
Source: Technologie Tencent
Le co-fondateur et PDG de Nvidia, Huang Renxun, a prononcé un discours d’ouverture à Computex 2024 (2024 Taipei International Computer Exhibition), partageant comment l’ère de l’intelligence artificielle peut promouvoir la nouvelle révolution industrielle mondiale.
Voici les points clés de ce discours:
① Huang Renxun a montré la dernière version produite en masse de Blackwell Chips et a déclaré qu’il lancera Blackwell Ultra AI Chips en 2025. La prochaine génération de plate-forme AI est nommée Rubin. « Une fois par an », enfreignant la loi « Moore » « .
② Huang Renxun a affirmé que NVIDIA avait promu la naissance d’un modèle de langue large, qui a changé l’architecture GPU après 2012 et a intégré toutes les nouvelles technologies sur un seul ordinateur.
La technologie de calcul accélérée de Nvidia a contribué à atteindre une augmentation de 100 fois, tandis que la consommation d’énergie n’est augmentée que 3 fois, et le coût est 1,5 fois.
④ Huang Renxun s’attend à ce que la prochaine génération d’IA doit comprendre le monde physique.La méthode qu’il a donnée est de laisser l’IA apprendre à travers des données vidéo et synthétiques et de laisser l’IA apprendre les unes des autres.
⑤ Huang Renxun a même finalisé une traduction chinoise pour le jeton en ppt – ci Yuan.
⑥ Huang Renxun a déclaré que l’ère des robots est arrivée et que tous les objets en mouvement fonctionneront indépendamment à l’avenir.

Ce qui suit est la transcription complète du discours de deux heures compilé par Tencent Technology:
Chers invités, je suis très honoré d’être ici.Tout d’abord, je tiens à remercier l’Université de Taiwan de nous avoir fourni ce gymnase comme lieu pour les événements.La dernière fois que je suis venu ici, c’est quand j’ai obtenu mon diplôme de l’Université de Taiwan.Aujourd’hui, il y a beaucoup de choses que nous allons explorer, donc je dois accélérer et transmettre le message d’une manière rapide et claire.Nous avons beaucoup de sujets à dire, et j’ai beaucoup d’histoires passionnantes à partager avec vous.
Je suis très heureux d’être ici à Taïwan, en Chine, où beaucoup de nos partenaires sont ici.En fait, ce n’est pas seulement une partie indispensable de l’histoire du développement de Nvidia, mais aussi un nœud clé pour nous et nos partenaires pour promouvoir conjointement l’innovation envers le monde.Nous travaillons avec de nombreux partenaires pour construire une infrastructure d’intelligence artificielle dans le monde entier.Aujourd’hui, je voudrais discuter de plusieurs sujets clés avec vous:
1) Quels progrès sont réalisés dans notre travail conjoint et quelle est la signification de ces progrès?
2) Qu’est-ce que l’intelligence artificielle générative?Comment cela affectera-t-il notre industrie, et même toutes les industries?
3) Un plan sur la façon dont nous pouvons aller de l’avant et comment saisir cette incroyable opportunité?
Que se passera-t-il ensuite?L’IA générative et son impact profond, notre plan stratégique, sont tous des sujets passionnants que nous allons explorer.Nous nous tenons au point de départ du redémarrage de l’industrie informatique, et une nouvelle ère créée par vous et créée par vous est sur le point de commencer.Vous êtes maintenant prêt pour le prochain voyage important.
1 et 1Une nouvelle ère de l’informatique commence
Mais avant de commencer la discussion approfondie, je veux souligner une chose: Nvidia est située à l’intersection des graphiques informatiques, de la simulation et de l’intelligence artificielle, qui forme l’âme de notre entreprise.Aujourd’hui, tout ce que je vais vous montrer est basé sur la simulation.Ce ne sont pas seulement des effets visuels, ils sont l’essence des mathématiques, des sciences et de l’informatique, et l’architecture informatique à couper le souffle.Aucune animation n’est préparée, tout est un chef-d’œuvre de notre propre équipe.C’est ce que Nvidia comprend, et nous incorporons tout cela dans le monde virtuel omniversé dont nous sommes fiers.Maintenant, profitez de la vidéo!
La consommation d’énergie dans les centres de données du monde entier augmente fortement, tandis que les coûts informatiques augmentent également.Nous sommes confrontés au grave défi de l’inflation informatique, qui ne peut évidemment pas être maintenu pendant longtemps.Les données continueront de croître de façon exponentielle, tandis que l’expansion des performances du processeur est difficile à se développer aussi rapidement qu’auparavant.Cependant, une approche plus efficace émerge.
Depuis près de deux décennies, nous travaillons sur une recherche informatique accélérée.La technologie CUDA améliore les capacités du processeur, le déchargement et l’accélération des tâches que les processeurs spéciaux peuvent effectuer plus efficacement.En fait, en raison du ralentissement ou même de la stagnation de l’expansion des performances du processeur, les avantages de l’informatique accélérée deviennent de plus en plus significatifs.Je prédis que chaque application à forte intensité de traitement sera accélérée et, dans un avenir proche, chaque centre de données sera entièrement accéléré.

Maintenant, le choix de l’informatique accélérée est une décision sage, qui est devenue un consensus de l’industrie.Imaginez qu’une application prend 100 unités de temps pour terminer.Que ce soit 100 secondes ou 100 heures, nous ne pouvons souvent pas supporter l’application AI qui fonctionne pendant des jours ou même des mois.
Parmi ces 100 unités de temps, une unité de temps implique un code qui doit être exécuté séquentiellement.La logique de contrôle du système d’exploitation est indispensable et doit être strictement exécutée conformément à la séquence d’instructions.Cependant, il existe de nombreux algorithmes, tels que l’infographie, le traitement d’image, la simulation physique, l’optimisation combinatoire, le traitement des graphiques et le traitement de la base de données, en particulier l’algèbre linéaire largement utilisée dans l’apprentissage en profondeur, qui sont bien adaptées à l’accélération grâce à un traitement parallèle.Pour y parvenir, nous avons inventé une architecture innovante qui combine parfaitement le GPU avec le CPU.
Un processeur dédié est en mesure d’accélérer les tâches qui prennent du temps à des vitesses incroyables.Étant donné que les deux processeurs peuvent travailler en parallèle, ils fonctionnent chacun indépendamment et indépendamment.Cela signifie que les tâches qui nécessitaient à l’origine 100 unités de temps peuvent désormais être effectuées en seulement 1 unité de temps.Bien que cet effet d’accélération semble incroyable, je vais aujourd’hui valider cette déclaration avec une série d’exemples.

Les avantages de cette amélioration des performances sont incroyables, avec une accélération de 100x, tandis que seulement environ 3 fois augmenter la puissance et seulement 50% augmentent des coûts.Nous avons déjà pratiqué cette stratégie dans l’industrie PC.L’ajout d’un GPU GeForce de 500 $ à votre PC améliorera considérablement ses performances, tout en augmentant sa valeur globale à 1 000 $.Dans le centre de données, nous avons adopté la même approche.Un centre de données d’un milliard de dollars s’est instantanément transformé en une puissante usine d’intelligence artificielle après avoir ajouté un GPU de 500 millions de dollars.Aujourd’hui, ce changement se produit dans le monde.
Les économies de coûts sont tout aussi choquantes.Pour chaque 1 $ investi, vous obtenez jusqu’à 60x gains de performance.L’accélération est 100 fois, tandis que la puissance n’est que 3 fois, et le coût n’est que 1,5 fois.Les économies sont réelles!
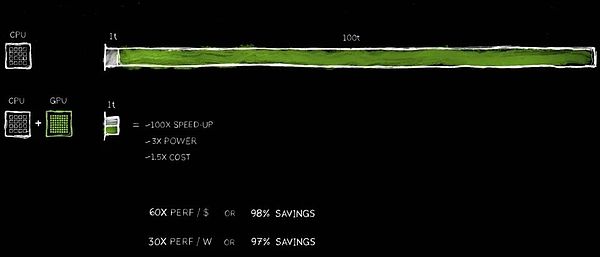
Apparemment, de nombreuses entreprises dépensent des centaines de millions de dollars pour le traitement des données dans le cloud.Économiser des centaines de millions de dollars devient raisonnable lorsque les données sont traitées plus rapidement.Pourquoi cela se produit-il?La raison en est simple, nous avons connu un goulot d’étranglement à long terme de l’efficacité dans l’informatique générale.
Maintenant, nous le reconnaissons enfin et avons décidé de l’accélérer.En adoptant un processeur dédié, nous pouvons retrouver beaucoup de gains de performance auparavant négligés, économisant beaucoup d’argent et d’énergie.C’est pourquoi je dis, plus vous achetez, plus vous économisez.
Maintenant, je vous ai montré les chiffres.Bien qu’ils ne soient pas précis à quelques décimales, cela reflète avec précision les faits.Cela peut être appelé « Mathématiques des PDG ».Bien que les mathématiques du PDG ne poursuivent pas une extrême précision, la logique derrière elle est correcte – plus vous achetez la puissance de calcul accélérée, plus vous économisez.
2350 bibliothèques de fonctions aident à ouvrir de nouveaux marchés
Les résultats de l’informatique accélérée sont en effet extraordinaires, mais le processus de mise en œuvre n’est pas facile.Pourquoi cela économise-t-il autant d’argent, mais les gens n’ont pas adopté cette technologie plus tôt?La raison en est qu’il est trop difficile à mettre en œuvre.
