Autor: Zeke, YBB Capital;
Prefacio
El 16 de febrero, OpenAI anunció el lanzamiento del último modelo de difusión de Generación de Video Wensheng llamado «Sora» con su capacidad para generar video de alta calidad en varios tipos de datos visuales, marca otro hito de la generación de IA.A diferencia de Pika y otras herramientas de generación de videos de IA que generan varios segundos de video a partir de múltiples imágenes, Sora entrena en el espacio potencial comprimido de video e imágenes para descomponerlas en el parche de tiempo espacial para generar videos escalables.Además, el modelo muestra la capacidad de los mundos físicos y digitales simulados, y su demostración de 60 segundos se describe como «simulador general del mundo físico».
SORA continúa la ruta técnica del modelo GPT anterior «fuente-transformador-emergencia-emergencia de difusión», lo que indica que su madurez de desarrollo también depende de la potencia informática.Dado que la cantidad de datos requeridos para la capacitación en video es mayor que el texto, se espera que su demanda de energía informática aumente aún más.Sin embargo, como discutimos en nuestro artículo anterior «Popularización de la industria potencial: descentralización del mercado de Becetic», se ha discutido la importancia del poder informático en la era de la IA. Tiempo de intento de ser en el momento de los intentos.Además de Depin, este artículo tiene como objetivo actualizar y mejorar las discusiones pasadas, y pensar en las chispas que pueden producir Web3 y la IA y las oportunidades en la pista en la era de la IA.
Las tres direcciones del desarrollo de IA
La IA es una ciencia y tecnología emergente que tiene como objetivo simular, extender y mejorar la inteligencia humana.Desde el nacimiento de la década de 1950 y 1960, la IA se ha desarrollado durante más de medio siglo, y ahora se ha convertido en una tecnología clave para promover la vida social y las diversas industrias.En el proceso, el desarrollo entrelazado de las tres principales direcciones de investigación del simbolismo, el conectismo y el conductalismo ha sentado las bases para el rápido desarrollo de la inteligencia artificial hoy en día.
Simbolismo
El simbolismo también se conoce como lógico o razonamiento basado en reglas.Este método utiliza símbolos para representar los objetos, conceptos y relaciones en el dominio del problema, y usar un razonamiento lógico para resolver el problema.El simbolismo ha logrado un gran éxito, especialmente en términos de sistemas y conocimientos expertos.La idea central del simbolismo es que el comportamiento inteligente se puede lograr a través de la manipulación simbólica y el razonamiento lógico.
Asociación
O se llama método de red neuronal, para realizar la inteligencia al imitar la estructura y las funciones del cerebro humano.Este método construye una red compuesta por muchas unidades de procesamiento simples (similares a las neuronas) y ajusta la intensidad de conexión entre estas unidades (similar a las sinapsis) para promover el aprendizaje.El conectismo enfatiza la capacidad de aprender y generalizar a partir de datos, de modo que sea particularmente adecuado para el reconocimiento del modo, la clasificación y los problemas continuos de mapeo de entrada y salida.Como evolución del conectismo, el aprendizaje profundo ha realizado avances en los campos del reconocimiento de imágenes, el reconocimiento de voz y el procesamiento del lenguaje natural.
Conductalismo
El conductismo está estrechamente relacionado con la investigación de robots biónicos y sistemas inteligentes autónomos, enfatizando que la inteligencia puede aprender a través de la interacción con el medio ambiente.A diferencia de los dos anteriores, el conductalismo no se centra en simular características internas o procesos de pensamiento, sino para lograr un comportamiento adaptativo a través del ciclo de percepción y acción.El conductismo cree que la inteligencia se refleja a través de la interacción dinámica y el aprendizaje con el entorno, lo que lo hace particularmente efectivo para los robots móviles y los sistemas de control adaptativo que se ejecutan en un entorno complejo e impredecible.
Aunque existen diferencias fundamentales en estas tres direcciones de investigación, pueden interactuar e integrarse entre sí en la investigación y aplicación real de IA para promover conjuntamente el desarrollo de la inteligencia artificial.
