Originaltitel: Kleber- und Koprozessorarchitekturen
Autor: Vitalik, Gründer von Ethereum;
Besonderer Dank geht an Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra und verschiedene Flashbots -Mitwirkende für ihr Feedback und Kommentare.
Wenn Sie ressourcenintensive Berechnungen analysieren, die in der modernen Welt mit moderaten Details durchgeführt werden, ist eine Funktion, die Sie immer wieder finden, dass die Berechnung in zwei Teile unterteilt werden kann:
-
Eine relativ kleine Menge komplexer, aber nicht sehr rechnerisch intensiver „Geschäftslogik“;
-
Viele intensive, aber hoch strukturierte „teure Jobs“.
Diese beiden Formen des Computers werden am besten auf unterschiedliche Weise behandelt: Ersteres, dessen Architektur weniger effizient ist, aber sehr vielseitig sein muss;
Was sind die Beispiele für diesen anderen Ansatz in der Praxis?
Schauen wir uns zunächst die Umgebung an, mit der ich am besten vertraut bin: Ethereum Virtual Machine (EVM).Hier ist das Getth -Debug -Tracking für meine jüngste Ethereum -Transaktion: Aktualisieren Sie den IPFS -Hash meines Blogs auf Ens.Die Transaktion verbrauchte insgesamt 46924 Gase und kann wie folgt klassifiziert werden:
-
Grundkosten: 21.000
-
Rufen Sie Daten an: 1.556
-
EVM -Ausführung: 24.368
-
Sload Opcode: 6.400
-
SSTORE OPCODE: 10.100
-
Log Opcode: 2.149
-
Andere: 6.719

EVM Trace für ENS Hash -Update.Die vorletzte Säule ist der Gasverbrauch.
Die Moral dieser Geschichte ist, dass die meiste Ausführung (ca. 73%, wenn Sie sich nur EVM ansehen, oder etwa 85%, wenn Sie den Grundkostenteil für die Berechnung einbeziehen) in sehr wenigen strukturierten teuren Vorgängen konzentriert: Lesen und Schreiben speichern, Protokolle und Verschlüsselung (die Grundkosten umfassen 3000 für die Überprüfung der Zahlungssignatur und die EVM auch 272 für Zahlungs -Hash).Der Rest der Ausführung ist „Geschäftslogik“: Tauschen Sie das Calldata -Bit aus, um die ID des Datensatzes zu extrahieren, die ich festlegen möchte, und den Hash, auf den ich sie festlegt, usw.In Token -Transfers umfasst dies das Hinzufügen und Abziehen von Balancen, in fortgeschritteneren Anwendungen, dies kann das Schleifen und so weiter umfassen.
In EVM werden diese beiden Ausführungsformen auf unterschiedliche Weise verarbeitet.Advanced Business Logic ist in fortgeschritteneren Sprachen geschrieben, normalerweise Solidität, die mit EVM zusammengestellt werden können.Teure Arbeiten werden weiterhin durch EVM -Opcodes (Sload usw.) ausgelöst, aber mehr als 99% der tatsächlichen Berechnungen werden in dedizierten Modulen durchgeführt, die direkt in den Client -Code (oder sogar Bibliotheken) geschrieben wurden.
Um unser Verständnis dieses Musters zu stärken, lassen Sie es uns in einem anderen Kontext untersuchen: AI -Code in Python mit Taschenlampe.
