Autor: Lucas Tcheyan, Arjun Yenamandra, Fuente: Galaxy Research, compilada por: Bittain Vision
Introducción
El año pasado, Galaxy Research publicó su primer artículo sobre la intersección de la criptomoneda e inteligencia artificial. El artículo explora cómo la criptomoneda sin confianza e infraestructura sin permiso puede convertirse en la base de la innovación de IA.Estos incluyen: la aparición de un mercado descentralizado para la potencia de procesamiento (o computación) que ha surgido en respuesta a la escasez de procesadores gráficos (GPU);Las primeras aplicaciones del aprendizaje automático de conocimiento cero (ZKML) en el razonamiento verificable en la cadena; y el potencial de los agentes de IA autónomos para simplificar las interacciones complejas y usar las criptomonedas como medio de intercambio nativo.
En ese momento, muchas de estas iniciativas estaban en su infancia, pero solo eran una prueba de conceptos convincente que implican que tenían ventajas prácticas sobre soluciones centralizadas, pero aún no se habían expandido lo suficiente como para remandar el panorama de la IA.Sin embargo, en el año desde entonces, la IA descentralizada ha hecho un progreso significativo para lograrlo.Para aprovechar este impulso y descubrir el progreso más prometedor, Galaxy Research lanzará una serie de artículos en el próximo año para explorar verticales específicas en las fronteras de cifrado + inteligencia artificial.
Este artículo se publicó por primera vez en capacitación descentralizada, centrándose en proyectos dedicados a implementar la capacitación sin permiso de modelos básicos a escala global.Las motivaciones para estos proyectos son duales.Desde una perspectiva práctica, reconocieron que una gran cantidad de GPU inactivas en todo el mundo se pueden utilizar para la capacitación de modelos, proporcionando a los ingenieros de IA en todo el mundo un proceso de capacitación insoportable y hacer realidad el desarrollo de IA de código abierto.Desde una perspectiva conceptual, estos equipos están motivados por el control estricto de una de las revoluciones tecnológicas más importantes de nuestro tiempo y la necesidad urgente de crear alternativas abiertas.
En términos más generales, para el campo de cifrado, la implementación de la capacitación descentralizada y posterior del modelo básico es un paso clave para construir una pila de IA completamente en cadena que no requiere permiso y se puede acceder en cada capa.El mercado de GPU puede acceder a modelos y proporcionar el hardware requerido para la capacitación e inferencia.Los proveedores de ZKML se pueden usar para verificar la salida del modelo y proteger la privacidad.Los agentes de IA pueden actuar como bloques de construcción compuestos que combinan modelos, fuentes de datos y protocolos en aplicaciones de orden superior.
Este informe explora la arquitectura subyacente del protocolo descentralizado de inteligencia artificial, los problemas técnicos que pretenden resolver y las perspectivas de capacitación descentralizada.La premisa subyacente de las criptomonedas e inteligencia artificial sigue siendo la misma que hace un año.Las criptomonedas proporcionan a la IA una capa de liquidación de transferencia de valor sin permiso, sin confianza y compuesta.El desafío ahora es demostrar que los enfoques descentralizados pueden generar ventajas prácticas sobre los enfoques centralizados.
Conceptos básicos de entrenamiento modelo
Antes de sumergirse en los últimos avances en capacitación descentralizada, es necesario tener una comprensión básica de los modelos de idiomas grandes (LLM) y su arquitectura subyacente.Esto ayudará a los lectores a comprender cómo funcionan estos proyectos y los principales problemas que están tratando de resolver.
Transformador
Los modelos de idiomas grandes (LLM) (como ChatGPT) están impulsados por una arquitectura llamada Transformer. Transformer propuso por primera vez en un Google Paper 2017 y es una de las innovaciones más importantes en el campo del desarrollo de inteligencia artificial.En resumen, el transformador extrae datos (llamados tokens) y aplica varios mecanismos para aprender la relación entre estos tokens.
La relación entre las entradas se modela utilizando pesos.Los pesos pueden considerarse como los millones de billones de perillas que componen el modelo, que se ajustan constantemente hasta que la siguiente entrada en la secuencia se puede predecir de manera consistente.Después de completar la capacitación, el modelo básicamente puede capturar los patrones y significados detrás del lenguaje humano.
Los componentes clave del entrenamiento del transformador incluyen:
-
Entrega hacia adelante:En el primer paso del proceso de capacitación, el transformador ingresa a un lote de tokens de un conjunto de datos más grande. Según estas entradas, el modelo intenta predecir cuál debería ser el siguiente token.Al comienzo del entrenamiento, los pesos del modelo son aleatorios.
-
Cálculo de pérdida:Las predicciones de propagación directa se utilizan para calcular la puntuación de pérdida, que mide la brecha entre estas predicciones y las marcas reales en el lote de datos original del modelo de entrada.En otras palabras, ¿cómo se comparan las predicciones producidas por el modelo durante la propagación directa con los marcadores reales utilizados para entrenarlo en el conjunto de datos más grande?Durante el entrenamiento, el objetivo es reducir este puntaje de pérdida para mejorar la precisión del modelo.
-
Backpropagation:El gradiente de cada peso se calcula utilizando la puntuación de pérdida.Estos gradientes le dicen al modelo cómo ajustar los pesos para reducir las pérdidas antes de la próxima propagación hacia adelante.
-
Optimizadorrenovar:OptimizarriñonalEl algoritmo lee estos gradientes y ajusta cada peso para reducir la pérdida.
-
repetir:Repita los pasos anteriores hasta que se hayan consumido todos los datos y el modelo comience a alcanzar la convergencia–En otras palabras, cuando la optimización adicional ya no resulta en una reducción significativa de pérdidas o una mejora del rendimiento.
Entrenamiento (pre-entrenamiento y posterior al entrenamiento)
El proceso completo de capacitación del modelo consta de dos pasos independientes: pretruamiento y post-entrenamiento. Los pasos anteriores son un componente central del proceso de pre-entrenamiento.Cuando se realizan, generan un modelo base previamente entrenado, comúnmente conocido como modelo base.
Sin embargo, los modelos a menudo requieren una mejora adicional después del previación, lo que se llama después del entrenamiento.El post-entrenamiento se utiliza para mejorar aún más el modelo base de varias maneras, incluida la mejora de su precisión o personalización para casos de uso específicos como la traducción o el diagnóstico médico.
El post-entrenamiento es un paso clave para hacer de los grandes modelos de idiomas (LLM) una herramienta poderosa hoy en día.Hay varias formas diferentes de entrenar después. Los dos más populares son:
-
Autorización supervisada (SFT):SFT es muy similar al proceso de pre-entrenamiento anterior.La principal diferencia es que el modelo básico está capacitado en conjuntos de datos o consejos y respuestas más cuidadosamente planificados, por lo que puede aprender a seguir instrucciones específicas o enfocarse en un campo determinado.
-
Aprendizaje de refuerzo (RL):RL no mejora el modelo ingresando nuevos datos, sino mediante la calificación de la salida del modelo y permitiendo que el modelo actualice el peso para maximizar esa recompensa. Recientemente, el modelo de inferencia (descrito a continuación) ha utilizado RL para mejorar su salida.En los últimos años, con los problemas de escala previa al entrenamiento que surgen, se han logrado un progreso significativo en el uso de modelos RL y de inferencia después del entrenamiento, ya que mejora significativamente el rendimiento del modelo sin datos adicionales o grandes cantidades de cálculo.
Específicamente, el entrenamiento posterior a la RL es ideal para resolver obstáculos enfrentados en el entrenamiento disperso (descrito a continuación).Esto se debe a que la mayor parte del tiempo en RL, el modelo usa pases hacia adelante (el modelo hace predicciones pero aún no se ha cambiado) para generar una gran cantidad de salida.Estos pases hacia adelante no requieren coordinación o comunicación entre máquinas y se pueden hacer de manera asincrónica.También son paralelos, lo que significa que se pueden dividir en subtareas independientes que se pueden realizar simultáneamente en múltiples GPU.Esto se debe a que cada despliegue se puede calcular de forma independiente y simplemente agregue el cálculo para aumentar el rendimiento a través de la ejecución de entrenamiento.Solo después de seleccionar la mejor respuesta, el modelo actualizará sus pesos internos, reduciendo la frecuencia a la que la máquina necesita ser sincronizada.
Después de capacitar al modelo, el proceso de usarlo para generar salida se llama inferencia.A diferencia del entrenamiento que requiere ajustes a millones o incluso miles de millones de pesos, el razonamiento mantiene estos pesos sin cambios y simplemente los aplica a nuevas entradas.Para los modelos de idiomas grandes (LLM), el razonamiento significa tomar un aviso, ejecutarlo a varias capas del modelo y paso a paso que predice el próximo marcado más probable.Dado que la inferencia no requiere backpropagation (el proceso de ajustar los pesos basados en el error del modelo) o las actualizaciones de peso, requiere mucho menos computacionalmente que la capacitación, pero debido a la gran escala de los modelos modernos, todavía tiene intensidad de recursos.
En resumen: el razonamiento es la fuerza impulsora detrás de aplicaciones como chatbots, asistentes de código y herramientas de traducción.En esta etapa, el modelo pone en práctica su «conocimiento aprendido».
Entrenamiento sobre la cabeza
La promoción del proceso de capacitación anterior requiere un software y hardware que intensifican en recursos y altamente especializados para ejecutar a escala.Las inversiones en los principales laboratorios de inteligencia artificial del mundo han alcanzado niveles sin precedentes, que van desde cientos de millones hasta miles de millones de dólares.El CEO de Openai, Sam Altman, dijo que el GPT-4 costó más de $ 100 millones, mientras que el CEO Anthrope Dario Amodei dijo que más de $ 1 mil millones en programas de capacitación ya están en marcha.
Una gran parte de estos costos proviene de las GPU.Las GPU superiores como H100 o B200 de NVIDIA cuestan hasta $ 30,000, y OpenAI, según los informes, planea desplegar más de un millón de GPU a fines de 2025. Sin embargo, no es suficiente tener el poder de la GPU solo.Estos sistemas deben implementarse en centros de datos de alto rendimiento equipados con infraestructura de comunicación de ultra alta velocidad.Las tecnologías como NVIDIA NVLink admiten un intercambio de datos rápidos entre las GPU dentro del servidor, mientras que Infiniband se conecta a los clústeres del servidor para que puedan ejecutarse como una estructura informática única y unificada.
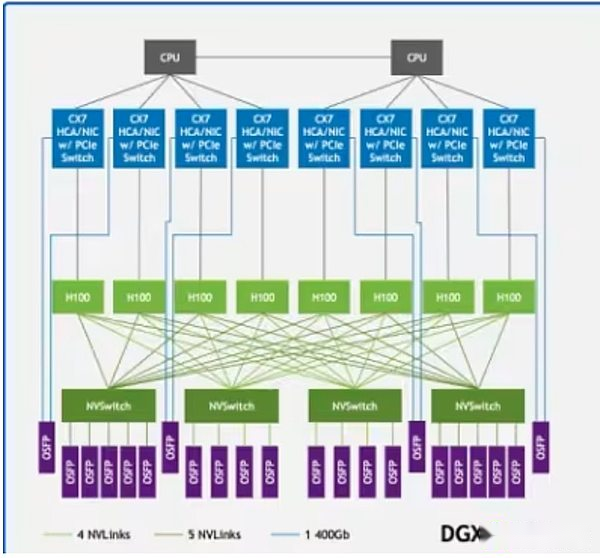 Nvlink en la arquitectura de muestra DGX H100 conecta las GPU (rectángulos de color verde claro) en el sistema, mientras que Infiniband conecta los servidores (líneas verdes) en una red unificada
Nvlink en la arquitectura de muestra DGX H100 conecta las GPU (rectángulos de color verde claro) en el sistema, mientras que Infiniband conecta los servidores (líneas verdes) en una red unificada
Por lo tanto, la mayoría de los modelos básicos son desarrollados por laboratorios de IA centralizados como OpenAI, Anthrope, Meta, Google y XAI. Solo tales gigantes tienen los ricos recursos necesarios para la capacitación.Aunque esto ha provocado un avance significativo en el entrenamiento y el rendimiento del modelo, también ha concentrado el control sobre el desarrollo de modelos básicos líderes en manos de algunas entidades.Además, existe una creciente evidencia de que la ley de escala puede estar funcionando, lo que limita la efectividad de mejorar la inteligencia de los modelos previos a la aparición simplemente agregando cálculo o datos.