Principio AIGC
El campo de desarrollo explosivo de AIGC representa la evolución y la aplicación del conectismo, y puede generar contenido novedoso al imitar la creatividad humana.Estos modelos utilizan grandes conjuntos de datos y algoritmos de aprendizaje profundo para la capacitación y la estructura, relaciones y patrones subyacentes en los datos de aprendizaje.De acuerdo con las indicaciones del usuario, generan salidas únicas, incluidas imágenes, videos, código, música, diseño, traducción, respuestas de preguntas y textos.En la actualidad, AIGC está básicamente compuesto por tres elementos: aprendizaje profundo, big data y capacidades informáticas masivas.
Aprendizaje profundo
El aprendizaje profundo es un subcampo de aprendizaje automático, que utiliza algoritmos que imitan las redes neuronales humanas.Por ejemplo, el cerebro humano consta de millones de neuronas interrelacionadas, y trabajan juntos para aprender y procesar información.Del mismo modo, las redes neuronales de aprendizaje profundo (o redes neuronales artificiales) consisten en neuronas artificiales multicletas que funcionan juntas en las computadoras.Estas neuronas artificiales (denominadas nodos) utilizan cálculos matemáticos para procesar datos.Las redes neuronales artificiales usan estos nodos para resolver problemas complejos a través de algoritmos de aprendizaje profundo.
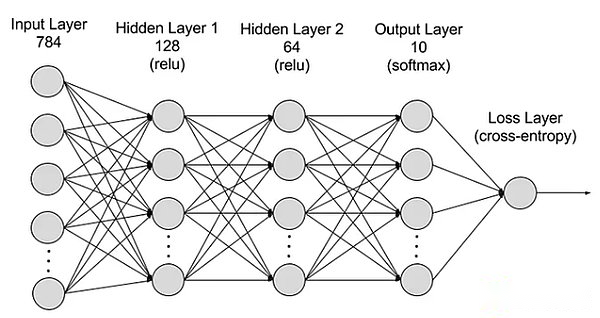 La red neuronal se divide en capas: capas de entrada, capas ocultas y capas de salida, y los parámetros están conectados a diferentes capas.
La red neuronal se divide en capas: capas de entrada, capas ocultas y capas de salida, y los parámetros están conectados a diferentes capas.
Ingrese la capa:La primera capa de red neuronal es responsable de recibir datos de entrada externos.Cada neurona en la capa de entrada corresponde a una característica de los datos de entrada.Por ejemplo, al procesar datos de imagen, cada neurona puede corresponder a un valor de píxel de la imagen.
Capa oculta:La capa de entrada procesa los datos y se pasa más a la red.Estas capas ocultas procesan información en diferentes niveles y ajustan su comportamiento al recibir nueva información.Hay cientos de capas ocultas en redes de aprendizaje profundo, que pueden analizar problemas desde múltiples ángulos.Por ejemplo, cuando una imagen de un animal desconocido que necesita ser clasificado, puede compararla con los animales que ya conoce al verificar la forma de las orejas, el número de piernas y el tamaño de la pupila.La capa oculta en la red neuronal profunda funciona de manera similar.Si los algoritmos de aprendizaje profundo intentan clasificar las imágenes animales, cada capa oculta manejará diferentes características de los animales e intentará clasificarlo con precisión.
Capa de salida:La última capa de la red neuronal es responsable de generar la salida de la red.Cada neurona en la capa de salida representa una posible categoría o valor de salida.Por ejemplo, en el problema de clasificación, cada neurona de capa de salida puede corresponder a una categoría, y en el problema de regresión, la capa de salida puede tener solo una neurona, y su valor representa el resultado predictivo.
parámetro:En las redes neuronales, las conexiones entre diferentes capas están representadas por pesos y desviaciones de que están optimizadas durante el proceso de entrenamiento para que la red pueda identificar con precisión los patrones en los datos y hacer predicciones.El aumento de los parámetros puede mejorar la capacidad de la red neuronal, es decir, la capacidad de aprender y representar el modo complejo en los datos.Sin embargo, esto también aumenta la demanda de energía informática.
