
Tl/dr
Wir haben diskutiert, wie KI und Web3 jeweils einander nutzen und sich in verschiedenen vertikalen Branchen wie Computernetzwerken, Proxy -Plattformen und Verbraucheranwendungen ergänzen können.Bei der Konzentration auf das vertikale Bereich der Datenressourcen bieten aufstrebende Webprojekte neue Möglichkeiten für die Datenerfassung, gemeinsame Nutzung und Nutzung.
-
Traditionelle Datenanbieter haben Schwierigkeiten, die Bedürfnisse von KI und anderen datengesteuerten Branchen für qualitativ hochwertige, in Echtzeit überprüfbare Daten zu erfüllen, insbesondere in Bezug auf Transparenz, Benutzerkontrolle und Datenschutzschutz
-
Web3 -Lösungen arbeiten daran, das Daten -Ökosystem zu umformieren.Technologien wie MPC, Zero-Knowledge Proof und TLS Notar sorgen für Authentizität und Datenschutzschutz, wenn Daten zwischen mehreren Quellen zirkuliert, während verteilte Speicher und Edge Computing eine größere Flexibilität und Effizienz für die Echtzeitverarbeitung von Daten bieten.
-
InDezentrales DatennetzwerkDiese aufstrebende Infrastruktur hat mehrere repräsentative Projekte hervorgebracht, OpenLayer (Modular Real Data Layer), Gras (mithilfe der Benutzer in der Leerlaufbandbreite und der dezentralen Crawler -Knoten -Netzwerke) und Vana (Benutzerdaten -Souvereignty Layer -1 AI -Schulungs- und Anwendungsfelder.
-
Durch Crowdsourcing-Kapazität, vertrauenslose Abstraktionsschicht und tokenbasierte Incentive-Mechanismen können dezentrale Dateninfrastrukturen privatere, sichere, effiziente und wirtschaftliche Lösungen liefern als Web2-Hyperscale-Dienstleister und den Benutzern die Möglichkeit, diese Kontrolle zu nutzen. ein offeneres, sichereres und miteinander verbundenes digitales Ökosystem.
1.Die Welle der Datenbedarf
Daten sind zu einem wesentlichen Treiber für Innovation und Entscheidungsfindung in verschiedenen Branchen geworden.UBS prognostiziert, dass das globale Datenvolumen zwischen 2020 und 2030 um mehr als zehnfach auf 660 ZB wachsen wird. Bis 2025 wird jede Person auf der Welt 463 EB (Exabytes, 1EB = 1 Milliarde GB) Daten pro Person pro Person erzeugen Tag.Der Markt für Daten-AS-a-Service (DAAS) wächst rasch, und laut einem Bericht von Grand View Research wird der globale DAAS-Markt im Jahr 2023 einen Wert von 14,36 Milliarden US 2030, schließlich 768. 100 Millionen Dollar.Hinter diesen wachstumsstarken Zahlen steckt die Nachfrage nach qualitativ hochwertigen, in Echtzeit vertrauenswürdigen Daten in mehreren Industriefeldern.
Das KI -Modelltraining basiert auf einer großen Menge an Dateneingaben, um Muster zu identifizieren und Parameter anzupassen.Nach dem Training ist der Datensatz auch erforderlich, um die Leistungs- und Generalisierungsfunktionen des Modells zu testen.Darüber hinaus erfordern KI-Agenten als vorhersehbare aufstrebende intelligente Antragsform in der Zukunft Echtzeit- und zuverlässige Datenquellen, um eine genaue Entscheidungsfindung und Aufgabenausführung sicherzustellen.
(Quelle: Spielraumhertz)
Die Nachfrage nach Geschäftsanalysen wird auch vielfältig und umfangreich und ist zum Kerninstrument für die Förderung von Unternehmeninnovationen geworden.Zum Beispiel benötigen Social -Media -Plattformen und Marktforschungsunternehmen zuverlässige Benutzerverhaltensdaten, um Strategien und Einblicke in Trends zu formulieren, mehrere Daten aus mehreren sozialen Plattformen zu integrieren und ein umfassenderes Porträt zu erstellen.
Für das Web3-Ökosystem sind auch zuverlässige und reale Daten auf Ketten erforderlich, um einige neue Finanzprodukte zu unterstützen.Da immer mehr neue Vermögenswerte tokenisiert werden, sind flexible und zuverlässige Datenschnittstellen erforderlich, um die Entwicklung und das Risikomanagement innovativer Produkte zu unterstützen, wodurch intelligente Verträge auf der Grundlage überprüfbarer Echtzeitdaten ausgeführt werden können.
Zusätzlich zu den oben genannten gibt es wissenschaftliche Forschung, das Internet der Dinge (IoT) usw.Neue Anwendungsfälle Die Nachfrage nach vielfältigen Echtzeitdaten in verschiedenen Branchen steigt, während traditionelle Systeme möglicherweise Schwierigkeiten haben, mit schnell wachsenden Datenmengen und sich ändernden Anforderungen fertig zu werden.
2. Einschränkungen und Probleme der traditionellen Datenökologie
Ein typisches Datenökosystem umfasst Datenerfassung, Speicher, Verarbeitung, Analyse und Anwendung.Das zentralisierte Modell ist durch die zentralisierte Datenerfassung und -speicherung, das Management sowie die Wartung und Wartung durch das IT -Team von Core Enterprise gekennzeichnet, und es wird eine strenge Zugriffskontrolle implementiert.
Beispielsweise deckt das Datenökosystem von Google mehrere Datenquellen ab, von Suchmaschinen, Google Mail bis hin zu Android -Betriebssystemen und verwendet diese Plattformen, um Benutzerdaten zu sammeln, in seinem global verteilten Rechenzentrum zu speichern und dann Algorithmen zu verarbeiten und zu analysieren, um verschiedene Unterstützung zu verarbeiten und zu analysieren Entwicklung und Optimierung von Produkten und Dienstleistungen.
Auf dem Finanzmarkt verwenden die Daten und Infrastruktur LSEG (früher Refinitiv) beispielsweise Echtzeit- und historische Daten, um globale Börsen, Banken und andere wichtige Finanzinstitutionen zu erhalten, und verwenden ein eigenes Reuters-Nachrichtennetzwerk, um marktbezogene Nachrichten und Nutzung zu sammeln Seine proprietären Algorithmen und Modelle generieren analytische Daten und Risikobewertung als zusätzliche Produkte.
