
Note: This article is the second part of the series of articles recently published by Vitalik, founder of Ethereum, “The Future of the Ethereum Agreement”Possible futures for the Ethereum protocol, part 2: The Surge“, the first part is shown in the previous report of Bitchain Vision”What else can be improved on Ethereum PoS”. Compiled by Deng Tong, the following is the full text of the second part:
At the beginning, there were two scaling strategies in Ethereum’s roadmap.
One of them is “sharding”: Each node only needs to verify and store a small portion of transactions, not all transactions in the chain.This is also how any other peer-to-peer network (e.g. BitTorrent) works, so we can certainly make the blockchain work the same way.
The other is the 2-layer protocol:The networks will be on top of Ethereum, allowing them to fully benefit from their security while keeping most data and computing away from the main chain.The “Layer 2 protocol” refers to the 2015 status channel, the 2017 Plasma, and the 2019 Rollups.Rollups are more powerful than state channels or Plasma, but they require a lot of on-chain data bandwidth.
Fortunately, by 2019, sharding research has addressed the issue of large-scale verification of “data availability”.As a result, the two paths merged and we got a Rollup-centric roadmap, which is still Ethereum’s scaling strategy today.
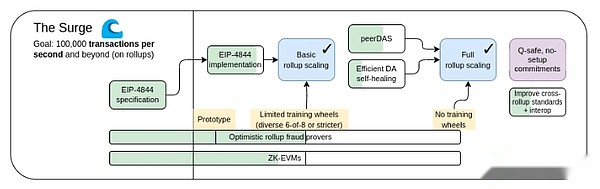
The Surge, 2023 Roadmap Edition.
The Rollup-centric roadmap proposes a simple division of labor: Ethereum L1 focuses on becoming a strong and decentralized foundation layer, while L2 undertakes the task of helping the ecosystem scale.This is a recurring pattern throughout society: the court system (L1) is not for super fast and efficient, but for protecting contracts and property rights, while the entrepreneur (L2) needs to build a solid foundation layer on this basis andBring humans to (metaphorically and literally) Mars.
This year, the Rollup-centric roadmap has achieved significant success: Ethereum L1 data bandwidth has increased significantly through EIP-4844 blobs, and multiple EVM Rollups are now in phase one.Very heterogeneous and diversified implementations of shards, where each L2 acts as a “fragment” with its own internal rules and logic is now a reality.But as we have seen, going this path has its own unique challenges.therefore,Now our mission is to complete the Rollup-centric roadmap and solve these problems while retaining the robustness and decentralization that sets Ethereum L1 apart.
Surge: Key Objectives
L1+L2 on 100,000+ TPS
Maintain the decentralization and robustness of L1
At least some L2s fully inherit the core attributes of Ethereum (trustless, open, censorship-resistant)
Maximum interoperability between L2s.Ethereum should feel like an ecosystem, not 34 different blockchains.
The triad of scalability
The scalability impossible triangle is an idea proposed in 2017 that it believes that there is tension between the three properties of blockchain: decentralization (more specifically: low cost of running nodes), scalability (moreSpecifically: handles a large number of transactions) and security (more specifically: an attacker needs to destroy most nodes in the entire network to make a single transaction fail).
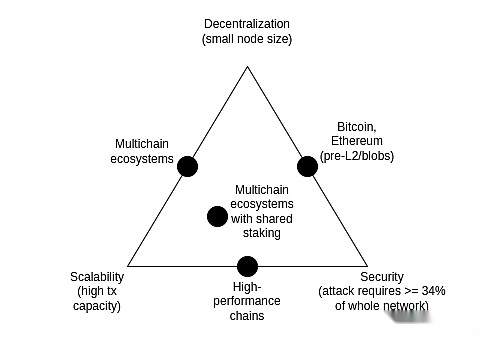
It is worth noting that the triad dilemma is not a theorem, and the posts introducing the triad dilemma do not come with mathematical proof.It gives a heuristic mathematical argument: if a decentralized friendly node (such as a consumer laptop) can verify N transactions per second, and you have a chain that processes k*N transactions per second, then(i) Each transaction can only be seen by 1/k nodes, which means that an attacker can only break a few nodes to drive bad transactions, or (ii) your node will become strong and your chain is notDecentralized.The purpose of this article is never to show that breaking the triad is impossible; rather, it is to show that breaking the triad is difficult-it requires some way to think outside the box implied by the argument.
Over the years, some high-performance chains have often claimed that they solved the triad without taking any clever measures at the infrastructure level, often by using software engineering skills to optimize nodes.This is always misleading, and running nodes in such chains is always much more difficult than in Ethereum.This post explores many subtleties of why this happens (and why L1 client software engineering cannot scale Ethereum itself alone).
However,The combination of data availability sampling (DAS) and SNARK does solve the triad: It allows the client to verify that a certain amount of data is available and whether a certain number of calculation steps are performed correctly, while only a small portion of that data is downloaded and the amount of calculations run is much smaller.SNARK is not credible.Data availability sampling has a subtle minority N trust model, but it retains the basic properties that non-scalable chains have, and even 51% of attacks cannot force the network to accept bad blocks.