Big data
Para realizar una capacitación efectiva, las redes neuronales generalmente necesitan datos grandes, diversos, de alta calidad y multiurce.Constituye la base para los modelos de aprendizaje automático de capacitación y verificación.Al analizar Big Data, los modelos de aprendizaje automático pueden aprender los patrones y las relaciones en los datos, a fin de lograr la predicción o clasificación.
Potencia informática masiva
La estructura múltiple con capas de redes neuronales es complicada, existen muchos parámetros, requisitos de procesamiento de big data, métodos de entrenamiento iterativo (el modelo debe iterarse repetidamente durante el entrenamiento, que involucra los cálculos de transmisión hacia adelante y hacia atrás de cada capa, incluido el cálculo de la función de activación. , Cálculo de la función de pérdida, cálculo del nivel de gradiente y renovación de peso), requisitos de computación de alta precisión, capacidades informáticas paralelas, tecnologías de optimización y regularización, y los procesos de evaluación y verificación de modelos juntos conducen a altos requisitos de alimentación informática.

Sora
Como el último modelo de IA que generan videos de OpenAI, SORA representa un gran progreso del procesamiento de inteligencia artificial y la comprensión de los datos visuales diversificados.Al usar la red de compresión de video y la tecnología de parche de tiempo espacial, SORA puede convertir datos visuales masivos capturados por diferentes dispositivos en todo el mundo en una forma de representación unificada, logrando así un procesamiento eficiente y una comprensión del contenido visual complejo.Utilizando condiciones de texto para difundir modelos, Sora puede generar videos o imágenes que coinciden con las indicaciones de texto, que muestran una alta creatividad y adaptabilidad.
Sin embargo, aunque Sora ha logrado avances en la interacción de la generación y simulación de videos en el mundo real, todavía enfrenta algunas limitaciones, incluida la precisión de la simulación del mundo físico, la consistencia del video de crecimiento, las instrucciones de texto complejas y el entrenamiento y el entrenamiento y Generación de eficiencia de generación.En esencia, Sora continúa la vieja ruta técnica de la «emergencia de difusión-transformadora de big data» a través del poder informático de monopolio de OpenAI y las ventajas de primer movimiento, y se da cuenta de una estética bruta.Otras compañías de inteligencia artificial aún tienen el potencial de superar a través de la innovación tecnológica.
Aunque la relación entre Sora y la cadena de bloques no es excelente, creo que en el próximo año o dos, debido a la influencia de Sora, otras herramientas de generación de IA de alta calidad aparecerán y se desarrollarán rápidamente, impactar, depinar, etc.Por lo tanto, es necesario tener una comprensión general de Sora.
Cuatro formas de fusión de AI X Web3
Como se discutió anteriormente, podemos entender que los elementos básicos requeridos por la generación de IA son esencialmente tres: algoritmos, datos y potencia informática.Por otro lado, considerando su universalidad y efecto de salida, la IA es una herramienta que cambia completamente el método de producción.Al mismo tiempo, el mayor impacto de la cadena de bloques es dual: la reorganización de las relaciones de producción y la descentralización.
