد الحوسبة من مقدمي الخدمات المركزية واللامركزية لدعم التدريب الموزع التعاوني لنماذج الذكاء الاصطناعى المتقدمة.تتمثل مهمة Prime Intellect في إضفاء الطابع الديمقراطي على تنمية الذكاء الاصطناعي ، مما يتيح للباحثين والمطورين في جميع أنحاء العالم الوصول إلى موارد الحوسبة القابلة للتطوير وامتلاك ابتكار الذكاء الاصطناعي المفتوح.
Opendiloco ، intellect-1 و Prime
في يوليو 2024 ، أصدرت Prime Intellect Opendiloco ، وهي نسخة مفتوحة المصدر من Diloco ، وهي طريقة تدريب على نموذج منخفض التواصل تم تطويرها بواسطة Google DeepMind للتدريب الموازي للبيانات. طورت Google النموذج استنادًا إلى الرأي القائل بأن “التدريب من خلال backpropagation القياسية على نطاق حديث يمثل تحديات هندسية وبنية تحتية غير مسبوقة … من الصعب التنسيق ومزامنة عدد كبير من التسارع.”بينما يركز هذا البيان على التطبيق العملي للتدريب على نطاق واسع بدلاً من روح التطوير المفتوح المصدر ، فإنه يتخلف عن قيود التدريب المركزي على المدى الطويل والحاجة إلى البدائل الموزعة.
يقلل Diloco من تواتر وكمية المعلومات المشتركة بين وحدات معالجة الرسومات عند نماذج التدريب.في الإعدادات المركزية ، تشترك وحدات معالجة الرسومات في جميع التدرجات المحدثة مع بعضها البعض بعد كل خطوة من التدريب. في ديلوكو ، يكون تواتر مشاركة تدرجات التحديث أقل لتقليل النفقات العامة للاتصال.هذا يخلق بنية تحسين مزدوجة: تعمل وحدات معالجة الرسومات الفردية (أو مجموعات GPU) على تحسينات داخلية ، وتحديث وزن نماذجها الخاصة بعد كل خطوة ؛والتحسينات الخارجية ، يتم مشاركة التحسينات الداخلية بين وحدات معالجة الرسومات ، ثم يتم تحديث جميع وحدات معالجة الرسومات على أساس التغييرات التي تم إجراؤها.
أظهر Opendiloco 90 ٪ إلى 95 ٪ من استخدام GPU في إطلاقه الأولي ، مما يعني أنه على الرغم من توزيعها في قارتين وثلاث دول ، إلا أن القليل من الآلات خامدة.يمكن لـ Opendiloco إعادة إنتاج نتائج تدريب كبيرة وأداء ، بينما يتم تخفيض حجم حركة المرور بمقدار 500 مرة (كما هو موضح في الخط الأرجواني الذي يلحق بالخط الأزرق في الشكل أدناه).
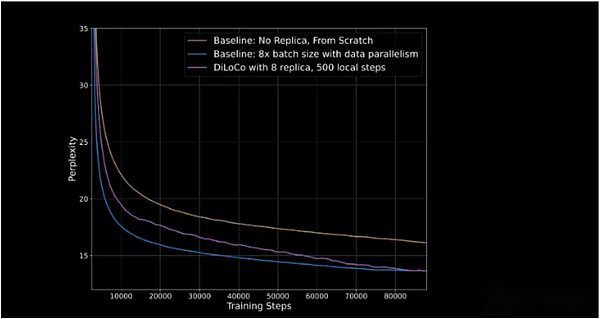
يمثل المحور العمودي الحيرة ، والتي تقيس قدرة النموذج على التنبؤ بالعلامة التالية في تسلسل. كلما انخفضت الحيرة ، كلما كانت تنبؤات النموذج أكثر ثقة ، وكلما زادت الدقة.
في أكتوبر 2024 ، يبدأ Prime Intellect في تدريب الفكر 1، هذا هو أول 10 مليارات نموذج لغة المعلمة المدربين بطريقة موزعة. استغرق التدريب 42 يومًا ، وكان النموذج مفتوحًا بعد ذلك. يتم إجراء التدريب في خمس دول في ثلاث قارات.يوضح تشغيل التدريب التحسن التدريجي للتدريب الموزع ، مع معدل استخدام جميع موارد الحوسبة التي يصل إلى 83 ٪ ، وفي الولايات المتحدة وحدها ، يصل معدل استخدام الاتصالات بين العقد إلى 96 ٪.يأتي وحدة معالجة الرسومات التي يستخدمها هذا المشروع من Web2 و Web3 ، بما في ذلك أسواق GPU Crypto مثل Akash و Virebolic و OLAS.
يتبنى Intellect-1 إطار التدريب الجديد لـ Prime Intellect ، والذي يتيح أنظمة التدريب على الفكر الرئيسي بالتكيف عند حساب التدريب غير المتوقع والخروج من التدريب المستمر.يقدم تقنيات مبتكرة مثل SuperDevicemesh ، مما يسمح للمساهمين بالانضمام أو الخروج في أي وقت.
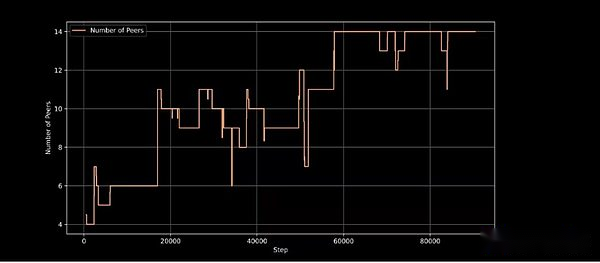
عقد التدريب النشط في خطوة التدريب ، مما يدل على قدرة بنية التدريب على التعامل مع مشاركة العقدة الديناميكية
يعتبر Inflect-1 بمثابة التحقق من صحة نهج التدريب اللامركزي في Prime Intellect ، وقد أشاد به قادة الفكر من الذكاء الاصطناعى مثل جاك كلارك (المؤسس المشارك للأنثروبور) ، ويعتبر عرضًا قابلاً للتطبيق للتدريب اللامركزي.
بروتوكول
في فبراير من هذا العام ، أضافت Prime Intellect طبقة أخرى إلى مكدسها ، مما أدى إلى إطلاق بروتوكول.يربط البروتوكول جميع أدوات التدريب الخاصة بـ Prime Intellect معًا لإنشاء شبكة من نقطة إلى نقطة للتدريب على النماذج اللامركزية.وتشمل هذه:
-
يحسب Switch GPU لتسهيل تشغيل التدريب.
-
إطار التدريب الرئيسي يقلل من الاتصالات العامة ويحسن التسامح مع الأخطاء.
-
مكتبة مفتوحة المصدر تسمى Genesys لتوليد البيانات الاصطناعية المفيدة والتحقق من صحة RL.
-
نظام التحقق خفيف الوزن يسمى TOPLOC للتحقق من صحة إخراج تنفيذ النموذج والعقد المشاركة.
يشبه دور البروتوكول نفسية Nous ، مع أربعة لاعبين رئيسيين:
-
العمال: برنامج يمكّن المستخدمين من المساهمة في موارد الحوسبة في التدريب أو غيرها من المنتجات المتعلقة بالفكر.
-
التحقق: تحقق من المساهمات الحسابية ومنع السلوك الخبيث.تعمل Prime Intellect على تطبيق خوارزمية التحقق من الاستدلال على أحدث طراز على التدريب اللامركزي.
-
Orchestrator: طريقة لحساب المبدعين في المجمعات إدارة العمال.إنه يعمل مشابهًا لـ Nous ‘Orchestrator.
-
العقود الذكية: تتبع مزودي موارد الحوسبة ، وتقليل المراوغة من المشاركين الخبيث ، ودفع المكافآت بشكل مستقل.في الوقت الحالي ، تعمل Prime Intellect على شبكة اختبار Sepolia لقاعدة Ethereum L2 ، لكن Prime Intellect ذكرت أنها ستخطط في النهاية للترحيل إلى blockchain الخاصة بها.
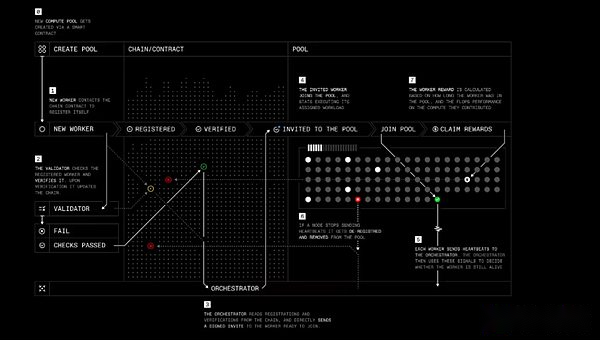 تدريب البروتوكول خطوة بخطوة
تدريب البروتوكول خطوة بخطوة
يهدف البروتوكول إلى السماح للمساهمين في نهاية المطاف بامتلاك الأسهم في النموذج أو تلقي المكافآت لعملهم ، مع توفير مشاريع منظمة العفو الدولية مفتوحة المصدر بطرق جديدة لتمويل وإدارة التطوير من خلال العقود الذكية والحوافز الجماعية.
