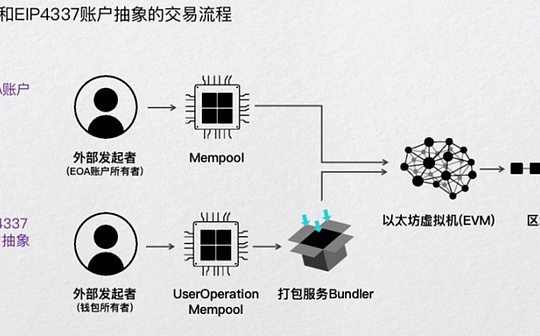
Auteur: David Attermann de M31 Capital
>
Le réseau de la subsomie est le premier index de données de blockchain modulaire et solution de requête dans l’industrie, permettant aux développeurs d’accéder et d’analyser facilement les informations sur la chaîne.Il fournit des architectures modulaires et évolutives uniques, permettant des pipelines de traitement de données hautement personnalisés et des mises à jour réelles.Parce que le marché n’en sait pas grand-chose, cela offre aux investisseurs une opportunité d’investissement rare et attrayante.
Le statu quo de la gestion des données de la blockchain
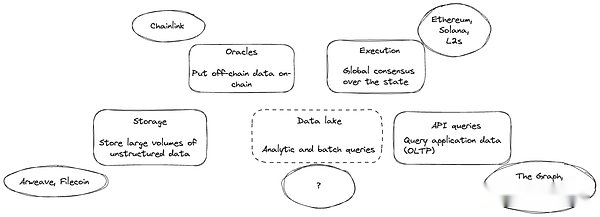
À l’heure actuelle, l’un des plus grands défis auxquels est confronté les développeurs Web3 est les données d’accès à grande échelle.À l’heure actuelle, les requêtes et résumer la blockchain (données de transaction et d’état), l’application (décodage de l’état du contrat intelligent) et toutes les données de liaison connexes (telles que les données de prix stockées dans IPFS et Arweave) sont extrêmement compliquées.Ces données sont généralement dispersées dans plusieurs écosystèmes, chaînes et technologies, entraînant l’apparition de structures et d’îles de données non standard, et finalement des ensembles de données incomplets, qui sont difficiles à extraire des informations significatives.
Dans Web2, les données sont stockées dans des lacs de données centralisés similaires à BigQuery, Snowflake, Apache et Iceberg pour l’accès à l’accès.Cependant, le stockage des données Web3 dans des lacs de données centralisés similaires violera l’intention d’ouverture d’ouverture et d’accès élastique.Si les données d’application Web3 peuvent être résumées, filtrées et commodément extraites, le potentiel de l’industrie sera publié sous le paradigme multi-chaîne pour promouvoir le développement de la prochaine génération de fonctions d’application.
>
Solution:Sous-marineréseau
La subsomie est un moteur de requête décentralisé qui l’optimise pour extraire efficacement une grande quantité de données.Il traite actuellement les données de plus de 100 réseaux EVM et de substrat, ainsi que les données de Solana et StarkNet au stade de test.Ces données incluent des informations détaillées telles que les journaux d’événements EVM, les reçus de transaction, le suivi et les différences de statut dans chaque transaction.Il développe également des collaborateurs et des fonctions de chiffon qui utilisent sa fonction multi-chaîne pour prouver que le marché et l’environnement d’exécution de confiance (TEE) se sont avérés avoir une connexion de confiance avec le réseau de ressources de lacs de données lié par le biais de la connaissance zéro.
Les méthodes de requête de données de blockchain traditionnelles sont lentes, décentralisées et rentables, et il est difficile pour les développeurs d’extraire des informations significatives.Le moteur de requête décentralisé de la subsquide fournit une architecture modulaire évolutive, permettant des pipelines de données personnalisés et des mises à jour en temps réel pour augmenter la vitesse d’extraction des données jusqu’à 100 fois, et le coût est réduit de 90%.
Kit de produit actuel
Ces outils permettent aux développeurs d’accéder et d’analyser facilement une grande quantité de données de blockchain, en créant ainsi et en élargissant les applications décentralisées complexes.
1. 1.Réseau de subsquive: Un moteur de requête distribué pour traiter les données de plus de 100 EVM et réseaux de substrat et la chaîne historique de Solana et Starknet dans la phase de test.
2Squid SDK: Un package de boîte à outils TypeScript pour construire des index sur le réseau de la subsomie pour fournir des bibliothèques élevées pour l’extraction, la conversion et le chargement des données.
3 ..Nuage de subsomise: Une plate-forme est le service (PAAS), qui est utilisé pour déployer l’indice Squid SDK, qui fournit l’allocation de ressources Postgres, la migration d’arrêt zéro et le point de terminaison RPC à haute performance.