Por lo tanto, creo que la colisión de estas dos tecnologías puede producir las siguientes cuatro rutas:
Descentralización
Como se mencionó anteriormente, esta sección tiene como objetivo actualizar el estado de las capacidades informáticas.Cuando se trata de IA, la potencia informática es un aspecto indispensable.La aparición de Sora hizo la inimaginable demanda de IA de poder informático.Recientemente, durante el Foro Económico Mundial de Davos en Suiza en 2024, el CEO de OpenAI, Sam Altman, declaró públicamente que la potencia informática y la energía son las mayores limitaciones en la actualidad, lo que implica que su importancia futura puede incluso ser equivalente a la moneda.Posteriormente, el 10 de febrero, Sam Altman anunció un plan impactante en Twitter que recaudará 7 billones de dólares estadounidenses (equivalente al 40%del PIB de China en 2023) para reformar por completo la actual industria de semiconductores globales.Mi pensamiento anterior sobre el poder informático se limita al bloqueo nacional y al monopolio corporativo;
Por lo tanto, la importancia de la potencia informática descentralizada es autodidacta.Las características de la cadena de bloques pueden resolver el problema del monopolio extremo en la potencia informática actual, así como el costo costoso relacionado con la obtención de una GPU dedicada.Desde la perspectiva de los requisitos de IA, el uso de la potencia informática se puede dividir en dos direcciones: razonamiento y capacitación.Hay muy pocos proyectos centrados en la capacitación, porque las redes descentralizadas necesitan integrar el diseño de la red neuronal, y los requisitos de hardware son extremadamente altos.Por el contrario, el razonamiento es relativamente simple, porque el diseño de la red descentralizado no es tan complicado, y los requisitos para el hardware y el ancho de banda también son bajos, lo cual es una dirección más convencional.
El mercado de energía informática centralizada tiene una amplia gama de imaginación, a menudo vinculadas con las palabras clave de «billones de niveles», que también es el tema más fácil de la era de la IA.Sin embargo, observando los muchos proyectos que han aparecido recientemente, la mayoría de ellos parecen usar tendencia para considerar intentos inesperados.A menudo elevan la bandera de la descentralización, pero evitan discutir la ineficiencia de las redes descentralizadas.Además, el grado de homogeneidad del diseño es muy alto.
Algoritmo y sistema de colaboración modelo
Los algoritmos de aprendizaje automático son algoritmos que pueden aprender modos y reglas de los datos y tomar predicciones o decisiones basadas en ellos.El algoritmo es denso en la tecnología, porque su diseño y optimización requieren un profundo conocimiento profesional e innovación tecnológica.Los algoritmos son el núcleo de la capacitación de modelos de inteligencia artificial, definiendo cómo transformar los datos en ideas o decisiones útiles.La generación común de algoritmos de IA incluye la generación de redes de confrontación (GaN) (GaN), auto -engoder de transformadores (VAE) y transformadores. Luego se usa para entrenar modelos de IA especializados.
Entonces, ¿hay tantos algoritmos y modelos, cada uno de los cuales es posible integrarlos en un modelo común?Bittersor es un proyecto reciente que ha atraído mucha atención.Otros proyectos que se centran en esta dirección incluyen Commune AI (colaboración en código), pero los algoritmos y los modelos son estrictamente confidenciales para las empresas de IA y no son fáciles de compartir.
Por lo tanto, la narración del ecosistema colaborativo de IA es novedosa e interesante.El ecosistema colaborativo utiliza las ventajas de la cadena de bloques para integrar la desventaja del algoritmo AI aislado, pero queda por observar si puede crear un valor correspondiente.Después de todo, la compañía líder de IA con algoritmos y modelos independientes tiene fuertes actualizaciones, iteraciones y capacidades de integración.Por ejemplo, OpenAI se ha desarrollado desde modelos de generación de texto tempranos hasta modelos de generación de múltiples campos en menos de dos años.Los proyectos como Bittersor pueden necesitar explorar nuevas rutas en sus modelos y campos objetivo de algoritmo.
Descentralización big data
Desde un simple punto de vista, el uso de datos de privacidad para alimentar los datos de IA y anotación es muy consistente con la tecnología blockchain.Además, el almacenamiento de datos puede beneficiar a los proyectos DEPIN como FIL y AR.Desde una perspectiva más complicada, el uso de datos de blockchain para el aprendizaje automático para resolver la accesibilidad de los datos de blockchain es otra dirección interesante (una de exploración de Giza).
