Autor: Lucas Tcheyan, Arjun Yenamandra, Quelle: Galaxy Research, zusammengestellt von: Bitchain Vision
Einführung
Im vergangenen Jahr veröffentlichte Galaxy Research seinen ersten Artikel über die Schnittstelle von Kryptowährung und künstlicher Intelligenz. In dem Artikel wird untersucht, wie Kryptowährung ohne Vertrauen und mit freundlicher Genehmigung ohne Infrastruktur zur Grundlage für KI -Innovation werden kann. Dazu gehören: die Entstehung eines dezentralen Marktes zur Verarbeitungsleistung (oder zum Computer), das als Reaktion auf den Mangel an Grafikprozessoren (GPUs) entstanden ist;die frühen Anwendungen von Null-Knowledge Machine Learning (ZKML) in überprüfbarem On-Chain-Denken;und das Potenzial autonomer KI -Agenten, komplexe Wechselwirkungen zu vereinfachen und Kryptowährungen als natives Austauschmedium zu verwenden.
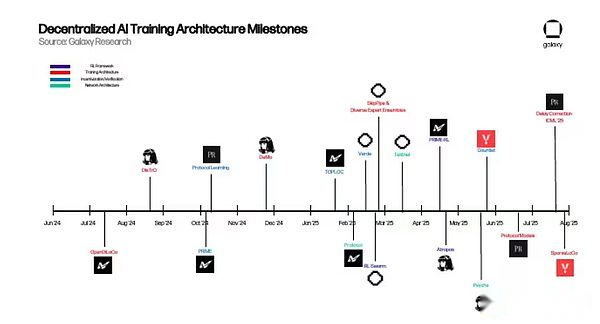
Zu dieser Zeit standen viele dieser Initiativen in den Kinderschuhen, waren jedoch nur einige überzeugende Beweise für Konzepte, die implizieren, dass sie praktische Vorteile gegenüber zentralisierten Lösungen hatten, aber noch nicht genug erweitert hatten, um die KI -Landschaft neu zu formen.In dem Jahr seitdem hat die dezentrale KI jedoch sinnvolle Fortschritte bei der Erzielung erzielt.Um diesen Dynamik zu erfassen und den vielversprechendsten Fortschritt zu entdecken, wird Galaxy Research im kommenden Jahr eine Reihe von Artikeln veröffentlichen, um bestimmte Vertikale an den Grenzen der Verschlüsselung + künstliche Intelligenz zu untersuchen.
Dieser Artikel wurde erstmals in Decentralized Training veröffentlicht, wobei sich auf Projekte konzentriert, die sich auf globaler Ebene um eine genehmigte Schulung von Basismodellen widmen.Die Motivationen für diese Projekte sind doppelt.Aus praktischer Sicht erkannten sie, dass eine große Anzahl von Leerlauf -GPUs auf der ganzen Welt für das Modelltraining verwendet werden kann, um KI -Ingenieuren auf der ganzen Welt einen ansonsten unerträglichen Trainingsprozess zu bieten und die Open -Source -KI -Entwicklung Wirklichkeit werden zu lassen.Aus konzeptioneller Sicht sind diese Teams durch die strenge Kontrolle einer der wichtigsten technologischen Revolutionen unserer Zeit und der dringenden Notwendigkeit, offene Alternativen zu schaffen.
Im weiteren Sinne ist die Implementierung des dezentralen und anschließenden Trainings des Basismodells ein wesentlicher Schritt zum Aufbau eines vollständig Onketten-KI-Stacks, der keine Erlaubnis erfordert und in jeder Ebene zugänglich ist.Der GPU -Markt kann auf Modelle zugreifen und die für Schulungen und Inferenz erforderliche Hardware bereitstellen.ZKML -Anbieter können verwendet werden, um die Modellausgabe zu überprüfen und die Privatsphäre zu schützen.AI-Agenten können als komponierbare Bausteine fungieren, die Modelle, Datenquellen und Protokolle in Anwendungen höherer Ordnung kombinieren.
In diesem Bericht wird die zugrunde liegende Architektur des dezentralen Protokolls für künstliche Intelligenz, die technischen Probleme, die sie lösen, und die Aussichten auf eine dezentrale Ausbildung untersucht.Die zugrunde liegende Prämisse von Kryptowährungen und künstlichen Intelligenz bleibt wie vor einem Jahr.Kryptowährungen bieten KI eine leistungslose, vertrauenslose und komponierbare Übertragungsübertragungsschicht.Die Herausforderung besteht nun darin, zu beweisen, dass dezentrale Ansätze praktische Vorteile gegenüber zentralisierten Ansätzen erzielen können.
Grundlagen des Modelltrainings
Bevor Sie in die neuesten Fortschritte im dezentralen Training eintauchen, ist es notwendig, ein grundlegendes Verständnis für Großsprachmodelle (LLMs) und ihre zugrunde liegende Architektur zu verzeichnen.Dies wird den Lesern helfen, zu verstehen, wie diese Projekte funktionieren und welche Hauptprobleme sie lösen möchten.
Transformator
Große Sprachmodelle (LLMs) (wie ChatGPT) werden von einer Architektur namens Transformator angetrieben. Transformator schlug erstmals in einem Google -Papier von 2017 vor und ist eine der wichtigsten Innovationen im Bereich der Entwicklung künstlicher Intelligenz.Kurz gesagt, Transformator extrahiert Daten (als Token genannte) und wendet verschiedene Mechanismen an, um die Beziehung zwischen diesen Token zu lernen.
Die Beziehung zwischen Einträgen wird unter Verwendung von Gewichten modelliert.Gewichte können als die Millionen bis Billionen von Knöpfen angesehen werden, aus denen das Modell besteht, die ständig angepasst werden, bis der nächste Eintrag in der Sequenz konstant vorhergesagt werden kann.Nach Abschluss des Trainings kann das Modell die Muster und Bedeutungen hinter der menschlichen Sprache grundsätzlich erfassen.
Zu den Schlüsselkomponenten des Transformator -Trainings gehören:
-
Vorwärtslieferung:Im ersten Schritt des Trainingsprozesses tritt der Transformator aus einem größeren Datensatz in eine Reihe von Token ein. Basierend auf diesen Eingaben versucht das Modell vorherzusagen, was das nächste Token sein sollte.Zu Beginn des Trainings sind die Gewichte des Modells zufällig.
-
Verlustberechnung:Vorhersage vorwärtsvermeidungsvorhersagen werden dann verwendet, um den Verlustwert zu berechnen, der die Lücke zwischen diesen Vorhersagen und den tatsächlichen Markierungen in der ursprünglichen Datenstapel des Eingangsmodells misst.Mit anderen Worten, wie werden die vom Modell während der Vorwärtsvermutung erzeugten Vorhersagen mit den tatsächlichen Markern, die zum Training im größeren Datensatz verwendet werden, verglichen werden?Während des Trainings ist es das Ziel, diesen Verlustwert zu verringern, um die Genauigkeit des Modells zu verbessern.
-
Backpropagation:Der Gradient jedes Gewichts wird dann unter Verwendung des Verlustwerts berechnet.Diese Gradienten geben dem Modell an, wie die Gewichte angepasst werden sollen, um die Verluste vor der nächsten Vorwärtsverbreitung zu reduzieren.
-
Optimierererneuern:OptimierenRDer Algorithmus liest diese Gradienten und passt jedes Gewicht an, um den Verlust zu verringern.
-
wiederholen:Wiederholen Sie die obigen Schritte, bis alle Daten verbraucht wurden und das Modell die Konvergenz erreichen beginnt– –Mit anderen Worten, wenn eine weitere Optimierung nicht mehr zu einer signifikanten Verringerung der Verluste oder der Leistungsverbesserung führt.
Training (Vorausbildung und Nachbildung)
Der vollständige Modelltrainingsprozess besteht aus zwei unabhängigen Schritten: Vorausbildung und Nachtraining. Die obigen Schritte sind eine Kernkomponente des Vorausbildungsprozesses.Wenn sie fertig sind, erzeugen sie ein vorgebildetes Basismodell, das allgemein als Basismodell bezeichnet wird.
Modelle erfordern jedoch häufig eine weitere Verbesserung nach der Vorbereitung, was als Nachtraining bezeichnet wird.Nach dem Training wird das Basismodell auf vielfältige Weise weiter verbessert, einschließlich der Verbesserung seiner Genauigkeit oder der Anpassung für bestimmte Anwendungsfälle wie Translation oder medizinische Diagnose.
Nach dem Training ist heute ein wichtiger Schritt bei der Herstellung von großsprachigen Modellen (LLMs) zu einem leistungsstarken Tool.Es gibt verschiedene Möglichkeiten, anschließend zu trainieren. Die beiden beliebtesten sind:
-
Übersichtliche Feinabstimmung (SFT):SFT ist dem oben genannten Vor-Trainingsprozess sehr ähnlich.Der Hauptunterschied besteht darin, dass das Basismodell auf sorgfältiger geplanten Datensätzen oder Tipps und Antworten geschult wird, sodass es lernen kann, bestimmte Anweisungen zu befolgen oder sich auf ein bestimmtes Feld zu konzentrieren.
-
Verstärkungslernen (RL):RL verbessert das Modell nicht durch Eingabe neuer Daten, sondern durch die Bewertung der Ausgabe des Modells und durch die Aktualisierung des Modells das Gewicht, um diese Belohnung zu maximieren. Kürzlich hat das Inferenzmodell (unten beschrieben) RL verwendet, um seine Ausgabe zu verbessern.In den letzten Jahren wurden nach dem Auftreten von Skalierungsproblemen vor dem Training erhebliche Fortschritte bei der Verwendung von RL- und Inferenzmodellen nach dem Training erzielt, da die Modellleistung ohne zusätzliche Daten oder große Berechnungsmengen erheblich verbessert wird.
Insbesondere ist das Nach-RL-Training ideal, um Hindernisse zu lösen, die im verteilten Training konfrontiert sind (nachstehend beschrieben).Dies liegt daran, dass das Modell die meiste Zeit in RL Vorwärtskarten verwendet (das Modell macht Vorhersagen, sich jedoch noch nicht verändert), um eine große Ausgabemenge zu erzeugen.Diese Vorwärtspässe erfordern keine Koordination oder Kommunikation zwischen Maschinen und können asynchron erfolgen.Sie sind auch parallel, was bedeutet, dass sie in unabhängige Unteraufgaben unterteilt werden können, die gleichzeitig auf mehreren GPUs durchgeführt werden können.Dies liegt daran, dass jeder Rollout unabhängig berechnet werden kann und einfach die Berechnung hinzufügen kann, um den Durchsatz durch den Trainingslauf zu erhöhen.Erst nachdem die beste Antwort ausgewählt ist, aktualisiert das Modell die internen Gewichte und verringert die Frequenz, mit der die Maschine synchronisiert werden muss.
Nach dem Training des Modells wird der Prozess der Verwendung zur Erzeugung von Ausgabe als Inferenz bezeichnet.Im Gegensatz zu Schulungen, die Anpassungen an Millionen oder sogar Milliarden Gewichte erfordert, hält die Argumentation diese Gewichte unverändert und wendet sie einfach auf neue Eingaben an.Für Großsprachmodelle (LLM) bedeutet das Argumentation, eine Eingabeaufforderung zu nehmen, sie zu verschiedenen Schichten des Modells zu leiten und Schritt für Schritt das wahrscheinlichste nächste Markup vorherzusagen.Da Inferenz keine Backpropagation (den Prozess der Anpassung von Gewichten basierend auf dem Fehler des Modells) oder Gewichtsaktualisierungen erfordert, erfordert es viel weniger rechnerisch als das Training, aber aufgrund der großen Auswahl an modernen Modellen ist es immer noch ressourcenintensiv.
Kurz gesagt: Argumentation ist die treibende Kraft hinter Anwendungen wie Chatbots, Codeassistenten und Übersetzungstools.In dieser Phase setzt das Modell sein „erlerntes Wissen“ in die Praxis um.
Training Overhead
Die Förderung des obigen Schulungsprozesses erfordert ressourcenintensive und hochspezialisierte Software und Hardware, die im Maßstab ausgeführt werden können.Die Investitionen in die weltweit führenden künstlichen Intelligenzlabors haben ein beispielloses Niveau erreicht, von Hunderten von Millionen bis Milliarden von Dollar.Sam Altman, CEO von OpenAI, sagte, der GPT-4 habe mehr als 100 Millionen US-Dollar gekostet, während der anthropische CEO Dario Amodei bereits mehr als 1 Milliarde US-Dollar an Schulungsprogrammen im Gange seien.
Ein großer Teil dieser Kosten stammt von GPUs.Top -GPUs wie Nvidia H100 oder B200 kosten bis zu 30.000 US -Dollar, und Openai plant Berichten zufolge, bis Ende 2025 mehr als eine Million GPUs einzusetzen.Es reicht jedoch nicht aus, die Macht der GPU allein zu haben. Diese Systeme müssen in leistungsstarken Rechenzentren eingesetzt werden, die mit einer ultrahoch-hohen Kommunikationsinfrastruktur ausgestattet sind.Technologien wie NVIDIA NVLINK unterstützen den schnellen Datenaustausch zwischen GPUs innerhalb des Servers, während Infiniband eine Verbindung zu Serverclustern herstellt, damit sie als einzelne, einheitliche Computerstruktur ausgeführt werden können.