Another way to solve the triad is the Plasma architecture, which uses clever techniques to push the responsibility for monitoring data availability to users in an incentivized compatible way.Back in 2017-2019, when all we needed to scale computing was fraud proof, Plasma’s security capabilities were very limited, but the mainstreaming of SNARK made Plasma architecture more suitable for a wider range of use cases than before.
Further progress in DAS
What problems do we want to solve?
As of March 13, 2024, when the Dencun upgrade went live, the Ethereum blockchain had 3 “blobs” of about 125 kB every 12-second period, or about 375 kB of data available bandwidth per period.Assuming that transaction data is directly posted to the chain, ERC20 transmission is about 180 bytes, so the maximum TPS of rollups on Ethereum is:
375000 / 12 / 180 = 173.6 TPS
If we add Ethereum’s calldata (theoretical maximum: 30 million Gas per slot / 16 Gas per byte = 1,875,000 bytes per slot), this will become 607 TPS.For PeerDAS, it is planned to increase the blob count target to 8-16, which will give us a calldata of 463-926 TPS.
This is a significant improvement over Ethereum L1, but that is not enough.We want more scalability.Our mid-term goal is 16 MB per slot, which, if combined with improvements in sink data compression, will give us about 58,000 TPS.
What is PeerDAS and how does it work?
PeerDAS is a relatively simple implementation of “one-dimensional sampling”.Each blob in Ethereum is a 4096-order polynomial on the 253-bit prime domain.We broadcast the “shares” of the polynomial, where each share consists of 16 evaluations at adjacent 16 coordinates taken from a total set of 8192 coordinates.The blob can be restored by any 4096 of 8192 evaluations (using the currently recommended parameters: any 64 of 128 possible samples).
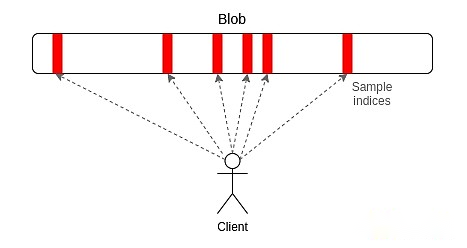
PeerDAS works by having each client listen to a small quantum network, where the i-th subnet broadcasts the i-th sample of any blob and also requests what is needed on other subnets by asking peers in the global p2p network.Blob (who will listen to different subnets).The more conservative version of SubnetDAS uses only the subnet mechanism and does not have additional request peer layers.The current recommendation is that the nodes participating in the Proof of Stake use SubnetDAS and the other nodes (i.e., the “client”) use PeerDAS.
In theory, we can scale 1D sampling quite far: if we increase the blob count maximum to 256 (so the target is 128), then we will reach the 16 MB target, while the data availability sampling only costs 16 per nodeSamples* 128 blobs* 512 bytes per blob per sample = 1 MB of data bandwidth per slot.This is just within our tolerance: it is feasible, but it means that bandwidth-limited clients cannot sample.We can optimize this by reducing the number of blobs and increasing the size of blobs, but this makes reconstruction more expensive.
So ultimately we want to go a step further and do 2D sampling, which not only randomly samples within the blob, but also between blobs.The linear properties promised by KZG are used to “extend” the blob set in a block by redundantly encoded new “virtual blobs” lists.
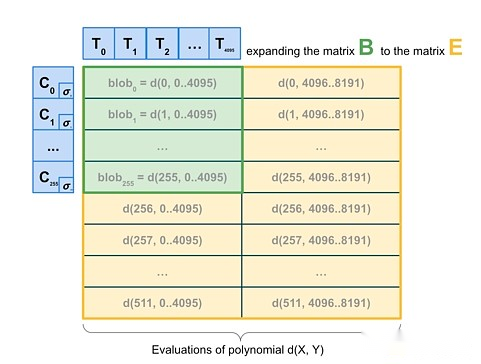
2D sampling. Source: a16z
Crucially, the computationally promised scaling does not require blobs, so the scheme is fundamentally friendly to distributed block building.The nodes that actually build the block only need to have Blob KZG promises and can rely on DAS to verify the availability of Blobs.1D DAS is also essentially friendly to distributed block construction.
What are the connections to existing research?
Original article introducing data availability (2018):https://github.com/ethereum/research/wiki/A-note-on-data-availability-and-erasure-coding
Follow-up papers:https://arxiv.org/abs/1809.09044
Interpreter post for DAS, paradigm:https://www.paradigm.xyz/2022/08/das
KZG promised 2D availability:https://ethresear.ch/t/2d-data-availability-with-kate-commitments/8081
PeerDAS on ethresear.ch:https://ethresear.ch/t/peerdas-a-simpler-das-approach-using-battle-tested-p2p-components/16541And papers:https://eprint.iacr.org/2024/1362
EIP-7594:https://eips.ethereum.org/EIPS/eip-7594
SubnetDAS on ethresear.ch:https://ethresear.ch/t/subnetdas-an-intermediate-das-approach/17169
Subtle differences in recoverability in 2D sampling:https://ethresear.ch/t/nuances-of-data-recoverability-in-data-availability-sampling/16256
What else needs to be done and what trade-offs need to be weighed?