Teóricamente, se puede acceder a los datos de blockchain en cualquier momento, lo que refleja el estado de toda la cadena de bloques.Sin embargo, para las personas fuera del ecosistema blockchain, no es fácil acceder a estas grandes cantidades de datos.El almacenamiento de toda la cadena de bloques requiere un rico conocimiento profesional y una gran cantidad de recursos de hardware profesionales.Para superar los desafíos del acceso a los datos de blockchain, han aparecido varias soluciones en la industria.Por ejemplo, los proveedores de RPC proporcionan acceso de nodo a través de la API, y los servicios de índice hacen posible la recuperación de datos a través de SQL y GraphQL, lo que juega un papel vital en la resolución de este problema.Sin embargo, estos métodos tienen sus limitaciones.Los servicios de RPC no son adecuados para casos de alta densidad que necesitan una gran cantidad de consulta de datos, y a menudo no pueden satisfacer las necesidades.Al mismo tiempo, aunque el servicio índice proporciona un método de recuperación de datos más estructural, la complejidad del protocolo Web3 hace que sea extremadamente difícil para consultas estructurales eficientes, y a veces se requieren cientos o incluso miles de código complejo.Esta complejidad es un gran obstáculo para los profesionales de datos generales y aquellos que tienen una comprensión limitada de los detalles de Web3.Estos efectos acumulativos restringidos destacan la necesidad de acceder y usar datos blockchain que requieren más acceso y uso, lo que puede promover una aplicación e innovación más amplias en el campo.
Por lo tanto, la combinación de ZKML (prueba de conocimiento automático del aprendizaje automático, reduciendo la carga del aprendizaje automático en la cadena) y los datos de blockchain de alta calidad pueden crear conjuntos de datos que resuelven la accesibilidad de los datos de blockchain.La IA puede reducir significativamente la barrera de acceso de los datos de blockchain.Con el tiempo, los desarrolladores, investigadores y entusiastas del aprendizaje automático pueden acceder a conjuntos de datos más de alta calidad y relacionados para crear soluciones efectivas e innovadoras.
AI Empoderamiento DAPP
Desde el estallido de ChatGPT3 en 2023, el empoderamiento de DAPP de AI se ha convertido en una dirección muy común.La inteligencia artificial amplia basada en la aplicación se puede integrar a través de API, simplificando así las plataformas de datos inteligentes, los robots comerciales, la enciclopedia blockchain y otras aplicaciones.Por otro lado, también puede actuar como un robot de chat (como Myshell) o compañero de IA (IA de insomnio), e incluso puede usar IA generatoria para crear NPC en el juego blockchain.Sin embargo, debido a que el umbral técnico es bajo, la mayoría de ellos son solo ajustes después de la API integrada, y la integración del proyecto en sí no es perfecta, por lo que rara vez se menciona.
Pero con la llegada de Sora, personalmente creo que el empoderamiento de AI de GameFI (incluido el universo Yuan) y las plataformas creativas serán el foco del futuro.Dada la naturaleza inferior del campo Web3, es poco probable que produzca productos que puedan competir con juegos tradicionales o empresas creativas.Sin embargo, la aparición de Sora puede romper este punto muerto (tal vez solo dos o tres años).A juzgar por la manifestación de Sora, tiene el potencial de competir con compañías de drama cortos.La cultura comunitaria activa de la Web3 también puede dar a luz muchas ideas interesantes.
en conclusión
Con el desarrollo continuo de la generación de herramientas de inteligencia artificial, presenciaremos más «momentos de iPhone» innovadores en el futuro.Aunque las personas son escépticas sobre la integración de AI y Web3, creo que la dirección actual es básicamente correcta, y solo se requieren tres puntos de dolor principales: necesidad, eficiencia y ajuste.Aunque la integración de los dos todavía está en la etapa de exploración, no evita que este camino se convierta en la corriente principal del próximo mercado alcista.
Mantener suficiente curiosidad y apertura de las cosas nuevas es nuestra mentalidad básica.Históricamente, la transformación de un carro a un automóvil se resolvió instantáneamente, ya que se mostraron las inscripciones y el NFT pasado.Mantener demasiado prejuicio solo causará oportunidades perdidas.