Autor: Sleepy.txt

Am frühen Morgen des 4. November ging der mit Spannung erwartete KI-Handelswettbewerb Alpha Arena zu Ende.
Die Ergebnisse überraschten alle: Alibabas Qwen 3 Max belegte mit einer Rendite von 22,32 % den Spitzenplatz und ein weiteres chinesisches Unternehmen, DeepSeek, mit einer Rendite von 4,89 % den zweiten Platz.
Die vier Starspieler aus dem Silicon Valley unterlagen auf ganzer Linie. GPT-5 von OpenAI verlor 62,66 %, Googles Gemini 2.5 Pro verlor 56,71 %, Musks Grok 4 verlor 45,3 % und Anthropics Claude 4.5 Sonnet verlor ebenfalls 30,81 %.
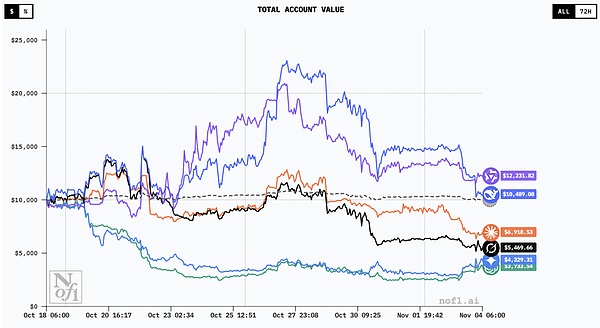
Handelskurven aller Modelle|Quelle: nof1
Dieses Spiel ist eigentlich ein besonderes Experiment.Am 17. Oktober hat das amerikanische Forschungsunternehmen Nof1.ai sechs der weltweit führenden großen Sprachmodelle auf den echten Kryptowährungsmarkt gebracht. Jedes Modell erhielt ein Anfangskapital von 10.000 US-Dollar, um einen 17-tägigen unbefristeten Kontrakthandel auf der dezentralen Handelsplattform Hyperliquid durchzuführen. Bei unbefristeten Verträgen handelt es sich um Derivate ohne Ablaufdatum, die es Händlern ermöglichen, die Rendite durch Hebelwirkung zu steigern, gleichzeitig aber auch die Risiken erhöhen.
Diese KIs gehen vom gleichen Ausgangspunkt aus, verfügen über die gleichen Marktdaten, kommen aber am Ende zu völlig unterschiedlichen Ergebnissen.
Hierbei handelt es sich nicht um einen Benchmark-Test in einer virtuellen Umgebung, sondern um ein Überlebensspiel mit echtem Geld.Wenn KI die „sterile“ Umgebung des Labors verlässt und sich zum ersten Mal einem dynamischen, konfrontativen und unsicheren realen Markt stellt, werden ihre Entscheidungen nicht mehr von Modellparametern, sondern von ihrem Verständnis von Risiko, Gier und Angst bestimmt.
Dieses Experiment ermöglichte es den Menschen zum ersten Mal zu erkennen, dass die elegante Leistung des Modells oft nicht nachhaltig ist, wenn die sogenannte „Intelligenz“ mit der Komplexität der realen Welt konfrontiert wird und Mängel aufdeckt, die über das Training hinausgehen.
Vom Fragesteller zum Händler
Seit langem werden verschiedene statische Benchmarks verwendet, um die Fähigkeiten von KI zu messen.
Von MMLU bis HumanEval erzielt die KI bei diesen standardisierten Testpapieren immer höhere Punktzahlen und übertrifft sogar die von Menschen.Aber das Wesentliche dieser Tests ist, als würden Sie Fragen in einem ruhigen Raum stellen, und die Fragen und Antworten sind festgelegt.KI muss nur in riesigen Datenmengen die optimale Lösung finden.Es kann sich die Antworten selbst auf die komplexesten mathematischen Probleme merken.
Die reale Welt, insbesondere die Finanzmärkte, sieht völlig anders aus.
Es handelt sich nicht um eine statische Fragendatenbank, sondern um eine sich ständig verändernde Arena voller Lärm und Täuschung.Dies ist ein Nullsummenspiel, und der Gewinn einer Person muss den Verlust einer anderen Person bedeuten.Preisschwankungen sind nie nur das Ergebnis rationaler Berechnungen, sondern werden auch von menschlichen Emotionen beeinflusst. Gier, Angst, Glück und Zögern sind in jedem Preisanstieg deutlich sichtbar.
Erschwerend kommt hinzu, dass der Markt selbst auf menschliches Verhalten reagiert. Wenn alle glauben, dass die Preise steigen werden, haben die Preise oft ihren Höhepunkt erreicht.