(Quelle: kdnuggets.com)
Traditionelle Datenarchitekturen sind in professionellen Dienstleistungen wirksam, aber die Einschränkungen zentraler Modelle werden immer deutlicher.Insbesondere traditionelle Datenökosysteme stehen vor Herausforderungen in Bezug auf die Abdeckung, Transparenz und den Schutz der Datenschutz des Benutzers von aufkommenden Datenquellen.Hier sind einige Beispiele:
-
Unzureichende Datenabdeckung: Traditionelle Datenanbieter haben Herausforderungen bei der schnellen Erfassung und Analyse neuer Datenquellen wie Social Media Sentiment und IoT -Gerätedaten.Zentralisierte Systeme sind schwer zu erfassen und integrieren „Long Tail“ -Daten aus zahlreichen kleinen oder nicht-Mainstream-Quellen.
Zum Beispiel zeigt der Gamestop -Vorfall im Jahr 2021 die Grenzen traditioneller Finanzdatenanbieter bei der Analyse der sozialen Medienstimmung.Die Anlegerstimmung auf Plattformen wie Reddit veränderte den Markttrend schnell, aber Datenanschlüsse wie Bloomberg und Reuters konnten diese Dynamik nicht rechtzeitig erfassen, was zu einer Verzögerung bei Marktprognosen führte.
-
Die Zugänglichkeit der Daten ist begrenzt: Monopol begrenzt die Zugänglichkeit.Viele traditionelle Anbieter öffnen einige ihrer Daten über API/Cloud -Dienste, aber die hohen Zugriffskosten und komplexen Autorisierungsprozesse erhöhen die Schwierigkeit der Datenintegration.
Für Entwickler von Onkains ist es schwierig, schnell auf zuverlässige Off-Chain-Daten zuzugreifen, und hochwertige Daten werden von einigen wenigen Riesen monopolisiert, und die Zugriffskosten sind hoch.
-
Datentransparenz- und Glaubwürdigkeitsprobleme: Viele zentralisierte Datenanbieter fehlen Transparenz in ihren Datenerfassungs- und Verarbeitungsmethoden und es fehlen wirksame Mechanismen, um die Authentizität und Integrität großem Maßstabsdaten zu überprüfen.Die Überprüfung großer Echtzeitdaten bleibt ein komplexes Problem, und die Art der Zentralisierung erhöht auch das Risiko, dass Daten manipuliert oder manipuliert werden.
-
Datenschutzschutz und Datenbesitz: Große Technologieunternehmen haben Benutzerdaten in großem Maßstab verwendet.Als Ersteller privater Daten ist es für Benutzer schwierig, die von ihnen verdienten Belohnungen zu erhalten.Benutzer haben häufig keine Ahnung, wie ihre Daten gesammelt, verarbeitet und verwendet werden, und es ist auch schwierig, den Umfang und die Art und Weise der Verwendung der Daten zu bestimmen.Das Überkollegen und Verwenden führt auch zu ernsthaften Privatsphärerisiken.
Beispielsweise enthüllte der Cambridge Analytica -Vorfall von Facebook große Schwachstellen, wie herkömmliche Datenanbieter Transparenz und Privatsphäre verwenden können.
-
Dateninsel: Darüber hinaus sind Echtzeitdaten aus verschiedenen Quellen und Formaten schwer schnell zu integrieren, was die Möglichkeit einer umfassenden Analyse beeinflusst.Viele Daten werden häufig in einer Organisation gesperrt, wodurch der Datenaustausch und die Innovation in Branchen und in Organisationen eingehalten wird, und der Datensilo-Effekt behindert die Integration und Analyse der Daten in der Domänen.
In der Verbraucherbranche müssen Marken beispielsweise Daten von E-Commerce-Plattformen, physischen Geschäften, sozialen Medien und Marktforschung integrieren. Diese Daten sind jedoch möglicherweise aufgrund der inkonsistenten oder Quarantine des Plattformformats schwer zu integrieren.Zum Beispiel können gemeinsame Reiseunternehmen wie Uber und Lyft, obwohl beide eine große Menge an Echtzeitdaten über den Transport, die Bedürfnisse und den geografischen Standort von Benutzern erfassen, nicht aufgrund des Wettbewerbs vorgeschlagen und geteilt und integriert werden.
Darüber hinaus gibt es auch Probleme wie Kosteneffizienz und Flexibilität.Traditionelle Datenanbieter reagieren aktiv auf diese Herausforderungen, aber die aufkommende Web3 -Technologie bietet neue Ideen und Möglichkeiten zur Lösung dieser Probleme.
3.Web3 -Daten -Ökosystem
Seit der Veröffentlichung dezentraler Speicherlösungen wie IPFS (Interplanetary File System) im Jahr 2014 hat sich in der Branche eine Reihe aufstrebender Projekte entstanden, die sich zur Lösung der Grenzen des traditionellen Datenökosystems verpflichtet haben.Wir sehen, dass dezentrale Datenlösungen ein mehrstufiges, miteinander verbundenes Ökosystem gebildet haben, das alle Phasen des Datenlebenszyklus abdeckt, einschließlich Datenerzeugung, Speicher, Austausch, Verarbeitung und Analyse, Überprüfung und Sicherheit sowie Privatsphäre und Eigentümer.
-
Datenspeicherung: Die schnelle Entwicklung von Filecoin und Arweave beweist, dass die dezentrale Speicherung (DCS) zu einer Paradigmenverschiebung im Speicherplatz wird.Das DCS-Schema verringert das Risiko eines Einzelpunktversagens durch eine verteilte Architektur und zieht Teilnehmer mit einer wettbewerbsfähigeren Kosteneffizienz an.Mit der Entstehung einer Reihe von Anwendungsfällen in großem Maßstab hat die DCS-Speicherkapazität ein explosives Wachstum gezeigt (z. B. hat die Gesamtspeicherkapazität des Filecoin-Netzwerks im Jahr 2024 22 Exabyte erreicht).
