Título original: Arquitecturas de pegamento y coprocesador
Autor: Vitalik, fundador de Ethereum;
Un agradecimiento especial a Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra y varios colaboradores de Flashbots por sus comentarios y comentarios.
Si analiza los cálculos intensivos en recursos que se están haciendo en el mundo moderno con detalles moderados, una característica que encontrará una y otra vez es que el cálculo se puede dividir en dos partes:
-
Una cantidad relativamente pequeña de «lógica comercial» compleja pero no muy intensiva computacionalmente intensiva;
-
Muchos «trabajos caros» intensivos pero altamente estructurados.
Estas dos formas de computación se manejan mejor de diferentes maneras: la primera, cuya arquitectura puede ser menos eficiente, pero debe ser muy versátil;
¿Cuáles son los ejemplos de este enfoque diferente en la práctica?
Primero, echemos un vistazo al entorno con el que estoy más familiarizado: Ethereum Virtual Machine (EVM).Aquí está el seguimiento de depuración Getth para mi reciente transacción Ethereum: actualice el hash IPFS de mi blog en ENS.La transacción consumió un total de 46924 gases y se puede clasificar de la siguiente manera:
-
Costo básico: 21,000
-
Datos de llamadas: 1.556
-
Evm Ejecución: 24,368
-
Código de operación de Sload: 6.400
-
Código de operación de Sstore: 10,100
-
Código de opción de registro: 2,149
-
Otros: 6.719

EVM Trace para la actualización de ESC.La penúltima columna es el consumo de gas.
La moraleja de esta historia es que la mayor parte de la ejecución (aproximadamente 73% si solo observa EVM, o alrededor del 85% si incluye la parte de costo básico que cubre el cálculo) se concentra en muy pocas operaciones costosas estructuradas: almacenar lectura y. Escribir, registros y cifrado (el costo básico incluye 3000 para la verificación de la firma de pago, y el EVM también incluye 272 para el hash de pago).El resto de la ejecución es «Lógica de negocios»: intercambie el bit CallData para extraer la identificación del registro que estoy intentando configurar y el hash al que lo configuré, etc.En las transferencias de tokens, esto incluirá la suma y el retoz de los saldos, en aplicaciones más avanzadas, esto puede incluir el bucle, etc.
En EVM, estas dos formas de ejecución se procesan de diferentes maneras.La lógica de negocios avanzada está escrita en idiomas más avanzados, generalmente solidez, que se puede compilar a EVM.El trabajo costoso todavía se desencadena por los códigos de operación EVM (SLOAD, etc.), pero más del 99% de los cálculos reales se realizan en módulos dedicados escritos directamente dentro del código del cliente (o incluso bibliotecas).
Para fortalecer nuestra comprensión de este patrón, exploremos en otro contexto: código de IA escrito en Python usando antorcha.
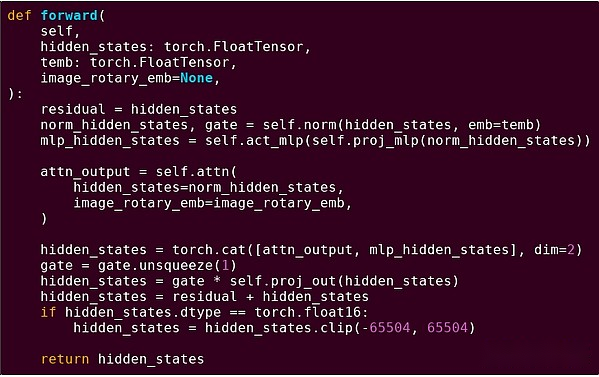
Entrega hacia adelante de un bloque del modelo Transformer
¿Qué vimos aquí?Vemos una cantidad relativamente pequeña de «lógica comercial» escrita en Python que describe la estructura de las operaciones que se realizan.En aplicaciones prácticas, hay otro tipo de lógica comercial que determina detalles como cómo obtener la entrada y qué operaciones se realizan en la salida.Sin embargo, si profundizamos en cada operación individual en sí (los pasos dentro de Self.norm, Torch.cat, +, *, self.attn …), vemos cálculos vectorizados: la misma operación calcula una gran cantidad de cálculos paralelos en una gran número de casos valor.Similar al primer ejemplo, una pequeña porción de los cálculos se utilizan para la lógica empresarial, y la mayoría se utilizan para realizar grandes operaciones de matriz estructurada y vectores; de hecho, la mayoría son solo multiplicación de matriz.
