著者:Lucas Tcheyan、Arjun Yenamandra、出典:Galaxy Research、編集:Bitchain Vision
導入
昨年、Galaxy Researchは、暗号通貨と人工知能の交差点に関する最初の記事を発表しました。この記事では、信頼のない暗号通貨や許可のないインフラストラクチャがAIイノベーションの基盤になる方法を探ります。これらには、グラフィックプロセッサ(GPU)の不足に応じて出現した処理能力(またはコンピューティング)の分散型市場の出現が含まれます。検証可能なオンチェーン推論におけるゼロ知識機械学習(ZKML)の初期の応用。また、自律的なAIエージェントが複雑な相互作用を簡素化し、暗号通貨をネイティブの交換媒体として使用する可能性。
当時、これらのイニシアチブの多くは初期段階にありましたが、集中化されたソリューションよりも実際的な利点があることを暗示する説得力のある概念の証明に過ぎませんでしたが、AIの景観を再構築するのに十分な拡張を行っていませんでした。しかし、それ以来、分散型AIはそれを達成する上で意味のある進歩を遂げました。この勢いをつかみ、最も有望な進歩を発見するために、Galaxy Researchは来年に一連の記事をリリースして、暗号化 +人工知能のフロンティアの特定の垂直を探索します。
この記事は、世界規模で基本モデルの許可されたトレーニングを実装することに専念するプロジェクトに焦点を当てた、分散型トレーニングで最初に公開されました。これらのプロジェクトの動機は2つあります。実用的な観点から、彼らは世界中の多数のアイドルGPUをモデルトレーニングに使用できることを認識し、世界中のAIエンジニアに耐えられないトレーニングプロセスを提供し、オープンソースのAI開発を実現しました。概念的な観点から、これらのチームは、私たちの時代の最も重要な技術革命の1つの厳格な制御と、オープンな代替案を作成する緊急の必要性によって動機付けられています。
より広く、暗号化フィールドの場合、基本モデルの分散化されたその後のトレーニングを実装することは、許可を必要とせず、すべてのレイヤーでアクセスできる完全にオンチェーンAIスタックを構築する重要なステップです。GPU市場はモデルにアクセスし、トレーニングと推論に必要なハードウェアを提供できます。ZKMLプロバイダーを使用して、モデルの出力を検証し、プライバシーを保護できます。AIエージェントは、モデル、データソース、プロトコルを高次アプリケーションに組み合わせた構成可能なビルディングブロックとして機能します。
このレポートでは、分散化された人工知能プロトコルの基礎となるアーキテクチャ、解決することを目的とした技術的な問題、および分散型トレーニングの見通しについて説明します。暗号通貨と人工知能の根底にある前提は、1年前と同じままです。暗号通貨は、AIに、許可されていない、信頼できない、構成可能な価値転送決済レイヤーを提供します。現在の課題は、分散型アプローチが集中的なアプローチよりも実際的な利点をもたらすことができることを証明することです。
モデルトレーニングの基本
分散トレーニングの最新の進歩に飛び込む前に、大規模な言語モデル(LLM)とその基礎となるアーキテクチャを基本的に理解する必要があります。これは、読者がこれらのプロジェクトがどのように機能するか、そして彼らが解決しようとしている主な問題を理解するのに役立ちます。
トランス
大規模な言語モデル(LLMS)(ChatGPTなど)は、Transformerと呼ばれるアーキテクチャを搭載しています。Transformerは2017年のGoogle Paperで最初に提案され、人工知能開発の分野で最も重要な革新の1つです。要するに、トランスはデータ(トークンと呼ばれる)を抽出し、これらのトークン間の関係を学ぶためにさまざまなメカニズムを適用します。
エントリ間の関係は、重みを使用してモデル化されます。ウェイトは、モデルを構成する数百万から数兆のノブと見なすことができます。これは、シーケンスの次のエントリが一貫して予測できるまで常に調整されています。トレーニングが完了した後、モデルは基本的に人間の言語の背後にあるパターンと意味をキャプチャできます。
トランストレーニングの重要なコンポーネントには次のものがあります。
-
フォワード配達:トレーニングプロセスの最初のステップでは、トランスはより大きなデータセットからトークンのバッチに入ります。これらの入力に基づいて、モデルは次のトークンがどうあるべきかを予測しようとします。トレーニングの開始時に、モデルの重みはランダムです。
-
損失計算:次に、順方向伝播予測を使用して、これらの予測と入力モデルの元のデータバッチの実際のマーキングとの間のギャップを測定する損失スコアを計算します。言い換えれば、前方伝播中にモデルによって生成された予測は、より大きなデータセットでそれをトレーニングするために使用される実際のマーカーと比較してどのように比較されますか?トレーニング中の目標は、この損失スコアを減らしてモデルの精度を向上させることです。
-
バックプロパゲーション:次に、各重量の勾配が損失スコアを使用して計算されます。これらの勾配は、次の前方繁殖の前に損失を減らすためにウェイトを調整する方法をモデルに示します。
-
オプティマイザ更新:最適化するrアルゴリズムはこれらの勾配を読み取り、各重量を調整して損失を減らします。
-
繰り返す:すべてのデータが消費され、モデルが収束に達するまで上記の手順を繰り返します–言い換えれば、さらに最適化がもはや大幅な損失の削減またはパフォーマンスの改善をもたらさない場合。
トレーニング(トレーニング前とトレーニング後)
完全なモデルトレーニングプロセスは、トレーニング前とトレーニング後の2つの独立した手順で構成されています。上記の手順は、トレーニング前のプロセスのコアコンポーネントです。完了すると、一般的にベースモデルとして知られている事前に訓練されたベースモデルを生成します。
ただし、モデルは、トレーニング後と呼ばれる前oraining後にさらに改善する必要があることがよくあります。トレーニング後は、翻訳や医療診断などの特定のユースケースの精度の向上やカスタマイズなど、さまざまな方法で基本モデルをさらに改善するために使用されます。
トレーニング後は、今日の大規模な言語モデル(LLMS)を強力なツールにするための重要なステップです。その後、トレーニングする方法はいくつかあります。最も人気のある2つは次のとおりです。
-
監視された微調整(SFT):SFTは、上記のトレーニング前のプロセスに非常に似ています。主な違いは、基本モデルがより慎重に計画されたデータセットまたはヒントと回答でトレーニングされているため、特定の指示に従うか、特定のフィールドに集中することを学ぶことができることです。
-
強化学習(RL):RLは、新しいデータを入力することでモデルを改善するのではなく、モデルの出力を評価し、モデルに重量を更新してその報酬を最大化させることで改善します。最近、推論モデル(以下で説明)がRLを使用して出力を改善しました。近年、トレーニング前のスケーリングの問題が明らかになっているため、トレーニング後にRLおよび推論モデルを使用することで大きな進歩が遂げられています。これは、追加データや大量の計算なしでモデルのパフォーマンスを大幅に向上させるためです。
具体的には、RL後のトレーニングは、分散トレーニングで直面する障害を解決するのに理想的です(以下で説明)。これは、ほとんどの場合、RLではモデルがフォワードパスを使用し(モデルは予測を行いますが、まだ変更されていません)、大量の出力を生成するためです。これらのフォワードパスは、マシン間の調整や通信を必要とせず、非同期に行うことができます。また、それらは並行しています。つまり、複数のGPUで同時に実行できる独立したサブタスクに分解できます。これは、各ロールアウトを個別に計算し、計算を追加してトレーニングの実行を通じてスループットを増やすことができるためです。最良の回答が選択された後にのみ、モデルは内部重量を更新し、マシンを同期する必要がある頻度を減らします。
モデルがトレーニングされた後、それを使用して出力を生成するプロセスは推論と呼ばれます。数百万または数十億の重みを調整する必要があるトレーニングとは異なり、推論はこれらのウェイトを変更しておき、単純に新しい入力に適用します。大規模な言語モデル(LLM)の場合、推論とは、プロンプトを取得し、モデルのさまざまなレイヤーに実行し、最も可能性の高い次のマークアップを段階的に予測することを意味します。推論では、バックプロパゲーション(モデルのエラーに基づいて重みを調整するプロセス)または重量の更新を必要としないため、トレーニングよりもはるかに少ない計算必要はありませんが、最新モデルの大規模なため、リソース集約型です。
要するに、推論は、チャットボット、コードアシスタント、翻訳ツールなどのアプリケーションの背後にある原動力です。この段階で、モデルは「学んだ知識」を実践に導きます。
オーバーヘッドのトレーニング
上記のトレーニングプロセスを促進するには、リソースを集中し、高度に専門化されたソフトウェアとハードウェアを大規模に実行する必要があります。世界をリードする人工知能ラボへの投資は、数億から数十億ドルの範囲で、前例のないレベルに達しました。Openai CEOのSam Altmanは、GPT-4の費用は1億ドルを超え、人類のCEOであるDario Amodeiは、10億ドル以上のトレーニングプログラムがすでに進行中であると述べました。
これらのコストの大部分はGPUから来ています。NvidiaのH100やB200のようなトップGPUのコストは最大30,000ドルであり、Openaiは2025年末までに100万GPU以上を展開する予定です。ただし、GPUだけの力を持つだけでは不十分です。これらのシステムは、超高速通信インフラストラクチャを備えた高性能データセンターに展開する必要があります。NVIDIA NVLINKなどのテクノロジーは、サーバー内のGPU間の高速データ交換をサポートしますが、Infinibandはサーバークラスターに接続して、単一の統一コンピューティング構造として実行できます。
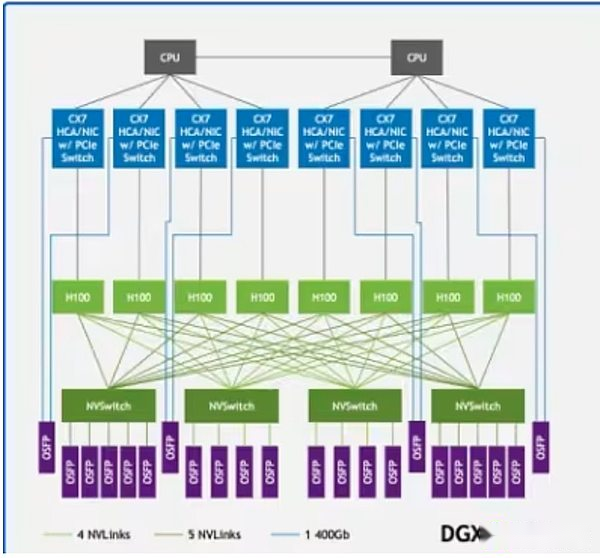 DGX H100サンプルアーキテクチャのnvlinkは、システム内のGPU(薄緑色の長方形)を接続し、Infinibandはサーバー(緑色の線)を統一ネットワークに接続します
DGX H100サンプルアーキテクチャのnvlinkは、システム内のGPU(薄緑色の長方形)を接続し、Infinibandはサーバー(緑色の線)を統一ネットワークに接続します