-
Verarbeitung und Analyse: Dezentrale Datencomputerplattformen wie Fluence verbessern die Echtzeit und die Effizienz der Datenverarbeitung durch Edge Computing-Technologie und eignen sich besonders für Anwendungsszenarien wie das Internet der Dinge (IoT) und KI-Inferenz, die eine hohe Echtzeitleistung erfordern.Das Web3-Projekt verwendet Technologien wie Federated Learning, Differential Privacy, vertrauenswürdige Ausführungsumgebung und vollständig homomorphe Verschlüsselung, um flexiblen Schutz und Kompromisse für Datenschutz und Kompromisse auf der Rechenschicht zu bieten.
-
Datenmarkt-/Austauschplattform: Um die Quantifizierung und Zirkulation des Datenwerts zu fördern, hat Ocean Protocol effiziente und offene Datenaustauschkanäle durch Tokenisierung und DEX um ihnen zu helfen, den Datenaustausch im Lieferkettenmanagement zu teilen.StreamR hingegen hat ein für IoT- und Echtzeit-Analytics-Szenarien geeignetes, abonnementbasiertes Datenstrom-Netzwerk erstellt, das ein hervorragendes Potenzial für Transport- und Logistikprojekte zeigt (z. B. mit finnischen Smart City-Projekten).
Mit der zunehmenden Häufigkeit des Datenaustauschs und der Nutzung sind die Authentizität, Glaubwürdigkeit und Privatsphäre von Daten zu Schlüsselproblemen geworden, die nicht ignoriert werden können.Dies hat das Web3 -Ökosystem dazu veranlasst, die Innovation auf die Bereiche der Datenüberprüfung und des Schutzes des Datenschutzes zu erweitern und eine Reihe bahnbrechender Lösungen zur Welt zu bringen.
3.1 Innovation bei der Datenüberprüfung und des Schutzes des Datenschutzes
Viele Web3 -Technologie und native Projekte arbeiten an der Lösung von Datenauthentizität und privaten Datenschutzproblemen.Zusätzlich zu ZK wurden MPC und andere Technologien weit verbreitet, unter denen der Notar (TLS Notar) als aufstrebende Verifizierungsmethode besonders aufmerksam ist.
Einführung in TLS Notar
Transport Layer Security Protocol (TLS) ist ein Verschlüsselungsprotokoll, das in der Netzwerkkommunikation weit verbreitet ist und die Sicherheit, Integrität und Vertraulichkeit der Datenübertragung zwischen Clients und Servern sicherstellen soll.Es ist ein üblicher Verschlüsselungsstandard in der modernen Netzwerkkommunikation und wird in HTTPS, E -Mail, Instant Messaging und anderen Szenarien verwendet.
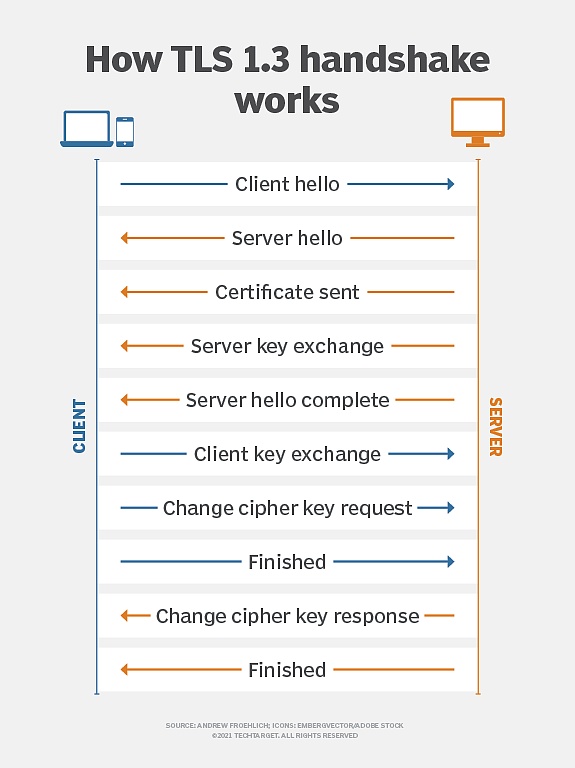
(TLS -Verschlüsselungsprinzip, Quelle: TechTarget)
Als es vor zehn Jahren geboren wurde, bestand das ursprüngliche Ziel von TLS Notary darin, die Authentizität von TLS-Sitzungen zu überprüfen, indem „Notare“ von Drittanbietern außerhalb des Clients (Prover) und Server eingeführt wurde.
Mithilfe der wichtigsten Segmentierungstechnologie wird der Hauptschlüssel der TLS -Sitzung in zwei Teile unterteilt, die vom Kunden und des Notars gehalten werden.Dieses Design ermöglicht es den Notaren, an dem Überprüfungsprozess als vertrauenswürdige Dritte teilzunehmen, kann jedoch nicht auf den tatsächlichen Kommunikationsinhalt zugreifen.Dieser Notarisierungsmechanismus soll Man-in-the-Middle-Angriffe erkennen, betrügerische Zertifikate verhindern, sicherstellen, dass die Kommunikationsdaten während der Übertragung nicht manipuliert werden, und es ermöglicht vertrauenswürdige Dritte, die Legitimität der Kommunikation zu bestätigen und gleichzeitig die Privatsphäre der Kommunikation zu schützen.
Daher bietet der TLS -Notare eine sichere Datenüberprüfung und gleicht die Überprüfungsanforderungen und den Schutz des Datenschutzes effektiv aus.
Im Jahr 2022 wird das TLS -Notarprojekt durch das Forschungslabor für Datenschutz- und Erweiterungsexploration (PSE) der Ethereum Foundation umgebaut.Die neue Version des TLS -Notarprotokolls wird in der Rust -Sprache von Grund auf neu geschrieben und enthält fortgeschrittenere Verschlüsselungsprotokolle (wie MPC). nicht durchgesickerte Dateninhalte.Während die Aufrechterhaltung der ursprünglichen TLS -Notar -Kernüberprüfungsfunktion, verbessert es den Datenschutzschutz erheblich, wodurch sie für die aktuellen und zukünftigen Datenschutzanforderungen geeigneter werden.