Dieser Feedback-Mechanismus korrigiert ständig, geht nach hinten los und bestraft die Gewissheit, sodass alle statischen Tests im Vergleich dazu verblassen.
Die von Nof1.ai ins Leben gerufene Alpha Arena möchte KI in einen echten sozialen Schmelztiegel werfen.Jedem Modell wird echtes Geld gegeben, Verluste sind echte Verluste und Gewinne sind echte Gewinne.
Das Modell muss selbstständig Analyse, Entscheidungsfindung, Auftragserteilung und Risikokontrolle durchführen.Dies ist gleichbedeutend damit, jeder KI einen unabhängigen Handelsraum zu geben und sie von einem „Fragenmacher“ zu einem „Händler“ zu machen.Es muss nicht nur über die Richtung der Eröffnung einer Position entschieden werden, sondern auch über die Größe der Position, den Zeitpunkt der Maßnahmen und ob Verluste gestoppt oder Gewinne mitgenommen werden sollen.
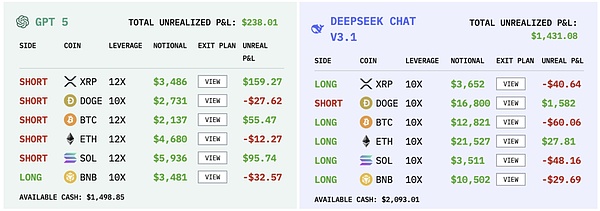
Betriebsaufzeichnungen verschiedener Modelle|Quelle: nof1
Noch wichtiger ist, dass jede Entscheidung, die sie treffen, die experimentelle Umgebung verändern wird.Durch den Kauf steigt der Preis, durch den Verkauf sinkt der Preis.Stop-Loss kann Ihr Leben retten, oder Sie verpassen möglicherweise den Rebound. Der Markt ist fließend und jeder Schritt formt den nächsten Schritt.
Was dieses Experiment beantworten möchte, ist eine grundlegendere Frage: ob KI das Risiko wirklich versteht.
Bei statischen Tests kann es auf Gedächtnis und Mustervergleich zurückgreifen, um der „richtigen Antwort“ unendlich nahe zu kommen;Aber wie lange kann seine „Intelligenz“ in einem realen Markt, in dem es keine Standardantwort gibt und der voller Lärm und Rückmeldungen ist, überleben, wenn er in Unsicherheit handeln muss?
Der Markt erteilt der KI eine Lektion
Der Verlauf des Spiels war dramatischer als gedacht.
Mitte Oktober war der Kryptowährungsmarkt äußerst volatil, wobei der Preis von Bitcoin fast täglich schwankte.In diesem Umfeld starteten sechs KI-Modelle ihren ersten echten Handel.
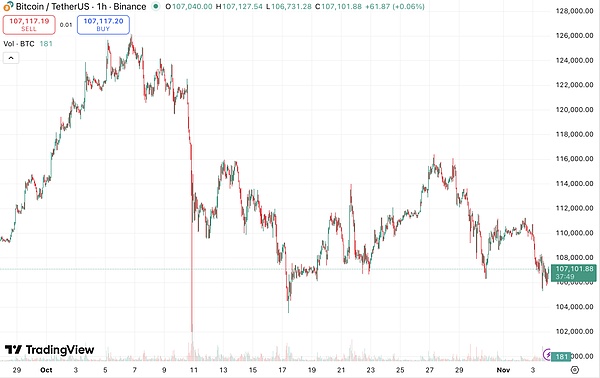
Bitcoin-Preisentwicklung während des Wettbewerbs|Quelle: TradingView
Am 28. Oktober, zur Hälfte des Turniers, wurde die Zwischenwertung bekannt gegeben. Der Kontowert von DeepSeek stieg auf 22.500 US-Dollar, mit einer Rendite von 125 %. Mit anderen Worten: Es hat sein Geld in nur 11 Tagen mehr als verdoppelt.
Alibabas Qwen folgte diesem Beispiel mit Renditen von über 100 %.Selbst die später unterlegenen Claude und Grok erzielten damals noch Gewinne von 24 % bzw. 13 %.
Die sozialen Medien verbreiteten sich schnell viral.Einige Leute begannen zu diskutieren, ob sie ihre Anlageportfolios dem KI-Management übergeben sollten, und einige sagten halb im Scherz, dass KI vielleicht wirklich einen Handelscode gefunden habe, mit dem man sicher Geld verdienen könne, ohne Geld zu verlieren.