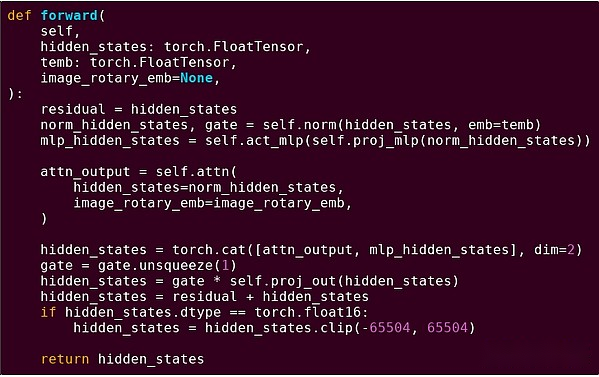
Vorwärtsabgabe eines Blocks des Transformatormodells
Was haben wir hier gesehen?Wir sehen eine relativ kleine Menge an „Geschäftslogik“ in Python, die die Struktur der durchgeführten Operationen beschreibt.In praktischen Anwendungen gibt es eine andere Art von Geschäftslogik, die Details festlegt, z. B. wie die Eingaben erhalten und welche Vorgänge für die Ausgabe ausgeführt werden.Wenn wir uns jedoch in jede einzelne Operation selbst graben (die Schritte in Self.Norm, Torch.cat, +, *, Self.attn…) sehen wir vektorisierte Berechnungen: Der gleiche Betrieb berechnet eine große Anzahl paralleler Berechnungen in einem großen Berechnungen Anzahl der Fälle.Ähnlich wie beim ersten Beispiel wird ein kleiner Teil der Berechnungen für die Geschäftslogik verwendet, und die meisten werden verwendet, um große strukturierte Matrix- und Vektoroperationen durchzuführen. Tatsächlich sind die meisten nur eine Matrixmultiplikation.
Genau wie im EVM -Beispiel werden diese beiden Arten von Arbeiten auf zwei verschiedene Arten behandelt.Advanced Business Logic Code ist in Python geschrieben, einer sehr allgemeinen und flexiblen Sprache, aber auch sehr langsam, und wir akzeptieren nur Ineffizienz, da er nur einen kleinen Teil der gesamten Rechenkosten umfasst.In der Zwischenzeit werden intensive Operationen in stark optimiertem Code geschrieben, in der normalerweise der CUDA -Code auf der GPU ausgeführt wird.Wir beginnen sogar zunehmend zu sehen, dass LLM -Argumentation auf ASICs stattfindet.
Die moderne programmierbare Kryptographie wie Snark folgt erneut einem ähnlichen Muster auf beiden Ebenen.Erstens kann der Prover in einer hochrangigen Sprache geschrieben werden, in der die schwere Arbeit durch Vektorisierungsoperationen wie das obige KI-Beispiel erledigt wird.Mein kreisförmiger Stark -Code hier zeigt dies.Zweitens können Programme, die in der Kryptographie ausgeführt wurden, selbst auf eine Weise geschrieben werden, die sich zwischen gemeinsame Geschäftslogik und hochstrukturierte teure Arbeit unterscheidet.
Um zu verstehen, wie es funktioniert, können wir uns einen der neuesten Trends, die Stark Provenen bewirbt, ansehen.Für allgemeine und einfach zu bedienende Nutzung baut das Team zunehmend Stark-Prover für weit verbreitete minimale virtuelle Maschinen wie RISC-V auf.Jedes Programm, das nachweisen muss, dass die Ausführung in RISC-V zusammengestellt werden kann, kann dann die RISC-V-Ausführung des Codes nachweisen.