Al igual que en el ejemplo de EVM, estos dos tipos de trabajo se manejan de dos maneras diferentes.El código lógico de negocios avanzado está escrito en Python, un lenguaje altamente general y flexible, pero también muy lento, y simplemente aceptamos ineficiencia porque solo implica una pequeña parte del costo total de computación.Mientras tanto, las operaciones intensivas se escriben en un código altamente optimizado, generalmente código CUDA que se ejecuta en la GPU.Incluso estamos comenzando cada vez más a ver que el razonamiento de LLM ocurre en los ASIC.
La criptografía programable moderna, como Snark, una vez más sigue un patrón similar en ambos niveles.Primero, el Prover se puede escribir en un lenguaje de alto nivel, donde el trabajo pesado se realiza a través de operaciones de vectorización, al igual que el ejemplo de IA anterior.Mi código circular Stark aquí muestra esto.En segundo lugar, los programas ejecutados dentro de la criptografía se pueden escribir de una manera que se divide entre la lógica comercial común y el trabajo costoso altamente estructurado.
Para comprender cómo funciona, podemos echar un vistazo a una de las últimas tendencias que Stark probó.Para el general y fácil de usar, el equipo está construyendo cada vez más a los sartos retrocesos para máquinas virtuales mínimas ampliamente adoptadas como RISC-V.Cualquier programa que deba probar la ejecución puede compilarse en RISC-V, y el comprobante puede probar la ejecución de RISC-V del código.
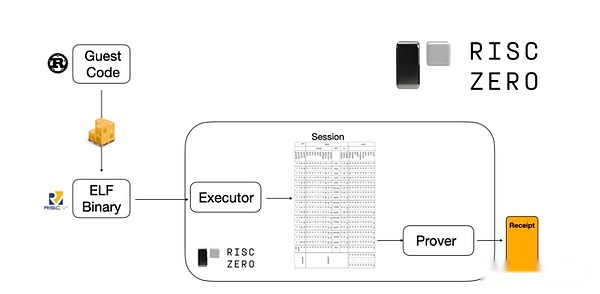
Gráficos de la documentación de Risczero
Esto es muy conveniente: significa que solo necesitamos escribir una lógica de prueba una vez, y a partir de entonces, cualquier programa que necesite pruebas se puede escribir en cualquier lenguaje de programación «tradicional» (como RiskZero es compatible con el óxido).Sin embargo, hay un problema: este enfoque puede incurrir en muchas sobrecargas.El cifrado programable ya es muy costoso;Por lo tanto, a los desarrolladores se les ocurrió un truco: identifique las operaciones costosas específicas (generalmente hashing y firmas) que componen la mayoría de los cálculos y luego crean módulos especializados para demostrarlos de manera muy eficiente.Luego puede obtener lo mejor de ambos mundos simplemente combinando el sistema de prueba RISC-V ineficiente pero universal con el sistema de prueba eficiente pero profesional.
El cifrado programable que no sea ZK-SNARK, como la computación múltiple (MPC) y el cifrado totalmente homomórfico (FHE), puede optimizarse utilizando métodos similares.
En general, ¿cuál es el fenómeno?
La computación moderna sigue cada vez más lo que yo llamo la arquitectura de la unión y el coprocesador: tiene algunos componentes centrales de «unión» que son altamente versátiles pero ineficientes y responsables de uno o más componentes del coprocesador.