したがって、基本モデルのほとんどは、Openai、人類、Meta、Google、Xaiなどの集中AIラボによって開発されています。そのような巨人だけがトレーニングに必要な豊富なリソースを持っています。これにより、モデルのトレーニングとパフォーマンスに大きなブレークスルーがもたらされましたが、いくつかのエンティティの手にある主要な基本モデルの開発に対する制御も集中しています。さらに、スケーリングの法則が機能している可能性があるという証拠が増えており、単に計算またはデータを追加することで、事前に処理されたモデルの知能を強化する有効性を制限しています。
この課題に対処するために、過去数年にわたって、AIエンジニアのグループは、これらの技術的複雑さに対処し、巨大なリソース要件を削減しようとする新しいモデルトレーニング方法を開発し始めました。この記事は、この取り組みを「分散トレーニング」と呼んでいます。
分散型および分散トレーニング
ビットコインの成功は、コンピューティングと資本を分散化して調整できるため、大規模な経済的ネットワークのセキュリティを確保できることを証明しています。分散トレーニングの目的は、中央集中型プロバイダーに匹敵する強力な基本モデルをトレーニングするために、許可、信頼のない、インセンティブメカニズムを含む暗号通貨の機能を使用して分散ネットワークを構築することを目的としています。
分散トレーニングでは、世界中のさまざまな場所にあるノードは、人工知能モデルのトレーニングに貢献して、許可されたインセンティブネットワークで機能します。これは、分散トレーニングとは異なります。これは、モデルが異なる地域でトレーニングされているが、ライセンスされている1つ以上のエンティティによって実行されることを指します(つまり、ホワイトリストプロセスを介して)。ただし、分散型トレーニングの実現可能性は、分散トレーニングに基づいている必要があります。トレーニング設定の厳格な制限を認識している多くの集中研究所は、既存の設定に匹敵する結果を達成するために分散トレーニングを実装する方法を探求し始めました。
分散化されたトレーニングが現実になるのを妨げるいくつかの実用的な障害があります。
-
コミュニケーションオーバーヘッド:ノードが地理的に分散している場合、上記の通信インフラストラクチャにアクセスできません。分散トレーニングには、標準的なネットワーク速度、大量のデータの頻繁な送信、およびトレーニング中のGPUの同期を考慮する必要があります。
-
確認する:分散型トレーニングネットワークは本質的にライセンスがなく、誰でもコンピューティングパワーを提供できるように設計されています。したがって、貢献者が誤ったまたは悪意のある入力を通じてネットワークを破壊しようとするのを防ぐために、効果的な作業を貢献することなく報酬を得るためにシステムの脆弱性を活用するための検証メカニズムを開発する必要があります。
-
計算します:サイズに関係なく、分散型ネットワークはモデルをトレーニングするのに十分なコンピューティング能力を収集する必要があります。これにより、GPUを持つ人なら誰でもトレーニングプロセスに参加できるように設計された分散ネットワークの利点がいくつかありますが、これらのネットワークは不均一なコンピューティングを調整する必要があるため、複雑さももたらします。
-
インセンティブ/資金/所有権と収益化:分散型トレーニングネットワークは、ネットワークの整合性を効果的に確保し、コンピューティングプロバイダー、バリッター、モデルデザイナーの貢献に報いるために、インセンティブメカニズムと所有権/収益化モデルを設計する必要があります。これは、モデルの建設と収益化が会社によって行われている集中化された研究室とは対照的です。
これらの制限にもかかわらず、多くのプロジェクトは、基礎となるモデルの制御が少数の企業の手に渡るべきではないと考えているため、分散トレーニングを依然として実装しています。彼らの目標は、いくつかの集中製品に依存しているための単一ポイント障害など、集中トレーニングによってもたらされるリスクに対処することです。データプライバシーと検閲。スケーラビリティ。人工知能における一貫性とバイアス。より広く言えば、彼らは、オープンソースの人工知能開発が必要であり、オプションではないと考えています。オープンで検証可能なインフラストラクチャがなければ、イノベーションは抑制され、アクセスはいくつかの特権クラスに限定され、社会は狭い企業のインセンティブによって形作られたAIシステムを継承します。この観点から、分散型トレーニングは、競争力のあるモデルを構築するだけでなく、独自の利益ではなく集団的利益を反映する回復力のある透明性のある参加型エコシステムを作成することでもあります。
プロジェクトの概要
以下に、いくつかの分散型トレーニングプロジェクトの基礎となるメカニズムの詳細な概要を示します。
ヌースリゾート
背景
2022年に設立されたNous Researchは、オープンソースのAI研究機関です。チームは、オープンソースAIコードの制限に対処するために取り組んでいるオープンソースのAI研究者と開発者の非公式グループとしてスタートしました。その使命は、「最高のオープンソースモデルを作成して提供する」ことです。
チームは長い間、分散型トレーニングを大きな障害と見なしてきました。具体的には、GPUにアクセスし、GPU間のコミュニケーションを調整するためのツールが主に集中型AI企業に対応するために開発されたことに気付きました。たとえば、Nvidiaの最新のBlackwell GPU(B200など)は、1秒あたり最大1.8 Tbの速度でnvlinkスイッチングシステムを使用して相互に通信できます。これは、主流のインターネットインフラストラクチャの総帯域幅に匹敵し、集中化されたデータセンター規模の展開でのみ実現できます。したがって、コミュニケーション戦略を再考することなく、小規模または分散ネットワークが大規模なAIラボのパフォーマンスを達成することはほぼ不可能です。
分散訓練の問題を解決する前に、Nousは人工知能の分野に多大な貢献をしました。2023年8月、Nousは「ヤーン:大規模な言語モデルの効率的なコンテキストウィンドウ拡張」を公開しました。このペーパーでは、単純だが重要な問題を解決します。ほとんどのAIモデルは、一度に一定量のテキスト(つまり、「コンテキストウィンドウ」)のみを覚えて処理できます。たとえば、2,000語の制限で訓練されたモデルは、入力ドキュメントが長くなるとすぐに情報を忘れたり失い始めたりします。Yarnは、モデルをゼロから再訓練することなく、この制限をさらに拡張する方法を紹介します。モデルが単語の位置(本のブックマークなど)を追跡する方法を調整して、テキストが数万単語の長さであっても情報フローを追跡できるようにします。この方法により、モデルは、マークトウェインのハックルベリーフィンの冒険の長さを約128,000マーカーのシーケンスを処理できます。要するに、YARNは、AIモデルが一度に長いドキュメント、会話、またはデータセットを「読み取り」、理解することを可能にします。これはAI能力の拡大における大きな進歩であり、中国のOpenaiやDeepseekなど、より広い研究コミュニティによって採用されています。
デモとディストリビューション
2024年3月、Nousは、「分離運動量最適化」(DEMO)と呼ばれる分散トレーニングの分野でブレークスルーを発表しました。デモは、Nousの研究者Bowen PengとJeffrey Quesnelleによって開発され、Openaiの共同設立者でありAdamw Optimizerの発明者であるDiederik P. Kingmaと協力して開発されました。これは、Nous分散型トレーニングスタックの主要なビルドブロックであり、GPU間で交換されるデータの量を減らすことにより、分散データの並列モデルトレーニング設定の通信オーバーヘッドを削減します。データの並列トレーニングでは、各ノードはモデルの重みの完全なコピーを保存しますが、データセットは異なるノードで処理されたブロックに分割されます。
ADAMWは、モデルトレーニングで最も一般的に使用されるオプティマーの1つです。Adamwの重要な機能は、過去に変化するモデルの重みの実行平均である勢いと呼ばれるものをスムーズにすることです。基本的に、ADAMWは、データの並列トレーニング中に導入されたノイズを排除するのに役立ち、それによりトレーニングの効率が向上します。Nous Researchは、AdamwとDemoに基づいて完全に新しいオプティマイザーを作成し、さまざまなトレーナーのローカルパーツと共有部品に勢いを分割します。これにより、ノード間で共有する必要があるデータの量を制限することにより、ノード間で必要なトラフィックの量が減少します。
デモは、各GPUイテレーション中に最も速く変化するパラメーターに選択的に焦点を当てています。ロジックは単純です。バリエーションが大きいパラメーターは学習にとって重要であり、優先度が高い労働者間で同期する必要があります。同時に、収束に大きな影響を与えることなく、より遅い変化するパラメーターを一時的に遅らせることができます。実際、これは最も意味のある更新を保持しながら、ノイズの更新を除外します。Nousは、JPEG圧縮画像と同様の離散コサイン変換(DCT)メソッドを含む圧縮技術も使用して、送信されるデータの量をさらに減らします。最も重要な更新のみを同期させることにより、デモは通信オーバーヘッドを10〜1,000倍削減します(モデルサイズに応じて)。
2024年6月、Nousチームは2番目の主要なイノベーションである分散トレーニングオプティマイザー(ディストリビューション)を開始しました。Demoはコアオプティマイザーの革新を提供し、ディストリビューションはGPUとGPUの同期、フォールトトレランス、負荷分散などの問題との間で共有された情報をさらに圧縮するより広いオプティマイザーフレームワークに統合します。2024年12月、Nousはディストリビューションを使用して、Llamaのようなアーキテクチャで150億パラメーターのモデルをトレーニングし、この方法の実現可能性を証明しました。
サイケ
5月、Nousは、分散トレーニングを調整するためのフレームワークであるPsycheをリリースし、デモおよびディストリビューションオプティマイザーアーキテクチャのさらなる革新を行いました。Psycheの主な技術的アップグレードには、トレーニングの次のステップを開始するときにGPUがモデルの更新を送信できるようにすることにより、非同期トレーニングの改善が含まれます。これにより、アイドル時間を最小限に抑え、GPUの使用率が集中化された、緊密に結合されたシステムに近づきます。Psycheは、ディストリビューションによって導入された圧縮技術をさらに改善し、通信負荷をさらに3回減らしました。