4. 4 ..Tuhose de la subsomiseur: Un adaptateur léger open source, qui est pratique pour les sous-diagrammes de développement et de déploiement sans grand nombre de paramètres.
Structure modulaire
Contrairement à d’autres solutions du marché, l’architecture modulaire unique de Subsquid permet aux développeurs d’effectuer la meilleure flexibilité et la meilleure personnalisation.Cela deviendra une différence clé dans la prochaine étape de la saisie du développement de Web3, rendant les applications et les cas d’utilisation plus complexes et fonctionnels.
1. 1.Personnaliser: Les développeurs peuvent personnaliser chaque composant du pipeline en fonction des besoins spécifiques pour obtenir un traitement de données plus efficace et efficace.
2Évolutivité: Les caractéristiques modulaires facilitent l’expansion horizontale et traitent la charge de données augmentant en continu en augmentant simplement le nœud de traitement.
3 ..flexibilité: Il peut développer et optimiser indépendamment les différentes étapes des pipelines, afin que la subsomie puisse s’adapter à divers cas et exigences de performance.
4. 4 ..efficacité: En contrôlant le flux de données et en logique de traitement, la subsquide peut atteindre des performances et une efficacité plus élevées dans les tâches d’indexation et de requête.
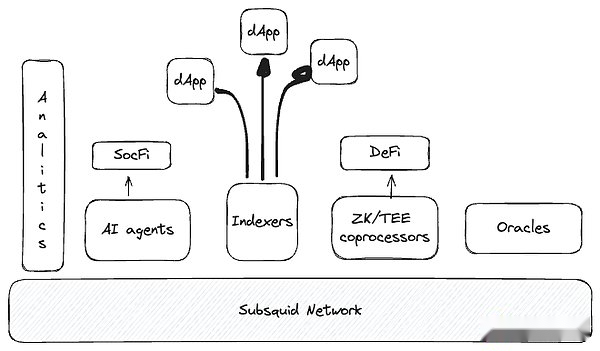
Afin d’expliquer la fonction puissante des méthodes d’accès aux données modulaires, nous pouvons comparer l’analyse et les cas d’utilisation d’accès aux données réels.Les deux ont besoin de sources de données très efficaces (réseau subalterne), mais les pipelines restants ont besoin de technologies complètement différentes.Dans le monde Web2, l’accès aux données en temps réel des applications est généralement pris en charge par des bases de données de transactions relativement petites (Postgres, SQLite), et l’analyse nécessite des solutions de Big Data telles que Snowflake, BigQuery ou Trino.La même distinction s’applique également aux cas d’utilisation de web3, etLa subsquide a un avantage unique et peut obtenir un partage de valeur significatif à partir de deux champs verticauxEssence
Marché cible et cas d’utilisation
La technologie de la subsquide est fortement corrélée dans tous les domaines de l’écosystème de la blockchain:
1. 1.Projet d’application décentralisé (Projets DAPP): Améliorer les performances et l’expérience utilisateur de l’application décentralisée dans Defi, NFT, jeux, médias sociaux et autres domaines.
2Réseau de blockchain (Réseaux de blockchain): Améliorer l’infrastructure de données des réseaux L1 et L2 pour aider les développeurs à créer des applications plus efficaces sur les données.
3 ..Analyse et recherche (Analytique et recherche): Aider l’entreprise à traiter une grande quantité de données de blockchain, d’extraire des informations et des tendances.
La valeur de chaque octet sur les données de la chaîne et du web3 est plusieurs amplitude supérieure à celle du Web2, et elle est consommée par les contrats intelligents, les index, l’API d’analyse et la technologie marginale (comme les agents d’IA).
>
Recherche de cas client
1. 1.Fer à chenilles: Infrastructure de portefeuille EVM avec portefeuille EVM axé sur la vie privée
• Railgun a utilisé une fois des outils internes pour appeler directement le solde de balayage RPC, mais la vitesse est lente.Après avoir essayé d’utiliser le graphique, il est constaté qu’il n’a pas de cohérence fonctionnelle sur toutes les chaînes.La subsquide a amélioré son nouveau produit « Pool Pool » en termes de balayage d’équilibre.
2Lisser: Plate-forme de sortie de jeton de tête
· Parce que Coinlist gère souvent de nouveaux projets, il est généralement difficile de trouver des fournisseurs de nœuds qu’ils ont l’intention de soutenir.Les grands fournisseurs ne soutiennent pas de nouvelles petites chaînes, mais il peut être difficile et peu fiable de compter sur les petits fournisseurs.Il n’est pas conseillé d’obtenir des données de l’équipe de projet elle-même, car cette infrastructure peut être falsifiée ou maintenue.Sous-marineCoinlist peut contourner complètement ce problème.
· Cette plate-forme est très intéressée par le prochain support natif de la subsquide pour la subsquide, car celaÉliminez complètement les contraintes RPCEssenceCela offre des possibilités de fragments.