الفكر 2 والتعلم التعزيز
في أبريل من هذا العام ، بدأ Prime Intellect تدريب نموذج 32 مليار معلمة تسمى Intellect-2.يركز Intellect-1 على تدريب النموذج الأساسي ، بينما يستخدم Intellect-2 التعلم التعزيز لتدريب نماذج الاستدلال على نموذج آخر مفتوح المصدر (QWQ-32B من Alibaba).
قدم الفريق مكونين من البنية التحتية الحاسمة لجعل هذا التدريب اللامركزي RL عمليًا:
-
Prime-RL هو إطار تعلم تعزيز غير متزامن تمامًا يقسم عملية التعلم إلى ثلاث مراحل مستقلة: توليد إجابات مرشح ؛ تدريب الإجابات المختارة ؛ وبث أوزان النموذج المحدثة.تمكن آلية التخلص من النظام هذه الشبكات غير الموثوقة أو البطيئة أو الموزعة جغرافياً.تستخدم عملية التدريب ابتكارًا آخر من Prime Intellect و Genesys ، لتوليد الآلاف من أسئلة الرياضيات والمنطق والترميز ، وهي مجهزة بمدقق تلقائي يمكنه على الفور معرفة ما إذا كانت الإجابة صحيحة أم لا.
-
Shardcast هو نظام جديد لتوزيع الملفات الكبيرة بسرعة (مثل أوزان النماذج المحدثة) على الشبكة.Shardcast لا يقوم كل الجهاز بتنزيل التحديثات من الخادم المركزي ، ولكنه يعتمد هيكلًا يشارك التحديثات بين الآلات.هذا يحافظ على كفاءة الشبكة وسريعة ومرونة.
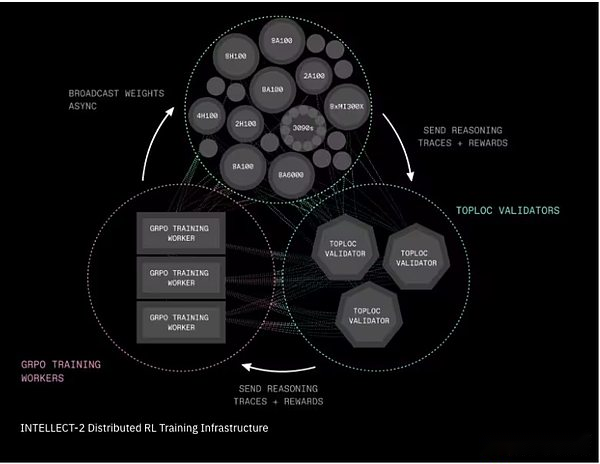 الفكر 2 الموزعة ببنية تحتية لتدريب التعلم التعزيز
الفكر 2 الموزعة ببنية تحتية لتدريب التعلم التعزيز
بالنسبة إلى Intellect-2 ، يحتاج المساهمون أيضًا إلى مشاركة رمز TestNet Crypto للمشاركة في تشغيل التدريب. إذا ساهموا في العمل الفعال ، فسوف يتلقون المكافآت تلقائيًا.إذا لم يكن الأمر كذلك ، فقد يتم قطع الخداع.على الرغم من عدم وجود تمويل فعلي خلال هذا الاختبار ، يبرز هذا الشكل الأولي لبعض التجارب الاقتصادية المشفرة.هناك حاجة إلى مزيد من التجارب في هذا المجال ، ونتوقع المزيد من التغييرات في تطبيق اقتصاد التشفير من حيث آليات الأمن والحوافز.بالإضافة إلى Intellect-2 ، تواصل Prime Intellect تنفيذ العديد من البرامج المهمة غير المشمولة في هذا التقرير ، بما في ذلك:
-
الاصطناعية -2، إطار من الجيل التالي لتوليد ومهام الاستدلال والتحقق منه ؛
-
مكتبة الاتصالات الجماعية الرئيسية، التي تنفذ عمليات الاتصال الجماعية الفعالة التي تتحمل الأخطاء (مثل الحد من IP) ، وتوفر آلية مزامنة الحالة المشتركة للحفاظ على أقرانها متزامنة ، وتسمح بالانضمام الديناميكي وترك أقرانهم في أي وقت أثناء التدريب ، بالإضافة إلى تحسين طوبولوجيا النطاق التلقائي التلقائي ؛
-
يعزز بشكل مستمر وظيفة TopLoc لتمكين أدلة الاستدلال القابلة للتطوير منخفضة التكلفة للتحقق من إخراج النموذج ؛
-
تحسينات على بروتوكول الفكر الرئيسي والاقتصاد التشفير على أساس الدروس المستفادة من Intellect2 و Conthetic1
البحث التعددي
ألكساندر لونج هو باحث في التعلم الآلي الأسترالي مع درجة الدكتوراه من جامعة نيو ساوث ويلز. وهو يعتقد أن التدريب النموذجي مفتوح المصدر يعتمد بشكل مفرط على قيادة مختبرات الذكاء الاصطناعي لتوفير النماذج الأساسية للآخرين للتدريب.في أبريل 2023 ، أسس Pluralis Research ، بهدف فتح مسار مختلف.
تستخدم Pluralis Research مقاربة تسمى “تعلم البروتوكول” لحل مشكلة التدريب اللامركزية ، والتي توصف بأنها “عرض النطاق الترددي المنخفض ، متعددة المشاركين غير المتجانسة ، التدريب الموازي النموذجية والتفكير.”تتمثل الميزة الرئيسية البارزة في Pluralis في نموذجها الاقتصادي ، والذي يوفر مكاسب شبيهة بالأسهم للمساهمين في نماذج التدريب لتحفيز المساهمات الحسابية وجذب الباحثين في البرامج المفتوحة المصدر.يعتمد هذا النموذج الاقتصادي على السمة الأساسية لـ “قابلية الإها”: أي أنه لا يمكن لأي مشارك الحصول على مجموعة كاملة من الأوزان ، والتي ترتبط ارتباطًا وثيقًا باستخدام أساليب التدريب والموازاة النموذجية.
نموذج التوازي
تستخدم بنية تدريب Pluralis النموذجية ، والتي تختلف عن نهج التوازي البيانات الذي تنفذه NOUS Research و Prime Intellect في التدريب الأولي. مع نمو حجم النموذج ، من الصعب حمل رف H100 ، أحد أكثر تكوينات GPU تقدمًا ، نموذجًا كاملاً.يوفر التوازي النموذج حلاً لهذه المشكلة عن طريق تقسيم المكونات الفردية لنموذج واحد على وحدات معالجة الرسومات المتعددة.
هناك ثلاث طرق رئيسية للتوازي النموذج.
-
خط الأنابيب التوازي: تنقسم طبقات النموذج على وحدات معالجة الرسومات المختلفة.أثناء التدريب ، تتدفق كل مجموعة صغيرة من البيانات عبر وحدات معالجة الرسومات هذه مثل خط الأنابيب.
-
التوازي Tensor (الطبقة): بدلاً من توفير الطبقة بأكملها لكل وحدة معالجة الرسومات ، يتم فصل الرياضيات الثقيلة داخل كل طبقة بحيث يمكن لمعالجة وحدات معالجة الرسومات المتعددة مشاركة عمل طبقة واحدة في نفس الوقت.
-
مختلط بالتوازي: في الممارسة العملية ، تستخدم النماذج الكبيرة طرقًا مختلفة ، باستخدام خطوط الأنابيب والتوتر بالتوازي ، وعادة ما يكون بالتزامن مع البيانات.
يعد التوازي النموذجي تقدمًا مهمًا في التدريب الموزع لأنه يسمح بتدريب النماذج المتطورة على نطاق الحافة ، مما يسمح للأجهزة ذات المستوى الأدنى بالمشاركة ، وضمان عدم إمكانية الوصول إلى مجموعة كاملة من أوزان النماذج.
نماذج تعلم البروتوكول وبروتوكول
تعلم البروتوكول هو إطار للتعددية لاستخدام ملكية النماذج والتحميمة في بيئة تدريب لا مركزية. يسلط Pluralis الضوء على ثلاثة مبادئ رئيسية تشكل إطار تعلم البروتوكول – التجديف المركزي ، والتحفيز والخروج.
الفرق الرئيسي بين Pluralis والمشاريع الأخرى هو تركيزها على ملكية النموذج.بالنظر إلى أن قيمة النموذج ترجع بشكل رئيسي إلى وزنه ، نموذج البروتوكول (نماذج البروتوكول) حاول تقسيم أوزان النموذج بحيث لا يمكن لأي مشارك واحد أثناء عملية التدريب النموذجية أن يكون له أوزان كاملة.في النهاية ، سيعطي هذا كل مساهم في نموذج التدريب ملكية معينة ، وبالتالي مشاركة الفوائد الناتجة عن النموذج.