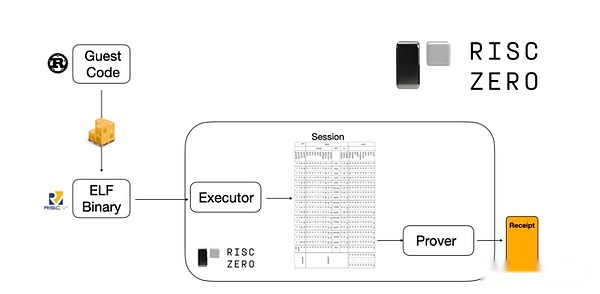
Diagramme aus Risczero -Dokumentation
Dies ist sehr bequem: Dies bedeutet, dass wir nur einmal eine Proof -Logik schreiben müssen, und von da an in jedem Programm, das Beweise benötigt, kann in jeder „traditionellen“ Programmiersprache geschrieben werden (wie Riskarero unterstützt Rost).Es gibt jedoch ein Problem: Dieser Ansatz kann viel Aufwand verursachen.Die programmierbare Verschlüsselung ist bereits sehr teuer.Entwickler haben also einen Trick entwickelt: Identifizieren Sie die spezifischen teuren Vorgänge (normalerweise Hashing und Signaturen), die die meisten Berechnungen ausmachen, und erstellen Sie dann spezielle Module, um sie sehr effizient zu beweisen.Dann können Sie das Beste aus beiden Welten erhalten, indem Sie einfach das ineffiziente, aber universelle RISC-V-Proof-System mit dem effizienten, aber professionellen Proof-System kombinieren.
Eine andere programmierbare Verschlüsselung als ZK-Snark, wie z. B. Multi-Party Computing (MPC) und vollständig homomorphe Verschlüsselung (FHE), kann mit ähnlichen Methoden optimiert werden.
Was ist insgesamt das Phänomen?
Das moderne Computer folgt zunehmend dem, was ich Bonding und Coprozessorarchitektur bezeichne: Sie haben einige zentrale „Bonding“ -Komponenten, die sehr vielseitig, aber für eine oder mehrere Koprozessorenkomponenten verantwortlich sind.
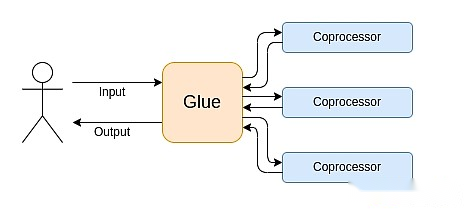
Dies ist eine Vereinfachung: In der Praxis beträgt die Kompromisse zwischen Effizienz und Universalität fast immer mehr als zwei Ebenen.GPUs und andere Chips, die üblicherweise als „Coprozessoren“ in der Branche bezeichnet werden, sind weniger vielseitig als CPUs, aber vielseitiger als ASICS.Die Kompromisse beim Spezialisierungsgrad sind komplex, abhängig von Vorhersagen und Intuition darüber, welche Teile des Algorithmus in fünf Jahren unverändert bleiben und welche Teile sich in sechs Monaten ändern werden.In der ZK-Proof-Architektur sehen wir oft ähnliche Mehrschichtspezialisierungen.Für ein breites Mind -Modell reicht es jedoch aus, zwei Ebenen zu berücksichtigen.In vielen Computerfeldern gibt es ähnliche Situationen:
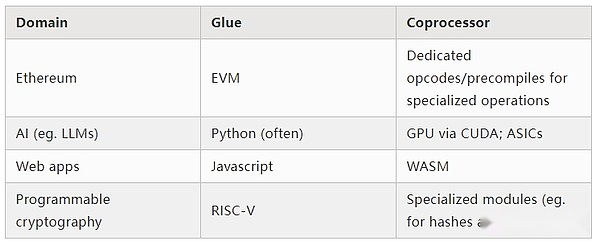
Nach den oben genannten Beispielen zu urteilen, können Berechnungen natürlich auf diese Weise aufgeteilt werden, was ein Naturgesetz zu sein scheint.Tatsächlich finden Sie Beispiele für die Computerspezialisierung über Jahrzehnte.Ich denke jedoch, dass diese Trennung zunimmt.Ich denke, es gibt einen Grund dafür:
Wir haben erst kürzlich die Grenze der CPU -Taktgeschwindigkeitsverbesserung erreicht, sodass weitere Vorteile nur durch Parallelisierung erzielt werden können.Parallelisierung ist jedoch schwierig zu argumentieren, daher ist es für Entwickler häufig praktischer, weiterhin nacheinander zu argumentieren und eine Parallelisierung im Backend aufzutreten und sie in einem dedizierten Modul zu verpacken, das für einen bestimmten Betrieb erstellt wurde.