Ignorer et malentendu
La subsomie est actuellement sous-évaluée par le marché qu’elle manque de popularité.Bien que ses différences techniques, sa valeur fonctionnelle, sa première attraction des utilisateurs et son énorme potentiel, le projet n’a pas reçu d’attention.La raison comprend:
DansLe marketing de marque est faible:Subsquid a reconnu qu’au cours des premières années, il ne s’est concentré que sur le développement de produits et l’acquisition de clients, et le marketing de marque était insuffisant.Jusqu’à présent, son influence sur les réseaux sociaux et ses activités de marketing n’ont pas transformé efficacement sa valeur à un public plus large.
DansL’émission de jetons fait défautÉtant donné que son travail de marketing n’est pas satisfaisant, la publication de jetons SQD ne provoque pas de sensation comme d’autres projets de blockchain, entraînant une faible évaluation initiale.
DansDifférences techniques profondes:La nature avancée et la technique des produits de la subsomiseur peuvent être difficiles à comprendre et à apprécier par un marché plus large.
Maintenant, l’équipe se concentre sur la notoriété de la marque et avec l’aide de partenaires stratégiques tels que M31 Capital, nous pensons que le projet transmettra mieux sa valeur au marché, ce qui favorisera la grande augmentation des évaluations récentes.
Schéma compétitif
Les principaux concurrents de la subsquide comprennent le graphique, le zettablock et l’espace et le temps.Chaque plate-forme présente ses avantages et ses inconvénients uniques, selon les besoins de projets spécifiques.Nous pensons que le marché Web3 Data Lake / Warehouse sera énorme à long terme, avec plusieurs grands gagnants.
Le graphiqueLe
DansPrédéterminer: Le graphique dépend de la sous-chaîne, et le sous-graphique est un ensemble d’instructions prédéterminé pour les données d’indexation et d’interrogation.Bien que cette méthode fournit une méthode structurée et amicale, elle manque de personnalisation profonde fournie par le processeur modulaire de la subsomiseur.
DansMécanisme d’index: Le graphique utilise un mécanisme d’index plus strict.
Dansperformance: Fournissez des performances moyennes à élevées en fonction de la complexité et de la charge du réseau du sous-MAP.Il offre une faible latence pour la requête et peut se développer plus horizontalement en ajoutant plus d’index.
•
ZettablockLe
DansContrôle concentré et intention décentralisée: Zettablock combine des infrastructures centralisées avec un mécanisme de confiance décentralisé.Cette méthode fournit des index de données réels et des fonctions de requête, mais ne fournit pas de personnalisation modulaire du même niveau en subsquide.
DansPipeline de données: Zettablock se concentre sur les pipelines de données à temps réel avec un processus ETL (extraction, conversion, chargement) personnalisé, mais par rapport aux méthodes de dispersion complètes et modulaires de la subsomide, il utilise un cadre de contrôle plus concentré.
Dansperformance: Conçu pour les index de données réels, le temps de réponse de la requête est court.Il est hautement évolutif et convient aux applications qui ont besoin de pipelines de données à temps réel.
Espace et tempsLe
· Proof et traitement hybride SQL: L’espace et le temps prouve l’intégrité des données via SQL et prend en charge les transactions hybrides et le traitement d’analyse.Bien qu’il fournit des fonctions avancées pour l’intégrité et le traitement des données, son architecture n’est pas modulaire ou personnalisée en tant que subside en termes de pipelines d’index.
· Entrepôt de données: L’architecture de l’espace et du temps est centrée sur des entrepôts de données décentralisés.
Performance: Fournir une optimisation haute performance pour les données de la blockchain et de la chaîne.Soutenez les transactions hybrides et le traitement d’analyse pour assurer une faible latence et l’évolutivité.
>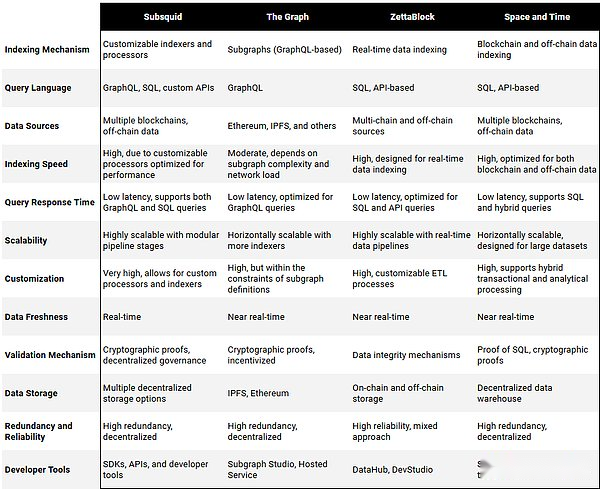
Différenciation des substances
Les méthodes de traitement des données modulaires et personnalisées uniques de la subsquide, associées à son attention à la flexibilité, aux performances et à l’évolutivité, le font se démarquer dans la plate-forme d’index de données et de requête de la blockchain.À mesure que l’industrie mûrit et que les applications deviennent de plus en plus chaîne et complexes, cette fonction deviendra de plus en plus précieuse.
