
1はじめに
2017年のDapps Etherol、Ethlend、Cryptokittiesの最初の波から、さまざまなブロックチェーンに基づいた現在のさまざまな財務、ゲーム、ソーシャルダップまで、分散型のチェーンアプリケーションについて話しています。これらのDappsが相互作用に採用したさまざまなデータのソース?
2024年、ホットスポットはAIとWeb3に焦点を当てます。植物が日光と湿気に依存して繁栄するように、AIシステムは膨大な量のデータにも依存して、絶えず「学習」し、「思考」します。データがなければ、AIのアルゴリズムがどれほど絶妙であっても、それは空中の城であり、その真の知性と効率を発揮することはできません。
このペーパーでは、ブロックチェーンデータアクセシビリティの観点から業界開発のプロセスにおけるブロックチェーンデータインデックスの進化を分析し、古いデータインデックス作成プロトコルとグラフと新興ブロックチェーンデータサービスプロトコルチェーンベースと時間と時間、類似点と違いを比較します。データサービスと製品アーキテクチャの特性におけるAIテクノロジーを組み合わせたこれら2つの新しいプロトコルについて説明します。
2従来のデータインデックス:ブロックチェーンノードからフルチェーンデータベースまで
2.1データソース:ブロックチェーンノード
「ブロックチェーンとは何か」について最初に学んだとき、この文はよく見られます。ブロックチェーンは分散型のアカウント帳です。ブロックチェーンノードは、ブロックチェーンネットワーク全体の基礎であり、チェーン上のすべてのトランザクションデータの記録、保存、および普及の責任を引き受けます。各ノードには、ブロックチェーンデータの完全なコピーがあり、ネットワークの分散特性が維持されるようにします。ただし、通常のユーザーにとっては、ブロックチェーンノードを自分で構築および維持するのは簡単ではありません。これには、専門的な技術的能力が必要であるだけでなく、高いハードウェアと帯域幅のコストも搭載されています。同時に、通常のノードクエリ機能は限られており、開発者が必要とする形式でデータをクエリすることはできません。したがって、誰もが理論的に独自のノードを実行できますが、実際には、ユーザーは通常、サードパーティサービスに依存する傾向があります。
この問題を解決するために、RPC(リモートプロシージャコール)ノードプロバイダーが出現しました。これらのプロバイダーは、ノードのコストと管理を担当し、RPCエンドポイントを介してデータを提供します。これにより、ユーザーは独自のノードを作成せずにブロックチェーンデータに簡単にアクセスできます。パブリックRPCエンドポイントは無料ですが、DAPPSのユーザーエクスペリエンスに悪影響を与える可能性のあるレート制限があります。プライベートRPCのエンドポイントは、混雑を減らすことでより良いパフォーマンスを提供しますが、単純なデータ取得でさえ、多くの前後のコミュニケーションが必要です。これにより、複雑なデータクエリに対して面倒で非効率的になります。さらに、プライベートRPCのエンドポイントをスケーリングするのが難しく、さまざまなネットワーク間の互換性が不足しています。ただし、ノードプロバイダーの標準化されたAPIインターフェイスにより、ユーザーはチェーン上のデータにアクセスするためのより低いしきい値を提供し、後続のデータ分析とアプリケーションの基礎を築きます。
2.2データ分析:プロトタイプデータから利用可能なデータまで
ブロックチェーンノードから取得したデータは、多くの場合、暗号化されエンコードされた生データです。これらのデータはブロックチェーンの完全性とセキュリティを保持していますが、それらの複雑さはデータ解析の難しさも増加させます。通常のユーザーまたは開発者の場合、これらのプロトタイプデータを直接処理するには、多くの技術的知識とコンピューティングリソースが必要です。