Computing ist erst in letzter Zeit so schnell geworden, dass die Rechenkosten der Geschäftslogik wirklich vernachlässigbar geworden sind.In dieser Welt ist es sinnvoll, VMs zu optimieren, die auf Geschäftslogik ausgeführt werden, um andere Ziele als die Recheneffizienz zu erreichen: Entwicklerfreundlichkeit, Vertrautheit, Sicherheit und andere ähnliche Ziele.In der Zwischenzeit können dedizierte „Coprozessor“ -Module weiterhin für die Effizienz ausgelegt sein und ihre Sicherheit und Entwicklerfreundlichkeit von ihrer relativ einfachen „Schnittstelle“ zu Klebstoffen erhalten.
Was der wichtigste und teurste Betrieb ist.Dies ist in der Kryptographie am offensichtlichsten, wo die Arten spezifischer teurer Vorgänge am wahrscheinlichsten verwendet werden: Moduloperationen, lineare Kombination von elliptischen Kurven (auch als Multiscalar -Multiplikation bezeichnet), schnelle Fourier -Transformation usw.Diese Situation ist auch in der künstlichen Intelligenz immer offensichtlicher geworden, wobei die meisten Berechnungen „hauptsächlich Matrixmultiplikation“ (obwohl unterschiedliche Genauigkeitsniveaus) sind.Ähnliche Trends sind in anderen Gebieten entstanden.Es gibt viel weniger Unbekannte in (rechenintensiven) Berechnungen als vor 20 Jahren.
Was bedeutet das?
Ein entscheidender Punkt ist, dass der Gluer (Kleber) optimiert werden sollte, um ein guter Kleber (Kleber) zu sein, und der Koprozessor sollte ebenfalls als ein guter Koprozessor optimiert werden.Wir können die Bedeutung in mehreren Schlüsselbereichen untersuchen.
Evm
Blockchain -virtuelle Maschinen (z. B. EVMs) müssen nicht effizient sein, sie müssen nur mit ihnen vertraut sein.Fügen Sie einfach den richtigen Koprozessor (auch bekannt als „vorkompiliert“) hinzu, und die Berechnung in einer ineffizienten VM kann genauso effizient sein wie die Berechnung in einer nativen effizienten VM.Zum Beispiel ist der Overhead, der durch das 256-Bit-Register von EVM entstanden ist, relativ gering, während die Vertrautheit von EVM und die Vorteile des bestehenden Entwicklerökosystems enorm und langlebig sind.Die Entwicklungsteams, die EVMs optimieren, stellten sogar fest, dass die mangelnde Parallelisierung häufig keine große Barriere für die Skalierbarkeit darstellt.
Der beste Weg, um EVM zu verbessern Die Kosten für den Zugriff auf benachbarte Speicherplätze.
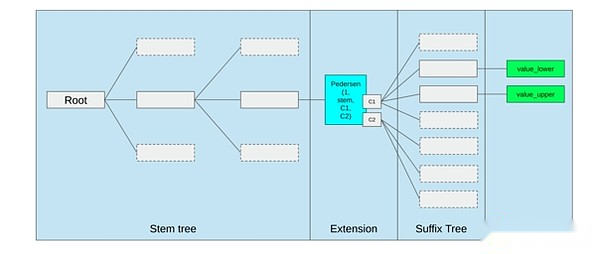
Speicheroptimierung im Vorschlag von Ethereum Querle Tree, fügen Sie benachbarte Speicherschlüssel zusammen und passen Sie die Gaskosten an, um dies widerzuspiegeln.Optimierungen wie diese in Verbindung mit einer besseren Vorkompilierung können wichtiger sein, als das EVM selbst zu optimieren.