The next step is to complete the implementation and rollout of PeerDAS.Since then, increasing the blob count on PeerDAS is a gradual effort, while carefully observing the network and improving the software for security.At the same time, we hope to do more academic work on the formalization of DAS and other versions of DAS and its interaction with issues such as security of fork selection rules.
Going forward, we need to do more to find out the ideal version of 2D DAS and prove its security features.We also hope to eventually migrate from KZG to an alternative that is resistant to quantum without a trusted setup.At the moment, we don’t know which candidates are friendly to distributed block building.Even the expensive “strong” technique to use recursive STARK to generate validity proofs for rebuilding rows and columns is not enough, because technically the hash size of STARK is O(log(n) * log(log(n)))(With STIR), STARK is actually almost as big as the entire spot.
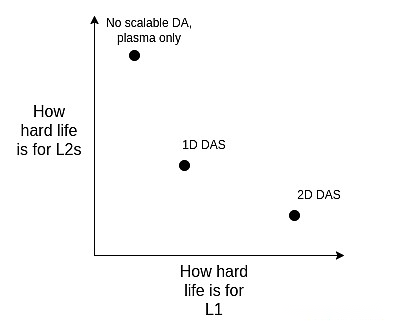
In the long run, I think the reality path is:
-
Ideal 2D DAS tool;
-
Stick to 1D DAS, sacrificing sampling bandwidth efficiency for simplicity and robustness and accepting lower data caps;
-
(Hard Pivot) Give up DA and embrace Plasma completely as the main tier 2 architecture we focus on.
We can look at these by weighing the scope:
Note that even if we decide to extend execution directly on L1, this choice remains.This is because if L1 is going to handle a large number of TPS, the L1 blocks will become very large and the customer will need an efficient way to verify that they are correct, so we have to use the same techniques that support Rollup (ZK-EVM and DAS) and L1.
How does it interact with the rest of the roadmap?
If data compression is implemented (see below), the demand for 2D DAS will be reduced, or at least delayed, and if Plasma is widely used, the demand for 2D DAS will be reduced further.DAS also presents challenges to distributed block building protocols and mechanisms: Although DAS is theoretically friendly to distributed reconstruction, it needs to be combined in practice with the fork selection mechanism that includes list proposals and their surroundings.
Data compression
What problems do we want to solve?
Each transaction in Rollup takes up a lot of on-chain data space: ERC20 transmission takes approximately 180 bytes.This limits the scalability of the Layer 2 protocol even when using ideal data availability sampling.16 MB per slot, we get:
16000000 / 12 / 180 = 7407 TPS
What if we can solve the denominator in addition to solving the numerator and make each transaction in Rollup take up fewer bytes on the chain?
What is it and how does it work?
I think the best explanation is this picture from two years ago:
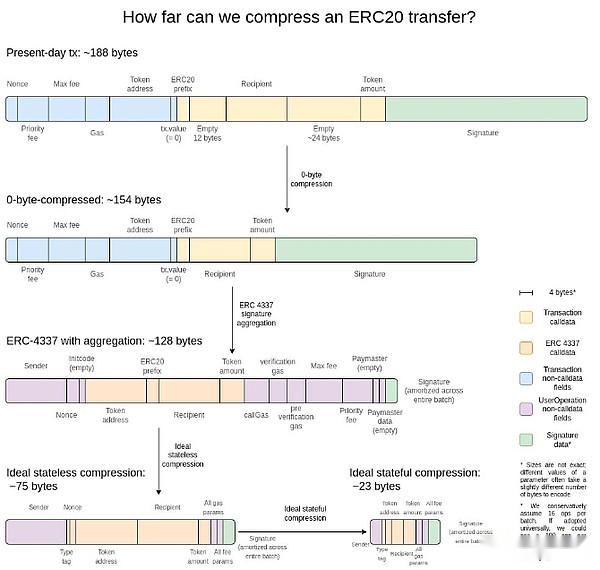
The simplest gain is zero-byte compression: replace each long zero-byte sequence with two bytes representing the number of zero-bytes.Going further, we take advantage of the specific properties of the transaction:
-
Signature aggregation– We switch from ECDSA signature to BLS signature, which has properties that can combine many signatures together to form a single signature that proves the validity of all original signatures.L1 does not consider this because the computational cost of validation (even using aggregation) is higher, but in data scarce environments like L2, they make arguably meaningful.The aggregation function of ERC-4337 provides a way to achieve this.
-
Replace address with pointer– If you have used an address before, we can replace the 20-byte address with a 4-byte pointer to the historical location.This is necessary to achieve the maximum gain, although it requires effort to achieve, as it requires (at least part of) the history of blockchain to be effectively part of the country.
-
Custom serialization of transaction values– Most transaction values have only very few numbers, for example.0.25 ETH is expressed as 250,000,000,000,000,000,000 wei.Gas max-basefees works similarly to priority fees.Therefore, we can use custom decimal floating point formats, or even dictionaries of particularly common values, representing most currency values very compactly.
What are the connections to existing research?
