Auteur: Vitalik Buterin, @ Vitalik.eth;
Une stratégie pour une meilleure décentralisation dans les protocoles d’incitation est la punition pour la pertinence.Autrement dit, si un participant se comporte mal (y compris les accidents), plus d’autres participants (mesurés par l’ETH total) se comportent mal avec eux, plus ils seront élevés.La théorie soutient que si vous êtes un grand participant, toutes les erreurs que vous faites sont plus susceptibles d’être copiées dans toutes les «identités» que vous contrôlez, même si vous répandez vos jetons dans de nombreux comptes nominalement indépendants.
Cette technologie a été appliquée dans le mécanisme de la coupe Ethereum (et, sans doute, de la fuite inactive).Cependant, les incitations aux cas de bord qui ne se produisent que dans des attaques extrêmement spéciales peuvent ne jamais apparaître dans la pratique,Probablement pas assez pour inspirer la décentralisation.
Cet article suggère de prolonger des incitations à une anticorrélation similaires à des cas de défaillance plus «triviaux», tels que des preuves manquantes, que presque tous les validateurs font au moins occasionnellement.La théorie suggère que les plus grands empreneurs, y compris les individus riches et les pools d’allumage, exécuteront de nombreux validateurs sur la même connexion Internet ou même sur le même ordinateur physique, ce qui entraînera des échecs liés de manière disproportionnée.De tels gardiens peuvent toujours faire des paramètres physiques séparés pour chaque nœud, mais s’ils finissent par le faire, cela signifie que nous avons complètement éliminé les économies d’échelle de jalonnement.
Vérification de la solidité: les erreurs de différents validateurs dans le même « cluster » sont-elles plus susceptibles de corréler les uns avec les autres?
Nous pouvons vérifier cela en combinant deux ensembles de données: (i) les données de preuve des périodes récentes, montrant quels validateurs devraient être prouvés pendant chaque fente, et quels validateurs prouvés, et (ii) mapper l’ID de validateur à un cluster contenant de nombreux validateurs (tels en tant que « lido », « Coinbase », « Vitalik Buterin »).Tu peuxIci,IcietIciTrouvez le dépotoir de l’ancien, dansIciTrouvez le dépotoir de ce dernier.
Nous exécutons ensuite un script pour calculer le nombre total de défaillances courantes: deux instances de validateurs dans le même cluster sont affectées pour prouver dans le même créneau de temps et échouer dans cette créneau horaire.
Nous calculons également lesDéfaut commun:Si la défaillance est le résultat total d’une chance aléatoire, le nombre d’échecs communs qui devraient se produire.
Par exemple, supposons qu’il y ait 10 validateurs, l’une des tailles de cluster est 4, les autres sont indépendantes et que 3 validateurs échouent: deux sont à l’intérieur du cluster et un est à l’extérieur du cluster.
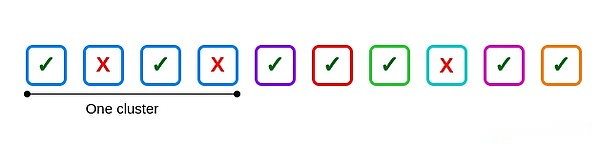
Voici un échec commun: les deuxième et quatrième validateurs dans le premier cluster.Si les quatre validateurs du cluster échouent, six défaillances courantes se produisent, une pour six paires possibles.
Mais combien d’échecs courants devraient être effectués?Il s’agit d’une question philosophique difficile.Plusieurs façons de répondre:
Pour chaque échec, supposons que le nombre d’échecs communs est égal au taux de défaillance des autres validateurs dans ce créneau multiplié par le nombre de validateurs dans le cluster et le coupe en deux pour compenser les calculs répétés.Pour l’exemple ci-dessus, 2/3 est donné.
Calculez le taux de défaillance global, carré et multipliez par [n * (n-1)] / 2 pour chaque cluster.Ceci est donné [(3/10) ^ 2] * 6 = 0,54
Redistribuez les échecs de chaque validateur au hasard sur toute son histoire.
Chaque méthode n’est pas parfaite.Les deux premières méthodes ne tiennent pas compte de différents clusters avec des paramètres de qualité différents.Dans le même temps, la dernière méthode ne tient pas compte des corrélations résultant de différents plages horaires avec différentes difficultés inhérentes: par exemple, le créneau horaire 8103681 a un grand nombre de preuves qui ne sont pas incluses dans un seul créneau horaire, peut-être parce que le Block a la publication est exceptionnellement tard.
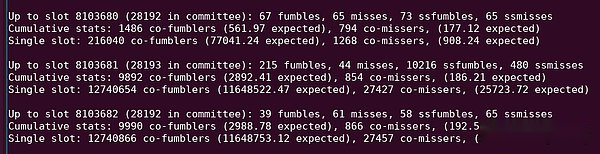
Voir « 10216 SSFumbles » dans cette sortie Python.
J’ai fini par mettre en œuvre trois méthodes: les deux premiers ci-dessus, et une approche plus complexe, j’ai comparé la « co-faculture réelle » avec « Fake Co-Failure »: chaque membre du cluster est remplacé par (pseudo) aléatoire La défaillance du validateur a un taux de défaillance similaire.
J’ai aussi clairement distinguéErreursetmanquer.Ma définition de ces termes est la suivante:
Erreurs: Lorsque le vérificateur manque la preuve dans la période en cours, mais prouve correctement dans la période précédente;
manquer: Lorsque le vérificateur a raté la preuve au cours de la période en cours et a également raté la preuve au cours de la période précédente.