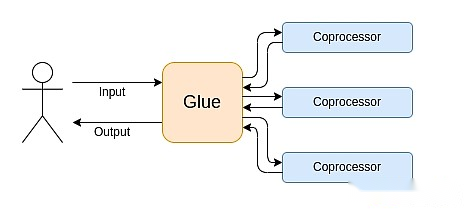
Esta es una simplificación: en la práctica, la curva de compensación entre eficiencia y universalidad es casi siempre más de dos niveles.Las GPU y otros chips comúnmente conocidos como «coprocesadores» en la industria son menos versátiles que las CPU, pero más versátiles que los ASIC.Las compensaciones sobre el grado de especialización son complejas, dependiendo de las predicciones e intuición sobre las cuales partes del algoritmo permanecerán sin cambios en cinco años y qué partes cambiarán en seis meses.En la arquitectura a prueba de ZK, a menudo vemos especializaciones similares de múltiples capas.Pero para un modelo de mente amplia, es suficiente considerar dos niveles.Hay situaciones similares en muchos campos informáticos:
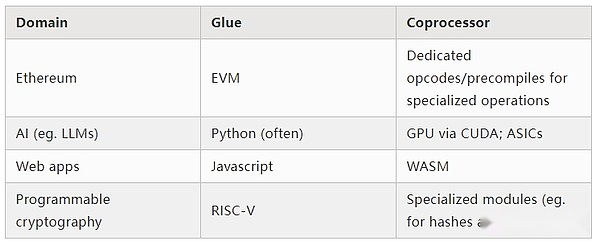
A juzgar por los ejemplos anteriores, los cálculos pueden dividirse, por supuesto, de esta manera, lo que parece ser una ley natural.De hecho, puede encontrar ejemplos de especialización computacional durante décadas.Sin embargo, creo que esta separación está aumentando.Creo que hay una razón para esto:
Hemos alcanzado recientemente el límite de mejora de la velocidad del reloj de la CPU, por lo que solo se pueden lograr mayores beneficios mediante la paralelización.Sin embargo, la paralelización es difícil de razonar, por lo que a menudo es más práctico que los desarrolladores continúen razonándose en secuencia y la paralelización ocurre en el backend, y lo empaqueta en un módulo dedicado construido para una operación específica.
La informática se ha vuelto tan rápido que el costo computacional de la lógica comercial se ha vuelto verdaderamente insignificante.En este mundo, tiene sentido optimizar las máquinas virtuales que se ejecutan en la lógica empresarial para lograr objetivos distintos de la eficiencia informática: amigable para desarrolladores, familiaridad, seguridad y otros objetivos similares.Mientras tanto, los módulos dedicados de «coprocesador» pueden continuar siendo diseñados para la eficiencia y obtener su seguridad y amigable para desarrolladores de su relativamente simple «interfaz» con adhesivos.
Lo que es la operación más importante y costosa es volverse más claro.Esto es más obvio en la criptografía, donde los tipos de operaciones costosas específicas tienen más probabilidades de usarse: operaciones de módulo, combinación lineal de curvas elípticas (también conocidas como multiplicación multiscalar), transformación rápida de Fourier, etc.Esta situación también se ha vuelto cada vez más obvia en la inteligencia artificial, y la mayoría de los cálculos son «principalmente multiplicación de matriz» (aunque diferentes niveles de precisión).Tendencias similares han surgido en otras áreas.Hay muchas menos incógnitas en los cálculos (intensivos en computación) que hace 20 años.
¿qué significa eso?
Un punto clave es que el gluer (pegamento) debe optimizarse para que sea un buen pegamento (pegamento), y el coprocesador también debe optimizarse para ser un buen coprocesador.Podemos explorar el significado de esto en varias áreas clave.