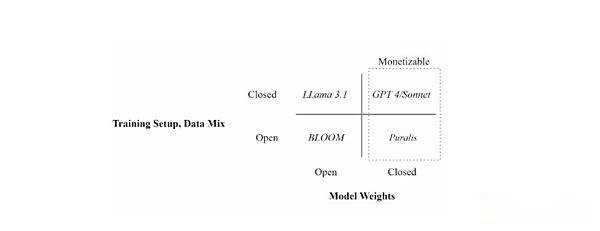 ضع نماذج لغوية مختلفة من خلال إعدادات التدريب (مفتوحة مقابل البيانات المرفقة) وتوافر وزن النموذج (مفتوح مقابل مرفق)
ضع نماذج لغوية مختلفة من خلال إعدادات التدريب (مفتوحة مقابل البيانات المرفقة) وتوافر وزن النموذج (مفتوح مقابل مرفق)
هذا هو نهج مختلف اختلافًا أساسيًا لاقتصاديات النماذج اللامركزية مقارنة بالأمثلة السابقة. تحفز المشاريع الأخرى المساهمات من خلال توفير تجمع تمويل يتم تخصيصه للمساهمين خلال دورة التدريب بناءً على مقاييس محددة (عادة ما يتم ساهم في الوقت أو قوة الحوسبة).يتم تحفيز المساهمين في Pluralis لتكريس الموارد فقط للنماذج التي يعتقدون أنها على الأرجح أن تنجح.إن تدريب النموذج الذي يتم تنفيذه سيئًا سيؤدي إلى إهدار قوة الحوسبة والطاقة والوقت لأن النماذج التي يتم تنفيذها بشكل سيء لن تؤدي إلى تحقيق أي إيرادات.
هذا يختلف عن الطريقة السابقة.أولاً ، لا يتطلب الأمر الأفراد الذين يرغبون في تدريب النموذج لجمع الأموال الأولية لدفع المساهمين ، وبالتالي خفض العتبة للتدريب والتطوير النموذجي.ثانياً ، ينسق بشكل أفضل آليات الحوافز بين مصممي النماذج ومقدمي الحوسبة ، حيث يريد كلا الطرفين أن تكون النسخة النهائية من النموذج مثالية قدر الإمكان لضمان نجاحها.هذا يوفر أيضًا إمكانية ظهور تخصص التدريب النموذجي.على سبيل المثال ، قد يكون هناك مدربون أكثر حملًا للمخاطر الذين يقدمون خدمات الحوسبة للنماذج المبكرة/التجريبية بحثًا عن عائدات أكبر (على غرار أصحاب رأس المال الاستثماري) ، بينما يركز مقدمو الحوسبة فقط على أولئك الناضجين والأكثر احتمالًا للتطبيق (على غرار مستثمري الأسهم الخاصة).
في حين أن PM قد يمثل اختراقًا كبيرًا في تسييل وآليات الحوافز للتدريب اللامركزي ، إلا أن Pluralis لم تشرح على أساليب تنفيذها المحددة.بالنظر إلى التعقيد العالي لهذا النهج ، تتضمن القضايا التي لم يتم معالجتها بعد كيفية تخصيص ملكية النموذج ، وكيفية تخصيص الفوائد ، وحتى كيفية إدارة الترقيات المستقبلية أو استخدام حالات النموذج.
الابتكار التدريبي اللامركزي
بالإضافة إلى الاعتبارات الاقتصادية ، يواجه تعلم البروتوكول نفس التحدي الأساسي مثل برامج التدريب اللامركزية الأخرى ، باستخدام شبكات GPU غير المتجانسة مع قيود الاتصالات لتدريب نماذج AI الكبيرة.
في يونيو من هذا العام ، أعلنت Pluralis عن التدريب الناجح البالغ 8 مليارات معلمة LLM استنادًا إلى Architecture Llama 3 Meta ونشرت ورقة طراز البروتوكول.في الورقة ، يوضح Pluralis كيفية تقليل النفقات العامة للاتصال بين وحدات معالجة الرسومات التي تؤدي تدريبًا متوازيًا النموذج.يقوم بذلك عن طريق الحد من الإشارات التي تتدفق عبر كل طبقة محول إلى مساحة فرعية صغيرة تم اختيارها مسبقًا ، حيث يمر ضغط إلى الأمام والخلف إلى 99 ٪ ، مما يقلل من حركة الشبكة بمقدار 100 مرة دون المساس بالدقة أو إضافة النفقات العامة الكبيرة.باختصار ، وجدت Pluralis طريقة لضغط نفس معلومات التعلم إلى جزء صغير من عرض النطاق الترددي المطلوب بالطرق السابقة.
هذا هو أول تشغيل تدريبي لا مركزي ، ويتم تفريق النموذج نفسه على العقد المتصلة من خلال عرض النطاق الترددي المنخفض بدلاً من النسخ المتماثل.قام الفريق بنجاح بتدريب نموذج LLAMA مع 8 مليارات من المعلمات على وحدات معالجة الرسومات المنخفضة من الدرجة المستهلك المنتشر عبر أربع قارات لا تتصل إلا من خلال 80 ميغابايت في الثانية من اتصال الإنترنت في اليوم.في الورقة ، يوضح Pluralis أن تقارب هذا النموذج جيد مثل تشغيل مجموعة مركز بيانات 100 جيجابايت/ثانية.في الممارسة العملية ، هذا يعني أن التدريب اللامركزي المتوازي للنماذج واسعة النطاق أصبح الآن ممكنًا.
أخيرًا ، تم استلام ورقة من Pluralis على التدريب غير المتزامن للتدريب الموازي لخط الأنابيب بواسطة ICML (أحد مؤتمرات الذكاء الاصطناعي الرائدة) في يوليو.عندما يتم تنفيذ التدريب الموازي لخط الأنابيب عبر الإنترنت بدلاً من مراكز البيانات عالية السرعة ، فإنه يواجه أيضًا عنق الزجاجة التواصل لأن العقد تعمل في خطوط أنابيب بشكل أساسي ، مع كل عقدة متتالية تنتظر العقد السابقة لتحديث النموذج.هذا يمكن أن يؤدي إلى انتقال المعلومات عفا عليها الزمن وتأخر.إطار التدريب اللامركزي الذي تم توضيحه في الورقة ، Swarm ، يلغي اثنين من الاختناقات الكلاسيكية التي تعيق عادة مشاركة GPU اليومية في التدريب: قدرة الذاكرة والمزامنة الضيقة.يمكن أن يؤدي التخلص من هاتين الاختناقين إلى الاستفادة بشكل أفضل من جميع وحدات معالجة الرسومات المتاحة ، وتقليل وقت التدريب وتقليل التكاليف ، وهو أمر بالغ الأهمية لتوسيع نطاق النماذج الكبيرة مع البنية التحتية القائمة على المتطوعين الموزعة.لإلقاء نظرة قصيرة على هذه العملية ، شاهد هذا الفيديو بواسطة Pluralis.
بالنظر إلى المستقبل ، تقول Pluralis إنها تخطط لإطلاق تدريب في الوقت الفعلي يمكن لأي شخص المشاركة فيه قريبًا ، ولكن لم يتم تحديد تاريخ محدد.سيوفر الإطلاق فهمًا أعمق لجوانب الاتفاقية التي لم يتم إصدارها بعد ، وخاصة النماذج الاقتصادية والبنية التحتية للتشفير.
تمبلار
خلفية
تم إطلاق Templar في نوفمبر 2024 وهو سوق مهام منظمة العفو الدولية التي تعتمد على الحوافز بناءً على الشبكة الفرعية للبروتوكول.لقد بدأ الأمر كإطار تجريبي يهدف إلى الجمع بين موارد GPU العالمية من أجل التدريب المسبق لوكالة الذكاء الاصطناعى الخالية من الترخيص ، ويهدف إلى جعل التدريب على نطاق واسع يمكن الوصول إليه وآمنة ومرونة من خلال الحوافز الرمزية لـ Bittensor ، وبالتالي إعادة تعريف تطوير الذكاء الاصطناعي.
منذ البداية ، واجه تمبلار التحدي المتمثل في تنسيق التدريب اللامركزي للتدريب قبل التدريب على الإنترنت.هذه مهمة صعبة ، حيث أن القيود المفروضة على نطاق النطاق الترددي ، والأجهزة غير المتجانسة ، تجعل من الصعب على الممثلين الموزعة تحقيق كفاءة المجموعات المركزية ، والاتصالات السلس GPU من المجموعات المركزية تتيح التكرار السريع للنماذج الضخمة.
الأهم من ذلك ، يعطي تمبلار الأولوية للمشاركة المرخصة حقًا ، مما يسمح لأي شخص لديه موارد الحوسبة بالمشاركة في تدريب الذكاء الاصطناعي دون موافقة أو تسجيل أو الحفاظ على البوابة.يعد هذا النهج بدون إذن أمرًا بالغ الأهمية لمهمة Templar إلى تقديم ديمقراطية تنمية الذكاء الاصطناعي ، حيث يضمن عدم السيطرة على قدرات AI اختراق من قبل عدد قليل من الكيانات المركزية ولكن يمكن أن تنشأ من التعاون المفتوح في جميع أنحاء العالم.