Para abordar este desafío, en los últimos años, un grupo de ingenieros de IA ha comenzado a desarrollar nuevos métodos de capacitación de modelos para tratar de abordar estas complejidades técnicas y reducir enormes requisitos de recursos.Este artículo llama a este esfuerzo «capacitación descentralizada».
Capacitación descentralizada y distribuida
El éxito de Bitcoin demuestra que la informática y el capital pueden coordinarse de manera descentralizada, asegurando así la seguridad de las grandes redes económicas.La capacitación descentralizada tiene como objetivo construir una red descentralizada utilizando las características de las criptomonedas, incluidos mecanismos sin permiso, sin confianza e incentivos, para capacitar un modelo básico poderoso comparable a los proveedores centralizados.
En capacitación descentralizada, los nodos ubicados en diferentes lugares de todo el mundo trabajan en redes incentivadas e incentivadas sin permiso, que contribuyen a la capacitación de modelos de inteligencia artificial.Esto es diferente de la capacitación distribuida, que se refiere al modelo entrenado en diferentes regiones, pero que se realiza una o más entidades que tienen licencia (es decir, a través de un proceso de lista blanca).Sin embargo, la viabilidad de la capacitación descentralizada debe basarse en la capacitación distribuida.Muchos laboratorios centralizados, conscientes de las limitaciones estrictas de sus entornos de capacitación, han comenzado a explorar formas de implementar la capacitación distribuida para lograr resultados comparables a los entornos existentes.
Hay algunos obstáculos prácticos que evitan que la capacitación descentralizada se convierta en una realidad:
-
Overhead de comunicación:Cuando los nodos se dispersan geográficamente, no pueden acceder a la infraestructura de comunicación anterior.El entrenamiento descentralizado requiere la consideración de la velocidad de red estándar, la transmisión frecuente de grandes cantidades de datos y la sincronización de GPU durante el entrenamiento.
-
verificar:Las redes de capacitación descentralizadas están esencialmente libres de licencias y están diseñadas para permitir que cualquier persona contribuya con su poder informático.Por lo tanto, deben desarrollar mecanismos de verificación para evitar que los contribuyentes intenten destruir la red a través de entradas incorrectas o maliciosas, o explotar vulnerabilidades del sistema para obtener recompensas sin contribuir con un trabajo efectivo.
-
calcular: Independientemente del tamaño, las redes descentralizadas deben reunir suficiente potencia informática para entrenar modelos.Si bien esto ofrece algunas de las ventajas de las redes descentralizadas, que fueron diseñadas para permitir que cualquier persona con una GPU participe en el proceso de capacitación, también trae complejidad, ya que estas redes deben coordinar la computación heterogénea.
-
Incentivos/financiación/propiedad y monetización:Las redes de capacitación descentralizadas deben diseñar mecanismos de incentivos y modelos de propiedad/monetización para garantizar efectivamente la integridad de la red y recompensar la contribución de los proveedores de computación, validadores y diseñadores de modelos.Esto está en marcado contraste con el laboratorio centralizado donde la construcción y la monetización del modelo son realizadas por una empresa.
A pesar de estas limitaciones, muchos proyectos todavía están implementando capacitación descentralizada porque creen que el control del modelo subyacente no debería estar en manos de algunas compañías.Su objetivo es lidiar con los riesgos planteados por la capacitación centralizada, como fallas de un solo punto debido a la dependencia de algunos productos centralizados;privacidad de datos y censura; escalabilidad;y consistencia y sesgo en la inteligencia artificial. En términos más generales, creen que el desarrollo de inteligencia artificial de código abierto es una necesidad, no opcional.Sin una infraestructura abierta y verificable, la innovación será suprimida, el acceso se limitará a algunas clases privilegiadas, y la sociedad heredará sistemas AI formados por incentivos corporativos estrechos.Desde esta perspectiva, la capacitación descentralizada no se trata solo de construir modelos competitivos, sino también de crear un ecosistema resistente, transparente y participativo que refleje intereses colectivos en lugar de intereses propietarios.
Descripción general del proyecto
A continuación, daremos una visión general en profundidad de los mecanismos subyacentes de varios proyectos de capacitación descentralizados.
Nous resort
fondo
Fundada en 2022, Nous Research es una institución de investigación de IA de código abierto. El equipo comenzó como un grupo informal de investigadores y desarrolladores de IA de código abierto que trabajan para abordar las limitaciones del código de IA de código abierto.Su misión es «crear y proporcionar el mejor modelo de código abierto».
El equipo ha considerado durante mucho tiempo el entrenamiento descentralizado como un obstáculo importante.Específicamente, se dieron cuenta de que las herramientas para acceder a las GPU y para coordinar la comunicación entre las GPU se desarrollaron principalmente para atender a grandes empresas de IA centralizadas, que dejaron organizaciones con recursos limitadas con poco espacio para participar en un desarrollo significativo.Por ejemplo, las últimas GPU de Blackwell de NVIDIA (como la B200) pueden comunicarse entre sí utilizando un sistema de conmutación NVLink a velocidades de hasta 1.8 TB por segundo.Esto es comparable al ancho de banda total de la infraestructura de Internet convencional y solo se puede lograr en implementaciones centralizadas de centro de datos a escala.Por lo tanto, es casi imposible que las redes pequeñas o distribuidas alcancen el rendimiento de los grandes laboratorios de IA sin repensar las estrategias de comunicación.
Antes de embarcarse en resolver el problema de la capacitación descentralizada, Nous ha hecho contribuciones significativas al campo de la inteligencia artificial.En agosto de 2023, Nous publicó «Hilo: extensión de ventana de contexto eficiente para modelos de idiomas grandes».Este documento resuelve un problema simple pero importante: la mayoría de los modelos de IA solo pueden recordar y procesar una cantidad fija de texto a la vez (es decir, su «ventana de contexto»).Por ejemplo, un modelo entrenado con un límite de 2,000 palabras pronto comenzará a olvidar o perder información si el documento de entrada es más largo.El hilo introduce una forma de extender esta limitación aún más sin volver a capacitar el modelo desde cero.Ajusta cómo el modelo rastrea la posición de las palabras (como los marcadores en un libro) para que aún pueda rastrear el flujo de información, incluso si el texto es decenas de miles de palabras de largo.El método permite que el modelo procese secuencias de hasta 128,000 marcadores, sobre la longitud de las aventuras de Mark Twain de Huckleberry Finn, utilizando mucho menos potencia computacional y datos de entrenamiento al mismo tiempo que el método anterior.En resumen, el hilo permite que los modelos de IA «lean» y comprendan documentos, conversaciones o conjuntos de datos más largos a la vez.Este es un avance importante en la expansión de las capacidades de IA y ha sido adoptado por una comunidad de investigación más amplia que incluye OpenAI y Deepseek en China.
Demostración y distribución
En marzo de 2024, Nous publicó un avance en el campo de la capacitación distribuida llamada «Optimización de impulso desacoplada» (demo). La demostración fue desarrollada por los investigadores de Nous Bowen Peng y Jeffrey Quesnelle en colaboración con Diederik P. Kingma, cofundador de OpenAi e Inventor de Adamw Optimizer.Es el principal bloque de construcción de la pila de capacitación descentralizada de Nous, lo que reduce la sobrecarga de comunicación en la configuración de capacitación del modelo paralelo de datos distribuidos al reducir la cantidad de datos intercambiados entre GPU.En el entrenamiento paralelo de datos, cada nodo guarda una copia completa de los pesos del modelo, pero el conjunto de datos se divide en bloques procesados por diferentes nodos.
ADAMW es uno de los optimizadores más utilizados en el entrenamiento modelo.Una función clave de ADAMW es suavizar lo que se llama Momentum, el promedio de ejecución de los pesos del modelo que cambian en el pasado.Esencialmente, ADAMW ayuda a eliminar el ruido introducido durante el entrenamiento paralelo de datos, mejorando así la eficiencia del entrenamiento.Nous Research crea un optimizador completamente nuevo basado en Adamw y demostración, dividiendo impulso en piezas locales y compartidas en diferentes entrenadores.Esto reduce la cantidad de tráfico requerido entre los nodos al limitar la cantidad de datos que deben compartirse entre los nodos.
La demostración se centra selectivamente en los parámetros de más rápido cambio durante cada iteración de GPU.La lógica es simple: los parámetros con variaciones más grandes son cruciales para el aprendizaje y deben sincronizarse entre los trabajadores con mayor prioridad.Al mismo tiempo, los parámetros de cambio más lento pueden retrasarse temporalmente sin afectar significativamente la convergencia.De hecho, esto filtra las actualizaciones de ruido mientras se conserva las actualizaciones más significativas.Nous también utiliza técnicas de compresión, incluido un método de transformación de coseno discreto (DCT) similar a las imágenes comprimidas JPEG para reducir aún más la cantidad de datos enviados.Al sincronizar solo las actualizaciones más importantes, la demostración reduce la sobrecarga de comunicación en 10 a 1,000 veces (dependiendo del tamaño del modelo).
En junio de 2024, el equipo de Nous lanzó su segunda gran innovación, el Optimizador de capacitación distribuida (Distro).Demo ofrece innovaciones de optimizadores centrales, mientras que la distribución lo integra en un marco de optimizador más amplio que comprime aún más la información compartida entre GPU y aborda problemas como la sincronización de GPU, la tolerancia a fallas y el equilibrio de carga.En diciembre de 2024, Nous usó distribución para entrenar un modelo con 15 mil millones de parámetros en una arquitectura similar a la llama, lo que demuestra la viabilidad del método.
Psique
En mayo, Nous lanzó Psique, un marco para coordinar la capacitación descentralizada, más innovaciones en la demostración y las arquitecturas de optimizador de distribución. Las principales actualizaciones técnicas de Psique incluyen capacitación asincrónica mejorada al permitir que la GPU envíe actualizaciones del modelo al comenzar el siguiente paso de capacitación.Esto minimiza el tiempo de inactividad y acerca la utilización de la GPU a los sistemas centralizados y bien acoplados.Psique mejoró aún más la tecnología de compresión introducida por Distro, reduciendo aún más la carga de comunicación en 3 veces.