Il n’y a pas de logiciel prêt à l’emploi qui peut être exécuté simplement en accélérant le compilateur, et l’application peut être instantanément accélérée de 100 fois.Ce n’est ni logique ni réaliste.Si c’était si facile, les fabricants de processeurs auraient fait cela il y a longtemps.
En fait, pour atteindre l’accélération, le logiciel doit être entièrement réécrit.C’est la partie la plus difficile du processus.Le logiciel doit être repensé et recodé afin de convertir des algorithmes qui fonctionnaient à l’origine sur le CPU en formats qui peuvent être exécutés en parallèle sur l’accélérateur.
Bien que cette recherche en informatique soit difficile, nous avons fait des progrès importants au cours des 20 dernières années.Par exemple, nous avons lancé la populaire Bibliothèque de Deep Learning Cudnn, spécialisée dans la gestion de l’accélération du réseau neuronal.Nous fournissons également une bibliothèque pour les simulations de physique de l’intelligence artificielle pour des applications telles que la dynamique des fluides qui nécessitent le respect des lois physiques.De plus, nous avons une nouvelle bibliothèque appelée Aerial, qui utilise CUDA pour accélérer la technologie radio 5G, nous permettant d’utiliser des logiciels pour définir et accélérer les réseaux de télécommunications comme les réseaux Internet définis par logiciel.

Ces capacités d’accélération améliorent non seulement les performances, mais nous aident également à transformer toute l’industrie des télécommunications en une plate-forme informatique similaire au cloud computing.De plus, la plate-forme de lithographie Coolitho Computing est également un bon exemple, ce qui améliore considérablement l’efficacité de la fabrication de masques, la partie la plus intensive en calcul du processus de fabrication des puces.Des entreprises telles que TSMC ont déjà commencé à utiliser Coolitho pour la production, ce qui éconore non seulement l’énergie, mais réduit également considérablement les coûts.Leur objectif est de se préparer au développement ultérieur des algorithmes et à l’énorme puissance de calcul nécessaire pour fabriquer des transistors plus profonds et plus étroits en accélérant la pile technologique.
Pair of Bricks est notre fière bibliothèque de séquençage de gènes, qui a le premier débit de séquençage des gènes au monde.Co Opt est une bibliothèque d’optimisation combinée remarquable qui peut résoudre des problèmes complexes tels que la planification des itinéraires, l’optimisation des itinéraires et les problèmes d’agence de voyage.On pense généralement que ces problèmes doivent être résolus par les ordinateurs quantiques, mais nous avons créé un algorithme extrêmement rapide grâce à une technologie informatique accélérée, battant avec succès 23 records mondiaux.
Coup quantum est un système de simulation informatique quantique que nous avons développé.Un simulateur fiable est essentiel pour les chercheurs qui souhaitent concevoir des ordinateurs quantiques ou des algorithmes quantiques.Sans ordinateurs quantiques réels, Nvidia Cuda – ce que nous appelons l’ordinateur le plus rapide du monde – est devenu leur outil préféré.Nous fournissons un simulateur qui peut simuler le fonctionnement des ordinateurs quantiques et aider les chercheurs à faire des percées dans le domaine de l’informatique quantique.Ce simulateur a été largement utilisé par des centaines de milliers de chercheurs à travers le monde et a été intégré dans tous les principaux cadres informatiques quantiques, fournissant un fort soutien aux centres de supercomputing scientifiques du monde entier.
De plus, nous avons lancé la bibliothèque de traitement des données Kudieff, qui est spécialement conçue pour accélérer le traitement des données.Le traitement des données explique la grande majorité des dépenses de cloud d’aujourd’hui, donc l’accélération du traitement des données est crucial pour les économies de coûts.QDF est un outil d’accélération que nous avons développé qui peut améliorer considérablement les performances des principales bibliothèques de traitement des données dans le monde, telles que Spark, Pandas, Polar et NetworkX Graph Processing Bases.
Ces bibliothèques sont un composant clé de l’écosystème, et ils permettent à l’informatique accélérée d’être largement utilisée.Sans nos bibliothèques spécifiques au domaine soigneusement conçues telles que CUDNN, les scientifiques de l’apprentissage en profondeur dans le monde pourraient ne pas être en mesure d’utiliser pleinement leur potentiel avec CUDA, car il existe des différences importantes entre CUDA et les algorithmes utilisés dans les cadres d’apprentissage en profondeur tels que Tensorflow et Pytorch.Ce n’est pas aussi peu pratique que de faire des graphiques informatiques sans OpenGL ou de traitement des données sans SQL.
Ces bibliothèques spécifiques au domaine sont des trésors de notre entreprise et nous avons actuellement plus de 350 bibliothèques de ce type.Ce sont ces bibliothèques qui nous maintiennent ouverts et en avance sur le marché.Aujourd’hui, je vais vous montrer des exemples plus excitants.
La semaine dernière, Google a annoncé qu’ils avaient déployé des QDF sur le cloud et réussi à accélérer les pandas.Pandas est la bibliothèque de science des données la plus populaire au monde, utilisée par 10 millions de scientifiques des données du monde entier, avec des téléchargements mensuels jusqu’à 170 millions de fois.C’est comme Excel des scientifiques des données, leur assistant de droite pour le traitement des données.
Maintenant, cliquez simplement sur la plate-forme de centre de données cloud de Google Colab et vous pouvez expérimenter les performances puissantes apportées par les pandas accélérés par QDF.Cette accélération est vraiment incroyable, tout comme la démo que vous venez de voir, elle termine la tâche de traitement des données presque instantanément.
3 et 3Cuda réalise un cycle vertueux
Cuda a atteint ce que les gens appellent un point critique, mais la réalité est meilleure que cela.Cuda a atteint un cycle de développement vertueux.En repensant à l’histoire et au développement de diverses architectures et plates-formes informatiques, nous pouvons constater que de telles boucles ne sont pas courantes.Prenons l’exemple du CPU du microprocesseur.
La création d’une nouvelle plate-forme informatique fait souvent face au dilemme de «Il y a d’abord des poulets ou des œufs en premier».Sans le soutien des développeurs, il est difficile pour la plate-forme d’attirer des utilisateurs;Ce dilemme a affligé le développement de plusieurs plateformes informatiques au cours des 20 dernières années.
Cependant, nous avons réussi à rompre ce dilemme en déployant continuellement des bibliothèques spécifiques au domaine et des bibliothèques accélérées.Aujourd’hui, nous avons 5 millions de développeurs dans le monde qui utilisent la technologie CUDA pour servir presque tous les grands domaines de l’industrie et des sciences, des soins de santé, des services financiers à l’industrie informatique, l’industrie automobile.
Alors que la clientèle continue de se développer, les fournisseurs de services OEM et cloud ont également commencé à développer l’intérêt pour nos systèmes, ce qui entraîne plus de systèmes pour entrer sur le marché.Ce cycle vertueux a créé d’énormes opportunités pour nous, nous permettant d’élargir notre échelle et d’augmenter les investissements en R&D, favorisant ainsi le développement accéléré de plus d’applications.
L’accélération de chaque application signifie une réduction significative des coûts informatiques.Comme je l’ai déjà montré, une accélération de 100x peut porter jusqu’à 97,96%, soit près de 98% d’économies.Alors que nous augmentons l’accélération du calcul de 100 fois à 200 fois, puis à 1000 fois, le coût marginal du calcul continue de baisser, montrant des avantages économiques remarquables.
Bien sûr, nous pensons qu’en réduisant considérablement les coûts informatiques, les marchés, les développeurs, les scientifiques et les inventeurs continueront de dénicher de nouveaux algorithmes qui consomment plus de ressources informatiques.Jusqu’à certains points, un changement profond se produira tranquillement.Lorsque le coût marginal de l’informatique devient si faible, une toute nouvelle façon d’utiliser des ordinateurs naîtra.
En fait, ce changement se produit sous nos yeux.Au cours de la dernière décennie, nous avons utilisé des algorithmes spécifiques pour réduire le coût marginal de l’informatique par un million de fois étonnant.Aujourd’hui, l’utilisation de toutes les données sur Internet pour former de grands modèles de langue est devenue un choix logique et naturel et n’est plus remis en question.
L’idée – construire un ordinateur qui peut traiter des quantités massives de données et de programme elle-même – est la pierre angulaire de la montée de l’intelligence artificielle.La montée de l’intelligence artificielle est entièrement possible parce que nous croyons fermement que si nous rendons l’informatique moins chère, il y aura toujours d’énormes utilisations.Aujourd’hui, le succès de Cuda a prouvé la faisabilité de ce cycle vertueux.
Avec l’expansion continue de la Fondation d’installation et la réduction continue des coûts informatiques, de plus en plus de développeurs sont en mesure de réaliser leur potentiel innovant et de proposer plus d’idées et de solutions.Cette innovation a entraîné une augmentation de la demande du marché.Maintenant, nous nous tenons à un tournant majeur.Cependant, avant de le montrer plus loin, je veux souligner que ce que je veux montrer ci-dessous ne serait pas possible sans la percée des technologies CUDA et AI modernes – en particulier l’IA génératrice.