1. 1.Indexeur et processeur personnalisésLe
• Index flexible: permettez aux développeurs de créer des index et des processeurs hautement personnalisés pour faciliter le traitement des tâches intégrées des données complexes et extraire des informations significatives des données de la blockchain.
• Optimisation des performances: les processeurs personnalisés peuvent optimiser les performances pour garantir que les index et les requêtes sont efficaces et évolutifs.
2Pipeline de traitement à plusieurs étagesLe
• Architecture de flux de données: les pipelines de traitement multi-étages divisent l’extraction, la conversion et le stockage des données en étapes indépendantes pour améliorer la gestion et l’évolutivité des tâches de traitement des données.
• Modification: chaque étape du pipeline peut être développée et optimisée indépendamment, fournissant un contrôle de workflow de traitement de données plus important.
3 ..Prise en charge de plusieurs sources de donnéesLe
• Diverses fusions de blockchain: prennent en charge une variété de blockchain et intègrent diverses bases de données, ce qui en fait un outil multi-fonctionnel pour que les développeurs travaillent dans différents écosystèmes de blockchain.
• Adaptabilité: la capacité de la plate-forme à traiter plusieurs sources de données pour s’assurer qu’elle peut répondre aux besoins changeants de l’industrie de la blockchain.
4.SDK
DanscompletSDK: Fournir une boîte à outils de développement logiciel (SDK), y compris les outils et les bibliothèques qui simplifient le développement d’index et de processeurs de données personnalisés.
DansSupport de l’API: Prise en charge une variété d’API pour les requêtes de données, y compris GraphQL et SQL, offrant aux développeurs une flexibilité.
5.
DansDécentralisation: Similaire au graphique et à l’espace et au temps, la subsquide utilise le traitement du réseau de nœuds décentralisé et les données d’index pour garantir la haute disponibilité et la tolérance aux pannes.
DansÉvolutivité: La conception de la plate-forme est une extension horizontale, qui peut gérer efficacement l’augmentation des données et la quantité de requête.
6. Performance et efficacité
Danshaute performance: Optimisations personnalisées à travers les étapes des pipelines de traitement des données, la subsquide peut atteindre des performances élevées dans les indices de données et les tâches de requête.
DansEfficacité d’utilisation des ressources: L’architecture de la plate-forme garantit l’utilisation efficace des ressources informatiques et réduit le coût et la complexité du traitement des données.
Lorsque vous comparez la subsomiseur avec les concurrents les plus matures dans ce domaine, le dernier point est particulièrement important.Comme indiqué dans la figure ci-dessous, les incitations à jetonDépasse mensuellement 50 à 100 fois le revenu du réseau chaque moisLe
>
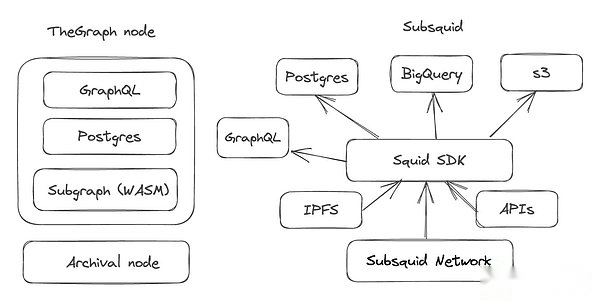
Du point de vue de l’architecture, le nœud d’index « unique » du graphique est une boîte noire qui est utilisée pour exécuter le sous-diagramme compilé dans WasM.Les données proviennent directement du nœud d’archives et de l’IPF local, et les données traitées sont stockées dans la base de données Postgres intégrée.En revanche, le réseau subalterne fournit un accès de données à coût presque zéro, une récupération de données plus fine à partir de plusieurs blocs et d’excellentes fonctions de traitement par lots et de filtrage.
>
Évaluation relative
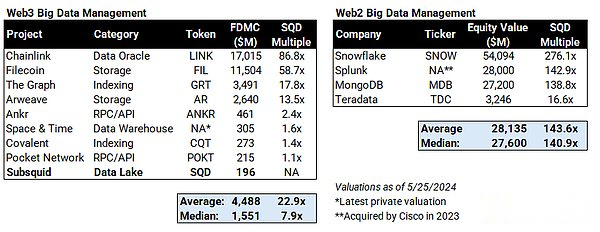
Les meilleurs jetons de la subsquide sont GRT, et son prix de transaction est 18 fois celui de la prime FDV de SQD.L’espace et le temps seront un autre jeton similaire.