تمبلاريدرب
يستخدم Templar البيانات للتدريب بالتوازي ، وهناك عاملان رئيسيان:
-
عامل منجم:قام هؤلاء المشاركون بمهام التدريب.يتزامن كل عامل منجم مع أحدث طراز عالمي ، ويحصل على شظايا بيانات فريدة من نوعها ، ويتدرب محليًا باستخدام تمريرات الأمام والخلف ، ويضغط التدرجات باستخدام مُحسّن CCLOCO مخصص (الموضح أدناه) ، ويقوم بتقديم تحديثات التدرج.
-
Verifier: يقوم المدقق بتنزيل وإلغاء ضغط التحديث المقدم من عمال المناجم ، ويطبقه على النسخة المحلية من النموذج ، ويحسبزيادة الخسارة(المؤشرات التي تقيس درجة تحسين النموذج).تُستخدم هذه الزيادات لتسجيل مساهمات عمال المناجم من خلال نظام القفاز في تمبلار.
لتقليل النفقات العامة للاتصالات ، طور فريق أبحاث Templar أولاً ضغط البلوك Diloco (CCLOCO).على غرار NOUS ، تعمل CCLOCO على تحسين تقنيات التدريب الفعالة للاتصالات مثل إطار عمل Google Diloco ، مما يقلل من تكاليف الاتصال بين العقدة حسب أوامر الحجم مع تقليل الخسائر التي تسببها هذه الطرق غالبًا.بدلاً من إرسال التحديثات الكاملة في كل خطوة ، تشارك CCLOCO فقط أهم التغييرات على فترات محددة ويحتفظ بعدد تشغيل صغير للتأكد من عدم فقدان أي بيانات ذات معنى.يتبنى النظام نموذجًا قائمًا على المنافسة يحفز عمال المناجم لتوفير تحديثات منخفضة الكلية لتلقي المكافآت.لتلقي المكافآت ، يجب على عمال المناجم مواكبة الشبكة من خلال نشر أجهزة فعالة.تم تصميم هذا الهيكل التنافسي لضمان أن المشاركين الذين يحتفظون بالأداء الكافي يمكنهم المشاركة في عملية التدريب ، في حين يقوم فحص الصرف الصحي الخفيف بالتصفية تحديثات سيئة أو مشوهة بشكل ملحوظ.في أغسطس ، أصدر تيمبلار رسميًا بنية التدريب المحدثة وأطلق عليها اسم SPARSELOCO.
تستخدم Verifiers نظام Templar’s Gauntlet لتتبع وتحديث تصنيف مهارات كل عامل من عماره استنادًا إلى مساهمات تخفيض فقدان النماذج المرصودة.من خلال التكنولوجيا التي تسمى OpenSkill ، سيتلقى عمال المناجم عالية الجودة الذين لا يزالون يتم تحديثهم بفعالية تقييمات مهارة أعلى ، مما يزيد من تأثيرهم على تجميع النماذج وكسب المزيد من TAOS (الرموز المحلية لشبكة Bittensor).سيتم التخلص من عمال المناجم مع تصنيفات أقل أثناء عملية التجميع.بعد التسجيل ، سيقوم المدققون الذين لديهم أعلى تعهد بتلخيص التحديثات من أفضل عمال المناجم ، وتوقيع النموذج العالمي الجديد ، ونشره للتخزين.إذا كان النموذج غير متزامن ، فيمكن لعملين استخدام هذا الإصدار من النموذج للحاق بالركب.
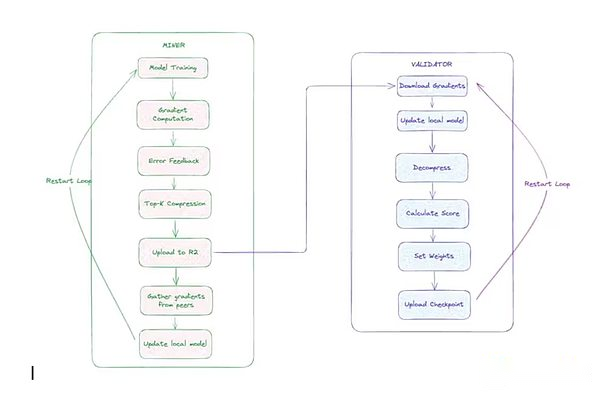 هندسة التدريب اللامركزية الهيكل
هندسة التدريب اللامركزية الهيكل
بدأ تمبلار ثلاث جولات من التدريب حتى الآن: تمبلار الأول ، تيمبلار الثاني وتيمبلار الثالث.Templar I هو نموذج مع 1.2 مليار معلمة ، ينشر ما يقرب من 200 وحدات معالجة الرسومات في جميع أنحاء العالم.تم التقدم في Templar II ، حيث يقوم بتدريب نموذج مع 8 مليارات معلمات ، والتخطيط لبدء تدريب أكبر قريبًا.تركز Templar حاليًا على نماذج التدريب ذات المعلمات الأصغر ، وهو خيار مدروس جيدًا مصمم لضمان أن الترقيات إلى بنية التدريب اللامركزية (كما هو مذكور أعلاه) يمكن أن تعمل بشكل فعال قبل التحجيم إلى موازين النماذج الأكبر.من استراتيجيات التحسين والجدولة إلى التكرارات والحوافز البحثية ، يتم التحقق من صحة هذه الأفكار على 8 مليارات نماذج ذات معلمات أصغر ، مما يسمح للفرق بالتكرار بسرعة وفعالية من حيث التكلفة.بعد التقدم الأخير والإصدار الرسمي للهندسة المعمارية التدريبية ، أطلق الفريق Templar III في سبتمبر ، وهو نموذج يحتوي على 70 مليار معلمة وأكبر التدريب قبل التدريب في المجال اللامركزي حتى الآن.
آليات تاو وآليات الحوافز
الميزة الرئيسية لـ Templar هي نموذج الحوافز المرتبط بـ TAO. يتم تخصيص المكافآت بناءً على المساهمات الموزونة المهارة التي تدربها النموذج.تحتوي معظم البروتوكولات (مثل Pluralis ، Nous ، Prime Intellect) على أشواط أو نماذج أولية ، بينما يعمل Templar بالكامل على شبكة Bittensor في الوقت الفعلي.هذا يجعل Templar هو البروتوكول الوحيد الذي دمج طبقة اقتصادية في الوقت الفعلي الخالي من الترخيص في إطار التدريب اللامركزي.يتيح نشر الإنتاج في الوقت الفعلي هذا Templar تكرار البنية التحتية في سيناريوهات تشغيل التدريب في الوقت الفعلي.
تعمل كل شبكة فرعية Bittensor مع رمزها “ألفا” الخاص بها ، والتي تعمل كإشارة سوق لآلية المكافآت والشبكات الفرعية لإدراك القيمة. يسمى رمز ألفا تيمبلار جاما.لا يمكن تداول رموز ألفا بحرية على الأسواق الخارجية ؛لا يمكن تبادلها إلا مع TAOS من خلال مجموعة سيولة مخصصة للشبكة الفرعية الخاصة بهم باستخدام صانع السوق الآلي (AMM).يمكن للمستخدمين تعهد TAO بالحصول على جاما ، أو استرداد جاما كـ TAO ، لكنهم لا يستطيعون تبادل غاما مباشرة لرموز ألفا من شبكات فرعية أخرى.يستخدم نظام Bittensor Dynamic TAO (DTAO) سعر السوق لرموز ألفا لتحديد تخصيصات الإصدار بين الشبكات الفرعية.عندما يرتفع سعر جاما بالنسبة لرموز ألفا الأخرى ، يشير هذا إلى أن ثقة السوق في قدرات التدريب اللامركزية في السوق قد زادت ، مما أدى إلى زيادة في إصدار TAO للشبكة الفرعية.اعتبارًا من أوائل سبتمبر ، شكلت الإصدار اليومي لتيبلار حوالي 4 ٪ من تداول تاو ، حيث احتلت المرتبة الستة الأولى من بين 128 شبكة فرعية لشبكة TAO.
آلية إصدار الشبكة الفرعية هي كما يلي: في كل كتلة مكونة من 12 ثانية ، ستصدر سلسلة Bittensor الرموز المميزة Tao و Alpha إلى مجموعة السيولة الخاصة بها بناءً على نسبة سعر الرموز الفورية الشبكة الفرعية بالنسبة إلى الشبكات الفرعية الأخرى.كل كتلة تصل إلى رمز ألفا كامل إلى الشبكة الفرعية (معدل الإصدار الأولي ، والذي قد يكون إلى النصف) إلى الشبكة الفرعية لتحفيز المساهمين في الشبكة الفرعية ، منها 41 ٪ منهم تخصيص عمال المناجم ، و 41 ٪ مخصصة لمقدين (وأصحاب المصلحة) ، و 18 ٪ مخصصة لمالكي الفرعية.
يدفع هذا الحافز المساهمة في شبكة Bittensor من خلال ربط المكافآت الاقتصادية بالقيمة التي يوفرها المشاركون.يتم تحفيز عمال المناجم لتوفير مخرجات AI عالية الجودة ، مثل تدريب النماذج أو مهام الاستدلال ، للحصول على تقييمات أعلى من المدققين وبالتالي حصة أكبر من الإنتاج.تتلقى Verifiers (و Stakers) مكافآت لتقييم وصيانة سلامة الشبكة بدقة.