このコンテキストでは、データ解析のプロセスが特に重要です。複雑なプロトタイプデータをより理解しやすく操作された形式に解析することにより、ユーザーはこのデータをより直感的に理解し、利用できます。データ分析の成功は、ブロックチェーンデータアプリケーションの効率と有効性を直接決定し、データインデックスプロセス全体の重要なステップです。
2.3データインデクサーの進化
ブロックチェーンデータの量が増加するにつれて、データインデクサーの需要も増加しています。インデクサーは、チェーン上のデータを整理し、クエリを容易にするためにデータベースに送信する上で重要な役割を果たします。インデクサーの原則は、ブロックチェーンデータをインデックス化し、SQLのようなクエリ言語(GraphQLなどのAPI)を介して容易に利用できるようにすることです。データをクエリするための統一されたインターフェイスを提供することにより、インデクサーは開発者が標準化されたクエリ言語を使用して必要な情報を迅速かつ正確に取得できるようにし、プロセスを大幅に簡素化できます。
さまざまなタイプのインデクサーは、さまざまな方法でデータ検索を最適化します。
-
フルノードインデクサー:これらのインデクサーは、完全なブロックチェーンノードを実行し、データを直接抽出して、データが完全かつ正確であることを確認しますが、多くのストレージと処理能力が必要です。
-
軽量のインデクサー:これらのインデクサーは、必要に応じて特定のデータを取得するために完全なノードに依存して、ストレージ要件を削減しますが、クエリ時間を増やす可能性があります。
-
専用のインデクサー:これらのインデクサーは、特定の種類のデータまたは特定のブロックチェーン向けに特別に設計されており、NFTデータやDEFIトランザクションなどの特定のユースケースの取得を最適化します。
-
集約されたインデクサー:これらのインデクサーは、オフチェーン情報を含む複数のブロックチェーンとソースからデータを抽出し、マルチチェーンDAPPに特に役立つ統一クエリインターフェイスを提供します。
現在、GETHクライアントのアーカイブモードのアーカイブノードは約13.5 TBのストレージスペースを占有していますが、エリゴンクライアントのアーカイブ要件は約3 TBです。ブロックチェーンが成長し続けるにつれて、アーカイブノードのデータストレージの量も増加します。このような膨大な量のデータに直面して、主流のインデクサープロトコルはマルチチェーンインデックスをサポートするだけでなく、さまざまなアプリケーションのデータニーズに対応するデータ分析フレームワークをカスタマイズしました。たとえば、グラフの「サブグラフ」フレームワークは典型的なケースです。
インデクサーの出現により、データのインデックス作成とクエリの効率が大幅に向上します。従来のRPCエンドポイントと比較して、インデクサーは大量のデータを効率的にインデックス化し、高速クエリをサポートできます。これらのインデクサーにより、ユーザーは複雑なクエリを実行し、データを簡単にフィルタリングし、抽出後に分析できます。さらに、一部のインデクサーは、複数のブロックチェーンからのデータソースの集約化をサポートして、マルチチェーンDAPPに複数のAPIを展開する必要性を回避します。複数のノードに分配された実行により、インデクサーはより大きなセキュリティとパフォーマンスを提供するだけでなく、中央集中RPCプロバイダーからの中断とダウンタイムの潜在的なリスクを減らします。
対照的に、インデクサーは事前定義されたクエリ言語を使用して、ユーザーが基礎となる複雑なデータを処理せずに必要な情報を直接取得できるようにします。このメカニズムは、データ取得の効率と信頼性を大幅に改善し、ブロックチェーンデータアクセスの重要な革新です。
2.4フルチェーンデータベース:フローのアライメントを優先します
通常、INODEを使用してデータをクエリすることは、APIが消化されたチェーン上のデータの唯一のポータルになることを意味します。ただし、プロジェクトが拡張フェーズに入ると、多くの場合、より柔軟なデータソースが必要です。これは、標準化されたAPIが提供できないものです。アプリケーション要件がより複雑になるにつれて、一次データインデックス係とその標準化されたインデックス形式は、検索、クロスチェーンアクセス、オフチェーンデータマッピングなど、ますます多様化するクエリのニーズを満たすことが徐々に困難です。