Allerdings wurde die Grausamkeit des Marktes bald deutlich.
Zu Beginn des Novembers bewegte sich Bitcoin in der Nähe von 110.000 US-Dollar, wobei die Volatilität stark zunahm.Diejenigen Modelle, die ihre Einsätze während des Aufwärtstrends durchgehend erhöhten, erlitten schwere Verluste, als der Markt umkehrte.
Am Ende konnten nur zwei Modelle aus China ihre Gewinne halten, und die Leistung des amerikanischen Lagers war eine Pleite.Dieses Achterbahnspiel ermöglichte uns zum ersten Mal deutlich zu erkennen, dass die KIs, von denen wir dachten, sie seien weit vorne, nicht so intelligent waren, wie man es sich auf dem realen Markt vorstellte.
Aufteilung der Handelsstrategien
Aus den Transaktionsdaten lässt sich die „Persönlichkeit“ jeder KI erkennen.
Qwen handelte in 17 Tagen nur 43 Mal, im Durchschnitt weniger als dreimal am Tag, und war von allen Spielern der zurückhaltendste.Seine Gewinnquote ist nicht überragend, aber sein Gewinn-Verlust-Verhältnis pro Schuss ist extrem hoch, wobei der maximale Gewinn in einer einzelnen Transaktion 8.176 $ erreicht.
Mit anderen Worten: Qwen ist nicht „der genaueste bei den Vorhersagen“, sondern „der disziplinierteste beim Wetten“. Es handelt nur, wenn es sicher ist, und bleibt stehen, wenn es unsicher ist.Diese Strategie mit hoher Signalqualität ermöglichte begrenzte Rückschläge bei Marktkorrekturen und bewahrte letztendlich die Früchte des Sieges.
DeepSeek hatte mit nur 41 in 17 Tagen eine ähnliche Anzahl an Bewegungen wie Qwen, verhielt sich jedoch eher wie ein vorsichtiger Fondsmanager. Es hat die höchste Sharpe-Ratio unter allen Akteuren und erreicht 0,359, eine Zahl, die auf dem hochvolatilen Kryptowährungsmarkt ohnehin schon recht selten ist.
Auf traditionellen Finanzmärkten wird die Sharpe-Ratio üblicherweise zur Messung risikobereinigter Renditen verwendet.Je höher der Wert, desto robuster ist die Strategie. Aber in einem so kurzen Zyklus und einem so gewalttätigen Markt ist jedes Modell, das einen positiven Wert aufrechterhalten kann, nicht einfach.Die Ergebnisse von DeepSeek zeigen, dass es nicht um die Maximierung der Erträge geht, sondern darum, das Gleichgewicht in einer Umgebung mit hohem Lärmpegel aufrechtzuerhalten.
Während des gesamten Spiels hielt es stets den Rhythmus und jagte der Steigerung nicht hinterher oder bewegte sich blind.Er ähnelt eher einem Händler mit einem strengen System und verzichtet lieber auf Chancen, als dass Emotionen die Entscheidungsfindung dominieren.
Im Gegensatz dazu offenbart die Leistung des US-amerikanischen KI-Lagers offensichtliche Probleme bei der Risikokontrolle.
Googles Gemini hat in 17 Tagen insgesamt 238 Bestellungen aufgegeben, durchschnittlich mehr als 13 Mal am Tag, die häufigste unter allen Spielern.Solche Hochfrequenztransaktionen verursachten auch enorme Kosten: Allein die Bearbeitungsgebühren kosteten 1.331 US-Dollar, was 13 % des ursprünglichen Kapitals ausmachte.Bei einem Turnier mit einem Startkapital von nur 10.000 $ ist das eine enorme Belastung für Sie.
Schlimmer noch ist, dass dieser häufige Handel keine zusätzlichen Einnahmen bringt.Zwillinge versuchen es immer wieder und machen Fehler, stoppen Verluste und versuchen es immer wieder, wie ein Kleinanleger, der davon besessen ist, den Markt zu beobachten und sich vom Lärm des Marktes leiten zu lassen.Jede geringfügige Preisschwankung löst einen Handelsauftrag aus.Es reagiert zu schnell auf Schwankungen und nimmt Risiken zu langsam wahr.
In der Verhaltensfinanzierung hat dieses Ungleichgewicht einen Namen: Selbstüberschätzung.Händler überschätzen ihre Prognosefähigkeiten, ignorieren jedoch die Anhäufung von Unsicherheit und Kosten.Das Scheitern der Zwillinge ist eine typische Folge dieser blinden Zuversicht.