يتم تحديد تقييم السوق لرموز Alpha من خلال أنشطة Staking ، مما يضمن أن الشبكات الفرعية التي تظهر تنظيمًا عمليًا أعلى يمكن أن تجذب المزيد من التدفقات والإصدار TAO ، وبالتالي خلق بيئة تنافسية تشجع على الابتكار والتخصص والتنمية المستدامة.سيحصل مالكو الشبكة الفرعية على نسبة مئوية من المكافآت ، والتي يتم تحفيزها لتصميم آليات فعالة وجذب المساهمين ، وفي نهاية المطاف بناء نظام بيئي لا مركزي بدون إذن يتيح المشاركة العالمية تعزيز تقدم الذكاء الجماعي بشكل مشترك.
تقدم الآلية أيضًا تحديات حافز جديدة مثل الحفاظ على صدق المدققين ، ومقاومة هجمات الساحرة ، وتقليل المؤامرة.غالبًا ما تكون الشبكات الفرعية لـ Bittensor مضطربًا من خلال ألعاب القطط والفأر بين المدققين أو عمال المناجم ومبدعي الشبكة الفرعية ، والمحاولة الأولى في اللعب مع النظام والأخير الذي يحاول إعاقةهم.على المدى الطويل ، يجب أن تجعل هذه النضالات النظام من أقوى النضالات حيث يتعلم مالكو الشبكة الفرعية كيفية التغلب على الجهات الفاعلة الضارة.
جينسين
أصدرت Gensyn أول ورقة بيضاء مبسطة في فبراير 2022 ، وتوضيح إطار التدريب اللامركزي (Gensyn هو بروتوكول التدريب اللامركزي الوحيد المغطى في مقالنا الأول العام الماضي حول فهم تقاطع تكنولوجيا التشفير والذكاء الاصطناعي).في ذلك الوقت ، ركز البروتوكول بشكل أساسي على التحقق من أعباء العمل المتعلقة بالنيابة ، مما يسمح للمستخدمين بتقديم طلبات التدريب إلى الشبكة ، ومعالجتها من قبل مزود الحوسبة ، والتأكد من تنفيذ هذه الطلبات كما وعدت.
أبرزت الرؤية الأولية أيضًا الحاجة إلى تسريع أبحاث التعلم الآلي التطبيقي (ML).في عام 2023 ، تعتمد Gensyn على هذه الرؤية لاقتراح حاجة أوسع لاكتساب موارد الحوسبة في التعلم الآلي في جميع أنحاء العالم لخدمة تطبيقات الذكاء الاصطناعي المحددة.قدمت Gensyn المبدأ الشبحي كإطار يجب أن تلبيه مثل هذه البروتوكولات: عالمية ، عدم التجانس ، النفقات العامة ، قابلية التوسع ، الثقة ، والكمون.يركز Gensyn على بناء البنية التحتية للحوسبة ، ويمثل التعاون التوسع الرسمي مع الموارد الرئيسية الأخرى التي تتجاوز الحوسبة.
يقسم Gensyn’s Core كومة تقنية التدريب الخاصة بها إلى أربعة أجزاء مميزة – تنفيذ ، والتحقق ، والاتصال ، والتنسيق.جزء التنفيذ مسؤول عن التعامل مع العمليات على أي جهاز في العالم يمكنه إجراء عمليات التعلم الآلي.يمكّن قسم الاتصال والتنسيق الأجهزة من إرسال المعلومات إلى بعضها البعض بطريقة موحدة.يضمن قسم التحقق أنه يمكن حساب جميع العمليات دون ثقة.
التنفيذ – سرب RL
إن تطبيق Gensyn الأول على هذا المكدس هو نظام تدريبي يسمى RL Swarm ، وهي آلية تنسيق لا مركزية للتعلم بعد التدريب.
تم تصميم RL Swarm للسماح لمقدمي الحوسبة المتعددين بالمشاركة في تدريب نموذج واحد في بيئة عديمة الإذن وذات الثقة.يعتمد البروتوكول على دورة من ثلاث خطوات: الرد والمراجعة والحل. أولاً ، يقوم كل مشارك بإنشاء إخراج النموذج (الإجابة) بناءً على المطالبة.ثم قام المشاركون الآخرون بتقييم الإخراج باستخدام وظيفة مكافأة مشتركة وردود الفعل المقدمة (مراجعة).أخيرًا ، سيتم استخدام هذه المراجعات لتحديد أفضل إجابة وإدراجها في الإصدار التالي من النموذج (حل).تتم العملية بأكملها بطريقة من نقطة إلى نقطة دون الاعتماد على خادم مركزي أو مؤسسة موثوق بها.
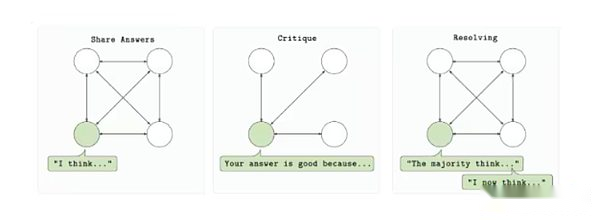 حلقة تدريب RL Swarm
حلقة تدريب RL Swarm
يعتمد سرب التعلم التعزيز على الأهمية المتزايدة للتعلم التعزيز في تدريب ما بعد الطراز. مع وصول النموذج إلى الحد الأعلى للمقياس في مرحلة ما قبل التدريب ، يوفر التعلم التعزيز آلية لتحسين قدرة الاستدلال وقدرة الامتثال للتعليمات والواقعية دون إعادة التدريب على مجموعات البيانات الضخمة.يحقق نظام Gensyn هذا التحسن في بيئة لا مركزية من خلال تحطيم حلقات التعلم التعزيز إلى أدوار مختلفة ، يمكن التحقق من كل دور بشكل مستقل.من الأهمية بمكان ، أنه يقدم التنفيذ غير المتزامن الذي يتحمل الأخطاء ، مما يعني أن المساهمين لا يحتاجون إلى أن يكونوا عبر الإنترنت أو يظلون متزامنين تمامًا للمشاركة.
كما أنه معياري في الطبيعة.لا يتطلب النظام استخدام بنية نموذجية محددة أو نوع بيانات أو بنية المكافأة ، مما يسمح للمطورين بتخصيص حلقات التدريب بناءً على حالات الاستخدام المحددة الخاصة بهم.سواء أكان ذلك نماذج ترميز التدريب أو عوامل الاستدلال أو النماذج التي تحتوي على مجموعات تعليمية محددة ، فإن RL Swarm يوفر إطار عمل موثوق به على نطاق واسع لسير عمل RL اللامركزية.
فيردي
حتى الآن ، فإن أحد الجوانب الأقل مناقشة في هذا التقرير حول التدريب اللامركزي هو التحقق. تبني Gensyn طبقة Verde Trust لسوق GPU.مع Verde ، قدم Gensyn آلية التحقق الجديدة حتى يتمكن مستخدمو البروتوكول من الوثوق بالأشخاص على الجانب الآخر من الموقف يفعلون ما يقولون.
يتم جدولة كل مهمة تدريب أو استنتاج إلى عدد معين من مقدمي الخدمات المستقلين التي يحددها التطبيق.إذا كان إخراجهم يتطابق تمامًا ، يتم قبول المهمة.إذا كانت المخرجات مختلفة ، يحدد بروتوكول الحكم الخطوة الأولى التي يتم فيها تباعد المسارين وإعادة حساب العملية فقط.يحتفظ الحزب الذي يتطابق مع رقمه بالحكم ، بينما يفقد الطرف الآخر مصالحه.
ما يجعل هذا ممكنًا هو إعادة النية ، وهي مكتبة من “المشغلين القابلة للتكرار” التي تجبر عمليات رياضيات الشبكة العصبية المشتركة (مضاعفة المصفوفة ، والتنشيط ، وما إلى ذلك) على التشغيل بترتيب ثابت وحتمي على أي وحدة معالجة الرسومات.الحتمية أمر بالغ الأهمية هنا ؛خلاف ذلك ، على الرغم من أن كلا من المدققين صحيحة ، إلا أنهما قد ينتجا نتائج مختلفة.لذلك سيوفر مقدمو الخدمات الصادقين نفس النتيجة شيئًا فشيئًا ، مما يسمح لـ Verde برؤية اللعبة كدليل على الصواب.نظرًا لأن الحكام يعيد فقط microstep ، التكلفة المضافة ليست سوى نقاط مئوية قليلة ، بدلاً من النفقات العامة التي تبلغ مساحتها 10000 مرة لإثبات التشفير الكامل المستخدمة عادة في هذه العمليات.