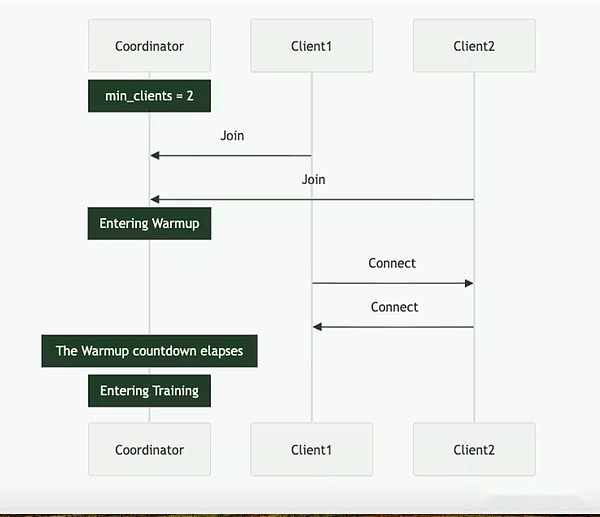
La psique se puede lograr a través de una configuración totalmente en cadena (a través de Solana) o fuera de la cadena.Contiene tres actores principales: el coordinador, el cliente y el proveedor de datos.El Coordinador almacena toda la información necesaria para facilitar la operación de capacitación, incluido el último estado del modelo, clientes participantes y asignación de datos y verificación de salida.El cliente es el proveedor real de GPU que realiza tareas de capacitación durante las ejecuciones de capacitación.Además de la capacitación modelo, están involucrados en el proceso de testigos (descrito a continuación).El proveedor de datos (el cliente puede almacenarlo por sí mismo) proporciona los datos necesarios para la capacitación.
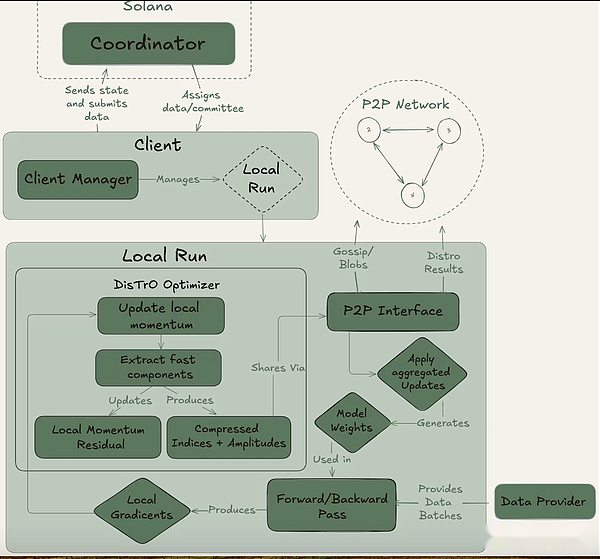 La psique divide el entrenamiento en dos etapas diferentes: época y paso.Esto crea puntos de entrada y salida naturales para los clientes para que puedan participar sin invertir en una carrera de capacitación completa.Esta estructura ayuda a minimizar los costos de oportunidad para los proveedores de GPU, ya que es posible que no puedan invertir recursos durante la ejecución.
La psique divide el entrenamiento en dos etapas diferentes: época y paso.Esto crea puntos de entrada y salida naturales para los clientes para que puedan participar sin invertir en una carrera de capacitación completa.Esta estructura ayuda a minimizar los costos de oportunidad para los proveedores de GPU, ya que es posible que no puedan invertir recursos durante la ejecución.
Al comienzo de una época, el coordinador define los parámetros clave: la arquitectura del modelo, el conjunto de datos que se utilizará y el número de clientes requeridos.La siguiente es una breve fase de calentamiento, donde el cliente se sincronizará con el último punto de control del modelo, que puede ser de una fuente pública o de otros clientes sincronización punto a punto.Después de que comience la capacitación, a cada cliente se le asignará una parte de los datos y se capacitará localmente.Después de la actualización del cálculo, el cliente transmite sus resultados al resto de la red junto con la promesa de cifrado (el hash SHA-256 que demuestra que el trabajo se realiza correctamente).
Una parte del cliente se selecciona al azar como testigos en cada ronda y sirve como el principal mecanismo de verificación de Psique.Estos testigos entrenan como de costumbre, pero también verifican qué actualizaciones del cliente se reciben y son válidas.Envían filtros Bloom al Coordinador, una estructura de datos liviana que resume efectivamente estas participaciones.Si bien el propio Nous admite que el enfoque no es perfecto porque puede producir falsos positivos, los investigadores están dispuestos a aceptar esta compensación por la eficiencia.Una vez que un testigo actualizado confirma que el quórum llega, el coordinador aplica la actualización al modelo global y permite a todos los clientes sincronizar su modelo antes de ingresar a la siguiente ronda.
Crucialmente, el diseño de Psyche permite una superposición en el entrenamiento y la verificación.Una vez que el cliente envía la actualización, puede comenzar inmediatamente a capacitar al siguiente lote sin esperar a que el coordinador u otros clientes complete la ronda de capacitación anterior.Este diseño superpuesto, combinado con la tecnología de compresión de Distro, asegura que la sobrecarga de comunicación se mantenga mínima y que la GPU no esté inactiva.
 En mayo de 2025, Nous Research lanzó la mayor realización de capacitación hasta la fecha: Consilience, un transformador con 40 mil millones de parámetros, pretruando aproximadamente 20 billones de tokens en la red de entrenamiento descentralizado de psique.El entrenamiento aún está en progreso.Hasta ahora, la operación ha sido básicamente estable, pero se han producido algunos picos de pérdida, lo que indica que la trayectoria de optimización se ha desviado brevemente de la convergencia.Para hacer esto, el equipo regresó al último punto de control de salud y encapsuló el optimizador utilizando la protección del paso de omisión de Olmo, que omite automáticamente cualquier actualización de cualquier norma de pérdida o gradiente que difiera en varias desviaciones estándar de la media, reduciendo el riesgo de picos futuros.
En mayo de 2025, Nous Research lanzó la mayor realización de capacitación hasta la fecha: Consilience, un transformador con 40 mil millones de parámetros, pretruando aproximadamente 20 billones de tokens en la red de entrenamiento descentralizado de psique.El entrenamiento aún está en progreso.Hasta ahora, la operación ha sido básicamente estable, pero se han producido algunos picos de pérdida, lo que indica que la trayectoria de optimización se ha desviado brevemente de la convergencia.Para hacer esto, el equipo regresó al último punto de control de salud y encapsuló el optimizador utilizando la protección del paso de omisión de Olmo, que omite automáticamente cualquier actualización de cualquier norma de pérdida o gradiente que difiera en varias desviaciones estándar de la media, reduciendo el riesgo de picos futuros.
El papel de Solana
Si bien la psique puede funcionar en un entorno fuera de la cadena, está diseñado para usarse en la cadena de bloques de Solana.Solana actúa como la capa de confianza y responsabilidad para la red de capacitación, registrando compromisos de clientes, pruebas de testigos y metadatos de capacitación en la cadena.Esto crea un rastro de auditoría inmutable para cada ronda de entrenamiento, lo que permite la verificación transparente de quién hizo contribuciones, qué trabajo se hizo y si pasó.
Nous también planea usar Solana para facilitar la distribución de las recompensas de capacitación.Aunque el proyecto no ha publicado una economía formal de token, la documentación de Psique describe un sistema en el que el coordinador rastreará las contribuciones computacionales del cliente y asignará puntos basados en el trabajo validado.Estos puntos se pueden intercambiar por tokens actuando como contratos inteligentes financieros cazados en la cadena. Los clientes que completan pasos de capacitación efectivos pueden recibir recompensas directamente del contrato en función de sus contribuciones. Psique aún no ha utilizado el mecanismo de recompensa en la ejecución de la capacitación, pero una vez que se lanzó oficialmente, se espera que el sistema desempeñe un papel central en la asignación de tokens criptográficos nous.
Serie Model de Hermes
Además de estas contribuciones de investigación, Nous ha establecido su estado de desarrollador de modelos de código abierto líder con su serie Hermes de modelos de idiomas grandes ajustados a instrucciones (LLM).En agosto de 2024, el equipo lanzó Hermes-3, una suite modelo de parámetro completo ajustado basado en Llama 3.1, que ha logrado resultados competitivos en la clasificación pública, aunque relativamente pequeña, comparable a los modelos propietarios más grandes.
Recientemente, Nous lanzó la serie Model Hermes-4 en agosto de 2025, la serie de modelos más avanzada hasta la fecha.Hermes-4 se enfoca en mejorar las capacidades de razonamiento paso a paso del modelo, al tiempo que se desempeña excelentemente en la ejecución regular de instrucciones.Se desempeñó bien en matemáticas, programación, comprensión y pruebas de sentido común.El equipo se adhiere a la misión de código abierto de Nous y libera públicamente todos los pesos de modelo Hermes-4 para que todos los usen y construyan. Además, Nous ha lanzado una interfaz de accesibilidad modelo llamada Nous Chat, que estará disponible de forma gratuita dentro de la primera semana de lanzamiento.
El lanzamiento del modelo Hermes no solo consolida la credibilidad de Nous como una organización de construcción de modelos, sino que también proporciona una validación práctica para su agenda de investigación más amplia.Cada lanzamiento de Hermes demuestra que las capacidades de vanguardia se pueden lograr en un entorno abierto, estableciendo las bases para los avances de capacitación descentralizados de los equipos (demostración, distribución y psique) y, en última instancia, lo que lleva a la ambiciosa ejecución de consiliencia 40B.
Atropos
Como se mencionó anteriormente, el aprendizaje de refuerzo juega un papel cada vez más importante en el post-entrenamiento debido a los avances en los modelos de inferencia y las limitaciones de expansión del pre-entrenamiento.Atropos es la solución de Nous para el aprendizaje de refuerzo en un entorno descentralizado.Es un marco de aprendizaje de refuerzo modular con plug-and-play para LLM, adaptándose a diferentes backends de inferencia, métodos de capacitación, conjuntos de datos y entornos de aprendizaje de refuerzo.
Cuando el aprendizaje posterior a la refuerzo se capacita de manera descentralizada utilizando una gran cantidad de GPU, la producción instantánea generada por el modelo durante el entrenamiento tendrá diferentes tiempos de finalización.Atropos actúa como un procesador de implementación, es decir, un coordinador central, que coordina la generación y finalización de tareas entre los dispositivos, permitiendo así la capacitación de aprendizaje de refuerzo asíncrono.
La versión inicial de Atropos se lanzó en abril, pero actualmente contiene solo un marco ambiental que coordina las tareas de aprendizaje de refuerzo. Nous planea lanzar un marco complementario de capacitación y razonamiento en los próximos meses.
Intelecto principal
fondo
Fundada en 2024, Prime Intellect se compromete a construir una infraestructura de desarrollo de IA descentralizada a gran escala.Fundado por Vincent Weisser y Johannes Hagemann, el equipo inicialmente se centró en integrar los recursos informáticos de proveedores centralizados y descentralizados para apoyar la capacitación distribuida colaborativa de modelos AI avanzados.La misión de Prime Intellect es democratizar el desarrollo de la IA, permitiendo a los investigadores y desarrolladores de todo el mundo acceder a recursos informáticos escalables y poseer conjuntamente la innovación abierta de IA.
Opendiloco, Intellect-1 y Prime
En julio de 2024, Prime Intellect lanzó Opendiloco, una versión de código abierto de Diloco, un método de entrenamiento de modelos de baja comunicación desarrollado por Google Deepmind para la capacitación paralela de datos.Google desarrolló el modelo basado en la opinión de que «la capacitación a través de la backpropagación estándar a una escala moderna presenta desafíos de ingeniería e infraestructura sin precedentes … es difícil coordinar y sincronizar de cerca una gran cantidad de aceleradores».Si bien esta declaración se centra en la practicidad de la capacitación a gran escala en lugar del espíritu del desarrollo de código abierto, el valor predeterminado a las limitaciones de la capacitación centralizada a largo plazo y la necesidad de alternativas distribuidas.