Exploration from sequence.xyz:https://sequence.xyz/blog/compressing-calldata
Calldata optimization contracts for L2, from ScopeLift:https://github.com/ScopeLift/l2-optimizoooors
Another strategy – Rollup (aka ZKRollup) based on validity proof of release status differences instead of transactions:https://ethresear.ch/t/rollup-diff-compression-application-level-compression-strategies-to-reduce-the-l2-data-footprint-on-l1/9975-l2-data footprint
BLS Wallet – BLS Aggregation via ERC-4337:https://github.com/getwax/bls-wallet
What else needs to be done and what trade-offs need to be weighed?
The main task left to do is to implement the above plan.The main tradeoffs are:
-
Switching to BLS signatures takes a huge effort and reduces compatibility with trusted hardware chips that improve security.It can be replaced by the ZK-SNARK wrapper of other signature schemes.
-
Dynamic compression (such as replacing address with pointers) complicates client code.
-
Posting state differences to a chain rather than a transaction reduces auditability and makes many software (such as block browsers) unworkable.
How does it interact with the rest of the roadmap?
The adoption of ERC-4337, and the ultimate incorporation of some of its content into L2 EVM, can greatly accelerate the deployment of aggregation technology.Incorporating parts of ERC-4337 into L1 can accelerate its deployment on L2.
Generalized Plasma
What problems do we want to solve?
Even with 16 MB blobs and data compression, 58,000 TPS is not necessarily enough to completely take over consumer payments, decentralized social or other high bandwidth areas, which is especially true if we start thinking about privacy, which could make scalability less3 -8x.For large-capacity, low-value applications, one option today is Validium, which puts data off-chain and has an interesting security model where operators can’t steal users’ funds, but they can disappear and temporarily or permanently freeze allUser funds.But we can do better.
What is it and how does it work?
Plasma is an extension solution that involves operators publishing blocks off-chain and placing the Merkle roots of these blocks on the chain (unlike Rollups, rollups is putting the entire block on the chain).For each block, the operator sends a Merkle branch to each user, proving what happened or nothing happened to that user’s assets.Users can extract assets by providing Merkle branch.Importantly, the branch does not have to be rooted in the latest state – so even if data availability fails, users can still recover their assets by revoking the latest state available.If a user submits an invalid branch (e.g., exiting an asset they have sent to someone else, or the operator creates an asset out of thin air), the on-chain challenge mechanism can determine who the asset belongs to correctly.
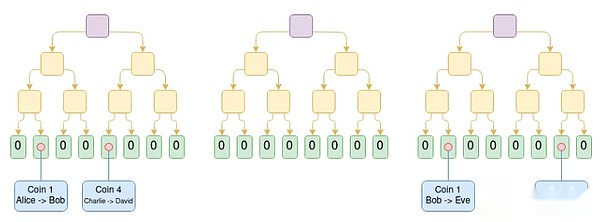
Plasma Cash chain diagram.The transaction of the cost coin i is placed in the i-th position in the tree.In this example, assuming that all previous trees are valid, we know that Eve currently owns coin 1, David has coin 4, and George has coin 6.
Early versions of Plasma can only handle payment use cases and cannot be further promoted effectively.However, if we require each root to be verified with SNARK, then Plasma becomes more powerful.Each challenge game can be greatly simplified because we eliminate most possible paths for operator cheating.New paths have also been opened up, allowing Plasma technology to expand to a wider range of asset classes.Finally, users can withdraw funds immediately without waiting for a week of challenge without waiting for the challenge period.
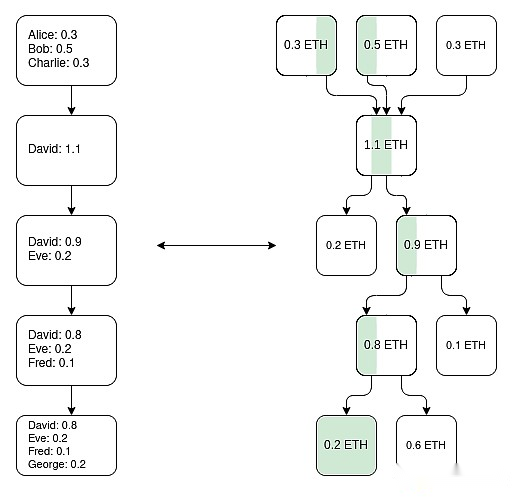
One way to make EVM Plasma chains (not the only way): build a parallel UTXO tree using ZK-SNARK, reflecting the balance changes made by EVM, and defining what is the unique mapping of “same coin” in history.Then you can build the Plasma structure on this basis.
An important insight is that Plasma systems don’t need to be perfect.Even if you can only protect a portion of your assets (e.g., even if it’s just tokens that haven’t moved in the past week), you’ve greatly improved the status quo of hyperscalable EVMs, which is a validation.
Another type of structure is a hybrid Plasma/rollups structure, such as Intmax.These structures put a very small amount of data on a chain (e.g. 5 bytes), and by doing so, you can get properties between Plasma and Rollup: In the Intmax case, you can get very high levelsScalability and privacy, even in the 16 MB world, the theoretical capacity is about 16,000,000 / 12 / 5 = 266,667 TPS.
What are the connections to existing research?