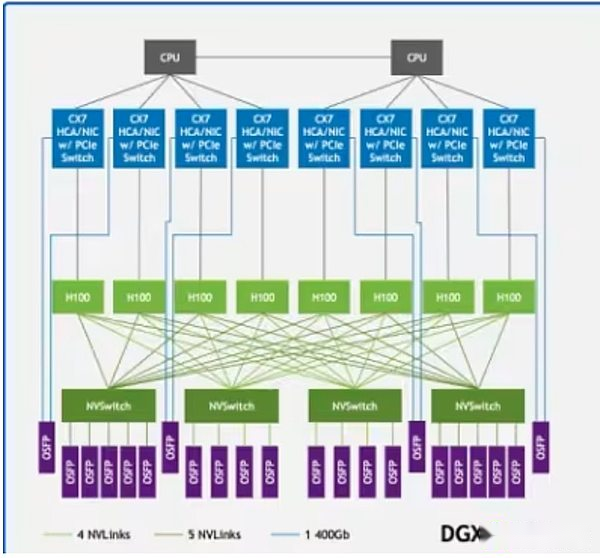 NVLink in der DGX H100 -Probenarchitektur verbindet den GPUs (hellgrüne Rechtecke) im System, während Infiniband die Server (grüne Linien) mit einem einheitlichen Netzwerk verbindet
NVLink in der DGX H100 -Probenarchitektur verbindet den GPUs (hellgrüne Rechtecke) im System, während Infiniband die Server (grüne Linien) mit einem einheitlichen Netzwerk verbindet
Daher werden die meisten Basismodelle von zentralisierten AI -Labors wie OpenAI, Anthrop, Meta, Google und XAI entwickelt. Nur solche Riesen verfügen über die reichhaltigen Ressourcen, die für das Training benötigt werden.Obwohl dies einen signifikanten Durchbruch bei Modelltraining und -leistung erzielt hat, hat es auch die Kontrolle über die Entwicklung führender Grundmodelle in den Händen einiger Einheiten konzentriert.Darüber hinaus gibt es zunehmend Hinweise darauf, dass das Gesetz der Skalierung funktionieren kann, was die Wirksamkeit der Verbesserung der Intelligenz vorbereiteter Modelle durch einfaches Hinzufügen von Berechnungen oder Daten einschränkt.
Um diese Herausforderung zu befriedigen, hat eine Gruppe von KI -Ingenieuren in den letzten Jahren begonnen, neue Modelltrainingsmethoden zu entwickeln, um diese technischen Komplexität zu befriedigen und enorme Ressourcenanforderungen zu reduzieren.Dieser Artikel nennt diese Bemühungen „dezentrales Training“.
Dezentrales und verteiltes Training
Der Erfolg von Bitcoin beweist, dass Computer und Kapital auf dezentrale Weise koordiniert werden können, wodurch die Sicherheit großer wirtschaftlicher Netzwerke gewährleistet werden kann.Das dezentrale Training zielt darauf ab, ein dezentrales Netzwerk unter Verwendung der Merkmale von Kryptowährungen, einschließlich kontrollloser, vertrauensloser und Anreizmechanismen, aufzubauen, um ein leistungsstarkes Basismodell auszubilden, das mit zentralisierten Anbietern vergleichbar ist.
Im dezentralen Training arbeiten Knoten an verschiedenen Orten auf der ganzen Welt an genehmigten, anreizenden Netzwerken und tragen zur Ausbildung künstlicher Intelligenzmodelle bei.Dies unterscheidet sich von verteiltem Training, das sich auf das Modell bezieht, das in verschiedenen Regionen geschult wird, jedoch von einem oder mehreren Unternehmen durchgeführt wird, die lizenziert sind (d. H. Durch einen Whitelisting -Prozess).Die Machbarkeit eines dezentralen Trainings muss jedoch auf verteilten Schulungen beruhen.Viele zentralisierte Labors, die sich der strengen Einschränkungen ihrer Schulungseinstellungen bewusst sind, haben begonnen, Wege zu untersuchen, um verteilte Schulungen zu implementieren, um Ergebnisse zu erzielen, die mit vorhandenen Einstellungen vergleichbar sind.
Es gibt einige praktische Hindernisse, die verhindern, dass dezentrales Training Wirklichkeit wird:
-
Kommunikationsaufwand:Wenn Knoten geografisch verteilt sind, können sie nicht auf die obige Kommunikationsinfrastruktur zugreifen.Das dezentrale Training erfordert die Berücksichtigung der Standard -Netzwerkgeschwindigkeit, die häufige Übertragung großer Datenmengen und die GPU -Synchronisation während des Trainings.
-
verifizieren:Dezentrale Schulungsnetzwerke sind im Wesentlichen lizenzfrei und sollen jedem dazu ermöglichen, seine Rechenleistung beizutragen.Daher müssen sie Überprüfungsmechanismen entwickeln, um zu verhindern, dass Mitwirkende versuchen, das Netzwerk durch falsche oder böswillige Eingaben zu zerstören oder Systemanfälligkeiten zu nutzen, um Belohnungen zu erhalten, ohne eine wirksame Arbeit beizutragen.
-
berechnen: Unabhängig von der Größe müssen dezentrale Netzwerke genügend Rechenleistung sammeln, um Modelle zu trainieren.Während dies einige der Vorteile dezentraler Netzwerke bietet, die es jedem mit einer GPU ermöglichen, am Trainingsprozess teilzunehmen, bringt es auch Komplexität, da diese Netzwerke heterogenes Computer koordinieren müssen.
-
Anreize/Finanzierung/Eigentum und Monetarisierung:Dezentrale Schulungsnetzwerke müssen Incentive -Mechanismen und Eigentümer-/Monetarisierungsmodelle entwerfen, um die Netzwerkintegrität effektiv sicherzustellen und den Beitrag von Computeranbietern, Validatoren und Modelldesignern zu belohnen.Dies steht in scharfem Gegensatz zu dem zentralisierten Labor, in dem die Konstruktion und Monetarisierung des Modells von einem Unternehmen durchgeführt werden.
Trotz dieser Einschränkungen implementieren viele Projekte immer noch eine dezentrale Schulung, weil sie der Ansicht sind, dass die Kontrolle über das zugrunde liegende Modell nicht in den Händen einiger weniger Unternehmen liegen sollte.Ihr Ziel ist es, mit den Risiken umzugehen, die durch zentrales Training bestehen, z. Datenschutz und Zensur; Skalierbarkeit;und Konsistenz und Voreingenommenheit in der künstlichen Intelligenz.Im weiteren Sinne glauben sie, dass die Entwicklung von Open Source -Entwicklung künstlicher Intelligenz eine Notwendigkeit ist, nicht optional.Ohne offene, überprüfbare Infrastruktur wird die Innovation unterdrückt, der Zugang wird auf einige privilegierte Klassen beschränkt, und die Gesellschaft wird KI -Systeme erben, die durch enge Unternehmensanreize geprägt sind.Aus dieser Perspektive geht es bei dezentraler Schulungen nicht nur um den Aufbau von Wettbewerbsmodellen, sondern auch darum, ein belastbares, transparentes und partizipatives Ökosystem zu schaffen, das eher kollektive Interessen als proprietäre Interessen widerspiegelt.
Projektübersicht
Im Folgenden geben wir einen umfassenden Überblick über die zugrunde liegenden Mechanismen mehrerer dezentraler Schulungsprojekte.
Nous Resort
Hintergrund
Nous Research wurde 2022 gegründet und ist eine Open -Source -AI -Forschungseinrichtung. Das Team begann als informelle Gruppe von Open -Source -KI -Forschern und -Entätigern, die daran arbeiteten, die Einschränkungen des Open -Source -KI -Codes anzugehen.Seine Mission ist es, „das beste Open -Source -Modell zu erstellen und bereitzustellen“.
Das Team hat das dezentrale Training seit langem als ein großes Hindernis angesehen.Insbesondere stellten sie fest, dass die Tools zum Zugriff auf GPUs und zur Koordinierung der Kommunikation zwischen GPUs in erster Linie entwickelt wurden, um große zentralisierte KI-Unternehmen zu richten, bei denen Organisationen, die ressourcenbezogene Organisationen mit wenig Raum für die Teilnahme an einer sinnvollen Entwicklung ließen.Zum Beispiel kann der neueste Blackwell -GPUs von NVIDIA (wie das B200) miteinander kommunizieren, indem ein NVLink -Schaltsystem mit einer Geschwindigkeit von bis zu 1,8 TB pro Sekunde verwendet wird.Dies ist vergleichbar mit der Gesamtbandbreite der Mainstream-Internetinfrastruktur und kann nur in zentralisierten Bereitstellungen im Rechenzentrumskala erreicht werden.Daher ist es für kleine oder verteilte Netzwerke nahezu unmöglich, die Leistung großer AI -Labors zu erreichen, ohne Kommunikationsstrategien zu überdenken.
Vor der Lösung des Problems des dezentralen Trainings hat Nous erhebliche Beiträge zum Bereich der künstlichen Intelligenz geleistet.Im August 2023 veröffentlichte Nous „Garn: Effiziente Kontextfenstererweiterung für Großsprachenmodelle“.Dieses Papier löst ein einfaches, aber wichtiges Problem: Die meisten KI -Modelle können sich nur eine feste Menge Text nacheinander erinnern und verarbeiten (d. H. Ihr „Kontextfenster“).Beispielsweise wird ein Modell, das mit einer Grenze von 2.000 Wörtern trainiert wurde, bald zu vergessen oder zu verlieren, wenn das Eingabedokument länger ist.Garn führt eine Möglichkeit ein, diese Einschränkung weiter zu erweitern, ohne das Modell von Grund auf neu umzuschicken.Es passt die Art und Weise, wie das Modell die Wortposition verfolgt (wie Lesezeichen in einem Buch), so, dass es noch den Informationsfluss verfolgen kann, auch wenn der Text Zehntausende von Wörtern lang ist.Die Methode ermöglicht es dem Modell, Sequenzen von bis zu 128.000 Markierungen zu verarbeiten – über die Länge von Mark Twains Abenteuern von Huckleberry Finn – und viel weniger Rechenleistung und Trainingsdaten gleichzeitig als die alte Methode.Kurz gesagt, mit Garn können KI -Modelle längere Dokumente, Gespräche oder Datensätze gleichzeitig „lesen“ und verstehen.Dies ist ein großer Fortschritt bei der Erweiterung der KI -Fähigkeiten und wurde von einer breiteren Forschungsgemeinschaft wie Openai und Deepseek in China übernommen.
Demo und Distribution
Im März 2024 veröffentlichte Nous einen Durchbruch auf dem Gebiet des verteilten Trainings, der als „entkoppeltes Momentum -Optimierung“ (Demo) bezeichnet wurde. Demo wurde von den NOUS-Forschern Bowen Peng und Jeffrey Quesnelle in Zusammenarbeit mit den Mitbegründer von OpenAI und Erfinder von Adamw Optimierer entwickelt.Es ist der Hauptbaustein des nusköpfigen Schulungsstapels, der den Kommunikationsaufwand in verteilten Daten -Parallelmodell -Schulungseinstellungen verringert, indem die Menge der zwischen GPUs ausgetauschten Daten reduziert wird.In Daten parallele Schulungen speichert jeder Knoten eine vollständige Kopie der Modellgewichte, der Datensatz wird jedoch in Blöcke aufgeteilt, die von verschiedenen Knoten verarbeitet werden.
Adamw ist einer der am häufigsten verwendeten Optimierer im Modelltraining.Eine Schlüsselfunktion von ADAMW besteht darin, das sogenannte Dynamik zu glätten, der laufende Durchschnitt der Modellgewichte, die sich in der Vergangenheit ändern.Im Wesentlichen hilft ADAMW bei der Beseitigung von Rauschen, die während der Daten parallele Schulungen eingeführt werden, wodurch die Schulungseffizienz verbessert wird.Nous Research erzeugt einen völlig neuen Optimierer, der auf Adamw und Demo basiert und Dynamik in lokale und gemeinsame Teile in verschiedenen Trainern aufteilt.Dies verringert die zwischen Knoten erforderliche Menge an Verkehr, indem die Datenmenge eingeschränkt wird, die zwischen Knoten geteilt werden muss.
Demo konzentriert sich selektiv auf die am schnellsten verändernden Parameter während jeder GPU-Iteration.Die Logik ist einfach: Parameter mit größeren Variationen sind entscheidend für das Lernen und sollten zwischen Arbeitnehmern mit höherer Priorität synchronisiert werden.Gleichzeitig können sich langsamer-verändernde Parameter vorübergehend verzögern, ohne die Konvergenz erheblich zu beeinflussen.Tatsächlich filtert dies Geräuschaktualisierungen und behält gleichzeitig die aussagekräftigsten Aktualisierungen bei.Nous verwendet auch Komprimierungstechniken, einschließlich einer diskreten Cosinus -Transformationsmethode (DCT) ähnlich wie bei JPEG -komprimierten Bildern, um die gesendete Datenmenge weiter zu reduzieren.Durch die Synchronisierung nur die wichtigsten Aktualisierungen reduziert Demo den Kommunikationsaufwand um das 10- bis 1.000 -fache (abhängig von der Modellgröße).
Im Juni 2024 startete das Nous -Team seine zweite große Innovation, den verteilten Trainingsoptimierer (Distribution).Demo bietet Core -Optimierer -Innovationen, während die Distro in ein breiteres Optimierer -Framework integriert, das Informationen weiter komprimiert, die zwischen GPUs geteilt werden und Probleme wie GPU -Synchronisation, Fehlertoleranz und Lastausgleich angehen.Im Dezember 2024 verwendete Nous Distribution, um ein Modell mit 15 Milliarden Parametern auf einer Lama-ähnlichen Architektur zu trainieren, was die Machbarkeit der Methode beweist.
Psyche
Im Mai veröffentlichte Nous Psyche, ein Rahmen für die Koordinierung des dezentralen Trainings, weitere Innovationen in der Demo- und Distro -Optimierer -Architekturen. Zu den wichtigsten technischen Upgrades von Psyche gehören ein verbessertes asynchrones Training, indem die GPU bei Beginn des nächsten Trainingsschritts Modellaktualisierungen senden kann.Dies minimiert die Leerlaufzeit und bringt die GPU -Auslastung näher an zentralisierten, eng gekoppelten Systemen.Psyche verbesserte die durch Distribution eingeführte Komprimierungstechnologie weiter und verringerte die Kommunikationsbelastung weiter um das dreifache.