Il s’agit du projet Earth 2 – une idée ambitieuse de créer le jumeau numérique de la Terre.Nous simulerons le mouvement de la Terre entière pour prédire ses changements futurs.Grâce à de telles simulations, nous pouvons mieux prévenir les catastrophes et avoir une compréhension plus approfondie des effets du changement climatique, nous permettant de mieux nous adapter à ces changements et même de commencer à changer nos comportements et nos habitudes maintenant.
Le projet Earth 2 est probablement l’un des projets les plus difficiles et ambitieux au monde.Nous avons fait des progrès significatifs dans ce domaine chaque année, et les résultats de cette année sont particulièrement remarquables.Maintenant, permettez-moi de vous montrer ces progrès passionnants.
Dans un avenir proche, nous aurons des capacités de prévision météorologiques continues couvrant chaque kilomètre carré de la planète.Vous comprendrez toujours comment le climat changera, et cette prédiction continuera de fonctionner parce que nous formons l’IA, ce qui nécessite une énergie extrêmement limitée.Ce serait une réalisation incroyable.J’espère que vous l’apprécierez, et plus important encore, cette prédiction a été réellement faite par Jensen AI, pas moi-même.Je l’ai conçu, mais les prédictions finales sont présentées par Jensen AI.
Alors que nous nous efforçons d’améliorer continuellement les performances et de réduire les coûts, les chercheurs ont découvert Cuda en 2012, qui a été le premier contact de Nvidia avec l’intelligence artificielle.Cette journée est cruciale pour nous car nous avons fait le sage choix de travailler en étroite collaboration avec les scientifiques pour rendre l’apprentissage en profondeur possible.L’émergence d’Alexnet a réalisé une énorme percée dans la vision par ordinateur.
4La montée des superordinateurs de l’IA n’a pas été reconnue au début
Mais la sagesse la plus importante est que nous prenons du recul et comprenons profondément la nature de l’apprentissage en profondeur.Quelle est sa base?Quel est son impact à long terme?Quel est son potentiel?Nous réalisons que cette technologie a un grand potentiel pour continuer à élargir les algorithmes inventés et découverts il y a des décennies, combinant plus de données, de plus grands réseaux et des ressources informatiques cruciales, l’apprentissage en profondeur peut soudainement réaliser des tâches humaines que les algorithmes ne peuvent pas atteindre.
Maintenant, imaginez ce qui se passerait si nous étendions davantage notre architecture et avions un réseau plus grand, plus de données et des ressources informatiques?Nous nous engageons donc à tout réinventer.Depuis 2012, nous avons changé l’architecture du GPU, ajouté le noyau du tenseur, inventé NV-Link, lancé CUDNN, Tensorrt, Nickel, acquis Mellanox et lancé le serveur Triton Inference.
Ces technologies sont intégrées sur un tout nouvel ordinateur, qui a dépassé l’imagination de chacun à l’époque.Personne ne s’attendait à ce que personne ne fasse une telle demande, et personne ne comprenait même son plein potentiel.En fait, je ne sais pas si quelqu’un voulait l’acheter.
Mais lors de la conférence du GTC, nous avons officiellement publié cette technologie.Une startup de San Francisco appelée Openai a rapidement remarqué nos résultats et nous a demandé de fournir un appareil.J’ai personnellement envoyé le premier supercalculateur d’intelligence artificielle au monde DGX à Openai.
En 2016, nous avons continué d’élargir notre échelle de R&D.D’un seul supercalculateur d’intelligence artificielle à une seule application d’intelligence artificielle, il s’est étendu au lancement d’un supercalculateur plus grand et puissant en 2017.Avec l’avancement continu de la technologie, le monde a été témoin de la montée en puissance de Transformer.L’émergence de ce modèle nous permet de traiter des quantités massives de données et d’identifier et d’apprendre des modèles continus sur de longues portées.
Aujourd’hui, nous avons la capacité de former ces grands modèles de langue pour réaliser des percées majeures dans la compréhension du langage naturel.Mais nous ne nous sommes pas arrêtés là, nous avons continué à avancer et avons construit un modèle plus grand.En novembre 2022, sur des supercalculateurs d’intelligence artificielle extrêmement puissants, nous utilisons des dizaines de milliers de GPU NVIDIA pour la formation.
À peine 5 jours plus tard, Openai a annoncé que Chatgpt compte 1 million d’utilisateurs.Ce taux de croissance incroyable a grimpé à 100 millions d’utilisateurs en seulement deux mois, établissant le record de croissance le plus rapide de l’historique des applications.La raison est très simple – l’expérience utilisateur de Chatgpt est pratique et magique.
Les utilisateurs peuvent interagir naturellement et en douceur avec les ordinateurs, comme s’ils communiquaient avec de vraies personnes.Sans instructions fastidieuses ou descriptions claires, Chatgpt peut comprendre les intentions et les besoins de l’utilisateur.
L’émergence de Chatgpt marque un changement de fabrication d’époches, et cette diapositive capture cette tournure critique.Veuillez me permettre de le montrer pour vous.
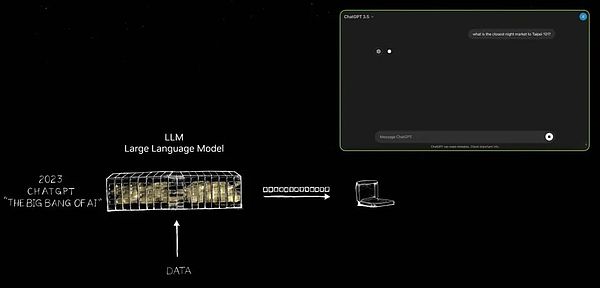
Ce n’est qu’à l’avènement de Chatgpt qu’il a vraiment révélé le potentiel infini de l’intelligence artificielle générative au monde.Pendant longtemps, l’intelligence artificielle se concentre sur les domaines de la perception, tels que la compréhension du langage naturel, la vision informatique et la reconnaissance de la parole, les technologies dédiées à la simulation des capacités de perception humaine.Mais Chatgpt a apporté un saut qualitatif, non seulement limité à la perception, mais démontre le pouvoir de l’intelligence artificielle générative pour la première fois.
Il génère des jetons un par un, qui peuvent être des mots, des images, des graphiques, des tables et même des chansons, du texte, de la voix et des vidéos.Un jeton peut représenter n’importe quoi avec un sens clair, qu’il s’agisse de produits chimiques, de protéines, de gènes ou des conditions météorologiques que nous avons mentionnées plus tôt.
La montée de cette intelligence artificielle générative signifie que nous pouvons apprendre et simuler des phénomènes physiques, permettant aux modèles d’intelligence artificielle de comprendre et de générer divers phénomènes dans le monde physique.Nous ne nous limitons plus à réduire la portée et à filtrer, mais nous explorons plutôt les possibilités infinies par la génération.
Aujourd’hui, nous pouvons générer des jetons pour presque tout ce qui est précieux, que ce soit le contrôle du volant de la voiture, le mouvement articulaire du bras robotique ou tout ce que nous pouvons apprendre pour le moment.Par conséquent, nous ne sommes plus à une époque d’intelligence artificielle, mais une nouvelle ère dirigée par l’intelligence artificielle générative.
Plus important encore, cet appareil, qui est apparu à l’origine en tant que supercalculateur, est maintenant devenu un centre de données d’intelligence artificielle efficace et efficace.Il continue de produire, non seulement génère des jetons, mais aussi une usine d’intelligence artificielle qui crée de la valeur.Cette usine d’intelligence artificielle génère, crée et produit de nouvelles matières premières avec un énorme potentiel de marché.
Tout comme Nikola Tesla a inventé l’alternateur à la fin du XIXe siècle, nous apportant un flux constant d’électronique, les générateurs d’intelligence artificielle de Nvidia génèrent également continuellement des jetons avec des possibilités infinies.Les deux ont d’énormes opportunités de marché et devraient changer dans chaque industrie.Ceci est en effet une nouvelle révolution industrielle!
Nous accueillons désormais une toute nouvelle usine qui peut produire de nouveaux produits sans précédent et précieux pour toutes les industries.Cette méthode est non seulement extrêmement évolutive, mais aussi complètement reproductible.Veuillez noter qu’à l’heure actuelle, divers modèles d’intelligence artificielle émergent constamment tous les jours, en particulier les modèles d’intelligence artificielle générative.De nos jours, chaque industrie est en concurrence pour participer, ce qui est une grande occasion sans précédent.
L’industrie informatique de 3 billions de dollars est sur le point de produire des réalisations innovantes qui peuvent servir directement l’industrie de 100 billions de dollars.Ce n’est plus un outil de stockage d’informations ou de traitement des données, mais un moteur pour générer de l’intelligence dans chaque industrie.Cela deviendra un nouveau type d’industrie manufacturière, mais ce n’est pas une industrie traditionnelle de fabrication informatique, mais un nouveau modèle de fabrication à l’aide d’ordinateurs.Un tel changement ne s’est jamais produit auparavant, et c’est en effet une chose remarquable.
5L’IA générative favorise le remodelage complet des logiciels, démontrant les microservices NIM Cloud-Native
Cela a ouvert une nouvelle ère d’informatique accélérée, favorisé le développement rapide de l’intelligence artificielle et a ainsi donné naissance à la montée de l’intelligence artificielle générative.Et maintenant, nous vivons une révolution industrielle.Examinons de plus près son impact.
L’impact de ce changement est tout aussi étendu pour notre industrie.Comme je l’ai déjà dit, c’est la première fois au cours des soixante dernières années, chaque couche informatique est en cours de transformation.De l’informatique à usage général du CPU à l’informatique accélérée des GPU, chaque changement marque un saut de technologie.