Diloco reduce la frecuencia y la cantidad de información compartida entre las GPU cuando los modelos de entrenamiento.En entornos centralizados, las GPU comparten todos los gradientes actualizados entre sí después de cada paso de entrenamiento. En Diloco, la frecuencia de intercambio de los gradientes de actualización es menor para reducir la sobrecarga de comunicación.Esto crea una arquitectura de optimización dual: las GPU individuales (o grupos de GPU) ejecutan optimizaciones internas, actualizando el peso de sus propios modelos después de cada paso; y optimizaciones externas, las optimizaciones internas se comparten entre las GPU, y todas las GPU se actualizan en función de los cambios realizados.
Opendiloco demostró del 90% al 95% de la utilización de GPU en su liberación inicial, lo que significa que a pesar de ser distribuido en dos continentes y tres países, pocas máquinas están inactivas.Opendiloco puede reproducir resultados y rendimiento de entrenamiento considerables, mientras que el volumen de tráfico se reduce en 500 veces (como se muestra en la línea púrpura que se pone al día con la línea azul en la figura a continuación).
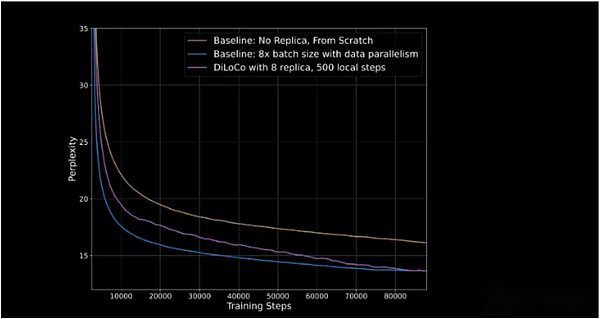
El eje vertical representa la perplejidad, que mide la capacidad del modelo para predecir el siguiente marcador en una secuencia.Cuanto menor sea la perplejidad, más segura son las predicciones del modelo, y mayor es la precisión.
En octubre de 2024, Prime Intellect comienza a entrenar intelecto-1, este es el primer modelo de lenguaje de parámetros de 10 mil millones entrenado de manera distribuida. La capacitación tomó 42 días, y el modelo fue abierto después de eso. La capacitación se realiza en cinco países en tres continentes.La ejecución de la capacitación demuestra la mejora gradual de la capacitación distribuida, con la tasa de utilización de todos los recursos informáticos que alcanzan el 83%, y solo en los Estados Unidos, la tasa de utilización de la comunicación entre nodo alcanza el 96%.La GPU utilizada por este proyecto proviene de los proveedores de Web2 y Web3, incluidos los mercados de GPU criptográficos como Akash, Hyperbolic y OLAS.
Intellect-1 adopta el nuevo marco de capacitación de Prime Intellect Prime, que permite que los sistemas de capacitación de intelectos primarios se adapten al calcular la entrada inesperada y la salida continua.Presenta tecnologías innovadoras como ElasticDevicemesh, lo que permite a los contribuyentes unirse o salir en cualquier momento.
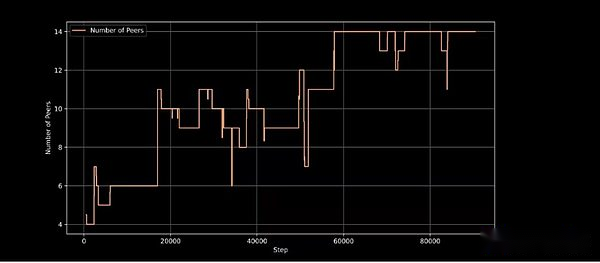
Nodos de entrenamiento activo en el paso de entrenamiento, demostrando la capacidad de la arquitectura de entrenamiento para manejar la participación de nodo dinámico
Intellect-1 es una validación importante del enfoque de entrenamiento descentralizado de Prime Intellect y ha sido elogiado por líderes de pensamiento de IA como Jack Clark (cofundador de Anthrope), y se considera una demostración viable de capacitación descentralizada.
Protocolo
En febrero de este año, Prime Intellect agregó otra capa a su pila, lanzando el protocolo.El protocolo conecta todas las herramientas de capacitación del intelecto principal para crear una red punto a punto para la capacitación de modelos descentralizados.Estos incluyen:
-
Calcula la GPU de conmutación para facilitar las carreras de entrenamiento.
-
El marco de capacitación principal reduce la sobrecarga de comunicación y mejora la tolerancia a las fallas.
-
Una biblioteca de código abierto llamada Genesys para una útil generación de datos sintéticos y validación en el ajuste fino RL.
-
Un sistema de verificación liviano llamado TopLoc para validar la salida de ejecución del modelo y nodos participantes.
El papel del protocolo es similar a la psique de Nous, con cuatro actores principales:
-
Trabajadores: un software que permite a los usuarios contribuir con sus recursos informáticos a la capacitación u otros productos relacionados con la IA de intelecto principal.
-
Verificador: verificar las contribuciones computacionales y prevenir el comportamiento malicioso.Prime Intellect está trabajando para aplicar el algoritmo de verificación de inferencia de vanguardia a la formación descentralizada.
-
Orchestrator: una forma de calcular los creadores de piscinas gestionan a los trabajadores.Funciona de manera similar al ‘orquestador de nous.
-
Contratos inteligentes: rastree los proveedores de recursos informáticos, reduzca la participación de los participantes maliciosos y pague recompensas de forma independiente.Actualmente, Prime Intellect se está ejecutando en la red de prueba Sepolia para Ethereum L2 Base, pero Prime Intellect ha declarado que eventualmente planeará migrar a su propia cadena de bloques.
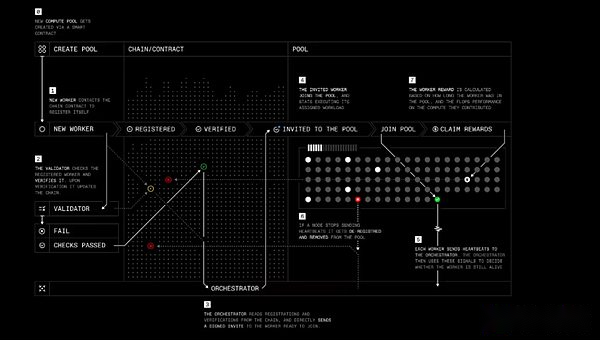 Entrenamiento de protocolo paso a paso
Entrenamiento de protocolo paso a paso
El protocolo tiene como objetivo permitir en última instancia a los contribuyentes propios acciones en el modelo o recibir recompensas por su trabajo, al tiempo que proporciona proyectos de IA de código abierto con nuevas formas de financiar y administrar el desarrollo a través de contratos inteligentes e incentivos colectivos.
Intelecto 2 y aprendizaje de refuerzo
En abril de este año, Prime Intellect comenzó a entrenar un modelo de parámetros de 32 mil millones llamado Intellect-2.Intellect-1 se centra en la capacitación del modelo básico, mientras que Intellect-2 utiliza el aprendizaje de refuerzo para entrenar modelos de inferencia en otro modelo de código abierto (QWQ-32B de Alibaba).
El equipo introdujo dos componentes críticos de infraestructura para que esta capacitación RL descentralizada sea práctica:
-
Prime-RL es un marco de aprendizaje de refuerzo completamente asincrónico que divide el proceso de aprendizaje en tres etapas independientes: generar respuestas candidatas; capacitación de respuestas seleccionadas; y transmisión de pesos de modelo actualizados.Este mecanismo de desacoplamiento permite que el sistema abarque redes poco confiables, lentas o distribuidas geográficamente.El proceso de capacitación utiliza otra innovación del intelecto principal, Genesys, para generar miles de preguntas matemáticas, lógicas y de codificación, y está equipado con un verificador automático que puede decir inmediatamente si la respuesta es correcta o no.
-
Shardcast es un nuevo sistema para distribuir rápidamente archivos grandes (como pesos de modelos actualizados) en la red.Shardcast No todas las máquinas descargan actualizaciones del servidor central, pero adopta una estructura que comparte actualizaciones entre máquinas.Esto mantiene la red eficiente, rápida y resistente.
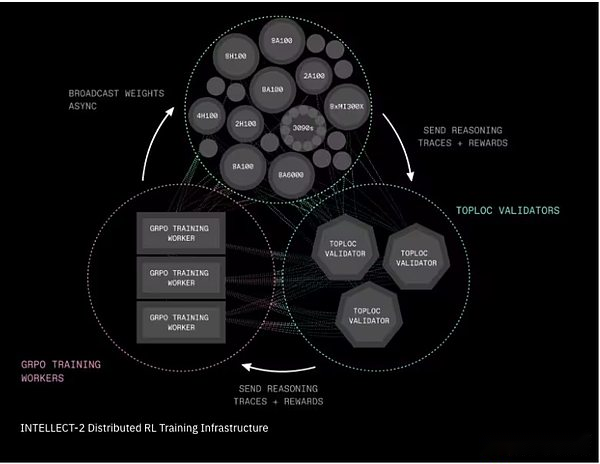 Intelecto-2 Infraestructura de capacitación de aprendizaje de refuerzo distribuido
Intelecto-2 Infraestructura de capacitación de aprendizaje de refuerzo distribuido
Para Intellect-2, los contribuyentes también necesitan apostar el token de cripto de prueba para participar en la ejecución de capacitación. Si contribuyen con un trabajo efectivo, recibirán recompensas automáticamente.Si no, su replanteo puede ser cortado.Aunque no se involucró fondos reales durante esta ejecución de la prueba, esto resalta la forma inicial de algunos experimentos criptoeconómicos.Se necesitan más experimentos en esta área, y esperamos más cambios en la aplicación de la economía criptográfica en términos de seguridad e incentivos.Además de Intellect-2, Prime Intellect continúa llevando a cabo varios programas importantes no cubiertos en este informe, que incluyen:
-
Sintético-2, un marco de próxima generación para generar y validar tareas de inferencia;
-
Biblioteca de comunicaciones colectivas Prime, que implementa operaciones de comunicación colectiva eficientes y tolerantes a fallas (por ejemplo, reducción a través de IP), y proporciona un mecanismo de sincronización de estado compartido para mantener sincronizados a los pares, y permite la unión dinámica y dejar a los compañeros en cualquier momento durante el entrenamiento, así como la optimización automática de la topología de la topología de la ancho de banda;
-
Mejora continuamente la funcionalidad de TopLoc para habilitar pruebas de inferencia escalables de bajo costo para verificar la salida del modelo;
-
Mejoras al protocolo de intelecto principal y la economía criptográfica basadas en las lecciones aprendidas de Intellect2 y Synthetic1
Investigación de pluralis
Alexander Long es un investigador de aprendizaje automático australiano con un doctorado de la Universidad de Nueva Gales del Sur. Él cree que la capacitación de modelos de código abierto depende demasiado de los principales laboratorios de inteligencia artificial para proporcionar los modelos básicos para que otros entrenen.En abril de 2023, fundó Pluralis Research, con el objetivo de abrir un camino diferente.
Pluralis Research utiliza un enfoque llamado «aprendizaje de protocolo» para resolver el problema de capacitación descentralizado, que se describe como «bajo ancho de banda, participantes múltiples heterogéneos, capacitación y razonamiento paralelos modelo».Una característica importante de pluralis es su modelo económico, que proporciona ganancias similares a la equidad para los contribuyentes de modelos de capacitación para incentivar las contribuciones computacionales y atraer a los investigadores de software de código abierto.Este modelo económico se basa en el atributo central de «inextractabilidad»: es decir, ningún participante puede obtener un conjunto completo de pesos, que está estrechamente relacionado con el uso de métodos de capacitación y paralelismo del modelo.