EVM
Las máquinas virtuales blockchain (como EVM) no necesitan ser eficientes, solo necesitan estar familiarizadas con ellas.Simplemente agregue el coprocesador correcto (también conocido como «Precompilado»), y el cálculo en una VM ineficiente puede ser tan eficiente como el cálculo en una VM eficiente nativa.Por ejemplo, la sobrecarga incurrida por el registro de 256 bits de EVM es relativamente pequeña, mientras que la familiaridad de EVM y los beneficios del ecosistema de desarrolladores existente son enormes y duraderos.Los equipos de desarrollo que optimizan EVMS incluso descubrieron que la falta de paralelización a menudo no es una barrera importante para la escalabilidad.
La mejor manera de mejorar EVM podría ser (i) agregar mejores códigos de operación precompilados o dedicados, como alguna combinación de EVM-Max y SIMD, y (ii) mejorar los diseños de almacenamiento, como los cambios en el árbol de Verkle, como efecto secundario, reduce en gran medida El costo de acceder a las ranuras de almacenamiento adyacentes.
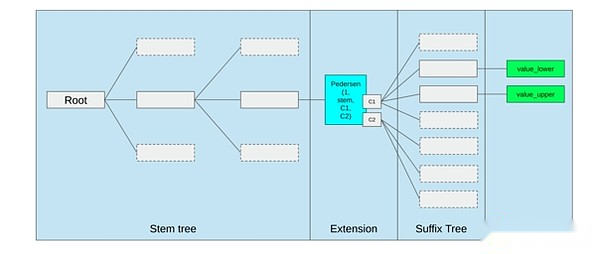
Optimización de almacenamiento en la propuesta de árbol de Ethereum Verkle, junte las llaves de almacenamiento adyacentes y ajuste los costos de gas para reflejar esto.Las optimizaciones como esta, junto con una mejor precompilación, pueden ser más importantes que ajustar el EVM en sí.
Información segura y hardware abierto
Uno de los desafíos para mejorar la seguridad informática moderna a nivel de hardware es su naturaleza demasiado compleja y patentada: el chip está diseñado para ser eficiente, lo que requiere una optimización patentada.La puerta trasera está fácilmente oculta, y las vulnerabilidades de los canales laterales se descubren constantemente.
Las personas continúan trabajando para promover alternativas más abiertas y más seguras desde múltiples perspectivas.Algunas computadoras se realizan cada vez más en un entorno de ejecución confiable, incluso en el teléfono del usuario, que ha mejorado la seguridad del usuario.La acción para impulsar más hardware de consumo de código abierto continúa, con algunas victorias recientes como las computadoras portátiles RISC-V que ejecutan Ubuntu.
La computadora portátil Risc-V ejecutando Debian
Sin embargo, la eficiencia sigue siendo un problema.El autor del artículo vinculado anteriormente escribió:
Es poco probable que los diseños de chips de código abierto más nuevos, como RISC-V, sean comparables con la tecnología de procesadores que ha existido y se ha mejorado durante décadas.Siempre hay un punto de partida para el progreso.
Más ideas paranoicas, como este diseño para construir computadoras RISC-V en FPGA, se enfrenta a una mayor sobrecarga.Pero, ¿qué pasa si el pegamento y la arquitectura del coprocesador significa que esta sobrecarga no es realmente importante?Si aceptamos chips abiertos y seguros, serán más lentos que los chips propietarios, si es necesario, incluso abandonamos las optimizaciones comunes, como la ejecución especulativa y la predicción de las ramas, pero trate de compensar esto agregando (propietarios, si es necesario) módulos ASIC que se usan para el ¿Lo más que sucede con los tipos específicos intensivos de cálculos?La computación sensible se puede hacer en el «chip principal» que se optimizará para la seguridad, el diseño de código abierto y la resistencia al canal lateral.Se realizarán cálculos más intensivos (por ejemplo, AI, AI) en el módulo ASIC, que aprenderá menos información sobre el cálculo que se está realizando (posiblemente, a través de la cegación de cifrado y, en algunos casos, incluso cero información).
