オリジナルタイトル:接着剤とコプロセッサのアーキテクチャ
著者:イーサリアムの創設者であるVitalik
ジャスティン・ドレイク、ジョージオス・コンスタントトプロス、アンドレジ・カルパシー、マイケル・ガオ、タルン・チトラ、そしてフィードバックとコメントにさまざまなフラッシュボットの寄稿者に感謝します。
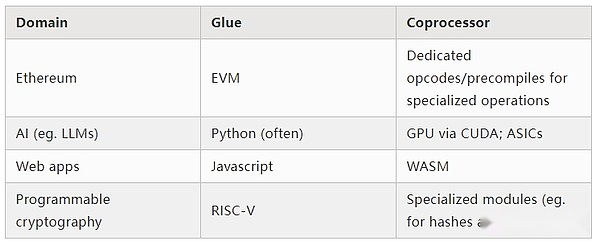
中程度の詳細で現代世界で行われているリソース集約的な計算を分析する場合、何度も見つける機能の1つは、計算を2つの部分に分割できることです。
-
比較的少量の複雑なが、非常に計算的に集中的ではない「ビジネスロジック」。
-
多くの集中的であるが高度に構造化された「高価な仕事」。
これらの2つの形式は、さまざまな方法で処理されます。
実際のこのさまざまなアプローチの例は何ですか?
まず、私が最もよく知っている環境、Ethereum Virtual Machine(EVM)を見てみましょう。私の最近のEthereumトランザクションのGetth Debugトラッキングは、私のブログのIPFハッシュをENSで更新します。トランザクションは合計46924ガスを消費し、次のように分類できます。
-
基本コスト:21,000
-
データの呼び出し:1,556
-
EVM実行:24,368
-
Sload OpCode:6,400
-
SSTORE OPCODE:10,100
-
ログオペコード:2,149
-
その他:6,719

ENSハッシュアップデートのEVMトレース。最後から2番目のカラムはガス消費です。
このストーリーの教訓は、ほとんどの実行(EVMのみを見る場合は約73%、計算をカバーする基本コストパーツを含める場合は約85%)が非常に少数の構造的な高価な操作に集中していることです。ログと暗号化(基本コストには支払い署名検証のために3000が含まれ、EVMには支払いハッシュの272も含まれます)。実行の残りの部分は「ビジネスロジック」です。CallDataビットを交換して、設定しようとしているレコードのIDと設定したハッシュなどです。トークン転送では、より高度なアプリケーションでのバランスの追加と減算が含まれます。これには、ループなどが含まれる場合があります。
EVMでは、これらの2つの形式の実行はさまざまな方法で処理されます。Advanced Business Logicは、より高度な言語、通常は堅実さで記述されており、EVMにコンパイルできます。高価な作業は依然としてEVMオペコード(スロードなど)によってトリガーされていますが、実際の計算の99%以上は、クライアントコード(またはライブラリ)内に直接記述された専用モジュールで行われます。
このパターンの理解を強化するために、別のコンテキストでそれを調べてみましょう:PythonでTorchを使用して書かれたAIコード。
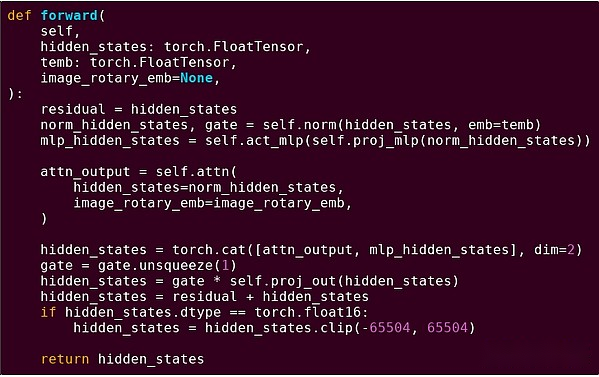
トランスモデルのブロックの前方配信
ここで何を見ましたか?実行中の操作の構造を説明するPythonで書かれた比較的少量の「ビジネスロジック」が表示されます。実際のアプリケーションでは、入力を取得する方法や出力で実行される操作などの詳細を決定する別のタイプのビジネスロジックがあります。ただし、個々の操作自体を掘り下げると(self.norm、torch.cat、 +、 *、self.attn…)、ベクトル化された計算が表示されます。同じ操作が大規模な並列計算を計算します。ケース数の値。最初の例と同様に、計算のごく一部はビジネスロジックに使用され、ほとんどは大きな構造化されたマトリックスとベクトル操作を実行するために使用されます。実際、ほとんどはマトリックスの乗算です。
EVMの例と同じように、これらの2種類の作業は2つの異なる方法で処理されます。高度なビジネスロジックコードは、非常に一般的で柔軟な言語であるPythonで記述されていますが、非常に遅い言語でもあり、総コンピューティングコストのごく一部しか関与していないため、非効率性を受け入れます。一方、集中操作は、通常GPUで実行されている高度に最適化されたコードで記述されています。私たちは、ASICでLLMの推論が起こっているのをますます見始めています。
Snarkなどの最新のプログラム可能な暗号化は、両方のレベルで同様のパターンに再び従います。まず、上記のAIの例と同様に、ハイレベルの言語では、高レベルの言語で書くことができます。ここの私の円形のスタークコードはこれを示しています。第二に、暗号化内で実行されたプログラム自体は、一般的なビジネスロジックと高度に構造化された高価な作業を分割する方法で書くことができます。