Paralelismo modelo
La arquitectura de capacitación de Pluralis utiliza el paralelismo del modelo, que es diferente del enfoque de paralelismo de datos implementado por Nous Research y el intelecto principal en la ejecución de capacitación inicial.A medida que crece el tamaño del modelo, incluso el estante H100, una de las configuraciones de GPU más avanzadas, es difícil de llevar un modelo completo.El paralelismo del modelo proporciona una solución a este problema al dividir los componentes individuales de un solo modelo en GPU múltiples.
Existen tres métodos principales para la paralelización del modelo.
-
Paralelismo de la tubería: las capas del modelo se dividen en diferentes GPU.Durante el entrenamiento, cada pequeño lote de datos fluye a través de estas GPU como una tubería.
-
Paralelismo tensor (en la capa): en lugar de proporcionar la capa completa para cada GPU, las matemáticas pesadas dentro de cada capa se separan para que múltiples GPU puedan compartir el trabajo de una sola capa al mismo tiempo.
-
Paralelo mixto: en la práctica, los modelos grandes usan varios métodos, utilizando tuberías y tensores en paralelo, y generalmente junto con los datos.
El paralelismo del modelo es un avance importante en la capacitación distribuida porque permite la capacitación de modelos a escala de vanguardia, lo que permite participar hardware de nivel inferior y garantizar que ningún participante tenga acceso al conjunto completo de pesos de modelos.
Modelos de aprendizaje y protocolo de protocolo
Protocol Learning es un marco para que Pluralis utilice la propiedad y la monetización del modelo en un entorno de capacitación descentralizado. Pluralis destaca tres principios clave que constituyen el marco de aprendizaje del protocolo: decentralización, motivación y detrense.
La principal diferencia entre pluralis y otros proyectos es su enfoque en la propiedad del modelo.Dado que el valor del modelo se debe principalmente a su peso, el modelo de protocolo (Modelos de protocolo) Intente dividir los pesos del modelo para que ningún participante único durante el proceso de entrenamiento del modelo pueda tener pesos completos.En última instancia, esto dará a cada contribuyente al modelo de capacitación una cierta propiedad, compartiendo así los beneficios generados por el modelo.
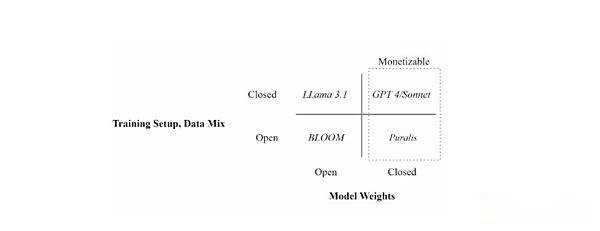 Posicione diferentes modelos de idiomas a través de configuraciones de capacitación (datos abiertos versus datos adjuntos) y disponibilidad de peso del modelo (abierto versus encerrado)
Posicione diferentes modelos de idiomas a través de configuraciones de capacitación (datos abiertos versus datos adjuntos) y disponibilidad de peso del modelo (abierto versus encerrado)
Este es un enfoque fundamentalmente diferente de la economía de los modelos descentralizados en comparación con ejemplos anteriores. Otros proyectos incentivan las contribuciones al proporcionar un grupo de fondos que se asigna a los contribuyentes durante el ciclo de capacitación basado en métricas específicas (generalmente el tiempo o la energía informática contribuyeron).Los contribuyentes de pluralis están motivados para dedicar recursos solo a los modelos que creen que es más probable que tengan éxito.Entrenar un modelo mal realizado desperdiciará la potencia informática, la energía y el tiempo porque los modelos mal realizados no generarán ningún ingreso.
Esto es diferente del método anterior.Primero, no requiere que las personas que deseen capacitar al modelo recauden fondos iniciales para pagar a los contribuyentes, reduciendo así el umbral para la capacitación y el desarrollo del modelo.En segundo lugar, coordina mejor los mecanismos de incentivos entre los diseñadores de modelos y los proveedores de computación, ya que ambas partes quieren que la versión final del modelo sea lo más perfecta posible para garantizar su éxito.Esto también proporciona la posibilidad de aparición de la especialización de capacitación modelo.Por ejemplo, puede haber más capacitadores de riesgo que brindan servicios informáticos a modelos tempranos/experimentales en busca de mayores rendimientos (similares a los capitalistas de riesgo), mientras que los proveedores de computación se centran solo en aquellos que maduran y tienen más probabilidades de aplicar (similar a los inversores de capital privado).
Si bien el PM puede representar un gran avance en los mecanismos de monetización e incentivos para el entrenamiento descentralizado, Pluralis no ha elaborado en sus métodos de implementación específicos.Dada la alta complejidad del enfoque, los problemas que aún no se han abordado incluyen cómo asignar la propiedad del modelo, cómo asignar beneficios e incluso cómo administrar futuras actualizaciones o casos de uso del modelo.
Innovación de capacitación descentralizada
Además de las consideraciones económicas, el aprendizaje del protocolo enfrenta el mismo desafío central que otros programas de capacitación descentralizados, utilizando redes de GPU heterogéneas con limitaciones de comunicación para capacitar a grandes modelos de IA.
En junio de este año, Pluralis anunció la capacitación exitosa de 8 mil millones de parámetros LLM basados en la arquitectura LLAMA 3 de Meta’s Meta y publicó su documento modelo de protocolo.En el documento, Pluralis muestra cómo reducir la sobrecarga de comunicación entre las GPU que realizan entrenamiento paralelo modelo.Lo hace al limitar las señales que fluyen a través de cada capa del transformador a un pequeño subespacio preseleccionado, comprimir hacia adelante y hacia atrás pasa hasta un 99%, reduciendo el tráfico de la red en 100 veces sin comprometer la precisión o agregar una sobrecarga significativa.En resumen, Pluralis encontró una manera de comprimir la misma información de aprendizaje a una pequeña fracción del ancho de banda requerido por los métodos anteriores.
Esta es la primera ejecución de entrenamiento descentralizado, y el modelo en sí se dispersa en nodos conectados a través de bajo ancho de banda en lugar de replicación.El equipo capacitó con éxito un modelo de llama con 8 mil millones de parámetros en GPU de bajo consumo de gama de gama baja repartida en cuatro continentes que se conectan solo a través de 80 megabytes por segundo de la conexión a Internet en el hogar por día.En el documento, Pluralis demuestra que la convergencia de este modelo es tan buena como funcionar en un clúster de centro de datos de 100 GB/s.En la práctica, esto significa que el entrenamiento descentralizado paralelo de modelos a gran escala ahora es posible.
Finalmente, ICML (una de las principales conferencias de inteligencia artificiales) recibió un artículo de pluralis sobre capacitación asincrónica para capacitación paralela de tuberías (una de las principales conferencias de inteligencia artificial).Cuando la capacitación paralela a la tubería se realiza a través de Internet en lugar de los centros de datos de alta velocidad, también enfrenta un cuello de botella de comunicación porque los nodos funcionan en una esencialmente similar a las tuberías, con cada nodo sucesivo que espera el nodo anterior para actualizar el modelo.Esto puede conducir a la transmisión de información obsoleta y retrasada de la información.El marco de entrenamiento descentralizado demostrado en el documento, enjambre, elimina dos cuellos de botella clásicos que generalmente obstaculizan la participación diaria de GPU en la capacitación: capacidad de memoria y sincronización estrecha.Eliminar estos dos cuellos de botella puede utilizar mejor todas las GPU disponibles, reducir el tiempo de entrenamiento y reducir los costos, lo que es fundamental para escalar modelos grandes con infraestructura distribuida basada en voluntarios. Para ver breve este proceso, mire este video de Pluralis.
Mirando hacia el futuro, Pluralis dice que planea lanzar una capacitación en tiempo real en la que cualquiera pueda participar pronto, pero no se ha determinado una fecha específica.El lanzamiento proporcionará una comprensión más profunda de los aspectos del acuerdo que aún no se han publicado, especialmente modelos económicos e infraestructura criptográfica.
Templario
fondo
Templar se lanzó en noviembre de 2024 y es un mercado de tareas de IA descentralizados basado en incentivos basado en la subred de protocolo Bittensor.Comenzó como un marco experimental que tiene como objetivo reunir los recursos globales de GPU para la capacitación previa de IA sin licencias y tiene como objetivo hacer que la capacitación de modelos a gran escala sea accesible, segura y resistente a través de los incentivos tokenizados de Bittensor, redefiniendo así el desarrollo de la IA.
Desde el principio, Templar asumió el desafío de coordinar la capacitación descentralizada para la pre-entrenamiento de LLM en Internet.Esta es una tarea difícil, ya que la latencia, las limitaciones de ancho de banda y el hardware heterogéneo dificultan que los actores distribuidos alcancen la eficiencia de los grupos centralizados y las comunicaciones de GPU perfectas de grupos centralizados permiten la rápida iteración de modelos masivos.
Lo más importante, Templario prioriza la participación que tiene una licencia verdaderamente con licencia, lo que permite a cualquier persona con recursos informáticos participar en la capacitación de IA sin aprobación, registro o control.Este enfoque sin permiso es crucial para la misión de Templario de democratizar el desarrollo de la IA, ya que garantiza que las capacidades de IA innovadores no estén controladas por algunas entidades centralizadas, sino que pueden surgir de una colaboración abierta en todo el mundo.
Templariotren
TEMPLAR utiliza datos para entrenar en paralelo, y hay dos factores principales:
-
minero:Estos participantes realizaron tareas de capacitación. Cada minero se sincroniza con el último modelo global, obtiene fragmentos de datos únicos, trenes localmente utilizando pases hacia adelante y hacia atrás, comprimir gradientes utilizando un optimizador CCLOCO personalizado (descrito a continuación) y envía actualizaciones de gradiente.
-
Verificador: el validador descarga y descomprime la actualización enviada por el minero, la aplica a la copia local del modelo y calculaIncremento de pérdida(Indicadores que miden el grado de mejora del modelo).Estos incrementos se utilizan para obtener las contribuciones de los mineros a través del sistema Gauntlet de Templar.
Para reducir la sobrecarga de comunicación, el equipo de investigación de Templar primero desarrolló el bloque de compresión de bloques (CCLOCO).Similar a Nous, CCLOCO mejora las técnicas de entrenamiento eficientes en comunicación, como el marco de Google Diloco, reduciendo los costos de comunicación entre nodos por órdenes de magnitud al tiempo que reduce las pérdidas a menudo causadas por dichos métodos.En lugar de enviar actualizaciones completas en cada paso, CCLOCO comparte solo los cambios más importantes a los intervalos establecidos y mantiene un pequeño recuento de ejecuciones para garantizar que no se pierdan datos significativos.El sistema adopta un modelo basado en la competencia que incentiva a los mineros a proporcionar actualizaciones de baja latencia para recibir recompensas.Para recibir recompensas, los mineros deben mantenerse al día con la red implementando hardware eficiente.Esta estructura competitiva está diseñada para garantizar que solo los participantes que mantienen un rendimiento suficiente puedan participar en el proceso de capacitación, mientras que las verificaciones de saneamiento livianas filtran actualizaciones notablemente malas o malformadas.En agosto, Templar lanzó oficialmente la arquitectura de capacitación actualizada y la renombró Sparseloco.
Los verificadores usan el sistema Gauntlet de Templar para rastrear y actualizar la clasificación de habilidad de cada minero en función de las contribuciones de reducción de pérdidas de modelos observadas.Con la tecnología llamada OpenSkill, los mineros de alta calidad que continúan actualizándose de manera efectiva recibirán calificaciones de habilidades más altas, aumentando su influencia en la agregación del modelo y ganando más TAI (tokens nativos de la red Bittensor).Los mineros con clasificaciones más bajas se descartarán durante el proceso de agregación.Después de la puntuación, los validadores con el más alto compromiso resumirán las actualizaciones de los principales mineros, firmarán el nuevo modelo global y lo publicarán en el almacenamiento.Si el modelo no está sincronizado, los mineros pueden usar esta versión del modelo para ponerse al día.