À long terme, avec la maturité de l’industrie Web3, il est raisonnable de comparer la subsquide avec les sociétés Web2 similaires d’aujourd’hui, ce qui signifie que si le projet (et l’ensemble du Web3) est réussi, son ascension est aussi élevée que 270 fois.
>
Tam et potentiel croissant en 2030
Bien que la gestion des données de la blockchain et Web3 soient généralement à ses balbutiements, nous pouvons utiliser Web2 comme référence pour TAM TAM à long terme en subsquide.J’ai estimé le tout avantLa montée potentielle du marché web3 en 2030D’ici 2030, le PIB Web3 (revenu total) atteindra 5,6 billions de dollars.Si nous représentons un pourcentage de lacs de données Web2 et de marchés d’entrepôt, nous pouvons l’appliquer aux prévisions du PIB Web3, et d’ici 2030, le marché du lac de données Web3 et de l’entrepôt atteindra 23,6 milliards de dollars.
>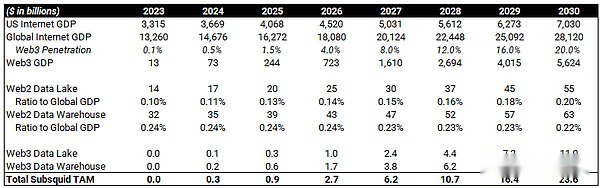
(source:Observation de l’omnichainAinsi que>Future Market InsightAinsi que>Étude de marché experte.
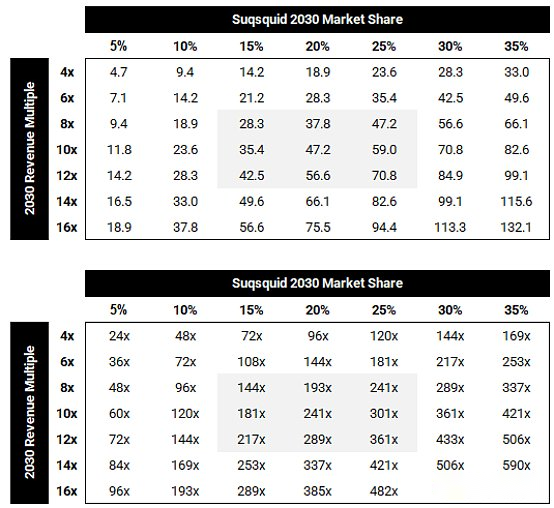
Si nous supposons que la subsquide a une part de marché de 20% en 2030 et utilise un multiple à 10 fois (il est raisonnable pour les actifs à forte croissance, ce qui suit sera introduit en détail), la valeur de SQD atteindra 47 milliards Dollars américains. 240 fois!
Pourquoi 20% sont-ils une part de marché?Tout au long de la dynamique concurrentielle des fournisseurs de gestion des données Web2, les chefs de marché ont maintenu une part de plus de 40% depuis longtemps.Compte tenu de la nature plus dispersée de Web3, nous pensons que 20% est une hypothèse raisonnable de la scène ascendante de la subsquide.
>
Pourquoi est-ce 10 fois des revenus?Il s’agit de la moyenne de 10 ans des sociétés publiques de cloud computing (atteint 22 fois en 2020!).
>
Le tableau de sensibilité de la subsomie en 2030 FDV (un milliard de dollars américains) et le multiple de retour est le suivant:
>
Théorie des investissements
· Opportunités d’investissement à risque / retour très asymétriques; le FDV actuel de la subsistance fournit 18 fois la salle à la hausse de l’espace pour réaliser l’évaluation de la valorisation avec le graphique (GRT). . Pauvre, tandis que l’espace de montée à long terme est plus de 240 fois.
· Stack de technologie Web3 (Data Lake and Warehouse) des actifs très précieux et différenciés dans la partie très précieuse. Plus il est important de conduire à la croissance de l’indice dans la chaîne.
· En raison du marketing de marque inefficace, du manque de bonnes activités d’émission de jetons et de la technologie profonde, elle est négligée et le prix est vraiment faux.
· Malgré le manque de préoccupations de marché, la subsquide a une feuille de route passionnante qui est meilleure que l’architecture du réseau mieux que les grandes entreprises existantes, la première attraction des clients précoces et la fourniture de fonctions d’entrepôt de données complètes et les fonctions de traitement collaboratif et de chiffon.
· De multiples catalyseurs récents incluent le lancement du réseau principal en juin, la prochaine mise à jour du site Web et la réinstallation de la marque, et une nouvelle attention sur le marketing et le plan partenaire stratégique.
Conception technique
La subsomie vise à fournir des niveaux d’évolutivité illimités, un accès aux données sans autorisation, une requête de minimisation de la confiance et des coûts de maintenance faibles.L’architecture garantit:
· Les données d’origine ont été téléchargées du fournisseur de données vers une mémoire permanente.
