著者:Vitalik Buterin、 @vitalik.eth;
インセンティブプロトコルにおける地方分権を改善するための戦略の1つは、関連性に対する罰です。つまり、1人の参加者が不適切に動作する(事故を含む)場合、他の参加者(Total ETHによって測定される)が彼らと不適切に振る舞うほど、罰は大きくなります。理論によると、あなたが大規模な参加者である場合、あなたが犯すすべての「アイデンティティ」であなたがコピーする可能性が高いと考えています。
この技術は、イーサリアムカット(そしておそらく、不活性なリーク)メカニズムに適用されています。ただし、非常に特別な攻撃でのみ発生するエッジケースインセンティブは、実際には決して現れない場合があります。おそらく地方分権を刺激するのに十分ではありません。
この記事では、同様の相関インセンティブを、ほとんどすべてのバリデーターが少なくとも時々行うなど、より「些細な」故障のケースに拡張することを示唆しています。理論は、裕福な個人やステーキングプールを含む大規模なステーカーが、同じインターネット接続または同じ物理的なコンピューターでさらに多くのバリデーターを実行し、不均衡に関連する障害をもたらすことを示唆しています。このようなステーカーは、各ノードに対して常に個別の物理的設定を作成できますが、最終的にそうすることになった場合、それは私たちがステーキングの規模の経済を完全に排除したことを意味します。
堅牢性チェック:同じ「クラスター」の異なるバリデーターからのエラーは、実際に互いに相関する可能性が高いのでしょうか?
これは、2つのデータセットを組み合わせて確認できます。(i)最近の期間の証明データ、各スロットで証明されるべきバリケーター、および実際に証明されているかを示し、(ii)バリケーターIDを多くの検証ターを含むクラスターにマッピングします(そのような「lido」、「coinbase」、「vitalik buterin」として)。あなたはできるここ、ここそしてここ前者のダンプを見つけてくださいここ後者のダンプを見つけてください。
次に、スクリプトを実行して一般的な障害の総数を計算します。同じクラスター内のバリデーターの2つのインスタンスが、同じ時間スロットで証明し、その時間スロットで故障するように割り当てられます。
また、期待も計算します一般的な過失:障害がランダムなチャンスの完全な結果である場合、発生するはずの一般的な障害の数。
たとえば、10個のバリデーターがあり、クラスターサイズの1つは4、その他は独立しており、3つのバリデーターが失敗します。2つはクラスターの内側、1つはクラスターの外側にあります。
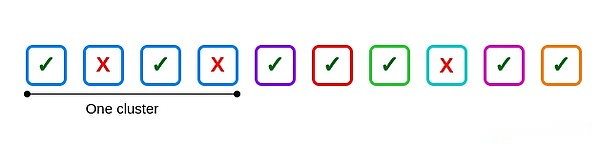
一般的な障害は次のとおりです。最初のクラスターの2番目と4番目のバリデーターです。クラスター内の4つのバリデーターがすべて失敗すると、6つの一般的な障害が発生します。1つは、可能な6つのペアごとに1つです。
しかし、いくつの一般的な障害を行う必要がありますか?これは難しい哲学的な質問です。答えるいくつかの方法:
各障害について、一般的な障害の数が、そのスロットの他のバリデーターの故障率にクラスター内のバリデーターの数を掛け、繰り返し計算を補うために半分にカットすることに等しいと仮定します。上記の例では、2/3が示されています。
クラスターごとにグローバルな故障率、2乗、および乗算を計算し、[n*(n-1)]/2を掛けます。これには[(3/10)^2]*6 = 0.54が与えられます
各履歴全体で各バリデーターの障害をランダムに再配布します。
各方法は完璧ではありません。最初の2つのメソッドは、異なる品質設定を持つ異なるクラスターを考慮していません。同時に、最後の方法では、さまざまな固有の難しさを持つ異なる時間スロットから生じる相関を考慮していません。たとえば、タイムスロット8103681には、おそらく1回のタイムスロットに含まれていない多くの証明があります。ブロックの投稿は非常に遅れています。
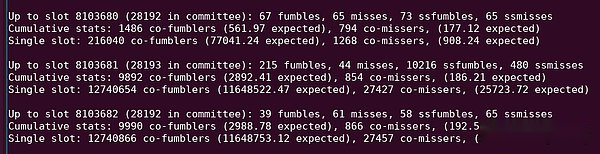
このPython出力の「10216 SSFumbles」を参照してください。
上記の最初の2つの方法とより複雑なアプローチの3つの方法を実装することになりました。「実際の共同申告」と「偽の共同ール」と比較しました。各クラスターメンバーは(擬似)ランダムに置き換えられます。同様の障害率。
私も明らかに際立っています間違いそして逃す。これらの用語の私の定義は次のとおりです。
間違い:検証者が現在の期間に証明を逃したが、前の期間に正しく証明する場合。
逃す:Verifierが現在の期間に証明を逃し、前の期間に証明を逃したとき。
目標は、2つの異なる現象を区別することです。(i)通常の動作中のネットワーク障害、および(ii)オフラインまたは長期障害。