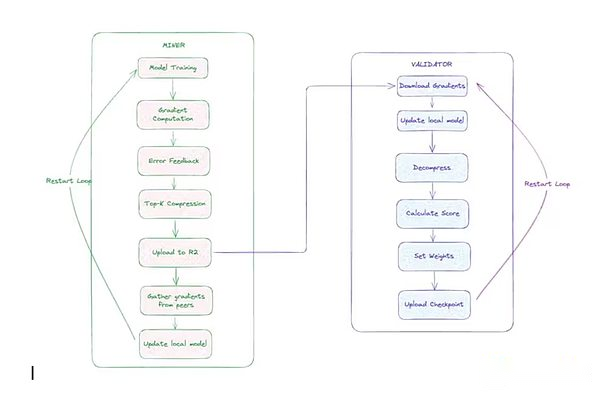 Arquitectura de capacitación descentralizada templaria
Arquitectura de capacitación descentralizada templaria
Templario ha comenzado tres rondas de entrenamiento hasta ahora: Templario I, Templario II y Templario III.Templar I es un modelo con 1,2 mil millones de parámetros, implementando casi 200 GPU en todo el mundo.Templar II está en progreso, capacitando un modelo con 8 mil millones de parámetros y planea comenzar una capacitación más grande pronto.Templar se centra actualmente en modelos de entrenamiento con parámetros más pequeños, una elección bien pensada diseñada para garantizar que las actualizaciones de la arquitectura de capacitación descentralizada (como se mencionó anteriormente) puede funcionar de manera efectiva antes de escalar a escalas modelo más grandes.Desde estrategias de optimización y programación hasta iteraciones e incentivos de investigación, estas ideas se validan en 8 mil millones de modelos con parámetros más pequeños, lo que permite a los equipos iterar de manera rápida y rentable.Tras el progreso reciente y el lanzamiento formal de la arquitectura de entrenamiento, el equipo lanzó Templar III en septiembre, un modelo con 70 mil millones de parámetros y la mayor ejecución previa en el campo descentralizado hasta la fecha.
Tao e mecanismos de incentivos
Una característica clave de Templar es su modelo de incentivo que está vinculado a TAO.Las recompensas se asignan en función de las contribuciones ponderadas de habilidad entrenadas por el modelo.La mayoría de los protocolos (como Pluralis, Nous, Prime Intellect) tienen ejecuciones o prototipos con licencia, mientras que Templar se ejecuta completamente en la red en tiempo real de Bittensor.Esto hace que Templar sea el único protocolo que ha integrado una capa económica en tiempo real sin licencias en su marco de capacitación descentralizado.Esta implementación de producción en tiempo real permite a Templario iterar su infraestructura en escenarios de ejecución de capacitación en tiempo real.
Cada subred bittensor se ejecuta con su propio token «alfa», que actúa como una señal de mercado para el mecanismo de recompensa y las subredes para percibir el valor. El token alfa de Templar se llama gamma.Los tokens alfa no se pueden negociar libremente en mercados externos;Solo se pueden intercambiar por TAO a través de un grupo de liquidez dedicado a su subred utilizando un fabricante de mercado automatizado (AMM).Los usuarios pueden comprometerse a TAO a obtener gamma, o canjear gamma como tao, pero no pueden intercambiar directamente gamma por tokens alfa de otras subredes.El sistema dinámico Tao (DTAO) de Bittensor utiliza el precio de mercado de los tokens alfa para determinar las asignaciones de emisión entre las subredes.Cuando el precio del gamma aumenta en relación con otros tokens alfa, esto indica que la confianza del mercado en las capacidades de capacitación descentralizadas de Templario ha aumentado, lo que ha resultado en un aumento en la emisión de TAO de la subred.A principios de septiembre, la emisión diaria de Templar representaba aproximadamente el 4% de la circulación de Tao, clasificándose en los seis primeros de las 128 subredes de la red Tao.
El mecanismo de emisión de la subred es el siguiente: en cada bloque de 12 segundos, la cadena Bittensor emitirá tokens Tao y alfa a su grupo de liquidez en función de la relación de precios de los tokens alfa de la subred en relación con otras subredes.Cada bloque emite hasta un token alfa completo a la subred (la tasa de emisión inicial, que puede reducirse a la mitad) a la subred para incentivar a los contribuyentes de la subred, de los cuales el 41% se asignan a los mineros, el 41% se asignan a los validadores (y sus partes interesadas), y el 18% se asignan a los propietarios de la subred.
Este incentivo impulsa la contribución a la red Bittensor al vincular las recompensas económicas con el valor proporcionado por los participantes.Los mineros están motivados para proporcionar salidas de IA de alta calidad, como tareas de entrenamiento o inferencia de modelos, para obtener calificaciones más altas de los validadores y, por lo tanto, una mayor proporción de la producción.Los verificadores (y sus Stakers) reciben recompensas para evaluar y mantener con precisión la integridad de la red.
La valoración del mercado de los tokens alfa se determina mediante actividades de replanteación, asegurando que las subredes que muestren una mayor practicidad pueden atraer más entradas y emisiones de TAO, creando así un entorno competitivo que fomenta la innovación, la especialización y el desarrollo sostenible.Los propietarios de la subred recibirán un porcentaje de recompensas, que están motivados para diseñar mecanismos efectivos y atraer contribuyentes, y en última instancia construirán un ecosistema de IA descentralizado sin permiso que permita a la participación global promover conjuntamente el progreso de la inteligencia colectiva.
El mecanismo también introduce nuevos desafíos de incentivos, como mantener la honestidad de los validadores, resistir los ataques de brujas y reducir la conspiración.Las subredes de Bittensor a menudo están preocupados por los juegos de gato y ratón entre validadores o mineros y creadores de subred, el primero que intenta jugar con el sistema y el segundo tratando de obstaculizarlos.A la larga, estas luchas deberían hacer del sistema uno de los más poderosos a medida que los propietarios de subred aprendan cómo superar los actores maliciosos.
Gensyn
Gensyn lanzó su primer libro blanco simplificado en febrero de 2022, elaborando el marco para la capacitación descentralizada (Gensyn es el único protocolo de capacitación descentralizado cubierto en nuestro primer artículo el año pasado para comprender la intersección de la tecnología de cifrado e inteligencia artificial).En ese momento, el protocolo se centró principalmente en la verificación de las cargas de trabajo relacionadas con la IA, permitiendo a los usuarios enviar solicitudes de capacitación a la red, procesadas por el proveedor de computación y asegurando que estas solicitudes se ejecutaran como se prometió.
La visión inicial también destacó la necesidad de acelerar la investigación de aprendizaje automático aplicado (ML).En 2023, Gensyn se basa en esta visión para proponer claramente una necesidad más amplia de adquirir recursos informáticos de aprendizaje automático en todo el mundo para atender aplicaciones de IA específicas.Gensyn introdujo el principio fantasmal como un marco que tales protocolos deben cumplir: universalidad, heterogeneidad, gastos generales, escalabilidad, sin confianza y latencia.Gensyn se ha centrado en construir infraestructura informática, y la colaboración marca su expansión formal a otros recursos clave más allá de la informática.
El núcleo de Gensyn divide su pila de tecnología de entrenamiento en cuatro partes distintas: ejecución, verificación, comunicación y coordinación.La parte de ejecución es responsable de manejar las operaciones en cualquier dispositivo del mundo que pueda realizar operaciones de aprendizaje automático.La sección de comunicación y coordinación permite que los dispositivos se envíen información entre sí de manera estandarizada.La sección de verificación garantiza que todas las operaciones se puedan calcular sin confianza.
Ejecución: enjambre de RL
La primera implementación de Gensyn en esta pila es un sistema de capacitación llamado RL Swarm, un mecanismo de coordinación descentralizado para el aprendizaje de refuerzo posterior al entrenamiento.
RL Swarm está diseñado para permitir que múltiples proveedores informáticos participen en la capacitación de un solo modelo en un entorno sin permiso y minimizado de confianza.El protocolo se basa en un ciclo de tres pasos: responder, revisar y resolver.Primero, cada participante genera salida del modelo (respuesta) en función de la solicitud.Los otros participantes evaluaron la salida utilizando una función de recompensa compartida y comentarios enviados (revisión).Finalmente, estas revisiones se utilizarán para seleccionar la mejor respuesta e incluirlas en la próxima versión del modelo (resuelto).Todo el proceso tiene lugar de manera punto a punto sin depender de un servidor central o una organización de confianza.
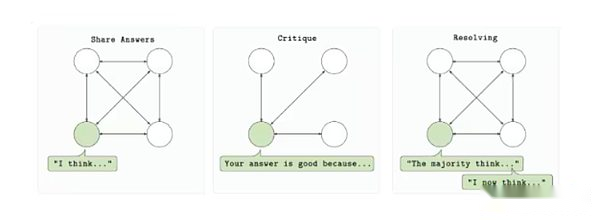 Bucle de entrenamiento de enjambre RL
Bucle de entrenamiento de enjambre RL
El enjambre de aprendizaje de refuerzo se basa en la creciente importancia del aprendizaje de refuerzo en la capacitación posterior al modelo. A medida que el modelo alcanza el límite superior de escala en la etapa previa a la capacitación, el aprendizaje de refuerzo proporciona un mecanismo para mejorar la capacidad de inferencia, la capacidad de cumplimiento de la instrucción y la realidad sin reentrenarse en conjuntos de datos masivos.El sistema de Gensyn logra esta mejora en un entorno descentralizado al desglosar los bucles de aprendizaje de refuerzo en diferentes roles, cada papel puede verificarse independientemente.De manera crucial, introduce una ejecución asincrónica tolerante a fallas, lo que significa que los contribuyentes no necesitan estar en línea o permanecer perfectamente sincronizados para participar.
También es de naturaleza modular.El sistema no requiere el uso de una arquitectura de modelo específica, tipo de datos o estructura de recompensas, lo que permite a los desarrolladores personalizar los bucles de capacitación en función de sus casos de uso específicos.Ya sea que se trate de capacitar modelos de codificación, agentes de inferencia o modelos con conjuntos de instrucciones específicos, RL Swarm proporciona un marco de operación a gran escala confiable para flujos de trabajo RL descentralizados.
Verde
Hasta ahora, uno de los aspectos menos discutidos en este informe sobre la capacitación descentralizada es la verificación. Gensyn construye una capa de confianza Verde para su mercado de GPU.Con Verde, Gensyn introdujo un nuevo mecanismo de verificación para que los usuarios de protocolo puedan confiar en las personas en el otro lado de la situación están haciendo lo que dicen.
Cada tarea de capacitación o inferencia está programada para un cierto número de proveedores independientes determinados por la aplicación. Si su salida coincide exactamente, la tarea se acepta.Si las salidas son diferentes, el protocolo del árbitro localiza el primer paso en el que las dos trayectorias están divergidas y recalcula la operación solamente.La parte cuyo número coincide con el árbitro conserva su pago, mientras que la otra parte pierde sus intereses.
Lo que hace que esto sea posible es Progs, una biblioteca de «operadores repetibles» que obliga a las operaciones comunes de matemáticas de la red neuronal (multiplicación de matriz, activación, etc.) para que se ejecute en un orden fijo y determinista en cualquier GPU.El determinismo es crucial aquí;De lo contrario, aunque ambos validadores son correctos, pueden producir resultados diferentes.Por lo tanto, los proveedores honestos proporcionarán el mismo resultado bit a poco, permitiendo que Verde vea el juego como una prueba de corrección.Dado que el árbitro solo reproduce un Microstep, el costo adicional es solo unos pocos puntos porcentuales, en lugar de la sobrecarga de 10,000 veces de la prueba completa de cifrado comúnmente utilizada en estos procesos.