それがどのように機能するかを理解するために、Stark Starkが証明された最新のトレンドの1つを見てみましょう。一般的で使いやすいために、チームはRISC-Vなどの広く採用されている最小限の仮想マシンのために、ますますスタークプーバーを構築しています。実行を証明する必要があるプログラムは、RISC-Vにコンパイルでき、プルーフィャーはコードのRISC-V実行を証明できます。
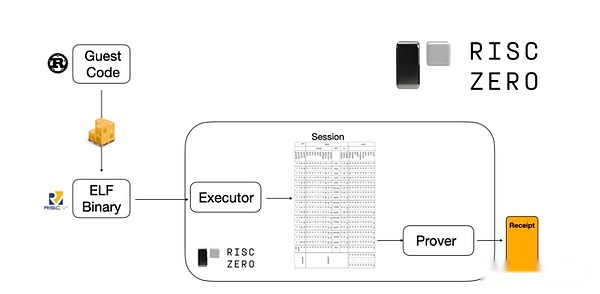
Risczeroドキュメントのチャート
これは非常に便利です。つまり、証明ロジックを一度しか書く必要があり、それ以降、「従来の」プログラミング言語(RiskzeroがRustをサポートするなど)で証明を必要とするプログラムで書くことができます。ただし、問題があります。このアプローチでは、多くのオーバーヘッドが発生する可能性があります。プログラム可能な暗号化はすでに非常に高価です。そのため、開発者は、ほとんどの計算を構成する特定の高価な操作(通常はハッシュとシグネチャ)を特定し、それらを非常に効率的に証明するための特殊なモジュールを作成するトリックを思いつきました。その後、非効率的で普遍的なRISC-V証明システムと効率的であるが専門的な証明システムを単に組み合わせることで、両方の世界を最大限に活用できます。
マルチパーティコンピューティング(MPC)や完全な準同型暗号化(FHE)など、ZK-SNARK以外のプログラム可能な暗号化は、同様の方法を使用して最適化できます。
全体的に、現象とは何ですか?
最新のコンピューティングは、私が結合とコプロセッサーのアーキテクチャと呼ぶものにますます従います。これは、非常に用途が広いが、1つ以上のコプロセッサコンポーネントに責任がある中央の「結合」コンポーネントがあります。
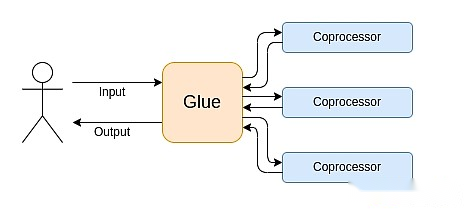
これは単純化です。実際には、効率と普遍性のトレードオフ曲線は、ほとんど常に2つ以上のレベルです。業界で一般的に「コポロセッサー」と呼ばれるGPUやその他のチップは、CPUよりも汎用性が低いが、ASICよりも多用途が多い。専門化の程度に関するトレードオフは、5年間でどの部分が変化しないか、6か月でどの部分が変化するかについての予測と直感に応じて複雑です。ZKプルーフアーキテクチャでは、同様のマルチレイヤーの専門化が見られることがよくあります。しかし、広い心モデルでは、2つのレベルを考慮するだけで十分です。多くのコンピューティングフィールドにも同様の状況があります。
上記の例から判断すると、計算はもちろんこのように分割することができますが、これは自然な法律のようです。実際、数十年にわたって計算の専門化の例を見つけることができます。しかし、この分離は増加していると思います。これには理由があると思います:
私たちは最近、CPUクロック速度の改善の限界に達したばかりなので、さらなる利点は並列化によってのみ達成できます。ただし、並列化を推論することは困難であるため、開発者が順番に推論し続け、バックエンドで並列化が発生し、特定の操作用に構築された専用モジュールにパッケージ化することがより実用的であることがよくあります。
コンピューティングは最近非常に速くなったため、ビジネスロジックの計算コストは本当に無視できます。この世界では、ビジネスロジックで実行されているVMを最適化して、開発者にとって優しい、親しみやすさ、セキュリティ、その他の同様の目標などのコンピューティング効率以外の目標を達成することが理にかなっています。一方、専用の「コプロセッサ」モジュールは、効率のために引き続き設計され、接着剤との比較的単純な「インターフェイス」からセキュリティと開発者に優しいことを獲得できます。
最も重要で高価な操作は、より明確になることです。これは、特定の高価な操作のタイプが使用される可能性が最も高い暗号化、楕円曲線の線形組み合わせ(マルチスカラー乗算とも呼ばれる)、高速フーリエ変換など、暗号化で最も明白です。この状況は、人工知能でもますます明らかになっており、ほとんどの計算は「主にマトリックスの乗算」です(ただし、精度のレベルはさまざまです)。他の分野でも同様の傾向が現れています。20年前よりも(計算集約型)計算にははるかに少ない未知数があります。
それはどういう意味ですか?