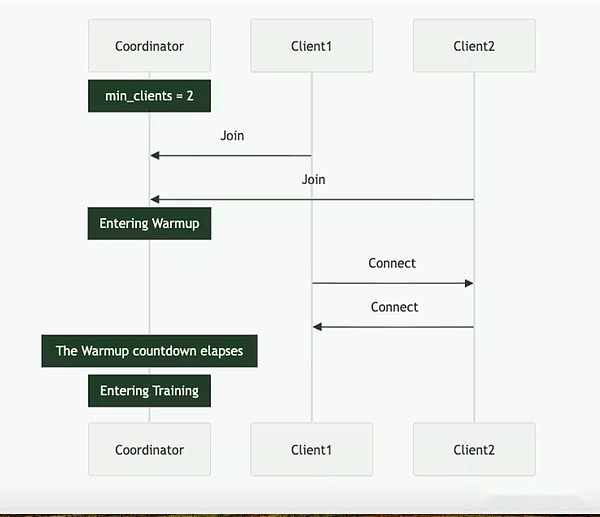
サイケは、完全にオンチェーン(ソラナ経由)またはオフチェーンのセットアップを通じて達成できます。コーディネーター、クライアント、データプロバイダーの3人の主要なプレーヤーが含まれています。コーディネーターは、モデルの最新の状態、参加クライアント、データの割り当てと出力検証など、トレーニング操作を促進するために必要なすべての情報を保存します。クライアントは、トレーニングの実行中にトレーニングタスクを実行する実際のGPUプロバイダーです。モデルトレーニングに加えて、彼らは証人プロセスに関与しています(以下で説明)。データプロバイダー(クライアントは単独で保存できます)は、トレーニングに必要なデータを提供します。
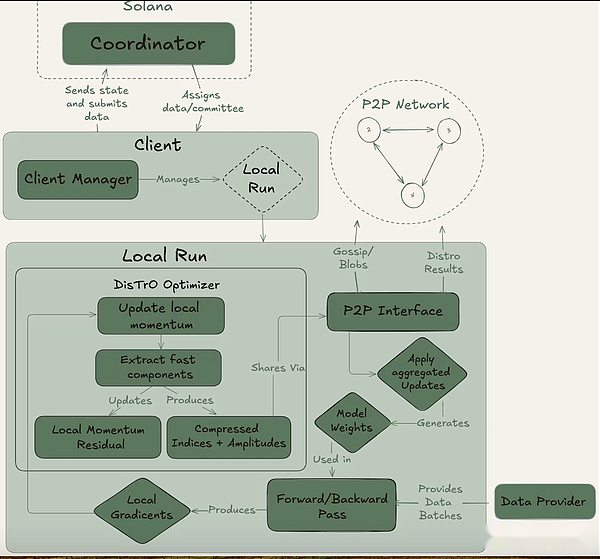 Psycheは、トレーニングをエポックとステップの2つの異なる段階に分割します。これにより、クライアントが自然なエントリと出口ポイントが作成され、フルトレーニングの実行に投資せずに参加できます。この構造は、GPUプロバイダーの機会コストを最小限に抑えるのに役立ちます。これは、実行中にリソースを投資できない可能性があるためです。
Psycheは、トレーニングをエポックとステップの2つの異なる段階に分割します。これにより、クライアントが自然なエントリと出口ポイントが作成され、フルトレーニングの実行に投資せずに参加できます。この構造は、GPUプロバイダーの機会コストを最小限に抑えるのに役立ちます。これは、実行中にリソースを投資できない可能性があるためです。
エポックの開始時に、コーディネーターは重要なパラメーターを定義します。モデルアーキテクチャ、使用するデータセット、および必要なクライアントの数です。次は、クライアントが最新のモデルチェックポイントに同期する短いウォームアップフェーズです。これは、パブリックソースまたは他のクライアントからのポイントツーポイントの同期からの可能性があります。トレーニングが開始された後、各クライアントはデータの一部を割り当てられ、ローカルでトレーニングされます。計算の更新後、クライアントは結果をネットワークの残りの部分にブロードキャストし、暗号化の約束(作業が正しく行われていることを証明するSHA-256ハッシュ)。
クライアントの一部は、各ラウンドの証人としてランダムに選択され、精神の主な検証メカニズムとして機能します。これらの証人は通常どおり訓練しますが、どのクライアントの更新が受信されているかを確認します。彼らは、これらの参加を効果的に要約する軽量データ構造であるコーディネーターにブルームフィルターを提出します。Nous自身は、このアプローチは誤った肯定的なものを生み出す可能性があるため、このアプローチは完全ではないことを認めていますが、研究者はこのトレードオフを効率的に受け入れることをいとわない。更新された証人が定足数が到達することを確認すると、コーディネーターはグローバルモデルに更新を適用し、すべてのクライアントが次のラウンドに入る前にモデルを同期させることができます。
重要なことに、Psycheの設計により、トレーニングと検証に重複することができます。クライアントがアップデートを提出すると、コーディネーターや他のクライアントが以前のトレーニングを完了するのを待つことなく、すぐに次のバッチのトレーニングを開始できます。この重複する設計は、ディストリビューションの圧縮技術と組み合わせて、通信オーバーヘッドを最小限に抑え、GPUがアイドル状態ではないことを保証します。
 2025年5月、Nous Researchは、Psyche分散トレーニングネットワークで約20兆トークンを事前トレーニングする、400億パラメーターを持つトランス、Consilience、Consilience:Consilience:Consilience:Consilience:Consilienceの実行を開始しました。トレーニングはまだ進行中です。これまでのところ、操作は基本的に安定していますが、いくつかの損失ピークが発生しており、最適化の軌跡が収束から一時的に逸脱していることを示しています。これを行うために、チームは最後のヘルスチェックポイントに戻り、Olmoのスキップステップ保護を使用してオプティマイザーをカプセル化しました。これにより、平均からいくつかの標準偏差によって異なる損失または勾配の規範の更新が自動的にスキップされ、将来のピークのリスクが減ります。
2025年5月、Nous Researchは、Psyche分散トレーニングネットワークで約20兆トークンを事前トレーニングする、400億パラメーターを持つトランス、Consilience、Consilience:Consilience:Consilience:Consilience:Consilienceの実行を開始しました。トレーニングはまだ進行中です。これまでのところ、操作は基本的に安定していますが、いくつかの損失ピークが発生しており、最適化の軌跡が収束から一時的に逸脱していることを示しています。これを行うために、チームは最後のヘルスチェックポイントに戻り、Olmoのスキップステップ保護を使用してオプティマイザーをカプセル化しました。これにより、平均からいくつかの標準偏差によって異なる損失または勾配の規範の更新が自動的にスキップされ、将来のピークのリスクが減ります。
ソラナの役割
Psycheはオフチェーン環境で実行できますが、Solanaブロックチェーンで使用するように設計されています。Solanaは、トレーニングネットワークの信頼と説明責任層として機能し、顧客のコミットメント、証人の証明、およびチェーン上のメタデータのトレーニングを記録します。これにより、トレーニングの各ラウンドに不変の監査証跡が作成され、誰が貢献したか、どのような作業が行われたか、それが合格したかどうかの透明な検証が可能になります。
また、NousはSolanaを使用して、トレーニングの報酬の分配を容易にする予定です。このプロジェクトは正式なトークン経済学をリリースしていませんが、Psycheのドキュメントでは、コーディネーターがクライアントの計算貢献を追跡し、検証済みの作業に基づいてポイントを割り当てるシステムの概要を説明しています。これらのポイントは、オンチェーンでエスクローされた金融スマートコントラクトとして機能することにより、トークンと交換できます。効果的なトレーニングステップを完了するクライアントは、貢献に基づいて契約から直接報酬を受け取ることができます。Psycheは、トレーニングの実行で報酬メカニズムをまだ使用していませんが、正式に発売されると、システムはNous Cryptoトークンの割り当てにおいて中心的な役割を果たすことが期待されています。
エルメスモデルシリーズ
これらの研究の貢献に加えて、Nousは、そのエルメスシリーズの命令チューニング大手言語モデル(LLM)で、その主要なオープンソースモデル開発者のステータスを確立しました。2024年8月、チームはLlama 3.1に基づいて微調整されたフルパラメーターモデルスイートであるHermes-3を立ち上げました。
最近、Nousは2025年8月にHermes-4モデルシリーズをリリースしました。これは、これまでで最も先進的なモデルシリーズです。Hermes-4は、モデルの段階的な推論機能の改善に焦点を当て、定期的な指導実行において優れたパフォーマンスを発揮します。数学、プログラミング、理解、常識テストでうまく機能しました。チームはNousのオープンソースミッションを順守し、すべてのエルメス4モデルの重みを公開して、誰もが使用および構築するために公開します。さらに、NousはNous Chatというモデルアクセシビリティインターフェイスをリリースしました。これは、リリースの最初の1週間以内に無料で利用できるようになります。
エルメスモデルのリリースは、モデル構築組織としての信頼性を強化するだけでなく、その幅広い研究アジェンダの実用的な検証も提供します。エルメスの各リリースは、オープンな環境で最先端の機能を達成できることを証明し、チームの分散化されたトレーニングのブレークスルー(デモ、ディストリビューション、精神)の基礎を築き、最終的には40Bランにつながります。
アトロポス
上記のように、強化学習は、推論モデルの進歩とトレーニング前の拡大の制限により、トレーニング後にますます重要な役割を果たします。Atroposは、分散環境で学習を強化するためのNousのソリューションです。これは、LLMのプラグアンドプレイモジュラー強化学習フレームワークであり、さまざまな推論バックエンド、トレーニング方法、データセット、および強化学習環境に適応します。
多数のGPUを使用して、延期後の学習が分散的にトレーニングされると、トレーニング中にモデルによって生成されるインスタント出力は、完了時間が異なります。Atroposは、ロールアウトプロセッサ、つまり、デバイス全体でタスクの生成と完了を調整する中央コーディネーターとして機能し、それにより非同期強化学習トレーニングを可能にします。
Atroposの初期バージョンは4月にリリースされましたが、現在、補強学習タスクを調整する環境フレームワークのみが含まれています。Nousは、今後数か月で補完的なトレーニングと推論フレームワークをリリースする予定です。
主な知性
背景
2024年に設立されたPrime Intellectは、大規模な分散型AI開発インフラストラクチャの構築に取り組んでいます。Vincent WeisserとJohannes Hagemannによって設立されたチームは、当初、集中型および分散型プロバイダーからコンピューティングリソースを統合して、高度なAIモデルの共同分散トレーニングをサポートすることに焦点を当てていました。Prime Intellectの使命は、AI開発を民主化し、世界中の研究者と開発者がスケーラブルなコンピューティングリソースにアクセスし、共同でAIイノベーションを共同で所有できるようにすることです。
Opendiloco、Intellect-1、Prime
2024年7月、Prime Intellectは、Google DeepMindがデータパラレルトレーニングのために開発した低コミュニケーションモデルトレーニング方法であるDilocoのオープンソースバージョンであるOpendilocoをリリースしました。Googleは、「現代スケールでの標準的なバックプロパゲーションによるトレーニングは、前例のないエンジニアリングおよびインフラストラクチャの課題を提示することを示しています。多数のアクセラレータを調整して密接に同期することは困難です」という見解に基づいてモデルを開発しました。この声明は、オープンソース開発の精神ではなく、大規模なトレーニングの実用性に焦点を当てていますが、デフォルトは長期的な集中トレーニングの限界と分散の代替案の必要性に焦点を当てています。