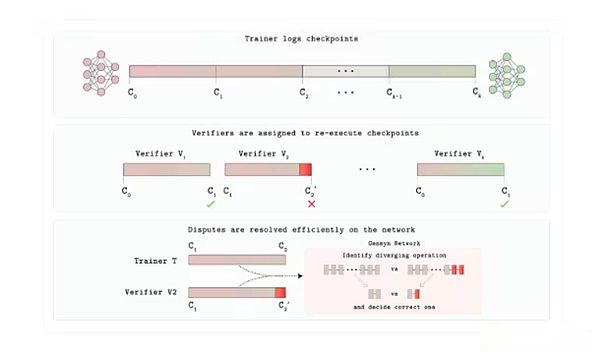
Arquitectura del protocolo de verificación Verde
En agosto, Gensyn lanzó Judge, un sistema de evaluación de IA verificable que contiene dos componentes centrales: Verde y un tiempo de ejecución reproducible, que garantiza un poco de resultado bit a poco el mismo resultado en el hardware.Para mostrarlo, Gensyn lanzó un «juego de revelación progresiva» en el que los modelos de IA apostaron en respuestas a preguntas complejas durante la revelación de la información, Judge valida determinista los resultados y recompensa las predicciones tempranas precisas.
El juez es significativo porque resuelve los problemas de confianza y escalabilidad en IA/ML.Permite comparaciones de modelos confiables, mejorar la transparencia en entornos de alto riesgo y reduce el riesgo de sesgo o manipulación al permitir la verificación independiente.Además de las tareas de inferencia, el juez puede apoyar otros casos de uso, como los mercados descentralizados de resolución de disputas y predicción, que se ajusta a la misión de Gensyn de construir una infraestructura de computación de IA distribuida confiable.En última instancia, herramientas como Judge pueden mejorar la repetibilidad y la responsabilidad, lo cual es crucial en una era en la que la IA está cada vez más en el corazón de la sociedad.
Comunicación y coordinación: integración de expertos en la tubería y la diversidad
Skip-Pipe es una solución de Gensyn para abordar el problema del cuello de botella de ancho de banda que se produce un solo modelo de megamo al cortar en varias máquinas.Como se mencionó anteriormente, el entrenamiento tradicional de la tubería obliga a cada microbatch a atravesar todas las capas en secuencia, por lo que cualquier nodo más lento causará estancamiento de la tubería.El planificador de Skip-Pipe puede omitir o reordenar dinámicamente las capas que pueden causar retrasos, reduciendo los tiempos de iteración hasta en un 55% y mantener la disponibilidad incluso cuando la mitad de los nodos fallan.Al reducir el tráfico entre nodo y permitir que las capas se eliminen según sea necesario, permite al entrenador escalar modelos muy grandes para GPU geo-distribuidos de bajo ancho de banda.
La integración de expertos diversificados resuelve otro rompecabezas de coordinación: cómo construir un poderoso sistema de «experto híbrido» que evite la diafonía continua.La integración de expertos en dominio heterogéneo (HDEE) de Gensyn capacita a cada modelo experto de forma completamente independiente y se fusiona solo al final.Sorprendentemente, bajo el mismo presupuesto de computación general, la integración final en 20 de las 21 áreas de prueba superó un punto de referencia unificado.Dado que no hay gradiente o flujo de funciones de activación entre las máquinas durante el entrenamiento, cualquier GPU inactiva puede contribuir con la potencia informática.
Skip-pipe y HDE juntos proporcionan a Gensyn una solución de comunicación eficiente.El protocolo puede fragmentar dentro de un solo modelo si es necesario, o entrenar a múltiples expertos pequeños en paralelo con menores costos de independencia sin operar una red de latencia perfecta y de baja latencia como se usa tradicionalmente.
Red de pruebas
En marzo, Gensyn implementó una red de prueba en un acurrucado de Ethereum personalizado. El equipo planea actualizar gradualmente la red de pruebas. Actualmente, los usuarios pueden participar en los tres productos de Gensyn: RL Swarm, Blockassist y Judge.Como se mencionó anteriormente, RL Swarm permite a los usuarios participar en procesos de capacitación post-RL.En agosto, el equipo lanzó Blockassist: «Esta es la primera demostración a gran escala de aprendizaje asistido, una forma de capacitar a los agentes directamente del comportamiento humano sin etiquetado manual o RLHF».Los usuarios pueden descargar Minecraft y usar Blockassist para entrenar modelos Minecraft para jugar.
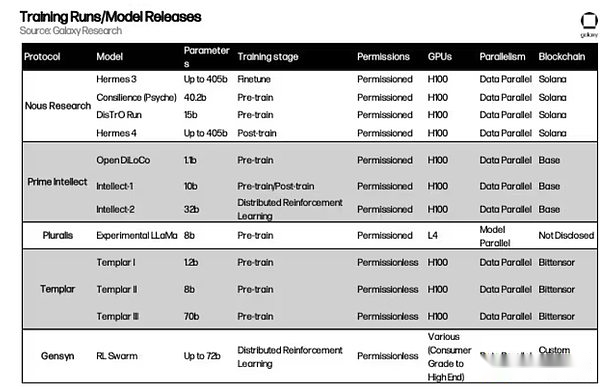
Otros proyectos que vale la pena prestar atención a
Los capítulos anteriores describen la arquitectura convencional implementada para lograr una capacitación descentralizada. Sin embargo, están emergiendo nuevos proyectos uno tras otro.Aquí hay algunos proyectos nuevos en el campo de la capacitación descentralizada:
Cuarenta y dos: FortyTwo se basa en la cadena de bloques de Mónada y se centra en el razonamiento grupal (SLM), donde múltiples modelos de lenguaje pequeño (SLMS) colaboran en consultas en una red de nodos y generan salidas revisadas por pares, mejorando así la precisión y la eficiencia.El sistema utiliza hardware de grado de consumo, como computadoras portátiles inactivas, eliminando la necesidad de usar racimos costosos de GPU como la IA centralizada.La arquitectura incluye la ejecución de inferencia descentralizada y las funciones de capacitación, como la generación de conjuntos de datos sintéticos para modelos dedicados.El proyecto ahora está disponible en la Red de Desarrollo de Mónados.
Ambiente: Ambient es la próxima cadena de bloques de capa 1 de «prueba de trabajo», diseñada para admitir agentes de IA autónomos y siempre en línea en la cadena, lo que les permite realizar continuamente tareas, aprender y evolucionar en un ecosistema sin permiso sin supervisión centralizada.Adoptará un único modelo de código abierto capacitado y mejorado por los mineros de la red en colaboración, y los contribuyentes serán recompensados por sus contribuciones a la capacitación, la construcción y el uso de modelos de IA.Aunque Ambient enfatiza el razonamiento descentralizado, especialmente en el aspecto proxy, los mineros en la red también serán responsables de actualizar continuamente los modelos subyacentes que admiten la red.Ambient utiliza un nuevo mecanismo de los Logits P-logits (en este sistema, los validadores pueden verificar que los cálculos del modelo se ejecuten correctamente al verificar el valor de salida original del minero (llamado logits). El proyecto se construye en una bifurcación de Solana y aún no se ha lanzado oficialmente.
Laboratorios de flores: Flower Labs está desarrollando un marco de código abierto para el aprendizaje federado, Flower, que respalda la capacitación en modelo de IA colaborativa en fuentes de datos descentralizadas sin compartir datos sin procesar, protegiendo así la privacidad al agregar actualizaciones del modelo. Flower se fundó para abordar la centralización de los datos, permitiendo a las instituciones e individuos capacitar modelos con datos locales, como la atención médica o las finanzas, al tiempo que contribuye a las mejoras globales a través del intercambio seguro de parámetros. A diferencia de los protocolos cripto-nativos que enfatizan las recompensas de tokens y la computación verificable, la flor prioriza la colaboración que protege la privacidad en las aplicaciones del mundo real, lo que lo convierte en una opción ideal para las industrias reguladas sin blockchain.
Macrocosmos: MacRocosmos se ejecuta en la red Bittensor y está desarrollando un proceso completo de creación de modelos de IA que cubre cinco subredes que se centran en la capacitación previa, el ajuste, la recopilación de datos y la ciencia descentralizada.Presenta el marco de arquitectura de capacitación de orquestación de incentivos (IOTA) para la capacitación previa de los modelos de idiomas grandes en hardware heterogéneo, poco confiable y sin licencia, y ha iniciado más de mil millones de entrenamientos de parámetros y planea escalar rápidamente a modelos de parámetros más grandes.
Flock.io: Flock es un ecosistema de capacitación de IA descentralizado que combina el aprendizaje federado con infraestructura de blockchain para lograr el desarrollo de modelos colaborativos para la protección de la privacidad en una red modular de incentivo token. Los participantes pueden contribuir con modelos, datos o recursos informáticos y recibir recompensas en cadena proporcionales a sus contribuciones.Para proteger la privacidad de los datos, el protocolo adopta el aprendizaje federado.Esto permite a los participantes capacitar a modelos globales utilizando datos locales que no se comparten con otros.Si bien esta configuración requiere pasos de verificación adicionales para evitar que los datos irrelevantes (a menudo denominados envenenamiento de datos) ingresen a la capacitación del modelo, es un enfoque promocional efectivo para casos de uso como aplicaciones de atención médica donde los proveedores de atención médica múltiples pueden capacitar a modelos globales sin filtrar datos médicos altamente sensibles.
Perspectivas y riesgos
En los últimos dos años, la capacitación descentralizada se ha transformado de un concepto interesante a una red efectiva que se ejecuta en un entorno real. Si bien estos proyectos aún están lejos del estado final esperado, están haciendo un progreso significativo en el camino hacia la capacitación descentralizada.Mirando hacia atrás en el patrón de entrenamiento descentralizado existente, algunas tendencias comienzan a surgir:
La prueba de concepto en tiempo real ya no es una fantasía.Las primeras verificaciones, como la consiliencia de Nous y el intelecto de Prime Intellect, han ingresado a las operaciones a escala de producción durante el año pasado.Los avances como los modelos de Opendiloco y Protocol están permitiendo la IA de alto rendimiento en las redes distribuidas, facilitando el desarrollo de modelos rentable, resistente y transparente.Estas redes coordinan docenas o incluso cientos de GPU, modelos medianos de tamaño real y ajustado en tiempo real, lo que demuestra que el entrenamiento descentralizado puede ir más allá de las demostraciones cerradas y los hackones temporales.Si bien estas redes aún no son redes sin permiso, Templar se destaca a este respecto;Su éxito refuerza la idea de que la capacitación descentralizada se está moviendo de simplemente demostrar que la tecnología subyacente es efectiva para poder escalar para que coincida con el rendimiento de los modelos centralizados y atraer los recursos de GPU necesarios para producir los modelos subyacentes a escala.
La escala del modelo continúa expandiéndose, pero la brecha permanece.De 2024 a 2025, el número de modelos de parámetros para proyectos descentralizados aumentó de un solo dígito a 30 mil millones a 40 mil millones.Sin embargo, el laboratorio de IA líder ha lanzado billones de parámetros del sistema y continúa innovando rápidamente con sus centros de datos integrados verticalmente y hardware de vanguardia.El entrenamiento descentralizado puede cerrar esta brecha aprovechando el hardware de entrenamiento de todo el mundo, especialmente a medida que los métodos de entrenamiento centralizados enfrentan restricciones crecientes debido a la necesidad de un número creciente de centros de datos de hiperescala.Pero cerrar esta brecha dependerá de nuevos avances en los optimizadores y la compresión de gradiente para comunicaciones eficientes para lograr la escala global, así como una capa de incentivos y verificación inoperables.