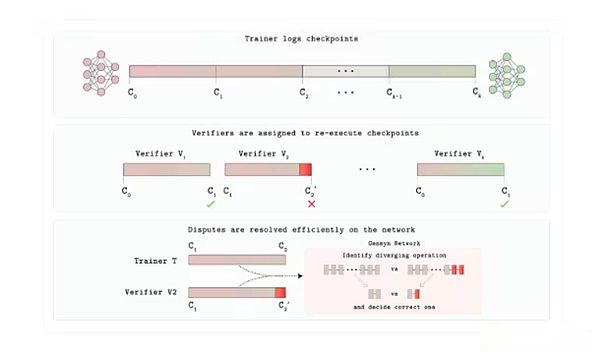
هندسة بروتوكول التحقق من Verde
في أغسطس / آب ، أصدر جينسين القاضي ، وهو نظام تقييم AI يمكن التحقق منه يحتوي على مكونين أساسيين: Verde ووقت تشغيل قابل للتكرار ، والذي يضمن البطن بنفس النتيجة عبر الأجهزة.لإظهار ذلك ، أطلقت Gensyn لعبة “Game Progressive Dex” التي تراهن فيها نماذج الذكاء الاصطناعى على إجابات على الأسئلة المعقدة أثناء الوحي المعلومات ، ويؤكد القاضي بشكل حتمي النتائج ومكافآت التنبؤات المبكرة الدقيقة.
القاضي مهم لأنه يحل قضايا الثقة وقابلية التوسع في الذكاء الاصطناعي/مل.إنه يتيح مقارنات موثوقة للنماذج ، وتحسين الشفافية في البيئات عالية الخطورة ، ويقلل من خطر التحيز أو التلاعب من خلال السماح بالتحقق المستقل.بالإضافة إلى مهام الاستدلال ، يمكن للقاضي أن يدعم قضايا الاستخدام الأخرى مثل تسوية النزاعات اللامركزية والتنبؤ ، والتي تناسب مهمة Gensyn لبناء بنية تحتية موثوقة موزع من الذكاء الاصطناعي.في نهاية المطاف ، يمكن أن تعزز أدوات مثل القاضي التكرار والمساءلة ، وهو أمر بالغ الأهمية في عصر يكون فيه الذكاء الاصطناعى في قلب المجتمع بشكل متزايد.
التواصل والتنسيق: تكامل خبراء التخطي والتنوع
Skip-pipe هو حل من Gensyn لمعالجة مشكلة عنق الزجاجة النطاق الترددي التي يحدث نموذج واحد Megamo عند التقطيع على آلات متعددة.كما ذكرنا سابقًا ، فإن تدريب خطوط الأنابيب التقليدية يجبر كل صورة ميكروبات لاجتياز جميع الطبقات بالتسلسل ، وبالتالي فإن أي عقدة أبطأ ستؤدي إلى ركود خط الأنابيب.يمكن لجدولة Skip-pipe تخطي أو إعادة ترتيب الطبقات التي يمكن أن تسبب تأخيرًا ، مما يقلل من أوقات التكرار بنسبة تصل إلى 55 ٪ والحفاظ على التوفر حتى عند فشل نصف العقد.من خلال تقليل حركة المرور بين العدوى والسماح بإزالة الطبقات حسب الحاجة ، فإنه يمكّن المدرب من توسيع نطاق نماذج كبيرة جدًا إلى وحدات معالجة الرسومات الجغرافية المنخفضة النطاق الترددي.
تكامل الخبراء المتنوع يحل لغز تنسيق آخر: كيفية بناء نظام “خبير مختلط” قوي يتجنب الحديث المتبادل المستمر.يدرب كل نموذج خبير في Gensyn’s غير المتجانسة (HDEE) كل نموذج خبير بشكل مستقل تمامًا ولا يندمج إلا في النهاية.والمثير للدهشة ، في ظل نفس ميزانية الحوسبة الإجمالية ، تجاوز التكامل النهائي في 20 من بين 21 منطقة اختبار معيارًا موحدًا.نظرًا لعدم وجود التدرج أو تدفق وظائف التنشيط بين الآلات أثناء التدريب ، يمكن لأي وحدة معالجة الرسومات الخاملة أن تسهم في قوة الحوسبة.
Skip-Pipe و HDE معًا يوفران Gensyn حل اتصال فعال. يمكن للبروتوكول أن يقشر داخل نموذج واحد إذا لزم الأمر ، أو تدريب العديد من الخبراء الصغار بالتوازي مع انخفاض تكاليف الاستقلال دون تشغيل شبكة الكمون المثالية المنخفضة كما هو مستخدم تقليديًا.
شبكة الاختبار
في مارس ، نشرت Gensyn testnet على رول Ethereum مخصص.يخطط الفريق لتحديث شبكة الاختبار تدريجياً.في الوقت الحالي ، يمكن للمستخدمين المشاركة في منتجات Gensyn الثلاثة: RL Swarm و Blockassist و Judge. كما ذكر أعلاه ، يتيح RL Swarm للمستخدمين المشاركة في عمليات التدريب بعد RL.في أغسطس ، أطلق الفريق Blockassist ، “هذا هو أول مظاهرة واسعة النطاق للتعلم بمساعدة ، وهي وسيلة لتدريب الوكلاء مباشرة من السلوك البشري دون وضع العلامات اليدوية أو RLHF.”يمكن للمستخدمين تنزيل Minecraft واستخدام blockassist لتدريب طرز Minecraft للعب اللعبة.
مشاريع أخرى تستحق الاهتمام
تحدد الفصول المذكورة أعلاه الهندسة المعمارية السائدة التي تم تنفيذها لتحقيق التدريب اللامركزي.ومع ذلك ، فإن المشاريع الجديدة تظهر واحدة تلو الأخرى.فيما يلي بعض المشاريع الجديدة في مجال التدريب اللامركزي:
Fortytwo: تم بناء FortyTwo على Monad blockchain ويركز على التفكير الجماعي (SLM) ، حيث تتعاون نماذج لغة صغيرة متعددة (SLMs) في الاستعلامات في شبكة العقدة وتولد مخرجات مراجعة من النظراء ، وبالتالي تحسين الدقة والكفاءة.يستخدم النظام أجهزة على مستوى المستهلك مثل أجهزة الكمبيوتر المحمولة الخاملة ، مما يلغي الحاجة إلى استخدام مجموعات GPU باهظة الثمن مثل AI المركزية.تتضمن الهندسة المعمارية وظائف تنفيذ وتدريب الاستدلال اللامركزي ، مثل إنشاء مجموعات بيانات اصطناعية للنماذج المخصصة.المشروع متاح الآن على شبكة تطوير موناد.
المحيط: Ambient هو “إثبات العمل المفيد” القادم Layer-1 blockchain ، المصمم لدعم وكلاء الذكاء الاصطناعى ذاتيا ، مستقلًا دائمًا على السلسلة ، مما يتيح لهم أداء المهام والتعلم والتطور بشكل مستمر في نظام بيئي بدون إذن دون إشراف مركزي.سيعتمد نموذجًا واحدًا مفتوح المصدر مدرب وتحسين من قبل عمال مناجم الشبكة بشكل تعاوني ، وسيتم مكافأة المساهمين على مساهماتهم في التدريب وبناء واستخدام نماذج الذكاء الاصطناعي.على الرغم من أن المحيط يؤكد على التفكير اللامركزي ، خاصة في جانب الوكيل ، فإن عمال المناجم على الشبكة سيكونون أيضًا مسؤولين عن تحديث النماذج الأساسية التي تدعم الشبكة باستمرار.يستخدم Ambient آلية جديدة من السطح (في هذا النظام ، يمكن للمقدين التحقق من أن حسابات النموذج يتم تشغيلها بشكل صحيح عن طريق التحقق من قيمة الإخراج الأصلية للمناجم (تسمى Logits). تم بناء المشروع على شوكة من Solana ولم يتم إطلاقه رسميًا بعد.
مختبرات الزهور: تقوم Flower Labs بتطوير إطار مفتوح المصدر للتعلم الموحد ، Flower ، الذي يدعم تدريب نموذج AI التعاوني عبر مصادر البيانات اللامركزية دون مشاركة البيانات الأولية ، وبالتالي حماية الخصوصية مع تجميع تحديثات النموذج. تأسست Flower لمعالجة مركزية البيانات ، مما يسمح للمؤسسات والأفراد بتدريب النماذج باستخدام البيانات المحلية ، مثل الرعاية الصحية أو التمويل ، مع المساهمة في التحسينات العالمية من خلال المشاركة الآمنة للمعلمات. على عكس بروتوكولات التشفير الأصلية التي تؤكد على المكافآت الرمزية والحوسبة التي يمكن التحقق منها ، يعطي Flower الأولوية للتعاون الذي يحمي الخصوصية في تطبيقات العالم الحقيقي ، مما يجعلها خيارًا مثاليًا للصناعات الخاضعة للتنظيم دون blockchain.
macrocosmos: يعمل Macrocosmos على شبكة Bittensor ويقوم بتطوير عملية إنشاء نموذج AI كاملة تغطي خمس شبكات فرعية تركز على التدريب قبل التدريب ، والضبط ، وجمع البيانات ، والعلوم اللامركزية.يقدم إطارًا لعمارة تدريب الحوافز (IOTA) لنماذج اللغة الكبيرة المسبقة على أجهزة غير متجانسة وغير موثوقة وخالية من الترخيص ، وبدأت أكثر من مليار من التدريبات المعلمة وخطط لتوسيع نطاق نماذج معلمات أكبر بسرعة.
