
Huang RenxunがドバイのWGSでスピーチをしたとき、彼は「ソーシャルAI」という言葉を提案しました。それでは、どの主権AIが暗号コミュニティの興味と要求を満たすことができますか?
たぶん、それはWeb3+AIの形で構築する必要があります。
「暗号 + AIアプリケーションの約束と課題」では、AIと暗号化の相乗効果について語りますデータストレージと追跡を助長します。このコラボレーションは、Web3+AIの業界全体の状況を通じて実行されます。
ほとんどのWeb3 + AIプロジェクトは、ブロックチェーンテクノロジーを使用してAI業界のインフラストラクチャプロジェクトの建設問題を解決しており、いくつかのプロジェクトでAIを使用してWeb3アプリケーションの特定の問題を解決しています。
Web3 + AI業界の景観は、ほぼ次のとおりです。
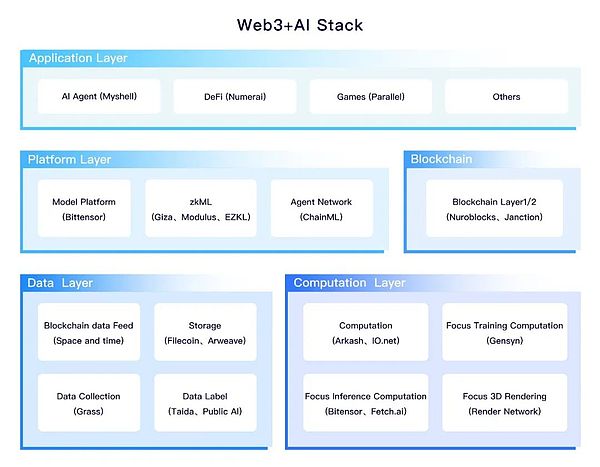
AIの生産とワークフローは、ほぼ次のとおりです。

これらのリンクでは、Web3とAIの組み合わせは、主に4つの側面に反映されています。
1。コンピューティングパワーレイヤー:コンピューティングパワーアセット化
過去2年間で、AIモデルのトレーニングに使用されるコンピューティング能力は指数関数的に増加し、基本的に四半期ごとに2倍になり、ムーアの法律をはるかに上回る速度で大幅に増加しています。この状況は、AIコンピューティングパワーの需要と供給に長期的な不均衡をもたらし、GPUなどのハードウェアの価格が急速に上昇し、コンピューティングパワーのコストが増加しました。
しかし同時に、市場には多数のミッドエンドおよびローエンドのコンピューティングパワーハードウェアもあり、中間およびローエンドのハードウェアのこの部分の単一のコンピューティングパワーは、高性能のニーズを満たしていない可能性があります。ただし、分散コンピューティングパワーネットワークがWeb3を介して構築され、分散型コンピューティングリソースネットワークをコンピューティングパワーリースと共有を通じて構築できる場合でも、多くのAIアプリケーションのニーズを満たすことができます。分散型アイドルコンピューティングパワーを使用するため、AIコンピューティングパワーのコストを大幅に削減できます。
コンピューティングパワーレイヤーセグメンテーションには次のものが含まれます。
-
一般的な分散コンピューティングパワー(Arkash、io.netなど);
-
AIトレーニングに使用される分散型コンピューティングパワー(Gensyn、Flock.ioなど);
-
AI推論に使用される分散型コンピューティングパワー(fetch.ai、双曲線など);
-
3Dレンダリングの分散コンピューティングパワー(レンダリングネットワークなど)。
Web3+AIのコンピューティングパワーアセットの中心的な利点は、分散型コンピューティングパワープロジェクトです。コンピューティングパワー。
2。データレイヤー:データ資産
データはAIの油と血です。Web3に依存していない場合、通常、大量のユーザーデータを持っているのは、通常のスタートアップが大量のデータを取得することは困難であり、AI業界のユーザーデータの価値はユーザーへのフィードバックではありません。Web3+AIを介して、データ収集、データアノテーション、分散データストレージなどのプロセスをより安く、透明性が高く、ユーザーにより有益にすることができます。
高品質のデータを収集することは、AIモデルトレーニングの前提条件であり、分散ネットワークを使用して、適切なトークンインセンティブメカニズムを組み合わせて、クラウドソーシングの収集方法を採用して、高品質で広範なデータを取得できます。
プロジェクトの目的によると、データプロジェクトには主に次のカテゴリが含まれています。
-
データ収集プロジェクト(草など);
-
データトランザクションプロジェクト(海洋プロトコルなど);
-
データ注釈項目(台湾、アラヤなど);
-
ブロックチェーンデータソースプロジェクト(スパイスAI、スペース、時間など);
-
分散型ストレージプロジェクト(Filecoin、Arweaveなど)。