El flujo de trabajo posterior al entrenamiento se está convirtiendo en un área de preocupación.El ajuste de fino supervisado, el RLHF y el aprendizaje de refuerzo específico del dominio requieren un ancho de banda de sincronización mucho más bajo que el pre-entrenamiento integral.Los marcos como Prime-RL y RL Swarm se han ejecutado en nodos inestables a nivel de consumidor, lo que permite a los contribuyentes obtener ganancias de los ciclos inactivos, mientras que los proyectos pueden comercializar rápidamente los modelos personalizados.Dado que RL es muy adecuado para la capacitación descentralizada, su importancia como un campo de enfoque para los programas de capacitación descentralizados puede volverse cada vez más prominente.Esto hace posible que la capacitación descentralizada sea la primera en encontrar un mercado de productos a gran escala que se ajuste en la capacitación RL, como lo demuestra el número cada vez mayor de equipos que lanzan marcos de capacitación específicos de RL.
El mecanismo de incentivos y de verificación se queda atrás de la innovación tecnológica. Los mecanismos de incentivos y verificación aún se quedan atrás de la innovación tecnológica.Solo unas pocas redes, especialmente Templar, proporcionan recompensas de monedas en tiempo real y los mecanismos de penalización y confiscación en la cadena, frenando efectivamente el mal comportamiento y se ha probado en entornos del mundo real.Aunque otros programas están experimentando con puntajes de reputación, prueba de testigos o programas de prueba de capacitación, estos sistemas aún no están verificados.Incluso si se superan las barreras técnicas, la gobernanza presentará desafíos igualmente difíciles, ya que las redes descentralizadas deben encontrar formas de formular reglas, hacer cumplir las reglas y resolver disputas sin ineficiencias repetidas que ocurran en cripto DAO.Resolver barreras técnicas es solo el primer paso; La viabilidad a largo plazo depende de combinarlo con mecanismos de verificación confiables, mecanismos de gobernanza efectivos y estructuras de monetización/propiedad convincentes para garantizar la confianza en el trabajo que se lleva a cabo y atraer el talento y los recursos necesarios para ampliar.
La pila se está fusionando en una tubería de extremo a extremo.Hoy, la mayoría de los equipos principales combinan optimizadores conscientes de ancho de banda (demostración, distribución), intercambios informáticos descentralizados (Prime Compute, Basilica) y capas de coordinación en la cadena (Psique, PM, Prime).Finalmente, se forma una tubería abierta modular, que refleja el flujo de trabajo de los laboratorios centralizados desde los datos hasta el despliegue, pero sin un solo punto de control.Incluso si los proyectos no integran sus propias soluciones directamente, o incluso si están integrados, se puede acceder a otros proyectos criptográficos centrados en las verticales requeridas para la capacitación descentralizada, como protocolos de aprovisionamiento de datos, GPU e mercados de inferencias, y backbons de almacenamiento descentralizado.Esta infraestructura periférica proporciona componentes plug-and-play para programas de capacitación descentralizados que pueden aprovecharse aún más para mejorar sus productos y competir mejor con pares centralizados.
riesgo
La optimización de hardware y software es un objetivo en constante cambio: el laboratorio central también se está expandiendo en este campo.El chip Blackwell B200 de Nvidia acaba de ser anunciado. En el punto de referencia de MLPERF, ya sea previamente entrenamiento con 405 mil millones de parámetros o 70 mil millones de lora ajustado, su rendimiento de entrenamiento es de 2.2 a 2.6 veces más rápido que la generación anterior, lo que reduce en gran medida los costos de tiempo y energía para los Gigantes.En términos de software, Pytorch 3.0 y Tensorflow 4.0 introducen fusión de gráficos a nivel de compilador y núcleos de forma dinámica para mejorar aún más el rendimiento en el mismo chip.Con mejoras en la optimización de hardware y software, o el advenimiento de las nuevas arquitecturas de capacitación, las redes de capacitación descentralizadas también deben mantener el ritmo de las actualizaciones continuas para adaptarse a los métodos de capacitación más rápidos y avanzados, atrayendo talento e inspirando un desarrollo de modelos significativo.Esto requerirá que el equipo desarrolle un software que garantice un alto rendimiento continuo, independientemente del hardware subyacente y una pila de software que permita a estas redes adaptarse a los cambios en la arquitectura de capacitación subyacente.
El modelo de código abierto empresarial existente desdibuja los límites entre la capacitación descentralizada y centralizada.La mayoría de los laboratorios de IA centralizados mantienen los modelos cerrados, lo que demuestra aún más que la capacitación descentralizada es una forma de garantizar la apertura, la transparencia y la gobernanza comunitaria.Aunque proyectos recientes como Deepseek, las versiones de código abierto de GPT y el llamado muestran su cambio hacia una apertura más alta, no está claro si esta tendencia puede continuar en el contexto de la creciente competencia, las preocupaciones regulatorias y de seguridad.Incluso si se revelan los pesos, aún reflejan los valores y opciones del laboratorio original: la capacidad de entrenar independientemente es fundamental para la adaptabilidad, la coordinación con diferentes prioridades y garantizar que el acceso no esté limitada por un puñado de negocios titulares.
El reclutamiento sigue siendo difícil.Muchos equipos nos dicen esto. Si bien la calidad del talento que se une a los programas de capacitación descentralizados ha mejorado, carecen de los sólidos recursos que lideran los laboratorios de IA (por ejemplo, OpenAi recientemente ofreció millones de dólares en «recompensas especiales» por empleado, o la oferta de $ 250 millones que Meta ha ofrecido a los investigadores de los cazadores furtivos).Actualmente, los proyectos descentralizados atraen a los investigadores impulsados por la misión que valoran la apertura y la independencia, al tiempo que atraen el talento de un grupo de talentos globales más amplios y una comunidad vibrante de código abierto.Sin embargo, para competir en escala, deben probarse a sí mismos entrenando modelos comparables a las empresas existentes y perfeccionando incentivos y mecanismos de monetización para crear beneficios significativos para los contribuyentes.Si bien las redes sin licencia y los incentivos criptoeconómicos sin licencia proporcionan un valor único, la incapacidad de acceder a la distribución y establecer un flujo de ingresos sostenible puede obstaculizar el crecimiento a largo plazo en el sector.
Existe la resistencia regulatoria, especialmente para los modelos sin censura. La capacitación descentralizada enfrenta desafíos regulatorios únicos: en cuanto al diseño, cualquiera puede entrenar cualquier tipo de modelo.Esta apertura es ciertamente una ventaja, pero también aumenta los riesgos de seguridad, especialmente en la bioseguridad, información falsa u otras áreas confidenciales de abuso.Los formuladores de políticas de la UE y los Estados Unidos han señalado que fortalecerán su escrutinio: la Ley de Inteligencia Artificial de la UE establece obligaciones adicionales en modelos base de alto riesgo, mientras que las agencias estadounidenses están considerando limitar los sistemas abiertos y las posibles medidas de control de estilo de exportación.Los eventos que involucran modelos descentralizados para fines dañinos por sí solo pueden desencadenar una regulación integral, amenazando el principio fundamental de la capacitación sin permiso.
Distribución y monetización: la distribución sigue siendo un gran desafío.Los laboratorios líderes, incluidos OpenAI, Anthrope y Google, tienen grandes ventajas de distribución a través del conocimiento de la marca, los contratos corporativos, la integración de la plataforma en la nube y el acceso directo a los consumidores.Por el contrario, los programas de capacitación descentralizados carecen de estos canales incorporados y se deben realizar más esfuerzos para permitir que los modelos se adopten, ganen confianza e integrados en flujos de trabajo reales.Dado que las criptomonedas todavía están en su infancia en su integración fuera de las aplicaciones criptográficas (aunque esto está cambiando rápidamente), esto puede ser más desafiante.Una pregunta muy importante y sin resolver es quién usará estos modelos de entrenamiento descentralizados.Ya existen modelos de código abierto de alta calidad, y una vez que se lanzan nuevos modelos avanzados, no es particularmente difícil para otros extraerlos o ajustarlos.Con el tiempo, la naturaleza de código abierto de los programas de capacitación descentralizados debería crear efectos de red que resuelvan el problema de distribución.Sin embargo, incluso si pueden resolver el problema de distribución, el equipo enfrentará el desafío de la monetización del producto.Actualmente, los gerentes de proyectos de Pluralis parecen abordar más directamente estos desafíos de monetización.Esto no es solo un problema de cifrado x ai, sino un problema de cifrado más amplio que resalta los desafíos futuros.
en conclusión
La capacitación descentralizada ha evolucionado rápidamente de un concepto abstracto a una red efectiva que coordina el funcionamiento de la capacitación global real.El año pasado, los proyectos que incluyen Nous, Prime Intellect, Pluralis, Templar y Gensyn han demostrado que es posible conectar GPU descentralizadas, comprimir las comunicaciones de manera eficiente e incluso comenzar a experimentar con incentivos en entornos del mundo real.Estas primeras manifestaciones demuestran que el entrenamiento descentralizado puede ir más allá de la teoría, aunque el camino hacia la competencia con laboratorios centralizados a escala de vanguardia sigue siendo difícil.
Incluso si los modelos fundamentales finalmente entrenados por proyectos descentralizados son comparables a los principales laboratorios de inteligencia artificial de hoy, enfrentan la prueba más severa: demostrar sus ventajas realistas más allá de las demandas de las ideas.Estas ventajas pueden manifestarse endógenamente a través de una excelente arquitectura o los nuevos esquemas de monetización y propiedad de los contribuyentes.Alternativamente, estas ventajas también pueden ser exógenas si los participantes existentes centralizados intentan sofocar la innovación manteniendo los pesos cerrados o inyectando sesgos de alineación desagradable.
Además de los avances tecnológicos, las actitudes hacia el campo también han comenzado a cambiar.Un fundador describió los cambios en las emociones en las principales conferencias de IA durante el año pasado: hace un año, había poco interés en la capacitación descentralizada, especialmente cuando se usaba junto con las criptomonedas; Hace seis meses, los participantes comenzaron a reconocer posibles problemas, pero expresaron dudas sobre la viabilidad de la implementación a gran escala; Y en los últimos meses, ha habido un reconocimiento creciente de que el progreso continuo puede hacer posible la capacitación descentralizada escalable.La evolución de este concepto muestra que el impulso de la capacitación descentralizada también está aumentando no solo en el campo de la tecnología, sino también en términos de legitimidad.
Los riesgos son reales: las empresas existentes aún mantienen sus ventajas de hardware, talento y distribución; La revisión regulatoria es inminente; Los incentivos y los mecanismos de gobernanza no se han probado a gran escala. Sin embargo, sus ventajas son igualmente llamativas.La capacitación descentralizada representa no solo una arquitectura de tecnología alternativa, sino también un concepto fundamental de construir inteligencia artificial: sin licencia, propiedad global y consistente con una comunidad diversa en lugar de algunas compañías.Incluso si solo un proyecto puede demostrar que la apertura puede traducirse en una iteración más rápida, una arquitectura novedosa o una gobernanza más inclusiva, marcará un momento innovador para las criptomonedas e inteligencia artificial.El camino por delante es largo, pero los elementos centrales del éxito ahora están firmemente captados.