Sichern Sie Computing und Öffnen Sie Hardware
Eine der Herausforderungen bei der Verbesserung der modernen Computersicherheit auf Hardwareebene ist die übermäßig komplexe und proprietäre Natur: Der Chip ist effizient ausgelegt, was eine proprietäre Optimierung erfordert.Die Hintertür ist leicht versteckt und die Schwachstellen der Seitenkanal werden ständig entdeckt.
Die Menschen arbeiten weiterhin daran, offenere und sicherere Alternativen aus mehreren Perspektiven zu fördern.In einer vertrauenswürdigen Ausführungsumgebung, einschließlich des Telefons des Benutzers, wird zunehmend eine Computing erfolgt, die die Benutzersicherheit verbessert hat.Die Aktion, um mehr Open-Source-Verbraucherhardware voranzutreiben, wird in jüngsten Siegen wie RISC-V-Laptops Ubuntu fortgesetzt.
RISC-V-Laptop Debian laufen
Die Effizienz bleibt jedoch ein Problem.Der Autor des obigen verknüpften Artikels schrieb:
Neue Open-Source-Chip-Designs wie RISC-V sind wahrscheinlich nicht mit der existierenden Prozessor-Technologie vergleichbar und wurden über Jahrzehnte verbessert.Es gibt immer einen Ausgangspunkt für den Fortschritt.
Weitere paranoide Ideen, wie dieses Design zum Aufbau von RISC-V-Computern auf FPGAs, stehen vor größerem Overhead.Aber was ist, wenn die Architektur der Kleber und Koprozessor bedeutet, dass dieser Overhead nicht wichtig ist?Wenn wir akzeptieren, dass offene und sichere Chips bei Bedarf langsamer sind als proprietäre Chips, geben Sie sogar gemeinsame Optimierungen wie spekulative Ausführung und Zweigvorhersage auf, aber versuchen Sie, dies durch das Hinzufügen (proprietär, bei Bedarf) ASIC -Module, die für die verwendet werden, zu kompensieren Das meiste, was passiert mit intensiven spezifischen Arten von Berechnungen?Sensitive Computing kann im „Hauptchip“ erfolgen, der für Sicherheit, Open Source -Design und Seitenkanalwiderstand optimiert wird.Intensivere Berechnungen (z. B. Zk Proof, AI) werden im ASIC -Modul durchgeführt, wodurch weniger Informationen über die durchzuführende Berechnung erfährt (möglicherweise durch Verschlüsselung und in einigen Fällen sogar keine Informationen).
Kryptographie
Ein weiterer wichtiger Punkt ist, dass all dies in Bezug auf die Kryptographie, insbesondere die programmierbare Kryptographie, sehr optimistisch ist und Mainstream wird.Wir haben einige spezifische hyperoptimierte Implementierungen von hochstrukturiertem Computer in Snark, MPC und anderen Einstellungen gesehen sehr niedrig.Weitere Verbesserungen wie GKR können dieses Niveau weiter verringern.Eine vollständig allgemeine VM-Ausführung, insbesondere wenn sie in einem RISC-V-Dolmetscher ausgeführt wird, kann weiterhin etwa das Zehntausendfache des Overheads entstehen, aber aus den in diesem Artikel beschriebenen Gründe spielt dies keine Rolle: Verwenden Sie einfach effiziente und dedizierte Technologien, um sie zu verarbeiten Die intensivsten Teile der Berechnung, der Gesamtaufwand, ist kontrollierbar.
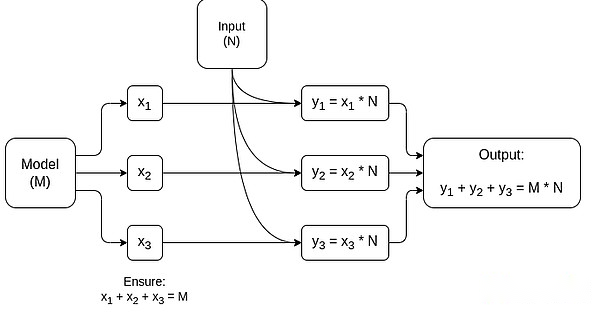
Ein vereinfachtes Diagramm von MPC, das der Matrix -Multiplikation gewidmet ist, was die größte Komponente in der Inferenz von AI -Modell ist.Weitere Informationen finden Sie in diesem Artikel, einschließlich, wie Sie Modelle und Eingaben privat halten.