Dilocoは、トレーニングモデル時にGPU間で共有される情報の頻度と量を減らします。集中設定では、GPUはトレーニングの各ステップの後、すべての更新された勾配を互いに共有します。ディロコでは、更新勾配の共有頻度が低く、通信が頭上を減らします。これにより、二重最適化アーキテクチャが作成されます。個々のGPU(またはGPUクラスター)は、内部最適化を実行し、各ステップの後に独自のモデルの重みを更新します。外部の最適化、内部最適化はGPU間で共有され、すべてのGPUは行われた変更に基づいて更新されます。
Opendilocoは、最初のリリースでGPU利用の90%から95%を実証しました。つまり、2つの大陸と3か国に分配されているにもかかわらず、アイドル状態はほとんどありません。Opendilocoはかなりのトレーニングの結果とパフォーマンスを再現することができますが、交通量は500回減少します(下の図の青い線に追いつく紫色のラインに示されています)。
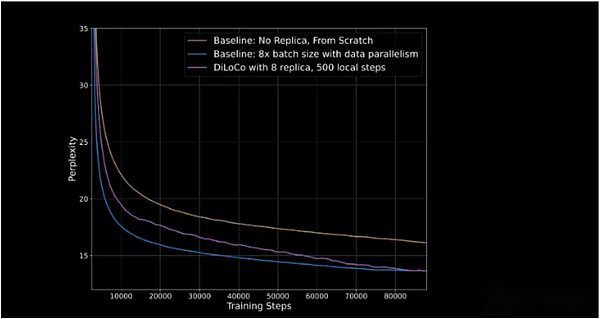
垂直軸は、次のマーカーをシーケンスで予測するモデルの能力を測定する困惑を表します。困惑が低いほど、モデルの予測が自信があり、精度が高くなります。
2024年10月、Prime IntellectはIntellect-1のトレーニングを開始します、これは、分散的に訓練された最初の100億パラメーター言語モデルです。トレーニングには42日かかり、その後モデルは開かれていました。トレーニングは、3つの大陸の5か国で実施されています。トレーニングの実行は、分散トレーニングの段階的な改善を示しており、すべてのコンピューティングリソースの利用率は83%に達し、米国だけではノード間通信の利用率が96%に達します。このプロジェクトで使用されるGPUは、Akash、双曲線、OLAなどの暗号GPU市場を含むWeb2およびWeb3プロバイダーからのものです。
Intellect-1は、Prime Intellectの新しいトレーニングフレームワークPrimeを採用しています。これにより、Prime Intellect Training Systemは、予期しないエントリを計算して継続的なトレーニングを終了するときに適応できます。ElasticDeviceMeshなどの革新的なテクノロジーを導入し、貢献者がいつでも参加または退場できるようにします。
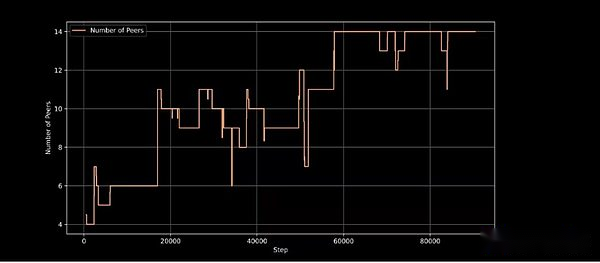
トレーニングステップでのアクティブトレーニングノード、動的ノードの参加を処理するトレーニングアーキテクチャの能力を実証する
Intellect-1は、Prime Intellectの分散型トレーニングアプローチの重要な検証であり、Jack Clark(Anthropicの共同設立者)などのAIの思想的リーダーによって賞賛されており、分散型トレーニングの実行可能な実証と考えられています。
プロトコル
今年2月、Prime Intellectはスタックに別のレイヤーを追加し、プロトコルを起動しました。プロトコルは、Prime Intellectのすべてのトレーニングツールを一緒に接続して、分散モデルトレーニングのためのポイントツーポイントネットワークを作成します。これらには以下が含まれます:
-
スイッチGPUを計算して、トレーニングの実行を容易にします。
-
主要なトレーニングフレームワークは、通信のオーバーヘッドを削減し、フォールトトレランスを向上させます。
-
RLファインチューニングにおける有用な合成データ生成と検証のためのGenesysと呼ばれるオープンソースライブラリ。
-
モデル実行および参加ノードの出力を検証するためのToplocと呼ばれる軽量検証システム。
プロトコルの役割は、4人の主要なプレーヤーがいるNousの精神に似ています。
-
ワーカー:ユーザーがコンピューティングリソースをトレーニングまたは他の主要な知性AI関連製品に提供できるようにするソフトウェア。
-
Verifier:計算貢献を確認し、悪意のある動作を防ぎます。Prime Intellectは、最先端の推論検証アルゴリズムToplocを分散トレーニングに適用するために取り組んでいます。
-
オーケストレーター:プールクリエイターが労働者を管理する方法。Nousのオーケストレーターに似ています。
-
スマートコントラクト:コンピューティングリソースプロバイダーを追跡し、悪意のある参加者からのステーキングを減らし、独立して報酬を支払う。現在、Prime IntellectはEthereum L2 BaseのSepoliaテストネットワークで実行されていますが、Prime Intellectは、最終的に独自のブロックチェーンに移行する計画を立てると述べています。
 段階的にプロトコルトレーニング
段階的にプロトコルトレーニング
Protocolは、最終的に貢献者がモデルの株式を所有するか、仕事に対する報酬を受け取ることを許可することを目的としていますが、スマートコントラクトと集団的インセンティブを通じて開発を資金提供および管理する新しい方法をオープンソースAIプロジェクトに提供します。
知性2と強化学習
今年4月、Prime IntellectはIntellect-2と呼ばれる320億パラメーターモデルのトレーニングを開始しました。Intellect-1は基本モデルのトレーニングに焦点を当て、Intellect-2は強化学習を使用して別のオープンソースモデル(AlibabaのQWQ-32B)で推論モデルをトレーニングします。
チームは、この分散型RLトレーニングを実用的にするために、2つの重要なインフラストラクチャコンポーネントを導入しました。
-
Prime-RLは、学習プロセスを3つの独立した段階に分割する完全に非同期の強化学習フレームワークです。選択した回答のトレーニング。更新されたモデルの重みを放送しました。この分離メカニズムにより、システムは信頼性、低速、または地理的に分散されたネットワークにまたがることができます。トレーニングプロセスは、主要な知性であるGenesysからの別の革新を使用して、数千の数学、論理、コーディングの質問を生成し、答えが正しいかどうかを即座に判断できる自動チェッカーを装備しています。
-
Shardcastは、ネットワーク上に大きなファイル(更新されたモデルの重みなど)をすばやく配布するための新しいシステムです。Shardcastすべてのマシンが中央サーバーから更新をダウンロードするわけではありませんが、マシン間の更新を共有する構造を採用しています。これにより、ネットワークを効率的に、高速で回復力があります。
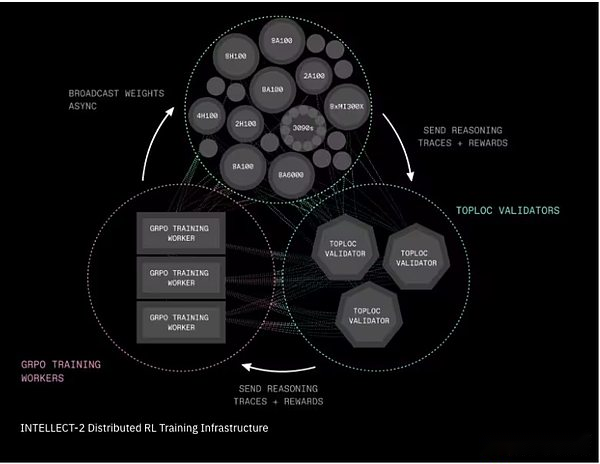 Intellect-2分散補強学習トレーニングインフラストラクチャ
Intellect-2分散補強学習トレーニングインフラストラクチャ
Intellect-2の場合、貢献者はトレーニングの実行に参加するために、TestNet Cryptoトークンを賭ける必要もあります。彼らが効果的な仕事に貢献した場合、彼らは自動的に報酬を受け取ります。そうでない場合、彼らのステーキングはカットされる可能性があります。このテストの実行中に実際の資金は関与していませんが、これはいくつかの暗号経済実験の初期形式を強調しています。この分野ではさらに多くの実験が必要であり、セキュリティとインセンティブメカニズムの観点から、暗号経済の適用にさらなる変化が予想されます。 Intellect-2に加えて、Prime Intellectは、次のことを含む、このレポートでカバーされていないいくつかの重要なプログラムを実行し続けています。
-
合成-2、推論タスクを生成および検証するための次世代フレームワーク。
-
Prime Collective Communications Library、効率的な断層耐性の集合通信操作(IPによる削減など)を実装し、ピアを同期させるための共有状態同期メカニズムを提供し、トレーニング中にいつでも仲間を去り、自動帯域幅を有するトポロジの最適化を可能にします。
-
Toplocの機能を継続的に強化して、スケーラブルで低コストの推論プルーフを有効にしてモデル出力を検証します。
-
Intellect2およびSynthetic1から学んだ教訓に基づいて、Prime Intellect ProtocolとCrypto Economyの改善
Pluralis Research
アレクサンダー・ロングは、ニューサウスウェールズ大学の博士号を取得したオーストラリアの機械学習研究者です。彼は、オープンソースモデルのトレーニングは、他の人がトレーニングするための基本モデルを提供するために、主要な人工知能ラボに過度に依存していると考えています。2023年4月、彼は別の道を開くことを目指して、Pluralis Researchを設立しました。
Pluralis Researchは、「プロトコル学習」と呼ばれるアプローチを使用して、分散型トレーニング問題を解決します。これは、「低帯域幅、異種多参加者、モデルの並列トレーニングと推論」と呼ばれています。Pluralisの主要な顕著な特徴は、その経済モデルです。これは、計算貢献を奨励し、トップのオープンソースソフトウェア研究者を引き付けるためのトレーニングモデルの貢献者に公平な利益を提供します。この経済モデルは、「Exlstractability」のコア属性に基づいています。つまり、トレーニング方法とモデルの並列性の使用に密接に関連する完全な重量セットを得ることができない参加者はいません。
モデルの並列性
Pluralisのトレーニングアーキテクチャは、モデルの並列性を利用しています。これは、初期トレーニングの実行でNous ResearchとPrime Intellectによって実装されたデータ並列性アプローチとは異なります。モデルのサイズが成長するにつれて、最も高度なGPU構成の1つであるH100ラックでさえ、完全なモデルを運ぶことは困難です。モデルの並列性は、複数のGPU上の単一モデルの個々のコンポーネントを分割することにより、この問題の解決策を提供します。
モデルの並列化には3つの主要な方法があります。
-
パイプライン並列性:モデルの層は、異なるGPUで分割されます。トレーニング中、データの各小さなバッチは、これらのGPUをパイプラインのように流れます。
-
テンソル(層)並列性:各GPUのレイヤー全体を提供する代わりに、各層内の重い数学が分離され、複数のGPUが単一層の作業を同時に共有できるようにします。
-