3.2 Variationen und Erweiterungen des TLS -Notars
In den letzten Jahren hat sich auch die TLS -Notare -Technologie kontinuierlich weiterentwickelt und hat sich auf der Grundlage der Entwicklung entwickelt und mehrere Varianten erstellt, wodurch die Datenschutz- und Überprüfungsfunktionen weiter verbessert werden:
-
Zktls: Eine von Datenschutzwesen verbesserte Version des TLS-Notars, kombiniert mit der ZKP-Technologie, ermöglicht es Benutzern, verschlüsselte Beweise von Webseitendaten zu generieren, ohne sensible Informationen aufzudecken.Es ist für Kommunikationsszenarien geeignet, die einen extrem hohen Datenschutzschutz erfordern.
-
3p-tls (Drei-Parteien TLS): Der Client, Server und Auditor werden eingeführt, damit die Auditoren die Sicherheit der Kommunikation überprüfen können, ohne den Kommunikationsinhalt zu veröffentlichen.Dieses Protokoll ist sehr nützlich in Szenarien, in denen Transparenz erforderlich ist, der Schutz des Datenschutzes jedoch erforderlich ist, z. B. Überprüfungen von Compliance oder Audits von Finanztransaktionen.
Web3 -Projekte verwenden diese Verschlüsselungstechnologien, um die Datenüberprüfung und den Schutz des Datenschutzes zu verbessern, das Datenmonopol zu brechen, Datensilos und vertrauenswürdige Übertragungsprobleme zu lösen und die Benutzer zu ermöglichen, ihre Privatsphäre zu beweisen, ohne ihre Einkaufsunterlagen für Social -Media -Konten und Finanzkredite zu enthüllen. , Professionelle Hintergrund- und akademische Zertifizierungsinformationen, wie z. B.:
-
Reclaim Protocol verwendet die ZKTLS-Technologie, um Null-Wissen-Beweise für den HTTPS-Verkehr zu generieren, sodass Benutzer Aktivität, Reputation und Identitätsdaten von externen Websites sicher importieren können, ohne sensible Informationen aufzudecken.
-
ZKPASS kombiniert die 3P-TLS-Technologie, mit der Benutzer reale private Daten ohne Leck zu überprüfen können.
-
Das Opacity -Netzwerk basiert auf ZKTLs, mit dem Benutzer ihre Aktivitäten auf verschiedenen Plattformen (wie Uber, Spotify, Netflix usw.) sicher beweisen können, ohne direkt auf die APIs dieser Plattformen zuzugreifen.Implementieren Sie plattformübergreifende Aktivitätsbeweise.
(Projekte arbeiten on tls oracles, Quelle: Bastian Wetzel)
Als wichtige Verbindung in der Daten-Ökosystemkette ist die Datenüberprüfung von Web3 umfassende Anwendungsaussichten.Die Entwicklung der Authentizitätsprüfungstechnologie ist jedoch nur der Beginn des Aufbaus einer neuen Generation von Dateninfrastruktur.
4. Dezentrales Data -Netzwerk
Einige Projekte kombinieren die oben genannte Datenüberprüfungs-Technologie, um eingehendere Erkundungen im vorläufigen Datenökosystem, nämlich Datenverfolgbarkeit, verteilte Datenerfassung und vertrauenswürdige Übertragung, eingehendere Erkundungen zu machen.Hier sind mehrere repräsentative Projekte: OpenLayer, Grass und Vana, die ein einzigartiges Potenzial beim Aufbau einer Dateninfrastruktur der nächsten Generation aufweisen.
4.1 OpenLayer
OpenLayer ist einer der A16Z Crypto Spring 2024 Crypto Entrepreneurship Accelerator -Projekte und dient als erste modulare reale Datenebene, die sich der Bereitstellung einer innovativen modularen Lösung für die Koordinierung der Datenerfassung, -verifizierung und -Transformation für die Bedürfnisse von Web2- und Web3 -Unternehmen verpflichtet hat.OpenLayer hat Unterstützung von bekannten Fonds und Angel-Investoren, einschließlich Geometrieunternehmen, Longhash Ventures, unterstützt.
In der traditionellen Datenschicht gibt es mehrere Herausforderungen: Der Mangel an vertrauenswürdiger Überprüfungsmechanismus, die Abhängigkeit von der zentralisierten Architektur führt zu einer Einschränkung des Zugriffs, den Daten zwischen verschiedenen Systemen fehlt Interoperabilität und Liquidität, und es gibt auch keinen Mechanismus für faire Datenwertzuordnungen.
Ein konkretteres Problem ist, dass KI -Trainingsdaten heute immer knapper werden.Im öffentlichen Internet haben viele Websites begonnen, Anti-Crawler-Beschränkungen zu nutzen, um zu verhindern, dass KI-Unternehmen Daten im Maßstab kriechen.
Und inPrivate und proprietäre DatenEinerseits ist die Situation komplizierter.Nach diesem Status Quo können Benutzer keine direkten Vorteile durch Bereitstellung privater Daten erhalten und sind daher nicht bereit, diese sensiblen Daten zu teilen.
Um diese Probleme zu lösen, hat OpenLayer eine modulare authentische Datenschicht mit der Datenverifizierungstechnologie erstellt und die Datenerfassung, Überprüfung und Konvertierung in einer dezentralen + wirtschaftlichen Anreize für Web2- und Web3 -Unternehmen koordiniert. Infrastruktur.
4.1.1 Die Kernkomponenten des modularen OpenLayer -Designs
OpenLayer bietet eine modulare Plattform, um den Prozess der Datenerfassung, der vertrauenswürdigen Überprüfung und der Konvertierung zu vereinfachen:
a) OpenNodes
OpenNodes ist die Kernkomponente für die dezentrale Datenerfassung im OpenLayer -Ökosystem.
OpenNodes unterstützt drei Hauptdatentypen, um den Anforderungen verschiedener Arten von Aufgaben zu erfüllen:
-
Öffentlich verfügbare Internetdaten (wie Finanzdaten, Wetterdaten, Sportdaten und Social Media -Streams)
-
Benutzer private Daten (z. B. Netflix -Ansichtsverlauf, Amazon -Bestellverlauf usw.)
-
Selbstberichtete Daten aus sicheren Quellen (z. B. von einem proprietären Eigentümer unterzeichneten Daten oder von einer bestimmten vertrauenswürdigen Hardware überprüft).
