1 Introduction
Starting from the first wave of dApps Etherol, ETHLend and CryptoKitties in 2017, to the current variety of financial, gaming and social dApps based on different blockchains are blooming. When we talk about decentralized on-chain applications, have we ever thought about itThrough the source of various data adopted by these dApps in interaction?
In 2024, the hot spots will focus on AI and Web3. In the world of artificial intelligence, data is like the source of life for its growth and evolution.Just as plants rely on sunlight and moisture to thrive, AI systems also rely on massive amounts of data to constantly “learn” and “think”.Without data, no matter how exquisite the algorithm of AI is, it is just a castle in the air and cannot exert its due intelligence and efficiency.
This paper analyzes the evolution of blockchain data indexing in the process of industry development from the perspective of blockchain data accessibility, and compares the old data indexing protocol The Graph and the emerging blockchain data service protocol Chainbaseand Space and Time, the similarities and differences between these two new protocols combining AI technology in data services and product architecture characteristics are discussed.
2 The traditional and simple data index: from blockchain nodes to full-chain database
2.1 Data source: Blockchain node
When we first learned about “what blockchain is”, we often see this sentence: Blockchain is a decentralized account book.Blockchain nodes are the basis of the entire blockchain network and assume the responsibility of recording, storing and disseminating all transaction data on the chain.Each node has a complete copy of blockchain data, ensuring that the decentralized characteristics of the network are maintained.However, for ordinary users, it is not easy to build and maintain a blockchain node by themselves.This not only requires professional technical capabilities, but also comes with high hardware and bandwidth costs.At the same time, ordinary node query capabilities are limited and data cannot be queried in the format required by developers.Therefore, although everyone can theoretically run their own nodes, in practice, users are usually more inclined to rely on third-party services.
To solve this problem, RPC (Remote Procedure Call) node providers emerged.These providers are responsible for the cost and management of nodes and provide data through RPC endpoints.This allows users to easily access blockchain data without building their own nodes.Public RPC endpoints are free but have rate limits that can negatively impact the user experience of dApps.Private RPC endpoints provide better performance by reducing congestion, but even simple data retrieval requires a lot of back and forth communication.This makes them cumbersome and inefficient for complex data queries.Additionally, private RPC endpoints are often difficult to scale and lack compatibility across different networks.However, the standardized API interface of node providers gives users a lower threshold for accessing data on the chain, laying the foundation for subsequent data analysis and application.
2.2 Data analysis: From prototype data to available data
The data obtained from blockchain nodes is often the raw data that has been encrypted and encoded.Although these data retain the integrity and security of the blockchain, their complexity also increases the difficulty of data parsing.For ordinary users or developers, directly processing these prototype data requires a lot of technical knowledge and computing resources.
The process of data parsing is particularly important in this context.By parsing complex prototype data into a more understandable and manipulated format, users can understand and utilize this data more intuitively.The success of data analysis directly determines the efficiency and effectiveness of blockchain data application and is a key step in the entire data indexing process.
2.3 Evolution of data indexer
As the amount of blockchain data increases, the demand for data indexers is also increasing.Indexers play a vital role in organizing data on a chain and sending it to a database for ease of querying.The principle of indexers is to index blockchain data and make it readily available through SQL-like query languages (APIs such as GraphQL).By providing a unified interface for querying data, the indexer allows developers to quickly and accurately retrieve the required information using a standardized query language, greatly simplifying the process.
Different types of indexers optimize data retrieval in various ways:
-
Full Node Indexers: These indexers run full blockchain nodes and extract data directly from them to ensure that the data is complete and accurate, but require a lot of storage and processing power.
-
Lightweight Indexers: These indexers rely on full nodes to obtain specific data as needed, reducing storage requirements but may increase query time.
-
Dedicated Indexers: These indexers are specifically designed for certain types of data or specific blockchains, and optimize retrieval of specific use cases, such as NFT data or DeFi transactions.
-
Aggregated indexers: These indexers extract data from multiple blockchains and sources, including off-chain information, and provide a unified query interface, which is particularly useful for multi-chain dApps.