Dans le passé, les ordinateurs ont dû suivre les instructions pour effectuer des opérations, mais maintenant, ils traitent davantage de LLM (modèle de grande langue) et de modèles d’intelligence artificielle.Les modèles informatiques antérieurs étaient basés sur la récupération, et presque chaque fois que vous utilisez votre téléphone, il récupère un texte, des images ou des vidéos pré-stockés pour vous et recombines ces contenus en fonction du système de recommandation pour vous les présenter.
Mais à l’avenir, votre ordinateur générera autant de contenu que possible et ne récupérera que les informations nécessaires, car la génération de données consomme moins d’énergie lors de l’obtention d’informations.De plus, les données générées ont une pertinence contextuelle plus élevée et peuvent refléter plus précisément vos besoins.Lorsque vous avez besoin d’une réponse, vous n’avez plus besoin de demander explicitement à l’ordinateur de «me procurer ces informations» ou de «donner ce fichier», dites simplement: «Donnez-moi une réponse».
De plus, les ordinateurs ne sont plus des outils que nous utilisons, ils commencent à générer des compétences.Il effectue des tâches et n’est plus une industrie de logiciels de production, ce qui était une idée perturbatrice au début des années 1990.Souviens-toi?Le concept d’emballage logiciel proposé par Microsoft a complètement changé l’industrie PC.Sans logiciel emballé, notre PC perdra la plupart de ses fonctionnalités.Cette innovation a motivé le développement de l’ensemble de l’industrie.
Maintenant, nous avons une nouvelle usine, un nouvel ordinateur, et sur cette base est un nouveau type de logiciel en cours d’exécution – nous l’appelons NIM (NVIDIA Inference Microservices).NIM qui coule dans cette nouvelle usine est un modèle pré-formé, qui est une intelligence artificielle.

Cette IA elle-même est assez complexe, mais la pile informatique qui exécute l’IA est incroyablement complexe.Lorsque vous utilisez un modèle comme Chatgpt, derrière c’est une énorme pile de logiciels.Cette pile est complexe et énorme car le modèle a des milliards à des milliards de paramètres et fonctionne non seulement sur un ordinateur, mais travaille ensemble sur plusieurs ordinateurs.
Pour maximiser l’efficacité, le système doit allouer des charges de travail à plusieurs GPU pour divers traitements parallèles, tels que le parallélisme du tenseur, le parallélisme du pipeline, le parallélisme des données et le parallélisme expert.Une telle allocation vise à garantir que le travail peut être achevé le plus rapidement possible, car dans une usine, le débit est directement lié aux revenus, à la qualité de service et au nombre de clients qui peuvent être servis.Aujourd’hui, nous sommes à une époque où l’utilisation du débit du centre de données est cruciale.
Dans le passé, bien que le débit était considéré comme important, ce n’était pas un facteur décisif.Cependant, tous les paramètres de l’heure de démarrage, du temps d’exécution, de l’utilisation, du débit au temps d’inactivité sont mesurés avec précision parce que le centre de données est devenu une véritable « usine ».Dans cette usine, l’efficacité opérationnelle est directement liée aux performances financières de l’entreprise.
Compte tenu de cette complexité, nous connaissons les défis auxquels la plupart des entreprises sont confrontées lors du déploiement de l’IA.Par conséquent, nous avons développé une solution de conteneur IA intégré qui résume l’IA dans une boîte facile à déployer et à gérer.Cette boîte contient une énorme collection de logiciels tels que Cuda, Cudacnn et Tensorrt, ainsi que le service d’inférence Triton.Il prend en charge les environnements natifs du cloud, permet une mise à l’échelle automatique dans l’environnement Kubernetes (une solution d’architecture distribuée basée sur la technologie des conteneurs) et fournit des services de gestion pour faciliter les utilisateurs pour surveiller l’état opérationnel des services d’intelligence artificielle.
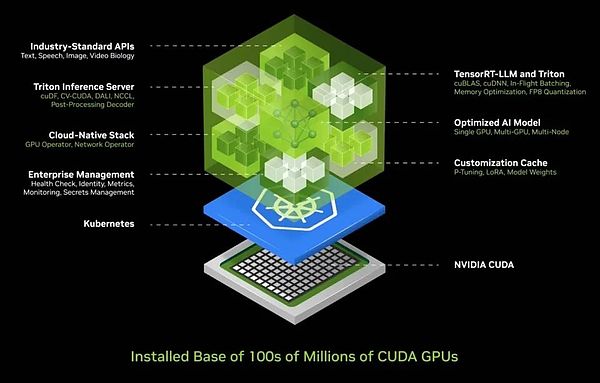
Ce qui est encore plus excitant, c’est que ce conteneur d’IA fournit une interface API standard universelle, permettant aux utilisateurs d’interagir directement avec la «boîte».Les utilisateurs peuvent facilement déployer et gérer les services d’IA en téléchargeant simplement NIM et en fonctionnant sur un ordinateur compatible Cuda.Aujourd’hui, CUDA est partout, il prend en charge les principaux fournisseurs de services cloud, et presque tous les fabricants d’ordinateurs fournissent un support CUDA, et il peut être trouvé dans des centaines de millions de PC.
Lorsque vous téléchargez NIM, vous avez immédiatement un assistant AI qui communique en douceur comme une conversation avec Chatgpt.Maintenant, tous les logiciels ont été rationalisés et intégrés dans un seul conteneur, et toutes les dépendances 400 précédemment lourdes sont optimisées au centre.Nous avons effectué des tests rigoureux de NIM, et chaque modèle pré-entraîné a été entièrement testé sur notre infrastructure cloud, y compris différentes versions de GPU tels que Pascal, Ampère et la dernière trémie.Ces versions sont d’une grande variété, couvrant presque toutes les exigences.
L’invention de Nim est sans aucun doute un exploit, et c’est l’une de mes réalisations les plus fières.Aujourd’hui, nous avons la capacité de construire des modèles de grands langues et divers modèles pré-formés qui couvrent plusieurs domaines tels que la langue, la vision, l’imagerie et les versions personnalisées pour des industries spécifiques telles que les soins de santé et la biologie numérique.

Pour en savoir plus ou essayer ces versions, visitez simplement ai.nvidia.com.Aujourd’hui, nous avons publié le LLAMA 3 NIM entièrement optimisé sur un visage étreint, que vous pouvez vivre immédiatement et même enlever gratuitement.Peu importe la plate-forme cloud que vous choisissez, vous pouvez l’exécuter facilement.Bien sûr, vous pouvez également télécharger ce conteneur dans votre centre de données, l’héberger vous-même et servir vos clients.
Comme je l’ai mentionné plus tôt, nous avons des versions NIM couvrant différents domaines, y compris la physique, la recherche sémantique, le langage visuel, etc., qui prennent en charge plusieurs langues.Ces microservices peuvent être facilement intégrés dans de grandes applications, l’une des applications les plus prometteuses est l’agent du service client.Il est standard dans presque toutes les industries et représente un marché mondial du service à la clientèle.
Il convient de mentionner que les infirmières, en tant que cœur du service client, jouent un rôle important dans la vente au détail, la restauration rapide, les services financiers, l’assurance et d’autres secteurs.Aujourd’hui, des dizaines de millions de membres du personnel du service à la clientèle ont été considérablement améliorés à l’aide de modèles linguistiques et de technologie d’intelligence artificielle.Au cœur de ces outils d’amélioration est exactement ce que vous voyez Nim.
Certains sont appelés agents de raisonnement, et lorsqu’ils sont affectés aux tâches, ils sont en mesure d’identifier les objectifs et de planifier.Certains sont bons pour récupérer des informations, certains sont compétents dans la recherche, et certains peuvent utiliser des outils tels que COOP, ou doivent apprendre des langages spécifiques en cours d’exécution sur SAP tels que ABAP, ou même exécuter des requêtes SQL.Ces soi-disant experts sont désormais formés en une équipe efficace et collaborative.
La couche d’application a également changé: dans le passé, les applications ont été écrites par des instructions, mais maintenant elles sont construites en assemblant des équipes d’intelligence artificielle.Bien que la rédaction d’un programme nécessite une expertise, presque tout le monde sait comment briser les problèmes et former une équipe.Par conséquent, je crois fermement que chaque entreprise à l’avenir aura une énorme collection de NIM.Vous pouvez sélectionner des experts comme vous le souhaitez et les connecter à une équipe.
Encore plus étonnant, vous n’avez même pas besoin de comprendre comment les connecter.Affectez simplement une tâche à l’agent, NIM décidera intelligemment comment décomposer la tâche et l’attribuer au meilleur expert.Ils sont comme des leaders centraux des applications ou des équipes, capables de coordonner le travail des membres de l’équipe et de vous présenter finalement les résultats.
L’ensemble du processus est aussi efficace et flexible que le travail d’équipe humain.Ce n’est pas seulement une tendance à l’avenir, mais c’est sur le point de devenir une réalité qui nous entoure.Il s’agit d’un look complètement nouveau que les applications présenteront à l’avenir.
6.PC deviendra le principal opérateur des personnes numériques
Lorsque nous parlons d’interactions avec les grands services d’IA, nous pouvons maintenant le faire avec des invites de texte et de voix.Mais dans l’attente de l’avenir, nous espérons interagir de manière plus humaine, à savoir les gens numériques.Nvidia a fait des progrès significatifs dans le domaine de la technologie humaine numérique.