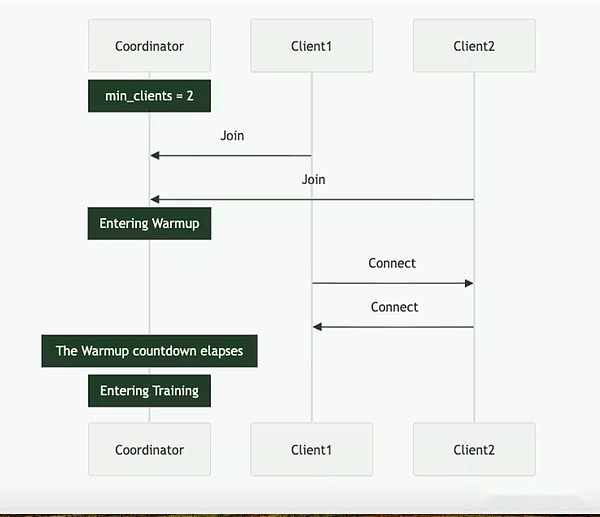
Psyche kann durch eine vollständige Kette (über Solana) oder Off-Chain-Setup erreicht werden. Es enthält drei Hauptakteure: den Koordinator, den Kunden und der Datenanbieter.Der Koordinator speichert alle erforderlichen Informationen, um den Schulungsbetrieb zu erleichtern, einschließlich des neuesten Standes des Modells, der teilnehmenden Kunden sowie der Datenallokation und der Ausgabeüberprüfung.Der Kunde ist der eigentliche GPU -Anbieter, der während der Trainingsläufe Schulungsaufgaben ausführt.Zusätzlich zum Modelltraining sind sie am Zeugenprozess (unten beschrieben) beteiligt.Der Datenanbieter (der Client kann es selbst speichern) liefert die für das Training erforderlichen Daten.
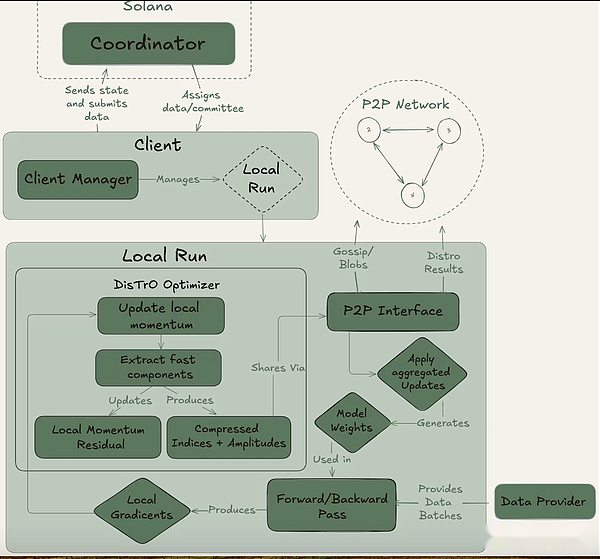 Psyche unterteilt das Training in zwei verschiedene Phasen: Epoche und Schritt.Dies schafft natürliche Eintritts- und Ausstiegspunkte für Kunden, damit sie teilnehmen können, ohne in einen vollständigen Trainingslauf zu investieren.Diese Struktur hilft, die Opportunitätskosten für GPU -Anbieter zu minimieren, da sie möglicherweise nicht in der Lage sind, Ressourcen während des gesamten Laufs zu investieren.
Psyche unterteilt das Training in zwei verschiedene Phasen: Epoche und Schritt.Dies schafft natürliche Eintritts- und Ausstiegspunkte für Kunden, damit sie teilnehmen können, ohne in einen vollständigen Trainingslauf zu investieren.Diese Struktur hilft, die Opportunitätskosten für GPU -Anbieter zu minimieren, da sie möglicherweise nicht in der Lage sind, Ressourcen während des gesamten Laufs zu investieren.
Zu Beginn einer Epoche definiert der Koordinator die Schlüsselparameter: die Modellarchitektur, der zu verwendende Datensatz und die Anzahl der erforderlichen Clients.Als nächstes folgt eine kurze Aufwärmphase, in der der Kunde mit dem neuesten Modell-Checkpoint synchronisiert wird, der von einer öffentlichen Quelle oder von anderen Clients-Punkt-zu-Punkt-Synchronisation stammen kann.Nach dem Beginn des Trainings wird jedem Kunde ein Teil der Daten zugewiesen und lokal geschult.Nach dem Berechnungsaktualisierung sendet der Client seine Ergebnisse zusammen mit dem Verschlüsselungsversprechen an den Rest des Netzwerks (der SHA-256-Hash, der beweist, dass die Arbeit korrekt durchgeführt wird).
Ein Teil des Klienten wird in jeder Runde zufällig als Zeugen ausgewählt und dient als Hauptverifizierungsmechanismus der Psyche.Diese Zeugen trainieren wie gewohnt, überprüfen aber auch, welche Kundenaktualisierungen empfangen und gültig sind.Sie senden Bloom -Filter an den Koordinator, eine leichte Datenstruktur, die diese Teilnehmer effektiv zusammenfasst.Während Nous selbst zugibt, dass der Ansatz nicht perfekt ist, weil er falsch positive Ergebnisse hervorrufen kann, sind die Forscher bereit, diesen Kompromiss für Effizienz zu akzeptieren.Sobald ein aktualisierter Zeuge bestätigt, dass das Quorum erreicht, wendet der Koordinator das Update auf das globale Modell an und ermöglicht es allen Clients, sein Modell vor dem Eintritt in die nächste Runde zu synchronisieren.
Entscheidend ist, dass das Design der Psyche eine Überschneidung in Training und Überprüfung ermöglicht.Sobald der Kunde das Update eingereicht hat, kann er sofort mit dem Training der nächsten Stapel beginnen, ohne darauf zu warten, dass der Koordinator oder andere Kunden die vorherige Schulungsrunde abschließen.Dieses überlappende Design in Kombination mit der Komprimierungstechnologie der Distribose stellt sicher, dass die Kommunikationsaufwand minimal gehalten wird und die GPU nicht untätig ist.
 Im Mai 2025 startete Nous Research den bislang größten Trainingslauf: Consilience, ein Transformator mit 40 Milliarden Parametern, das etwa 20 Billionen Token im psyche dezentralen Trainingsnetzwerk vor der Ausbildung vor der Ausbildung vor der Ausbildung stand.Das Training ist noch im Gange.Bisher war die Operation im Grunde stabil, aber es sind einige Verlustspitzen aufgetreten, was darauf hinweist, dass die Optimierungsbahn kurz von der Konvergenz abgewichen ist.Zu diesem Zweck rollte das Team zum letzten Checkpoint des Gesundheitswesens zurück und hat den Optimierer mit dem Skip-Step-Schutz von OLMO eingekapselt, der automatisch alle Aktualisierungen von Verlust- oder Gradientennormen überspringt, die sich durch mehrere Standardabweichungen vom Mittelwert unterscheiden, was das Risiko künftiger Peaks verringert.
Im Mai 2025 startete Nous Research den bislang größten Trainingslauf: Consilience, ein Transformator mit 40 Milliarden Parametern, das etwa 20 Billionen Token im psyche dezentralen Trainingsnetzwerk vor der Ausbildung vor der Ausbildung vor der Ausbildung stand.Das Training ist noch im Gange.Bisher war die Operation im Grunde stabil, aber es sind einige Verlustspitzen aufgetreten, was darauf hinweist, dass die Optimierungsbahn kurz von der Konvergenz abgewichen ist.Zu diesem Zweck rollte das Team zum letzten Checkpoint des Gesundheitswesens zurück und hat den Optimierer mit dem Skip-Step-Schutz von OLMO eingekapselt, der automatisch alle Aktualisierungen von Verlust- oder Gradientennormen überspringt, die sich durch mehrere Standardabweichungen vom Mittelwert unterscheiden, was das Risiko künftiger Peaks verringert.
Solanas Rolle
Während die Psyche in einer unüberlegten Umgebung laufen kann, ist sie für die Solana-Blockchain ausgelegt.Solana fungiert als Vertrauens- und Rechenschaftspflicht für das Schulungsnetzwerk, die Kundenverpflichtungen, Zeugen von Beweisen und Schulungsmetadaten in der Kette aufzeichnet.Dies schafft eine unveränderliche Prüfungsspur für jede Trainingsrunde, die ermöglicht, die Möglichkeiten zu ermöglichen, wer Beiträge geleistet hat, welche Arbeiten erledigt wurden und ob sie vergangen ist.
Nous plant auch, Solana zu nutzen, um die Verteilung der Schulungsprämien zu erleichtern.Obwohl das Projekt keine formelle Token -Ökonomie veröffentlicht hat, beschreibt die Dokumentation von Psyche ein System, in dem der Koordinator die Rechenbeiträge des Kunden verfolgt und Punkte basierend auf validierten Arbeiten zuteilt. Diese Punkte können dann gegen Token ausgetauscht werden, indem sie als finanzielle intelligente Verträge fungieren. Kunden, die effektive Schulungsschritte ausführen, können aufgrund ihrer Beiträge direkt aus dem Vertrag Belohnungen erhalten.Psyche hat den Belohnungsmechanismus im Trainingslauf noch nicht verwendet, aber sobald das System offiziell gestartet wurde, wird erwartet, dass das System eine zentrale Rolle bei der Zuweisung von Nous Crypto -Token spielt.
Hermes Model Series
Zusätzlich zu diesen Forschungsbeiträgen hat Nous seinen führenden Open-Source-Modellentwicklerstatus mit seiner Hermes-Reihe von Anleitungsstimmungsmodellen (LLM) etabliert.Im August 2024 startete das Team HERMES-3, eine fein abgestimmte Vollparameter-Modellsuite, die auf Lama 3.1 basiert, die wettbewerbsfähige Ergebnisse in der öffentlichen Rangliste erzielt hat, obwohl sie relativ klein und mit größeren proprietären Modellen vergleichbar ist.
Kürzlich hat Nous im August 2025 die Hermes-4-Modellreihe veröffentlicht, die bisher am weitesten fortgeschrittene Modellserie.HERMES-4 konzentriert sich auf die Verbesserung der Schritt-für-Schritt-Überlegungsfunktionen des Modells und wird gleichzeitig in der regelmäßigen Ausführung von Anleitungen hervorragend durchgeführt.Es war gut in Mathematik, Programmierung, Verständnis und gesunden Menschenverstand. Das Team hält sich an die Open-Source-Mission von Nous und veröffentlicht öffentlich alle Hermes-4-Modellgewichte für alle, die alle verwenden und bauen können.Darüber hinaus hat Nous eine Model Accessibility -Schnittstelle namens Nous Chat veröffentlicht, die innerhalb der ersten Veröffentlichungswoche kostenlos zur Verfügung steht.
Die Veröffentlichung des Hermes-Modells zementiert nicht nur die Glaubwürdigkeit von Nous als Modellbuilding-Organisation, sondern bietet auch eine praktische Validierung für seine breitere Forschungsagenda.Jede Veröffentlichung von Hermes beweist, dass in einer offenen Umgebung hochmoderne Fähigkeiten erzielt werden können, die die Grundlage für die dezentralen Trainingsbrüche (Demo, Distribose und Psyche) der Teams bilden und letztendlich zu dem ehrgeizigen Durchgang 40B führt.
Atropos
Wie oben erwähnt, spielt das Verstärkungslernen aufgrund von Fortschritten in Inferenzmodellen und den Expansionsbeschränkungen der Vorausbildung eine zunehmend wichtige Rolle bei der Nachbildung.Atropos ist die Lösung von Nous für die Verstärkungslernen in einer dezentralen Umgebung. Es handelt sich um ein Plug-and-Play-Lernrahmen für LLM, das sich an verschiedene Inferenz-Backends, Trainingsmethoden, Datensätze und Verstärkungslernumgebungen anpasst.
Wenn das Lernen nach der Umsetzung auf dezentrale Weise unter Verwendung einer großen Anzahl von GPUs geschult wird, hat die vom Modell während des Trainings generierte sofortige Ausgabe unterschiedliche Abschlusszeiten.Atropos fungiert als Rollout -Prozessor, d. H. Ein zentraler Koordinator, der die Erzeugung und den Abschluss der Aufgaben über Geräte koordiniert und so ein asynchrones Verstärkungslernen -Training ermöglicht.
Die anfängliche Version von Atropos wurde im April veröffentlicht, enthält jedoch derzeit nur einen Umweltrahmen, der Verstärkungslernaufgaben koordiniert. Nous plant, in den kommenden Monaten ein komplementäres Trainings- und Argumentationsrahmen zu veröffentlichen.
Prime -Intellekt
Hintergrund
Prime Intellekt wurde im Jahr 2024 gegründet und verpflichtet sich, eine groß angelegte dezentrale KI-Entwicklungsinfrastruktur aufzubauen.Das von Vincent Weisser und Johannes Hagemann gegründete Team konzentrierte sich zunächst auf die Integration von Computerressourcen von zentralisierten und dezentralen Anbietern zur Unterstützung der kollaborativen verteilten Ausbildung fortschrittlicher KI -Modelle.Die Mission von Prime Intellekt besteht darin, die KI -Entwicklung zu demokratisieren und Forscher und Entwickler auf der ganzen Welt zu ermöglichen, auf skalierbare Rechenressourcen zuzugreifen und gemeinsam offene KI -Innovationen zu besitzen.
Opendiloco, Intellekt-1 und Prime
Im Juli 2024 veröffentlichte Prime Intellekt Opendiloco, eine Open-Source-Version von Diloco, einer von Google Deepmind für Daten parallele Training entwickelten Modell-Schulungsmethode mit niedriger Kommunikation.Google entwickelte das Modell basierend auf der Ansicht, dass „das Training durch Standard -Backpropagation in modernen Maßstäben beispiellose technische und Infrastrukturherausforderungen darstellt. Es ist schwierig, eine große Anzahl von Beschleunigern zu koordinieren und genau zu synchronisieren.“Während sich diese Aussage eher auf die Praktikabilität des groß angelegten Trainings als auf den Geist der Open-Source-Entwicklung konzentriert, ist sie in Verzug auf die Grenzen des langfristigen zentralisierten Trainings und die Notwendigkeit verteilter Alternativen ausfällt.