Currently, the Archive Node in the archive mode in the Geth client occupies about 13.5 TB of storage space, while the archive requirement for the Erigon client is about 3 TB.As blockchain continues to grow, the amount of data storage of archive nodes will also increase.Faced with such a huge amount of data, the mainstream indexer protocol not only supports multi-chain indexing, but also customized a data analysis framework for data needs of different applications.For example, the “Subgraph” framework of The Graph is a typical case.
The emergence of indexers greatly improves the indexing and query efficiency of data.Compared with traditional RPC endpoints, the indexer can efficiently index large amounts of data and supports high-speed queries.These indexers allow users to perform complex queries, filter data easily, and analyze after extraction.In addition, some indexers also support aggregating data sources from multiple blockchains to avoid the need to deploy multiple APIs in multi-chain dApps.By running distributed across multiple nodes, the indexer not only provides greater security and performance, but also reduces the potential risk of interruptions and downtime from centralized RPC providers.
In contrast, the indexer uses a predefined query language to enable users to directly obtain the required information without processing the underlying complex data.This mechanism significantly improves the efficiency and reliability of data retrieval and is an important innovation in blockchain data access.
2.4 Full-chain database: prioritize the alignment to the flow
Querying data using inodes usually means that the API becomes the only portal for data on the digested chain.However, when a project enters the expansion phase, it often requires a more flexible data source, which is not available to standardized APIs.As application requirements become more complex, primary data indexers and their standardized index formats are gradually difficult to meet the increasingly diverse query needs, such as search, cross-chain access or off-chain data mapping.
In modern data pipeline architecture, the “stream first” approach has become a solution to the limitations of traditional batch processing, enabling real-time data ingestion, processing and analysis.This paradigm shift allows organizations to respond immediately to incoming data, resulting in almost instant insights and decisions.Similarly, the development of blockchain data service providers is also moving towards building blockchain data streams. Traditional indexer service providers have successively launched products that obtain real-time blockchain data through data streams, such as TheGraph’s Substreams, Goldsky’s Mirror, and real-time data lakes that generate data streams based on blockchains, such as Chainbase and SubSquid.
These services are designed to address the need to parse blockchain transactions in real time and provide more comprehensive query capabilities.Just as the “Flow First” architecture has revolutionized the way data processing and consumption in traditional data pipelines by reducing latency and enhancing responsiveness, these blockchain data streaming service providers also hope to support more advanced and mature data sources.Application development and assist on-chain data analysis.
Through the perspective of modern data pipelines, we are able to look at the full potential of on-chain management, storage and delivery of on-chain data from a completely new perspective.When we start to think of indexers such as subgraphs and Ethereum ETL as data streams in data pipelines rather than final outputs, we can imagine a possible world that can tailor high-performance datasets for any business use case.
3 AI + Database? In-depth comparison The Graph, Chainbase, Space and Time
3.1 The Graph
The Graph network implements multi-chain data indexing and query services through a decentralized node network, which promotes developers to conveniently index blockchain data and build decentralized applications.Its main product model is the market for data query execution and data index cache. These two markets are essentially serving users’ product query needs. The market for data query execution specifically refers to consumers choosing appropriate provisions for the required data.The inode of data is paid, while the data index cache market is the inode that mobilizes resource allocation based on the historical index popularity of the subgraph, the query fee charged, and the demand of the curator on the chain for the output of the subgraph.
Subgraphs are the basic data structures in The Graph network.They define how data can be extracted and converted from a blockchain into a queryable format (such as GraphQL schema).Anyone can create subgraphs and multiple applications can reuse them, which improves data reusability and efficiency.