Original Plasma paper:https://plasma.io/plasma-deprecated.pdf
Plasma Cash:https://ethresear.ch/t/plasma-cash-plasma-with-much-less-per-user-data-checking/1298
Plasma Cash Flow:https://hackmd.io/DgzmJIRjSzCYvl4lUjZXNQ?view#-Exit
Intmax (2023):https://eprint.iacr.org/2023/1082
What else needs to be done and what trade-offs need to be weighed?
The remaining main task is to put the Plasma system into production.As mentioned above, “plasma and validium” are not binary oppositions: any validium can improve at least a little security performance by adding the Plasma functionality to the exit mechanism.The research partly was to obtain the best attributes of the EVM (in terms of trust requirements, worst-case L1 Gas cost and DoS vulnerability) and alternative application-specific structures.In addition, Plasma has greater conceptual complexity compared to rollups and needs to be directly solved by studying and building a better general framework.
The main drawback of using Plasma designs is that they are more operator-dependent and harder to “based on”, although hybrid Plasma/rollup designs often avoid this weakness.
How does it interact with the rest of the roadmap?
The more effective the Plasma solution is, the less stress the L1 has to have high-performance data availability capabilities.Moving the activity to L2 also reduces MEV pressure on L1.
Mature L2 proof system
What problems do we want to solve?
Today, most Rollups are not actually trustworthy; there is a Security Council that has the ability to overturn (optimism or effectiveness) prove the behavior of the system.In some cases, the proof system does not even exist at all, or even if it exists, it only has a “consultation” function.The leading ones are (i) some application-specific Rollups, such as Fuel, which are trustless, and (ii) as of this writing, Optimism and Arbitrum, two full EVM Rolups have implemented partial trustlessness.The milestone is called the “first phase”.The reason why Rollups didn’t develop further is worrying about bugs in the code.We need to trust Rollup, so we need to solve this problem head-on.
What is it and how does it work?
First, let’s review the “stage” system that was originally introduced in this article.There are more detailed requirements, but the summary is as follows:
-
Stage 0:The user must be able to run the node and synchronize the chain.If the verification is fully trusted/centralized.
-
Phase 1:There must be a (trustless) proof system to ensure that only valid transactions are accepted.There is a security committee that can overturn the proof system, but there is only a 75% voting threshold.Additionally, the quorum blocking portion of the Council (i.e., over 26%) must be located outside the main companies that built Rollup.Weaker-featured upgrade mechanisms (such as DAO) are allowed, but there must be a long enough delay so that if a malicious upgrade is approved, users can exit funds before the upgrade goes live.
-
Phase 2:There must be a (untrusted) proof system to ensure that only valid transactions are accepted.The Council is allowed to intervene only if there is a proven error in the code, for example.If two redundant proof systems are inconsistent with each other, or if one proof system accepts two different post-state roots of the same block (or does not accept anything for a long enough time, such as a week).The upgrade mechanism is allowed, but there must be a long delay.
Our goal is to reach the second stage.The main challenge to reaching the second phase is to gain enough confidence to prove that the system is actually trustworthy enough.There are two main ways to do this:
-
Formal verification:We can use modern mathematical and computational techniques to prove (optimistic or validity) that the system accepts only blocks that pass the EVM specification.These technologies have been around for decades, but recent advances (such as Lean 4) make them more practical, and advances in AI-assisted proofs may accelerate this trend further.
-
Multiple proofreaders:Making multiple proof systems and investing funds into 2-of-3 (or larger) multi-signatures between these proof systems and the Security Council (and/or other widgets with trust assumptions, such as TEE).If the system is proved to agree, the Council has no power.If they disagree, the Council can only choose one of them and cannot unilaterally impose its own answer.
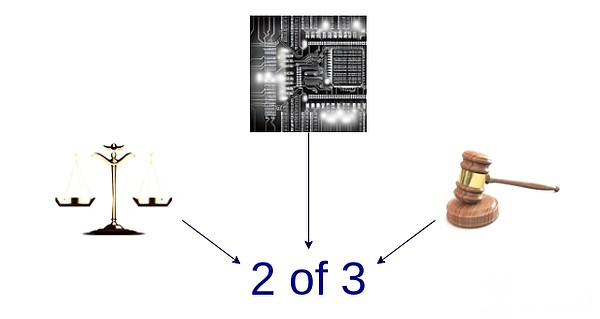
A stylized diagram of multi-proveners, combining an optimistic proof system, a proof of effectiveness system, and a security committee.
What are the connections to existing research?
EVM K Semantics (formal verification work since 2017):https://github.com/runtimeverification/evm-semantics
Demo on the idea of multi-proven persons (2022):https://www.youtube.com/watch?v=6hfVzCWT6YI
Taiko plans to use multiple proofs:https://docs.taiko.xyz/core-concepts/multi-proofs/
What else needs to be done and what trade-offs need to be weighed?
There are many for formal verification.We need to create a formal validated version of the entire SNARK proofer of the EVM.This is an extremely complex project, although we have already started.There is a trick that can significantly simplify tasks: we can make a formally validated SNARK prover for the smallest virtual machine, for example.RISC-V or Cairo, then write an implementation of the EVM in that minimal VM (and formally prove its equivalent to some other EVM specifications).