Diloco reduziert die Häufigkeit und Menge an Informationen, die bei Trainingsmodellen zwischen GPUs geteilt werden.In zentralisierten Einstellungen teilen sich der GPUs nach jedem Trainingsschritt alle aktualisierten Gradienten miteinander. In Diloco ist die gemeinsame Häufigkeit von Aktualisierungsgradienten niedriger, um die Kommunikationsaufwand zu reduzieren.Dies erzeugt eine Doppeloptimierungsarchitektur: Individuelle GPUs (oder GPU -Cluster) führen interne Optimierungen aus und aktualisieren das Gewicht ihrer eigenen Modelle nach jedem Schritt; und externe Optimierungen, interne Optimierungen werden unter den GPUs geteilt, und alle GPUs werden dann auf der Grundlage der vorgenommenen Änderungen aktualisiert.
Opendiloco zeigte in seiner anfänglichen Freisetzung 90% bis 95% der GPU -Auslastung, was bedeutet, dass trotz der Verteilung auf zwei Kontinente und drei Länder nur wenige Maschinen untätig sind.Opendiloco ist in der Lage, beträchtliche Trainingsergebnisse und Leistung zu reproduzieren, während das Verkehrsvolumen um das 500 -fache reduziert wird (wie in der lila Linie gezeigt, die die blaue Linie in der folgenden Abbildung einholt).
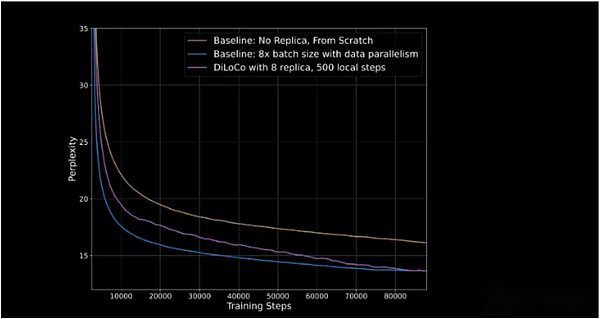
Die vertikale Achse stellt Verwirrung dar, die die Fähigkeit des Modells misst, den nächsten Marker in einer Sequenz vorherzusagen.Je niedriger die Verwirrung ist, desto sicherer sind die Vorhersagen des Modells und desto höher ist die Genauigkeit.
Im Oktober 2024 beginnt Prime Intellekt intellekt-1 auszubildenDies ist das erste 10 Milliarden Parametersprachenmodell, das auf verteilte Weise trainiert wurde. Das Training dauerte 42 Tage und das Modell war danach offen.Die Ausbildung wird in fünf Ländern auf drei Kontinenten durchgeführt.Der Trainingslauf zeigt die allmähliche Verbesserung des verteilten Trainings, wobei die Nutzungsrate aller Rechenressourcen 83%beträgt, und allein in den USA erreicht die Nutzungsrate der Kommunikation zwischen den Noten 96%.Die von diesem Projekt verwendete GPU stammt von Web2- und Web3 -Anbietern, einschließlich der Krypto -GPU -Märkte wie Akash, Hyperbolic und Olas.
Intellekt-1 übernimmt das neue Trainingsrahmen von Prime Intellekt, mit dem Prime Intellekt-Trainingssysteme bei der Berechnung des unerwarteten Eintritts und der Aussteigerung des laufenden Trainings anpassen können.Es führt innovative Technologien wie ElasticDevicemesh ein und ermöglicht den Beitrag zu jeder Zeit dazu, sich anzuschließen oder zu verlassen.
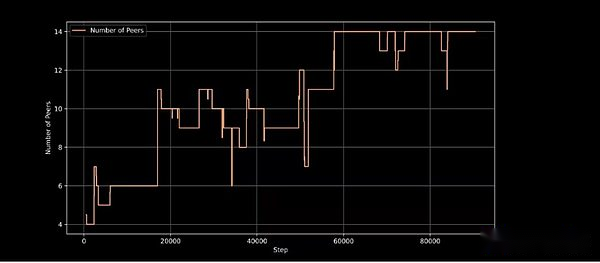
Aktive Trainingsknoten im Trainingsschritt und demonstrieren die Fähigkeit der Trainingsarchitektur, die dynamische Knotenbeteiligung zu bewältigen
Intellekt-1 ist eine wichtige Validierung des dezentralen Trainingsansatzes von Prime Intellekt und wurde von KI-Vordenker wie Jack Clark (Mitbegründer von Anthropic) gelobt und gilt als praktikable Demonstration dezentraler Ausbildung.
Protokoll
Im Februar dieses Jahres fügte Prime Intellekt seinen Stapel eine weitere Schicht hinzu und startete das Protokoll.Protocol verbindet alle Trainingswerkzeuge des Prime-Intellekts zusammen, um ein Punkt-zu-Punkt-Netzwerk für das dezentrale Modelltraining zu erstellen.Dazu gehören:
-
Berechnet die Switch -GPU, um Trainingsläufe zu erleichtern.
-
Der Haupttraining -Rahmen reduziert die Kommunikationsaufwand und verbessert die Fehlertoleranz.
-
Eine Open -Source -Bibliothek namens GeneSys für nützliche synthetische Datenerzeugung und -validierung bei der RL -Feinabstimmung.
-
Ein leichtes Überprüfungssystem namens Toploc zur Validierung der Ausgabe der Modellausführung und der teilnehmenden Knoten.
Die Rolle von Protocol ähnelt Nous’s Psyche mit vier Hauptakteuren:
-
Arbeitnehmer: Eine Software, mit der Benutzer ihre Rechenressourcen zum Schulungsressourcen oder in anderen Produkten der KI-Bezogenen intelligierten Intellekten beitragen können.
-
Prüfer: Überprüfen Sie die Berechnungsbeiträge und verhindern Sie böswilliges Verhalten.Prime Intellekt arbeitet daran, den hochmodernen Inferenzverifizierungsalgorithmus Toploc auf das dezentrale Training anzuwenden.
-
Orchestrator: Eine Möglichkeit, Pool -Ersteller zu berechnen, die Arbeiter verwalten.Es funktioniert dem Nous ‚Orchestrator ähnlich.
-
Smart Contracts: Verfolgen Sie die Anbieter von Computerressourcen, reduzieren Sie das Ablegen von böswilligen Teilnehmern und zahlen Sie die Belohnungen unabhängig.Derzeit läuft Prime Intellekt im Sepolia -Testnetzwerk für Ethereum L2 Base, aber Prime Intellekt hat festgestellt, dass er schließlich in eine eigene Blockchain migriert wird.
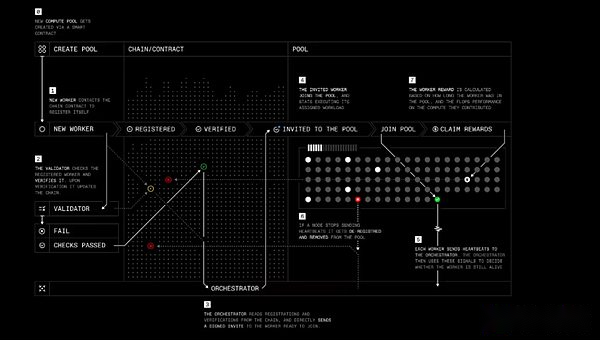 Protokolltraining Schritt für Schritt
Protokolltraining Schritt für Schritt
Das Protokoll soll letztendlich die Mitwirkenden ermöglichen, Aktien des Modells zu besitzen oder Belohnungen für ihre Arbeit zu erhalten, während Open -Source -KI -Projekte neue Möglichkeiten zur Finanzierung und Verwaltung von Entwicklung durch intelligente Verträge und kollektive Anreize bieten.
Intellekt 2 und Verstärkungslernen
Im April dieses Jahres begann Prime Intellekt, ein 32-Milliarden-Parametermodell namens Intellekt-2 auszubilden.Intellekt-1 konzentriert sich auf die Schulung des Basismodells, während Intellekt-2 Verstärkungslernen verwendet, um Inferenzmodelle auf einem anderen Open-Source-Modell (Alibabas QWQ-32B) zu trainieren.
Das Team führte zwei kritische Infrastrukturkomponenten ein, um dieses dezentrale RL -Training praktisch zu machen:
-
Prime-RL ist ein vollständig asynchroner Verstärkungslernrahmen, der den Lernprozess in drei unabhängige Stufen unterteilt: Kandidatenantworten generieren; Training ausgewählte Antworten; und Rundfunk aktualisierte Modellgewichte.Dieser Entkopplungsmechanismus ermöglicht es dem System, unzuverlässige, langsame oder geografisch verteilte Netzwerke zu umfassen.Der Schulungsprozess verwendet eine weitere Innovation aus dem Prime -Intellekt, Genesys, um Tausende von mathematischen, logischen und codierenden Fragen zu generieren, und ist mit einem automatischen Checker ausgestattet, der sofort feststellen kann, ob die Antwort korrekt ist oder nicht.
-
Shardcast ist ein neues System, um große Dateien (z. B. aktualisierte Modellgewichte) im Netzwerk schnell zu verteilen.Shardcast nicht jeder Maschine lädt Aktualisierungen vom zentralen Server herunter, wird jedoch eine Struktur verwendet, die Aktualisierungen zwischen Maschinen teilt. Dies hält das Netzwerk effizient, schnell und belastbar.
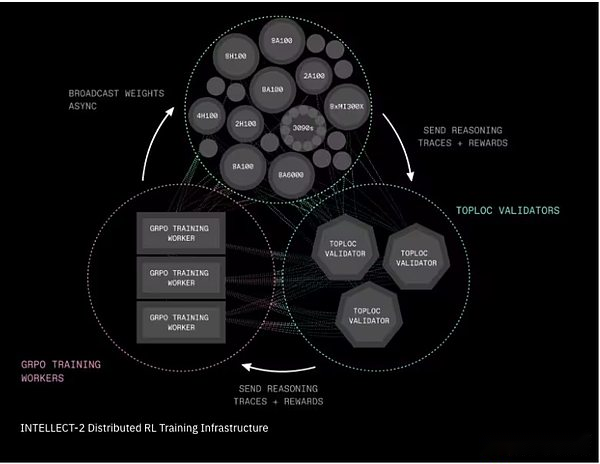 Intellekt-2 verteilte Verstärkungslernungstrainingstruktur
Intellekt-2 verteilte Verstärkungslernungstrainingstruktur
Für Intellekt-2 müssen die Mitwirkenden auch das TestNet Crypto-Token festlegen, um am Trainingslauf teilzunehmen.Wenn sie eine effektive Arbeit leisten, erhalten sie automatisch Belohnungen.Wenn nicht, kann ihre Einstellung geschnitten werden.Obwohl während dieses Testlaufs keine tatsächliche Finanzierung beteiligt war, unterstreicht dies die anfängliche Form einiger kryptoökonomischer Experimente.In diesem Bereich sind weitere Experimente erforderlich, und wir erwarten weitere Änderungen in der Anwendung der Kryptowirtschaft in Bezug auf Sicherheits- und Anreizmechanismen. Zusätzlich zu Intellekt-2 führt Prime Intellekt weiterhin mehrere wichtige Programme durch, die in diesem Bericht nicht behandelt werden, einschließlich:
-
Synthetisch-2, ein Framework der nächsten Generation zum Generieren und Validieren von Inferenzaufgaben;
-
Prime Collective Communications Library, der effiziente, fehlertolerante kollektive Kommunikationsoperationen (z. B. Reduktion über IP) implementiert und einen gemeinsamen Zustandssynchronisationsmechanismus für gemeinsame Zustandsanlagen bietet, um die Gleichaltrigen synchronisiert zu halten, und ermöglicht die dynamische Verbindungs- und Verlassen von Gleichaltrigen jederzeit während des Trainings sowie automatische Bandbreiten-bewusste Topologieoptimierung;
-
Verbessern Sie kontinuierlich die Funktionalität von Toploc, um skalierbare, kostengünstige Inferenznachweise zur Überprüfung der Modellausgabe zu ermöglichen.
-
Verbesserungen an der Haupttätigkeit des Intellektprotokolls und der Krypto -Wirtschaft auf der Grundlage von Lehren aus Intellekt2 und Synthetic111
Pluralis -Forschung
Alexander Long ist ein australischer Forscher für maschinelles Lernen mit einer Doktorarbeit an der University of New South Wales.Er glaubt, dass Open -Source -Modelltraining übermäßig auf führende künstliche Intelligenzlabors angewiesen ist, um die Grundmodelle für andere zu schulen.Im April 2023 gründete er Pluralis Research und zielte darauf ab, einen anderen Weg zu eröffnen.
Pluralis Research verwendet einen Ansatz mit dem Namen „Protokolllernen“, um das dezentrale Trainingsproblem zu lösen, das als „niedrige Bandbreite, heterogene Mehrteilnehmer, Modellparallel-Training und -Angut“ beschrieben wird.Ein wichtiges bemerkenswertes Merkmal von Pluralis ist sein Wirtschaftsmodell, das für Schulungsmodelle Eigenkapitalgewinne bietet, um Berechnungsbeiträge zu treiben und Top-Open-Source-Softwareforscher anzuziehen.Dieses Wirtschaftsmodell basiert auf dem Kernattribut von „Unzugehörigkeit“: Das heißt, kein Teilnehmer kann einen vollständigen Satz von Gewichten erhalten, das eng mit der Verwendung von Trainingsmethoden und der Modellparallelität zusammenhängt.