Non seulement les personnes numériques ont le potentiel d’être d’excellents agents interactifs, ils sont plus attrayants et peuvent montrer une plus grande empathie.Cependant, il faut toujours un énorme effort pour franchir cet incroyable écart et faire en sorte que les gens numériques paraissent et se sentent plus naturels.Ce n’est pas seulement notre vision, mais aussi notre objectif incessant.
Avant de vous montrer nos réalisations actuelles, permettez-moi d’exprimer mes salutations chaleureuses à Taïwan, en Chine.Avant d’explorer le charme des marchés nocturnes en profondeur, apprécions d’abord la dynamique de pointe de la technologie humaine numérique.
C’est en effet incroyable.ACE (Avatar Cloud Engine) s’exécute non seulement efficacement dans le cloud, mais est également compatible avec les environnements PC.Nous avons l’intégration prospective des GPU de base du tenseur dans toutes les familles RTX, qui marque l’arrivée de l’ère des GPU AI et nous sommes pleinement préparés à cela.
La logique derrière cela est très claire: pour construire une nouvelle plate-forme informatique, une base solide doit être posée en premier.Avec une base solide, les applications émergeront naturellement.Si une telle fondation fait défaut, la demande sera hors de question.Donc, ce n’est que lorsque nous le construisons que la prospérité de la demande peut être possible.
Par conséquent, nous avons intégré des unités de traitement des trousses de tension dans chaque GPU RTX.Lors de la récente exposition Computex, nous avons lancé quatre nouveaux ordinateurs portables AI.
Ces appareils ont la capacité de gérer l’intelligence artificielle.Les ordinateurs portables et les PC du futur deviendront porteurs de l’intelligence artificielle, et ils vous fourniront silencieusement de l’aide et du soutien en arrière-plan.Dans le même temps, ces PC exécuteront également des applications renforcées par l’intelligence artificielle, et que vous effectuiez la modification photo, l’écriture ou l’utilisation d’autres outils, vous apprécierez les effets de commodité et d’amélioration apportés par l’intelligence artificielle.

De plus, votre PC sera en mesure d’héberger des applications humaines numériques avec l’intelligence artificielle, permettant à l’IA d’être présentée de manière plus diversifiée et appliquée sur votre PC.De toute évidence, le PC deviendra une plate-forme IA cruciale.Alors, comment allons-nous développer ensuite?
J’ai déjà parlé de l’expansion de nos centres de données, et chaque expansion s’accompagne de nouveaux changements.Lorsque nous nous sommes passés de DGX aux grands superordinateurs d’IA, nous avons mis en œuvre une formation efficace de Transformer sur d’énormes ensembles de données.Cela marque un changement majeur: au début, les données nécessitent une supervision humaine et l’intelligence artificielle est formée à travers les marques humaines.Cependant, la quantité de données que les humains peuvent étiqueter est limitée.Maintenant, avec le développement du transformateur, l’apprentissage non supervisé est devenu possible.
Aujourd’hui, Transformer est en mesure d’explorer des quantités massives de données, de vidéos et d’images en soi, l’apprentissage et la découverte de modèles et de relations cachés.Afin de promouvoir l’intelligence artificielle à un niveau supérieur, la prochaine génération d’intelligence artificielle doit être enracinée dans la compréhension des lois physiques, mais la plupart des systèmes d’intelligence artificielle manquent d’une profonde compréhension du monde physique.Afin de générer des images réalistes, des vidéos, des graphiques 3D et de simuler des phénomènes physiques complexes, nous devons de toute urgence pour développer l’intelligence artificielle basée sur la physique, qui exige qu’elle puisse comprendre et appliquer les lois de la physique.
Il existe deux façons principales d’y parvenir.Premièrement, en apprenant des vidéos, l’intelligence artificielle peut progressivement accumuler des connaissances du monde physique.Deuxièmement, en utilisant des données synthétiques, nous pouvons fournir un environnement d’apprentissage riche et contrôlable pour les systèmes d’intelligence artificielle.De plus, l’apprentissage simulé entre les données et les ordinateurs est également une stratégie efficace.Cette méthode est similaire au mode auto-agent d’Alphago, permettant deux entités avec la même capacité à apprendre les unes des autres pendant longtemps, améliorant ainsi continuellement leur niveau d’intelligence.Par conséquent, nous pouvons prévoir que ce type d’intelligence artificielle émerge progressivement à l’avenir.
7Blackwell est entièrement mis en production, et sa puissance de calcul a augmenté de 1 000 fois en huit ans
Lorsque des données d’intelligence artificielle sont générées par la synthèse et combinées avec la technologie d’apprentissage du renforcement, le taux de génération de données sera considérablement amélioré.À mesure que la génération de données augmente, la demande de puissance de calcul augmentera également en conséquence.Nous sommes sur le point d’entrer dans une nouvelle ère dans laquelle l’intelligence artificielle sera en mesure d’apprendre les lois de la physique, de comprendre et de prendre des décisions et des actions basées sur des données du monde physique.Par conséquent, nous nous attendons à ce que le modèle d’IA continue de se développer et les exigences pour les performances du GPU deviendront de plus en plus élevées.
Pour répondre à ce besoin, Blackwell a vu le jour.Conçu pour soutenir une nouvelle génération d’intelligence artificielle, ce GPU a plusieurs technologies clés.Cette taille de puce est la meilleure de l’industrie.Nous utilisons deux puces aussi grandes que possible, les connectant étroitement ensemble via un lien à grande vitesse de 10 téraoctets par seconde combinés avec les Serdes les plus avancés au monde (interface à haute performance ou technologie de connexion).De plus, nous plaçons deux de ces puces sur un nœud informatique et coordonnons efficacement via le CPU Grace.
Les processeurs Grace sont polyvalents et non seulement adaptés aux scénarios de formation, mais jouent également un rôle clé dans l’inférence et la génération, tels que le point de contrôle rapide et le redémarrage.De plus, il peut stocker des contextes, permettant aux systèmes d’IA d’avoir de la mémoire et de comprendre le contexte des conversations utilisateur, ce qui est crucial pour améliorer la continuité et la maîtrise des interactions.
Notre moteur de transformateur de deuxième génération améliore encore l’efficacité informatique de l’intelligence artificielle.Ce moteur peut s’adapter dynamiquement à une précision inférieure en fonction de la précision et des exigences de plage de la couche informatique, réduisant ainsi la consommation d’énergie tout en maintenant les performances.Pendant ce temps, les GPU Blackwell ont également des capacités d’intelligence artificielle sécurisées pour s’assurer que les utilisateurs peuvent demander aux fournisseurs de services de les protéger contre le vol ou la falsification.
En termes d’interconnexion GPU, nous avons adopté la technologie NV Link NV de cinquième génération, qui nous permet de connecter facilement plusieurs GPU.De plus, les GPU Blackwell sont équipés de la première génération de moteurs de fiabilité et de disponibilité (systèmes RAS), une technologie innovante qui peut tester chaque transistor, déclencheur, mémoire et mémoire hors puce sur la puce pour nous assurer que nous pouvons juger avec précision sur le site Si une puce particulière répond au temps moyen entre les échecs (MTBF).
La fiabilité est particulièrement critique pour les grands superordinateurs.Le temps d’intervalle de défaillance moyen pour un supercalculateur avec 10 000 GPU peut être en heures, mais lorsque le nombre de GPU augmente à 100 000, le temps d’intervalle de défaillance moyen sera réduit à quelques minutes.Par conséquent, pour garantir que les superordinateurs peuvent fonctionner de manière stable pendant longtemps pour former des modèles complexes qui peuvent prendre des mois, nous devons améliorer la fiabilité grâce à l’innovation technologique.L’amélioration de la fiabilité peut non seulement augmenter le temps de disponibilité du système, mais aussi réduire efficacement les coûts.
Enfin, nous intégrons également un moteur de décompression avancé dans le GPU Blackwell.En termes de traitement des données, la vitesse de décompression est cruciale.En intégrant ce moteur, nous pouvons retirer les données du stockage 20 fois plus rapidement que la technologie existante, améliorant considérablement l’efficacité de traitement des données.
Les caractéristiques ci-dessus du GPU Blackwell en font un produit remarquable.Lors de la précédente conférence GTC, je vous ai montré Blackwell dans l’état du prototype.Et maintenant, nous sommes heureux d’annoncer que ce produit a été mis en production.

C’est Blackwell, tout le monde, en utilisant une technologie incroyable.C’est notre chef-d’œuvre, l’ordinateur le plus complexe et le plus performant du monde aujourd’hui.Parmi eux, nous voulons particulièrement mentionner le CPU Grace, qui porte une énorme puissance de calcul.Veuillez voir, ces deux puces Blackwell, elles sont étroitement connectées.L’avez-vous remarqué?Il s’agit de la plus grande puce au monde, et nous utilisons des liens jusqu’à A10To par seconde pour mélanger deux de ces puces en une seule.
Alors, qu’est-ce que Blackwell?Sa performance est incroyable.Veuillez observer attentivement ces données.En seulement huit ans, notre puissance de calcul, les capacités arithmétiques à virgule arithmétique à virgule flottante et artificielle ont augmenté de 1 000 fois.Cette vitesse dépasse presque la croissance de la loi de Moore dans la meilleure période.