混合並列:実際には、大規模なモデルはさまざまな方法を使用して、パイプラインとテンソルを並行して、通常はデータと併用しています。
モデルの並列性は、最先端のスケールモデルのトレーニングを可能にし、低レベルのハードウェアが参加できるため、分散トレーニングの重要な進歩であり、誰もモデルウェイトの完全なセットにアクセスできないようにします。
プロトコル学習およびプロトコルモデル
プロトコル学習は、分散型トレーニング環境でモデルの所有権と収益化を使用するためのFrameworkです。 Pluralisは、プロトコル学習のフレームワークを構成する3つの重要な原則、つまり中心化、動機付け、Detrurtを強調しています。
Pluralisと他のプロジェクトの主な違いは、モデルの所有権に焦点を当てることです。モデルの値は主にその重量によるものであることを考えると、プロトコルモデル(プロトコルモデル)モデルトレーニングプロセス中に1人の参加者が完全な重みを持たないように、モデルの重みを分割してみてください。最終的に、これにより、トレーニングモデルへの各貢献者が特定の所有権を与え、モデルによって生み出される利点を共有します。
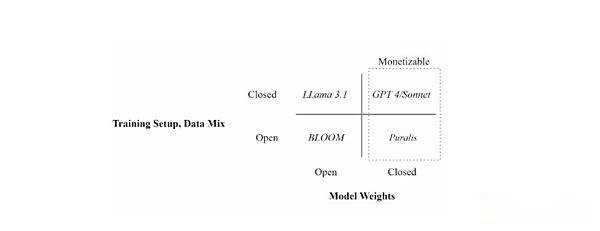 トレーニングの設定(オープンと囲まれたデータ)とモデルの重量の可用性(オープンvs.囲まれた)を使用して、さまざまな言語モデルを配置します
トレーニングの設定(オープンと囲まれたデータ)とモデルの重量の可用性(オープンvs.囲まれた)を使用して、さまざまな言語モデルを配置します
これは、以前の例と比較して、分散モデルの経済性に対する根本的に異なるアプローチです。他のプロジェクトは、特定のメトリック(通常は貢献される時間またはコンピューティングパワー)に基づいて、トレーニングサイクル中に貢献者に割り当てられる資金提供プールを提供することにより、貢献を奨励します。Pluralisの貢献者は、成功する可能性が最も高いと思われるモデルにのみリソースを捧げるように動機付けられています。パフォーマンスが低いモデルのトレーニングでは、コンピューティングパワー、エネルギー、時間を無駄にしても、パフォーマンスが低いモデルは収益を生み出しません。
これは、以前の方法とは異なります。第一に、モデルを訓練したい個人が、貢献者に支払うために初期資金を調達するために、モデルのトレーニングと開発のしきい値を下げる必要はありません。第二に、モデルデザイナーとコンピューティングプロバイダーの間のインセンティブメカニズムをより適切に調整します。両当事者は、モデルの最終バージョンが成功を確実にするために可能な限り完璧であることを望んでいるからです。これは、モデルトレーニングの専門化の出現の可能性も提供します。たとえば、より大きなリターン(ベンチャーキャピタリストと同様)を求めて、早期/実験モデルにコンピューティングサービスを提供するリスクを負担するトレーナーが増えている場合がありますが、コンピューティングプロバイダーは、成熟していて適用される可能性が高い(プライベートエクイティ投資家と同様)に焦点を当てています。
PMは、分散型トレーニングの収益化とインセンティブメカニズムの主要なブレークスルーを表している可能性がありますが、Pluralisは特定の実装方法について詳しく説明していません。アプローチの複雑さが高いことを考えると、まだ対処されていない問題には、モデルの所有権を割り当てる方法、利益の割り当て方法、モデルの将来のアップグレードまたはユースケースを管理する方法も含まれます。
分散型トレーニングイノベーション
経済的考慮事項に加えて、プロトコル学習は、大規模なAIモデルを訓練するための通信制限を備えた不均一なGPUネットワークを使用して、他の分散型トレーニングプログラムと同じコアチャレンジに直面しています。
今年6月、PluralisはMetaのLlama 3 Architectureに基づいて80億パラメーターLLMの成功したトレーニングを発表し、そのプロトコルモデルペーパーを公開しました。論文では、Pluralisは、モデルの並列トレーニングを実行するGPU間の通信オーバーヘッドを減らす方法を示しています。これは、各変圧器層を流れるシグナルを事前に選択された小さな部分空間に制限し、前後に圧縮して99%まで圧縮し、精度を損なうことなくネットワークトラフィックを100倍削減したり、重大なオーバーヘッドを追加したりすることでこれを行います。要するに、Pluralisは、以前の方法で必要な帯域幅の一部に同じ学習情報を圧縮する方法を見つけました。
これは最初の分散トレーニングの実行であり、モデル自体は、複製ではなく低帯域幅で接続されたノードに分散されます。チームは、1日あたり1秒あたり80メガバイトのホームインターネット接続でのみ接続する4つの大陸に広がるローエンドの消費者GPUの80億パラメーターでラマモデルのトレーニングに成功しました。論文では、Pluralisは、このモデルの収束が100 GB/sのデータセンタークラスターで実行されるのと同じくらい良いことを示しています。実際には、これは、大規模モデルの並行して分散化されたトレーニングが可能になることを意味します。
最後に、7月にICML(主要な人工知能会議の1つ)がパイプライン並列トレーニングのための非同期トレーニングに関するPluralisによる論文を受けました。パイプラインの並列トレーニングが高速データセンターではなくインターネットを介して実行されると、ノードは本質的にパイプラインに似ているため、通信ボトルネックにも面しています。これにより、勾配が時代遅れで遅延した情報伝達につながる可能性があります。紙に示されている分散型トレーニングフレームワーク、群れは、通常、トレーニングへの毎日のGPUの参加を妨げる2つの古典的なボトルネックを排除します。メモリ容量と緊密な同期。これらの2つのボトルネックを排除すると、利用可能なすべてのGPUをよりよく利用し、トレーニング時間を短縮し、コストを削減できます。これは、ボランティアベースのインフラストラクチャを分散する大きなモデルをスケーリングするために重要です。このプロセスを簡単に見るには、このビデオをPluralisでご覧ください。
先を見据えて、Pluralisは、誰でもすぐに参加できるリアルタイムトレーニングを開始する予定ですが、特定の日付は決定されていません。この打ち上げは、まだ発表されていない契約の側面、特に経済モデルと暗号インフラストラクチャをより深く理解することを提供します。
テンプラー
背景
テンプラーは2024年11月に開始され、両テンソールプロトコルサブネットに基づいて、インセンティブ主導の分散型AIタスク市場です。それは、ライセンスフリーのAIの事前トレーニングのためにグローバルGPUリソースをまとめることを目的とした実験フレームワークとして始まり、ビテンサーのトークン化されたインセンティブを通じて大規模なモデルトレーニングをアクセスしやすく、安全で回復力のあるものにすることを目的としています。
テンプラーは当初から、インターネット上でのLLM事前トレーニングの分散型トレーニングを調整するという課題を引き受けました。これは、遅延、帯域幅の制限、不均一なハードウェアが集中クラスターの効率を達成することを困難にし、集中クラスターのシームレスなGPU通信が大規模なモデルの迅速な反復を可能にするため、これは困難なタスクです。
最も重要なことは、テンプル騎士団は真にライセンスされた参加を優先し、コンピューティングリソースを持つ人なら誰でも承認、登録、またはゲートキーピングなしでAIトレーニングに参加できるようにすることです。この許可されたアプローチは、AI開発を民主化するというテンプルの使命にとって重要です。これは、画期的なAI機能がいくつかの集中型エンティティによって制御されず、世界中のオープンコラボレーションから出現できることを保証するためです。
テンプラー電車
テンプラーはデータを使用して並行してトレーニングを行い、2つの主な要因があります。
-
マイナー:これらの参加者はトレーニングタスクを実行しました。各マイナーは、最新のグローバルモデルと同期し、一意のデータシャードを取得し、前後のパスを使用してローカルでトレーニングを受け、カスタムCCLOCOオプティマイザー(以下で説明)を使用してグラデーションを圧縮し、勾配の更新を提出します。
-
Verifier:ValidatorはMinerが送信した更新をダウンロードして減圧し、モデルのローカルコピーに適用し、計算します損失の増加(モデルの改善度を測定する指標)。これらの増分は、テンプルのガントレットシステムを通じて鉱夫の貢献を獲得するために使用されます。
通信オーバーヘッドを減らすために、テンプル騎士団の研究チームは最初にブロック圧縮ディロコ(CCLOCO)を開発しました。Nousと同様に、CCLOCOはGoogle Dilocoフレームワークなどの通信効率の良いトレーニング技術を改善し、ノード間通信コストを桁違いに削減しながら、そのような方法によってしばしば引き起こされる損失を減らします。CCLOCOは、すべてのステップで完全な更新を送信する代わりに、設定された間隔で最も重要な変更のみを共有し、意味のあるデータが失われないように小さな実行カウントを維持します。このシステムは、報酬を受け取るために低遅延の更新を提供するように鉱夫を奨励する競争ベースのモデルを採用しています。報酬を受け取るには、マイナーは効率的なハードウェアを展開することにより、ネットワークに追いつく必要があります。この競争力のある構造は、十分なパフォーマンスを維持する参加者のみがトレーニングプロセスに参加できるようにするように設計されていますが、軽量の衛生チェックは著しく悪いまたは奇形の更新を除外します。8月、テンプラーは更新されたトレーニングアーキテクチャを正式にリリースし、Sparselocoと改名しました。
Verifiersは、テンプル騎士団のGauntlet Systemを使用して、観測されたモデル損失削減の寄与に基づいて、各マイナーのスキル評価を追跡および更新します。OpenSkillと呼ばれる技術により、効果的に更新され続ける高品質の鉱山労働者は、より高いスキル評価を受け、モデルの集約に対する影響を高め、より多くのTAOS(ビテンサーネットワークのネイティブトークン)を獲得します。評価が低い鉱山労働者は、集約プロセス中に破棄されます。スコアリングの後、最高の誓約を持つバリデーターは、トップマイナーからの更新を要約し、新しいグローバルモデルに署名し、ストレージに公開します。モデルが同期していない場合、マイナーはこのバージョンのモデルを使用して追いつくことができます。
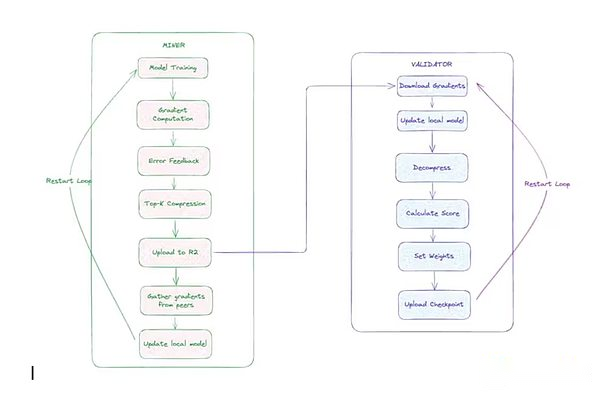 テンプルの分散型トレーニングアーキテクチャ
