Autor: Vitalik Buterin, @vitalik.eth;
Una estrategia para una mejor descentralización en los protocolos de incentivos es el castigo por relevancia.Es decir, si un participante se comporta de manera incorrecta (incluidos los accidentes), cuanto más otros participantes (medidos por Total ETH) que se comportan incorrectamente con ellos, mayor será el castigo.La teoría sostiene que si usted es un gran participante, es más probable que se copie los errores en todas las «identidades» que controle, incluso si difunde sus tokens en muchas cuentas nominalmente independientes.
Esta tecnología se ha aplicado en el mecanismo de corte Ethereum (y, posiblemente, fuga inactiva).Sin embargo, los incentivos de caso de borde que ocurren solo en ataques extremadamente especiales pueden nunca aparecer en la práctica,Probablemente no sea suficiente para inspirar la descentralización.
Este artículo sugiere extender incentivos anticorrelación similares a casos de falla más «triviales», como pruebas faltantes, que casi todos los validadores hacen al menos ocasionalmente.La teoría sugiere que los puñaladas más grandes, incluidas las personas ricas y los grupos de replanteo, ejecutarán muchos validadores en la misma conexión a Internet o incluso en la misma computadora física, lo que dará como resultado fallas de manera desproporcionadamente relacionada.Tales Stakers siempre pueden hacer una configuración física separada para cada nodo, pero si terminan haciéndolo, significa que hemos eliminado por completo las economías de escala de replanteo.
Verificación de solidez: ¿Los errores de diferentes validadores en el mismo «clúster» en realidad es más probable que se correlacionen entre sí?
Podemos verificar esto combinando dos conjuntos de datos: (i) datos de prueba de períodos recientes, que muestran qué validadores deben probarse durante cada ranura, y qué validadores realmente probados, y (ii) asignan la ID de validador a un clúster que contiene muchos validadores (tales como validados (tales como como «lido», «coinbase», «vitalik buterin»).PuedeAquí,AquíyAquíEncuentra el vertedero del primero, enAquíEncuentra el vertedero de este último.
Luego ejecutamos un script para calcular el número total de fallas comunes: se asignan dos instancias de validadores en el mismo clúster para probar en la misma ranura de tiempo y fallar en ese intervalo de tiempo.
También calculamos la esperadaFalla común:Si la falla es un resultado total de una posibilidad aleatoria, entonces el número de fallas comunes que deberían ocurrir.
Por ejemplo, suponga que hay 10 validadores, uno de los tamaño del clúster es 4, los otros son independientes y 3 validadores fallan: dos están dentro del clúster y uno está fuera del clúster.
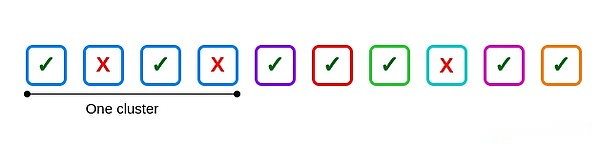
Aquí hay una falla común: el segundo y cuarto validadores en el primer clúster.Si los cuatro validadores en el clúster fallan, se producen seis fallas comunes, una por cada seis pares posibles.
Pero, ¿cuántas fallas comunes se deben hacer?Esta es una pregunta filosófica dura.Varias formas de responder:
Para cada falla, suponga que el número de fallas comunes es igual a la tasa de falla de otros validadores en esa ranura multiplicada por el número de validadores en el clúster y lo corta a la mitad para compensar los cálculos repetidos.Para el ejemplo anterior, se da 2/3.
Calcule la tasa de falla global, cuadrado y multiplique por [N*(N-1)]/2 para cada grupo.Esto se da [(3/10)^2]*6 = 0.54
Redistribuya las fallas de cada validador al azar en toda su historia.
Cada método no es perfecto.Los dos primeros métodos no consideran diferentes grupos con diferentes configuraciones de calidad.Al mismo tiempo, el último método no tiene en cuenta las correlaciones que surgen de diferentes intervalos de tiempo con diferentes dificultades inherentes: por ejemplo, la ranura de tiempo 8103681 tiene una gran cantidad de pruebas que no están incluidas en un solo espacio de tiempo, posiblemente porque el Block tiene la publicación es excepcionalmente tarde.
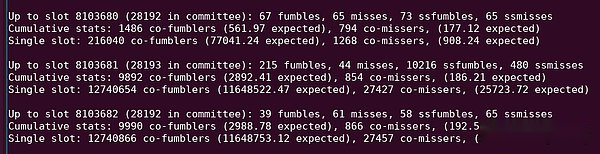
Ver «10216 SSFUMBLES» en esta salida de Python.
Terminé implementando tres métodos: los dos primeros anteriores, y un enfoque más complejo, comparé «cofailure real» con «cofailure falso»: cada miembro del clúster se reemplaza con (pseudo) aleatorio La falla del validador ha una tasa de falla similar.
También he distinguido claramenteErroresyextrañar.Mi definición de estos términos es la siguiente:
Errores: Cuando el verificador pierde la prueba en el período actual, pero lo demuestra correctamente en el período anterior;
extrañar: Cuando el verificador se perdió la prueba en el período actual y también se perdió la prueba en el período anterior.