Modellparallelität
Pluralis ‚Trainingsarchitektur nutzt die Modellparallelität, die sich von dem Datenparallelismus -Ansatz unterscheidet, der im ersten Trainingslauf durch NOUS -Forschung und Prime -Intellekt implementiert wird.Wenn die Größe des Modells wächst, ist selbst das H100 -Rack, eine der fortschrittlichsten GPU -Konfigurationen, schwer ein vollständiges Modell.Die Modellparallelität bietet eine Lösung für dieses Problem, indem einzelne Komponenten eines einzelnen Modells auf mehreren GPUs aufgeteilt werden.
Es gibt drei Hauptmethoden zur Modellparallelisierung.
-
Pipeline -Parallelität: Die Schichten des Modells sind auf verschiedene GPUs unterteilt.Während des Trainings fließt jede kleine Menge Daten wie eine Pipeline durch diese GPUs.
-
Tensor (In-Layer) Parallelität: Anstatt die gesamte Schicht für jede GPU bereitzustellen, wird die schwere Mathematik in jeder Schicht getrennt, damit mehrere GPUs gleichzeitig die Arbeit einer einzelnen Schicht teilen können.
-
Gemischte Parallele: In der Praxis verwenden große Modelle verschiedene Methoden, wobei Pipelines und Tensoren parallel und normalerweise in Verbindung mit Daten verwendet werden.
Die Modellparallelität ist ein wichtiger Fortschritt in der verteilten Schulung, da die Schulung von Modellen auf Spitzentsorgungen, sodass die Hardware auf niedrigerer Ebene teilnehmen kann, und sicherzustellen, dass kein Teilnehmer Zugriff auf den gesamten Satz von Modellgewichten hat.
Protokolllernen und Protokollmodelle
Protokolllernen ist ein Rahmen für Pluralis, um das Modellbesitz und die Monetarisierung in einer dezentralen Trainingsumgebung zu verwenden. Pluralis hebt drei wichtige Prinzipien hervor, die den Protokolllernen -Rahmen darstellen – die Dezentralisierung, Motivation und den Stillstand.
Der Hauptunterschied zwischen Pluralis und anderen Projekten ist der Schwerpunkt auf dem Modelleigentum.Da der Wert des Modells hauptsächlich auf sein Gewicht zurückzuführen ist, ist das Protokollmodell (Protokollmodelle) Versuchen Sie, die Gewichte des Modells so zu teilen, dass kein einzelner Teilnehmer während des Modelltrainings mit vollem Gewicht aufweisen kann.Letztendlich wird dies jedem Beitrag zum Schulungsmodell ein bestimmtes Eigentum verleihen und so die vom Modell generierten Vorteile teilen.
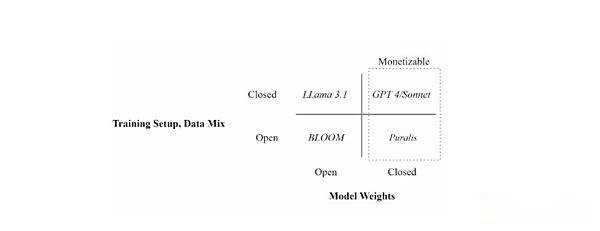 Positionieren Sie verschiedene Sprachmodelle durch Trainingseinstellungen (offene vs. geschlossene Daten) und Modellgewichtsverfügbarkeit (offen und geschlossen)
Positionieren Sie verschiedene Sprachmodelle durch Trainingseinstellungen (offene vs. geschlossene Daten) und Modellgewichtsverfügbarkeit (offen und geschlossen)
Dies ist ein grundsätzlich anderer Ansatz für die Wirtschaft dezentraler Modelle als frühere Beispiele. Andere Projekte geben Beiträge an, indem sie einen Finanzierungspool bereitstellen, der während des Trainingszyklus auf der Grundlage bestimmter Metriken (in der Regel die Zeit- oder Rechenleistung beigetragen) zugeteilt wird.Die Mitarbeiter von Pluralis sind motiviert, Ressourcen nur den Modellen zu widmen, von denen sie glauben, dass sie am wahrscheinlichsten Erfolg haben.Das Training eines schlecht durchgeführten Modells verschwendet Rechenleistung, Energie und Zeit, da schlecht durchgeführte Modelle keine Einnahmen erzielen.
Dies unterscheidet sich von der vorherigen Methode.Erstens sind keine Personen erforderlich, die das Modell ausbilden möchten, um die ersten Mittel zur Bezahlung der Mitwirkenden zu sammeln, und senkt so den Schwellenwert für Modelltraining und -entwicklung.Zweitens koordiniert es die Anreizmechanismen zwischen Modelldesigner und Computeranbietern besser, da beide Parteien wollen, dass die endgültige Version des Modells so perfekt wie möglich ist, um ihren Erfolg zu gewährleisten.Dies bietet auch die Möglichkeit für die Entstehung der Modelltrainingspezialisierung.Beispielsweise kann es mehr risikotragende Trainer geben, die sich für frühe/experimentelle Modelle für die Suche nach größeren Renditen (ähnlich wie Venture-Kapitalisten) anbieten, während Computeranbieter nur auf diejenigen ausgereift und eher angewendet werden (ähnlich wie Private-Equity-Investoren).
Während PM einen großen Durchbruch bei der Monetarisierung und in der Anreizmechanismen für das dezentrale Training darstellen kann, hat Pluralis seine spezifischen Implementierungsmethoden nicht ausgearbeitet.In Anbetracht der hohen Komplexität des Ansatzes umfassen Probleme, die noch nicht angegangen werden müssen, wie das Eigentum an dem Modell zugewiesen werden, wie die Vorteile zugewiesen werden und sogar zukünftige Upgrades oder Anwendungsfälle des Modells verwaltet werden.
Dezentrale Traininginnovation
Zusätzlich zu wirtschaftlichen Überlegungen steht das Protokolllernen der gleichen zentralen Herausforderung wie andere dezentrale Trainingsprogramme, wobei heterogene GPU -Netzwerke mit Kommunikationsbeschränkungen verwendet werden, um große KI -Modelle zu schulen.
Im Juni dieses Jahres kündigte Pluralis die erfolgreiche Ausbildung von 8 Milliarden Parameter LLM an, die auf der LLAMA 3 -Architektur von Meta basiert, und veröffentlichte sein Protokollmodellpapier.In der Arbeit zeigt Pluralis, wie der Kommunikationsaufwand zwischen GPUs, das Modell parallele Training durchführt, reduziert wird.Dies geschieht, indem die Signale, die durch jede Transformatorschicht fließen, auf einen vorgewählten winzigen Unterraum einschränken, wodurch die Vorwärts- und Rückwärtspässe bis zu 99%komprimiert wird, wodurch der Netzwerkverkehr das 100-fache verringert wird, ohne die Genauigkeit zu beeinträchtigen oder einen signifikanten Aufwand hinzuzufügen.Kurz gesagt, Pluralis fand einen Weg, um dieselben Lerninformationen auf einen kleinen Teil der von früheren Methoden erforderlichen Bandbreite zu komprimieren.
Dies ist der erste dezentrale Trainingslauf, und das Modell selbst ist auf Knoten verteilt, die eher durch eine niedrige Bandbreite als durch Replikation verbunden sind.Das Team trainierte erfolgreich ein Lama-Modell mit 8 Milliarden Parametern für GPUs mit niedrigem Verbraucherqualität auf vier Kontinenten, die nur 80 Megabyte pro Sekunde der Internetverbindung pro Tag verbinden.In der Arbeit zeigt Pluralis, dass die Konvergenz dieses Modells so gut ist wie auf einem 100 -GB/s -Rechenzentrumscluster.In der Praxis bedeutet dies, dass jetzt eine parallele dezentrale Ausbildung großer Modelle möglich ist.
Schließlich wurde im Juli ein Papier von Pluralis über ein asynchrones Training für Pipeline Parallele Training (eine der führenden Konferenzen für künstliche Intelligenz) eingegangen.Wenn Pipeline Parallele Training eher über das Internet als über Hochgeschwindigkeits-Rechenzentren durchgeführt wird, steht es auch mit einem Kommunikations Engpass aus, da die Knoten in einem im Wesentlichen ähnlichen Pipelines funktionieren, wobei jeder aufeinanderfolgende Knoten darauf wartet, dass der vorherige Knoten das Modell aktualisiert.Dies kann zu einer veralteten und verzögerten Informationsübertragung führen.Das dezentrale Trainingsrahmen, das in der Zeitung Swarm demonstriert wurde, beseitigt zwei klassische Engpässe, die normalerweise die tägliche Beteiligung der GPU am Training behindern: Speicherkapazität und enge Synchronisation.Das Eliminieren dieser beiden Engpässe kann alle verfügbaren GPUs besser nutzen, die Schulungszeit verkürzen und die Kosten senken.Dies ist entscheidend für die Skalierung großer Modelle mit verteilter freiwilliger Infrastruktur. Sehen Sie sich dieses Video von Pluralis an, um einen kurzen Überblick über diesen Prozess zu erhalten.
Mit Blick auf die Zukunft plant Pluralis, ein Echtzeit-Training zu starten, an dem jeder bald teilnehmen kann, aber ein bestimmtes Datum wurde nicht festgelegt.Der Start wird ein tieferes Verständnis der Aspekte der Vereinbarung vermitteln, die noch nicht veröffentlicht wurden, insbesondere Wirtschaftsmodelle und Kryptoinfrastruktur.
Templer
Hintergrund
Templar wurde im November 2024 auf den Markt gebracht und ist ein Anreiz für dezentrale KI-Aufgabenmarkt, das auf dem Bittensor-Protokoll-Subnetz basiert.Es begann als experimenteller Rahmen, der darauf abzielt, die globalen GPU-Ressourcen für lizenzfreie KI-Voraussetzungen zusammenzubringen, und zielt darauf ab, groß angelegte Modellschulungen durch Bittensors tokenisierte Anreize zugänglich, sicher und belastbar zu machen, wodurch die KI-Entwicklung neu definiert wird.
Von Anfang an nahmen Templer die Herausforderung an, das dezentrale Training für LLM-Voraussetzungen im Internet zu koordinieren.Dies ist eine schwierige Aufgabe, da Latenz, Bandbreitenbeschränkungen und heterogene Hardware den verteilten Akteuren schwierig machen, die Effizienz zentraler Cluster zu erreichen, und die nahtlose GPU -Kommunikation zentraler Cluster ermöglicht eine schnelle Iteration massiver Modelle.
Am wichtigsten ist, dass Templare die Teilnahme, die wirklich lizenziert ist, priorisiert, sodass jeder mit Rechenressourcen ohne Genehmigung, Registrierung oder Gatekeeping an KI -Schulungen teilnehmen kann.Dieser netzlose Ansatz ist entscheidend für die Mission von Templar, die KI -Entwicklung zu demokratisieren, da er sicherstellt, dass die Durchbruch der KI -Funktionen nicht von einigen wenigen zentralisierten Einheiten kontrolliert werden, sondern aus der offenen Zusammenarbeit auf der ganzen Welt hervorgehen können.
TemplerZug
Templar verwendet Daten, um parallel zu trainieren, und es gibt zwei Hauptfaktoren:
-
Bergmann:Diese Teilnehmer führten Trainingsaufgaben durch. Jedes Miner synchronisiert mit dem neuesten globalen Modell, erhält eindeutige Datenschards, zog lokal mit Vorwärts- und Rückwärtspässen, komprimiert Gradienten mit einem benutzerdefinierten CCLOCO -Optimierer (unten beschrieben) und legt Gradienten -Updates vor.
-
Verifier: Der Validator lädt das vom Bergmann eingereichte Update herunter und dekomprimiert es auf die lokale Kopie des Modells und berechnet esVerlustinkrement(Indikatoren, die den Grad der Verbesserung des Modells messen).Diese Schritte werden verwendet, um die Beiträge der Miner über das Gauntlet -System von Templer zu erzielen.
Um den Kommunikationsaufwand zu reduzieren, entwickelte das Forschungsteam von Templar zunächst das Block Compression Diloco (CCLOCO).Ähnlich wie bei NOUS verbessert CCLOCO die Kommunikationstrainingstechniken wie das Google Diloco-Framework und senkt die Kommunikationskosten zwischen den Noten um Größenordnungen und reduzieren gleichzeitig die häufig durch solche Methoden verursachten Verluste.Anstatt bei jedem Schritt vollständige Updates zu senden, teilt CCloco nur die wichtigsten Änderungen in festgelegten Intervallen und hält eine kleine Laufzahl, um sicherzustellen, dass keine aussagekräftigen Daten verloren gehen.Das System nimmt ein Wettbewerbsmodell an, das Bergarbeiter dazu aufrütt, dass die Aktualisierungen mit geringer Latenz für die Erhaltung von Belohnungen bereitgestellt werden.Um Belohnungen zu erhalten, müssen Bergleute mit dem Netzwerk Schritt halten, indem sie effiziente Hardware bereitstellen.Diese Wettbewerbsstruktur soll sicherstellen, dass nur Teilnehmer, die eine ausreichende Leistung aufrechterhalten, am Trainingsprozess teilnehmen können, während leichte Hygiene -Überprüfungen deutlich schlechte oder missgebildete Aktualisierungen herausfiltern.Im August veröffentlichte Templar offiziell die aktualisierte Trainingsarchitektur und benannte sie in Sparseloco um.
Verifikatoren verwenden das Gauntlet -System von Templar, um die Qualifikationsbewertung jedes Miner auf der Grundlage der beobachteten Beiträge zur Modellverlustreduktion zu verfolgen und zu aktualisieren.Mit der Technologie, die als OpenSkill bezeichnet wird, werden hochwertige Bergleute, die weiterhin effektiv aktualisiert werden, höhere Fähigkeiten erhalten, was ihren Einfluss auf die Modellaggregation erhöht und mehr Taos verdient (native Token des Bittensor-Netzwerks).Bergleute mit niedrigeren Bewertungen werden während des Aggregationsprozesses verworfen.Nach der Bewertung werden die Validatoren mit dem höchsten Versprechen Updates von den Top -Bergleuten zusammenfassen, das neue globale Modell unterschreiben und es für den Speicher veröffentlichen.Wenn das Modell nicht synchron ist, können Bergleute diese Version des Modells verwenden, um aufzuholen.