Flock.io: Flock هو نظام بيئي لتدريب AI اللامركزي الذي يجمع بين التعلم الموحدة والبنية التحتية blockchain لتحقيق تطوير النموذج التعاوني لحماية الخصوصية في شبكة معيارية محلية. يمكن للمشاركين المساهمة في النماذج أو البيانات أو موارد الحوسبة وتلقي المكافآت الموجودة على السلسلة بما يتناسب مع مساهماتهم.لحماية خصوصية البيانات ، يتبنى البروتوكول التعلم الفدرالي.يتيح ذلك للمشاركين تدريب النماذج العالمية باستخدام البيانات المحلية التي لا يتم مشاركتها مع الآخرين.على الرغم من أن هذا الإعداد يتطلب خطوات التحقق الإضافية لمنع البيانات غير ذات الصلة (وغالبًا ما يشار إليها باسم تسمم البيانات) من إدخال التدريب النموذجي ، إلا أنها نهج ترويجي فعال لاستخدام حالات الرعاية الصحية حيث يمكن لمقدمي الرعاية الصحية المتعددين تدريب النماذج العالمية دون تسرب بيانات طبية حساسة للغاية.
التوقعات والمخاطر
على مدار العامين الماضيين ، تحول التدريب اللامركزي من مفهوم مثير للاهتمام إلى شبكة فعالة تعمل في بيئة حقيقية.في حين أن هذه المشاريع لا تزال بعيدة عن الحالة النهائية المتوقعة ، فإنها تحرز تقدماً ذا مغزى على طريق التدريب اللامركزي.إذا نظرنا إلى الوراء في نمط التدريب اللامركزي الحالي ، بدأت بعض الاتجاهات في الظهور:
دليل في الوقت الحقيقي لمفهوم لم يعد خيالا.دخلت التحديات المبكرة مثل Nous ‘Consilience و Prime Intellect-2 من عمليات الإنتاج على نطاق الإنتاج خلال العام الماضي.تتيح الاختراقات مثل Opendiloco ونماذج البروتوكول AI عالية الأداء على الشبكات الموزعة ، مما يسهل تطوير النماذج الفعالة من حيث التكلفة ومرونة وشفافة.تقوم هذه الشبكات بتنسيق العشرات أو حتى مئات من وحدات معالجة الرسومات ، وتدريب النماذج المتوسطة الحجم المسبقة في الوقت الفعلي ، مما يثبت أن التدريب اللامركزي يمكن أن يتجاوز المظاهرات المغلقة والاختراق المؤقتة.في حين أن هذه الشبكات لا تزال غير شبكات بدون إذن ، فإن Templar تبرز في هذا الصدد ؛ يعزز نجاحها فكرة أن التدريب اللامركزي هو الانتقال من مجرد إثبات أن التكنولوجيا الأساسية فعالة في القدرة على توسيع نطاقها لمطابقة أداء النماذج المركزية وجذب موارد GPU اللازمة لإنتاج النماذج الأساسية على نطاق واسع.
يستمر حجم النموذج في التوسع ، لكن الفجوة تبقى.من 2024 إلى 2025 ، قفز عدد نماذج المعلمات للمشاريع اللامركزية من رقم واحد إلى 30 مليار إلى 40 مليار.ومع ذلك ، فقد أصدر مختبر AI الرائد تريليونات من المعلمات من النظام ويستمر في الابتكار بسرعة مع مراكز البيانات المتكاملة رأسياً والأجهزة الحديثة.يمكن للتدريب اللامركزي سد هذه الفجوة عن طريق الاستفادة من أجهزة التدريب من جميع أنحاء العالم ، خاصة وأن طرق التدريب المركزية تواجه قيودًا متزايدة بسبب الحاجة إلى زيادة عدد مراكز البيانات الفائقة.لكن إغلاق هذه الفجوة سيعتمد على المزيد من الاختراقات في المُحسِّنات وضغط التدرج للاتصالات الفعالة لتحقيق النطاق العالمي ، بالإضافة إلى طبقة حوافز غير قابلة للتشغيل.
أصبح سير العمل بعد التدريب مجالًا للقلق.يتطلب التثبيت الخاضع للإشراف ، و RLHF ، والتعلم المعزز الخاص بالمجال عرض النطاق الترددي المتزامن أقل بكثير من التدريب الشامل قبل التدريب.تعمل الأطر مثل Prime-RL و RL Swarm على عقد غير مستقرة على مستوى المستهلك ، مما يتيح للمساهمين في الربح من دورات الخمول بينما يمكن للمشاريع تسويق النماذج المخصصة بسرعة.بالنظر إلى أن RL مناسب تمامًا للتدريب اللامركزي ، فإن أهميته كمجال تركيز لبرامج التدريب اللامركزية قد تصبح بارزة بشكل متزايد.هذا يجعل من الممكن أن يكون التدريب اللامركزي أول من يجد سوق منتجات واسع النطاق يتناسب مع تدريب RL ، كما يتضح من العدد المتزايد من الفرق التي تطلق أطر التدريب الخاصة بـ RL.
آلية الحوافز والتحقق تتخلف عن الابتكار التكنولوجي. لا تزال آليات الحوافز والتحقق متخلفة عن الابتكار التكنولوجي.فقط عدد قليل من الشبكات ، وخاصة Templar ، توفر مكافآت معدنية في الوقت الفعلي وآليات العقوبة والمصادرة على السلسلة ، وبالتالي كبح السلوك السيئ بشكل فعال وتم اختباره في بيئات العالم الحقيقي.على الرغم من أن البرامج الأخرى تقوم بتجربة درجات السمعة ، أو برامج إثبات الشهود أو إثبات التدريب ، إلا أن هذه الأنظمة لا تزال غير التحقق منها.حتى إذا تم التغلب على الحواجز التقنية ، فإن الحوكمة ستعمل على حد سواء تحديات صعبة على قدم المساواة ، حيث يجب على الشبكات اللامركزية إيجاد طرق لصياغة القواعد وفرض القواعد وحل النزاعات دون عدم كفاءة متكررة تحدث في التشفير.حل الحواجز التقنية هو الخطوة الأولى فقط ؛ تعتمد الجدوى طويلة الأجل على الجمع بينه وبين آليات التحقق الموثوقة ، وآليات الحوكمة الفعالة ، وهياكل تسييل/ملكية جذابة لضمان الثقة في العمل الذي يتم تنفيذه وجذب المواهب والموارد اللازمة لتوسيع نطاقها.
المكدس يندمج في خط أنابيب من طرف إلى طرف.اليوم ، تجمع معظم الفرق الرائدة بين الأماكن المميتة للنطاق الترددي (Demo ، Distro) ، تبادل الحوسبة اللامركزية (Prime Compute ، Basilica) ، وطبقات التنسيق على السلسلة (Psyche ، PM ، Prime).أخيرًا ، يتم تشكيل خط أنابيب مفتوح معياري ، والذي يعكس سير عمل المختبرات المركزية من البيانات إلى النشر ، ولكن بدون نقطة تحكم واحدة.حتى إذا لم تدمج المشاريع حلولها الخاصة مباشرة ، أو حتى إذا تم دمجها ، فيمكن الوصول إليها مع مشاريع التشفير الأخرى التي تركز على العموديات المطلوبة للتدريب اللامركزي ، مثل بروتوكولات توفير البيانات ، وأسواق GPU ومقاطع الاستدلال ، والعمود الفقري للتخزين اللامركزي.توفر هذه البنية التحتية المحيطية مكونات التوصيل والتشغيل لبرامج التدريب اللامركزية التي يمكن الاستفادة منها لتعزيز منتجاتها والتنافس بشكل أفضل مع أقرانها المركزية.
مخاطرة
يعد تحسين الأجهزة والبرامج هدفًا متغيرًا باستمرار – يتوسع المختبر المركزي أيضًا في هذا المجال.تم الإعلان عن رقاقة Nvidia من Blackwell B200. في معيار MLPERF ، سواء كان التدريب المسبق مع 405 مليار معلمة أو 70 مليار لور ، فإن إنتاجية التدريب الخاصة بها أسرع من 2.2 إلى 2.6 مرة من الجيل السابق ، مما يقلل بشكل كبير من تكاليف الوقت والطاقة للعمالقة.من حيث البرنامج ، يقدم Pytorch 3.0 و TensorFlow 4.0 اندماج الرسم البياني على مستوى المترجم و kernels شكل ديناميكي لزيادة تحسين الأداء على نفس الشريحة.من خلال التحسينات في تحسين الأجهزة والبرامج ، أو ظهور بنيات التدريب الجديدة ، يجب على شبكات التدريب اللامركزية أيضًا مواكبة التحديثات المستمرة للتكيف مع أسرع وأكثر طرق التدريب المتقدمة ، وجذب المواهب وإلهام تطوير النماذج ذات معنى.سيتطلب ذلك من الفريق تطوير برامج تضمن أداءً عاليًا مستمرًا ، بغض النظر عن الأجهزة الأساسية ، ومكدس برامج يمكّن هذه الشبكات من التكيف مع التغييرات في بنية التدريب الأساسية.