テンプルの分散型トレーニングアーキテクチャ
テンプラーはこれまでに3回のトレーニングを開始しました。テンプルI、テンプルII、テンプルIIIです。テンプルIは12億パラメーターを持つモデルで、世界中で約200のGPUを展開しています。テンプルIIは進行中で、80億パラメーターのモデルをトレーニングし、すぐに大規模なトレーニングを開始することを計画しています。テンプラーは現在、より小さなパラメーターを使用したトレーニングモデルに焦点を当てています。これは、分散型トレーニングアーキテクチャへのアップグレード(上記の)がより大きなモデルスケールにスケーリングする前に効果的に機能することを保証するために設計されたよく考えられた選択です。最適化戦略やスケジューリングから反復やインセンティブを調査することまで、これらのアイデアはパラメーターが小さい80億モデルで検証されており、チームが迅速かつコスト効果的に反復することができます。最近の進捗状況とトレーニングアーキテクチャの正式なリリースに続いて、チームは9月にテンプルターIIIを立ち上げました。これは、700億パラメーターとこれまでに分散型フィールドで最大のトレーニング前のモデルです。
タオとインセンティブメカニズム
テンプル騎士団の重要な特徴は、タオに結合したインセンティブモデルです。報酬は、モデルによって訓練されたスキル加重貢献に基づいて割り当てられます。ほとんどのプロトコル(Pluralis、nous、Prime Intellectなど)には、ランまたはプロトタイプがライセンスされていますが、テンプルはBittensorのリアルタイムネットワークで完全に実行されています。これにより、テンプル騎士団は、リアルタイムのライセンスのない経済層を分散型トレーニングフレームワークに統合した唯一のプロトコルになります。このリアルタイムの生産展開により、テンプル騎士団はリアルタイムトレーニングランシナリオでインフラストラクチャを反復することができます。
各Bittensorサブネットは、独自の「アルファ」トークンで実行されます。これは、価値を知覚するための報酬メカニズムとサブネットの市場シグナルとして機能します。テンプラーのアルファトークンはガンマと呼ばれます。アルファトークンは、外部市場で自由に取引することはできません。彼らは、自動化されたマーケットメーカー(AMM)を使用して、サブネット専用の流動性プールを通じてタオスとのみ交換できます。ユーザーはタオを誓約してガンマを取得したり、ガンマをタオとして引き換えたりすることができますが、他のサブネットからのアルファトークンと直接ガンマを交換することはできません。BittensorのDynamic Tao(DTAO)システムは、アルファトークンの市場価格を使用して、サブネット間の発行割り当てを決定します。ガンマの価格が他のアルファトークンと比較して上昇すると、これはテンプル騎士団の分散型トレーニング機能に対する市場の信頼が増加し、サブネットのTAO発行が増加したことを示しています。9月上旬の時点で、テンプル騎士団の毎日の発行は、TAOの循環の約4%を占め、TAOネットワークの128のサブネットのトップ6にランク付けされています。
サブネットの発行メカニズムは次のとおりです。12秒ブロックごとに、両節チェーンは、他のサブネットに対するサブネットアルファトークンの価格比に基づいて、TAOおよびAlphaトークンを流動性プールに発行します。各ブロックは、サブネットにサブネットに最大1つの完全なアルファトークン(初期発行率)を発行してサブネットの貢献者を奨励します。
このインセンティブは、経済的報酬を参加者が提供する価値にリンクすることにより、ビテンサーネットワークへの貢献を促進します。鉱夫は、モデルトレーニングや推論タスクなどの高品質のAI出力を提供し、バリッターからより高い評価を得るために、したがって出力のより多くのシェアを提供するように動機付けられています。Verifiers(およびそのステーカー)は、ネットワークの整合性を正確に評価および維持するための報酬を受け取ります。
アルファトークンの市場評価は、活動を浸し、より高い実用性を示すサブネットがより多くのタオの流入と発行を引き付けることができることを保証することによって決定され、それによりイノベーション、専門化、持続可能な開発を促進する競争環境を作り出します。サブネットの所有者は、効果的なメカニズムを設計し、貢献者を引き付ける動機付けの報酬の割合を受け取り、最終的には、グローバルな参加が集団情報の進捗を共同で促進できるようにする許可のない分散型AIエコシステムを構築します。
このメカニズムは、バリッターの誠実さを維持し、魔女の攻撃に抵抗し、陰謀を減らすなど、新しいインセンティブの課題をもたらします。ビテンサーサブネットは、バリデーターまたはマイナーとサブネットクリエイターの間の猫とマウスのゲームに悩まされていることが多く、前者はシステムでプレイしようとし、後者はそれらを妨害しようとしています。長期的には、これらの闘争は、サブネットの所有者が悪意のある俳優を克服する方法を学ぶため、システムを最も強力なものにする必要があります。
ジェンシン
Gensynは2022年2月に最初の合理化されたホワイトペーパーをリリースし、分散トレーニングの枠組みについて詳しく説明しました(Gensynは、昨年の最初の記事では、暗号化技術と人工知能の交差点を理解する最初の記事で取り上げられた唯一の分散トレーニングプロトコルです)。当時、プロトコルは主にAI関連のワークロードの検証に焦点を当てており、ユーザーはコンピューティングプロバイダーによって処理され、これらのリクエストが約束どおりに実行されたことを確認し、ネットワークにトレーニングリクエストを送信できました。
最初のビジョンはまた、応用機械学習(ML)研究を加速する必要性を強調しました。2023年、Gensynはこのビジョンに基づいて、特定のAIアプリケーションにサービスを提供するために世界中の機械学習コンピューティングリソースを取得するためのより広範なニーズを明確に提案しています。Gensynは、そのようなプロトコルが満たさなければならないフレームワークとして、幽霊のような原則を導入しました:普遍性、異質性、オーバーヘッド、スケーラビリティ、信頼性、およびレイテンシ。Gensynは、コンピューティングインフラストラクチャの構築に焦点を当てており、このコラボレーションは、コンピューティングを超えて他の主要なリソースへの正式な拡張を示しています。
Gensyn’s Coreは、トレーニングテクノロジースタックを、解釈、検証、コミュニケーション、および調整の4つの異なる部分に分割します。実行部品は、機械学習操作を実行できる世界の任意のデバイスでの操作を処理する責任があります。通信および調整セクションにより、デバイスは標準化された方法で情報を相互に送信できます。検証セクションでは、すべての操作を信頼せずに計算できるようにします。
実行 – rl swarm
このスタックでのGensynの最初の実装は、RL Swarmと呼ばれるトレーニングシステムです。これは、トレーニング後の強化学習のための分散型調整メカニズムです。
RL Swarmは、複数のコンピューティングプロバイダーが、許可された信頼最小化された環境で単一モデルのトレーニングに参加できるように設計されています。プロトコルは、回答、レビュー、解決という3段階のサイクルに基づいています。まず、各参加者はプロンプトに基づいてモデル出力(回答)を生成します。その後、他の参加者は、共有報酬機能と送信フィードバックを使用して出力を評価しました(レビュー)。最後に、これらのレビューを使用して、最良の回答を選択し、モデルの次のバージョン(解決)に含めるために使用されます。プロセス全体は、中央サーバーや信頼できる組織に依存することなく、ポイントツーポイントで行われます。
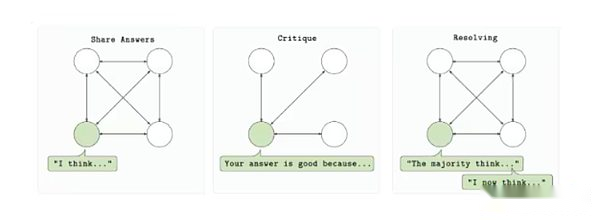 RLスウォームトレーニングループ
RLスウォームトレーニングループ
強化学習群れは、モデル後のトレーニングにおける補強学習の重要性の増加に基づいています。モデルがトレーニング前の段階でスケールの上限に達すると、強化学習は、大規模なデータセットを再訓練することなく、推論能力、命令コンプライアンス能力、および事実性を改善するメカニズムを提供します。Gensynのシステムは、強化学習ループをさまざまな役割に分解することにより、分散型環境でこの改善を達成します。各役割は独立して検証できます。重要なことに、それは誤りのない非同期実行を導入します。つまり、貢献者はオンラインであるか、参加するために完全に同期し続ける必要はありません。
また、本質的にモジュール式です。このシステムでは、特定のモデルアーキテクチャ、データ型、または報酬構造の使用を必要としないため、開発者は特定のユースケースに基づいてトレーニングループをカスタマイズできます。コーディングモデル、推論エージェント、特定の命令セットを備えたモデルのトレーニングであれ、RL Swarmは、分散型RLワークフローのための信頼できる大規模な操作フレームワークを提供します。
ヴェルデ
これまでのところ、分散トレーニングに関するこのレポートで最も議論されていない側面の1つは検証です。Gensynは、GPU市場のVerde Trustレイヤーを構築しています。Verdeを使用して、Gensynは新しい検証メカニズムを導入して、プロトコルユーザーが状況の反対側の人々を信頼できるようにしています。
各トレーニングまたは推論タスクは、アプリケーションによって決定された特定の数の独立したプロバイダーにスケジュールされます。出力が正確に一致する場合、タスクは受け入れられます。出力が異なる場合、審判プロトコルは、2つの軌跡が発散し、操作のみを再計算する最初のステップを見つけます。数字が審判と一致する当事者は支払いを保持し、相手はその利益を失います。
これを可能にしているのは、共通のニューラルネットワーク数学操作(マトリックス増殖、アクティブ化など)がGPUで固定された決定論的順序で実行される「再現可能な演算子」のライブラリであるRepopsです。ここでは決定論が重要です。それ以外の場合、両方のバリデーターは正しいものの、異なる結果を生成する可能性があります。そのため、正直なプロバイダーは同じ結果を少しずつ提供し、Verdeがゲームを正確性の証明と見なすことができます。審判は1つのマイクロステップのみを再生するため、追加のコストは、これらのプロセスで一般的に使用される完全な暗号化証明の10,000倍のオーバーヘッドではなく、わずか数パーセントポイントです。
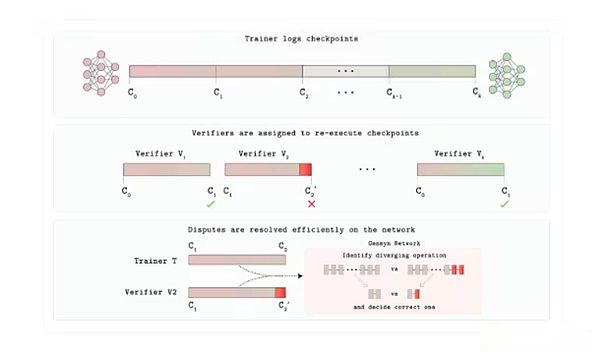
Verde検証プロトコルアーキテクチャ