Entwickler können problemlos neue Datentypen hinzufügen, neue Datenquellen, Anforderungen und Datenabrufmethoden angeben, und Benutzer können entscheiden, festgelegte Daten im Austausch gegen Belohnungen bereitzustellen.Mit diesem Design kann das System kontinuierlich erweitert werden, um sich an neue Datenanforderungen anzupassen.
b) OpenValidatoren
OpenValidators sind für die Datenüberprüfung nach der Sammlung verantwortlich, sodass Datenverbraucher bestätigen, dass die vom Benutzer bereitgestellten Daten genau mit der Datenquelle übereinstimmen.Alle bereitgestellten Überprüfungsmethoden können durch Verschlüsselung überprüft werden, und die Verifizierungsergebnisse können anschließend überprüft werden.Für den gleichen Beweistyp gibt es mehrere verschiedene Anbieter, um Dienste bereitzustellen.Entwickler können den am besten geeigneten Überprüfungsanbieter entsprechend ihren Bedürfnissen auswählen.
In anfänglichen Anwendungsfällen, insbesondere für öffentliche oder private Daten der Internet -API, verwendet OpenLayer TLSNotary als Überprüfungslösung, um Daten aus einer Webanwendung zu exportieren und die Authentizität der Daten zu beweisen, ohne die Privatsphäre zu beeinträchtigen.
Das Verifizierungssystem kann dank seines modularen Designs nicht auf TLSNotary beschränkt sind, sondern kann auf andere Verifizierungsmethoden zugreifen, um verschiedene Arten von Daten- und Überprüfungsanforderungen zu entsprechen, einschließlich, aber nicht beschränkt auf:
-
Bewohnte TLS -Verbindungen: Verwenden Sie eine vertrauenswürdige Ausführungsumgebung (TEE), um eine zertifizierte TLS -Verbindung herzustellen, um die Integrität und Authentizität von Daten während der Übertragung sicherzustellen.
-
Sichere Enklaven: Verwenden Sie sichere Isolationsumgebungen auf Hardware-Ebene (wie Intel SGX), um sensible Daten zu verarbeiten und zu überprüfen, um ein höheres Datenschutzniveau bereitzustellen.
-
ZK -Proof -Generatoren: Integriertes ZKP, das die Überprüfung von Dateneigenschaften oder Berechnungsergebnissen ermöglicht, ohne Originaldaten anzugeben.
c) openconnect
OpenConnect ist das Kernmodul im OpenLayer -Ökosystem, das für die Datenumwandlung und die Realisierung der Verfügbarkeit verantwortlich ist, Daten aus verschiedenen Quellen verarbeitet, die Interoperabilität von Daten zwischen verschiedenen Systemen sicherstellen und die Anforderungen verschiedener Anwendungen erfüllen.Zum Beispiel:
-
Konvertieren Sie Daten in ein On-Ketten-Orakelformat, das für die direkte Verwendung von intelligenten Verträgen geeignet ist.
-
Umwandeln Sie unstrukturierte Rohdaten in strukturierte Daten und führen Sie die Vorverarbeitung für KI-Schulungen und andere Zwecke durch.
Für Daten aus privaten Konten von Benutzern bietet OpenConnect Daten -Desensibilisierung zum Schutz der Privatsphäre sowie Komponenten zur Verbesserung der Sicherheit während des Datenaustauschs und zur Verringerung von Datenverletzungen und Missbrauch.Um die Anforderungen von Echtzeitdaten für Anwendungen wie AI und Blockchain zu erfüllen, unterstützt OpenConnect eine effiziente Echtzeit-Datenkonvertierung.
Derzeit ist OpenLayer AVS-Betreiber durch Integration mit Eigenlayer Datenanforderungsaufgaben überwacht, verantwortlich für die Krabbeln von Daten und die Überprüfung der IT und meldet dann die Ergebnisse an das System, um Vermögenswerte durch Eigenlayer zu verpflichten oder neu zu stillen .Wenn ein böswilliges Verhalten bestätigt wird, werden Sie das Risiko ausgesetzt sein, eine Geldstrafe zu belegt und aus dem verpfändeten Vermögen beschlagnahmt zu werden.Als eines der frühesten AVs (Active Verification Services) des Eigenlayer-Hauptnetzes hat OpenLayer mehr als 50 Betreiber und 4 Milliarden US-Dollar für die Wiederaufnahme von Vermögenswerten angezogen.
Im Allgemeinen erweitert die von OpenLayer erstellte dezentrale Datenschicht den Umfang und die Vielfalt der verfügbaren Daten, ohne die Praktikabilität und Effizienz zu beeinträchtigen, während die Authentizität der Daten durch Verschlüsselungstechnologie und wirtschaftliche Anreize sicherstellt.Seine Technologie verfügt über eine breite Palette praktischer Anwendungsfälle für Web3-Dapps, um außerkettige Informationen, KI-Modelle zu erhalten, für die echte Input zum Training und Abschluss erforderlich ist, und Unternehmen, die Benutzer segmentieren und auf der Grundlage ihrer vorhandenen Identität und Reputation suchen möchten.Benutzer können auch ihre privaten Daten bewerten.
4.2 Gras
Grass ist ein Flaggschiffprojekt, das von Wynd Network entwickelt wurde, um eine dezentrale Web -Crawler- und KI -Trainingsdatenplattform zu erstellen.Ende 2023 absolvierte das Grass -Projekt eine Saatgut -Runde in Höhe von 3,5 Millionen US -Dollar unter der Leitung von Polychain Capital und Tribe Capital.Unmittelbar danach, im September 2024, leitete das Projekt eine von Hackvc angeführte Serie-A-Finanzierung mit bekannten Investmentinstitutionen wie Polychain, Delphi, Gitter und Brevan Howard teil.
Wir haben erwähnt, dass das KI -Training eine neue Datenbelastung erfordert, und eine der Lösungen besteht darin, mehrere IPs zu verwenden, um Datenzugriffsberechtigungen zu durchbrechen und KI -Daten zu füttern.Grass begann davon, um ein verteiltes Crawler -Knoten -Netzwerk zu erstellen, das sich der Nutzung der Leerlaufbandbreite der Benutzer zum Sammeln und Bereitstellen von überprüfbaren Datensätzen für das KI -Training in Form einer dezentralen physischen Infrastruktur widmet.Der Knoten leitet Webanforderungen über die Internetverbindung des Benutzers weiter, greift auf öffentliche Websites zu und erstellt strukturierte Datensätze.Es verwendet die Edge Computing -Technologie, um die vorläufige Datenreinigung und -formatierung durchzuführen, um die Datenqualität zu verbessern.