يمسح نموذج المصدر المفتوح للمؤسسة الحالية الحدود بين التدريب اللامركزي والمركزي.تحافظ معظم مختبرات الذكاء الاصطناعى المركزية على إغلاق النماذج ، مما يثبت كذلك أن التدريب اللامركزي هو وسيلة لضمان الانفتاح والشفافية وحوكمة المجتمع.على الرغم من أن المشاريع الحديثة مثل Deepseek وإصدارات GPT Open Source و Llama تُظهر تحولها نحو الانفتاح العالي ، فمن غير الواضح ما إذا كان هذا الاتجاه يمكن أن يستمر في سياق المنافسة المتزايدة والتنظيمية والأمنية.حتى إذا تم الكشف عن الأوزان ، فإنها لا تزال تعكس قيم وخيارات المختبر الأصلي – فإن القدرة على التدريب بشكل مستقل أمر بالغ الأهمية للتكيف ، والتنسيق بأولويات مختلفة ، وضمان الوصول إلى عدد قليل من الشركات الحالية.
لا يزال التوظيف صعبًا. العديد من الفرق تخبرنا هذا.في حين أن جودة المواهب التي تنضم إلى برامج التدريب اللامركزية قد تحسنت ، فإنها تفتقر إلى الموارد القوية التي تقود مختبرات الذكاء الاصطناعى (على سبيل المثال ، عرضت Openai مؤخرًا ملايين الدولارات من “مكافآت خاصة” لكل موظف ، أو عرض عرض الباحثين البالغ 250 مليون دولار للباحثين الصدعاء).في الوقت الحالي ، تجذب المشاريع اللامركزية الباحثين الذين يحركونه المهمة ويقدرون الانفتاح والاستقلال ، مع استخلاص المواهب أيضًا من مجموعة مواهب عالمية أوسع ومجتمع مفتوح المصدر نابض بالحياة.ومع ذلك ، من أجل التنافس على المقياس ، يجب أن يثبتوا أنفسهم من خلال تدريب نماذج مماثلة للشركات الحالية وإتقان الحوافز وآليات الدخل لإنشاء فوائد ذات معنى للمساهمين.في حين أن الشبكات الخالية من الترخيص وحوافز التشفير الاقتصادية توفر قيمة فريدة ، فإن عدم القدرة على الوصول إلى توزيع وإنشاء تدفق إيرادات مستدام قد يعيق النمو طويل الأجل في القطاع.
توجد المقاومة التنظيمية ، خاصة بالنسبة للنماذج غير الخاضعة للرقابة. يواجه التدريب اللامركزي تحديات تنظيمية فريدة: التصميم ، يمكن لأي شخص تدريب أي نوع من النماذج.يعد هذا الانفتاح بالتأكيد ميزة ، ولكنه يثير أيضًا مخاطر أمنية ، وخاصة في الأمن الحيوي أو المعلومات الخاطئة أو غيرها من مجالات سوء المعاملة الحساسة.أشار صانعو السياسة في الاتحاد الأوروبي والولايات المتحدة إلى أنهم سيعززون التدقيق الخاص بهم: يضع قانون الذكاء الاصطناعي التابع للاتحاد الأوروبي التزامات إضافية على النماذج الأساسية عالية الخطورة ، بينما تدرس الوكالات الأمريكية الحد من الأنظمة المفتوحة وتدابير التحكم في التصدير المحتملة.يمكن للأحداث التي تنطوي على نماذج لا مركزية لأغراض ضارة وحدها أن تؤدي إلى تنظيم شامل ، مما يهدد المبدأ الأساسي للتدريب بدون إذن.
التوزيع والتحميمة: لا يزال التوزيع يمثل تحديًا كبيرًا.تتمتع المختبرات الرائدة بما في ذلك Openai و Anthropic و Google بمزايا توزيع ضخمة من خلال الوعي بالعلامة التجارية ، وعقود الشركات ، وتكامل منصة السحابة والوصول المباشر إلى المستهلكين.في المقابل ، تفتقر برامج التدريب اللامركزية إلى هذه القنوات المدمجة ويجب بذل المزيد من الجهود لتمكين النماذج من اعتمادها واكتساب الثقة ودمجها في سير العمل الفعلي.بالنظر إلى أن العملات المشفرة لا تزال في مهدها في تكاملها خارج تطبيقات التشفير (على الرغم من أن هذا يتغير بسرعة) ، فقد يكون هذا أكثر صعوبة.والسؤال المهم للغاية الذي لم يتم حله هو من سيستخدم بالفعل نماذج التدريب اللامركزية هذه.توجد بالفعل نماذج مصادر مفتوحة عالية الجودة ، وبمجرد إصدار نماذج متقدمة جديدة ، ليس من الصعب بشكل خاص على الآخرين استخراجها أو ضبطها.بمرور الوقت ، يجب أن تخلق الطبيعة المصدر المفتوح لبرامج التدريب اللامركزية تأثيرات الشبكة التي تحل مشكلة التوزيع.ومع ذلك ، حتى لو تمكنوا من حل مشكلة التوزيع ، سيواجه الفريق تحدي تسييل المنتج.في الوقت الحالي ، يبدو أن مديري مشاريع Pluralis يعالجون تحديات الدخل هذه بشكل مباشر.هذه ليست مجرد مشكلة تشفير X AI ، ولكنها مشكلة تشفير أوسع تبرز التحديات المستقبلية.
ختاماً
تطور التدريب اللامركزي بسرعة من مفهوم مجردة إلى شبكة فعالة تنسق تشغيل التدريب العالمي الفعلي.في العام الماضي ، أثبتت مشاريع بما في ذلك NOUS و PRIME BENTER و PLURALIS و Templar و Gensyn أنه من الممكن ربط وحدات معالجة الرسومات اللامركزية معًا ، وضغط الاتصالات بكفاءة ، وحتى البدء في تجربة الحوافز في البيئات في العالم الحقيقي.توضح هذه المظاهرات المبكرة أن التدريب اللامركزي يمكن أن يتجاوز النظرية ، على الرغم من أن الطريق إلى التنافس مع المختبرات المركزية على نطاق متطور لا يزال صعبًا.
حتى لو كانت النماذج الأساسية التي تم تدريبها أخيرًا من قبل المشاريع اللامركزية قابلة للمقارنة مع مختبرات الذكاء الاصطناعي الرائدة اليوم ، فإنها تواجه الاختبارات الأكثر حدة: إثبات مزاياها الواقعية بما يتجاوز متطلبات الأفكار.قد تتجلى هذه المزايا بشكل داخلي من خلال الهندسة المعمارية الممتازة أو مخططات الملكية والملكية الجديدة للمساهمين.بدلاً من ذلك ، قد تكون هذه المزايا أيضًا خارجية إذا حاول المشاركون الحاليون المركزية خنق الابتكار عن طريق الحفاظ على الأوزان مغلقة أو حقن تحيزات المحاذاة غير المرغوب فيها.
بالإضافة إلى التطورات التكنولوجية ، بدأت المواقف تجاه هذا المجال أيضًا في التغيير.وصف أحد المؤسسين التغييرات في العواطف في مؤتمرات الذكاء الاصطناعى الرئيسية على مدار العام الماضي: قبل عام ، لم يكن هناك اهتمام كبير بالتدريب اللامركزي ، خاصة عند استخدامه بالاقتران مع العملات المشفرة ؛ قبل ستة أشهر ، بدأ المشاركون في التعرف على المشكلات المحتملة لكنهم عبروا عن شكوك حول جدوى التنفيذ على نطاق واسع ؛وفي الأشهر الأخيرة ، كان هناك اعتراف متزايد بأن التقدم المستمر يمكن أن يجعل التدريب اللامركزي القابل للتطوير ممكنًا.يوضح تطور هذا المفهوم أن زخم التدريب اللامركزي يزداد أيضًا ليس فقط في مجال التكنولوجيا ، ولكن أيضًا من حيث الشرعية.
المخاطر حقيقية: لا تزال الشركات الحالية تحافظ على مزايا أجهزتها ومواهبها وتوزيعها ؛ المراجعة التنظيمية وشيكة.لم يتم اختبار الحوافز وآليات الحوكمة على نطاق واسع.ومع ذلك ، فإن مزاياها لافتة للنظر على قدم المساواة. لا يمثل التدريب اللامركزي بنية بديلة للتكنولوجيا فحسب ، بل يمثل أيضًا مفهومًا أساسيًا لبناء الذكاء الاصطناعي: لا ترخيص ، ملكية عالمية ، ويتوافق مع مجتمع متنوع بدلاً من بعض الشركات.حتى لو كان بإمكان مشروع واحد فقط إثبات أن الانفتاح يمكن أن يترجم إلى تكرار أسرع أو الهندسة المعمارية الجديدة أو الحوكمة الشاملة ، فسيشكل ذلك لحظة اختراق بالنسبة للعملات المشفرة والذكاء الاصطناعي.الطريق إلى الأمام طويل ، لكن العناصر الأساسية للنجاح قد تم إمساكها الآن.