Eine Ausnahme von der Idee, dass „geklebte Schichten nur vertraut sein müssen, nicht effizient“ sind, ist eine Latenz und in geringerem Umfang die Datenbandbreite.Wenn die Berechnung Dutzende von wiederholten schweren Operationen für dieselben Daten (wie Kryptographie und künstliche Intelligenz) umfasst, kann jede durch ineffizientes Klebstoff verursachte Verzögerung zum Hauptgutall in der Laufzeit werden.Daher hat die Kleberschicht auch Effizienzanforderungen, obwohl diese Anforderungen spezifischer sind.
abschließend
Insgesamt denke ich, dass die oben genannten Trends aus mehreren Perspektiven sehr positiv sind.Erstens ist es eine vernünftige Möglichkeit, die Recheneffizienz zu maximieren, gleichzeitig die Entwicklerfreundlichkeit aufrechtzuerhalten und in der Lage zu sein, mehr von beiden zu bekommen, für alle gut.Insbesondere durch Spezialisierung auf die Client -Seite, um die Effizienz zu verbessern, verbessert es unsere Fähigkeit, sensible und hochdarstellende Berechnungen (z. B. ZK Proof, LLM -Argumentation) lokal auf Benutzerhardware auszuführen.Zweitens schafft es ein großes Fenster der Möglichkeit, um sicherzustellen, dass das Streben nach Effizienz anderen Werten nicht schadet, insbesondere Sicherheit, Offenheit und Einfachheit: Seitungskanalsicherheit und Offenheit in Computerhardware, Reduzierung der Komplexität der Schaltung in ZK-Snark und die Verringerung der Komplexität in virtuellen Maschinen.In der Vergangenheit hat das Streben nach Effizienz dazu geführt, dass diese anderen Faktoren in den Hintergrund treten.Mit der Kleber- und Coprozessor -Architektur wird es nicht mehr benötigt.Ein Teil der Maschine optimiert die Effizienz, und der andere Teil optimiert die Vielseitigkeit und andere Werte, und die beiden arbeiten zusammen.
Dieser Trend ist auch für die Kryptographie sehr vorteilhaft, was ein Hauptbeispiel für „teures strukturiertes Computing“ ist, das die Entwicklung dieses Trends beschleunigt hat.Dies fügt eine weitere Möglichkeit hinzu, die Sicherheit zu verbessern.In der Blockchain -Welt sind auch Sicherheitsverbesserungen möglich: Wir können uns weniger Sorgen über die Optimierung virtueller Maschinen machen und uns mehr auf die Optimierung der Vorkompilation und andere Funktionen des Koexistierens mit virtuellen Maschinen konzentrieren.
Drittens bietet dieser Trend kleinere, neuere Teilnehmer die Möglichkeit, teilzunehmen.Wenn die Berechnungen immer modularer werden, senkt dies die Eintrittsbarriere erheblich.Selbst bei einer Art von Rechenaspekten ist es möglich, einen Unterschied zu machen.Gleiches gilt für das Feld ZK Proof und in der EVM -Optimierung.Das Schreiben von Code mit nahezu frontierter Effizienz wird leichter und zugänglich.Die Prüfung und die formale Überprüfung eines solchen Codes wird immer einfacher zugänglich.Da diese sehr unterschiedlichen Computerfelder zu einigen gemeinsamen Mustern konvergieren, gibt es mehr Raum für Zusammenarbeit und Lernen zwischen ihnen.