8月、Gensynは、2つのコアコンポーネントを含む検証可能なAI評価システム、Verdeと再現可能なランタイムをリリースしました。それを示すために、Gensynは「Progressive Leave Game」を開始しました。このモデルは、情報の啓示中にAIモデルが複雑な質問への回答に賭けます。
裁判官は、AI/MLの信頼とスケーラビリティの問題を解決するため、重要です。信頼できるモデルの比較を可能にし、高リスク環境の透明性を改善し、独立した検証を可能にすることにより、バイアスまたは操作のリスクを軽減します。推論タスクに加えて、裁判官は、分散型の紛争解決や予測市場などの他のユースケースをサポートできます。これは、信頼できる分散AIコンピューティングインフラストラクチャを構築するというGensynの使命に適合します。最終的に、裁判官のようなツールは、繰り返しと説明責任を高めることができます。これは、AIがますます社会の中心にある時代に重要です。
コミュニケーションと調整:スキップパイプと多様性の専門家統合
スキップパイプは、複数のマシンをスライスするときに単一のメガモモデルが発生する帯域幅のボトルネックの問題に対処するためのGensynyによるソリューションです。前述のように、従来のパイプライントレーニングにより、各マイクロバッチはすべての層を順番に通過させるため、ノードが遅いとパイプラインの停滞が発生します。Skip-Pipeのスケジューラは、遅延を引き起こす可能性のあるレイヤーを動的にスキップまたは並べ替えることができ、ノードの半分が失敗した場合でも反復時間を最大55%削減し、可用性を維持できます。ノード間トラフィックを削減し、必要に応じてレイヤーを削除できるようにすることで、トレーナーは非常に大きなモデルを拡大して地理分散した低帯域幅GPUを拡大することができます。
多様化された専門家統合は、別の調整パズルを解決します。連続したクロストークを回避する強力な「ハイブリッドエキスパート」システムを構築する方法。Gensynの不均一なドメインエキスパート統合(HDEE)は、各専門家モデルを完全に独立してトレーニングし、最後にのみ合併します。驚くべきことに、同じ全体的なコンピューティング予算の下で、21のテストエリアのうち20の最終統合が統一されたベンチマークを上回りました。トレーニング中にマシン間で活性化機能の勾配または流れがないため、アイドルGPUはコンピューティングパワーに寄与できます。
スキップパイプとHDEは一緒になって、Gensynに効率的な通信ソリューションを提供します。プロトコルは、必要に応じて単一のモデル内で破片を破ることができます。または、従来使用されている完全な低レイテンシネットワークを運用せずに、独立コストの低いと並行して複数の小規模の専門家を並行して訓練できます。
テストネットワーク
3月、Gensynはカスタムイーサリアムロールアップにテストネットを展開しました。チームは、テストネットワークを徐々に更新する予定です。現在、ユーザーはGensynの3つの製品(RL Swarm、Blockassist、Judge)に参加できます。上記のように、RL Swarmを使用すると、ユーザーはRL後のトレーニングプロセスに参加できます。 8月に、チームは「これは、手動タグ付けやRLHFなしで人間の行動から直接エージェントを訓練する方法である、これは最初の大規模な学習のデモです。」ユーザーはMinecraftをダウンロードし、BlockAssistを使用してMinecraftモデルをトレーニングしてゲームをプレイできます。
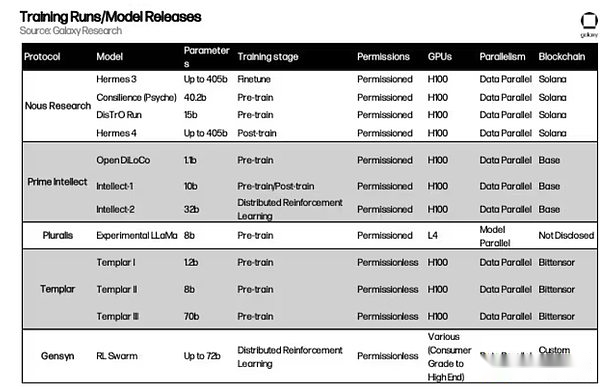
注意を払う価値のある他のプロジェクト
上記の章では、分散トレーニングを実現するために実装された主流のアーキテクチャの概要を説明します。ただし、新しいプロジェクトは次々と出現しています。分散トレーニングの分野での新しいプロジェクトを次に示します。
fortytwo:fortytwoはMonadブロックチェーン上に構築され、グループ推論(SLM)に焦点を当てています。複数の小言語モデル(SLM)は、ノードネットワークのクエリでコラボレーションし、ピアレビューされた出力を生成し、それにより精度と効率を改善します。このシステムは、アイドルラップトップなどの消費者グレードのハードウェアを利用して、集中AIなどの高価なGPUクラスターを使用する必要性を排除します。アーキテクチャには、専用モデルの合成データセットの生成など、分散型推論の実行とトレーニング機能が含まれます。このプロジェクトは、Monad Development Networkで利用可能になりました。
アンビエント:Ambientは、チェーン上の常にオンラインで自律的なAIエージェントをサポートするように設計された今後の「有用な作業証明」レイヤー-1ブロックチェーンであり、集中監督なしでは、継続的にタスクを実行し、許可されていないエコシステムで学習し、進化させることができます。ネットワークマイナーが協力して訓練および改善された単一のオープンソースモデルを採用し、貢献者はAIモデルのトレーニング、構築、および使用への貢献に対して報われます。Ambientは分散型の推論を強調していますが、特にプロキシの側面では、ネットワーク上のマイナーは、ネットワークをサポートする基礎となるモデルを継続的に更新する責任があります。Ambientは、新しいPルーフオブロギットメカニズムを使用します(このシステムでは、バリデーターは、マイナーの元の出力値(ロジッツと呼ばれる)をチェックすることにより、モデル計算が正しく実行されることを確認できます。プロジェクトはSolanaのフォーク上に構築されており、まだ正式に発売されていません。
フラワーラボ:Flower Labsは、Federated LearningのオープンソースフレームワークであるFlowerを開発しています。これは、生データを共有せずに分散型データソースを横切る共同AIモデルトレーニングをサポートし、モデルの更新を集約しながらプライバシーを保護します。 Flowerは、データの集中化に対処するために設立され、機関や個人が医療や金融などのローカルデータを使用してモデルをトレーニングできるようにし、パラメーターの安全な共有を通じてグローバルな改善に貢献しました。トークンの報酬と検証可能なコンピューティングを強調する暗号化とネイティブのプロトコルとは異なり、フラワーは、実際のアプリケーションのプライバシーを保護するコラボレーションを優先し、ブロックチェーンなしの規制業界に理想的な選択肢となっています。
マクロコスモス:MacrocosmosはBittensorネットワークで実行され、トレーニング前、微調整、データ収集、分散科学に焦点を当てた5つのサブネットをカバーする完全なAIモデル作成プロセスを開発しています。不均一、信頼性、ライセンスのないハードウェアに関するトレーニング前の大規模な言語モデルのためのインセンティブオーケストレーショントレーニングアーキテクチャ(IOTA)フレームワークを導入し、10億以上のパラメータートレーニングを開始し、より大きなパラメーターモデルに迅速にスケーリングする計画を立てています。
flock.io:Flockは、フェデレート学習とブロックチェーンインフラストラクチャを組み合わせて、モジュール式トークン臨時ネットワークでのプライバシー保護のための共同モデル開発を実現する分散型AIトレーニングエコシステムです。参加者は、モデル、データ、またはコンピューティングリソースに貢献し、貢献に比例したチェーン上の報酬を受け取ることができます。データのプライバシーを保護するために、プロトコルはフェデレーション学習を採用します。これにより、参加者は他の人と共有されていないローカルデータを使用してグローバルモデルをトレーニングできます。このセットアップでは、無関係なデータ(データ中毒と呼ばれることが多い)がモデルトレーニングに入るのを防ぐための追加の検証手順が必要ですが、複数のヘルスケアプロバイダーが非常に敏感な医療データを漏らすことなくグローバルモデルを訓練できるヘルスケアアプリケーションなどのユースケースの効果的なプロモーションアプローチです。
見通しとリスク
過去2年間、分散型トレーニングは、興味深い概念から実際の環境で実行される効果的なネットワークに変わりました。これらのプロジェクトはまだ予想される最終状態からはほど遠いものですが、分散型トレーニングへの道で意味のある進歩を遂げています。既存の分散型トレーニングパターンを振り返ると、いくつかの傾向が現れ始めています。
リアルタイムの概念実証はもはやファンタジーではありません。NousのConsilienceやPrime IntellectのIntellect-2などの初期の検証は、過去1年間にわたって生産規模の業務に参加しました。Opendilocoモデルやプロトコルモデルなどのブレークスルーにより、分散ネットワーク上の高性能AIが可能になり、費用対効果が高く、回復力があり、透明なモデル開発が促進されます。これらのネットワークは、数十または数百のGPUを調整し、トレーニング前および微調整中の中サイズのモデルをリアルタイムで調整しており、分散型トレーニングが閉じたデモンストレーションや一時的なハッカソンを超えていることを証明しています。これらのネットワークはまだ許可されていないネットワークではありませんが、この点でテンプル騎士団は際立っています。その成功は、分散型トレーニングが単に基礎となるテクノロジーが集中モデルのパフォーマンスに合わせて拡張できるように効果的であることを証明し、大規模なモデルを生産するために必要なGPUリソースを引き付けるという考えを強化しています。
モデルのスケールは拡大し続けていますが、ギャップは残ります。2024年から2025年にかけて、分散化されたプロジェクトのパラメーターモデルの数は、1桁から300億から400億から400億から400億に増加しました。ただし、主要なAIラボは、システムの数兆個のパラメーターをリリースしており、垂直に統合されたデータセンターと最先端のハードウェアで迅速に革新を続けています。分散型トレーニングは、特に集中型トレーニング方法がハイパースケールのデータセンターの数が増えているために制限の増加に直面しているため、世界中からトレーニングハードウェアを活用することにより、このギャップを埋めることができます。しかし、このギャップを閉じると、最適化装置のさらなるブレークスルーと、効率的な通信のための勾配圧縮が、世界規模を達成するためだけでなく、動作不能なインセンティブと検証層に依存します。