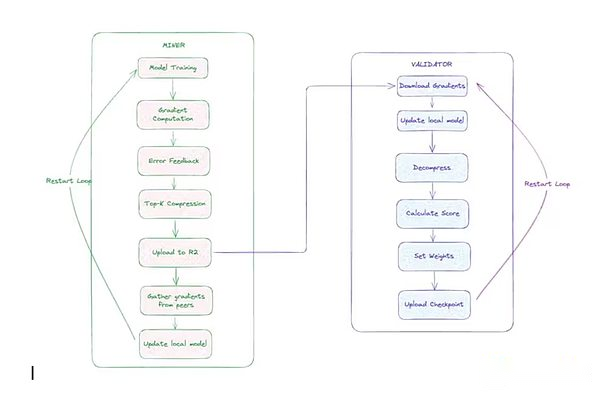 Templer -dezentrale Trainingsarchitektur
Templer -dezentrale Trainingsarchitektur
Bisher hat Templar drei Trainingsrunden begonnen: Templar I, Templar II und Templar III.Templar I ist ein Modell mit 1,2 Milliarden Parametern, das weltweit fast 200 GPUs bereitstellt.Templar II ist im Gange, trainiert ein Modell mit 8 Milliarden Parametern und plant, bald ein größeres Training zu beginnen.Templar konzentriert sich derzeit auf Trainingsmodelle mit kleineren Parametern, eine gut durchdachte Wahl, mit der sichergestellt werden soll, dass Upgrades auf die dezentrale Trainingsarchitektur (wie oben erwähnt) effektiv funktionieren, bevor sie zu größeren Modellskalen skaliert werden.Von Optimierungsstrategien und Planung bis hin zu Forschungs-Iterationen und Anreizen werden diese Ideen auf 8 Milliarden Modellen mit kleineren Parametern validiert, sodass Teams schnell und kostengünstig iterieren können.Nach den jüngsten Fortschritten und der formellen Veröffentlichung der Trainingsarchitektur startete das Team im September Templar III, ein Modell mit 70 Milliarden Parametern und dem bisher größten Vorbildungslauf im dezentralen Bereich.
Tao- und Incentive -Mechanismen
Ein wesentliches Merkmal von Templar ist das Anreizmodell, das an Tao gebunden ist.Belohnungen werden auf der Grundlage der vom Modell ausgebildeten Fähigkeiten gewichtete Beiträge bereitgestellt.Die meisten Protokolle (wie Pluralis, Nous, Prime Intellekt) haben lizenzierte Läufe oder Prototypen, während Templar vollständig im Echtzeit-Netzwerk von Bittensor läuft.Dies macht Templer zum einzigen Protokoll, das eine Echtzeit-lizenzfreie wirtschaftliche Schicht in seinen dezentralen Trainingsrahmen integriert hat.Diese Echtzeit-Produktionsbereitstellung ermöglicht es Templer, seine Infrastruktur in Echtzeit-Trainings-Run-Szenarien zu iterieren.
Jedes Bittensor -Subnetz läuft mit seinem eigenen „Alpha“ -Token, das als Marktsignal für den Belohnungsmechanismus und Subnetze fungiert, um den Wert wahrzunehmen. Templars Alpha -Token heißt Gamma.Alpha -Token können nicht frei auf externen Märkten gehandelt werden.Sie können nur mit einem automatisierten Markthersteller (AMM) gegen Taos über einen Liquiditätspool ausgetauscht werden.Benutzer können Tao verpflichten, Gamma zu erhalten oder Gamma als Tao einzulösen, aber sie können Gamma jedoch nicht direkt gegen Alpha -Token aus anderen Subnetzen austauschen.Das dynamische TAO -System (DTAO) von Bittensor verwendet den Marktpreis von Alpha -Token, um die Ausstellungszuweisungen zwischen Subnetzen zu bestimmen.Wenn der Preis für Gamma im Vergleich zu anderen Alpha -Token steigt, weist dies darauf hin, dass das Vertrauen des Marktes in die dezentralen Schulungsfähigkeiten des Templers zugenommen hat, was zu einer Erhöhung der Tao -Emission des Subnetzes führt.Anfang September machte die tägliche Ausgabe von Templar etwa 4% der Tao -Verbreitung aus und legte unter den Top -sechs der 128 Subnetze des Tao -Netzwerks.
Der Ausstellungsmechanismus des Subnetzes lautet wie folgt: In jedem 12-Sekunden-Block wird die Bittensor-Kette Tao- und Alpha-Token in ihrem Liquiditätspool basierend auf dem Preisverhältnis der Subnetz-Alpha-Token im Vergleich zu anderen Subnets ausstellen.Jeder Block gibt bis zu einem vollständigen Alpha -Token an das Subnetz (anfängliche Ausstellungsrate, die halbiert werden kann) zum Subnetz aus, von denen Subnetz -Mitwirkende angeregt werden, von denen 41% den Bergleuten zugewiesen werden, 41% für Validatoren (und deren Stakeholder) zugewiesen werden und 18% Subnetzbesitzer zugewiesen werden.
Dieser Incentive leistet den Beitrag zum Bittensor -Netzwerk, indem wir wirtschaftliche Belohnungen mit dem von den Teilnehmern bereitgestellten Wert verbinden.Bergleute sind motiviert, qualitativ hochwertige KI-Ausgänge wie Modelltraining oder Inferenzaufgaben bereitzustellen, um höhere Bewertungen von Validatoren und damit einen größeren Anteil der Ausgabe zu erhalten.Verifikatoren (und ihre Staker) erhalten Belohnungen für die genaue Bewertung und Aufrechterhaltung der Netzwerkintegrität.
Die Marktbewertung von Alpha -Token wird durch Absetzen von Aktivitäten bestimmt, um sicherzustellen, dass Subnetze, die eine höhere Praktikabilität zeigen, mehr TAO -Zuflüsse und -ausstellungen anziehen und so ein Wettbewerbsumfeld schaffen können, das Innovation, Spezialisierung und nachhaltige Entwicklung fördert.Subnetzbesitzer erhalten einen Prozentsatz an Belohnungen, die motiviert sind, effektive Mechanismen zu entwerfen und Mitwirkende zu gewinnen, und letztendlich ein mit freundlicher Genehmigung dezentraler AI -Ökosystem aufbauen, mit dem die globale Teilnahme gemeinsam den Fortschritt der kollektiven Intelligenz fördert.
Der Mechanismus führt auch neue Anreizherausforderungen wie die Aufrechterhaltung der Ehrlichkeit der Validatoren, der Widerstand gegen Hexenangriffe und die Verringerung der Verschwörung.Bittensor-Subnetze werden oft durch Katzen- und Mausspiele zwischen Validatoren oder Bergleuten und Subnetzschötern beunruhigt, die ersteren versuchen, mit dem System zu spielen, und der letzteren versuchen, sie zu behindern.Auf lange Sicht sollten diese Kämpfe das System zu einem der leistungsstärksten Subnetzbesitzer machen, wie man böswillige Schauspieler überwindet.
Gensyn
Gensyn veröffentlichte im Februar 2022 sein erstes optimiertes Whitepaper, das den Rahmen für das dezentrale Training ausgab (Genyn ist das einzige dezentrale Trainingsprotokoll, das in unserem ersten Artikel im vergangenen Jahr über das Verständnis des Schnittpunkts der Verschlüsselungstechnologie und der künstlichen Intelligenz behandelt wurde).Zu diesem Zeitpunkt konzentrierte sich das Protokoll hauptsächlich auf die Überprüfung von Workloads im Zusammenhang mit KI, sodass Benutzer Schulungsanfragen an das vom Computeranbieter verarbeitete Netzwerk senden und sicherstellen können, dass diese Anfragen wie versprochen ausgeführt wurden.
Die anfängliche Vision zeigte auch die Notwendigkeit, angewandte maschinelle Lernforschung (ML) zu beschleunigen.Im Jahr 2023 baut Gensyn auf dieser Vision ein, um ein breiteres Bedürfnis vorzuschlagen, weltweit maschinelles Lernenscomputerressourcen zu erwerben, um spezifische KI -Anwendungen zu bedienen.Gensyn führte das geisterhafte Prinzip als Rahmen ein, den solche Protokolle erfüllen müssen: Universalität, Heterogenität, Gemeinkosten, Skalierbarkeit, Vertrauenslosigkeit und Latenz.Gensyn hat sich auf den Aufbau von Computerinfrastrukturen konzentriert, und die Zusammenarbeit markiert ihre formelle Expansion auf andere wichtige Ressourcen, die über die Computer hinausgehen.
Gensyns Kern unterteilt seinen Trainingstechnologie -Stapel in vier verschiedene Teile – Ausdruck, Überprüfung, Kommunikation und Koordination.Der Ausführungsteil ist für den Umgang mit Operationen auf jedem Gerät der Welt verantwortlich, mit dem maschinelle Lernvorgänge durchgeführt werden können.Mit dem Abschnitt Kommunikations- und Koordinationsabschnitt können die Geräte standardisierte Informationen aneinander senden. Der Überprüfungsabschnitt stellt sicher, dass alle Operationen ohne Vertrauen berechnet werden können.
Ausführung – RL Schwarm
Gensyns erste Implementierung in diesem Stapel ist ein Trainingssystem namens RL Swarm, ein dezentraler Koordinationsmechanismus für das Lernen nach der Verstärkung nach dem Training.
RL Swarm ist so konzipiert, dass mehrere Computeranbieter an der Schulung eines einzelnen Modells in einer genehmigten, vertrauensminimierten Umgebung teilnehmen können.Das Protokoll basiert auf einem dreistufigen Zyklus: Beantwortung, Überprüfung und Lösung.Zunächst generiert jeder Teilnehmer die Modellausgabe (Antwort) basierend auf der Eingabeaufforderung.Die anderen Teilnehmer bewerteten dann die Ausgabe mithilfe einer gemeinsam genutzten Belohnungsfunktion und haben Feedback (Überprüfung) eingereicht.Schließlich werden diese Bewertungen verwendet, um die beste Antwort auszuwählen und sie in die nächste Version des Modells (gelöst) aufzunehmen. Der gesamte Prozess findet punktuspunktisch statt, ohne sich auf einen zentralen Server oder eine vertrauenswürdige Organisation zu verlassen.
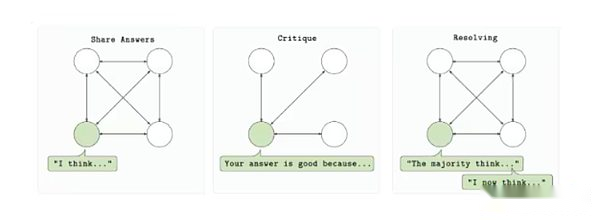 RL Schwarm Trainingsschleife
RL Schwarm Trainingsschleife
Das Verstärkungslernenschwarm basiert auf der zunehmenden Bedeutung des Verstärkungslernens im Training nach dem Modell.Wenn das Modell in der Vorausbildung die Obergrenze der Skalierung erreicht, bietet das Verstärkungslernen einen Mechanismus zur Verbesserung der Inferenzfähigkeit, der Fähigkeit zur Einhaltung von Anweisungen und der Tatsache, ohne sich auf massive Datensätze umzusetzen.Gensyns System erzielt diese Verbesserung in einer dezentralen Umgebung, indem die Verstärkungslernschleifen in unterschiedliche Rollen unterteilt werden. Jede Rolle kann unabhängig verifiziert werden.Entscheidend ist, dass eine fehlertolerante asynchrone Ausführung einführt, was bedeutet, dass Mitwirkende nicht online sein oder perfekt synchronisiert werden müssen, um teilzunehmen.
Es ist auch modular in der Natur.Das System erfordert nicht die Verwendung einer bestimmten Modellarchitektur, einer Datentyp oder einer Belohnungsstruktur, mit der Entwickler Schulungsschleifen anhand ihrer spezifischen Anwendungsfälle anpassen können.Unabhängig davon, ob es sich um Trainingscodierungsmodelle, Inferenzmittel oder Modelle mit spezifischen Anweisungssätzen handelt, bietet RL Swarm ein zuverlässiges großes Betriebsgerüst für dezentrale RL-Workflows.
Verde
Einer der am wenigsten diskutierten Aspekte in diesem Bericht über die dezentrale Schulung ist die Überprüfung.Gensyn baut eine Verde Trust -Schicht für seinen GPU -Marktplatz auf.Mit Verde führte Genyn einen neuen Überprüfungsmechanismus ein, damit Protokollbenutzer Menschen auf der anderen Seite der Situation vertrauen können, was sie sagen.
Jede Schulungs- oder Inferenzaufgabe ist einer bestimmten Anzahl unabhängiger Anbieter geplant, die von der Anwendung bestimmt werden. Wenn ihre Ausgabe genau übereinstimmt, wird die Aufgabe akzeptiert.Wenn die Ausgänge unterschiedlich sind, lokalisiert das Schiedsrichterprotokoll den ersten Schritt, in dem die beiden Trajektorien unterschiedlich sind, und berechnen den Betrieb nur neu.Die Partei, deren Nummer dem Schiedsrichter entspricht, behält ihre Zahlung bei, während die andere Partei ihre Interessen verliert.