· Les données sont compressées et distribuées entre les nœuds de réseau.
· L’activité d’exploitation de nœuds paiera un dépôt, ce qui peut être réduit en raison du comportement byzantin.
Chaque nœud utilise DuckDB pour vérifier efficacement les données locales.
· Vous pouvez vérifier les enquêtes en soumettant la réponse de signature au contrat intelligent sur la chaîne.
Architecture de réseau
>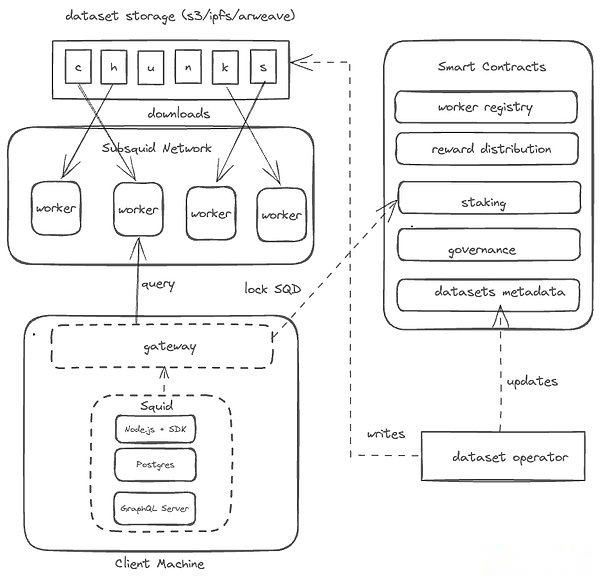
1. 1.Fournisseur de données: Les fournisseurs de données garantissent la qualité et la fourniture en temps opportun de données.Dans la phase de démarrage, les laboratoires de subsquide GmbH sont le seul fournisseur de données et les données proxy extraites de diverses chaînes.Ces données sont vérifiées en comparant le hachage, puis divisées en petits blocs comprimés et enregistrées en stockage à long terme.Ces blocs sont assignés au hasard aux travailleurs.
>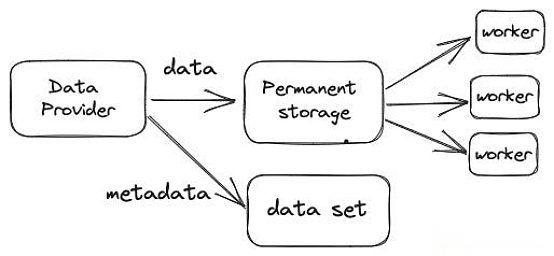
2Travailleur: Stocker et calcul des ressources sur le réseau, fournir des données de manière point-point et obtenir un jeton SQD comme compensation.Chaque travailleur doit enregistrer et hypothéquer les 100 000 jetons carrés sur la chaîne, et la violation de l’accord sera réduite.Les détenteurs de SQD peuvent également confier le jeton à des travailleurs spécifiques pour indiquer leur fiabilité et obtenir des récompenses.
3 ..Planification: Blocs de données soumis par le fournisseur de données pour les travailleurs.Il surveille la mise à jour de l’ensemble de données et de l’ensemble des travailleurs, envoyez une demande aux travailleurs pour télécharger le nouveau bloc ou redéfinir le bloc existant en fonction de la capacité et de l’objectif redondant.Après avoir reçu la demande de mise à jour, les travailleurs ont téléchargé des blocs de données manquants à partir du stockage à long terme.
4. 4 ..Collectionneur de journaux: Collectez les journaux actifs de ping et d’exécution de requête des travailleurs, partez-le et enregistrez-le dans le stockage persistant public.Ces journaux sont signés par le P2P des travailleurs et fixés sur IPF.Ces données sont stockées pendant au moins six mois pour d’autres participants au réseau.
5Récompense: Visitez le journal, calculez la récompense et soumettez une promesse qui peut être reconnue à chaque cycle.Les travailleurs reçoivent ensuite leurs récompenses et les récompenses peuvent expirer après une période de temps.
6.Consommateur de données: Réseau de demande en exploitant la passerelle ou en utilisant les services (public ou privé) fournis par l’extérieur.Chaque passerelle est liée à une adresse de chaîne.Le nombre de demandes soumis par la passerelle est déterminée par le nombre de jetons SQD de verrouillage.Tous les coûts de requête sont de 1 Cu, jusqu’à ce que la requête SQL complexe soit mise en œuvre.