重要な点は、Gluer(接着剤)を良い接着剤(接着剤)に最適化する必要があり、コプロセッサーも優れたコプロセッサになるように最適化する必要があることです。この意味をいくつかの重要な領域で探求できます。
EVM
ブロックチェーン仮想マシン(EVMなど)は効率的である必要はありません。それらに精通する必要があります。正しいコプロセッサ(別名「プリコンパイル」)を追加するだけで、非効率的なVMでの計算は、ネイティブ効率の高いVMの計算と同じくらい効率的です。たとえば、EVMの256ビットレジスタによって発生したオーバーヘッドは比較的少ないですが、EVMの親しみやすさと既存の開発者エコシステムの利点は巨大で耐久性があります。EVMを最適化する開発チームは、並列化の欠如がスケーラビリティに対する大きな障壁ではないことが多いことを発見しました。
EVMを改善する最良の方法は、(i)EVM-MaxとSIMDの組み合わせなど、より優れたプリコンパイルまたは専用のオペコードを追加し、(ii)副作用としてのVerkleツリーの変化などのストレージレイアウトの改善は、大幅に減少することです。隣接するストレージスロットにアクセスするコスト。
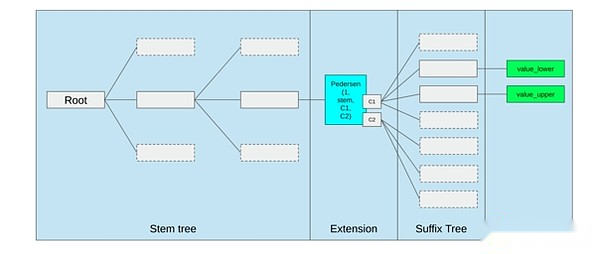
Ethereum Verkle Treeの提案でのストレージ最適化、隣接するストレージキーをまとめて、これを反映するためにガスコストを調整します。このような最適化は、より良いプリコンパイルと相まって、EVM自体を微調整するよりも重要かもしれません。
セキュアなコンピューティングとオープンハードウェア
ハードウェアレベルで最新のコンピューティングセキュリティを改善する上での課題の1つは、その過度に複雑で独自の性質です。チップは効率的に設計されており、独自の最適化が必要です。バックドアは簡単に隠され、サイドチャネルの脆弱性は絶えず発見されています。
人々は、複数の視点からよりオープンで安全な代替案を促進するために働き続けています。一部のコンピューティングは、ユーザーのセキュリティが改善されたユーザーの携帯電話など、信頼できる実行環境でますます行われています。より多くのオープンソースの消費者ハードウェアを駆動するためのアクションは継続され、RISC-Vラップトップのような最近の勝利はUbuntuを実行しています。
Debianを実行しているRISC-Vラップトップ
ただし、効率は依然として問題です。上記の記事の著者は次のように書いています。
RISC-Vなどの新しいオープンソースチップデザインは、数十年にわたって存在し、改善されてきたプロセッサテクノロジーに匹敵する可能性は低いです。進歩には常に出発点があります。
FPGAにRISC-Vコンピューターを構築するためのこのデザインなど、より多くの妄想的なアイデアは、より大きなオーバーヘッドに直面しています。しかし、接着剤とコプロセッサのアーキテクチャがこのオーバーヘッドが実際に重要ではないことを意味する場合はどうなりますか?オープンチップとセキュアチップを受け入れると、必要に応じて独自のチップよりも遅くなり、投機的実行や分岐予測などの一般的な最適化を放棄しますが、使用される(必要に応じて、必要に応じて)ASICモジュールを追加することでこれを補償しようとします。集中的な種類の計算は何が起こるのですか?セキュリティ、オープンソース設計、サイドチャネル抵抗のために最適化される「メインチップ」では、敏感なコンピューティングを実行できます。ASICモジュールでは、より集中的な計算(ZKプルーフ、AIなど)が行われ、実行中の計算に関する情報が少なくなります(おそらく、暗号化の盲検化を介して、場合によっては情報もゼロです)。