トレーニング後のワークフローは、懸念の分野になりつつあります。監視された微調整、RLHF、およびドメイン固有の補強学習には、包括的なトレーニングよりもはるかに低い同期帯域幅が必要です。Prime-RLやRL Swarmなどのフレームワークは、不安定な消費者レベルのノードで実行されており、貢献者はアイドルサイクルから利益を得ることができ、プロジェクトはカスタマイズされたモデルを迅速に商業化できます。RLが分散型トレーニングに適していることを考えると、分散型トレーニングプログラムの焦点としての重要性はますます顕著になる可能性があります。これにより、RL固有のトレーニングフレームワークを開始するチームの数が増えていることから明らかなように、RLトレーニングに適合する大規模な製品市場を最初に見つけることができます。
インセンティブと検証のメカニズムは、技術革新に遅れをとっています。インセンティブと検証のメカニズムは、まだ技術革新に遅れをとっています。特にテンプル騎士団は、リアルタイムのコイン報酬とチェーン上のペナルティおよび没収メカニズムを提供し、それにより悪い行動を効果的に抑制し、実際の環境でテストされています。他のプログラムは評判のスコア、証人の証明、または訓練の証明プログラムを実験していますが、これらのシステムはまだ未確認です。技術的な障壁が克服されたとしても、ガバナンスは同様に困難な課題を提示します。分散ネットワークは、暗号DAOで発生する繰り返しの非効率性なしにルールを策定し、規則を施行し、紛争を解決する方法を見つけなければなりません。技術的な障壁を解決することは、最初のステップにすぎません。長期的な実行可能性は、信頼できる検証メカニズム、効果的なガバナンスメカニズム、および魅力的な収益化/所有権構造と組み合わせることに依存し、実行される作業への信頼を確保し、スケールアップに必要な才能とリソースを引き付けることに依存します。
スタックはエンドツーエンドのパイプラインに融合しています。今日、ほとんどの主要なチームは、帯域幅の認識オプティマザー(デモ、ディストリビューション)、分散型コンピューティング交換(Prime Compute、Basilica)、およびオンチェーン調整層(Psyche、PM、Prime)を組み合わせています。最後に、モジュラーオープンパイプラインが形成されます。これは、集中型研究所のワークフローからデータから展開までのワークフローを反映していますが、単一の制御ポイントはありません。プロジェクトが独自のソリューションを直接統合せず、または統合されていても、データプロビジョニングプロトコル、GPU、推論市場、分散型ストレージバックボーンなど、分散トレーニングに必要な垂直に焦点を当てた他の暗号プロジェクトにアクセスできます。この周辺インフラストラクチャは、製品を強化し、集中型のピアとの競争をよりよく競うためにさらに活用できる分散型トレーニングプログラムのプラグアンドプレイコンポーネントを提供します。
リスク
ハードウェアとソフトウェアの最適化は絶えず変化する目標です。この分野では、中央研究所も拡大しています。NvidiaのBlackwell B200チップが発表されました。 MLPERFベンチマークでは、400億パラメーターまたは700億LORAの微調整を伴う事前トレーニングであろうと、そのトレーニングスループットは前世代の2.2〜2.6倍高速であり、巨人の時間とエネルギーコストを大幅に削減します。ソフトウェアに関しては、Pytorch 3.0とTensorflow 4.0がコンパイラレベルのグラフ融合と動的形状カーネルを導入して、同じチップのパフォーマンスをさらに向上させます。ハードウェアとソフトウェアの最適化の改善、または新しいトレーニングアーキテクチャの出現により、分散型トレーニングネットワークは、最速かつ最も高度なトレーニング方法に適応し、人材を引き付け、意味のあるモデル開発を刺激するために、継続的な更新に対応する必要があります。これにより、チームは、基礎となるハードウェアに関係なく、継続的な高性能を保証するソフトウェアと、これらのネットワークが基礎となるトレーニングアーキテクチャの変更に適応できるようにするソフトウェアスタックを開発する必要があります。
既存のエンタープライズオープンソースモデルは、分散化されたトレーニングと集中トレーニングの境界を曖昧にします。中央集中化されたAIラボのほとんどは、モデルを閉じたままにしているため、分散トレーニングが開放性、透明性、コミュニティガバナンスを確保する方法であることがさらに証明されています。DeepSeek、GPTオープンソースバージョン、Llamaなどの最近のプロジェクトは、より高いオープン性への移行を示していますが、この傾向が競争、規制、セキュリティの懸念の高まりの文脈で継続できるかどうかは不明です。重みが明らかにされたとしても、それらは元のラボの価値と選択を依然として反映しています。独立して訓練する能力は、適応性、異なる優先順位との調整、および既存のビジネスによってアクセスが制限されないようにするために重要です。
採用はまだ難しいです。多くのチームがこれを教えてくれます。分散型トレーニングプログラムに参加する人材の質は向上しましたが、AIラボをリードしている強力なリソースが不足しています(たとえば、Openaiは最近、従業員ごとに数百万ドルを「特別な報酬」に提供するか、メタが研究者を密猟するために提供した2億5,000万ドルのオファーが提供されました)。現在、分散型プロジェクトは、オープン性と独立性を大切にしているミッション主導の研究者を引き付け、同時に、より広いグローバルな才能プールと活気のあるオープンソースコミュニティから才能を引き出しています。ただし、規模で競争するためには、既存の企業に匹敵するトレーニングモデルと、貢献者にとって有意義な利点を生み出すインセンティブと収益化メカニズムを完成させることで、自分自身を証明する必要があります。ライセンスのないネットワーキングと暗号経済のインセンティブは独自の価値を提供しますが、分布にアクセスして持続可能な収益源を確立することができないため、セクターの長期的な成長が妨げられる可能性があります。
特に無修正モデルには、規制抵抗が存在します。分散トレーニングは、独自の規制上の課題に直面しています。デザイン的には、誰でもあらゆる種類のモデルを訓練できます。この開放性は確かに利点ですが、特にバイオセキュリティ、虚偽の情報、またはその他の乱用領域では、セキュリティリスクも高まります。EUと米国の政策立案者は、彼らが精査を強化することを示しています。EUの人工知能法は、高リスクの基本モデルに追加の義務を設定し、米国の機関はオープンシステムと潜在的な輸出スタイルの制御措置の制限を検討しています。有害な目的のために分散モデルを含むイベントは、包括的な規制を引き起こし、許可されたトレーニングの基本原則を脅かす可能性があります。
分布と収益化:分布は依然として大きな課題です。OpenAI、人類、Googleなどの主要なラボには、ブランド認知度、企業契約、クラウドプラットフォームの統合、消費者への直接アクセスを通じて、大きな流通の利点があります。対照的に、分散型トレーニングプログラムにはこれらの組み込みチャネルがなく、モデルを採用し、信頼を獲得し、実際のワークフローに組み込むために、より多くの努力を払う必要があります。暗号通貨は、暗号アプリケーション以外の統合においてまだ初期段階にあることを考えると(これは急速に変化していますが)、これはより困難な場合があります。非常に重要で未解決の質問は、これらの分散型トレーニングモデルを実際に使用する人です。高品質のオープンソースモデルがすでに存在し、新しい高度なモデルがリリースされると、他のモデルを抽出または調整することは特に困難ではありません。時間が経つにつれて、分散型トレーニングプログラムのオープンソースの性質は、分布の問題を解決するネットワーク効果を作成するはずです。ただし、分布の問題を解決できる場合でも、チームは製品の収益化の課題に直面します。現在、Pluralisのプロジェクトマネージャーは、これらの収益化の課題に最も直接対処しているようです。これは単なる暗号化X AIの問題ではなく、将来の課題を強調するより広範な暗号化の問題です。
結論は
分散型トレーニングは、抽象的な概念から、実際のグローバルトレーニングの運用を調整する効果的なネットワークに急速に進化しました。過去1年間、Nous、Prime Intellect、Pluralis、Templar、Gensynを含むプロジェクトは、分散型GPUを一緒に接続し、通信を効率的に圧縮し、実際の環境でのインセンティブの実験を開始することが可能であることを証明しています。これらの初期のデモンストレーションは、分散型トレーニングが理論を超えて進むことができることを示していますが、最先端のスケールで集中型の研究所と競合する道は依然として困難です。
分散化されたプロジェクトによって最終的に訓練された基本的なモデルが、今日の主要な人工知能研究所に匹敵する場合でも、最も厳しいテストに直面しています。アイデアの要求を超えた現実的な利点を証明します。これらの利点は、優れたアーキテクチャまたはやりがいのある貢献者の新しい所有権と収益化スキームを通じて内因的に明らかにされる可能性があります。あるいは、集中型の既存の参加者がウェイトを閉じたままにしたり、歓迎されないアライメントバイアスを注入したりすることでイノベーションを抑えようとする場合、これらの利点は外因性である場合があります。
技術の進歩に加えて、フィールドに対する態度も変化し始めています。1人の創設者は、過去1年間の主要なAI会議での感情の変化について説明しました。1年前、特に暗号通貨と併用する場合、分散型トレーニングにはほとんど興味がありませんでした。 6か月前、参加者は潜在的な問題を認識し始めましたが、大規模な実装の実現可能性について疑問を表明しました。また、ここ数ヶ月で、継続的な進捗がスケーラブルな分散トレーニングを可能にする可能性があるという認識が高まっています。この概念の進化は、分散トレーニングの勢いがテクノロジーの分野だけでなく、正当性の観点からも増加していることを示しています。
リスクは本物です。既存の企業は、ハードウェア、人材、流通の利点を依然として維持しています。規制審査は差し迫っています。インセンティブとガバナンスメカニズムは、大規模にテストされていません。ただし、その利点も同様に印象的です。分散型トレーニングは、代替のテクノロジーアーキテクチャだけでなく、人工知能を構築するという基本的な概念でもあります。ライセンス、グローバルな所有権、および少数の企業ではなく、多様なコミュニティと一致していません。オープン性がより速い反復、新しいアーキテクチャ、またはより包括的なガバナンスに変換できることを証明できるプロジェクトが1つだけであっても、暗号通貨と人工知能の画期的な瞬間をマークします。今後の道は長いですが、成功の核となる要素は今やしっかりと把握されています。