<図>
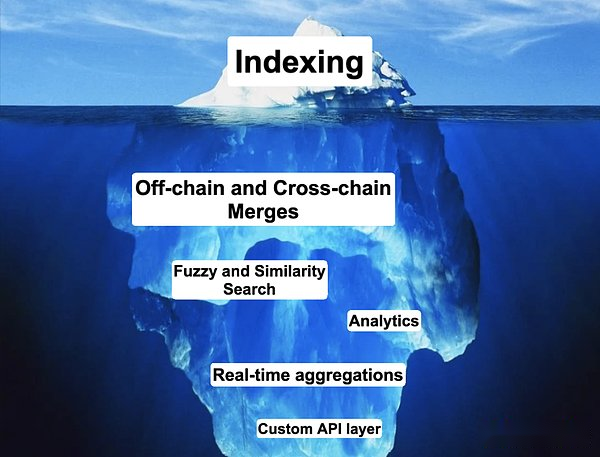
最新のデータパイプラインアーキテクチャでは、「Stream First」アプローチは、従来のバッチ処理の制限の解決策となり、リアルタイムのデータ摂取、処理、分析を可能にします。このパラダイムシフトにより、組織は着信データに直ちに対応することができ、ほぼ瞬時の洞察と決定が生まれます。同様に、ブロックチェーンデータサービスプロバイダーの開発は、グラフのサブストリーム、ゴールドスキーのミラー、リアルタイムなどのデータストリームを介してリアルタイムのブロックチェーンデータを取得する製品を継続的に発売しました。チェーンベースやサブキッドなどのブロックチェーンに基づいてデータストリームを生成するデータ湖。
これらのサービスは、ブロックチェーントランザクションをリアルタイムで解析し、より包括的なクエリ機能を提供する必要性に対処するように設計されています。「Flow First」アーキテクチャが、レイテンシを減らし、応答性を高めることにより、従来のデータパイプラインのデータ処理と消費に革命をもたらしたように、これらのブロックチェーンデータストリーミングサービスプロバイダーは、より高度で成熟したデータソースをサポートすることを望んでいます。チェーンデータ分析。
最新のデータパイプラインの観点を通して、完全に新しい観点からオンチェーン管理、保管、およびオンチェーンデータの配信の可能性を最大限に引き出すことができます。サブグラフやEthereum ETLなどのインデクサーを最終出力ではなくデータパイプラインのデータストリーミングと考え始めると、あらゆるビジネスケースの高性能データセットを調整できる世界を想像できます。
3 AI +データベースは、グラフ、チェーンベース、空間、時間を比較します
3.1グラフ
グラフネットワークは、分散型ノードネットワークを介してマルチチェーンデータのインデックス作成とクエリサービスを実装し、開発者がブロックチェーンデータを便利にインデックスを作成し、分散型アプリケーションを構築することを促進します。その主な製品は、データの実行とデータのクエリのニーズを基本的に提供していますデータインデックスキャッシュの市場は、サブグラフの歴史的なインデックスの人気、請求されたクエリ料金、およびオンチェーンキュレーターによるサブグラフ出力の需要に基づいてリソース割り当てを動員する市場です。
サブグラフは、グラフネットワーク内の基本的なデータ構造です。データを抽出してブロックチェーンからクエリ形式(GraphQLスキーマなど)に変換する方法を定義します。誰でもサブグラフを作成でき、複数のアプリケーションがそれらを再利用できるため、データの再利用性と効率が向上します。
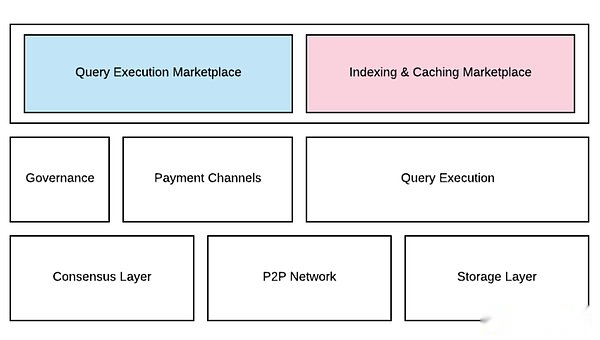
グラフ製品構造(出典:グラフホワイトペーパー)
グラフネットワークは、Web3アプリケーションのデータサポートを提供するために協力するインデクサー、キュレーター、クライアント、開発者の4つの重要な役割で構成されています。それぞれの責任は次のとおりです。
-
インデクサー:インデックスは、グラフネットワークのノード演算子です。インデックスセクションは、GRT(グラフのネイティブトークン)をステーキングして、インデックスおよびクエリ処理サービスを提供します。
-
委任者:委任者は、grtトークンを侵入してinodeを稼働させて操作をサポートするユーザーです。校長は、委任するノードを通じて報酬の一部を獲得します。
-
キュレーター:キュレーターは、ネットワークによって信号のサブグラフをインデックス作成する責任があります。キュレーターは、貴重なサブグラフが優先されるようにするのに役立ちます。
-
開発者:サプライヤーとしての最初の3人とは異なり、開発者は需要者であり、グラフの主なユーザーです。彼らはサブグラフを作成してグラフネットワークに送信し、ネットワークが必要なデータを満たすのを待っています。