また、2つのデータセットで同時にこの分析を行います。最大締め切りとシングルスロットの締め切りです。最初のデータセットは、証明がまったく含まれていない場合にのみ、期間内にバリデーターを失敗として扱います。証明が単一のスロットに含まれていない場合、2番目のデータセットはバリデーターを障害として扱います。
予想される共通障害を計算する最初の2つの方法の結果を以下に示します。ここでのssfumblesとsssmissesは、シングルスロットデータセットを使用する目標と間違いを指します。
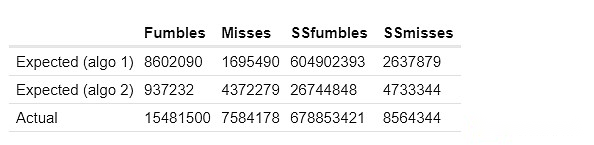
最初のアプローチでは、効率のためにより制限されたデータセットが使用されるため、実際の動作は異なります。

「予想される」および「偽のクラスター」列は、上記の手法に基づいて、クラスター内にある一般的な障害の数を示しています。実際の列は、実際に存在する一般的な障害の数を示しています。一貫して、クラスター内の「相関障害が多すぎる」という強力な証拠が見られます。同じクラスター内の2つのバリデーターは、異なるクラスターの2つのバリッタよりも証明を同時に見逃す可能性が非常に高くなります。
ペナルティルールにどのように適用しますか?
私は簡単な議論をします:各スロットで、Pを最後の32スロットの平均で現在見逃しているスロットの数をPとします。
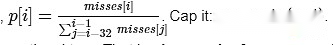
このスロットの証明に対するペナルティは、pに比例する必要があります。
つまり、他の最近のスロットと比較して、そのスロット内の失敗したバリデーターの数に比例しないことが証明されていない場合のペナルティ。
このメカニズムには良い特徴があります。つまり、攻撃するのは容易ではありません。いずれにせよ、障害はペナルティを減らし、平均を操作するだけで十分な影響があり、多くの失敗を自分で行う必要があります。
さて、実際に実行してみましょう。大型クラスター、中程度のクラスター、小さなクラスター、およびすべてのバリデーター(非クラスターを含む)の合計ペナルティは次のとおりです。
基本:ミスごとに1つのポイントが差し引かれます(つまり、現在の状況に似ています)
BASIC_SS:同じですが、ミスと見なされるために単一のスロットを含める必要があります
それを超えた:上記のPを使用して、Pポイントを罰する
extra_ss:上記のPを計算してPポイントを罰し、ミスを封じ込めないように単一のスロットを要求する

「基本」スキームを使用すると、大規模なスキームは、小さなスキームよりも約1.4倍の利点があります(シングルスロットデータセットでは約1.2倍)。「追加」スキームを使用して、値は約1.3倍に低下しました(シングルスロットデータセットでは約1.1倍)。わずかに異なるデータセットを使用して、他の複数の反復を通じて、過剰なペナルティスキームは、「小さな人々」よりも「大人」の利点を均一に狭めます。
どうしたの?
スロットごとに障害はほとんどありません。通常、数十個しかありません。これは、ほぼすべての「大きな共有」よりもはるかに小さいです。実際、大規模なステーカー(つまり、総株の1/32)よりも、単一のスロットでアクティブなバリデーターの数よりも少ないです。大きなステイカーが同じ物理コンピューターまたはインターネット接続で多くのノードを実行すると、障害はすべてのバリデーターに影響を与える可能性があります。
これはつまり:大規模なバリデーターがプルーフインクルージョンの障害を示すと、現在のスロットの故障率を独力で変更し、ペナルティが増加します。小さなバリデーターはこれをしません。
原則として、主要な株主は、各バリデーターを別のインターネット接続に配置することにより、この罰スキームをバイパスできます。しかし、これは、大規模な利害関係者が同じ物理的インフラストラクチャを再利用できるようにする規模の優位性の経済を犠牲にします。
さらなる分析
-
この効果の大きさを確認するための他の戦略を探してください。同じクラスター内の検証因子が同時に失敗する可能性が高い場合。
-
小さなバリッターよりも大きなバリデーターの平均的な利点を最小限に抑えるために、理想的な(ただし、過剰適合と未使用化を避けるためにまだ簡単な)報酬/罰スキームを見つけてみてください。
-
このようなインセンティブスキームのセキュリティの性質を実証してみてください。理想的には、奇妙な攻撃のリスク(たとえば、平均を操作するための特定の時間に戦略的にオフライン)を特定することは高すぎて価値がありません。
-
地理的位置によるクラスター。これにより、メカニズムが地理的分散化を促すことができるかどうかを判断できます。
-
(実行およびビーコン)クライアントソフトウェアのクラスタリング。これにより、メカニズムが少数の顧客の使用を奨励できるかどうかを判断できます。