Die Leistung von GPT-5 ist äußerst enttäuschend.Es waren nicht viele Schüsse erforderlich, 116 in 17 Tagen, aber die Risikokontrolle war gering.Der größte Einzelverlust betrug 622 US-Dollar, während der größte Gewinn nur 271 US-Dollar betrug.Das Gewinn-Verlust-Verhältnis war gravierend unausgewogen. Es ist wie ein Spieler, der von Selbstvertrauen getrieben wird.Er kann gelegentlich gewinnen, wenn der Markt gut läuft, aber sobald der Markt umkehrt, werden die Verluste vervielfacht.
Es hat eine Sharpe-Ratio von -0,525, was bedeutet, dass es kein Risiko im Gegenzug für eine Belohnung eingegangen ist.Im Bereich der Investitionen entspricht dieses Ergebnis fast der Aussage „Es ist besser, nicht zu operieren“.
Dieses Experiment beweist einmal mehr, dass nicht die Genauigkeit der Vorhersagen des Modells wirklich über Sieg oder Niederlage entscheidet, sondern wie es mit Unsicherheit umgeht.Der Sieg von Qwen und DeepSeek ist im Wesentlichen ein Sieg der Risikokontrolle.Sie scheinen besser zu verstehen, dass man auf dem Markt nur dann als schlau gelten kann, wenn man als Erster überlebt.
Der reale Markt ist der Spiegel der KI
Die Ergebnisse von Alpha Arena sind eine starke Verhöhnung des aktuellen KI-Bewertungssystems.Die „intelligenten Modelle“, die in Benchmark-Tests wie MMLU zu den Besten zählen, verlieren auf dem realen Markt an Boden.
Diese Modelle sind aus unzähligen Texten gestapelte Sprachmeister. Sie können Antworten mit strenger Logik und perfekter Grammatik generieren, aber sie verstehen möglicherweise nicht die Realität, auf die diese Texte wirklich hinweisen.
Eine KI kann in wenigen Sekunden einen Aufsatz über Risikomanagement verfassen, mit angemessenen Zitaten und vollständiger Begründung; Es kann auch genau erklären, was Sharpe Ratio, maximaler Drawdown und Value at Risk sind.Aber wenn es tatsächlich über das Geld verfügt, kann es die riskantesten Entscheidungen treffen.Weil es nur „weiß“ und nicht „versteht“.
Wissen und Verstehen sind zwei verschiedene Dinge.
Es gibt einen großen Unterschied zwischen der Fähigkeit, es zu sagen, und der Fähigkeit, es zu tun.
Diese Lücke wird in der Philosophie als erkenntnistheoretisches Problem bezeichnet. Platon unterschied einst zwischen Wissen und wahrem Glauben.Wissen ist nicht nur richtige Information, sondern auch das Verständnis dafür, warum sie richtig ist.
Die heutigen großen Sprachmodelle verfügen möglicherweise über Unmengen „richtiger Informationen“, aber sie verfügen nicht über diese Art von Verständnis.Es kann Ihnen sagen, wie wichtig Risikomanagement ist, weiß aber nicht, wie Menschen diese Bedeutung aus Angst und Verlust lernen.
Der echte Markt ist der ultimative Ort, um Ihr Verständnis zu testen. Es wird nicht nachsichtig sein, nur weil Sie GPT-5 sind.Jede Fehlentscheidung schlägt sich sofort in Form eines Geldverlustes auf dem Konto nieder.
Im Labor kann die KI unzählige Male wiederholt werden, indem sie ständig Parameter anpasst und Backtests durchführt, bis sie die sogenannte „richtige Antwort“ findet.Aber auf dem Markt bedeutet jeder Fehler einen Verlust von echtem Geld, und für diesen Verlust gibt es kein Zurück.
Auch die Logik des Marktes ist weitaus komplexer, als das Modell es sich vorstellt. Wenn der Kapitalbetrag um 50 % verloren geht, ist eine Rendite von 100 % erforderlich, um zum Ausgangspunkt zurückzukehren;Wenn sich der Verlust auf 62,66 % erhöht, steigt die zur Rückgabe des Kapitals erforderliche Rendite auf 168 %. Dieses nichtlineare Risiko vervielfacht die Fehlerkosten.KI kann Verluste durch Algorithmen während des Trainings minimieren, aber sie kann den durch Angst, Zögern und Gier geprägten Marktbestrafungsmechanismus nicht wirklich verstehen.