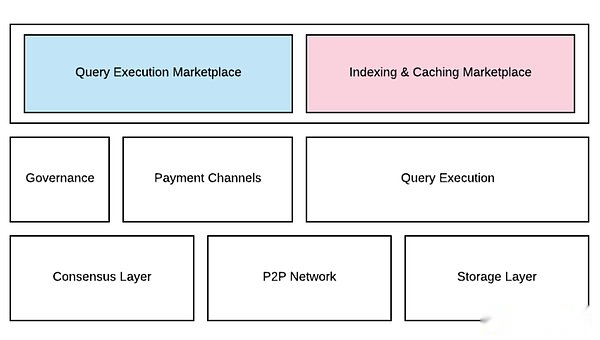
The Graph Product Structure (Source: The Graph Whitepaper)
The Graph network consists of four key roles: indexer, curator, client and developer, who work together to provide data support for web3 applications.Here are their respective responsibilities:
-
Indexer: The indexer is the node operator in The Graph network. The index section participates in the network by staking GRT (the native token of The Graph), providing indexing and query processing services.
-
Delegator: Delegator is those users who stake GRT tokens to inodes to support their operations.The principal earns a portion of the reward through the inodes they delegate.
-
Curator: The curator is responsible for which subgraphs of signals should be indexed by the network.Curators help ensure valuable subgraphs are prioritized.
-
Developer: Unlike the first three as suppliers, developers are the demanders and the main users of The Graph.They create and submit subgraphs to The Graph network, waiting for the network to meet the data required.

Currently, The Graph has turned to a comprehensive decentralized sub-graph hosting service, with economic incentives for circulation among different participants to ensure the system is running:
-
Inode Rewards: Inode earns revenue through consumer query fees and part of GRT token block rewards.
-
Principal Rewards: Principals receive partial rewards through the inodes they support.
-
Curator Rewards: If the curator signals a valuable subgraph, they can receive a partial reward from the query fee.
In fact, The Graph’s products are also growing rapidly in the wave of AI.As one of the core development teams in The Graph ecosystem, Semiotic Labs has been committed to leveraging AI technology to optimize index pricing and user query experience.Currently, the AutoAgora, Allocation Optimizer and AgentC tools developed by Semiotic Labs have improved the performance of the ecosystem in many aspects.
-
AutoAgora introduces a dynamic pricing mechanism to adjust prices in real time based on query volume and resource usage, optimize pricing strategies, and ensure the competitiveness and revenue of the indexer.
-
Allocation Optimizer solves the complex problem of subgraph resource allocation, helping indexers achieve optimal allocation of resources to improve revenue and performance.
-
AgentC is an experimental tool that allows users to access The Graph’s blockchain data through natural language, thereby enhancing the user experience.
The application of these tools allows The Graph to combine AI assistance to further improve the intelligence and user-friendliness of the system.
3.2 Chainbase
Chainbase is a full-chain data network that integrates all blockchain data into one platform to facilitate developers to build and maintain applications more easily.Its unique features include:
-
Real-time Data Lake: Chainbase provides a real-time data lake dedicated to blockchain data flows, so that data can be accessed instantly when generated.
-
Double-chain architecture: Chainbase builds an execution layer based on Eigenlayer AVS, forming a parallel double-chain architecture with CometBFT consensus algorithm.This design enhances the programmability and composability of cross-chain data, supports high throughput, low latency and finality, and improves network security through a dual staking model.
-
Innovative data format standards: Chainbase introduces a new data format standard called “manuscripts”, which optimizes the structure and utilization of data in the encryption industry.
-
Crypto World Model: With its huge blockchain data resources, Chainbase combines AI model technology to create an AI model that can effectively understand, predict and interact with blockchain transactions.Theia, the basic model, has been launched for public use.
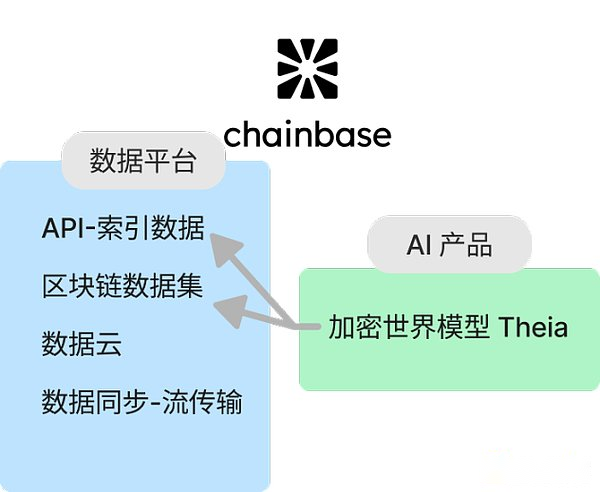
These capabilities make Chainbase stand out in the blockchain indexing protocol, focusing especially on real-time data accessibility, innovative data formats, and creating smarter models for insights through the combination of on-chain and off-chain data.