暗号化
もう1つの重要な点は、これがすべて暗号化、特にプログラム可能な暗号化について非常に楽観的であり、主流になることです。Snark、MPC、およびその他の設定における高度に構造化されたコンピューティングの特定の超最適化された実装を見てきました。一部のハッシュ関数は、コンピューティングを直接実行するよりも数百倍の高価です。非常に低い。GKRなどのさらなる改善により、このレベルがさらに低下する可能性があります。特にRISC-V通訳者で実行された場合、完全に一般的なVMの実行は、オーバーヘッドの約1万倍の発生を続ける可能性がありますが、この記事で説明されている理由により、それは重要ではありません。計算の最も集中的な部分である合計オーバーヘッドは制御可能です。
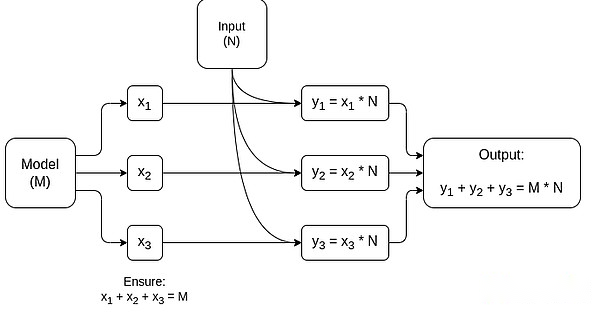
AIモデル推論で最大のコンポーネントであるマトリックス乗算専用のMPCの簡略グラフ。モデルと入力をプライベートに保つ方法など、詳細については、この記事を参照してください。
「接着されたレイヤーは馴染みのあるだけでなく、効率的ではない」という考えの1つの例外は、遅延であり、より低い程度のデータ帯域幅です。計算が同じデータ(暗号化や人工知能など)で数十の繰り返し重い操作を伴う場合、非効率的な接着剤によって引き起こされる遅延は、ランタイムの主要なボトルネックになる可能性があります。したがって、接着層には効率要件もありますが、これらの要件はより具体的です。
結論は
全体として、上記の傾向は複数の観点から非常に前向きであると思います。第一に、これは、開発者に優しい維持を維持しながら、コンピューティング効率を最大化する合理的な方法であり、両方をより多くのものを得ることができることは、誰にとっても良いことです。特に、効率を向上させるためにクライアント側を専門とすることにより、ユーザーハードウェアでローカルに敏感で高性能の計算(ZKプルーフ、LLM推論など)を実行する能力を向上させます。第二に、それは効率の追求が他の価値、特にセキュリティ、オープン性、シンプルさを害しないようにするための大きな機会の窓を生み出します:コンピューターハードウェアのサイドチャネルのセキュリティとオープン性、ZK-SNARKの回路の複雑さを減らし、仮想マシンの複雑さを削減します。歴史的に、効率性の追求は、これらの他の要因が後部座席をとることにつながりました。接着剤とコプロセッサのアーキテクチャでは、もはや必要ありません。マシンの一部は効率を最適化し、他の部分は汎用性とその他の値を最適化し、2つは一緒に機能します。
この傾向は、暗号化にとっても非常に有益です。これは、この傾向の開発を加速した「高価な構造化コンピューティング」の主要な例です。これにより、セキュリティを改善する別の機会が追加されます。ブロックチェーンの世界では、セキュリティの改善も可能です。仮想マシンの最適化についてはあまり心配し、仮想マシンと共存するその他の機能の最適化にもっと焦点を当てることができます。
第三に、この傾向は、より小さく、より新しい参加者が参加する機会を提供します。計算が単一でモジュール式になると、エントリの障壁が大幅に低下します。1つのタイプの計算ASICがあっても、違いを生むことが可能です。同じことが、ZKプルーフフィールドとEVM最適化でも当てはまります。ほぼ華やかな効率でコードを作成することは、簡単にアクセスしやすくなります。このようなコードの監査と正式な検証は、アクセスしやすくなります。最後に、これらの非常に異なるコンピューティングフィールドがいくつかの一般的なパターンに収束しているため、それらの間でコラボレーションと学習の余地が増えます。