El objetivo es distinguir dos fenómenos distintos: (i) falla de la red durante la operación normal, y (ii) falla fuera de línea o a largo plazo.
También hago este análisis en dos conjuntos de datos al mismo tiempo: la fecha límite máxima y la fecha límite de ranura única.El primer conjunto de datos trata al validador por falla dentro de un período de tiempo solo si la prueba no se incluye en absoluto.Si la prueba no se incluye en una sola ranura, el segundo conjunto de datos trata el validador como una falla.
Aquí están los resultados de mis dos primeros métodos para calcular las fallas comunes esperadas.SSFUMBLES y SSMISSS aquí se refieren a objetivos y errores que usan un conjunto de datos de un solo rango.
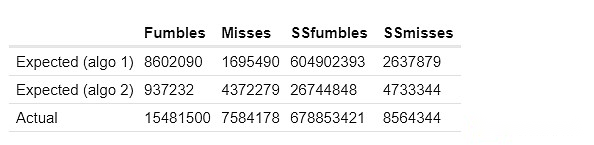
Para el primer enfoque, los comportamientos reales difieren porque para la eficiencia, se utiliza un conjunto de datos más restringido:

Las columnas «esperadas» y «clúster falsas» muestran cuántas fallas comunes «deberían estar» en el clúster en función de las técnicas anteriores.La columna real muestra cuántas fallas comunes realmente existen.Consistentemente, vemos una fuerte evidencia de «demasiadas fallas de correlación» dentro del clúster: dos validadores en el mismo grupo tienen significativamente más probabilidades de perder pruebas al mismo tiempo que dos validadores en diferentes grupos.
¿Cómo lo aplicamos a las reglas de penalización?
Hago un argumento simple: en cada ranura, deje que P divida el número de espacios que actualmente se pierden por el promedio de las últimas 32 espacios.
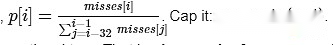
La pena por la prueba de este espacio debe ser proporcional a la p.
Es decir,En comparación con otras espacios recientes, la penalización por no demostrada es proporcional al número de validadores fallidos en ese espacio.
Existe una buena característica de este mecanismo, es decir, no es fácil de atacar: en cualquier caso, la falla reduce sus sanciones y manipular el promedio es suficiente para tener un impacto que requiere que haga muchas fallas usted mismo.
Ahora, intentemos ejecutarlo.Aquí están la penalización total para grupos grandes, grupos medianos, grupos pequeños y todos los validadores (incluidos los no clusteros):
Básico:Se deduce un punto por cada error (es decir, similar a la situación actual)
BASIC_SS:Lo mismo, pero necesita incluir una sola ranura para ser considerado una señorita
Excedido:Use la P calculada anteriormente para castigar el punto P
extra_ss:Use la P calculada anteriormente para castigar el punto P, requiriendo una sola ranura para contener no Miss

Usando el esquema «básico», los esquemas grandes tienen aproximadamente 1.4 veces la ventaja sobre pequeños esquemas (aproximadamente 1.2 veces en conjuntos de datos de un solo rango).Usando el esquema «extra», el valor cayó a aproximadamente 1.3 veces (aproximadamente 1.1 veces en un conjunto de datos de un solo ranura).A través de varias otras iteraciones, utilizando conjuntos de datos ligeramente diferentes, el esquema de penalización excesivo reduce uniformemente las ventajas de «personas grandes» sobre «personas pequeñas».
¿Qué está sucediendo?
Hay muy pocas fallas por ranura: generalmente solo unas pocas docenas.Esto es mucho más pequeño que casi cualquier «gran participación».De hecho, es menor que el número de validadores activos en una sola ranura que los grandes Stakers (es decir, 1/32 de su stock total).Si un gran alñador ejecuta muchos nodos en la misma computadora física o conexión a Internet, cualquier falla podría afectar a todos sus validadores.
Esto significa:Cuando los grandes validadores muestran fallas en la inclusión de prueba, cambiarán solo la tasa de falla de la ranura actual, lo que a su vez aumentará su penalización.Los pequeños validadores no hacen esto.
En principio, los principales accionistas pueden evitar este esquema de castigo colocando cada validador en una conexión a Internet separada.Pero esto sacrifica las economías de escala de que las grandes partes interesadas pueden reutilizar la misma infraestructura física.
Análisis posterior
-
Busque otras estrategias para confirmar la magnitud de este efecto, donde es probable que los validadores en el mismo grupo fallarán al mismo tiempo.
-
Trate de encontrar un esquema ideal (pero aún simple para evitar el sobreajuste y la untilización) un esquema de recompensa/castigo para minimizar la ventaja promedio de grandes validadores sobre pequeños validadores.
-
Trate de demostrar la naturaleza de seguridad de tales esquemas de incentivos, idealmente identificar un «área espacial de diseño» donde el riesgo de un ataque extraño (por ejemplo, estratégicamente fuera de línea en un momento específico para manipular el promedio) es demasiado costoso y no vale la pena.
-
Clúster por ubicación geográfica.Esto puede determinar si el mecanismo también puede inspirar la descentralización geográfica.
-
Agrupación a través del software cliente (Ejecución y Beacon).Esto puede determinar si el mecanismo también puede incentivar el uso de un pequeño número de clientes.