<図>

現在、グラフは、システムが実行されていることを確認するために、さまざまな参加者間の流通のための経済的インセンティブを備えた包括的な分散型サブグラフホスティングサービスに変わりました。
-
INODEの報酬:INODEは、消費者のクエリ料金とGRTトークンブロックの報酬の一部を通じて収益を獲得します。
-
プリンシパルの報酬:プリンシパルは、サポートするノードを通じて部分的な報酬を受け取ります。
-
キュレーターの報酬:キュレーターが貴重なサブグラフを通知する場合、クエリ料金から部分的な報酬を受け取ることができます。
実際、グラフの製品もAIの波で急速に成長しています。グラフエコシステムのコア開発チームの1つとして、Semiotic Labsは、インデックスの価格設定とユーザークエリエクスペリエンスを最適化するためにAIテクノロジーを活用することに取り組んできました。現在、Semiotic Labsによって開発されたAutoagora、Alocation Optimizer、およびAgentCツールは、多くの面で生態系のパフォーマンスを改善しました。
-
Autoagoraは、クエリのボリュームとリソースの使用に基づいてリアルタイムで価格を調整するための動的価格設定メカニズムを導入し、価格設定戦略を最適化し、インデクサーの競争力と収益を確保します。
-
割り当てオプティマイザーは、サブグラフリソース割り当ての複雑な問題を解決し、インデクサーが収益とパフォーマンスを改善するためにリソースの最適な割り当てを達成するのを支援します。
-
AgentCは、ユーザーが自然言語を介してグラフのブロックチェーンデータにアクセスできるようにする実験ツールであり、それによりユーザーエクスペリエンスが向上します。
これらのツールを適用することで、グラフはAI支援を組み合わせて、システムのインテリジェンスとユーザーフレンドリーをさらに向上させることができます。
3.2チェーンベース
Chainbaseは、すべてのブロックチェーンデータを1つのプラットフォームに統合して、開発者がアプリケーションをより簡単に構築および維持できるようにするフルチェーンデータネットワークです。そのユニークな機能には次のものがあります。
-
リアルタイムのデータ湖:チェーンベースは、ブロックチェーンデータフロー専用のリアルタイムデータレイクを提供するため、生成時にデータに即座にアクセスできます。
-
ダブルチェーンアーキテクチャ:Chainbaseは、Eigenlayer AVSに基づいて実行レイヤーを構築し、CometBFTコンセンサスアルゴリズムを備えた並列ダブルチェーンアーキテクチャを形成します。この設計により、クロスチェーンデータのプログラマ性と複合性が向上し、高いスループット、低レイテンシ、最終性をサポートし、デュアルステーキングモデルを通じてネットワークセキュリティを改善します。
-
革新的なデータ形式標準:ChainBaseは、暗号化業界のデータの構造と利用を最適化する「原稿」と呼ばれる新しいデータ形式標準を導入します。
-
Crypto World Model:その巨大なブロックチェーンデータリソースにより、ChainbaseはAIモデルテクノロジーを組み合わせて、ブロックチェーントランザクションを効果的に理解、予測、相互作用できるAIモデルを作成します。基本モデルであるTheiaは、公的に使用するために開始されました。
<図>
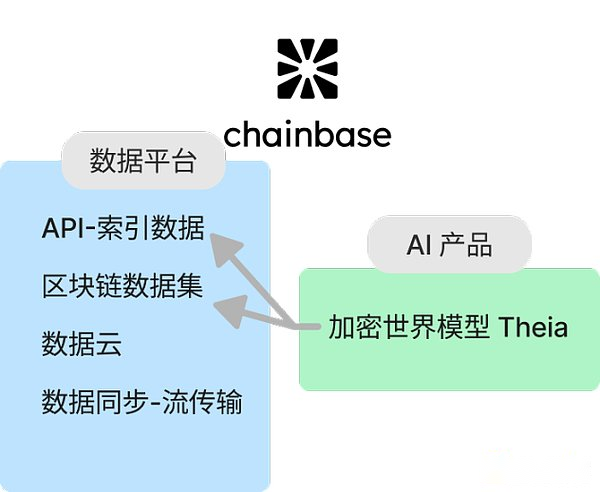
これらの機能により、チェーンベースはブロックチェーンインデックスプロトコルで際立っており、特にリアルタイムのデータアクセシビリティ、革新的なデータ形式、およびオンチェーンデータとオフチェーンデータの組み合わせを通じて洞察のためのよりスマートなモデルを作成します。