Gras nimmt die Solana Layer 2 -Datenrollup -Architektur an, die auf Solana basiert, um die Verarbeitungseffizienz zu verbessern.Grass verwendet einen Validator, um Web -Transaktionen von Knoten zu empfangen, zu verifizieren und zu stapeln, und generieren ZK -Proofs, um die Datenauthentizität sicherzustellen.Die verifizierten Daten werden im Data Ledger (L2) gespeichert und mit dem entsprechenden L1 -Kettensicherheit verbunden.
4.2.1 Gras Hauptkomponenten
A) Grasknoten
Ähnlich wie bei OpenNodes installieren C-End-Benutzer Grasanwendungen oder Browser-Erweiterungen und führen sie aus, verwenden Sie die Idle-Bandbreite, um Netzwerk-Crawling-Vorgänge durchzuführen, Webanforderungen des Benutzers über die Internetverbindung des Benutzers zu starten, auf öffentliche Websites zuzugreifen und strukturierte Datensätze zu kompilieren und Edge Computing zu verwenden Technologie zur Durchführung.Benutzer erhalten Gras -Token -Belohnungen auf der Grundlage der Bandbreite und der Datenmenge, die beigetragen haben.
b) Router
Schließen Sie Grasknoten und Validatoren an, verwalten Sie Knotennetzwerke und Relaisbandbreite.Router werden dazu angeregt, Belohnungen zu betreiben und zu erhalten, wobei das Belohnungsverhältnisanteil Anteil an Proportionen an der Gesamtüberprüfungsbandbreite durchläuft.
c) Validatoren
Empfangen, Überprüfungen und Stapel -Web -Transaktionen aus dem Router, generieren Sie ZK -Proofs, verwenden Sie einen eindeutigen Schlüsselsatz, um eine TLS -Verbindung herzustellen, und wählen Sie die entsprechende Cipher -Suite für die Kommunikation mit dem Ziel -Webserver aus.Grass verwendet derzeit einen zentralisierten Validator und plant, in Zukunft zum Validator Committee zu wechseln.
d) ZK -Prozessor (ZK -Prozessor)
Erhalten Sie den Nachweis der Generierung jeder Knotensitzungsdaten aus dem Überprüfer, dem Batch -Beweis für die Gültigkeit aller Webanforderungen und senden Sie an Layer 1 (Solana).
e) Grasdatenbuch (Gras L2)
Speichern Sie den vollständigen Datensatz und verbinden Sie ihn mit der entsprechenden L1 -Kette (Solana).
f) Kantenbettungsmodell
Verantwortlich für die Konvertierung unstrukturierter Webdaten in strukturierte Modelle, die mit KI trainiert werden können.
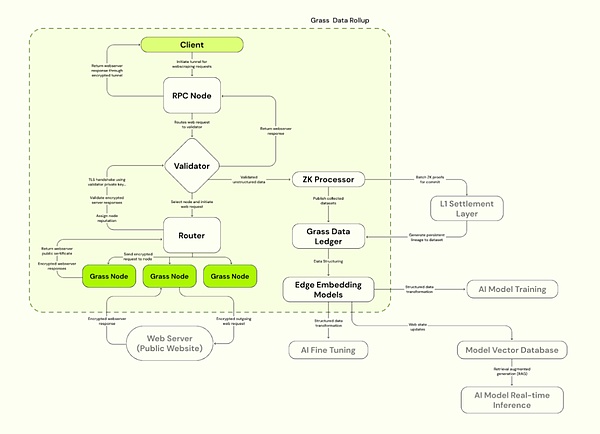
Quelle: Gras
Analyse und Vergleich von Gras und OpenLayer
Sowohl OpenLayer- als auch Gras -Hebel haben verteilte Netzwerke, um Unternehmen die Möglichkeit zu geben, auf offene Internetdaten und geschlossene Informationen zuzugreifen, für die Authentifizierung erforderlich ist.Der Incentive-Mechanismus fördert die Datenaustausch und die hochwertige Datenproduktion.Beide sind bestrebt, eine dezentrale Datenschicht zu erstellen, um das Problem des Zugriffs und der Überprüfung des Datenerfassungen zu lösen, jedoch leicht unterschiedliche technische Wege und Geschäftsmodelle einführen.
Verschiedene technische Architekturen
Grass verwendet die Layer 2 -Datenrollup -Architektur auf Solana und verwendet derzeit einen zentralisierten Überprüfungsmechanismus und einen einzelnen Validator.OpenLayer basiert als erste AVSDezentraler Überprüfungsmechanismus.Es wird auch ein modulares Design verwendet, wodurch die Skalierbarkeit und Flexibilität von Datenverifizierungsdiensten betont wird.
Produktunterschiede
Beide bieten ähnliche C -Produkte, sodass Benutzer den Wert von Daten über Knoten monetarisieren können.Auf B-Anwendungsfälle bietet Grass ein interessantes Datenmarktmodell und verwendet L2, um vollständige Daten zu speichern, um KI-Unternehmen einen strukturierten, qualitativ hochwertigen und überprüfbaren Schulungssatz zur Verfügung zu stellen.OpenLayer verfügt nicht über eine temporäre dedizierte Datenspeicherkomponente, bietet jedoch eine breitere Reihe von Echtzeit-Datenflussverifizierungsdiensten (VAAS). Für den RWA/Defi/Prediction Market-Projektpreis-Feed geben Sie in Echtzeit soziale Daten und mehr an.
Daher richtet sich der Kundenbasis von Grass hauptsächlich an KI-Unternehmen und Datenwissenschaftler, die großflächige und strukturierte Schulungsdatensätze bereitstellen und auch Forschungseinrichtungen und Unternehmen bedienen, die eine große Anzahl von Netzwerkdatensätzen erfordern. Off-Chain-Datenbedürfnisse.
Potenzieller Wettbewerb in der Zukunft
In Anbetracht der Branchentrends werden jedoch die Funktionen der beiden Projekte in Zukunft wahrscheinlich in Zukunft konvergieren.Gras kann bald auch in Echtzeit strukturierte Daten liefern.Als modulare Plattform kann OpenLayer in Zukunft auch auf das Datensatzmanagement erweitern, um ein eigenes Datenbuch zu haben, sodass sich die Wettbewerbsbereiche der beiden allmählich überschneiden können.