Dies macht dies möglich, eine Bibliothek von „wiederholbaren Operatoren“, die gemeinsame Mathematikoperationen des neuronalen Netzwerks (Matrix -Multiplikation, Aktivierung usw.) dazu zwingt, in einer festen, deterministischen Reihenfolge auf jeder GPU zu laufen. Determinismus ist hier entscheidend;Andernfalls können sie, obwohl beide Validatoren korrekt sind, unterschiedliche Ergebnisse erzielen.Daher liefern ehrliche Anbieter die gleiche Ergebnisbetriebsbetrieb und ermöglichen Verde, das Spiel als Beweis für die Korrektheit zu sehen.Da der Schiedsrichter nur einen Mikrostep wiederholt, beträgt die zusätzlichen Kosten nur wenige Prozentpunkte und nicht den 10.000-fachen Overhead des vollständigen Verschlüsselungsnachweises, der üblicherweise in diesen Prozessen verwendet wird.
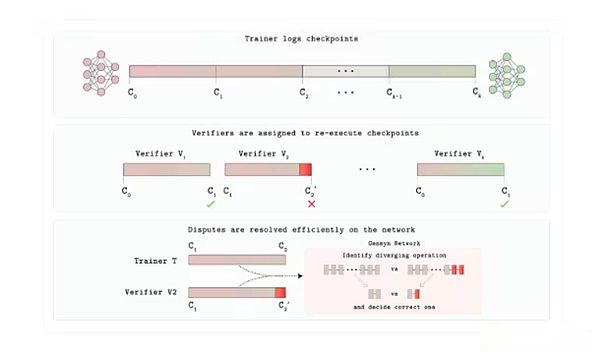
Verde Verifizierungsprotokollarchitektur
Im August veröffentlichte Gensyn Richter, ein überprüfbares AI -Bewertungssystem, das zwei Kernkomponenten enthält: Verde und eine reproduzierbare Laufzeit, die das gleiche Ergebnis von Hardware bitig für das gleiche Ergebnis garantiert. Um dies zu zeigen, startete Genyn ein „progressives Enthüllungsspiel“, bei dem KI -Modelle auf die Antworten auf komplexe Fragen während der Informationsförderung wetten, Richter die Ergebnisse dauerhaft validieren und genaue frühe Vorhersagen belohnt.
Richter ist von Bedeutung, weil es die Probleme mit Vertrauen und Skalierbarkeit in AI/ML löst.Es ermöglicht zuverlässige Modellvergleiche, verbessert die Transparenz in Umgebungen mit hohem Risiko und verringert das Risiko einer Verzerrung oder Manipulation, indem sie eine unabhängige Überprüfung ermöglicht.Zusätzlich zu Inferenzaufgaben kann Richter andere Anwendungsfälle wie dezentrale Streitbeilegung und Vorhersagemärkte unterstützen, die Gensyns Mission für den Aufbau einer vertrauenswürdigen AI -Computerinfrastruktur für den Aufbau einer vertrauenswürdigen AI -Computing -Infrastruktur unterstützen.Letztendlich können Tools wie Richter die Wiederholbarkeit und Rechenschaftspflicht verbessern, was in einer Zeit von entscheidender Bedeutung ist, in der AI zunehmend im Mittelpunkt der Gesellschaft steht.
Kommunikation und Koordination: Integration von Skip-Pipe und Diversity Expert
Skip-Pipe ist eine Lösung von Genyn, um das Problem der Bandbreite zu beheben, dass ein einzelnes Megamo-Modell beim Schneiden mehrerer Maschinen auftritt.Wie bereits erwähnt, zwingt die traditionelle Pipeline -Training jeden Mikrobatch dazu, alle Schichten nacheinander zu durchqueren, sodass jeder langsamere Knoten die Pipeline -Stagnation verursacht.Der Scheduler von Skip-Pipe kann dynamisch überspringen oder nachbestellen, die zu Verzögerungen führen, die Iterationszeiten um bis zu 55% reduzieren und die Verfügbarkeit beibehalten können, selbst wenn die Hälfte der Knoten fehlschlägt.Durch die Reduzierung des Verkehrs zwischen den Noten und die Entfernung von Schichten nach Bedarf ermöglicht es dem Trainer, sehr große Modelle auf geoperierte, niedrige Bandbreiten-GPUs zu skalieren.
Diversifizierte Expertenintegration löst ein weiteres Koordinationsuzzle: Wie man ein leistungsstarkes „Hybrid -Experten“ -System aufbaut, das kontinuierliches Übersprechen vermeidet.Gensyns heterogenes Domain Expert Integration (HDEE) schult jedes Expertenmodell vollständig unabhängig und verschmilzt nur am Ende.Überraschenderweise übertraf die endgültige Integration in 20 der 21 Testbereiche unter dem gleichen Gesamtbudget einen einheitlichen Benchmark.Da zwischen den Maschinen während des Trainings keinen Gradienten oder keine Aktivierungsfunktionen vorhanden sind, kann jede Leerlauf -GPU die Rechenleistung beitragen.
Skip-Pipe und HDE zusammen bieten Gensyn eine effiziente Kommunikationslösung. Das Protokoll kann bei Bedarf innerhalb eines einzelnen Modells scharden oder mehrere kleine Experten parallel zu niedrigeren Unabhängigkeitskosten schulen, ohne ein perfektes Netzwerk mit niedrigem Latenz zu betreiben, wie sie traditionell verwendet werden.
Testnetzwerk
Im März stellte Genyn ein TestNet für eine benutzerdefinierte Ethereum -Rollup ein.Das Team plant, das Testnetzwerk schrittweise zu aktualisieren.Derzeit können Benutzer an Gensyns drei Produkten teilnehmen: RL Swarm, Blockassist und Richter. Wie oben erwähnt, ermöglicht RL Swarm Benutzern, an Schulungsprozessen nach RL teilzunehmen.Im August startete das Team Blockassist: „Dies ist die erste groß angelegte Demonstration des assistierten Lernens, eine Möglichkeit, Agenten direkt aus menschlichem Verhalten ohne manuelles Markieren oder RLHF zu schulen.“Benutzer können Minecraft herunterladen und Blockassist verwenden, um Minecraft -Modelle zu trainieren, um das Spiel zu spielen.
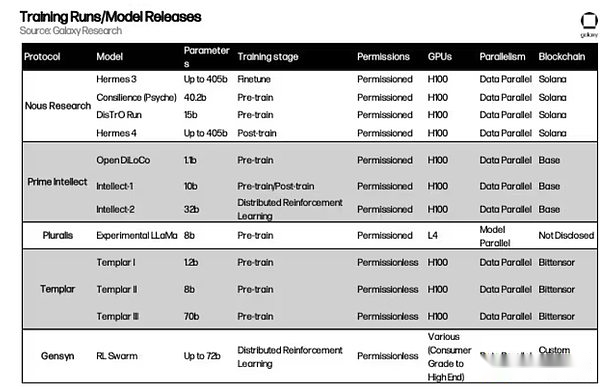
Andere Projekte, die es wert sind, darauf zu achten
In den oben genannten Kapiteln wird die Mainstream -Architektur umrissen, die ein dezentrales Training absolviert hat.Nach dem anderen entstehen jedoch neue Projekte.Hier sind einige neue Projekte auf dem Gebiet des dezentralen Trainings:
Vierzig: Defytwo basiert auf der Monad-Blockchain und konzentriert sich auf Gruppengründungen (SLM), wobei mehrere SLMS (SLMS) mit kleinem Sprachmodellen (SLMS) an Abfragen in einem Knotennetzwerk zusammenarbeiten und von Experten überprüfte Ausgaben generieren, wodurch die Genauigkeit und Effizienz verbessert werden.Das System verwendet Hardware für Verbraucherqualität wie Leerlauflaptops, wodurch teure GPU-Cluster wie zentralisierte KI verwendet werden müssen.Die Architektur umfasst dezentrale Inferenzausführungen und Schulungsfunktionen, wie z.B. das Generieren von synthetischen Datensätzen für dedizierte Modelle.Das Projekt ist jetzt im Monad Development Network verfügbar.
Ambient: Ambient ist der bevorstehende Blockchain „Nützlicher Beweis für die Arbeit“, die immer auf linesische, autonome KI-Agenten in der Kette unterstützt werden und es ihnen ermöglicht, kontinuierlich Aufgaben auszuführen, in einem mit freundlichem Ökosystem ohne zentralisierten Überwachung kontinuierlich zu lernen, zu lernen und zu entwickeln.Es wird ein einzelnes Open -Source -Modell einnehmen, das von Netzwerkmineneilen gemeinsam geschult und verbessert wird, und die Mitwirkenden werden für ihre Beiträge zum Schulungs-, Aufbau und der Verwendung von KI -Modellen belohnt.Obwohl Ambient das dezentrale Denken betont, insbesondere im Proxy -Aspekt, werden Bergleute im Netzwerk auch dafür verantwortlich sein, die zugrunde liegenden Modelle, die das Netzwerk unterstützen, kontinuierlich zu aktualisieren.Ambient verwendet einen neuartigen P-Dach-F-Logits-Mechanismus (in diesem System können Validatoren überprüfen, ob die Modellberechnungen korrekt durchgeführt werden, indem der ursprüngliche Ausgangswert des Bergmanns (als Protokoll genannte Logits) geprüft wird. Das Projekt basiert auf einer Gabel von Solana und wurde noch nicht offiziell gestartet.
Blumenlabors: Flower Labs entwickelt ein Open -Source -Framework für Federated Learning, Flower, das das kollaborative KI -Modelltraining über dezentrale Datenquellen in Bezug auf dezentrale Datenquellen unterstützt, ohne Rohdaten zu teilen, wodurch Datenschutz geschützt und Modellaktualisierungen aggregiert werden. Die Blume wurde gegründet, um die Zentralisierung der Daten zu beheben, die es Institutionen und Einzelpersonen ermöglichte, Modelle mithilfe lokaler Daten wie Gesundheitswesen oder Finanzen zu schulen und gleichzeitig zu globalen Verbesserungen durch die sichere gemeinsame Nutzung von Parametern beizutragen.Im Gegensatz zu krypto-nativen Protokollen, die auf Token-Belohnungen und überprüfbares Computing hervorheben, priorisiert Blumen die Zusammenarbeit, die die Privatsphäre in realen Anwendungen schützt, was es zu einer idealen Wahl für regulierte Branchen ohne Blockchain macht.
Makrokosmos: Macrocosmos läuft im Bittensor-Netzwerk und entwickelt einen vollständigen KI-Modellerstellungsprozess, der fünf Subnetze abdeckt, die sich auf Vorausbildung, Feinabstimmung, Datenerfassung und dezentrale Wissenschaft konzentrieren.Es führt den Rahmenwerk für Incentive Orchestration Training Architecture (IoTA) für Großsprachmodelle vor der Training zu heterogenen, unzuverlässigen und lizenzfreien Hardware ein und hat über eine Milliarde Parameter-Schulungen eingeleitet und plant, schnell zu größeren Parametermodellen zu skalieren.
Flock.io: Flock ist ein dezentrales AI-Training-Ökosystem, das Federated Learning mit Blockchain-Infrastruktur kombiniert, um die kollaborative Modellentwicklung für den Schutz des Datenschutzes in einem modularen, token-incentiven Netzwerk zu erreichen. Die Teilnehmer können Modelle, Daten oder Rechenressourcen beibehalten und auf Kettenbelohnungen proportional zu ihren Beiträgen erhalten.Um die Datenschutzschütze zu schützen, nimmt das Protokoll das Föderierte Lernen an.Auf diese Weise können die Teilnehmer globale Modelle mithilfe lokaler Daten ausbilden, die nicht mit anderen gemeinsam genutzt werden.Während dieses Setup zusätzliche Überprüfungsschritte erfordert, um irrelevante Daten (häufig als Datenvergiftung bezeichnet) zu verhindern, ist es ein wirksamer Werbeansatz für Anwendungsfälle wie Gesundheitsanwendungen, bei denen mehrere Gesundheitsdienstleister globale Modelle schulen können, ohne hochempfindliche medizinische Daten auszulösen.
Aussichten und Risiken
In den letzten zwei Jahren hat sich das dezentrale Training von einem interessanten Konzept zu einem effektiven Netzwerk verwandelt, das in einer realen Umgebung läuft. Während diese Projekte noch weit vom erwarteten Endzustand entfernt sind, machen sie auf dem Weg zum dezentralen Training sinnvolle Fortschritte.Wenn man auf das vorhandene dezentrale Trainingsmuster zurückblickt, beginnen einige Trends zu entstehen:
Echtzeit-Proof of Concept ist keine Fantasie mehr.Frühe Überprüfungen wie Nous ‚Consilience und Prime Intellekts Intellekt-2 haben im vergangenen Jahr in den Produktionsmaßstab eingegangen.Durchbrüche wie Opendiloco- und Protokollmodelle ermöglichen Hochleistungs-KI in verteilten Netzwerken und ermöglichen die kostengünstige, widerstandsfähige und transparente Modellentwicklung.Diese Netzwerke koordinieren Dutzende oder sogar Hunderte von GPUs, die in Echtzeit mittelgroße Modelle vor der Ausbildung und Feinabstimmung, und beweisen, dass dezentrales Training über geschlossene Demonstrationen und temporäre Hackathons hinausgehen kann.Während diese Netzwerke immer noch keine netzlosen Netzwerke sind, fällt Templer in dieser Hinsicht auf.Sein Erfolg verstärkt die Idee, dass das dezentrale Training einfach beweist, dass die zugrunde liegende Technologie wirksam ist, um die Leistung zentraler Modelle zu entsprechen und die GPU -Ressourcen anzuziehen, die zur Erzeugung der zugrunde liegenden Modelle im Maßstab erforderlich sind.
Die Skala des Modells expandiert weiter, aber die Lücke bleibt bestehen.Von 2024 bis 2025 stieg die Anzahl der Parametermodelle für dezentrale Projekte von einstellig auf 30 bis 40 Milliarden.Das führende AI-Labor hat jedoch Billionen von Parametern des Systems veröffentlicht und wird mit seinen vertikal integrierten Rechenzentren und hochmodernen Hardware weiterhin schnell innovativ sein.Dezentrales Training kann diese Lücke überbrücken, indem sie Trainingshardware aus der ganzen Welt nutzt, insbesondere wenn zentrale Trainingsmethoden aufgrund der Notwendigkeit einer zunehmenden Anzahl von Hyperscale -Rechenzentren zunehmende Einschränkungen ausgesetzt sind.Das Schließen dieser Lücke hängt jedoch von weiteren Durchbrüchen bei Optimierern und der Gradientenkomprimierung für effiziente Kommunikation ab, um die globale Skala sowie eine nicht operierbare Anreiz- und Überprüfungsschicht zu erreichen.