For multiple provers, there are two main remaining parts.First, we need to have enough confidence in at least two different proof systems, each of which is fairly secure, and if they crash, they will crash for different and irrelevant reasons (so they won’t crash at the same time).Secondly, we need to obtain a very high level of assurance in the underlying logic of the merging proof system.This is a small piece of code.There are several ways to make it very small—just store funds in a secure multi-signature contract whose signature is a contract representing a personal proof system—but this comes at a high cost of on-chain Gas.There is a need to find some balance between efficiency and safety.
How does it interact with the rest of the roadmap?
Moving activity to L2 reduces MEV pressure on L1.
Cross-L2 interoperability improvements
What problems do we want to solve?
One of the biggest challenges in today’s L2 ecosystem is that it’s difficult for users to manipulate.Furthermore, the easiest approach often reintroduces trust assumptions: centralized bridges, RPC clients, and so on.If we take the idea that L2 is part of Ethereum seriously, we need to make using the L2 ecosystem feel like using a unified Ethereum ecosystem.
An example of a pathologically bad (even dangerous: I personally lost $100 for the wrong chain selection here) across L2 UX – While this is not Polymarket’s fault, across L2 interoperability should be for wallet and Ethereum standardsResponsibility (ERC) Community.In a well-run Ethereum ecosystem, sending tokens from L1 to L2 or from one L2 to another should be like sending tokens in the same L1.
What is it and how does it work?
There are many categories of cross-L2 interoperability improvements.Generally speaking, the way to ask these questions is to note that in theory, Rollup-centric Ethereum is the same as L1 performing sharding, and then ask what aspects of the current Ethereum L2 version are in practice, in terms of gaps between the ideals and the current Ethereum L2 version.Here are some:
-
Link specific address:The chain (L1, Optimism, Arbitrum…) should be part of the address.Once implemented, you can implement the cross-L2 sending process by simply putting the address into the “Send” field, and the wallet can figure out how to send in the background (including using the bridge protocol).
-
Chain-specific payment requests:Making messages in the form of “send me a Y type X token on the Z chain” should be simple and standardized.There are two main use cases for this: (i) payment, whether it is an individual to an individual or an individual to a merchant service, and (ii) a dapp requesting funds, for example.The above Polymarket example.
-
Cross-chain exchange and Gas payment:There should be a standardized open protocol to express cross-chain operations such as “I send 1 ETH on Optimism to someone who sends 0.9999 ETH on Arbitrum” and “I send 0.0001 ETH on Optimism” Anyone includes this on ArbitrumTransactions”. ERC-7683 is an attempt to the former, while RIP-7755 is an attempt to the latter, although both are more general than these specific use cases.
-
Light client:Users should be able to actually verify the chain they are interacting with, rather than just trusting the RPC provider.Helios of A16z cryptocurrency did this for Ethereum itself, but we need to extend this trustlessness to L2.ERC-3668 (CCIP-read) is a strategy to achieve this.
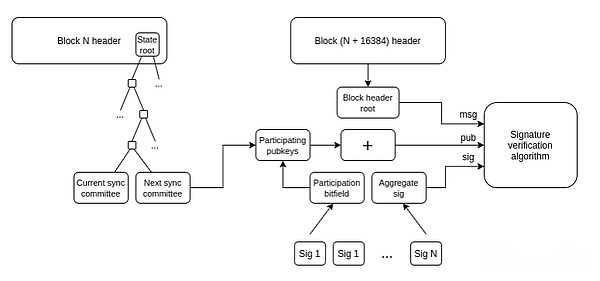
How light clients update their Ethereum header chain’s view.Once you have a header chain, you can use Merkle proof to verify any state object.Once you have the correct L1 state object, you can verify any state object on L2 using Merkle proof (or maybe signature if you want to check pre-confirmation).HeliosHave done the former.Extending to the latter is a challenge of standardization.
-
Keystore wallet:Today, if you want to update the key that controls a smart contract wallet, you must do this on all N chains where that wallet is located.A keystore wallet is a technique that allows the key to exist in a location (whether on L1 or later on L2) and then read from any L2 that has a copy of the wallet.This means that the update only needs to happen once.To improve efficiency, the keystore wallet requires L2 to have a standardized way to read L1 at no cost; two suggestions for this are L1SLOAD and REMOTESTATICCALL.
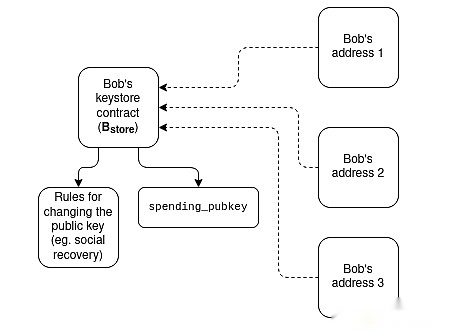
A stylized diagram of how a keystore wallet works.