La croissance de la puissance de calcul de Blackwell est tout simplement incroyable.Ce qui mérite d’être mentionné, c’est que chaque fois que notre puissance de calcul augmente, le coût est constamment en baisse.Laissez-moi vous montrer quelque chose.En améliorant la puissance de calcul, l’énergie utilisée pour former des modèles GPT-4 (2 billions de paramètres et 8 billions de jetons) a chuté de 350 fois.
Imaginez si Pascal fait la même formation, il consommerait jusqu’à 1000 GWh d’énergie.Cela signifie qu’un centre de données GW est nécessaire pour les soutenir, mais que ces centres de données n’existent pas dans le monde.Même s’il existe, il faudra un mois pour fonctionner en continu.Et s’il s’agit d’un centre de données de 100 MW, le temps de formation sera aussi long qu’un an.
De toute évidence, personne ne veut ou ne peut créer un tel centre de données.C’est pourquoi il y a huit ans, les modèles de grandes langues comme Chatgpt étaient encore un rêve lointain pour nous.Mais maintenant, nous y parvenons en augmentant les performances et en réduisant la consommation d’énergie.
Nous avons utilisé Blackwell pour réduire l’énergie qui nécessiterait autrement jusqu’à 1 000 GWh à seulement 3 GWh, une réalisation qui est sans aucun doute une percée choquante.Imaginez en utilisant 1 000 GPU, l’énergie qu’ils consomment ne sont qu’équivalent aux calories d’une tasse de café.Et 10 000 GPU peuvent accomplir la même tâche en seulement 10 jours.Ces progrès réalisés en huit ans sont tout simplement incroyables.

Blackwell convient non seulement à l’inférence, mais son amélioration des performances de la génération de jetons est encore plus accrocheuse.À l’ère Pascal, chaque jeton a consommé jusqu’à 17 000 joules d’énergie, qui concernait l’énergie de deux ampoules fonctionnant pendant deux jours.Pour générer un jeton GPT-4, il faut presque deux ampoules de 200 watts pour fonctionner pendant deux jours.Étant donné qu’il faut environ 3 jetons pour générer un mot, il s’agit en effet d’une énorme consommation d’énergie.
Cependant, la situation est complètement différente maintenant.Blackwell ne fait que coûter 0,4 joules d’énergie pour générer chaque jeton, et la génération de jetons est à une vitesse incroyable et à une consommation d’énergie extrêmement faible.C’est sans aucun doute un énorme saut.Mais même ainsi, nous ne sommes toujours pas satisfaits.Pour une plus grande percée, nous devons construire des machines plus puissantes.
Il s’agit de notre système DGX, et la puce Blackwell y sera intégrée.Ce système utilise la technologie de refroidissement de l’air et est équipé de 8 GPU de ce type à l’intérieur.Regardez les dissipateurs thermiques sur ces GPU, leur taille est incroyable.La consommation d’énergie de l’ensemble du système est d’environ 15 kW, ce qui est complètement réalisé grâce au refroidissement par air.Cette version est compatible avec x86 et a été appliquée à nos serveurs expédiés.
Cependant, si vous préférez la technologie de refroidissement liquide, nous avons également un tout nouveau système – le MGX.Il est basé sur cette conception de la carte mère, que nous appelons un système « modulaire ».Le cœur du système MGX se trouve dans deux puces Blackwell, et chaque nœud intègre quatre puces Blackwell.Il adopte la technologie de refroidissement liquide pour assurer un fonctionnement efficace et stable.
Dans l’ensemble du système, il y a neuf de ces nœuds, un total de 72 GPU, formant un énorme cluster informatique.Ces GPU sont étroitement connectés via la nouvelle technologie NV Link pour former un réseau informatique transparent.Les commutateurs de liaison NV sont un miracle technique.Il s’agit actuellement du commutateur le plus avancé au monde, avec un taux de transmission de données étonnant.Ces commutateurs rendent chaque puce Blackwell efficacement connectée, formant un énorme cluster de 72 GPU.
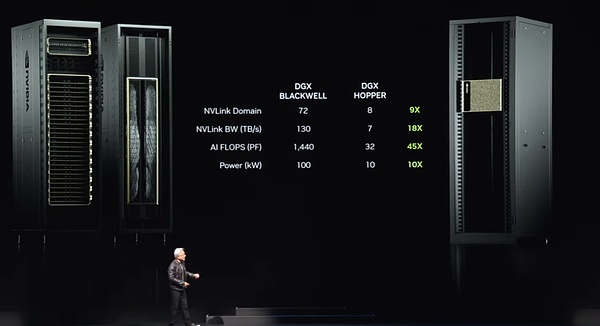
Quels sont les avantages de ce cluster?Tout d’abord, dans le domaine GPU, il agit maintenant comme un seul GPU super grand.Ce « super GPU » a les capacités de base de 72 GPU, et les performances sont 9 fois plus élevées que la génération précédente de 8 GPU.Dans le même temps, la bande passante a augmenté de 18 fois, les flops d’IA (opérations de points flottants par seconde) ont augmenté de 45 fois et la puissance n’a augmenté que 10 fois.C’est-à-dire qu’un de ces systèmes peut fournir une forte puissance de 100 kilowatts, tandis que la génération précédente n’était que de 10 kilowatts.
Bien sûr, vous pouvez également connecter davantage de ces systèmes ensemble pour former un réseau informatique plus grand.Mais le vrai miracle réside dans le fait que cette puce de liaison NV devient de plus en plus grande avec la taille croissante du modèle de langue grande.Étant donné que ces modèles de gros langues ne conviennent plus pour fonctionner sur un seul GPU ou un seul nœud, ils nécessitent le fonctionnement de l’ensemble du rack GPU ensemble.Tout comme le nouveau système DGX que je viens de mentionner, il peut accueillir de grands modèles de langage avec des centaines de milliards de paramètres.
Le commutateur de liaison NV lui-même est un miracle technologique, avec 50 milliards de transistors, 74 ports et un débit de données allant jusqu’à 400 Go par port.Mais plus important encore, le commutateur intègre également les fonctions de fonctionnement mathématique, qui peuvent effectuer directement des opérations de réduction, ce qui est d’une grande importance dans l’apprentissage en profondeur.Ceci est le nouveau look du système DGX actuel.
Beaucoup de gens sont curieux à propos de nous.Ils ont demandé qu’il y avait un malentendu de la portée commerciale de Nvidia.Les gens se demandent comment Nvidia pourrait devenir si énorme en faisant des GPU.Par conséquent, beaucoup de gens ont fait l’impression que le GPU devrait ressembler d’une certaine manière.
Cependant, ce que je veux vous montrer maintenant, c’est que c’est en effet un GPU, mais ce n’est pas le genre que vous pensez que c’est.C’est l’un des GPU les plus avancés au monde, mais il est principalement utilisé dans le domaine du jeu.Mais nous savons tous que le vrai pouvoir des GPU est bien plus que cela.
Tout le monde, veuillez regarder cela, c’est la vraie forme de GPU.Il s’agit d’un GPU DGX conçu pour l’apprentissage en profondeur.L’arrière de ce GPU est connecté au squelette de la liaison NV, qui se compose de 5 000 lignes et mesure 3 kilomètres de long.Ces lignes sont l’épine dorsale du lien NV, qui connecte 70 GPU pour former un puissant réseau informatique.Il s’agit d’un miracle mécanique électronique dans lequel l’émetteur-récepteur nous permet de conduire des signaux sur toute la longueur sur le fil de cuivre.
Par conséquent, ce commutateur de liaison NV transmet des données sur le fil de cuivre via le squelette de la liaison NV, nous permettant d’économiser 20 kW de puissance dans un seul rack, qui est désormais entièrement utilisé pour le traitement des données, ce qui est en effet un fait fascinant incroyable.Il s’agit de la puissance de l’épine dorsale du lien NV.
8Promouvoir Ethernet pour une IA générative
Mais cela ne suffit pas pour répondre à la demande, en particulier pour les grandes usines d’IA, nous avons donc une autre solution.Nous devons connecter ces usines d’IA à l’aide de réseaux à grande vitesse.Nous avons deux options de réseau: Infiniband et Ethernet.Parmi eux, Infiniband a été largement utilisé dans les usines de supercalcul et d’intelligence artificielle du monde entier et se développe rapidement.Cependant, tous les centres de données ne peuvent pas utiliser Infiniband directement car ils ont fait des investissements importants dans l’écosystème Ethernet, et la gestion des commutateurs et des réseaux Infiniband nécessite une certaine expertise et technologie.
Par conséquent, notre solution consiste à apporter les performances d’Infiniband dans l’architecture Ethernet, ce qui n’est pas facile.La raison en est que chaque nœud, chaque ordinateur, est généralement connecté à différents utilisateurs sur Internet, mais la plupart de la communication se produit en fait à l’intérieur du centre de données, c’est-à-dire la transmission de données entre le centre de données et les utilisateurs à l’autre bout d’Internet .Cependant, dans le scénario d’apprentissage en profondeur des usines d’intelligence artificielle, les GPU ne communiquent pas avec les utilisateurs sur Internet, mais les échanges de données fréquemment et intensifs.
Ils communiquent entre eux parce qu’ils collectent tous une partie des résultats.Ils doivent ensuite réduire ces résultats partiels et les redistribuer.Ce mode de communication est caractérisé par un trafic hautement éclaté.Ce qui compte n’est pas le débit moyen, mais les dernières données qui arrivent, car si vous collectez des résultats partiels de tout le monde et que j’essaie de recevoir tous vos résultats partiels, si le dernier paquet arrive en retard, alors l’ensemble de l’opération retardera .La latence est une question cruciale pour les usines d’IA.