Chainbase’s AI model Theia is a key highlight that distinguishes it from other data service protocols.Theia is based on the DORA model developed by NVIDIA, combining on-chain and off-chain data and space-time activities to learn and analyze encryption modes, and respond through causal reasoning, thereby deeply exploring the potential value and laws of on-chain data and providing users with more intelligentdata services.
AI-enabled data services make Chainbase no longer just a blockchain data service platform, but a more competitive intelligent data service provider.Through powerful data resources and proactive analysis of AI, Chainbase can provide broader data insights and optimize users’ data processing processes.
3.3 Space and Time
Space and Time (SxT) aims to create a verifiable computing layer that extends zero-knowledge proof on decentralized data warehouses to provide trusted data processing for smart contracts, large language models and enterprises.Space and Time has received a latest round of $20 million in its Series A round led by Framework Ventures, Lightspeed Faction, Arrington Capital and Hivemind Capital.
In the field of data indexing and verification, Space and Time has introduced a new technological path – Proof of SQL.This is an innovative zero-knowledge proof (ZKP) technology developed by Space and Time to ensure that SQL queries executed on decentralized data warehouses are tamper-proof and verifiable.When running a query, Proof of SQL generates an encrypted proof that verifies the integrity and accuracy of the query results.This proof is attached to the query results, so that any verifier (such as smart contracts, etc.) can independently confirm that the data has not been tampered with during processing.Traditional blockchain networks usually rely on consensus mechanisms to verify the authenticity of data, and Space and Time’s Proof of SQL implements a more efficient way to verify data.Specifically, in Space and Time systems, one node is responsible for data acquisition, while other nodes verify the authenticity of the data through zk technology.This method changes the resource loss of multiple nodes repeatedly indexing the same data under the consensus mechanism and finally reaching a consensus to obtain the data, improving the overall performance of the system.As this technology matures, it has created a stepping stone for a series of traditional industries that focus on data reliability to use data structure products on blockchain.
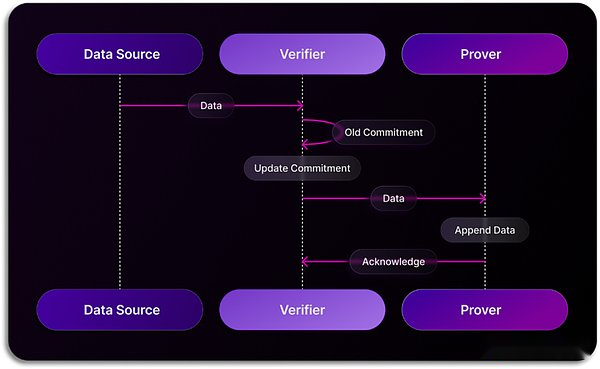
At the same time, SxT has been working closely with Microsoft AI Joint Innovation Lab to accelerate the development of integrated AI tools to make it easier for users to process blockchain data through natural language.Currently in Space and Time Studio, users can experience inputting natural language queries, and AI will automatically convert them to SQL and execute query statements on behalf of the user to present the final result the user needs.
3.4 Difference comparison

Conclusion and prospect
To sum up, blockchain data indexing technology has evolved from the initial node data source, through data analysis and indexer development, and finally evolved into AI-enabled full-chain data services, and has gone through a gradual improvement process.The continuous evolution of these technologies not only improves the efficiency and accuracy of data access, but also brings an unprecedented intelligent experience to users.
Looking ahead, with the continuous development of new technologies such as AI technology and zero-knowledge proof, blockchain data services will be further intelligent and secure.We have reason to believe that blockchain data services will continue to play an important role as infrastructure in the future, providing strong support for industry progress and innovation.