L’objectif est de distinguer deux phénomènes distincts: (i) une défaillance du réseau pendant le fonctionnement normal, et (ii) une défaillance hors ligne ou à long terme.
Je fais également cette analyse sur deux ensembles de données en même temps: la date limite maximale et la date limite de machine à sous unique.Le premier ensemble de données traite le validateur comme un échec dans un délai que si la preuve n’est pas du tout incluse.Si la preuve n’est pas incluse dans un seul emplacement, le deuxième ensemble de données traite le validateur comme une défaillance.
Voici les résultats de mes deux premières méthodes de calcul des échecs communs attendus.Les SSFumbles et les SSMISS se réfèrent ici aux objectifs et aux erreurs qui utilisent un ensemble de données à guichet unique.
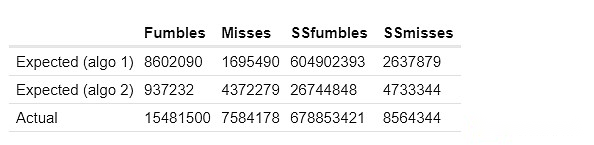
Pour la première approche, les comportements réels diffèrent car pour l’efficacité, un ensemble de données plus restreint est utilisé:

Les colonnes « attendues » et « faux cluster » montrent combien d’échecs courants « devraient » être dans le cluster en fonction des techniques ci-dessus.La colonne réelle montre combien d’échecs communs existent réellement.De manière cohérente, nous constatons des preuves solides de «trop d’échecs de corrélation» dans le cluster: deux validateurs dans le même cluster sont beaucoup plus susceptibles de manquer des preuves en même temps que deux validateurs dans différents grappes.
Comment l’appliquer aux règles de pénalité?
Je fais un argument simple: dans chaque créneau, laissez P diviser le nombre de créneaux actuellement manqués par la moyenne des 32 derniers emplacements.
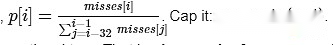
La pénalité pour la preuve de cette fente doit être proportionnelle à p.
C’est-à-dire,Par rapport à d’autres créneaux récents, la pénalité pour non prouvée comme proportionnelle au nombre de validateurs défaillants dans cette fente.
Il y a une bonne caractéristique de ce mécanisme, c’est-à-dire qu’il n’est pas facile d’attaquer: en tout cas, l’échec réduit vos pénalités et manipuler la moyenne est suffisant pour avoir un impact qui vous oblige à faire beaucoup d’échecs vous-même.
Maintenant, essayons de l’exécuter.Voici la pénalité totale pour les grands grappes, les grappes moyennes, les petits grappes et tous les validateurs (y compris les non-cluster):
Basique:Un point est déduit pour chaque erreur (c’est-à-dire similaire à la situation actuelle)
Basic_SS:Idem, mais besoin d’inclure une seule fente pour être considérée comme une raté
Dépassé:Utilisez le P calculé ci-dessus pour punir le point P
extra_ss:Utilisez le P calculé ci-dessus pour punir le point P, nécessitant une seule emplacement pour ne pas contenir

En utilisant le schéma « de base », les grands schémas ont environ 1,4 fois l’avantage sur les petits schémas (environ 1,2 fois dans des ensembles de données à guichet unique).En utilisant le schéma « supplémentaire », la valeur est tombée à environ 1,3 fois (environ 1,1 fois dans un ensemble de données à guichet unique).Grâce à plusieurs autres itérations, en utilisant des ensembles de données légèrement différents, le schéma de pénalité excédentaire rétrécit uniformément les avantages des « grandes personnes » sur les « petites personnes ».
Que se passe-t-il?
Il y a très peu d’échecs par emplacement: généralement seulement quelques dizaines.C’est beaucoup plus petit que presque n’importe quelle « grande part ».En fait, il est inférieur au nombre de validateurs actifs dans une seule fente que les grands Stakers (c’est-à-dire 1/32 de leur stock total).Si un grand staker exécute de nombreux nœuds sur le même ordinateur physique ou la même connexion Internet, tout échec pourrait affecter tous ses validateurs.
Cela signifie:Lorsque les grands validateurs montrent des échecs de preuve, ils modifieront à eux seul le taux de défaillance de la fente actuelle, ce qui augmentera leur pénalité.Les petits validateurs ne font pas cela.
En principe, les principaux actionnaires peuvent contourner ce programme de punition en plaçant chaque validateur sur une connexion Internet distincte.Mais cela sacrifie les économies d’échelle que les grandes parties prenantes peuvent réutiliser la même infrastructure physique.
Analyse plus approfondie
-
Recherchez d’autres stratégies pour confirmer l’ampleur de cet effet, où les validateurs dans le même cluster sont susceptibles d’échouer en même temps.
-
Essayez de trouver un schéma de récompense / punition idéal (mais toujours simple pour éviter le sur-ajustement et l’inutilisation) pour minimiser l’avantage moyen des grands validateurs par rapport aux petits validateurs.
-
Essayez de démontrer la nature de sécurité de ces schémas d’incitation, identifiant idéalement une « zone d’espace de conception » où le risque d’une attaque étrange (par exemple, stratégiquement hors ligne à un moment précis pour manipuler la moyenne) est trop cher et ne vaut pas la peine.
-
Cluster par emplacement géographique.Cela peut déterminer si le mécanisme peut également inspirer la décentralisation géographique.
-
Clustering via le logiciel client (exécution et balise).Cela peut déterminer si le mécanisme peut également inciter l’utilisation d’un petit nombre de clients.