Par conséquent, notre objectif n’est pas sur le débit moyen, mais en veillant à ce que le dernier paquet arrive à l’heure et sans erreur.Cependant, Ethernet traditionnel n’a pas été optimisé pour des exigences aussi hautement synchronisées et faibles.Pour répondre à ce besoin, nous avons conçu de manière créative une architecture de bout en bout qui permet de communiquer les NICS (cartes d’interface réseau) et les commutateurs.Pour y parvenir, nous avons adopté quatre technologies clés:
Premièrement, NVIDIA possède la technologie RDMA (accès à la mémoire directe à distance).Maintenant, nous avons RDMA au niveau du réseau Ethernet et il fait un excellent travail.
Deuxièmement, nous avons introduit un mécanisme de contrôle de la congestion.Le commutateur a une fonction de télémétrie en temps réel, qui peut rapidement identifier et répondre à la congestion dans le réseau.Lorsque la quantité de données envoyées par le GPU ou le NIC est trop grande, le commutateur envoie immédiatement un signal pour les informer pour ralentir le taux de transmission, évitant ainsi efficacement la génération de points chauds du réseau.
Troisièmement, nous adoptons la technologie de routage adaptative.Ethernet traditionnel transmet des données dans un ordre fixe, mais dans notre architecture, nous pouvons nous ajuster de manière flexible en fonction des conditions de réseau en temps réel.Lorsque la congestion est trouvée ou que certains ports sont inactifs, nous pouvons envoyer des paquets à ces ports inactifs et les réorganiser par l’appareil Bluefield à l’autre bout pour garantir que les données sont renvoyées dans le bon ordre.Cette technologie de routage adaptative améliore considérablement la flexibilité et l’efficacité du réseau.
Quatrièmement, nous avons mis en œuvre la technologie d’isolement du bruit.Dans un centre de données, le bruit et le trafic généré par plusieurs modèles, l’entraînement peut interférer les uns avec les autres et provoquer une gigue.Notre technologie d’isolement du bruit peut isoler efficacement ces bruits, garantissant que la transmission de paquets de données critiques n’est pas affectée.
En adoptant ces technologies, nous avons réussi à fournir des solutions de réseau à faible latence à haute performance aux usines d’IA.Dans un centre de données de plusieurs milliards de dollars, si l’utilisation du réseau augmente de 40% et que le temps de formation est réduit de 20%, cela signifie en fait qu’un centre de données de 5 milliards de dollars équivaut à un centre de données de 6 milliards de dollars en performance, révèle l’impact significatif des performances du réseau sur la rentabilité globale.
Heureusement, la technologie Ethernet avec Spectrum X est la clé de notre réalisation, qui améliore considérablement les performances du réseau, ce qui rend les coûts de réseau presque négligeables par rapport à l’ensemble du centre de données.C’est sans aucun doute une grande réussite que nous avons faite dans le domaine de la technologie du réseau.
Nous avons une forte gamme de produits Ethernet, dont la plus notable est le spectre x800.Avec 51,2 To par seconde et 256 chemins (radix), cet appareil fournit une connectivité réseau efficace à des milliers de GPU.Ensuite, nous prévoyons de lancer le X800 Ultra en un an, qui prendra en charge 512 Radix avec jusqu’à 512 chemins, améliorant encore la capacité et les performances du réseau.Le X1600 est conçu pour les plus grands centres de données et peut répondre aux besoins de communication de millions de GPU.

Avec l’avancement continu de la technologie, l’ère du centre de données de millions de GPU approche à grands pas.Il y a des raisons profondes derrière cette tendance.D’une part, nous sommes impatients de former des modèles plus grands et plus complexes; mais plus important encore, les futures interactions Internet et informatique s’appuieront de plus en plus sur l’intelligence artificielle générative basée sur le cloud.Ces IA fonctionneront et interagiront avec nous pour générer des vidéos, des images, des textes et même des personnes numériques.Par conséquent, presque toutes les interactions avec lesquelles nous interagissons avec les ordinateurs sont inséparables de la participation de l’intelligence artificielle générative.Et il y a toujours une IA générative qui lui est connectée, certaines en cours d’exécution localement, certaines fonctionnant sur votre appareil, et beaucoup peuvent fonctionner dans le cloud.
Ces intelligences artificielles génératives ont non seulement de solides capacités de raisonnement, mais aussi d’optimiser de manière itérative des réponses pour améliorer la qualité des réponses.Cela signifie que nous générerons des besoins de génération de données massifs à l’avenir.Ce soir, nous avons été témoins du pouvoir de cette innovation technologique ensemble.
Blackwell, en tant que première génération de la plate-forme Nvidia, a attiré beaucoup l’attention depuis son lancement.Aujourd’hui, l’ère de l’intelligence artificielle générative inaugure le monde, le début d’une nouvelle révolution industrielle, et chaque coin est conscient de l’importance des usines d’intelligence artificielle.Nous sommes profondément honorés d’avoir reçu un soutien étendu de tous les horizons, y compris tous les OEM (fabricant d’équipements d’origine), fabricant d’ordinateurs, CSP (fournisseur de services cloud), cloud GPU, cloud souverain et sociétés de télécommunications.
Nous sommes profondément ravis que le succès de Blackwell, l’adoption généralisée et l’enthousiasme de l’industrie pour cela aient atteint des niveaux sans précédent, et nous aimerions vous exprimer notre sincère gratitude.Cependant, notre rythme ne s’arrêtera pas.Dans cette ère en développement rapide, nous continuerons à travailler dur pour améliorer les performances des produits, réduire le coût de la formation et du raisonnement, tout en élargissant continuellement les capacités de l’intelligence artificielle afin que chaque entreprise puisse en bénéficier.Nous croyons fermement qu’avec l’amélioration des performances, les coûts seront encore réduits.La plate-forme Hopper est sans aucun doute le processeur de centres de données le plus réussi de l’histoire.
9.Blackwell Ultra sortira l’année prochaine, et la plate-forme de prochaine génération s’appelle Rubin
C’est en effet une réussite choquante.Comme vous pouvez le voir, la naissance de la plate-forme Blackwell n’est pas un seul composant, mais un système complet qui intègre plusieurs éléments tels que CPU, GPU, NVLink, Nick (composants techniques spécifiques) et les commutateurs NVLink.Nous nous engageons à connecter étroitement tous les GPU à travers chaque génération en utilisant de grands commutateurs à ultra-hauts vitesses pour former un domaine informatique énorme et efficace.
Nous intégrons la plate-forme entière dans notre usine d’IA, mais plus critique, nous fournissons cette plate-forme aux clients du monde entier sous une forme modulaire.L’intention d’origine est que nous nous attendons à ce que chaque partenaire crée une configuration unique et innovante basée sur leurs propres besoins pour s’adapter à différents styles de centres de données, différents groupes de clients et divers scénarios d’application.De l’informatique Edge aux télécommunications, toutes sortes d’innovations deviendront possibles tant que le système restera ouvert.
Pour vous permettre d’innover librement, nous avons conçu une plate-forme intégrée, mais en même temps qui vous est fournie en décomposition, vous permettant de construire facilement des systèmes modulaires.Maintenant, la plate-forme Blackwell a été entièrement lancée.
Nvidia adhère toujours au rythme de mise à jour annuel.Notre philosophie principale est très claire: 1) construire des solutions qui couvrent toute l’échelle du centre de données; 2) diviser ces solutions en composants et les lancer à des clients du monde entier à une fréquence annuelle; Extrême, que ce soit la technologie de processus de TSMC, la technologie d’emballage, la technologie de la mémoire ou la technologie optique, nous recherchons tous des performances ultimes.
Après avoir terminé le défi ultime du matériel, nous ferons de notre mieux pour nous assurer que tous les logiciels se déroulent en douceur sur cette plate-forme complète.Dans la technologie informatique, l’inertie des logiciels est cruciale.Lorsque notre plate-forme informatique est compatible en arrière et que l’architecture est parfaitement compatible avec les logiciels existants, la vitesse des produits à commercialiser sera considérablement améliorée.Par conséquent, lorsque la plate-forme Blackwell a été lancée, nous avons pu utiliser pleinement la base de l’écosystème logiciel construit pour atteindre une vitesse de réponse du marché incroyable.L’année prochaine, nous accueillerons le Blackwell Ultra.
Tout comme la série H100 et H200 que nous avons lancée, le Blackwell Ultra mènera également l’engouement d’une nouvelle génération de produits, apportant des expériences innovantes sans précédent.Dans le même temps, nous continuerons de remettre en question les limites de la technologie et de lancer les commutateurs de spectre de nouvelle génération, qui est la première tentative de l’industrie.Cette percée majeure a été réalisée avec succès, bien que j’hésite encore un peu à rendre cette décision publique.
Dans NVIDIA, nous avons l’habitude d’utiliser des noms de code et de maintenir une certaine confidentialité.Plusieurs fois, même la plupart des employés de l’entreprise ne connaissent pas très bien ces secrets.Cependant, notre plate-forme de nouvelle génération a été nommée Rubin.Je n’entrerai pas dans les détails sur Rubin ici.Je sais que la curiosité de tout le monde, mais permettez-moi de garder un mystère.Vous pouvez être impatient de prendre des photos ou d’étudier attentivement ces petits personnages, alors n’hésitez pas à le faire.