-
More radical “shared token bridge” idea:Imagine a world where all L2 is a proven Rollup, with each slot dedicated to Ethereum.Even in this world, “local” transferring assets from one L2 to another requires withdrawal and deposit, which requires a large amount of L1 Gas.One way to solve this problem is to create a shared minimum Rollup whose only function is to maintain balances of which L2 has how many types of tokens and allow those balances to be collectively updated through a series of crossovers.L2 send operation initiated by any L2.This will allow transmission across L2 without paying for L1 Gas per transmission, and also without the need for liquidity provider-based technology (such as ERC-7683).
-
Synchronous Composability:Allows synchronous calls between specific L2 and L1 or between multiple L2s.This may help improve the financial efficiency of the defi protocol.The former can be done without any cross-L2 coordination; the latter requires shared sequencing.Rollup is automatically friendly to all of these technologies.
What are the connections to existing research?
Chain specific address: ERC-3770:https://eips.ethereum.org/EIPS/eip-3770
ERC-7683:https://eips.ethereum.org/EIPS/eip-7683
RIP-7755:https://github.com/wilsoncusack/RIPs/blob/cross-l2-call-standard/RIPS/rip-7755.md
Scrolling Keystore Wallet Design:https://hackmd.io/@haichen/keystore
Helios:https://github.com/a16z/helios
ERC-3668 (sometimes called CCIP-read):https://eips.ethereum.org/EIPS/eip-3668
Justin Drake’s proposal for “based on (shared) pre-confirmation”:https://ethresear.ch/t/based-preconfirmations/17353
L1SLOAD (RIP-7728):https://ethereum-magicians.org/t/rip-7728-l1sload-precompile/20388
乐观中的远程调用:https://github.com/ethereum-optimism/ecosystem-contributions/issues/76
AggLayer, which includes the idea of sharing token bridge:https://github.com/AggLayer
What else needs to be done and what trade-offs need to be weighed?
Many of the above examples face the standard dilemma of when to standardize and which layers of standardization.If standardization is too early, you may be at risk of poor quality solutions.If standardization is too late, it may cause unnecessary fragmentation.In some cases, there are short-term solutions that are weaker but easier to implement, as well as long-term solutions that are “finally correct” but take quite a while to achieve.
What’s unique about this section is that these tasks are not just technical issues: they are (perhaps mainly!) social issues.They need L2 and wallets and L1 to work together.Our ability to successfully deal with this issue is a test of our ability to unite as a community.
How does it interact with the rest of the roadmap?
Most of these suggestions are “higher” structures and therefore do not have much impact on L1 considerations.One exception is shared sorting, which has a great impact on MEVs.
Extended execution on L1
What problems do we want to solve?
If L2 becomes very scalable and successful, but L1 still can only handle very small transactions, there are many risks on Ethereum:
-
The economic situation of ETH assets becomes more dangerous, which in turn affects the long-term security of the network.
-
Many L2s benefit from a close connection to the highly developed financial ecosystem on L1, and if this ecosystem is greatly weakened, the motivation to become L2 (rather than a separate L1) will be weakened.
-
It takes a long time for the L2 to have the exact same security as the L1.
-
If L2 fails (for example, due to malicious operations or disappearing carriers), the user still needs to go through L1 to recover their assets.So, L1 needs to be strong enough to at least be able to really deal with the end of the highly complex and confusing L2 at times.
For these reasons, it is valuable to continue to expand the L1 itself and ensure it can continue to adapt to more and more uses.
What is it and how does it work?
The easiest way to expand is to simply add Gas limits.However, this has the risk of centralizing L1, thus weakening another important attribute that makes Ethereum L1 so powerful: its credibility as a strong underlying layer.There has been debate about how simple Gas restrictions are increased to be sustainable, and this will also vary according to the implementation of other technologies to make larger blocks easier to verify (e.g., historical expiration, stateless, L1 EVMproof of validity).Another important thing that needs continuous improvement is the efficiency of Ethereum client software, which is more optimized today than it was five years ago.An effective L1 Gas restriction increase strategy will involve accelerating these verification techniques.
Another scaling strategy involves identifying specific features and computing types that can become cheaper without compromising network dispersion or its security properties.Examples of this include:
-
EOF– A new EVM bytecode format that is more static analysis-friendly and allows for faster implementation.Given these efficiencies, a lower Gas cost can be given to the EOF bytecode.
-
Multidimensional Gas pricing– Establishing separate basic expenses and limitations on computing, data and storage can increase the average capacity of Ethereum L1 without increasing its maximum capacity (and thus creating new security risks).
-
Reduce Gas costs for specific opcodes and precompiled– Historically, we have conducted several rounds of Gas cost increase on certain underpriced operations to avoid denial of service attacks.We have done less but can do more, and that is to reduce the cost of gas for overpriced operations.For example, addition is much cheaper than multiplication, but the cost of ADD and MUL opcodes is currently the same.We can make ADD cheaper, and even simpler opcodes (such as PUSH) cheaper.There are many EOFs as a whole.