Criptografía
Otro punto clave es que todo esto es muy optimista sobre la criptografía, especialmente la criptografía programable, que se convierte en la corriente principal.Hemos visto algunas implementaciones hiperoptimizadas específicas de informática altamente estructurada en sarcases, MPC y otras configuraciones: algunas funciones hash son solo unos pocos cientos de veces más caras que ejecutar la computación directamente, y la IA (principalmente multiplicación de matriz) también es gastos generales. muy bajo.Otras mejoras como GKR pueden reducir aún más este nivel.Una ejecución de VM completamente general, especialmente cuando se ejecuta en un intérprete RISC-V, puede continuar incurriendo aproximadamente diez mil veces en la sobrecarga, pero por las razones descritas en este artículo, no importa: solo use tecnologías eficientes y dedicadas para manejar para manejar Las partes más intensivas del cálculo, la sobrecarga total es controlable.
Un gráfico simplificado de MPC dedicado a la multiplicación de matriz, que es el componente más grande en la inferencia del modelo AI.Consulte este artículo para obtener más detalles, incluyendo cómo mantener privados modelos e entradas.
Una excepción a la idea de que «las capas pegadas solo necesitan ser familiares, no eficientes» es la latencia y, en menor medida, el ancho de banda de datos.Si el cálculo involucra docenas de operaciones pesadas repetidas en los mismos datos (como la criptografía e inteligencia artificial), cualquier retraso causado por el pegamento ineficiente puede convertirse en el cuello de botella principal en tiempo de ejecución.Por lo tanto, la capa pegada también tiene requisitos de eficiencia, aunque estos requisitos son más específicos.
en conclusión
En general, creo que las tendencias anteriores son muy positivas desde múltiples perspectivas.Primero, es una forma razonable de maximizar la eficiencia de la computación mientras se mantiene la amistad del desarrollador, y poder obtener más de ambos es bueno para todos.En particular, al especializarse en el lado del cliente para mejorar la eficiencia, mejora nuestra capacidad de ejecutar cálculos sensibles y de alto rendimiento (por ejemplo, ZK Proof, LLM Railoning) localmente en el hardware de los usuarios.En segundo lugar, crea una gran oportunidad para garantizar que la búsqueda de la eficiencia no dañe otros valores, especialmente la seguridad, la apertura y la simplicidad: Seguridad y apertura del canal lateral en hardware de la computadora, reduciendo la complejidad del circuito en ZK-SNARK y reduciendo la complejidad en máquinas virtuales.Históricamente, la búsqueda de la eficiencia ha llevado a estos otros factores a quedarse en segundo plano.Con el pegamento y la arquitectura del coprocesador, ya no es necesario.Parte de la máquina optimiza la eficiencia, y la otra parte optimiza la versatilidad y otros valores, y los dos trabajan juntos.
Esta tendencia también es muy beneficiosa para la criptografía, que es un ejemplo importante de «computación estructurada costosa» que ha acelerado el desarrollo de esta tendencia.Esto agrega otra oportunidad para mejorar la seguridad.En el mundo blockchain, también son posibles mejoras de seguridad: podemos preocuparnos menos por la optimización de las máquinas virtuales y centrarnos más en optimizar la precompilación y otras funciones de coexistir con máquinas virtuales.
En tercer lugar, esta tendencia brinda oportunidades para que participen los participantes más pequeños y más nuevos.Si los cálculos se vuelven menos simples y más modulares, esto reducirá en gran medida la barrera de entrada.Incluso con un tipo de ASIC computacional, es posible marcar la diferencia.Lo mismo es cierto en el campo de prueba de ZK y en la optimización EVM.Escribir código con eficiencia casi frontier se vuelve más fácil y más fácil de acceder.La auditoría y la verificación formal de dicho código se vuelven más fácil y más fácil de acceder.Finalmente, como estos campos informáticos muy diferentes están convergiendo a algunos patrones comunes, hay más espacio para la colaboración y el aprendizaje entre ellos.