ChainbaseのAIモデルTheiaは、他のデータサービスプロトコルと区別する重要なハイライトです。Theiaは、Nvidiaによって開発されたDORAモデルに基づいており、オンチェーンと鎖のデータと時空アクティビティを組み合わせて、暗号化モードを学習および分析し、因果的推論を通じて対応し、それにより、鎖の潜在的な価値と法則を深く調査します。データとユーザーに、よりインテリジェントなデータサービスを提供します。
AI対応のデータサービスにより、Chainbaseは単なるブロックチェーンデータサービスプラットフォームではなく、より競争力のあるインテリジェントデータサービスプロバイダーになります。強力なデータリソースとAIの積極的な分析により、Chainbaseはより広範なデータ洞察を提供し、ユーザーのデータ処理プロセスを最適化できます。
3.3スペースと時間
Space and Time(SXT)は、分散型データウェアハウスのゼロ知識証明を拡張する検証可能なコンピューティングレイヤーを作成し、スマートコントラクト、大手言語モデル、企業の信頼できるデータ処理を提供することを目的としています。Space and Timeは、フレームワークベンチャー、Lightspeed Faction、Arrington Capital、Hivemind Capitalが率いるシリーズAラウンドで最新の2,000万ドルを受け取りました。
データのインデックス作成と検証の分野では、空間と時間が新しい技術パス – SQLの証明を導入しました。これは、空間と時間によって開発された革新的なゼロ知識証明(ZKP)テクノロジーであり、分散型のデータ倉庫で実行されたSQLクエリが改ざんされており、検証可能であることを保証します。クエリを実行すると、SQLの証明は、クエリ結果の整合性と精度を検証する暗号化された証明を生成します。この証明はクエリの結果に添付されているため、検証剤(スマートコントラクトなど)は、処理中にデータが改ざんされていないことを独立して確認できます。従来のブロックチェーンネットワークは通常、コンセンサスメカニズムに依存してデータの信頼性を検証し、SQLの空間と時間の証明は、データを検証するためのより効率的な方法を実装します。具体的には、空間および時間システムでは、1つのノードがデータ収集を担当し、他のノードはZKテクノロジーを介したデータの信頼性を検証します。この方法は、コンセンサスメカニズムの下で同じデータを繰り返しインデックスを作成し、最終的にデータを取得するコンセンサスに到達し、システムの全体的なパフォーマンスを改善する複数のノードのリソース損失を変更します。このテクノロジーが成熟するにつれて、ブロックチェーンでデータ構造製品を使用するデータの信頼性に焦点を当てた一連の従来の産業の足がかりを作り出しました。
<図>
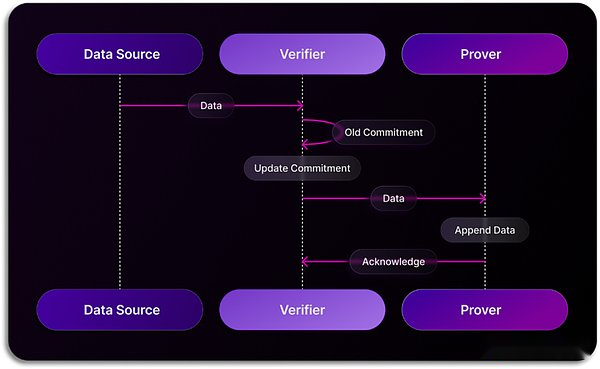
同時に、SXTはMicrosoft AI Joint Innovation Labと緊密に連携して、統合されたAIツールの開発を加速して、ユーザーが自然言語を通じてブロックチェーンデータを処理しやすくします。現在、Space and Time Studioでは、ユーザーは自然言語クエリの入力を経験できます。AIは自動的にSQLに変換し、ユーザーに代わってクエリステートメントを実行して、ユーザーが必要とする最終結果を表示します。
3.4差の比較
<図>

結論と見通し
要約すると、ブロックチェーンデータインデックステクノロジーは、初期ノードデータソースから、データ分析とインデクサー開発を通じて進化し、最終的にAI対応のフルチェーンデータサービスに進化し、徐々に改善プロセスを経ました。これらのテクノロジーの継続的な進化は、データアクセスの効率と精度を改善するだけでなく、ユーザーに前例のないインテリジェントエクスペリエンスをもたらします。
AIテクノロジーやゼロ認識証明などの新しいテクノロジーの継続的な開発により、ブロックチェーンデータサービスはさらにインテリジェントで安全になります。ブロックチェーンデータサービスが将来インフラストラクチャとして重要な役割を果たし続け、業界の進歩とイノベーションを強力にサポートすると信じる理由があります。