Vérification de la requête
Le réseau de substances conformes fournit l’efficacité des données de requête grâce à la garantie économique et peut être vérifiée sur la chaîne.Toutes les réponses de la requête sont signées par des travailleurs qui exécutent la requête comme un engagement envers la réponse.S’il est déterminé comme incorrect, le dépôt du travailleur sera réduit.La logique de vérification peut être spécifique, y compris les options suivantes:
1. 1.Preuve d’autorité: La liste blanche de la chaîne détermine l’efficacité de la réponse.
2Vérification sur l’optimisme: Après avoir vérifié la demande, n’importe qui peut soumettre une preuve d’une réponse d’erreur.
3 ..Certificat de connaissances zéro: La réponse de vérification de la certification Zero-Knowledge est entièrement adaptée à la demande.La preuve est générée par la preuve de la chaîne et est vérifiée par le contrat intelligent sur la chaîne.
Développement de produits futurs
Bien que nous croyions fermement que les capacités d’indexation et de requête actuelles et l’attraction des utilisateurs de la plate-forme de la substitution sont sérieusement sous-évaluées. La future application Web3 efficace est indispensable.
1. 1.Collaborateur Tee / ZKLe
• La subsquide est sous la solution de processeur d’association de développement pour combiner ses puissantes capacités d’indexation multi-chaînes avec un tee-shirt et ZK de troisième partie (tels que Brevis, Polyhedra, Phala) pour atteindre le contrat sans intelligence et le réseau de ressources de lacs de données sur le réseau de ressources sur le lac Data sur le chaîne de chaîne.La subsistance estime que la fourniture de plusieurs options de vérification est un moyen idéal d’optimiser des cas d’utilisation spécifiques et des performances de charge de travail, plutôt que de développer une seule solution ZK.
• Cela ouvre la porte à des applications de chaîne élevées et conduites aux données (telles que le livre de commandes Dex, l’accord de prêt et le contrat permanent), qui peut être réalisé même sur les TP faibles et la blockchain stricte avec un langage de programmation strict.
2Fonction proxy / ragLe
• Il est prévisible qu’au cours des 10 prochaines années, la plupart des trafics Internet seront générés et consommés par des agents de l’IA.Un point de vue inverse estime qu’aucune des plateformes d’agent d’agent d’IA ne peut dominer le marché, similaire à la plate-forme de construction du site Web (tel que WordPress) ne sert que des domaines spécifiques de passe-temps amateurs.Dans le même temps, la plus grande part de croissance après 2000 est occupée par l’Amazon Cloud Service (AWS) du côté des infrastructures.
• Nous nous attendons à une dynamique similaire dans l’IA et l’espace blockchain.Cependant, le goulot d’étranglement clé peut être un accès aux données.L’objectif de la subsomie est de fournir l’interface réalisable minimale avec un débit élevé, ce qui fait de l’accès aux données un volant de croissance.
Attraction du client et partenaire stratégique
>
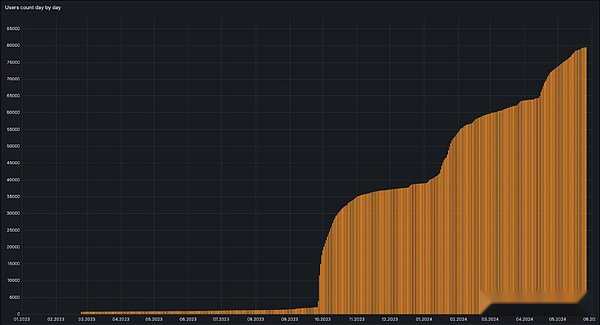
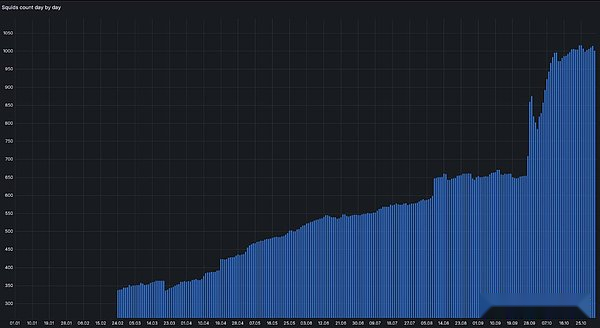
Depuis le lancement du réseau de test à la fin de l’année dernière, le nombre d’utilisateurs, Squid (Cloud Index) et Archive Query (Network Query) et le trafic de données réseau ont montré une tendance à la hausse.