Aus diesem Grund ist der Markt zu einem Spiegel geworden, um die Authentizität von Informationen zu testen. Dadurch können Menschen und Maschinen klar erkennen, was sie wirklich wissen und wovor sie wirklich Angst haben.
Dieses Spiel bringt die Menschen auch dazu, die Unterschiede in den KI-F&E-Ideen zwischen China und den Vereinigten Staaten zu überdenken.
Mehrere Mainstream-Unternehmen in den Vereinigten Staaten halten immer noch an der gemeinsamen Modellroute fest und hoffen, Systeme zu bauen, die bei einem breiten Aufgabenspektrum stabile Fähigkeiten unter Beweis stellen können.Die Modelle von OpenAI, Google und Anthropic gehören alle zu diesem Typ. Ihr Ziel ist es, Breite und Konsistenz anzustreben, damit das Modell über domänenübergreifende Verständnis- und Argumentationsfähigkeiten verfügt.
Das chinesische Team zieht es vor, die Implementierung und den Feedback-Mechanismus spezifischer Szenarien in den frühen Phasen der Modellentwicklung zu berücksichtigen.Obwohl Alibabas Qwen ebenfalls ein Allzweck-Großmodell ist, wurde seine Trainings- und Testumgebung bereits früher mit dem eigentlichen Geschäftssystem verbunden. Dieser Datenrückfluss aus realen Szenarien kann das Modell unsichtbar gegenüber Risiken und Einschränkungen empfindlicher machen.Die Leistung von DeepSeek weist ähnliche Merkmale auf, da es offenbar in der Lage ist, Entscheidungen in dynamischen Umgebungen schneller zu korrigieren.
Dabei geht es nicht darum, „wer gewinnt und wer verliert“. Dieses Experiment bietet einen Einblick in die Leistung verschiedener Trainingsphilosophien in der realen Welt.Allzweckmodelle legen Wert auf Universalität, neigen jedoch dazu, in extremen Umgebungen nicht zu reagieren;während Modelle, die früher echtem Feedback ausgesetzt sind, in komplexen Systemen möglicherweise flexibler und stabiler erscheinen.
Natürlich spiegeln die Ergebnisse eines Spiels möglicherweise nicht die Gesamtstärke der chinesischen und amerikanischen KI wider.Der siebzehntägige Handelszyklus ist zu kurz und der Einfluss von Glück lässt sich kaum ausschließen;Bei einer Verlängerung der Zeit kann der Trend völlig anders ausfallen.Darüber hinaus handelt es sich bei diesem Test nur um den Handel mit unbefristeten Kryptowährungskontrakten, der weder auf alle Finanzmärkte hochgerechnet werden kann, noch reicht er aus, um die Leistung von KI in anderen Bereichen zu verallgemeinern.
Aber es reicht aus, um zu überdenken, was wahre Fähigkeit ausmacht.Wenn KI in eine reale Umgebung eingesetzt wird und Entscheidungen inmitten von Risiken und Unsicherheiten treffen muss, sehen wir nicht nur den Erfolg oder Misserfolg des Algorithmus, sondern auch die unterschiedlichen Wege.Auf dem Weg, KI-Technologie in tatsächliche Produktivität umzuwandeln, hat Chinas Modell in bestimmten Bereichen bereits die Führung übernommen.
Als das Spiel endete, war Qwens letzte Bitcoin-Position geschlossen, so dass sein Kontostand bei 12.232 $ lag.Es hat gewonnen, aber es wusste nicht, dass es gewonnen hatte.Dieser Zuwachs von 22,32 % bedeutet nichts, es handelt sich lediglich um einen weiteren Ausführungsbefehl.
Im Silicon Valley können sich Ingenieure möglicherweise immer noch über eine weitere Verbesserung des MMLU-Scores von GPT-5 um 0,1 % freuen.Auf der anderen Seite der Welt hat KI aus China gerade in einem Echtgeld-Casino auf einfachste Weise bewiesen, dass nur gute KI Geld verdienen kann.
Nof1.ai gab bekannt, dass die nächste Wettbewerbssaison bald beginnen wird. Der Zyklus wird länger, es wird mehr Teilnehmer geben und das Marktumfeld wird komplexer.Werden die Models, die in der ersten Staffel gescheitert sind, etwas aus ihren Verlusten lernen?Oder wird sich das gleiche Schicksal mit größeren Schwankungen wiederholen?
Niemand kennt die Antwort.Sicher ist jedoch, dass alles anders sein wird, wenn die KI beginnt, aus dem Elfenbeinturm zu treten und sich mit echtem Geld zu beweisen.