Der Workflow nach dem Training wird zu einem Anliegen.Überwachende Feinabstimmung, RLHF und domänenspezifisches Verstärkungslernen erfordern eine viel niedrigere Synchronisationsbandbreite als eine umfassende Vorausbildung.Frameworks wie Prime-RL und RL Swarm sind auf instabilen Knoten auf Verbraucherebene ausgeführt, sodass Mitwirkenden von Leerlaufzyklen profitieren können, während Projekte kundenspezifische Modelle schnell kommerzialisieren können.Angesichts der Tatsache, dass RL für eine dezentrale Schulung gut geeignet ist, kann seine Bedeutung als Schwerpunkt für dezentrale Trainingsprogramme immer wichtiger werden.Dies ermöglicht es für dezentrale Schulungen, als erster einen groß angelegten Produktmarkt zu finden, der in RL-Training geeignet ist, wie sich die zunehmende Anzahl von Teams zeigt, die RL-spezifische Trainingsrahmen auf den Markt bringen.
Der Anreiz- und Überprüfungsmechanismus bleibt hinter der technologischen Innovation zurück.Die Anreiz- und Überprüfungsmechanismen bleiben immer noch hinter der technologischen Innovation zurück.Nur wenige Netzwerke, insbesondere Templer, bieten Echtzeit-Münzprämien sowie Straf- und Beschlagnahmungsmechanismen in Echtzeit, wodurch das schlechte Verhalten effektiv eindämmt und in realen Umgebungen getestet wurde.Obwohl andere Programme mit Reputationswerten, Beweis- oder Ausbildungsnachweisprogrammen experimentieren, sind diese Systeme weiterhin nicht überprüft.Selbst wenn technische Hindernisse überwunden werden, wird die Governance ebenso schwierige Herausforderungen stellen, da dezentrale Netzwerke Wege finden müssen, Regeln zu formulieren, Regeln durchzusetzen und Streitigkeiten ohne wiederholte Ineffizienzen, die in Krypto -DAOs auftreten, zu lösen.Die Lösung technischer Hindernisse ist nur der erste Schritt.Die langfristige Lebensfähigkeit hängt davon ab, es mit zuverlässigen Überprüfungsmechanismen, effektiven Governance-Mechanismen und überzeugenden Monetisierungs-/Eigentümerstrukturen zu kombinieren, um das Vertrauen in die durchgeführten Arbeiten zu gewährleisten und die für die Skalierung erforderlichen Talente und Ressourcen anzuziehen.
Der Stapel verschmilzt zu einer End-to-End-Pipeline.Heute kombinieren die meisten führenden Teams Bandbreiten-Ahal-Optimierer (Demo, Distro), dezentrale Computerbörsen (Prime Compute, Basilica) und Koordinationsschichten für Onkain (Psyche, PM, Prime). Schließlich wird eine modulare offene Pipeline gebildet, die den Workflow von zentralisierten Labors von Daten bis zur Bereitstellung widerspiegelt, jedoch ohne einen einzigen Kontrollpunkt.Auch wenn Projekte ihre eigenen Lösungen nicht direkt integrieren oder selbst wenn sie integriert sind, können sie mit anderen Kryptoprojekten zugreifen, die sich auf die für dezentralen Schulungen erforderlichen Branten konzentrieren, wie z.Diese periphere Infrastruktur bietet Plug-and-Play-Komponenten für dezentrale Trainingsprogramme, die weiter genutzt werden können, um ihre Produkte zu verbessern und besser mit zentralisierten Kollegen zu konkurrieren.
Risiko
Hardware- und Softwareoptimierung ist ein ständig ändernes Ziel – das zentrale Labor erweitert sich auch in diesem Bereich.Der Blackwell B200 -Chip von Nvidia wurde gerade angekündigt. In der MLPERF-Benchmark, unabhängig davon, ob es sich um 405 Milliarden Parameter oder 70 Milliarden Lora-Feinabstimmung handelt, beträgt der Trainingsdurchsatz 2,2- bis 2,6-mal schneller als die vorherige Generation, was die Zeit- und Energiekosten für die Giants erheblich verringert.In Bezug auf die Software führen Pytorch 3.0 und TensorFlow 4.0 COMPILER-Niveau-Graphenfusion und dynamische Formkörner ein, um die Leistung auf demselben Chip weiter zu verbessern.Mit Verbesserungen der Hardware- und Softwareoptimierung oder dem Aufkommen neuer Trainingsarchitekturen müssen dezentrale Trainingsnetzwerke auch mit kontinuierlichen Updates Schritt halten, um sich an die schnellsten und fortschrittlichsten Trainingsmethoden anzupassen, Talente anzuziehen und eine sinnvolle Modellentwicklung zu inspirieren.Dies erfordert, dass das Team Software entwickelt, die unabhängig von der zugrunde liegenden Hardware eine kontinuierliche hohe Leistung gewährleistet, und einen Software -Stapel, mit dem diese Netzwerke sich an Änderungen in der zugrunde liegenden Trainingsarchitektur anpassen können.
Das vorhandene Open -Source -Modell des Unternehmens verwischt die Grenzen zwischen dezentraler und zentraler Schulung.Die meisten zentralisierten KI -Labors halten Modelle geschlossen, was weiter beweist, dass eine dezentrale Schulung eine Möglichkeit ist, Offenheit, Transparenz und Gemeinschaftsführung zu gewährleisten.Obwohl jüngste Projekte wie Deepseek, GPT Open Source -Versionen und Lama ihre Verlagerung in Richtung höherer Offenheit zeigen, ist unklar, ob dieser Trend im Zusammenhang mit wachsenden Wettbewerb, regulatorischen und Sicherheitsbedenken fortgesetzt werden kann.Selbst wenn die Gewichte aufgedeckt werden, spiegeln sie die Werte und Auswahlmöglichkeiten des ursprünglichen Labors wider – die Fähigkeit, unabhängig zu trainieren, ist entscheidend für die Anpassungsfähigkeit, die Koordination mit unterschiedlichen Prioritäten und die Sicherstellung, dass der Zugang nicht durch eine Handvoll amtierender Unternehmen eingeschränkt wird.
Die Rekrutierung ist immer noch schwierig.Viele Teams erzählen uns das. Während sich die Qualität des Talents, die sich dezentralen Schulungsprogrammen anschließen, verbessert hat, fehlen ihnen die starken Ressourcen, die die KI -Labors leiten (zum Beispiel hat Openai kürzlich Millionen von Dollar an „Sonderbelohnungen“ pro Mitarbeiter oder das 250 -Millionen -Dollar -Angebot Meta angeboten, um Forschern zu pochieren).Derzeit ziehen dezentrale Projekte missionsgetriebene Forscher an, die Offenheit und Unabhängigkeit schätzen und gleichzeitig Talente aus einem breiteren globalen Talentpool und einer lebendigen Open-Source-Community ziehen.Um jedoch im Maßstab zu konkurrieren, müssen sie sich jedoch durch Schulungsmodelle beweisen, die mit bestehenden Unternehmen vergleichbar sind und Anreize und Monetarisierungsmechanismen perfektionieren, um sinnvolle Vorteile für Mitwirkende zu erzielen.Während lizenzfreie Netzwerke und kryptoökonomische Anreize einen einzigartigen Wert bieten, kann die Unfähigkeit, den Zugang zu Verteilung zu erhalten und eine nachhaltige Einnahmequelle zu schaffen, das langfristige Wachstum in diesem Sektor behindern.
Es gibt regulatorische Resistenz, insbesondere für unzensierte Modelle. Dezentrales Training steht vor einzigartigen regulatorischen Herausforderungen: In Bezug auf Design kann jeder jede Art von Modell ausbilden.Diese Offenheit ist sicherlich ein Vorteil, erhöht aber auch Sicherheitsrisiken, insbesondere in Biosicherheit, falschen Informationen oder anderen sensiblen Missbrauchsbereichen.EU und US-politische Entscheidungsträger haben signalisiert, dass sie ihre Prüfung stärken werden: Das Gesetz über künstliche Intelligenz der EU setzt zusätzliche Verpflichtungen zu Basismodellen mit hohem Risiko fest, während US-amerikanische Agenturen in Betracht ziehen, offene Systeme und potenzielle Kontrollmaßnahmen im Exportstil zu begrenzen.Ereignisse mit dezentralen Modellen allein für schädliche Zwecke können eine umfassende Regulierung auslösen und das grundlegende Prinzip der Erlaubnislosenausbildung bedrohen.
Verteilung und Monetarisierung: Die Verteilung bleibt eine große Herausforderung. Führende Labors wie OpenAI, Anthropic und Google haben enorme Vertriebsvorteile durch Markenbekanntheit, Unternehmensverträge, Cloud -Plattform -Integration und direkten Zugriff auf Verbraucher.Im Gegensatz dazu fehlen dezentrale Trainingsprogramme diese integrierten Kanäle, und es müssen weitere Anstrengungen unternommen werden, damit die Modelle übernommen, Vertrauen gewinnen und in tatsächliche Workflows eingebettet werden können.Angesichts der Tatsache, dass Kryptowährungen in ihrer Integration außerhalb von Kryptoanwendungen noch in den Kinderschuhen stecken (obwohl sich dies schnell ändert), kann dies schwieriger sein.Eine sehr wichtige und ungelöste Frage ist, wer diese dezentralen Trainingsmodelle tatsächlich verwenden wird.Es gibt bereits hochwertige Open-Source-Modelle, und sobald neue fortschrittliche Modelle veröffentlicht sind, ist es für andere nicht besonders schwierig, sie zu extrahieren oder anzupassen.Im Laufe der Zeit sollte die Open -Source -Natur der dezentralen Trainingsprogramme Netzwerkeffekte erzeugen, die das Verteilungsproblem lösen.Selbst wenn sie das Vertriebsproblem lösen können, wird das Team der Herausforderung der Produktmonetarisierung stehen.Derzeit scheinen die Projektmanager von Pluralis diese Monetarisierungsherausforderungen am direkten zu begegnen.Dies ist nicht nur ein Problem mit der Verschlüsselung X AI, sondern auch ein breiteres Verschlüsselungsproblem, das zukünftige Herausforderungen hervorhebt.
abschließend
Das dezentrale Training hat sich schnell von einem abstrakten Konzept zu einem effektiven Netzwerk entwickelt, das den Betrieb der tatsächlichen globalen Schulungen koordiniert.Im vergangenen Jahr haben Projekte wie Nous, Prime Intellekt, Pluralis, Templar und Genyn gezeigt, dass es möglich ist, dezentrale GPUs miteinander zu verbinden, die Kommunikation effizient zu komprimieren und sogar mit Anreizen in realen Umgebungen zu experimentieren.Diese frühen Demonstrationen zeigen, dass das dezentrale Training über die Theorie hinausgehen kann, obwohl der Weg zum Wettbewerb mit zentralisierten Labors in hochmodernen Maßstäben schwierig bleibt.
Auch wenn die von dezentralen Projekten schließlich geschulten grundlegenden Modelle mit den heutigen Labors für künstliche Intelligenz vergleichbar sind, stehen sie vor dem schwerwiegendsten Test: ihre realistischen Vorteile über die Anforderungen der Ideen hinaus.Diese Vorteile können sich durch exzellente Architektur oder lohnende neue Eigentums- und Monetarisierungssysteme endogen manifestieren.Alternativ können diese Vorteile auch exogen sein, wenn die zentralisierten vorhandenen Teilnehmer versuchen, Innovationen zu unterdrücken, indem sie Gewichte geschlossen halten oder unerwünschte Ausrichtungsverzerrungen injizieren.
Zusätzlich zu den technologischen Fortschritten haben sich auch die Einstellungen zum Feld geändert.Ein Gründer beschrieb die Veränderungen der Emotionen auf wichtigen KI -Konferenzen im vergangenen Jahr: Vor einem Jahr gab es wenig Interesse an dezentralem Training, insbesondere in Verbindung mit Kryptowährungen. Vor sechs Monaten begannen die Teilnehmer, potenzielle Probleme zu erkennen, zeigten jedoch Zweifel an der Machbarkeit einer groß angelegten Umsetzung. In den letzten Monaten wurde die Erkenntnis zunehmend, dass ein weiterer Fortschritt skalierbares dezentrales Training ermöglichen kann.Die Entwicklung dieses Konzepts zeigt, dass der Impuls des dezentralen Trainings nicht nur im Bereich Technologie, sondern auch in Bezug auf die Legitimität zunimmt.
Risiken sind real: Bestehende Unternehmen behalten ihre Hardware-, Talent- und Vertriebsvorteile weiter. Die regulatorische Überprüfung steht unmittelbar bevor. Anreize und Governance -Mechanismen wurden nicht in großem Umfang getestet. Die Vorteile sind jedoch gleichermaßen auffällig.Das dezentrale Training stellt nicht nur eine alternative Technologiearchitektur dar, sondern auch ein grundlegendes Konzept für den Aufbau künstlicher Intelligenz: keine Lizenz, globale Eigentümer und im Einklang mit einer vielfältigen Gemeinschaft als mit einigen wenigen Unternehmen.Auch wenn nur ein Projekt beweisen kann, dass Offenheit in eine schnellere Iteration, neuartige Architektur oder eine inklusivere Regierungsführung führen kann, wird es einen Durchbruch für Kryptowährungen und künstliche Intelligenz markieren.Die Straße vor uns ist lang, aber die Kernelemente des Erfolgs sind jetzt fest erfasst.