Darüber hinaus können beide Projekte in Betracht ziehen, Datenkennzeichnung als Schlüsselverbindung hinzuzufügen.Gras kann sich in dieser Hinsicht schneller bewegen, da sie ein riesiges Netzwerk von Knoten haben – Berichten zufolge mehr als 2,2 Millionen aktive Knoten.Dieser Vorteil gibt Gras das Potenzial, die Dienste für Verstärkungslernen (RLHF) zu erbringen, die auf menschlichem Feedback basieren und eine große Anzahl markierter Daten zur Optimierung von KI -Modellen verwenden.
OpenLayer kann jedoch mit seinem Know-how in Bezug auf Datenüberprüfung und Echtzeitverarbeitung seine Vorteile in Bezug auf die Datenqualität und Glaubwürdigkeit beibehalten.Als einer der AVs von Eigenlayer kann OpenLayer im dezentralen Überprüfungsmechanismus weiterentwickelt werden.
Während die beiden Projekte in bestimmten Bereichen konkurrieren können, können ihre jeweiligen einzigartigen Stärken und technischen Routen auch dazu führen, dass sie unterschiedliche Nischen im Datenökosystem besetzen.
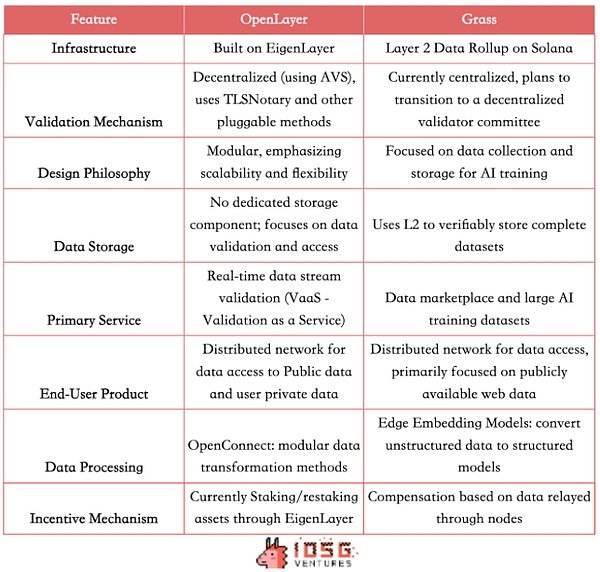
(Quelle: iOSG, David)
4.3 Vava
Als benutzerzentriertes Datenpool-Netzwerk setzt sich Vana auch dafür ein, qualitativ hochwertige Daten für KI und verwandte Anwendungen bereitzustellen.Im Vergleich zu OpenLayer und Gras nimmt Vana mehr unterschiedliche Technologiewege und Geschäftsmodelle an.Vana hat im September 2024 eine Finanzierung von 5 Millionen US-Dollar abgeschlossen, angeführt von Coinbase Ventures.
Vana wurde ursprünglich im Jahr 2018 als Forschungsprojekt für MIT eingeführt und zielt darauf ab, eine Blockchain in Layer -1 zu werden, die speziell für private Benutzerdaten entwickelt wurde.Mit seinen Innovationen in Bezug auf Datenbesitz und Wertverteilung können Benutzer aus KI -Modellen profitieren, die auf ihren Daten geschult sind.Der Kern von Vana ist durch vertrauenslose, private und zugeschriebenDatenliquiditätspoolund innovativBeitragsnachweisMechanismen, um den Kreislauf und den Wert privater Daten zu verwirklichen:
4.3.1
Vana führt ein einzigartiges Konzept des Datenliquiditätspools (DLP) ein: Als Kernkomponente des Vana-Netzwerks ist jedes DLP ein unabhängiges Peer-to-Peer-Netzwerk für die Aggregation bestimmter Arten von Datenanlagen.Benutzer können ihre privaten Daten (z. B. Einkaufsgeschichte, Browsing -Gewohnheiten, Social -Media -Aktivitäten usw.) in einen bestimmten DLP hochladen und entscheiden flexibel, ob diese Daten für bestimmte Dritte zur Verwendung autorisieren sollen.Die Daten werden über diese Liquiditätspools integriert und verwaltet, die nicht identifiziert werden, um die Privatsphäre der Benutzer zu gewährleisten und gleichzeitig die Teilnahme an kommerziellen Anwendungen wie für KI-Modellschulungen oder Marktforschung zuzulassen.
Benutzer senden Daten an DLP und erhalten entsprechende DLP -Token (jede DLP verfügt über eine bestimmte Token). .Benutzer können nicht nur Daten teilen, sondern können auch kontinuierliche Vorteile von nachfolgenden Aufrufen der Daten erhalten (und visuelle Verfolgung bereitstellen).Im Gegensatz zu herkömmlichen alltäglichen Datenverkäufen ermöglicht Vana die Daten weiterhin am Wirtschaftszyklus.
4.3.2.
Eine der anderen Kerninnovationen von Vana istBeitragsnachweis(Beitrag des Beitrags) Mechanismus.Dies ist der Hauptmechanismus von Vana, um die Datenqualität zu gewährleisten und jedem DLP einzigartige Beitragsbeweisfunktionen basierend auf seinen Merkmalen anzupassen, um die Authentizität und Integrität der Daten zu überprüfen und den Beitrag der Daten zur Leistungsverbesserung des KI -Modells zu bewerten.Dieser Mechanismus stellt sicher, dass die Datenbeiträge der Benutzer quantifiziert und aufgezeichnet werden, wodurch Benutzer Belohnungen bereitgestellt werden.Ähnlich wie der „Arbeitsnachweis“ in Kryptowährungen verteilt der Beitrag des Beitrags den Benutzern auf der Grundlage der Qualität, der Menge der von den Benutzern beigestellten Daten und der Nutzungshäufigkeit.Die automatische Ausführung intelligenter Verträge stellt sicher, dass Mitwirkende Belohnungen erhalten, die ihren Beiträgen entsprechen.