データWeb3+AIプロジェクトは、コンピューティングパワーよりも標準化が困難であるため、トークン経済モデルを設計するプロセスでより困難です。
3。プラットフォームレイヤー:プラットフォーム値の資産
ほとんどのプラットフォームプロジェクトは、AI業界のさまざまなリソースの統合に焦点を当てて、顔を抱きしめます。データ、コンピューティングパワー、モデル、AI開発者、ブロックチェーンなど、さまざまなリソースやロールへのリンクを集約するプラットフォームを確立し、プラットフォームとしてさまざまなニーズをセンターとしてより便利に解決します。たとえば、Gizaは、データとモデルのブラックボックスが現在AIで一般的な問題であり、ZKやFHEなどのパスワードがWeb3を通じて採用されるため、機械学習の推論を信頼できるようにすることを目指して、包括的なZKML操作プラットフォームの構築に焦点を当てていますモデルの推論が実際に正しく実装されている場合は、遅かれ早かれ業界から求められます。
nuroblocks、Janctionなど、AIに焦点を合わせるlayer1/layer2もあります。コアの物語は、さまざまなコンピューティングパワー、データ、モデル、AI開発者、ノード、その他のリソースを接続し、一般的なコンポーネントと一般的なSDKをパッケージ化することにより、Web3+AIアプリケーションを支援することです。
また、このタイプのプラットフォームに基づいてエージェントネットワークのようなプラットフォームがあり、AIエージェントは、OLA、ChainMLなどのさまざまなアプリケーションシナリオ用に構築できます。
プラットフォームタイプのWeb3+AIプロジェクトは、主にトークンを使用してプラットフォームの価値をキャプチャし、すべての参加者が共同でそれを構築することを奨励します。0-1からプロジェクトを開始するプロセスに役立ちます。これにより、プロジェクトパーティーがコンピューティングパワー、データ、AI開発者コミュニティ、ノードなどのパートナーを見つけるのが難しいことが役立ちます。
4。アプリケーションレイヤー:AI値資産
以前のインフラストラクチャプロジェクトのほとんどは、ブロックチェーンテクノロジーを使用して、AI業界のインフラストラクチャプロジェクト構築の問題を解決しています。アプリケーションレイヤープロジェクトは、AIを使用してWeb3アプリケーションの問題を解決します。
たとえば、Vitalikはこの記事で2つの指示に言及しましたが、これは非常に意味があると思います。
まず、AIはWeb3参加者です。たとえば、AIはゲームのルールを迅速に理解し、DEXで最も効率的に完了することができます市場)、AIエージェントは、大量のデータ、知識、情報を広く受け入れ、モデルの分析的および予測機能を訓練し、スポーツなどのモデル推論を通じてユーザーが特定のイベントを予測できるように生産的な方法でユーザーに提供できます。イベント、大統領選挙など。
2つ目は、スケーラブルな分散型プライベートAIを作成することです。多くのユーザーは、AIのブラックボックスの問題を心配しているため、システムのバイアスを心配するか、AIテクノロジーを通じてユーザーを欺くためにお金を稼ぐ特定のDappを心配しています。基本的に、これは、ユーザーがAIのモデルトレーニングと推論プロセスのレビュー許可とガバナンス許可を持っていないためです。ただし、Web3プロジェクトのようにWeb3 AIを作成すると、コミュニティはこのAIにガバナンスの権利を分配しているため、より簡単に受け入れられる可能性があります。
これまで、Web3+AIアプリケーションレイヤーに高い天井がある白い馬プロジェクトはありませんでした。
要約します
Web3 + AIはまだ初期の頃であり、業界はこのトラックの開発見通しについて異なる見解を持っています。このトラックには注意を払い続けます。Web3とAIの組み合わせにより、集中化されたAIよりも価値のある製品が作成され、AIがよりコミュニティで「巨大なコントロール」と「独占」および「AIの共同統治」のラベルを取り除くことができることを願っています。ベースの方法。おそらく、より緊密な参加とガバナンスの過程で、人間はAIについてより多くの「a敬の念」と「恐怖」をより少ないでしょう。