>
>
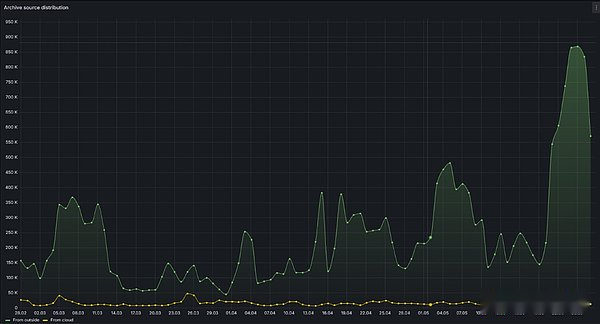
>
>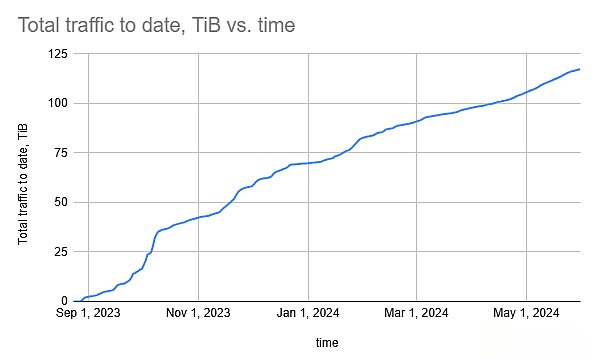
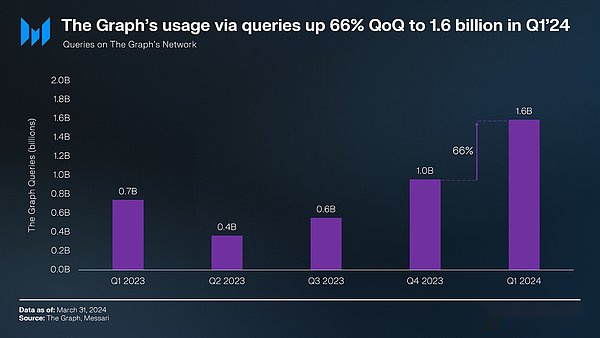
Afin de comparer le graphique, nous devons comparer les demandes de l’utilisateur final.La requête utilisateur final subsquiide peut être envoyée à partir du cloud (peut être suivi) ou une solution d’auto-détention (actuellement ne peut pas être suivie).Pour le premier trimestre de 2024, Yun Quere était de 1,2 milliard de fois.Étant donné que la requête d’archives implémentée par l’auto-hébergement est environ 9 fois (la distribution de la source d’archives ci-dessus), nous pouvons supposer que le nombre d’utilisateurs finaux de l’utilisateur d’auto-host est également 9 fois.Par conséquent, nous pouvons estimerAu premier trimestre, le nombre total de requêtes de fin-utilisateur de la subsquide au premier trimestre était d’environ 10 milliards de fois, ce qui dépassait considérablement le graphique, et le nombre de requêtes de fin-user au cours de la même période était de 1,6 milliard.
>
>
Partenariat Google Cloud (Intégration de BigQuery)
>
BigQuery de Google Cloud est une puissante solution d’entrepôt de données d’entreprise qui permet aux entreprises et aux particuliers de stocker et d’analyser les données de niveau PB.Conçu pour une analyse de données à grande échelle.BigQuery est également entièrement intégré à la propre intelligence commerciale de Google et aux outils externes, permettant aux utilisateurs d’exécuter leur code dans BigQuery et d’utiliser les ordinateurs portables Jupyter ou Apache Zeppelin.
Le projet multi-chaîne peut utiliser la combinaison de la subsomiseur et de la bigQuery pour analyser rapidement son utilisation sur différentes chaînes et obtenir des informations sur les coûts, les coûts d’exploitation et les tendances.Enregistrer les données prévues sur les développeurs de BigQuery.
Diagramme d’itinéraire et catalyseur à venir
1. 1.Réseau principal: Il a été officiellement lancé le 3 juin et il est prévu d’augmenter les incitations SQD en juillet à étendre l’ampleur de la participation.
>
2Rethaping de marque: La rafraîchissement du site Web et la nouvelle stratégie de marque devraient commencer dans les prochaines semaines.
3 ..Support de cosmos: Étendez la fonction de l’écosystème COSMOS et développez la base d’utilisateurs.
4. 4 ..Pas de numéro de licenceSelon la soumission de l’ensemble: Maintenir actuellement des ensembles de données par la substitution de la subsomie et planifier une soumission et une planification décentralisées.
5DécentralisationFlux de base de données SQL: Divisez et synchronisez les bases de données dans les lacs de données pour garantir la précision et la rapidité.
6.Outil d’entreprise: Réalisez Kafka pour le traitement des données en temps réel, Snowflake est utilisé pour l’analyse et le stockage des mégadonnées.
7Traitement collaboratifFonction de chiffon: Actuellement sur la scène POC, l’équipe publiera une feuille de route plus spécifique dans un avenir proche.
Ré-évaluation à court terme et histoire de croissance à long terme
SQD est l’un des jetons liquides les plus attrayants que j’aie jamais vus.Avec plusieurs catalyseurs à venir, nous pensons que le jeton peut être apprécié par 10 à 20 fois à court terme, mais son TAM à long terme offre plus de 240 fois le potentiel ascendant passionnant.Essence