Vanas technische Architektur
-
Datenliquiditätsschicht
Dies ist die Kernschicht von Vana, die für den Beitrag, die Überprüfung und Aufzeichnung von Daten zu DLPs verantwortlich ist und Daten als übertragbares digitales Vermögen in die Kette einführt.DLP -Ersteller stellen DLP -Smart Contracts bereit, um den Zweck des Datenbeitrags, der Überprüfungsmethoden und der Beitragsparameter festzulegen.Datenversuche und Depotbanken senden Daten zur Überprüfung ein, und das POC -Modul (Nachweis des Beitrags (Nachweis des Beitrags) führt die Datenüberprüfung und die Wertschätzung durch und gewährt Governance -Rechte und -prämien basierend auf den Parametern.
-
Datentrennbarkeitsschicht
Dies ist eine offene Datenplattform für Datenversuche und Entwickler und auch die Anwendungsschicht von Vana.Die Datentretabilitätsschicht bietet einen Kollaborationsraum für Datenversorger und Entwickler, um Anwendungen mithilfe der in DLPs akkumulierten Datenliquidität zu erstellen.Bietet Infrastruktur für die verteilte Schulung von benutzerbezogenen Modellen und AI DAPP-Entwicklung.
-
Universal Connectome
Ein dezentrales Hauptbuch ist auch ein Echtzeitdatenflussdiagramm, das das gesamte Vana-Ökosystem durchläuft.Stellen Sie eine effektive Übertragung von DLP-Token sicher und geben Sie den Zugang zu DLP-Daten zu Anwendungen.Kompatibel mit EVM und ermöglicht die Interoperabilität mit anderen Netzwerken, Protokollen und Defi -Anwendungen.
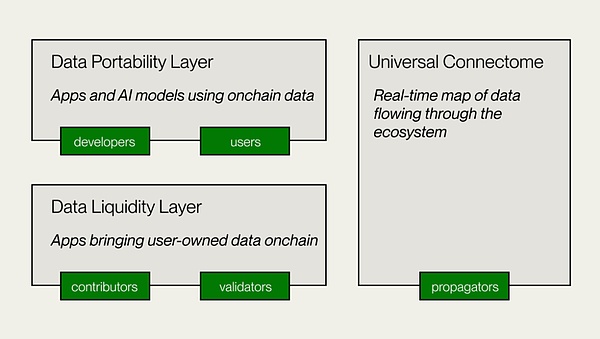
(Quelle: Vana)
Vana bietet einen relativ unterschiedlichen Weg und konzentriert sich auf die Liquidität und die Wertschöpfung von Benutzerdaten Interoperabilität und Lizenzierung bieten eine neue Lösung.Erstellen Sie letztendlich ein offenes Internet -Ökosystem, mit dem Benutzer ihre eigenen Daten sowie intelligente Produkte besitzen und verwalten können, die aus diesen Daten erstellt wurden.
5. Das Wertversprechen dezentraler Datennetzwerke
Der Datenwissenschaftler Clive Humby sagte 2006, dass Daten in der neuen Ära Öl sind.In den letzten 20 Jahren haben wir die rasche Entwicklung der „Raffinering“ -Technologie miterlebt.Technologie wie Big Data Analysis und maschinelles Lernen haben einen beispiellosen Datenwert ermöglicht.Laut der Prognose von IDC wird der globale Datenkreis bis 2025 auf 163 ZB wachsen, von denen die meisten von einzelnen Nutzern stammen. muss in Zukunft kommerzialisiert werden.
Schmerzpunkte traditioneller Lösungen: Innovation in Web3 freischalten
Über ein verteiltes Knotennetzwerk durchbricht die Web3-Datenlösung die Einschränkungen herkömmlicher Einrichtungen, erreicht eine breitere und effizientere Datenerfassung und verbessert die Effizienz der Echtzeit-Akquisition und die Glaubwürdigkeit bestimmter Daten.In diesem Prozess sorgt die Web3 -Technologie für die Authentizität und Integrität von Daten und kann die Privatsphäre der Benutzer effektiv schützen und so ein faireres Datenauslastungsmodell erreichen.Diese dezentrale Datenarchitektur fördert die DatenerfassungDemokratisierung.
Egal, ob es sich um den Benutzerknotenmodus von OpenLayer und Gras oder die Monetarisierung von Benutzer privaten Daten von Vana handelt, zusätzlich zur Verbesserung der Effizienz spezifischer Datenerfassung können gewöhnliche Benutzer die Dividenden der Datenwirtschaft teilen und ein Win-Win-Modell für Benutzer und Benutzer erstellen und Benutzer und Benutzer und Benutzer erstellen und Benutzer und Benutzer erstellen und Benutzer und Benutzer erstellen und Benutzer und Benutzer und Benutzer erstellen Entwickler, damit Benutzer ihre Daten und verwandten Ressourcen wirklich steuern und profitieren.
Durch die Token -Wirtschaft hat die Web3 -Datenlösung das Incentive -Modell neu gestaltet und einen mechanischeren Mechanismus für faire Datenwert zugewiesen.Es hat eine große Anzahl von Benutzern, Hardwareressourcen und Kapital angezogen, um den Betrieb des gesamten Datennetzwerks zu koordinieren und zu optimieren.
Sie haben auchModularität und Skalierbarkeit: Zum Beispiel bietet das modulare Design von OpenLayer Flexibilität für zukünftige technologische Iteration und ökologische Expansion.Dank der technischen Merkmale optimieren wir die Datenerfassungsmethode des KI -Modelltrainings, um reichhaltigere und vielfältigere Datensätze bereitzustellen.
Von der Datenerzeugung, Speicherung über Überprüfung bis hin zum Austausch und Analyse lösen Web3-gesteuerte Lösungen viele Nachteile traditioneller Einrichtungen durch einzigartige technologische Vorteile und geben den Benutzern auch die Möglichkeit, personenbezogene Daten zu monetarisieren, wodurch eine grundlegende Änderung des Datenwirtschaftsmodells ausgelöst wird.Mit der Weiterentwicklung und Entwicklung der Technologie und der Ausweitung von Anwendungsszenarien wird erwartet, dass die dezentrale Datenschicht zusammen mit anderen Web3-Datenlösungen die nächste Generation kritischer Infrastruktur wird, was eine breite Palette datengesteuerter Branchen unterstützt.