-
EVM-MAX 和 SIMD:EVM-MAX (“Modular Arithmetic Extensions”) is a proposal that allows more efficient native large-number modular mathematics as a separate module for EVM.Values calculated by EVM-MAX calculations can only be accessed by other EVM-MAX opcodes unless intentionally exported; this allows for greater space to store these values in an optimized format.SIMD (“Single Instruction Multi-Data”) is a proposal that allows efficient execution of the same instructions on an array of values.Together, the two can create a powerful coprocessor with EVM that can be used to implement encryption operations more efficiently.This is especially useful for privacy protocols and L2 proof systems, so it will help with L1 and L2 expansion.
These improvements will be discussed in more detail in future articles about Splurge.
Finally, the third strategy is native Rollup (or “built-in Rollup, enshrined rollups”): essentially, many copies of EVMs running in parallel, forming a model equivalent to the models Rollup can provide, but more nativelyIntegrate into the protocol.
What are the connections to existing research?
Polynya’s Ethereum L1 expansion roadmap:https://polynya.mirror.xyz/epju72rsyncfB-JK52_uYI7HuhJ-W_zM735NdP7alkAQ
Multidimensional Gas pricing:https://vitalik.eth.limo/general/2024/05/09/multidim.html
EIP-7706:https://eips.ethereum.org/EIPS/eip-7706
EOF:https://evmobjectformat.org/
EVM-MAX:https://ethereum-magicians.org/t/eip-6601-evm-modular-arithmetic-extensions-evmmax/13168
SIMD:https://eips.ethereum.org/EIPS/eip-616
Native Rollup:https://mirror.xyz/ohotties.eth/P1qSCcwj2FZ9cqo3_6kYI4S2chW5K5tmEgogk6io1GE
Interview with Max Resnick about the value of extending L1:https://x.com/BanklessHQ/status/1831319419739361321
Justin Drake About extending with SNARK and native Rollup:https://www.reddit.com/r/ethereum/comments/1f81ntr/comment/llmfi28/
What else needs to be done and what trade-offs need to be weighed?
There are three strategies for L1 extensions that can be executed individually or in parallel:
-
Improved technologies (e.g. client code, stateless client, historical expiration) make L1 easier to verify, and then increase Gas limits
-
Reduce the cost of a specific operation and increase the average capacity without increasing the worst-case risk
-
Native Rollup (i.e. “Create N parallel replicas of EVM”, although it may provide a lot of flexibility for developers in deploying the parameters of replicas)
It is worth understanding that these are different technologies with different trade-offs.For example, native Rollup has many of the same weaknesses as regular Rollup in terms of composability: You cannot send a single transaction to perform operations synchronously across multiple transactions, just like you can handle contracts on the same L1 (or L2).Increasing Gas restrictions deprives other benefits that can be achieved by making L1 easier to verify, such as increasing the percentage of users running verification nodes and increasing individual stakeholders.Making specific operations in EVM cheaper (depending on how it is operated) may increase the overall complexity of the EVM.
One big question that any L1 expansion roadmap needs to be answered is: What is the ultimate vision for L1 and L2?Obviously, it is ridiculous to do everything on L1: the potential use cases have hundreds of thousands of transactions per second, which will make L1 completely unverified (unless we take the native Rollup route).But we do need some guiding principles so we can make sure we don’t cause a situation where we raise the Gas limit by 10 times, seriously hurting the decentralization of Ethereum L1 and finding that we’re just entering a world, not 99% of the activity is on L2 and 90% of the activity is on L2, so the results look almost the same, except for most of the irreversible losses of Ethereum L1’s particularity.
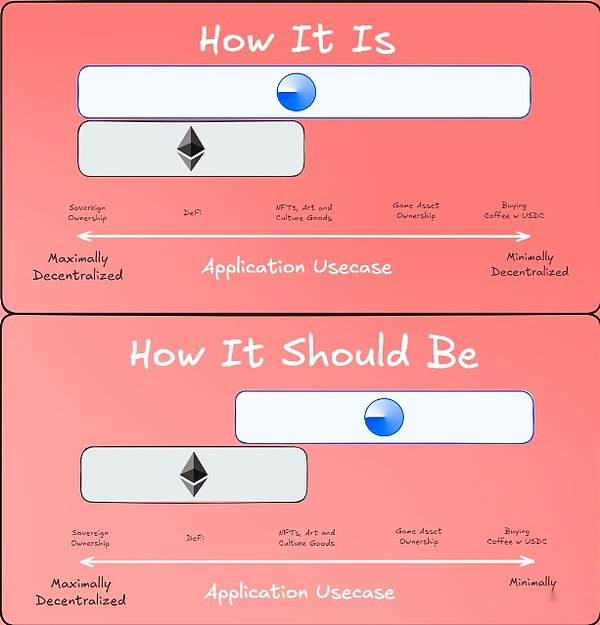
A proposed view on the “division of labor” between L1 and L2
How does it interact with the rest of the roadmap?
Getting more users into L1 means improving not only scale but other aspects of L1.This means that more MEVs will remain on L1 (rather than just being an issue with L2), so it is more urgent to deal with it explicitly.It greatly increases the value of fast slot time on L1.It also relies heavily on whether L1 (“The Verge”) verification went smoothly.
Special thanks to Justin Drake, Francesco, Hsiao-wei Wang, @antonttc and Georgios Konstantopoulos