Nous avons non seulement la plate-forme Rubin, mais nous lancerons également la plate-forme Rubin Ultra en un an.Toutes les puces présentées ici sont en phase de développement complète, garantissant que chaque détail est soigneusement poli.Notre rythme de mise à jour est toujours une fois par an, poursuivant toujours le summum de la technologie tout en veillant à ce que tous les produits conservent une compatibilité architecturale à 100%.

En regardant en arrière sur les 12 dernières années, à partir du moment où ImageNet est né, nous prévoyons l’avenir du champ informatique qui subira des changements à la terre.Maintenant, tout cela est devenu une réalité, qui coïncide avec notre idée originale.De Geforce avant 2012 à Nvidia aujourd’hui, la société a subi une énorme transformation.Ici, je voudrais remercier sincèrement tous mes partenaires pour leur soutien et leur entreprise en cours de route.
10L’ère des robots est arrivée
Il s’agit de la plate-forme Blackwell de Nvidia.
L’intelligence artificielle physique mène une nouvelle vague dans le domaine de l’intelligence artificielle.À cette fin, l’intelligence artificielle physique doit non seulement construire un modèle mondial précis pour comprendre comment interpréter et percevoir le monde qui l’entoure, mais doit également avoir d’excellentes capacités cognitives pour comprendre profondément nos besoins et effectuer des tâches efficacement.
Pour l’avenir, la robotique ne sera plus un concept hors de portée, mais sera de plus en plus intégré dans notre vie quotidienne.Lorsque vous parlez de robotique, les gens pensent souvent aux robots humanoïdes, mais en fait, leurs applications sont bien plus que cela.La mécanisation deviendra la norme, les usines réaliseront pleinement l’automatisation et les robots fonctionneront ensemble pour créer une série de produits mécanisés.L’interaction entre eux sera plus proche, créant ensemble un environnement de production hautement automatisé.
Pour y parvenir, nous devons surmonter une gamme de défis techniques.Ensuite, je présenterai ces technologies de pointe via la vidéo.
Ce n’est pas seulement une vision de l’avenir, elle devient progressivement une réalité.
Nous servirons le marché de diverses manières.Tout d’abord, nous nous engageons à créer des plateformes pour différents types de systèmes de robots: plates-formes dédiées pour les usines et entrepôts de robots, les plateformes de robots de manipulation d’objets, les plateformes de robot mobile et les plateformes de robot humanoïde.Comme beaucoup de nos autres entreprises, ces plateformes robotiques reposent sur des bibliothèques d’accélération informatique et des modèles pré-formés.
Nous utilisons des bibliothèques d’accélération informatique, des modèles pré-formés et effectuons des tests, une formation et une intégration complets dans OmIverse.Comme le montre la vidéo, OmIverse est l’endroit où les robots apprennent à mieux s’adapter au monde réel.Bien sûr, l’écosystème des entrepôts de robots est extrêmement complexe et nécessite de nombreuses entreprises, outils et technologies pour construire conjointement les entrepôts modernes.Aujourd’hui, les entrepôts se déplacent progressivement vers la mécanisation complète et seront un jour entièrement automatisés.
Dans un tel écosystème, nous fournissons des interfaces SDK et API pour l’industrie des logiciels, Edge Artificial Intelligence Industry and Companies, et concevons également des systèmes dédiés aux systèmes PLC et robotiques pour répondre aux besoins de domaines spécifiques tels que le ministère de la Défense.Ces systèmes sont intégrés par le biais d’intégrateurs pour finalement créer des entrepôts efficaces et intelligents pour les clients.Par exemple, Ken Mac construit un entrepôt de robot pour le groupe géant géant.
Ensuite, concentrons-nous sur le champ d’usine.L’écosystème de l’usine est très différent.Prenez Foxconn à titre d’exemple, ils construisent certaines des usines les plus avancées du monde.Les écosystèmes de ces usines couvrent également les ordinateurs de bord, les logiciels robotiques, pour la conception de dispositions d’usine, l’optimisation des flux de travail, la programmation des robots et les ordinateurs PLC utilisés pour coordonner les usines numériques et les usines d’intelligence artificielle.Nous fournissons également une interface SDK pour chaque lien de ces écosystèmes.
De tels changements ont lieu dans le monde entier.Foxconn et Delta construisent des jumeaux numériques pour leurs usines pour obtenir un mélange parfait de réalité et de numérique, et OmIverse joue un rôle crucial.Il convient également de mentionner que Pegatron et Wistron suivent également la tendance et établissent des installations jumelles numériques pour leurs usines de robot respectives.
C’est vraiment excitant.Ensuite, veuillez profiter d’une merveilleuse vidéo de la nouvelle usine de Foxconn.
L’usine de robots se compose de trois principaux systèmes informatiques qui forment des modèles AI sur la plate-forme NVIDIA AI, et nous nous assurons que le robot fonctionne efficacement sur le système local pour orchestrer les processus d’usine.Dans le même temps, nous utilisons OmIverse, une plate-forme de collaboration de simulation pour simuler tous les éléments d’usine, y compris les armes robotiques et AMR (robot mobile autonome).Il convient de mentionner que ces systèmes de simulation partagent le même espace virtuel pour obtenir une interaction et une collaboration transparentes.
Lorsque les bras robotiques et AMR entrent dans cet espace virtuel partagé, ils peuvent simuler un environnement d’usine réel dans Omverse, assurant une vérification et une optimisation adéquates avant le déploiement réel.
Pour améliorer davantage la gamme d’intégration et d’application des solutions, nous proposons trois ordinateurs haute performance, équipés de couches d’accélération et de modèles d’IA pré-formés.De plus, nous avons combiné avec succès NVIDIA Manipulateur et OMIVERS avec les logiciels et systèmes d’automatisation industrielle de Siemens.Cette collaboration permet à Siemens de permettre un fonctionnement et une automatisation plus efficaces dans les usines du monde entier.
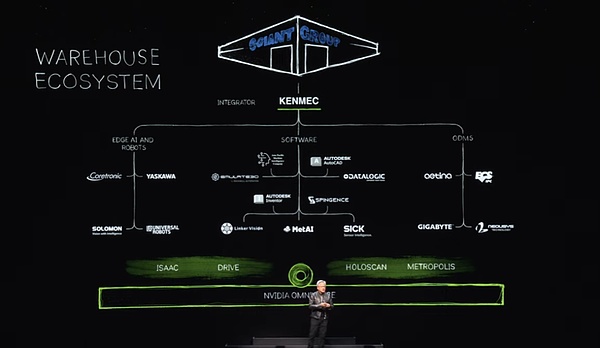
En plus de Siemens, nous avons également établi des relations coopératives avec de nombreuses entreprises bien connues.Par exemple, Symantec Pick AI a intégré le manipulateur de Nvidia Isaac, tandis que Somatic Pick AI a réussi et exploité des robots à partir de marques bien connues telles que ABB, Kuka et Yaskawa Motoman.
L’ère de la robotique et de l’intelligence artificielle physique est arrivée, et elles sont largement utilisées partout.Pour l’avenir, les robots en usines deviendront courant, et ils fabriqueront tous les produits, dont deux particulièrement accrocheurs.Premièrement, des voitures ou des voitures autonomes avec une autonomie élevée, Nvidia joue à nouveau un rôle central dans ce domaine avec sa pile de technologie complète.L’année prochaine, nous prévoyons de nous joindre à l’équipe Mercedes-Benz, puis de travailler avec l’équipe Jaguar Land Rover (JLR) en 2026.Nous proposons une pile de solutions complète, mais les clients peuvent choisir n’importe quelle pièce ou hiérarchie en fonction de leurs besoins, car la pile de pilotes entière est ouverte et flexible.
Ensuite, un autre produit qui peut être fabriqué à des rendements élevés des usines de robots est les robots humanoïdes.Ces dernières années, de grandes percées ont été faites en capacité cognitive et en compréhension du monde, et les perspectives de développement dans ce domaine sont passionnantes.Je suis particulièrement enthousiasmé par les robots humanoïdes car ils sont les plus susceptibles de s’adapter au monde que nous avons construit pour les humains.
La formation des robots humanoïdes nécessite beaucoup de données par rapport à d’autres types de robots.Étant donné que nous avons des formes de corps similaires, la grande quantité de données d’entraînement fournies par la démonstration et les capacités vidéo sera d’une grande valeur.Par conséquent, nous nous attendons à des progrès significatifs dans ce domaine.

Maintenant, accueillons-nous quelques amis de robot spéciaux.L’ère des robots est arrivée, et c’est la prochaine vague d’intelligence artificielle.Il existe une grande variété d’ordinateurs fabriqués à Taïwan, y compris des modèles traditionnels équipés de claviers, de petits appareils mobiles légers et portables, ainsi que des équipements professionnels qui fournissent une puissance de calcul puissante pour les centres de données cloud.Mais avec impatience, nous allons assister à un moment plus excitant – créer des ordinateurs qui peuvent marcher et rouler, à savoir les robots intelligents.
Ces robots intelligents ont des similitudes techniques frappantes avec les ordinateurs tels que nous les connaissons, et ils sont tous construits sur des technologies matérielles et logicielles avancées.Nous avons donc des raisons de croire que ce sera un voyage vraiment extraordinaire!







